18.标准库
Python 标准库非常庞大,所提供的组件涉及范围十分广泛,使用标准库我们可以让您轻松地完成各种任务。
以下是一些 Python3 标准库中的模块:
-
os 模块:os 模块提供了许多与操作系统交互的函数,例如创建、移动和删除文件和目录,以及访问环境变量等。
-
sys 模块:sys 模块提供了与 Python 解释器和系统相关的功能,例如解释器的版本和路径,以及与 stdin、stdout 和 stderr 相关的信息。
-
time 模块:time 模块提供了处理时间的函数,例如获取当前时间、格式化日期和时间、计时等。
-
datetime 模块:datetime 模块提供了更高级的日期和时间处理函数,例如处理时区、计算时间差、计算日期差等。
-
random 模块:random 模块提供了生成随机数的函数,例如生成随机整数、浮点数、序列等。
-
math 模块:math 模块提供了数学函数,例如三角函数、对数函数、指数函数、常数等。
-
re 模块:re 模块提供了正则表达式处理函数,可以用于文本搜索、替换、分割等。
-
json 模块:json 模块提供了 JSON 编码和解码函数,可以将 Python 对象转换为 JSON 格式,并从 JSON 格式中解析出 Python 对象。
-
urllib 模块:urllib 模块提供了访问网页和处理 URL 的功能,包括下载文件、发送 POST 请求、处理 cookies 等。
操作系统接口os
os 模块提供了不少与操作系统相关联的函数,例如文件和目录的操作。
import os
# 获取当前工作目录
getcwd = os.getcwd()
print(getcwd)
#D:\learn\learncode\PythonLearn
# 列出目录下文件
listdir = os.listdir(getcwd)
print(listdir)
#['.idea', '.venv', '01变量.py']建议使用 import os 风格而非 from os import *,这样可以保证随操作系统不同而有所变化的 os.open() 不会覆盖内置函数 open()。
在使用 os 这样的大型模块时内置的 dir() 和 help() 函数非常有用:
# dir:列举目标的所有属性和方法 l = dir(os) print(l)#['DirEntry', 'EX_OK', 'F_OK', 'GenericAlias', 'Mapping', 'MutableMapping', 'O_APPEND', 'O_BINARY', 'O_CREAT', 'O_EXCL', 'O_NOINHERIT', 'O_RANDOM', 'O_RDONLY', 'O_RDWR', 'O_SEQUENTIAL', 'O_SHORT_LIVED', 'O_TEMPORARY', 'O_TEXT', 'O_TRUNC', 'O_WRONLY', 'P_DETACH', 'P_NOWAIT', 'P_NOWAITO', 'P_OVERLAY', 'P_WAIT', 'PathLike', 'R_OK', 'SEEK_CUR', 'SEEK_END', 'SEEK_SET', 'TMP_MAX', 'W_OK', 'X_OK', '_AddedDllDirectory', '_Environ', '__all__', '__builtins__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_check_methods', '_execvpe', '_exists', '_exit', '_fspath', '_get_exports_list', '_walk_symlinks_as_files', '_wrap_close', 'abc', 'abort', 'access', 'add_dll_directory', 'altsep', 'chdir', 'chmod', 'close', 'closerange', 'cpu_count', 'curdir', 'defpath', 'device_encoding', 'devnull', 'dup', 'dup2', 'environ', 'error', 'execl', 'execle', 'execlp', 'execlpe', 'execv', 'execve', 'execvp', 'execvpe', 'extsep', 'fchmod', 'fdopen', 'fsdecode', 'fsencode', 'fspath', 'fstat', 'fsync', 'ftruncate', 'get_blocking', 'get_exec_path', 'get_handle_inheritable', 'get_inheritable', 'get_terminal_size', 'getcwd', 'getcwdb', 'getenv', 'getlogin', 'getpid', 'getppid', 'isatty', 'kill', 'lchmod', 'linesep', 'link', 'listdir', 'listdrives', 'listmounts', 'listvolumes', 'lseek', 'lstat', 'makedirs', 'mkdir', 'name', 'open', 'pardir', 'path', 'pathsep', 'pipe', 'popen', 'process_cpu_count', 'putenv', 'read', 'readlink', 'remove', 'removedirs', 'rename', 'renames', 'replace', 'rmdir', 'scandir', 'sep', 'set_blocking', 'set_handle_inheritable', 'set_inheritable', 'spawnl', 'spawnle', 'spawnv', 'spawnve', 'st', 'startfile', 'stat', 'stat_result', 'statvfs_result', 'strerror', 'supports_bytes_environ', 'supports_dir_fd', 'supports_effective_ids', 'supports_fd', 'supports_follow_symlinks', 'symlink', 'sys', 'system', 'terminal_size', 'times', 'times_result', 'truncate', 'umask', 'uname_result', 'unlink', 'unsetenv', 'urandom', 'utime', 'waitpid', 'waitstatus_to_exitcode', 'walk', 'write'] help1 = help(os) print(help1)#打印帮助文档
针对日常的文件和目录管理任务,:mod:shutil 模块提供了一个易于使用的高级接口:
import shutil
# /复制文件
copyfile = shutil.copyfile("./test/Test__name__main.py", "test/Test__name__main2.py")
print(copyfile)#./test/Test__name__main.py
# 移动文件或文件夹
move = shutil.move("test/Test__name__main.py", "./tem/Test__name__main.py")
print(move)#./tem/Test__name__main.py
shutil.move("./test", "./tem/Test")文件通配符
glob 模块提供了一个函数用于从目录通配符搜索中生成文件列表:
import glob
# 文件通配符
# glob 模块提供了一个函数用于从目录通配符搜索中生成文件列表:
glob_glob = glob.glob("./test/*.py")
print(glob_glob)#['./test\\fibo.py', './test\\Test__name__main.py', './test\\__init__.py']命令行参数
通用工具脚本经常调用命令行参数。这些命令行参数以链表形式存储于 sys 模块的 argv 变量。例如在命令行中执行 "python demo.py one two three" 后可以得到以下输出结果:
PS D:\learn\Python-卢战士优选\learncode\01FirstProject> py 28标准库.py "one" "two" "three" argv = sys.argv print(argv)#['28标准库.py', 'one', 'two', 'three']
错误输出重定向和程序终止
sys 还有 stdin,stdout 和 stderr 属性,即使在 stdout 被重定向时,后者也可以用于显示警告和错误信息。
>>>sys.stderr.write("这是错误提示")
![]()
大多脚本的定向终止都使用 sys.exit()。
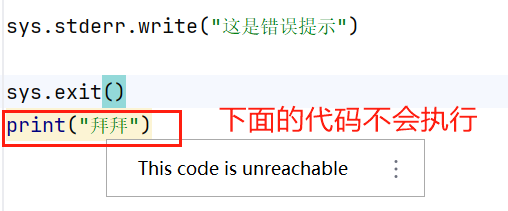
字符串正则匹配
re 模块为高级字符串处理提供了正则表达式工具。对于复杂的匹配和处理,正则表达式提供了简洁、优化的解决方案:
>>> import re >>> re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest') ['foot', 'fell', 'fastest'] >>> re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat') 'cat in the hat'
>>> 'tea for too'.replace('too', 'two') 'tea for two'
数学
math 模块为浮点运算提供了对底层 C 函数库的访问:
>>> import math >>> math.cos(math.pi / 4) 0.70710678118654757 >>> math.log(1024, 2) 10.0
random 提供了生成随机数的工具。
>>> import random >>> random.choice(['apple', 'pear', 'banana']) 'apple' >>> random.sample(range(100), 10) # sampling without replacement [30, 83, 16, 4, 8, 81, 41, 50, 18, 33] >>> random.random() # random float 0.17970987693706186 >>> random.randrange(6) # random integer chosen from range(6) 4
random.uniform()
生成在某个范围的随机数
random.uniform(15,20) help(random.uniform)
访问 互联网
有几个模块用于访问互联网以及处理网络通信协议。其中最简单的两个是用于处理从 urls 接收的数据的 urllib.request 以及用于发送电子邮件的 smtplib:
from urllib.request import urlopen for line in urlopen("https://www.hao123.com/"): line = line.decode("utf-8") if line.startswith("#"): print(line) elif "哪吒" in line: print("这句话包含哪吒", line) # 注意第二个例子需要本地有一个在运行的邮件服务器: import smtplib smtp = smtplib.SMTP("localhost") smtp.sendmail("13265570324@163.com", "1967610524@qq.com",'''你好,这是邮件内容''') smtp.quit()

日期和时间
datetime 模块为日期和时间处理同时提供了简单和复杂的方法。
支持日期和时间算法的同时,实现的重点放在更有效的处理和格式化输出。
print("----------获取当前日期和时间----------") now = datetime.datetime.now() print("未格式化的时间:",now)#未格式化的时间: 2025-03-16 10:30:20.485893 print("格式化的时间:",now.strftime("%Y-%m-%d %H:%M:%S"))#格式化的时间: 2025-03-16 10:30:20 print("----------获取当前日期----------") today = datetime.date.today() print(today)#2025-03-16 strftime = now.strftime("%m-%d-%y. %d %b %Y is a %A on the %d day of %B.") print(strftime)#03-16-25. 16 Mar 2025 is a Sunday on the 16 day of March. from datetime import date birthday = date(1996, 12, 12) age=today-birthday print(age)#10321 days, 0:00:00
数据压缩
以下模块直接支持通用的数据打包和压缩格式:zlib,gzip,bz2,zipfile,以及 tarfile。
import zlib
str='hello world'
print(len(str))#11
print(str)#hello world
strBytes=b'hello world'
print(len(strBytes))#11
print(strBytes)#b'hello world'
compress = zlib.compress(strBytes)
print(compress)#b'x\x9c\xcbH\xcd\xc9\xc9W(\xcf/\xcaI\x01\x00\x1a\x0b\x04]'
print(len(compress))#19 [这里压缩之后长度变得更长了,不知道为啥,下面我再试试有很多重复字母的字符串]
strBytes=bytes('我我我我我,和你你你你,还有他他他他'.encode('utf-8') )
print(len(strBytes))#54
zlib_compress = zlib.compress(strBytes)
print(len(zlib_compress))#38
strBytes=bytes('我和你还有他'.encode('utf-8') )
print(len(strBytes))#18
zlib_compress = zlib.compress(strBytes)
print(len(zlib_compress))#29
# 事实证明,只有存在重复字符,或者内容长度比较大时,压缩才有效
strBytes=bytes('以下是根据您提供的描述生成的Mermaid图代码。该图展示了“产品分析核心体系”的层次结构,包括宏观层(行业分析)、中观层(市场分析)和微观层(竞品分析)的详细模块。核心关系是:行业分析为市场分析提供宏观前提,而市场分析是行业分析的核心子模块。'.encode('utf-8') )
print(len(strBytes))#352
zlib_compress = zlib.compress(strBytes)
print(len(zlib_compress))#245性能度量Timer
有些用户对了解解决同一问题的不同方法之间的性能差异很感兴趣。Python 提供了一个度量工具,为这些问题提供了直接答案。
例如,使用元组封装和拆封来交换元素看起来要比使用传统的方法要诱人的多,timeit 证明了现代的方法更快一些。
from timeit import Timer timer__timeit = Timer('t=a;b=t;a=b','a=1;b=2').timeit() print(timer__timeit)#0.014803800033405423 timer__timeit2 = Timer('a,b=b,a','a=1;b=2').timeit() print(timer__timeit2)#0.012231300002895296
-
Timer类:来自 Python 的timeit模块,用于测量代码片段的执行时间。 -
参数说明:
-
第一个参数
't=a; a=b; b=t':
这是要计时的代码(stmt),即交换变量a和b的值(通过临时变量t)。 -
第二个参数
'a=1; b=2':
这是初始化代码(setup),在每次计时前运行,确保a和b的初始值始终为1和2。
-
-
.timeit()方法:
默认重复执行stmt一百万次,返回总耗时(单位:秒)。.timeit()返回总秒数,可通过参数number=1000指定运行次数(例如timeit(number=1000))。
测试模块
开发高质量软件的方法之一是为每一个函数开发测试代码,并且在开发过程中经常进行测试
doctest模块提供了一个工具,扫描模块并根据程序中内嵌的文档字符串执行测试。
测试构造如同简单的将它的输出结果剪切并粘贴到文档字符串中。
通过用户提供的例子,它强化了文档,允许 doctest 模块确认代码的结果是否与文档一致:这段代码实现了一个计算平均值的函数 average,并用 doctest 模块进行简单测试。
# 测试模块 def average(values): """Computes the arithmetic mean of a list of numbers. >>> average([20, 30, 70]) # 直接返回值,无需 print 40.0 >>> average([]) # 测试空列表 Traceback (most recent call last): ... ZeroDivisionError: division by zero """ return sum(values) / len(values) if __name__ == "__main__": import doctest doctest_testmod = doctest.testmod(verbose=True) print(doctest_testmod)#TestResults(failed=0, attempted=1)
unittest模块不像 doctest模块那么容易使用,不过它可以在一个独立的文件里提供一个更全面的测试集:
def average(numbers): if not isinstance(numbers, (list, tuple)): raise TypeError("Expected a list or tuple") if len(numbers) == 0: raise ZeroDivisionError("Cannot average empty sequence") return sum(numbers) / len(numbers) import unittest class TestStatisticalFunctions(unittest.TestCase): def test_average(self): # 测试用例 1:基础功能 self.assertEqual(average([20, 30, 70]), 40.0) # 测试用例 2:浮点数精度处理 self.assertEqual(round(average([1, 5, 7]), 1), 4.3) # 测试用例 3:空列表异常 self.assertRaises(ZeroDivisionError, average, []) # 测试用例 4:参数类型错误 self.assertRaises(TypeError, average, 20, 30, 70) unittest.main()
测试用例详解
1. 基础功能测试
self.assertEqual(average([20, 30, 70]), 40.0)
-
目的:验证
average函数计算列表[20, 30, 70]的平均值是否为40.0。 -
逻辑:
(20 + 30 + 70) / 3 = 120 / 3 = 40.0,期望结果为40.0。
2. 浮点数精度处理
self.assertEqual(round(average([1, 5, 7]), 1), 4.3)
-
目的:测试函数对浮点数的四舍五入处理是否合理。
-
逻辑:
(1 + 5 + 7) / 3 = 13 / 3 ≈ 4.333,四舍五入到小数点后一位应为4.3。
3. 空列表异常
self.assertRaises(ZeroDivisionError, average, [])
-
目的:确保当传入空列表时,函数抛出
ZeroDivisionError异常。 -
原因:
计算平均值时需用列表长度作为分母,若列表为空,分母为0,导致除零错误。
4. 参数类型错误
self.assertRaises(TypeError, average, 20, 30, 70)
-
目的:验证函数是否拒绝多个单独参数(如
20, 30, 70),仅接受单一可迭代参数(如列表)。 -
原因:
若average定义为def average(numbers),则调用average(20, 30, 70)会因参数过多抛出TypeError。
代码运行机制
-
unittest.main():
自动运行所有继承自unittest.TestCase的测试类中的测试方法。当直接执行脚本时(如python test.py),会执行测试并输出结果。
运行测试的输出示例
.... ---------------------------------------------------------------------- Ran 4 tests in 0.001s OK
-
表示测试通过,
F表示失败,E表示错误。
总结:这段代码是对 average 函数的单元测试,覆盖了基本功能、异常处理和类型校验。通过运行测试,可以快速验证函数是否符合设计要求。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号