标准化、归一化
为什么需要归一化?
-
消除量纲差异
不同特征的量纲(单位)可能差异巨大(例如:年龄在0-100,收入在0-100000),归一化可避免某些特征因数值大而主导模型。
例如,在房价预测中:
- 面积(以平方米计)可能是 50~500 之间。
- 房龄(以年计)可能是 1~50 之间。
- 房间数 可能是 1~10 之间。
由于数值范围不同,大数值的特征可能主导模型的学习过程,影响训练效果。
- 加速模型收敛:梯度下降等优化算法在归一化后的数据上收敛更快。
- 提升模型精度:某些模型(如KNN、神经网络、SVM)对数据尺度敏感,归一化能提高预测准确性。
- 增强鲁棒性:减少异常值的影响(部分归一化方法)。
常见的归一化方法
1. 最小-最大归一化(Min-Max Normalization)
📌 公式:

- 作用:将数据缩放到 [0,1]之间。
- 适用于:数据范围已知且没有异常值的情况。
- 示例:
- 原数据:[50,100,200]
- 归一化后:

结果为 [0,0.33,1]。
🔹 缺点:如果数据有异常值(outlier),容易受到影响。
2. Z-score 归一化(标准化,Standardization)
📌 公式:

- 其中:作用:将数据转换为均值为 0,标准差为 1 的分布(即服从标准正态分布)。
- μ是均值(mean)
- σ 是标准差(standard deviation)
- 适用于:数据服从正态分布,且可能包含异常值的情况。
- 示例:
- 假设数据 [50,100,200]的均值 μ=116.67,标准差 σ=76.38。
- 归一化后:
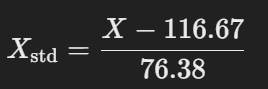
得到 [−0.87,−0.22,1.09]。
🔹 优点:适用于有异常值的数据。
🔹 缺点:不适用于所有数据,尤其是非正态分布的数据。
3. 小数定标归一化(Decimal Scaling)
📌 公式:

其中 d是使得数据变为 [−1,1]之间的最小整数,通常取决于数据的最大绝对值。
- 适用于:数据范围已知且希望保持数据的整数特性时。
- 示例:
- 原数据:[500,2000,10000]。
- 由于最大值是 10000,需要除以 104:

得到 [0.05,0.2,1.0][0.05, 0.2, 1.0][0.05,0.2,1.0]。
🔹 优点:简单且直观,适用于数值较大的数据。
🔹 缺点:如果数据范围很大,精度可能会降低。
4. 最大绝对值归一化(MaxAbsScaler)
-
公式:

-
效果:将数据缩放到 [-1, 1],保留数据的稀疏性(适合稀疏矩阵)。
-
适用场景:文本数据(如TF-IDF矩阵)或稀疏特征。
5. Robust Scaling(鲁棒归一化)
-
公式:
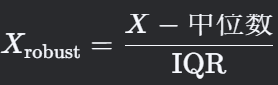
-
IQR(四分位距)= 75%分位数 - 25%分位数。
-
-
效果:通过中位数和IQR缩放,减少异常值的影响。
-
适用场景:数据包含较多异常值。
归一化的应用场景
| 场景 | 推荐方法 |
|---|---|
| 图像像素值处理 | 最小-最大归一化(缩放到[0,1]) |
| 神经网络输入 | Z-Score标准化或Min-Max |
| 文本或稀疏数据 | MaxAbsScaler |
| 数据存在异常值 | Robust Scaling |
| 需要保留原始分布 | Z-Score标准化 |
归一化 vs 标准化
-
归一化(Normalization):
强调将数据映射到特定范围(如[0,1]),消除量纲差异。
核心公式:线性缩放(如Min-Max)。 -
标准化(Standardization):
强调调整数据分布(均值为0,方差为1),不一定限制范围。
核心公式:基于均值和标准差。
Python代码示例
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler import numpy as np # 原始数据(假设为一个特征列) data = np.array([[30], [60], [90]]) # 最小-最大归一化 minmax_scaler = MinMaxScaler() normalized_data = minmax_scaler.fit_transform(data) print("Min-Max归一化结果:\n", normalized_data) # Z-Score标准化 zscore_scaler = StandardScaler() standardized_data = zscore_scaler.fit_transform(data) print("Z-Score标准化结果:\n", standardized_data) # Robust Scaling robust_scaler = RobustScaler() robust_data = robust_scaler.fit_transform(data) print("鲁棒归一化结果:\n", robust_data)
输出:
Min-Max归一化结果: [[0. ] [0.5] [1. ]] Z-Score标准化结果: [[-1.22474487] [ 0. ] [ 1.22474487]] 鲁棒归一化结果: [[-1.] [ 0.] [ 1.]]
注意事项
-
训练集与测试集的统一:
-
归一化参数(如Min-Max的XminXmin和XmaxXmax)需在训练集上计算,并应用于测试集,避免数据泄漏。
-
-
模型敏感性:
-
树模型(如随机森林、XGBoost)对特征尺度不敏感,无需归一化;
-
神经网络、SVM、KNN等模型必须归一化。
-
-
异常值处理:
-
Min-Max归一化对异常值敏感,若存在极端值,优先使用Robust Scaling。
-
总结
-
归一化是数据预处理的关键步骤,能提升模型训练效率和精度。
-
根据数据分布、模型需求和异常值情况,选择合适的方法(如Min-Max、Z-Score、Robust Scaling)。
-
实践中需结合业务场景和模型特性灵活应用。
总结
- 归一化(Min-Max):适用于数据范围已知且无异常值的情况,把数据缩放到 [0,1]。
- 标准化(Z-score):适用于数据分布不均或包含异常值的情况,使数据变为均值为 0、标准差为 1 的分布。
- 小数定标归一化:适用于数据范围特别大的情况,通常在特殊情况下使用。
如果不确定该用哪种方式,Z-score 归一化更通用。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号