卷积神经网络(CNN)
一、非线性激活函数
多层的线性网络和单层的线性网络没有区别,线性模型能够解决的问题也是有限的。
可在此网站观察模拟:Tinker With a Neural Network Right Here in Your Browser.
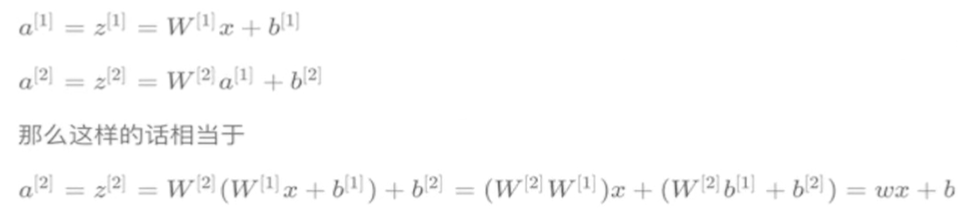
使用线性激活函数和不使用激活函数、直接使用Logistic回归没有区别,无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,也就是最原始的感知机。
二、卷积神经网络的引入
为啥不使用多层的神经网络去处理图像?
参数太多,千万上亿级别,神经网络的参数更新需要大量的计算,也很难达到好的效果。
卷积神经网络的引入,减少了网络参数的数量,达到更好的效果。
1、感受野
概念
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域,如图所示。
某一层feature map(特性图)中某个位置的特征向量,是由前面某一层固定区域的输入计算出来的,那这个区域就是这个位置的感受野。
感受野区域之外图像区域的像素不会影响feature map层的特征向量。
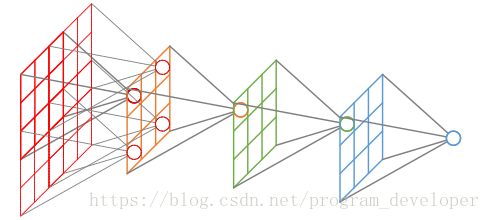
作用
- 一般task要求感受野越大越好,如图像分类中最后卷积层的感受野要大于输入图像,网络深度越深感受野越大性能越好
- 密集预测task要求输出像素的感受野足够的大,确保做出决策时没有忽略重要信息,一般也是越深越好
- 目标检测task中设置anchor要严格对应感受野,anchor太大或偏离感受野都会严重影响检测性能
2、边缘检测
为了能够更少的参数,检测出更多的信息,基于上面的感受野的思想,通常神经网络需要检测出物体最明显的垂直和水平边缘来区分物体。
三、卷积神经网络结构
组成部分:一个或多个卷积层、池化层以及全连接层等组成

其中包含了几个主要结构
- 卷积层(Convolutions)
- 池化层(Subsampling)
- 全连接层(Full connection)
- 激活函数
1、卷积层
- 目的:卷积运算的目的是提取输入的不同特征,某些卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
- 参数:缺点:
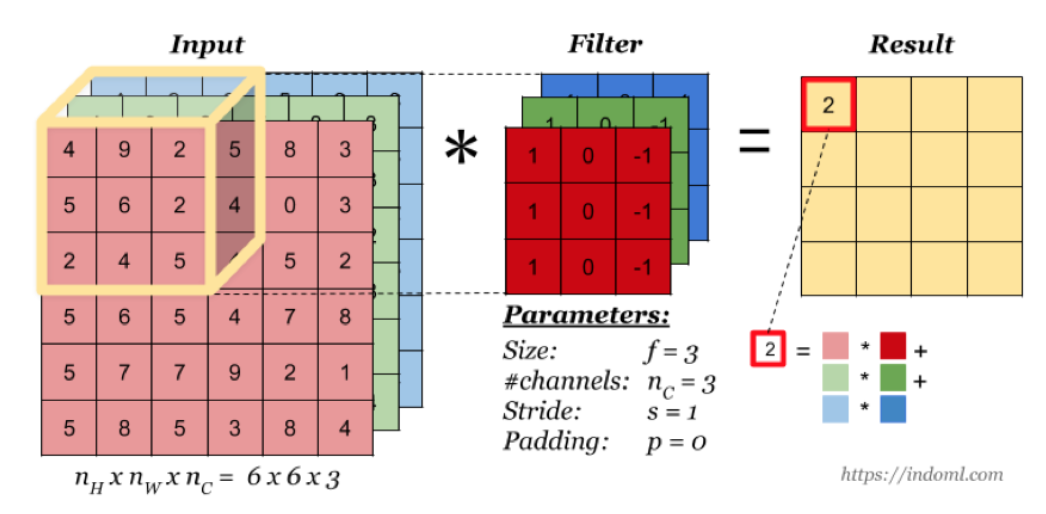
- size:卷积核/过滤器大小,选择有1 * 1, 3 * 3, 5 * 5(为什么是奇数个)
- padding:零填充,Valid 与Same
- stride:步长,通常默认为1
- 图像变小
- 边缘信息丢失
- 计算公式padding-零填充
- 零填充:在图片像素的最外层加上若干层0值,若一层,记做p =1。

为什么增加的是0?
因为0在权重乘积和运算中对最终结果不造成影响,也就避免了图片增加了额外的干扰信息。
-
Valid and Same卷积
- valid:不填充
- same:输出大小与原图大小一致
想一想卷积核大小为啥要奇数层嘞?联想一下padding后输出与原大小一致,怎么计算
增加步长的影响因素之后,计算一下卷积核大小
多通道卷积
特征图只有一个
多卷积核
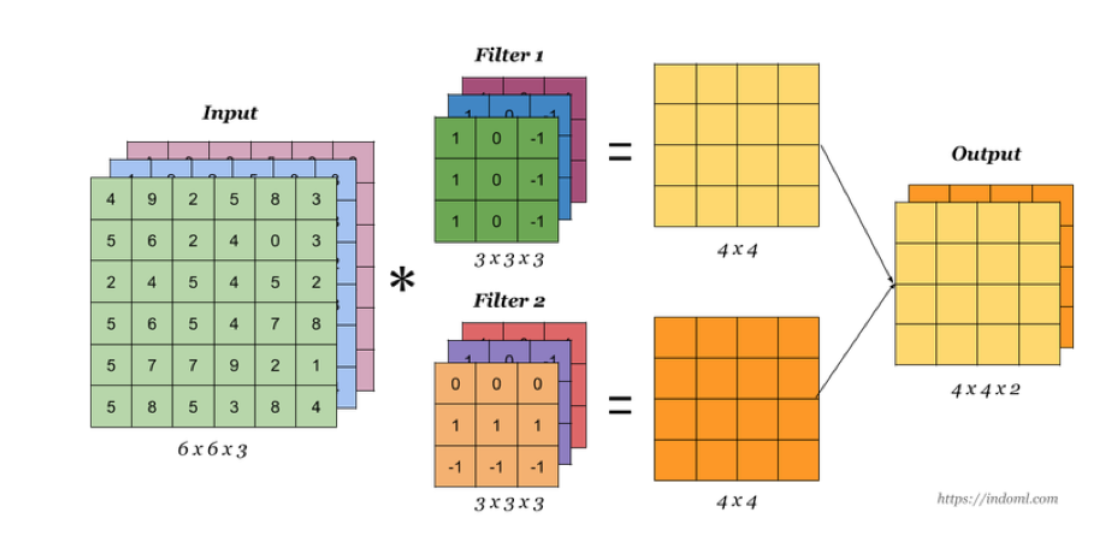
卷积层充当特征提取的角色,但是并没有减少图片的特征数量,在最后的全连接层依然面临大量的参数,所以需要池化层进行特征数量的减少
2、池化层
降低了后续网络层的输入维度,缩减模型大小,提高计算速度;
提高了Feature Map的鲁棒性,防止过拟合;
池化层主要对卷积层学习到的特征图进行亚采样(subsampling)处理,主要由两种
- 最大池化:Max Pooling,取窗口内的最大值作为输出
- 平均池化:Avg Pooling,取窗口内的所有值的均值作为输出
通用:feature 为2*2,步长step为2
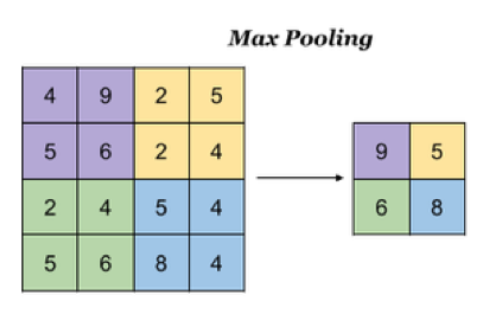
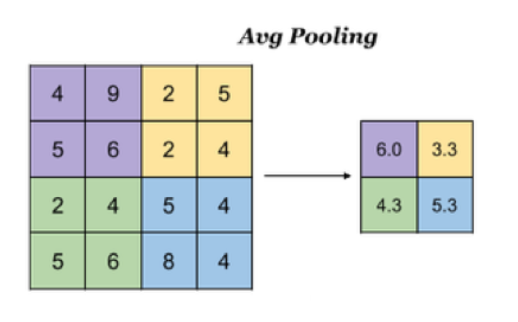
3、全连接层
卷积层+激活层+池化层可以看成是CNN的特征学习/特征提取层,而学习到的特征(Feature Map)最终应用于模型任务(分类、回归):
- 先对所有 Feature Map 进行扁平化(flatten, 即 reshape 成 1 x N 向量)
- 再接一个或多个全连接层,进行模型学习
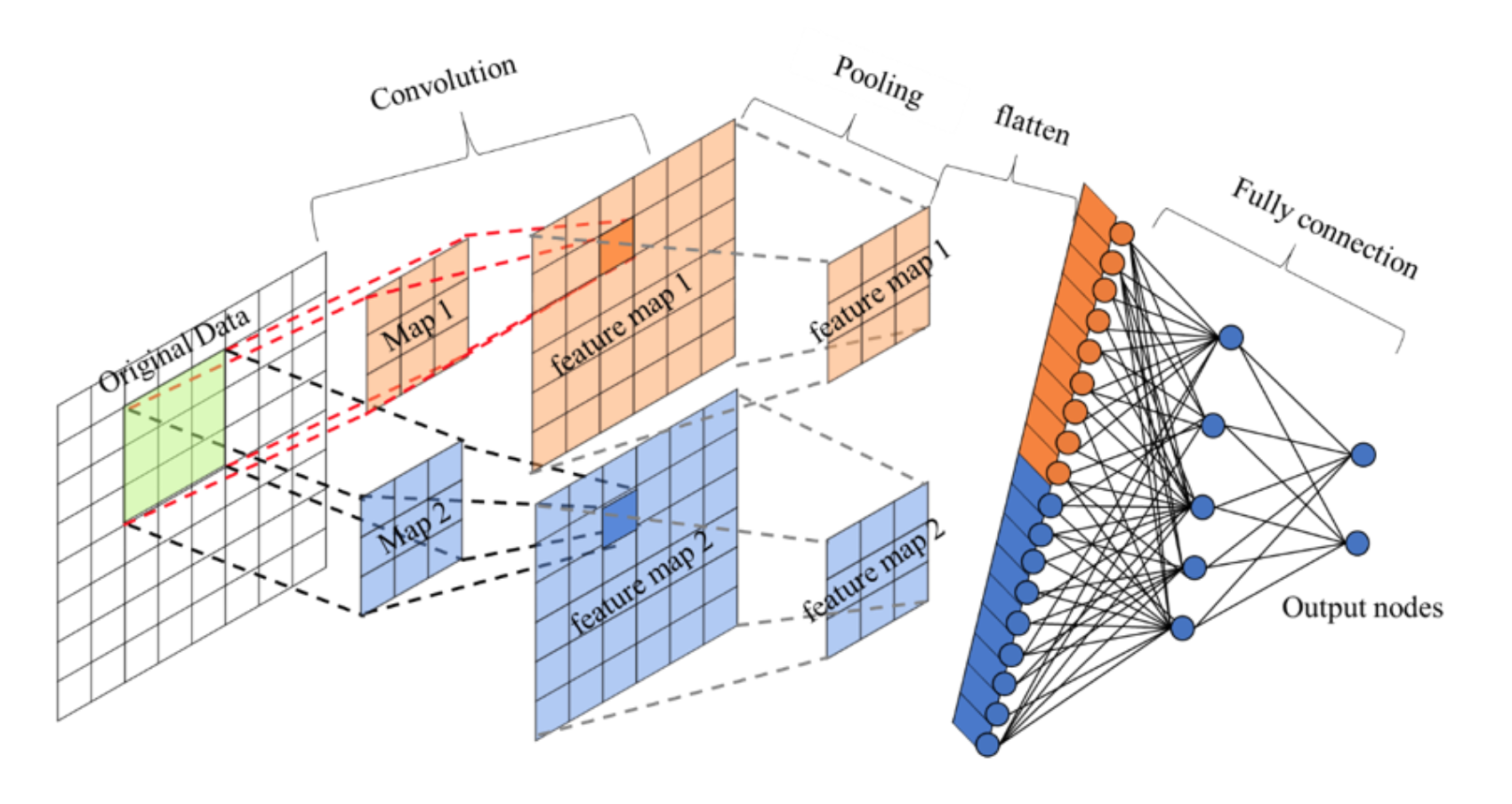
四、CIFAR案例
1、模型设计
-
进行模型编写
- 两层卷积层+两个神经网络层
- 网络设计
- 输入:[None,32*32*3] --> [None,32,32,3]
-
第一层
- 卷积:32个filter、大小5*5、strides=1、padding="SAME" -----> [None, 32, 32, 32]
- 激活:Relu -----> [None, 32, 32, 32]
- 池化:大小2x2、strides2 -----> [None, 16, 16, 32]
- 第二层
- 卷积:64个filter、大小5*5、strides=1、padding="SAME" -----> [None, 16, 16, 64]
- 激活:Relu -----> [None, 16, 16, 64]
- 池化:大小2x2、strides2 -----> [None, 8, 8, 64]
- 全连接层
- 第一层神经网络:1024
- [None, 8, 8, 64] --> [None,8*8*64] * 权重:[8*8*64,1024],+偏置:[1024] ---------------> [None,1024]
- 最后一层全连接层:100(等于类别数)
- [None,1024]* 权重:[1024,100],+偏置:[100] -------------> [None,100]
- 第一层神经网络:1024
2、完整代码


1 from tensorflow.python.keras.datasets import cifar100 2 from tensorflow.python import keras 3 import tensorflow as tf 4 5 6 class CNNMnist(object): 7 8 # 构建模型 9 model = keras.models.Sequential([ 10 # 卷积层1,32个filter、大小5*5、strides=1、padding="SAME" 11 keras.layers.Conv2D(32, kernel_size=5, strides=1, padding="same", data_format="channels_last", activation=tf.nn.relu), 12 # 池化层1,大小2x2、strides2 13 keras.layers.MaxPool2D(pool_size=2, strides=2, padding="same"), 14 # 卷积层2, 64个filter、大小5*5、strides=1、padding="SAME" 15 keras.layers.Conv2D(64, kernel_size=5, strides=1, padding='same', data_format='channels_last', activation=tf.nn.relu), 16 # 池化层, 大小2x2、strides2 17 keras.layers.MaxPool2D(pool_size=2, strides=2, padding="same"), 18 # 全连接层,神经网络 19 keras.layers.Flatten(), 20 # [None, 8, 8, 64] --> [None,8*8*64] * 权重:[8*8*64,1024],+偏置:[1024] ---------------> [None,1024] 21 keras.layers.Dense(1024, activation=tf.nn.relu), 22 # [None,1024]* 权重:[1024,100],+偏置:[100] -------------> [None,100] 23 keras.layers.Dense(100, activation=tf.nn.softmax) 24 ]) 25 26 27 def __init__(self): 28 # 获取数据集 29 (self.x_train, self.y_train), (self.x_test, self.y_test) = cifar100.load_data() 30 # 进行数据归一化 31 self.x_train = self.x_train / 255.0 32 self.x_test = self.x_test / 255.0 33 34 def compile(self): 35 CNNMnist.model.compile(optimizer=keras.optimizers.Adam(), 36 loss=keras.losses.sparse_categorical_crossentropy, 37 metrics=['accuracy']) 38 return None 39 40 def fit(self): 41 CNNMnist.model.fit(self.x_train, self.y_train, epochs=1, batch_size=32) 42 return None 43 44 def evaluate(self): 45 test_loss, test_acc = CNNMnist.model.evaluate(self.x_test, self.y_test) 46 print(test_loss, test_acc) 47 return None 48 49 50 if __name__ == '__main__': 51 cnn = CNNMnist() 52 cnn.compile() 53 cnn.fit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号