Python requests 模块
Python requests 是一个常用的 HTTP 请求库,可以方便地向网站发送 HTTP 请求,并获取响应结果。
requests 模块比 urllib 模块更简洁。
使用 requests 发送 HTTP 请求需要先导入 requests 模块:
import requests
导requests模块失败(已成功安装requests模块的同学请跳过本段)
注意,如果导包之后还是报红:
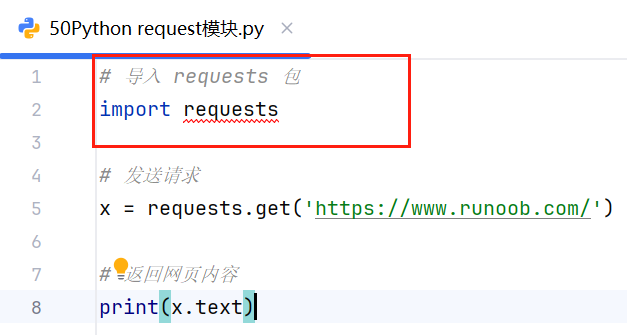
极有可能是安装requests没有成功,我们可以通过命令行安装试试:
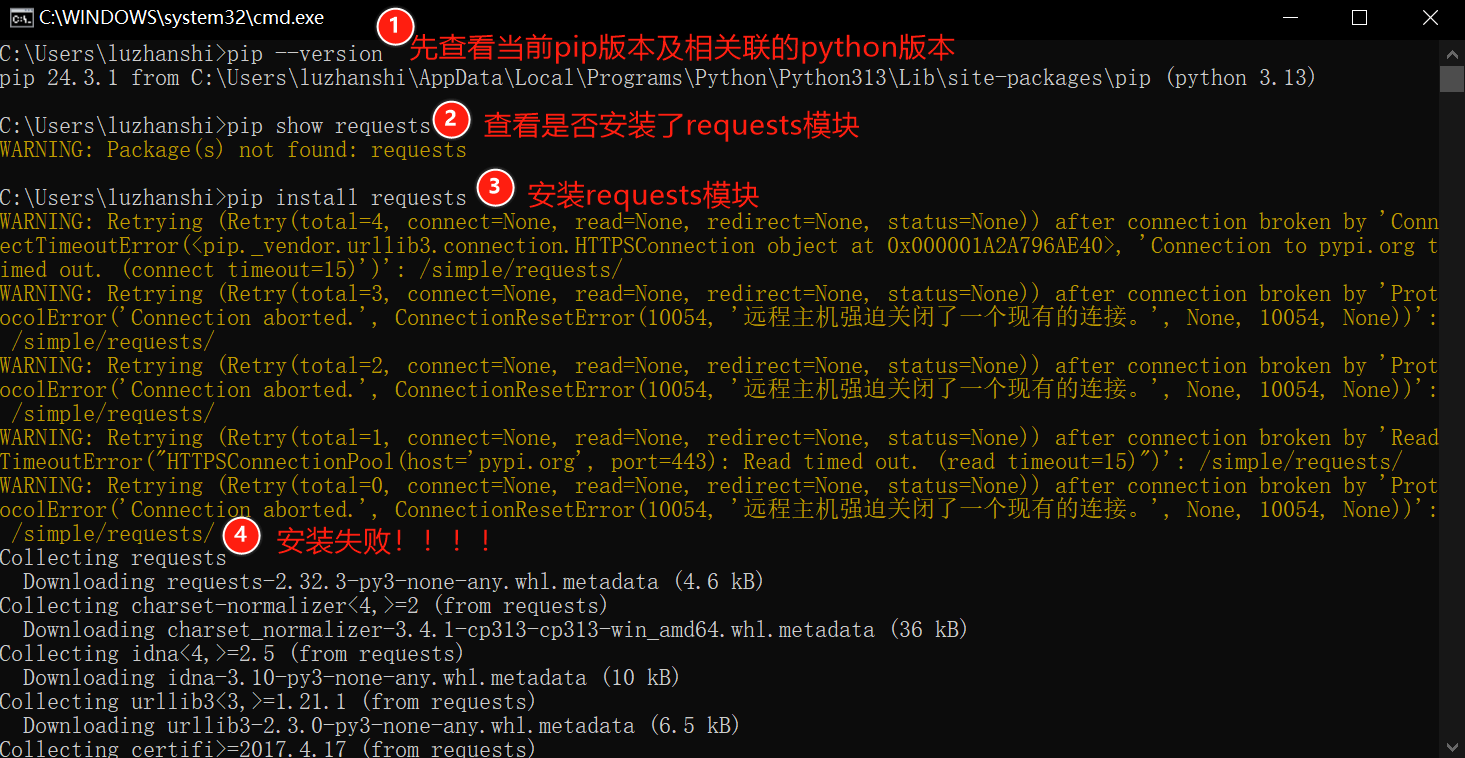
使用命令行安装也失败,但是命令行给出了原因:
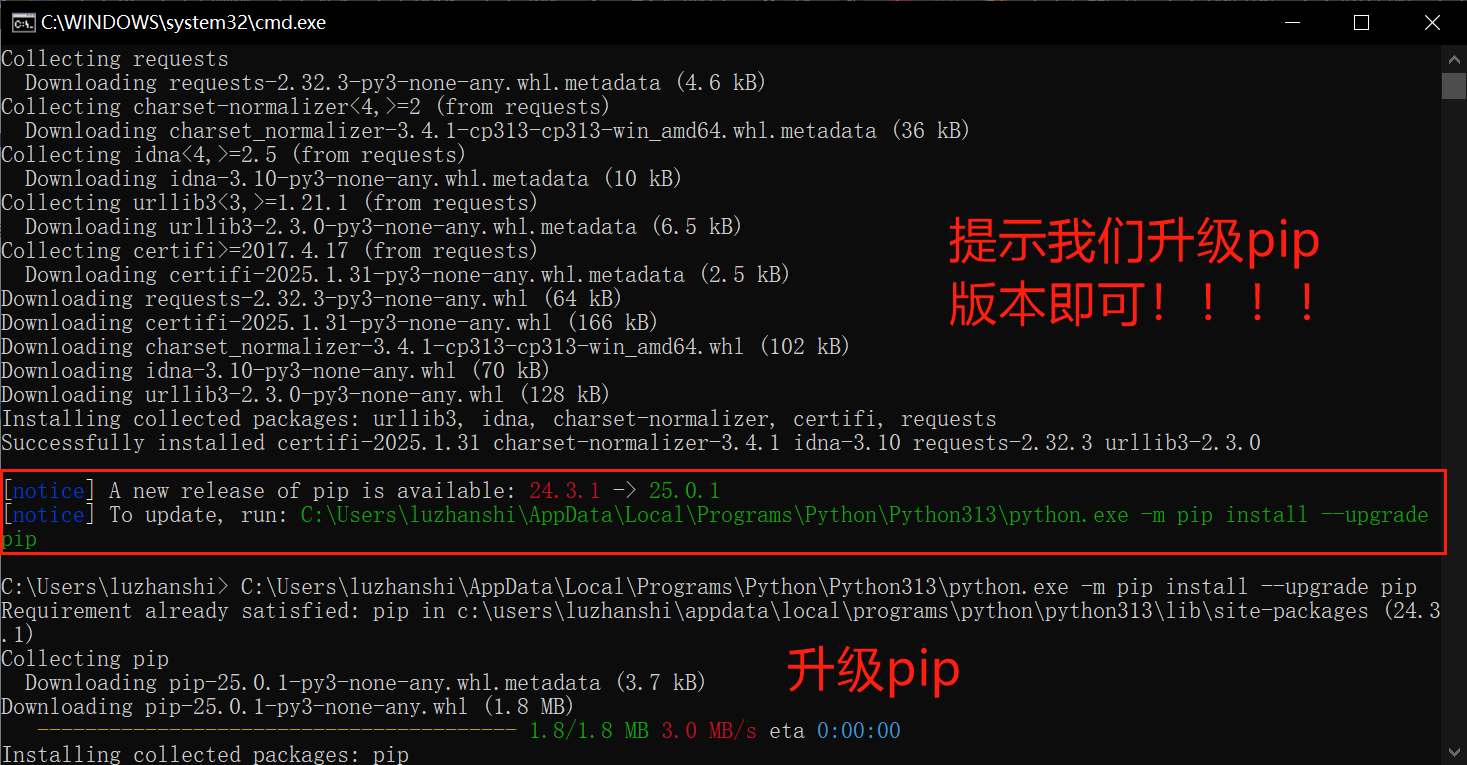
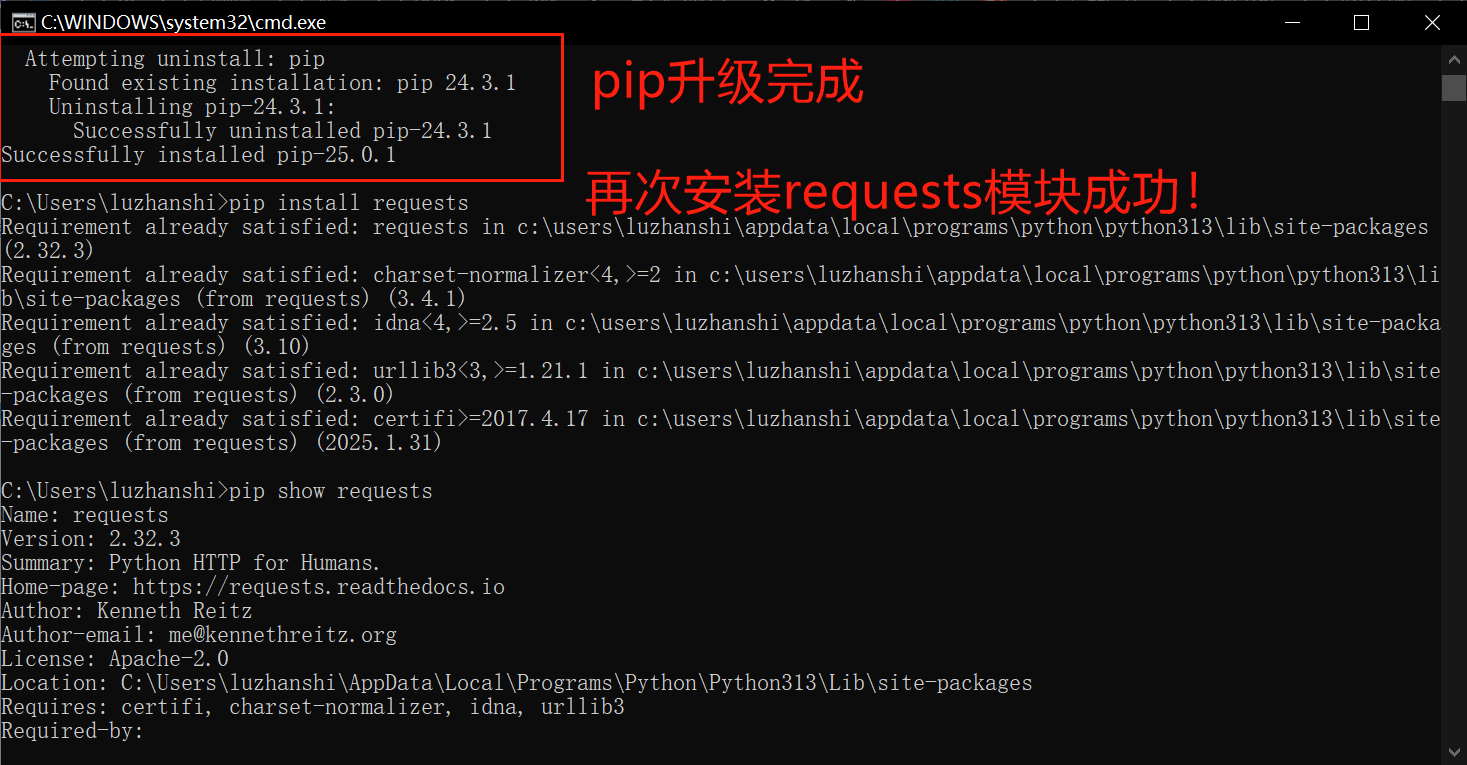
# 导入 requests 包 import requests url = r"https://www.runoob.com/" # 发送请求 response = requests.get(url) # 打印响应内容:每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息,如状态码、响应头、响应内容等: print(response) # <Response [200]> # 获取响应状态码 print(response.status_code) # 200 # 获取响应头 print( response.headers) # {'Date': 'Sun, 23 Mar 2025 08:36:19 GMT', 'Content-Type': 'text/html; charset=UTF-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Link': '<http://www.runoob.com/wp-json/>; rel="https://api.w.org/"', 'Content-Encoding': 'gzip', 'X-Ser': 'i27159_c3573, i36126_c26725', 'X-Cache': 'HIT from i36126_c26725(cloudsvr)'} # 返回响应的内容,以字节为单位 print(response.content) # 返回响应的内容,unicode 类型数据 print(response.text) #返回响应的 URL print(response.url) # https://www.runoob.com/ # 编码方式 print(response.apparent_encoding) # utf-8 # 解码 r.text 的编码方式 print(response.encoding) # UTF-8
请求 json 数据文件,返回 json 内容:
jsonurl="https://www.runoob.com/try/ajax/json_demo.json" response = requests.get(jsonurl) print(response.json())#{'name': '网站', 'num': 3, 'sites': [{'name': 'Google', 'info': ['Android', 'Google 搜索', 'Google 翻译']}, {'name': 'Runoob', 'info': ['菜鸟教程', '菜鸟工具', '菜鸟微信']}, {'name': 'Taobao', 'info': ['淘宝', '网购']}]}
更多响应信息如下:
| 属性或方法 | 说明 |
|---|---|
| apparent_encoding | response.apparent_encoding 是 requests 通过内容分析(使用 chardet 库)推测出的编码。更准确,更接近真实编码,但 检测需要时间(对大型响应可能影响性能) |
| encoding | 解码 r.text 的编码方式:response.encoding 是 requests 用来将响应内容(二进制 response.content)解码为字符串(response.text)的字符编码。可能不准确 |
| close() | 关闭与服务器的连接 |
| content | 返回响应的内容,以字节为单位;
|
| text | 返回响应的内容,unicode 类型数据;即,content采用encoding的值(utf-8或者gbk等)进行解码之后就得到text
response.content.decode()==response.text
|
| cookies | 返回一个 CookieJar 对象,包含了从服务器发回的 cookie |
| elapsed | 返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 |
| headers | 返回响应头,字典格式; |
| history | 返回包含请求历史的响应对象列表(url) |
| is_permanent_redirect | 如果响应是永久重定向的 url,则返回 True,否则返回 False |
| is_redirect | 如果响应被重定向,则返回 True,否则返回 False |
| iter_content() | 迭代响应 |
| iter_lines() | 迭代响应的行 |
| json() | 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
| links | 返回响应的解析头链接 |
| next | 返回重定向链中下一个请求的 PreparedRequest 对象 |
| ok | 检查 "status_code" 的值,如果小于400,则返回 True,如果不小于 400,则返回 False |
| raise_for_status() | 如果发生错误,方法返回一个 HTTPError 对象 |
| reason | 响应状态的描述,比如 "Not Found" 或 "OK" |
| request | 返回请求此响应的请求对象 |
| status_code | 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) |
| url | 返回响应的 URL |

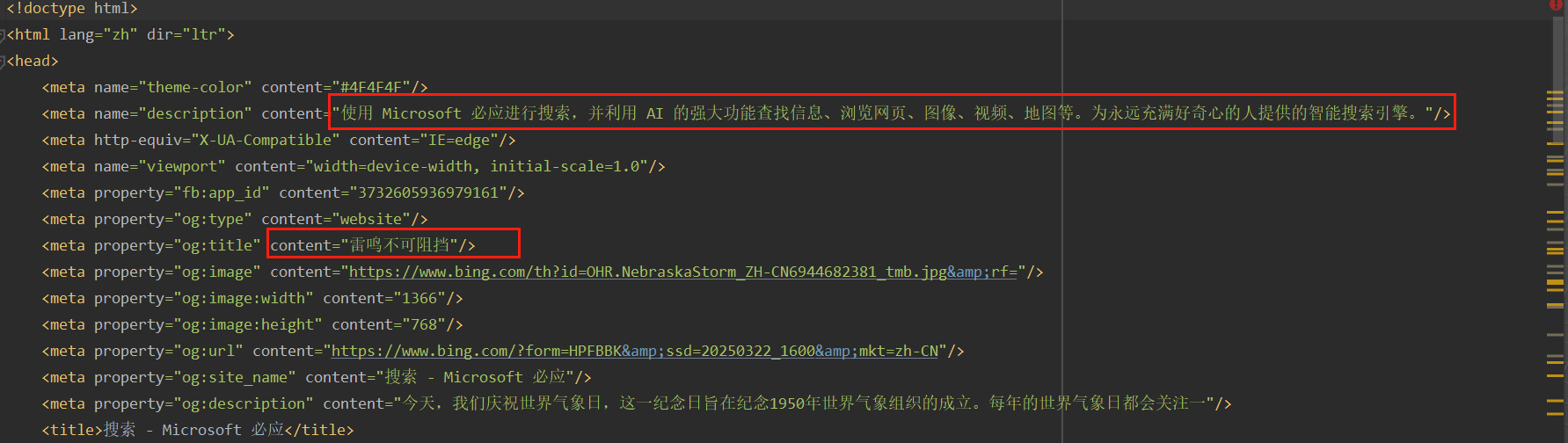
中文乱码问题
在 Python 的 requests 模块中,response.encoding 和 response.apparent_encoding 是用于处理 响应内容编码 的两个重要属性。
1. response.encoding
定义:
-
官方文档:
response.encoding是requests用来将响应内容(二进制response.content)解码为字符串(response.text)的字符编码。 -
来源:
-
优先从 HTTP 响应头中的
Content-Type字段提取编码(例如Content-Type: text/html; charset=utf-8)。 -
如果响应头未指定编码,则尝试从 HTML 的
<meta>标签中解析编码(如<meta charset="gbk">)。 -
如果上述均未找到,则默认使用
ISO-8859-1(一种兼容 ASCII 的编码)。
-
特点:
-
是
requests自动推断的编码,可能不准确。 -
直接影响
response.text的解码结果(若编码错误,response.text会显示乱码)。 -
可以手动修改(例如
response.encoding = 'utf-8')以纠正解码错误。
import requests response = requests.get("https://www.example.com") print(response.encoding) # 输出可能为 'utf-8' 或 'ISO-8859-1'
2. response.apparent_encoding
定义:
-
官方文档:
response.apparent_encoding是requests通过内容分析(使用chardet库)推测出的编码。 -
来源:
-
完全基于响应内容(
response.content)的统计分析,与 HTTP 头或 HTML 标签无关。 -
调用
chardet.detect(response.content)实现。
-
特点:
-
更接近真实编码,但 检测需要时间(对大型响应可能影响性能)。
-
不会直接影响
response.text,需手动设置response.encoding = response.apparent_encoding以应用。 -
适用于解决因服务器错误配置导致的编码问题。
import requests response = requests.get("https://www.example.com") print(response.apparent_encoding) # 输出可能为 'utf-8' 或 'gb2312' # 手动应用推测的编码 response.encoding = response.apparent_encoding print(response.text) # 正确解码的内容
3. 核心区别对比
| 属性 | response.encoding | response.apparent_encoding |
|---|---|---|
| 来源 | HTTP 头或 HTML 标签 | 响应内容的统计分析(chardet 库) |
| 是否自动生效 | 是(直接影响 response.text) |
否(需手动设置 response.encoding) |
| 准确性 | 依赖服务器正确配置,可能错误 | 通常更准确,但存在误判可能 |
| 性能开销 | 无 | 需要分析内容,可能较慢(尤其是大文件) |
4. 常见使用场景
场景 1:处理乱码
当 response.text 出现乱码时,优先使用 apparent_encoding 纠正:
response = requests.get(url) response.encoding = response.apparent_encoding # 修正编码 print(response.text) # 正常显示内容
场景 2:强制指定编码
若已知目标编码(如网站强制使用 gbk),直接设置:
response.encoding = 'gbk' # 覆盖自动检测的编码 print(response.text)
场景 3:调试编码问题
对比两种编码结果:
5. 注意事项
-
编码优先级:
response.encoding的默认值可能不符合实际内容,需根据实际情况调整。 -
性能权衡:对大型响应(如文件下载),避免频繁调用
apparent_encoding(会触发内容分析)。 -
编码覆盖:手动设置
response.encoding后,response.text会立即重新解码。
总结
-
response.encoding:依赖服务器元信息,自动生效,但可能不准确。 -
response.apparent_encoding:基于内容推测,更可靠,但需手动应用。
合理使用这两个属性,可以高效解决绝大多数编码问题!
chardet 检测编码
import chardet url="https://cn.bing.com/" response = requests.get(url) print(response.headers)#{'Cache-Control': 'private', 'Content-Length': '6869', 'Content-Type': 'text/html; charset=utf-8', 'Content-Encoding': 'gzip', 'Vary': 'Accept-Encoding', 'P3P': 'CP="NON UNI COM NAV STA LOC CURa DEVa PSAa PSDa OUR IND"', 'Set-Cookie': 'MUID=30984D5D81F4688F36D458E580BE69C6; domain=.bing.com; expires=Fri, 17-Apr-2026 13:11:31 GMT; path=/; secure; SameSite=None, MUIDB=30984D5D81F4688F36D458E580BE69C6; expires=Fri, 17-Apr-2026 13:11:31 GMT; path=/; HttpOnly, _EDGE_S=F=1&SID=0A35FA510CAE63400504EFE90DE46200; domain=.bing.com; path=/; HttpOnly, _EDGE_V=1; domain=.bing.com; expires=Fri, 17-Apr-2026 13:11:31 GMT; path=/; HttpOnly, SRCHD=AF=NOFORM; domain=.bing.com; expires=Tue, 23-Mar-2027 13:11:31 GMT; path=/, SRCHUID=V=2&GUID=54BE9D77FB0A40A989614E33018A6439&dmnchg=1; domain=.bing.com; expires=Tue, 23-Mar-2027 13:11:31 GMT; path=/, SRCHUSR=DOB=20250323; domain=.bing.com; expires=Tue, 23-Mar-2027 13:11:31 GMT; path=/, SRCHHPGUSR=SRCHLANG=zh-Hans; domain=.bing.com; expires=Tue, 23-Mar-2027 13:11:31 GMT; path=/, _SS=SID=0A35FA510CAE63400504EFE90DE46200; domain=.bing.com; path=/, ULC=; domain=.bing.com; expires=Sat, 22-Mar-2025 13:11:31 GMT; path=/, _HPVN=CS=eyJQbiI6eyJDbiI6MSwiU3QiOjAsIlFzIjowLCJQcm9kIjoiUCJ9LCJTYyI6eyJDbiI6MSwiU3QiOjAsIlFzIjowLCJQcm9kIjoiSCJ9LCJReiI6eyJDbiI6MSwiU3QiOjAsIlFzIjowLCJQcm9kIjoiVCJ9LCJBcCI6dHJ1ZSwiTXV0ZSI6dHJ1ZSwiTGFkIjoiMjAyNS0wMy0yM1QwMDowMDowMFoiLCJJb3RkIjowLCJHd2IiOjAsIlRucyI6MCwiRGZ0IjpudWxsLCJNdnMiOjAsIkZsdCI6MCwiSW1wIjoxLCJUb2JuIjowfQ==; domain=.bing.com; expires=Tue, 23-Mar-2027 13:11:31 GMT; path=/', 'X-EventID': '67e008834bc64f869e2a02029c44d2d9', 'UserAgentReductionOptOut': 'A7kgTC5xdZ2WIVGZEfb1hUoNuvjzOZX3VIV/BA6C18kQOOF50Q0D3oWoAm49k3BQImkujKILc7JmPysWk3CSjwUAAACMeyJvcmlnaW4iOiJodHRwczovL3d3dy5iaW5nLmNvbTo0NDMiLCJmZWF0dXJlIjoiU2VuZEZ1bGxVc2VyQWdlbnRBZnRlclJlZHVjdGlvbiIsImV4cGlyeSI6MTY4NDg4NjM5OSwiaXNTdWJkb21haW4iOnRydWUsImlzVGhpcmRQYXJ0eSI6dHJ1ZX0=', 'Strict-Transport-Security': 'max-age=31536000; includeSubDomains; preload', 'Content-Security-Policy': "script-src https: 'strict-dynamic' 'report-sample' 'wasm-unsafe-eval' 'nonce-9nzRu0vli/Aa4mcJrE3siRzQbwIbHMkgc5DM2s7LTQ0='; base-uri 'self';", 'X-Frame-Options': 'SAMEORIGIN', 'X-Cache': 'CONFIG_NOCACHE', 'Accept-CH': 'Sec-CH-UA-Arch, Sec-CH-UA-Bitness, Sec-CH-UA-Full-Version, Sec-CH-UA-Full-Version-List, Sec-CH-UA-Mobile, Sec-CH-UA-Model, Sec-CH-UA-Platform, Sec-CH-UA-Platform-Version', 'X-MSEdge-Ref': 'Ref A: E788687DF08C4D51B188B744F81BB320 Ref B: BJ1EDGE0717 Ref C: 2025-03-23T13:11:31Z', 'Date': 'Sun, 23 Mar 2025 13:11:31 GMT'} print(response.encoding)#utf-8 print(response.apparent_encoding)#utf-8 encoding = chardet.detect(response.content)["encoding"] print(encoding)#utf-8 response.encoding=encoding# 修正编码
显示调用chardet.detect和response.apparent_encoding的区别
核心差异对比表
| 对比项 | 代码1(显式使用 chardet) | 代码2(使用 response.apparent_encoding) |
|---|---|---|
| 底层实现 | 直接调用 chardet.detect 检测原始二进制内容编码 |
Requests 内部使用 chardet 的变体(如果安装)或自研逻辑 |
| 编码检测范围 | 仅基于 response.content 的二进制内容分析 |
可能结合 HTTP 头部信息(如 Content-Type)优化猜测 |
| 性能开销 | 显式调用 chardet 可能增加额外计算时间 |
Requests 内部缓存检测结果,可能更高效 |
| 依赖关系 | 需显式安装 chardet 库 |
若未安装 chardet,Requests 回退到自研逻辑 |
| 边缘案例处理 | 完全依赖 chardet 的算法 |
Requests 可能针对常见错误编码(如 GB2312 → GBK)优化 |
关键结论
-
多数场景效果一致
对于标准规范的网页(如编码声明与内容一致),两者通常输出相同结果。 -
边缘场景差异
-
若 HTTP 头部
Content-Type中的charset与内容实际编码冲突,apparent_encoding可能更倾向于信任内容分析结果(需看 Requests 版本实现)。 -
chardet.detect完全依赖内容分析,不受 HTTP 头部干扰。
-
-
性能与依赖
-
代码2更简洁且无额外依赖(若 Requests 自带逻辑足够)。
-
代码1在需要更精确控制检测参数(如
chardet的置信度阈值)时更灵活。
-
最佳实践建议
-
默认选择代码2:
使用response.encoding = response.apparent_encoding,简洁高效且满足多数场景。
response = requests.get(url) response.encoding = response.apparent_encoding # 推荐
特殊场景使用代码1:
需手动覆盖 Requests 的编码猜测逻辑时(如已知 apparent_encoding 检测不准)。
import chardet response.encoding = chardet.detect(response.content)['encoding'] # 备用方案
验证方法
可通过对比两种方式对同一网页的解码结果是否一致:
import requests import chardet url = "https://example.com" # 方法1 r1 = requests.get(url) encoding1 = chardet.detect(r1.content)['encoding'] r1.encoding = encoding1 text1 = r1.text # 方法2 r2 = requests.get(url) r2.encoding = r2.apparent_encoding text2 = r2.text print("解码结果一致:", text1 == text2) # 输出 True 或 False
requests 方法
requests 方法如下表:
| 方法 | 描述 |
|---|---|
| delete(url, args) | 发送 DELETE 请求到指定 url |
| get(url, params, args) | 发送 GET 请求到指定 url |
| head(url, args) | 发送 HEAD 请求到指定 url |
| patch(url, data, args) | 发送 PATCH 请求到指定 url |
| post(url, data, json, args) | 发送 POST 请求到指定 url |
| put(url, data, args) | 发送 PUT 请求到指定 url |
| request(method, url, args) | 向指定的 url 发送指定的请求方法 |
使用 requests.request() 发送 get 请求:
url = r"https://www.runoob.com/" request = requests.request("GET", url) print(request)#<Response [200]>
设置请求头和参数:
# 导入 requests 包 import requests kw = {'s':'python 教程'} # 设置请求头 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode() response = requests.get("https://www.runoob.com/", params = kw, headers = headers) # 查看响应状态码 print (response.status_code) # 查看响应头部字符编码 print (response.encoding) # 查看完整url地址 print (response.url) # 查看响应内容,response.text 返回的是Unicode格式的数据 print(response.text)
输出结果如下:
200
UTF-8
https://www.runoob.com/?s=python+%E6%95%99%E7%A8%8B
... 其他内容...
post() 方法可以发送 POST 请求到指定 url,一般格式如下:
requests.post(url, data={key: value}, json={key: value}, args)
-
url 请求 url。
-
data 参数为要发送到指定 url 的字典、元组列表、字节或文件对象。
-
json 参数为要发送到指定 url 的 JSON 对象。
-
args 为其他参数,比如 cookies、headers、verify等。
# 导入 requests 包 import requests # 发送请求 x = requests.post('https://www.runoob.com/try/ajax/demo_post.php') # 返回网页内容 print(x.text)
输出结果如下:
<p style='color:red;'>本内容是使用 POST 方法请求的。</p><p style='color:red;'>请求时间:
2022-05-26 17:30:47</p>
post 请求带参数:
# 导入 requests 包 import requests # 表单参数,参数名为 fname 和 lname myobj = {'fname': 'RUNOOB','lname': 'Boy'} # 发送请求 x = requests.post('https://www.runoob.com/try/ajax/demo_post2.php', data = myobj) # 返回网页内容 print(x.text)
输出结果如下:
<p style='color:red;'>你好,RUNOOB Boy,今天过得怎么样?</p>
附加请求参数
发送请求我们可以在请求中附加额外的参数,例如请求头、查询参数、请求体等,例如:
headers = {'User-Agent': 'Mozilla/5.0'} # 设置请求头
params = {'key1': 'value1', 'key2': 'value2'} # 设置查询参数
data = {'username': 'example', 'password': '123456'} # 设置请求体
response = requests.post('https://www.runoob.com', headers=headers, params=params, data=data)
上述代码发送一个 POST 请求,并附加了请求头、查询参数和请求体。
除了基本的 GET 和 POST 请求外,requests 还支持其他 HTTP 方法,如 PUT、DELETE、HEAD、OPTIONS 等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号