一文搞懂编码Unicode、utf-8、ISO-8859-1、GBK、ASCII 、扩展ASCII码、GB2312等知识
概述
五花八门的编码方式,Unicode、utf-8、ISO-8859-1、GBK、ASCII 、扩展ASCII码、GB2312等等,到底是什么关系?编码是怎么出现的?是怎么一步步发展的?每一种编码为什么诞生?本文彻底搞懂编码相关知识。
编码
- 信息从一种形式或格式转换为另一种形式的过程。
- 用代码来表示各种信息,以便于计算机处理。
需要编码的信息种类
- 数值
- 字符
- 声音
- 图形、图像
编码方式的发展历程与关系解析
1. 起源:ASCII(1963年)
-
背景:计算机初期仅处理英文,需要统一字符表示。计算机诞生于西方,所以一开始的编码只考虑了:数值和西文字符。
-
特点:
-
7位编码,共128个字符(0-127)。
-
包含英文大小写、数字、标点及控制字符(如换行、回车)。
-
-
问题:无法表示其他语言字符(如中文、法文符号)。

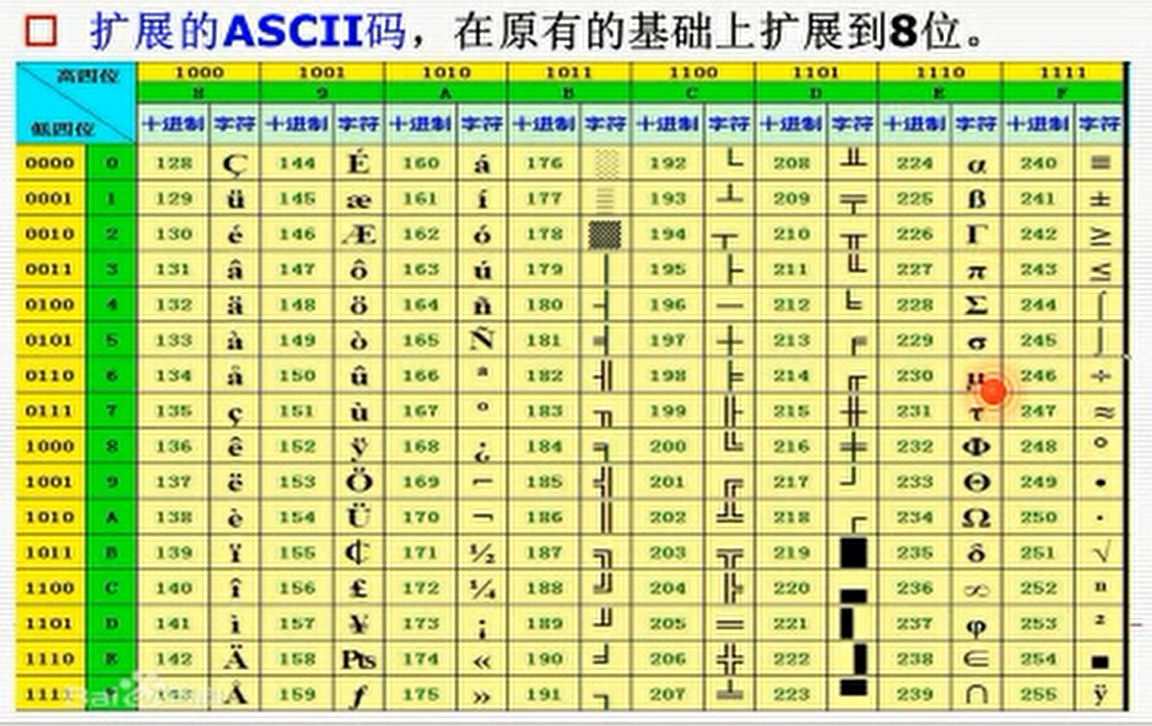
2. 扩展ASCII(8位时代)
-
背景:ASCII不够用,厂商自行扩展第8位(128-255)。
-
结果:
-
混乱的扩展:不同厂商定义不同符号(如IBM vs Windows)。
-
典型代表:
-
ISO-8859系列(1987年):标准化扩展,如:
-
ISO-8859-1(Latin-1):西欧语言(法语、西班牙语)。
-
ISO-8859-5:西里尔字母(俄语)。
-
-
Windows-1252:微软对ISO-8859-1的扩展,加入欧元符号等。
-
-
-
问题:仍无法覆盖亚洲语言(如中日韩文字)。
随着计算机从美国想欧洲普及,原来的ASCII码表无法表示一下欧洲国家字符,所以最后就把第8位利用起来,形成了总共256个字符的扩展ASCII码表:
3. 地区性编码的兴起
-
背景:各国需支持本地字符,自行制定标准。
-
代表编码:
-
GB2312(1980年,中国):GB2312 的 "2312" 是《国家标准编号》,代表该标准在国家标准体系中的顺序号,没有特殊技术含义。
-
完整名称:GB 2312-1980(1980年发布的国家标准第2312号)。
-
双字节编码,涵盖6763个简体汉字。
-
兼容ASCII:0-127与ASCII一致。
-
-
GBK(1993年):GB2312扩展,支持繁体及更多字符(21886字)(GBK即“国标”、“扩展”汉语拼音的第一个字母)。
-
Big5(台湾,1984年):繁体中文标准。
-
Shift_JIS(日本):支持日文假名和汉字。
-
-
问题:编码互不兼容,跨语言文本易乱码。

4. Unicode:大一统的尝试(1991年)
-
目标:为全球所有字符分配唯一编号(码点),终结编码混乱。
码点
-
- Unicode:定义全球字符的唯一编号(码点),如
U+4E2D表示“中”。
- Unicode:定义全球字符的唯一编号(码点),如
-
- 表示方式:
U+开头,后跟 4~6位十六进制数,例如:
- 表示方式:
-
-
-
-
- U+0041 → 字母 A
- U+4E2D → 汉字 中
- U+1F600 → 表情符号 😀
- 范围:从 U+0000 到 U+10FFFF(共 1,114,112 个可分配码点)。
-
-
-
-
编码方式:将码点转换为字节序列的规则,如 UTF-8、UTF-16、UTF-32。
-
码点分区
Unicode将所有码点划分为 17个平面(Planes),每个平面包含 65,536(2^16) 个码点:
| 平面名称 | 码点范围 | 用途 |
|---|---|---|
| 基本多文种平面 | U+0000 ~ U+FFFF |
覆盖绝大多数常用字符(英文、中文、日文等) |
| 辅助平面 | U+10000 ~ U+10FFFF |
生僻汉字、表情符号、历史文字等 |
码点分配规则
-
按语言/功能分区:
-
ASCII区:
U+0000~U+007F(直接兼容ASCII)。 -
CJK统一汉字区:
U+4E00~U+9FFF(覆盖中日韩常用汉字)。 -
表情符号区:
U+1F000~U+1F9FF(如😀、🚀)。
-
-
保留区:部分码点范围未分配,供未来扩展使用。
Unicode (码点)与编码方式的关系
码点只是字符的“逻辑编号”,具体存储或传输时需转换为字节序列(即编码方式):
| 编码方式 | 规则 | 示例(“中”的码点 U+4E2D) |
|---|---|---|
| UTF-8 | 将码点转换为1~4字节的变长编码 | 0xE4 0xB8 0xAD(3字节) |
| UTF-16 | 基本平面字符用2字节,辅助平面字符用4字节(代理对) | 0x4E 0x2D(2字节) |
| UTF-32 | 直接固定4字节表示码点 | 0x00004E2D(4字节) |
码点的实际应用
-
编程中的使用:
-
Python:
ord('中')→ 返回码点十进制值20013(对应十六进制4E2D)。 -
Java:
char类型实际存储UTF-16编码(仅支持基本平面)。
-
-
输入法支持:
输入Unicode码点直接打出字符(如Windows按Alt + 20013→ 输出“中”)。
Unicode编码方式的发展与进化:
UCS-2(1990年代初期):
-
-
固定2字节编码,仅支持 Unicode 的 基本多文种平面(BMP)(码点
U+0000到U+FFFF)。 -
问题:无法表示
U+FFFF以上的字符(如表情符号 🚀)。
-
UTF-32(1991年,Unicode 1.0)
-
出现背景:
Unicode最初想用固定长度编码覆盖所有字符,简化处理逻辑。 -
特点:
-
固定4字节表示每个字符(如
U+0000 4E2D表示“中”)。
-
-
解决的问题:
-
直接映射Unicode码点,无需复杂计算。
-
-
缺点:
-
空间浪费:存储英文文本时体积是ASCII的4倍。
-
未普及:仅用于特殊场景(如内存处理)。
-
UTF-16(1996年,Unicode 2.0)
-
出现背景:
Unicode早期使用2字节(UCS-2),但后来字符超6万,需扩展。 -
特点:
-
变长编码:基本字符用2字节,扩展字符用4字节(代理对)。
-
示例:“中” (
U+4E2D) 用4E 2D,而“😂” (U+1F602) 用D83D DE02。
-
-
解决的问题:
-
支持Unicode扩展(超出最初的16位限制)。
-
平衡存储效率和访问速度(适合内存操作)。
-
-
主要应用:
Windows系统内部、Java、JavaScript(早期)。
UTF-8(1993年,由Ken Thompson设计)
-
-
完全独立设计,与 UCS-2/UTF-16 无继承关系。
-
目标:兼容 ASCII 并优化网络传输。
-
-
出现背景:
解决ASCII兼容性和网络传输效率问题。 -
特点:
-
变长编码(1-4字节),英文保持单字节,中文用3字节。
-
示例:“A”用
41,“中”用E4 B8 AD。
-
-
解决的问题:
-
完美兼容ASCII:旧系统无需改造即可读取英文部分。
-
空间高效:英文为主的文本体积接近ASCII。
-
无字节序问题:适合网络传输和跨平台交换。
-
-
成为主流:
互联网(HTML、HTTP)、Linux、数据库默认编码。
三者的关系图
Unicode(字符集) ├─→ UCS-2(旧,固定2字节,仅支持 BMP) │ └─→ UTF-16(扩展,支持代理对) │ └─→ UTF-8(独立设计,变长1-4字节)
-
UTF-8:为兼容 ASCII 而生,适合存储和传输。
-
UTF-16:为高效处理 BMP 字符而生,适合内存操作。
-
UCS-2:UTF-16 的“前传”,已淘汰。



5. 现代编码格局
-
主流编码:
-
UTF-8:互联网首选,兼容ASCII,空间高效。
-
UTF-16:Java、Windows内部常用。
-
GBK:中文环境旧系统遗留支持。
-
-
编码关系图解:
ASCII (7位) │ ├─→ 扩展ASCII (ISO-8859-1, Windows-1252等) │ └─→ Unicode ├─→ UTF-8 ├─→ UTF-16 └─→ UTF-32
关键问答
Q1: 为什么需要多种Unicode编码方式(UTF-8/16/32)?
-
UTF-8:兼容ASCII,适合网络和存储(英文为主时省空间)。
-
UTF-16:平衡空间与性能,适合内存处理(如Java)。
-
UTF-32:固定长度,处理简单但浪费空间。
Q2: 如何避免乱码?
-
统一编码:系统、文件、通信均使用UTF-8。
-
显式声明:如HTML中
<meta charset="UTF-8">。 -
转换工具:使用
iconv等工具转换旧编码至UTF-8。
Q3: 实际例子:中文“中”在不同编码中的表示
-
GBK:
0xD6 0xD0(双字节)。 -
UTF-8:
0xE4 0xB8 0xAD(三字节,码点U+4E2D)。 -
UTF-16:
0x4E 0x2D(两字节,同码点)。
总结
-
编码发展动力:从英语到多语言支持,从混乱到统一。
-
选择建议:
-
现代系统:优先使用UTF-8。
-
遗留系统:根据地区使用GBK、Big5等。
-
-
核心原则:编码一致才能避免乱码,理解历史背景有助于处理兼容问题。
补充:
数值编码:
- 二进制码
- BCD码
西文字符编码
- ASCII码
BCD码



ASCII码




 浙公网安备 33010602011771号
浙公网安备 33010602011771号