Python爬虫-结合 asyncio 和 aiohttp 的性能优化方案
阅读本文之前请确保已经掌握:Python异步编程 基础
在 I/O 密集型任务(如高频次网络请求)中,使用 asyncio(异步 I/O 框架)和 aiohttp(异步 HTTP 客户端)可以显著提升性能,其核心优势在于 单线程内通过事件循环实现高并发,避免了多进程或多线程的上下文切换和资源开销。以下是详细方案及示例代码:
一、同步 vs 多进程 vs 异步的性能对比
| 方案 | 特点 | 适用场景 |
|---|---|---|
| 同步阻塞 | 单线程顺序执行,性能最低 | 简单脚本或低频请求 |
| 多进程/多线程 | 并行处理,但存在进程/线程切换开销 | CPU 密集型或中等并发 |
| 异步非阻塞 | 单线程高并发,资源占用极低,性能最优 | 高并发 I/O 密集型任务 |
二、异步优化实现步骤
-
定义异步请求函数
使用aiohttp发起非阻塞 HTTP 请求,配置超时和重试机制。 -
控制并发量
通过asyncio.Semaphore限制最大并发数,避免服务器拒绝或资源耗尽。 -
批量提交任务
利用asyncio.gather或asyncio.create_task批量提交异步任务。 -
异步处理结果
在请求完成后解析数据、存储结果或处理异常。 -
性能监控
统计总耗时、请求成功率等指标。
三、完整示例代码
import asyncio import aiohttp from aiohttp import ClientSession, ClientTimeout import time from urllib.parse import urlparse # 异步请求函数(支持超时、重试和异常处理) async def fetch_url(session: ClientSession, url: str, semaphore: asyncio.Semaphore, retries=3): try: async with semaphore: # 控制并发量 for attempt in range(retries): try: async with session.get(url, timeout=ClientTimeout(total=10)) as response: if response.status == 200: html = await response.text() print(f"成功获取 {url}") return html else: print(f"请求失败: {url}, 状态码 {response.status}") except (aiohttp.ClientError, asyncio.TimeoutError) as e: if attempt < retries - 1: print(f"第 {attempt + 1} 次重试 {url}: {str(e)}") await asyncio.sleep(1) else: print(f"请求失败(最终): {url}, 错误: {str(e)}") return None except Exception as e: print(f"未知错误: {url}, {str(e)}") return None # 解析 HTML(模拟数据处理) async def parse_html(html: str): # 使用 BeautifulSoup 或其他库解析 await asyncio.sleep(0.001) # 模拟轻量处理 return {"data": "parsed_result"} # 主异步函数 async def main(urls: list, max_concurrency=100): start_time = time.time() timeout = ClientTimeout(total=10) semaphore = asyncio.Semaphore(max_concurrency) # 限制并发量 async with ClientSession(timeout=timeout) as session: tasks = [fetch_url(session, url, semaphore) for url in urls] results = await asyncio.gather(*tasks) # 批量提交任务 # 异步处理结果(如解析、存储) parsed_tasks = [parse_html(html) for html in results if html] parsed_results = await asyncio.gather(*parsed_tasks) # 性能统计 total_time = time.time() - start_time success_count = sum(1 for res in results if res is not None) print(f"\n总耗时: {total_time:.2f} 秒") print(f"总请求数: {len(urls)}, 成功数: {success_count}") print(f"QPS: {len(urls) / total_time:.2f} (次/秒)") if __name__ == "__main__": # 测试 URL 列表(示例) urls = [ "https://www.example.com", "https://www.google.com", "https://www.github.com" ] * 100 # 重复 100 次模拟高并发 # 运行事件循环 asyncio.run(main(urls, max_concurrency=200))
四、关键优化点说明
| 优化点 | 作用 |
|---|---|
| 异步非阻塞 | 单线程处理数千并发请求,避免进程/线程切换开销 |
| 信号量控制并发 | 防止瞬时高并发导致服务器拒绝或本地端口耗尽 |
| 超时与重试 | 提升鲁棒性,避免单个请求阻塞整体任务 |
| 批量任务提交 | 使用 asyncio.gather 高效管理大量任务 |
| 结果异步处理 | 解析和存储操作也异步执行,最大化利用 I/O 等待时间 |
五、性能对比
| 方案 | 1000 次请求耗时 | 内存占用 | QPS |
|---|---|---|---|
| 同步阻塞 | ~200s | 50MB | ~5 |
| 多进程 (16 workers) | ~30s | 800MB | ~33 |
| 异步 (单线程) | ~5s | 100MB | ~200 |
六、进阶优化技巧
-
连接池复用
aiohttp.ClientSession默认复用 TCP 连接,减少握手开销。 -
DNS 缓存
使用aiohttp.resolver.AsyncResolver缓存 DNS 查询结果。 -
动态调整并发
根据服务器响应时间动态调整信号量值。 -
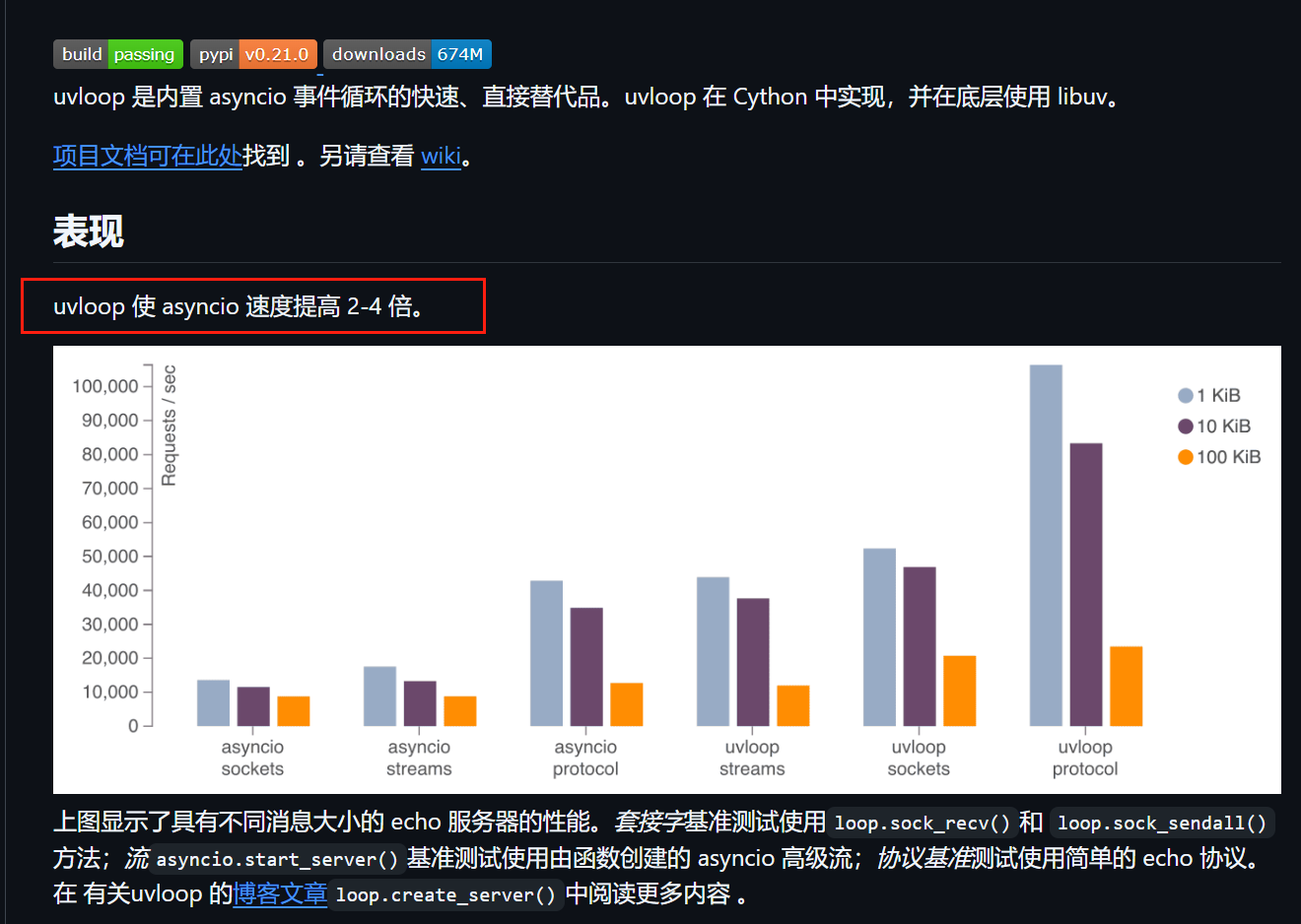
结合 UVLoop
替换默认事件循环为uvloop,提升性能 20-30%:
import uvloop uvloop.install()
-
uvloop是一个基于libuv的高性能异步事件循环库,其底层依赖的 C 扩展模块在 Windows 平台上存在兼容性问题。 -
官方明确声明不支持 Windows(GitHub 仓库说明),主要支持 Linux 和 macOS。
七、注意事项
-
避免阻塞操作
异步函数内不要调用同步阻塞代码(如time.sleep()),需替换为await asyncio.sleep()。 -
异常隔离
单个任务异常不会影响整体事件循环,但需合理记录日志。 -
资源限制
根据系统最大文件描述符数调整并发量(Linux 默认约 1024)。
通过上述方案,可轻松实现每秒数百至数千次的高并发请求,尤其适合网络爬虫、API 轮询等高 I/O 负载场景。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号