YOLOv3:训练自己的数据(附优化与问题总结)
环境说明
-
系统:ubuntu16.04
-
显卡:Tesla k80 12G显存
-
python环境: 2.7 && 3.6
-
前提条件:cuda9.0 cudnn7.0 opencv3.4.0
实现YOLOV3的demo
-
首先安装darknet框架,官网链接
git clone https://github.com/pjreddie/darknet.git cd darknet vim Makefile-
根据情况修改Makefile,如果使用GPU、cudnn和opencv,就将其标志位改成1。

-
编译
make -
编译完成,测试一下
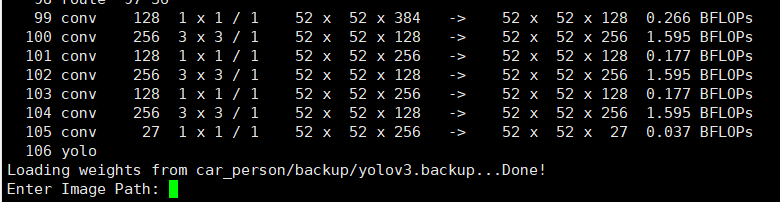
./darknet应该会出现以下信息
usage: ./darknet <function>如果有使用opencv,则可以测试下检测用例,会出现很多老鹰的图片说明darknet的安装odk了
./darknet imtest data/eagle.jpg
-
-
使用yolov3预训练模型检测物体
-
首先获取模型权重
wget https://pjreddie.com/media/files/yolov3.weights -
然后运行目标检测
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
这边运行的时候很可能出现的一个问题就是,没有出现bbox
原因
如果GPU = 1或CUDNN = 1,darknet将为每个层预先分配GPU虚拟内存,这取决于cfg文件中的批量大小和子分区设置。
对于训练,批量大小表示将在迭代中对GPU执行多少图片,更大的值可以减少训练时间,并且如果GPU在迭代中没有足够的内存,则子划分可以将它们分组以防止存储器大小限制问题。
保持1检测,因为这些设置主要用于训练网络。参考:
https://github.com/pjreddie/darknet/issues/405
https://github.com/pjreddie/darknet/issues/405
解决方法:
(1)检测的时候令cudnn=0,
(2)修改cfg文件成batch=1,sub=1
-
命令简介
先举个例子
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
darknet :一个可执行的程序,类似win下的exe
detector:是第一个参数,执行detector.c
test:detector.c里面的一个函数test_detector(),用来测试图片
cfg/coco.data:"cfg/"是训练的配置文件所在路径,coco.data是.data配置文件名
cfg/yolov3.cfg:"cfg/"是训练的配置文件所在路径,yolov3.cfg是.cfg配置文件名
yolov3.weights:训练好的模型,yolov3.weights在darknet根目录
data/dog.jpg:“data/”是要测试图片所在路径,dog.jpg是测试图片文件名
-
测试
-
测试图片
指令格式
./darknet detector test <data_cfg> <test_cfg> <weights> <image_file>(可选)如果没有指定 <image_file> 就可以像这样测试多张图片
<test_cfg>文件中batch和subdivisions两项须为1或者测试时不使用cudnn
测试时还可以用-thresh调整置信度阈值 ,例如只显示置信度在60%以上的 bbox
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh .6 -
检测视频,需要用到demo函数(src/demo.c)
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights test.avi -
在摄像头上测试,需要用到demo函数
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
-
-
训练模型
指令格式
./darknet -i <gpu_id> detector train <data_cfg> <train_cfg> <weights>-
单GPU训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -
更换GPU训练
./darknet detector -i 2 train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -
多GPU训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -gpus 0,1,2,3 -
CPU训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 --nogpu
-
-
模型评估recall,生成测试结果
-
生成测试结果
./darknet detector valid <data_cfg> <test_cfg> <weights> <out_file>(1)<test_cfg>文件中batch和subdivisions两项需为1。
(2)测试结果生成在<data_cfg>的results指定的目录下以<out_file>开头的若干文件中,若<data_cfg>没有指定results,那么默认为darknet/results。 -
计算recall(需要修改detectocr.c请参考第五部分优化与个性化——计算map与recall)
/darknet detector recall <data_cfg> <test_cfg> <weights>(1)<test_cfg>文件中batch和subdivisions两项需为1
(2)RPs/Img、IOU、Recall都是到当前测试图片的均值(意义待续)
-
训练自己的数据
-
首先下载预训练卷积权重
wget https://pjreddie.com/media/files/darknet53.conv.74 -
其次标注数据集,生成yolo所需要的txt格式的labels
-
推荐使用yolo_mark数据集标注工具,可以直接生成txt
-
下载yolo_mark
git clone https://github.com/AlexeyAB/Yolo_mark.git -
要在Linux上编译,输入:
cd Yolo_mark cmake . make chmod +x linux_mark.sh ./linux_mark.sh -
打开yolo_mark就是GUI的标注了,主要是修改data和names,具体请参考官网
-
-
修改配置文件
-
修改.data文件
classes= 4 (修改成自己训练的种类数) train = /home/user_name/darknet/data/train.txt (修改成自己train.txt的路径) valid = /home/user_name/darknet/data/2007_test.txt (评估测试的图片的路径,用于后面的评估测试) names = data/voc.names (修改成自己的类别名的路径) backup = backup (训练的权重所存放的路径) results = results (评估测试结果存放路径,也可以自己定义) -
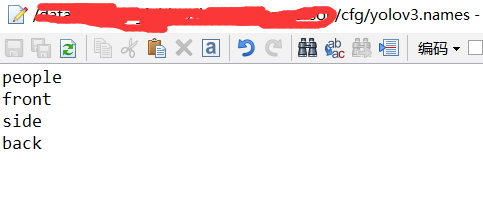
修改.names这个比较简单,修改自己的类别就可以
例如我的文件是yolov3.names
-
修改.cfg文件
-
关于cfg修改,以4类目标检测为例,主要有以下几处调整(蓝色标出),#表示注释,根据训练和测试,自行修改,修改说明:
A:filters的计算和聚类数目分布有关
yolov3:filters=(classes + 5)x3
yolov2: filters=(classes + 5)x5。
B.classes就是类别数量
C.如果想修改默认anchors数值,可以使用k-means;
D.如果显存够大,则可以开启多尺度训练令random=1,不过loss会有点震荡;
给出一份我的cfg以供参考,传送门
[net]
Testing
batch=1
subdivisions=1
Training
batch=64
subdivisions=8
......
[convolutional]
size=1
stride=1
pad=1filters=27###75
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=4###20
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0###1......
[convolutional]
size=1
stride=1
pad=1
filters=27###75
activation=linear[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=4###20
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0###1......
[convolutional]
size=1
stride=1
pad=1
filters=27###75
activation=linear[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=4###20
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0###1 -
给一份标注好的数据集,有需要的可以参考目录和格式.百度网盘戳我
提取码: j1zi
-
-
开始训练
./darknet detector train cfg/yolov3.data cfg/yolov3.cfg darknet53.conv.74
avg:平均loss,越小越好,
rate:学习率,默认为0.001,可以根据自己的训练情况调整,一般为0.01,0.003,0.001等
训练参数说明
Region xx: cfg文件中yolo-layer的索引,82是大物体层,94是中物体层,106小物体层;
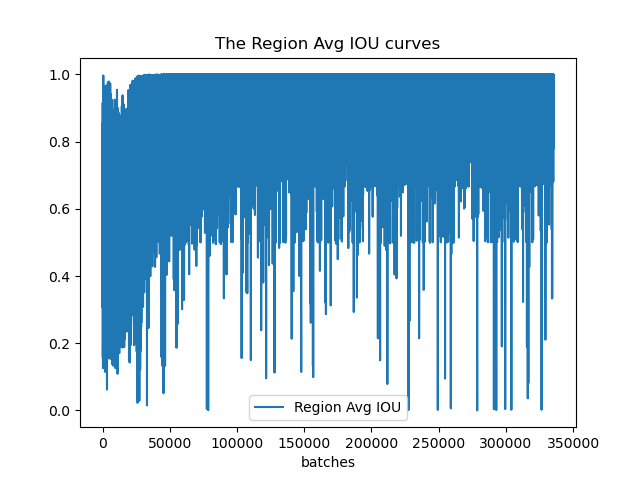
Avg IOU: 当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class: 标注物体的分类准确率,越大越好,期望数值为1;
obj: 越大越好,期望数值为1;
No obj: 越小越好;
.5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
0.75R: 以IOU=0.75为阈值时候的recall;
count: 正样本数目。
优化与个性化问题
这边的更改之后都需要make clean后再make。如果改了之后发现没变化,请第一时间看看是不是没有执行这一步。
-
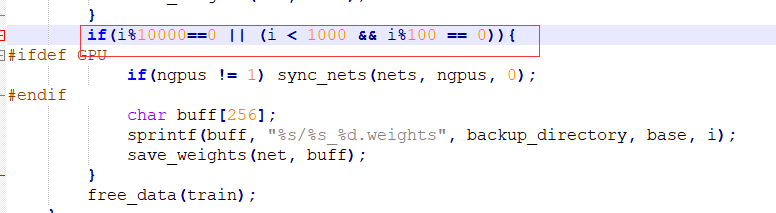
什么时候保存模型,又要如何更改呢?
迭代次数小于1000时,每100次保存一次,大于1000时,每10000次保存一次。
自己可以根据需求进行更改,然后重新编译即可[ 先 make clean ,然后再 make]
代码位置: examples/detector.c line 138
-
如何在图像上添加置信度?
可以看github的修改记录,也可以看下面的修改,修改传送门
修改src/image.c文件draw_detections()函数,代码修改如下:
int i,j; for(i = 0; i < num; ++i){ char labelstr[4096] = {0}; char s1[]={" "};//为了name与置信度之间加空格 int class = -1; char possible[5];//存放检测的置信值 for(j = 0; j < classes; ++j){ sprintf(possible,"%.2f",dets[i].prob[j]);//置信值截取小数点后两位赋给possible if (dets[i].prob[j] > thresh){ if (class < 0) { strcat(labelstr, names[j]); strcat(labelstr,s1); //加空格 strcat(labelstr, possible);//标签中加入置信值 class = j; } else { strcat(labelstr, ", "); strcat(labelstr, names[j]); strcat(labelstr,s1);//加空格 strcat(labelstr, possible);//标签中加入置信值 } printf("%s: %.0f%%\n", names[j], dets[i].prob[j]*100); } } -
如何缩小标签大小?
src/image.c的draw_detections()函数中,get_label函数调用的参数,修改成合适的大小

效果图:

-
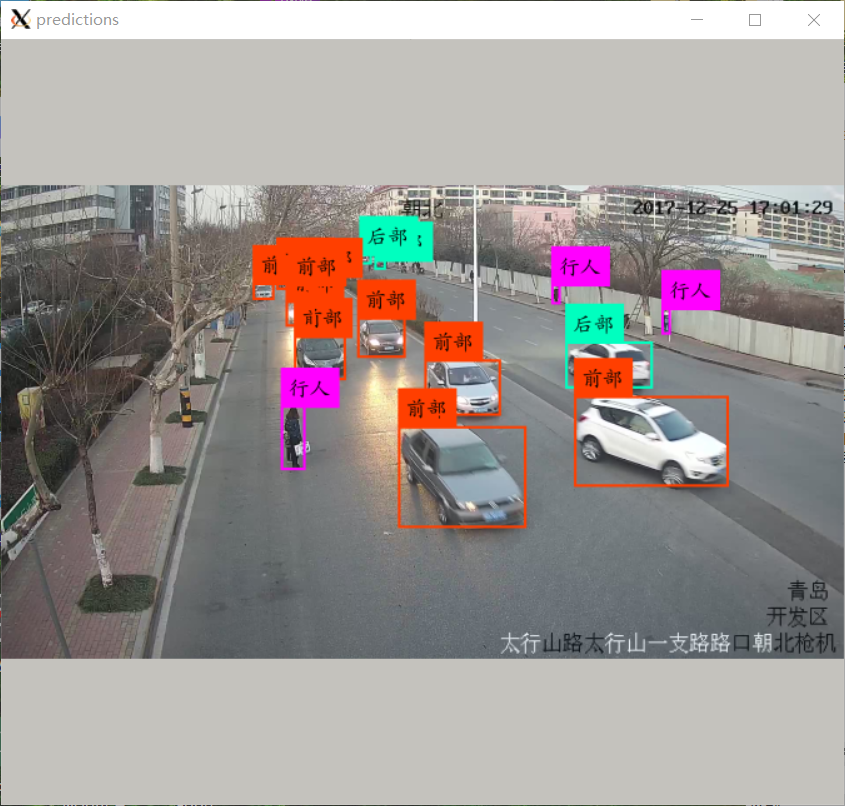
如何添加中文标签?
-
首先制作中文标签图片,
在darknet/data/labels里面有制作脚本make_labels.py。修改以下就可以用了
例如我的是四类,我就修改成
# -*- coding: utf-8 -*- import os l=["行人","前部","侧边","后部"] def make_labels(s): i = 0 for word in l: os.system("convert -fill black -background white -bordercolor white -border 4 -font /usr/share/fonts/truetype/arphic/ukai.ttc -pointsize %d label:\"%s\" \"cn_%d_%d.png\""%(s,word,i,s/12-1)) i = i + 1 for i in [12,24,36,48,60,72,84,96]: make_labels(i)运行脚本
python make_labels.py就可以在labels里面看到自己制作的图片标签

-
其次修改src/image.c的代码
具体请看github的修改,传送门,修改完之后,make clean && make.
测试以下,如图,Bingo!!!
-
-
如何批量检测?
可以看我github的修改,也可以按照下面的修改。修改传送门
- 首先在添加一个获取图片名字的函数:
#include "darknet.h" #include <opencv2/highgui/highgui.hpp> static int coco_ids[]={1,2,3,4,5,6,7,8,9,10,11,13,14,15,16,17,18,19,20,21,22,23,24,25,27,28,31,32,33,34,35,36,37,38,39,40,41,42,43,44,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,67,70,72,73,74,75,76,77,78,79,80,81,82,84,85,86,87,88,89,90}; char *GetFilename(char *p) { static char name[20]={""}; char *q = strrchr(p,'/') + 1; strncpy(name,q,10);//后面的10是你自己图片名的长度,可修改 return name; }- 替换examples/detector.c 中的test_detector函数
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh, float hier_thresh, char *outfile, int fullscreen) { list *options = read_data_cfg(datacfg); char *name_list = option_find_str(options, "names", "data/names.list"); char **names = get_labels(name_list); image **alphabet = load_alphabet(); network *net = load_network(cfgfile, weightfile, 0); set_batch_network(net, 1); srand(2222222); double time; char buff[256]; char *input = buff; float nms=.45; int i=0; while(1){ if(filename){ strncpy(input, filename, 256); image im = load_image_color(input,0,0); image sized = letterbox_image(im, net->w, net->h); layer l = net->layers[net->n-1]; float *X = sized.data; time=what_time_is_it_now(); network_predict(net, X); printf("%s: Predicted in %f seconds.\n", input, what_time_is_it_now()-time); int nboxes = 0; detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes); if (nms) do_nms_sort(dets, nboxes, l.classes, nms); draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes); free_detections(dets, nboxes); if(outfile) { save_image(im, outfile); } else{ save_image(im, "predictions"); #ifdef OPENCV cvNamedWindow("predictions", CV_WINDOW_NORMAL); if(fullscreen){ cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN); } show_image(im, "predictions",0); cvWaitKey(0); cvDestroyAllWindows(); #endif } free_image(im); free_image(sized); if (filename) break; } else { printf("Enter Image Path: "); fflush(stdout); input = fgets(input, 256, stdin); if(!input) return; strtok(input, "\n"); list *plist = get_paths(input); char **paths = (char **)list_to_array(plist); printf("Start Testing!\n"); int m = plist->size; if(access("/home/lzm/data/test_folder/darknet/car_person/out",0)==-1)//"/homelzm/......"修改成自己要保存图片的的路径 { if (mkdir("/home/lzm/data/test_folder/darknet/car_person/out",0777))//"/homelzm/......"修改成自己要保存图片的的路径 { printf("creat folder failed!!!"); } } for(i = 0; i < m; ++i){ char *path = paths[i]; image im = load_image_color(path,0,0); image sized = letterbox_image(im, net->w, net->h); //image sized = resize_image(im, net->w, net->h); //image sized2 = resize_max(im, net->w); //image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h); //resize_network(net, sized.w, sized.h); layer l = net->layers[net->n-1]; float *X = sized.data; time=what_time_is_it_now(); network_predict(net, X); printf("Try Very Hard:"); printf("%s: Predicted in %f seconds.\n", path, what_time_is_it_now()-time); int nboxes = 0; detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes); //printf("%d\n", nboxes); //if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms); if (nms) do_nms_sort(dets, nboxes, l.classes, nms); draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes); free_detections(dets, nboxes); if(outfile){ save_image(im, outfile); } else{ char b[2048]; sprintf(b,"/home/lzm/data/test_folder/darknet/car_person/out/%s",GetFilename(path));//"/homelzm/......"修改成自己要保存图片的的路径 save_image(im, b); printf("OJBK!\n",GetFilename(path)); #ifdef OPENCV cvNamedWindow("predictions", CV_WINDOW_NORMAL); if(fullscreen){ cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN); } show_image(im, "predictions",0); cvWaitKey(0); cvDestroyAllWindows(); #endif } free_image(im); free_image(sized); if (filename) break; } } } }make clean后再make然后批量测试即可,输入的路径为那些图片路径的txt。
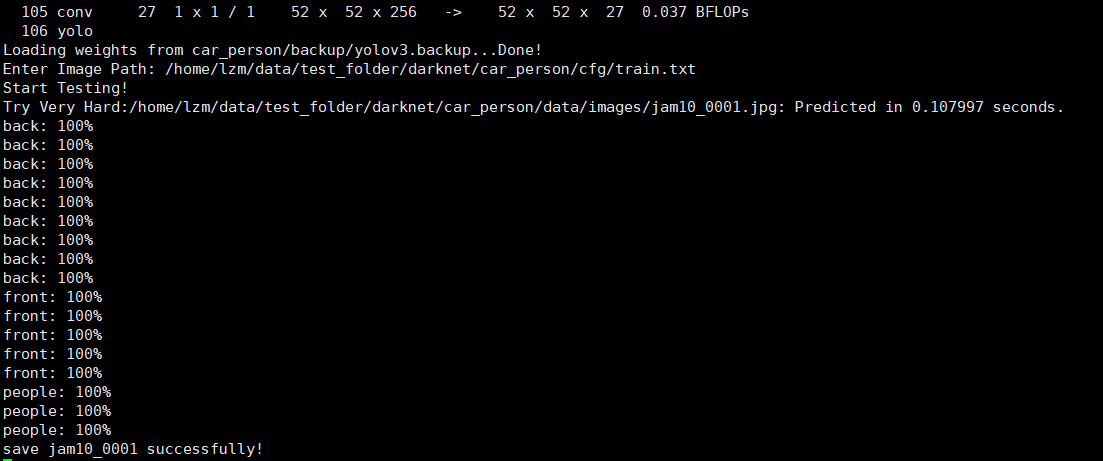
-
如何输入检测结果文本,计算recall,map计算
-
生成测试结果
./darknet detector valid <data_cfg> <test_cfg> <weights> <out_file><test_cfg>文件中batch和subdivisions两项必须为1。
结果生成在<data_cfg>的results指定的目录下以<out_file>开头的若干文件中,若<data_cfg>没有指定results,那么默认为<darknet_root>/results。
如果出现以下问题,则说明在.data文件里面没有指定valid的路径,添加即可
Couldn't open file: data/train.list
-
计算recall
修改examples/detector.c的validate_detector_recall函数,修改传送门
首先将validate_detector_recall函数定义和调用修改成
void validate_detector_recall(char *datacfg, char *cfgfile, char *weightfile) validate_detector_recall(datacfg, cfg, weights);list *plist = get_paths("data/coco_val_5k.list"); char **paths = (char **)list_to_array(plist); 修改成 list *options = read_data_cfg(datacfg); char *valid_images = option_find_str(options, "valid", "data/train.list"); list *plist = get_paths(valid_images); char **paths = (char **)list_to_array(plist);修改完老规矩,make clean后再make
计算recall
./darknet detector recall <data_cfg> <test_cfg> <weights>- <test_cfg>文件中batch和subdivisions两项必须为1。
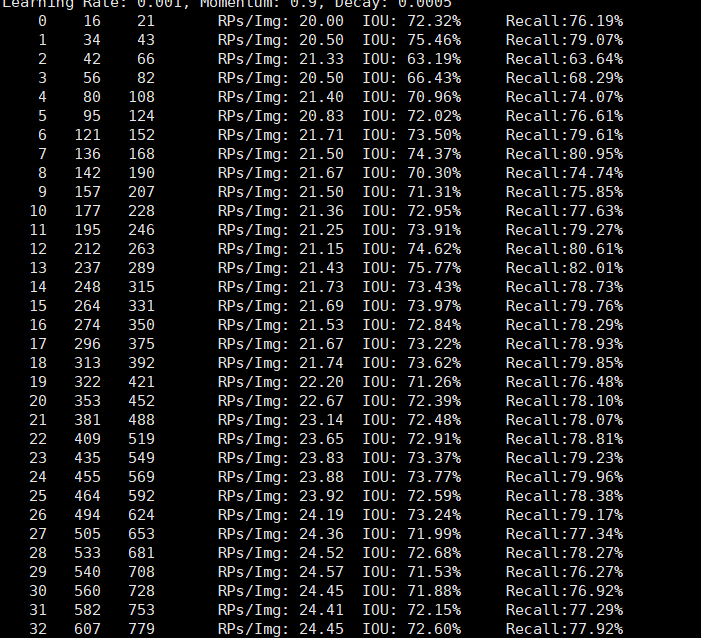
-
计算map
-
先制作xml文件,由于yolo需要的是txt标注,所以之前没有制作xml的。现在利用一个脚本txt2xml.py进行转换,txt2xml.py传送门。
在python3的环境下运行,就可以得到xml文件
-
计算mAP
借助py-faster-rcnn下的voc_eval.py计算,voc_eval.py传送门
然后新建一个all_map.py(顾名思义是计算所有类的ap,平均一下就是map)的计算脚本,这边提供一个例子,根据注释修改即可。all_map.py传送门
python2 all_map.py即可看到ap
若不想让他输出这么多rec什么,可以修改voc.eval.py的返回值只返回ap既可
若要输出结果就直接在命令后面加一个 > ap_res.txt 即可
若有需求重复计算map,需要删除生成的annots.pkl

-
-
-
后台运行并保存训练日志
nohup 执行命令 > 输出文件 2>&1 &
例如
nohup ./darknet detector train head_detector/head.data head_detector/head.cfg head_detector/backup/head.backup -gpus 0,1 > train.log 2>&1 & -
Loss和IOU可视化
用上面生成的train.log来可视化,代码在github,可以根据注释修改,安装pandas等相关模块即可我的训练初步效果
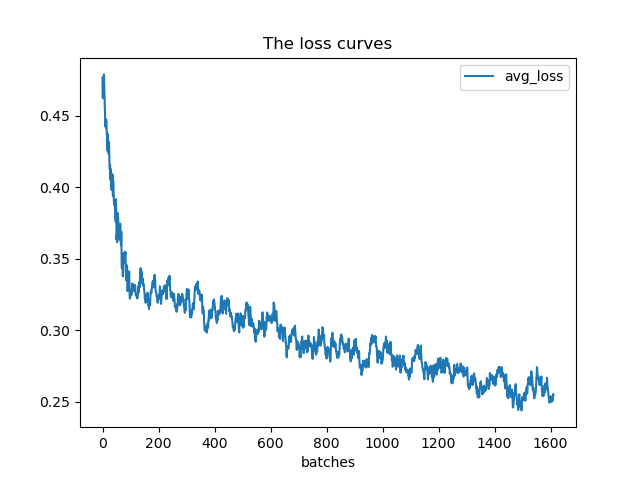

-
使用python接口进行批量检测并保存测试结果和分割图片
只需要将python接口中的文件路径替换成自己的,具体看github代码注释,代码传送门python darknet.py测试结果目录树类似以下。若出现模块报错等,则安装相应模块即可。
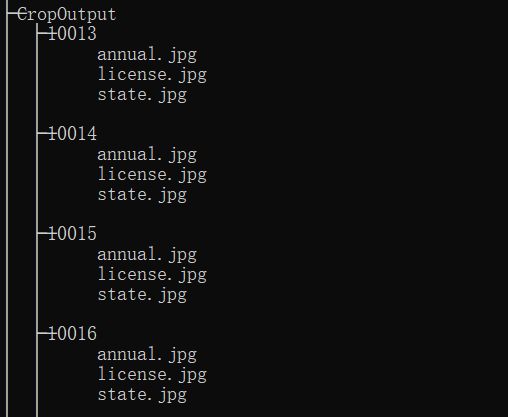
可能出现的问题
-
出现大量的-nan
原因
有三个可能
-
可能cfg文件的batch=1,subdivisions=1
-
可能batch太小了
-
训练的图片中没有遍布大中小三个层
解决方案
- 修改成Training状态的参数batch=64, subdicisions=16

-
在显存允许的情况下,增加batch
-
第三种情况属于正常,因为YOLOv3从三个scale上提取了特征,且不同尺度选取了不同尺度的的检测框,比如你在训练小目标,那么region82和region94出现nan就正常。
-
-
CUDA: out of memory
darknet: ./src/cuda.c:36: check_error: Assertion `0' failed.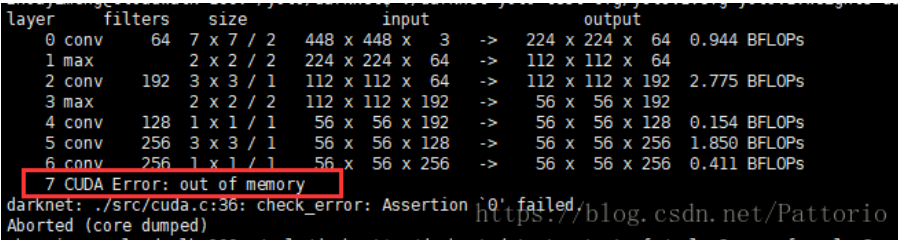
原因:显存不够
解决方案:关闭random,如果还是不行,可以适当调小batch(32或者16)
-
训练了很多次itertation,但是还是什么都没有检测出来?
原因
-
检测的时候需要batch和sub不是1 ;
-
如果调低thresh后还没有出现bbox,那么就是训练的时候可能batch和sub都是1,这样训练的模 型几乎不能用
解决方案
- 测试的时候.cfg文件中令 (batch=1,subdivisions=1);
- 训练的时候将.cfg文件修改成(batch=64, subdicisions=16)
-
-
cfg修改问题?
darknet: ./src/parser.c:348: parse_region: Assertion `l.outputs == params.inputs' failed原因:filters修改错误,没有对上classes;
解决方案:修改filters
YOLOv2: filters =(classes+5)x5
YOLOv3: filters =(classes+5)x3
-
can't open file :train.txt or can't load image ?
Couldn't open file:/home/lzm/test_folder/darknet/car_person/labels/jam6_0116.txt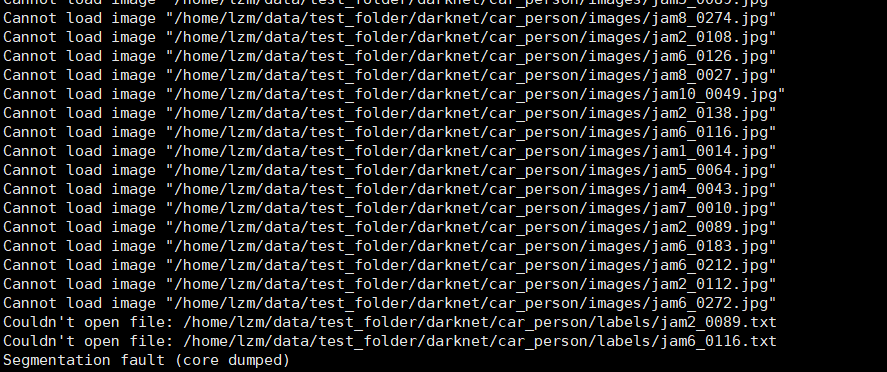
原因:一般来说是train.txt的文件格式问题;
解决方案:把train.txt的换行格式修改成unix换行格式,另外图片路径要正确,参考博文
-
Segmentation fault (core dumped),训练几百次intertation后分段错误
原因- 开了尺度训练即cfg中random=1,显存不足;
- 标注的box里面出现x,y=0的情况;
解决方案
-
关闭尺度训练,random=0;
-
修改坐标让x,y>0; 参考issue
-
detector recall的时候出现大量nan
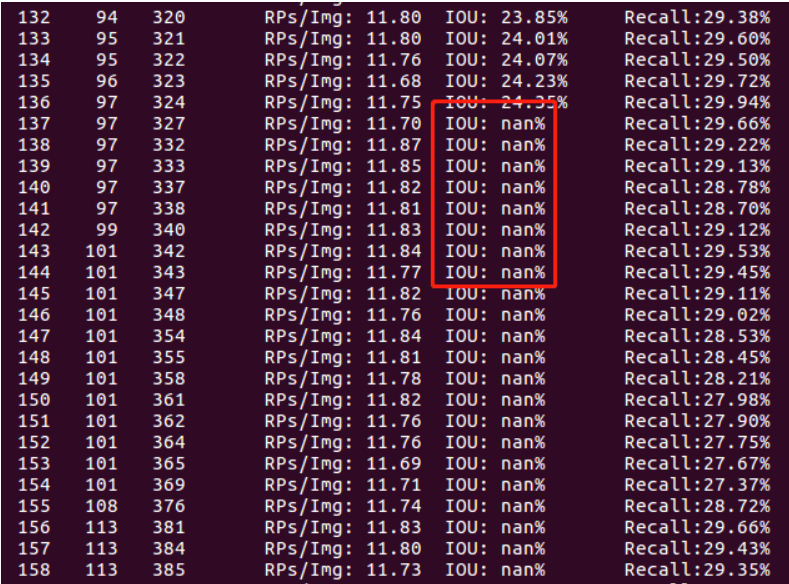
原因:detector.c代码中的bug,k的最大值必须由nbox确定,而不是
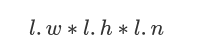
解决方案:修改examples/detector.c的代码,修改参考
-
为了批量检测图片,修改detector.c后,编译出现问题
error: too few arguments to function ‘show_image’ show_image(im, "predictions");
原因:show_image函数少了一个参数,有些代码是比较旧的。解决方案:修改报错的那一行
show_image(im, "predictions"); 改成 show_image(im, "predictions",0); -
为了批量检测图片,修改detector.c后,编译出现问题
error: ‘CV_WINDOW_NORMAL’ undeclared (first use in this function) cvNamedWindow("predictions", CV_WINDOW_NORMAL);
原因:原因链接,darknet.h还少了opencv的一个头文件,#include <opencv2/highgui/highgui.hpp>解决方案:在报错的程序中加上即可
#include "darknet.h" #include <opencv2/highgui/highgui.hpp> -
使用txt2xml.py生成xml时候的问题
'encoding' is an invalid keyword argument for this function
原因:在Python 2中,open()函数不带编码参数(第三个参数是缓冲选项)
解决方法:有两种
-
import io
open改成 io.open
-
使用python3
References
- https://pjreddie.com/darknet/
- https://blog.csdn.net/Pattorio/article/details/80051988
- https://blog.csdn.net/lilai619/article/details/79695109
- https://blog.csdn.net/mieleizhi0522/article/details/79989754
- https://blog.csdn.net/cgt19910923/article/details/80524173
- https://github.com/AlexeyAB/darknet/blob/master/README.md

 浙公网安备 33010602011771号
浙公网安备 33010602011771号