虚拟机使用ceph-deploy安装ceph
参考:
安装虚拟机
首先安装虚拟机环境,虚拟机安装这里不做介绍,本实验使用的镜像为CentOS-7-x86_64-Everything-1804,采用最小安装,如需安装其余工具请自己搭建yum源,下面给出搭建本地yum源以及网络配置的方法
下面实验虚拟机上准备四个节点:
host 192.168.1.220/221 用作主机
node1 192.168.1.210/211 ceph节点,同时当做admin node安装ceph-deploy
node2 192.168.1.212/213 ceph节点
node3 192.168.1.214/215 ceph节点
网络的配置情况如下:
要建3个网络: public网络,cluster网络,admin网络
admin网络: 用来运行yum install从外网下载和安装
| host | 192.168.1.221 |
| node1 | 192.168.1.211 |
| node2 | 192.168.1.213 |
| node3 | 192.168.1.215 |
public网络: 是client和Ceph cluster之间通信与数据传输的网络
| host | 192.168.1.220/221 |
| node1 | 192.168.1.210 |
| node2 | 192.168.1.212 |
| node3 | 192.168.1.214 |
cluster网络: 是Ceph节点之间通信和传输数据的网络
| host | 192.168.1.221 |
| node1 | 192.168.1.211 |
| node2 | 192.168.1.213 |
| node3 | 192.168.1.215 |
安装前准备工作
Step 1.admin node Enable epel (Extra Packages for Enterprise Linux) repository、ceph.repo配置文件
# 认证,但我显示系统证书崩溃,请重新注册,就先跳过了
yum install subscription-manager
subscription-manager repos --enable=rhel-7-server-extras-rpms
yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm 安装参考: http://www.mamicode.com/info-detail-1287279.html
文件位于控制节点(即admin node)的 /etc/yum.repos.d/ceph.repo
[ceph-noarch] name=Ceph noarch packages # baseurl=https://download.ceph.com/rpm/el7/noarch baseurl=http://mirrors.163.com/ceph/rpm-luminous/el7/noarch enabled=1 gpgcheck=1 type=rpm-md # gpgkey=https://download.ceph.com/keys/release.asc gpgkey=http://mirrors.163.com/ceph/keys/release.asc
注意:
上面的注释部分,是Ceph官网的写法。但是对于我们国内的安装,这样几乎无法成功,因为下载Ceph太慢了,会导致失败。因此,需要改写repo文件以更新Ceph源。
常用的Ceph镜像是163镜像。但在使用163镜像之后,必须将rpm写成rpm-luminous,这样才会安装ceph-deploy-2.0.0;若只写成rpm,则实际安装的是ceph-deploy-1.5.
Step 2.admin node安装ceph-deploy
yum update
yum install -y ceph-deploy
管理节点必须具有对Ceph节点的无密码SSH访问。 当ceph-deploy以用户身份登录到Ceph节点时,该特定用户必须具有无密码的sudo权限。
Step 3.每个ceph node 安装ntp和openssh-server
因为将来拥有monitor的Ceph node需要使用ntp来同步时间,因此需要安装ntp相关工具。而openssh-server也是必须的。
yum install -y ntp ntpdate ntp-doc
yum install -y openssh-server
Step 4.每个ceph node创建一个Ceph Deploy用户
ceph-deploy实用程序必须以具有无密码sudo权限的用户身份登录到Ceph节点,因为它需要安装软件和配置文件而不提示输入密码。
最新版本的ceph-deploy支持--username选项,因此您可以指定任何具有无密码sudo的用户(包括root用户,但不建议这样做)。要使用ceph-deploy --username {username},您指定的用户必须具有对Ceph节点的无密码SSH访问权限,因为ceph-deploy不会提示您输入密码。
我们建议在群集中的所有Ceph节点上为ceph-deploy创建特定用户。请不要使用“ceph”作为用户名。群集中的统一用户名可以提高易用性(不是必需的),但是您应该避免使用明显的用户名,因为黑客通常会使用暴力破解(例如root,admin,{productname})。以下过程用{username}替换您定义的用户名,描述了如何使用无密码sudo创建用户。
注意:从Infernalis版本开始,“ceph”用户名是为Ceph守护进程保留的。 如果Ceph节点上已存在“ceph”用户,则必须在尝试升级之前删除该用户。
useradd -d /home/luxiaodai -m luxiaodai
passwd luxiaodai(123456)
# 给该用户sudo的权限
echo "luxiaodai ALL = (root) NOPASSWD:ALL" | tee /etc/sudoers.d/luxiaodai
chmod 0440 /etc/sudoers.d/luxiaodai
Step 5.admin node设置免密和填写 ~/.ssh/config 文件
设置免密
# 生成秘钥 ssh-keygen # 拷贝到其余节点 ssh-copy-id {username}@node1 ssh-copy-id {username}@node2 ssh-copy-id {username}@node3
~/.ssh/config 这个文件是给ceph-deploy使用的。通过此文件,ceph-deploy可以知道用户名和Ceph node的信息;这样,就不用每次在执行ceph-deploy的时候都指定–username {username}了。用户(luxiaodai)和节点名称(node1等)后面会介绍怎么创建的
Host node1
Hostname node1
User luxiaodai
Host node2
Hostname node2
User luxiaodai
Host node3
Hostname node3
User luxiaodai
关闭防火墙:
Step 6.TTY
在CentOS和RHEL上,您可能在尝试执行ceph-deploy命令时收到错误。 如果在您的Ceph节点上默认设置了requiretty,请通过执行sudo visudo并找到Defaults requiretty设置来禁用它。 将其更改为Defaults:ceph!requiretty或将其注释掉以确保ceph-deploy可以使用您创建的用户与创建Ceph部署用户进行连接。
Step 7.确保您的包管理器已安装并启用了priority/preferences package。 在CentOS上,您可能需要安装EPEL
yum install yum-plugin-priorities
CEPH STORAGE CLUSTER安装
Step 1. 创建工作目录
本步骤在admin node上完成。
mkdir my_cluster cd my_cluster
ceph-deploy工具将输出一些文件到这个my-cluster目录。要确保每次运行ceph-deploy命令都是在这个目录下。
注意: 不要使用sudo来运行ceph-deploy命令,也不要在使用非root用户时以root用户身份运行ceph-deploy命令。因为ceph-deploy不会把sudo命令也发送到远端的ceph node上执行。
Step 2.环境清理
在任何时候当你陷入困境希望从头开始部署时,就执行以下的命令以清空Ceph的package以及擦除它的数据和配置:
ceph-deploy purge {ceph-node} [{ceph-node}]
ceph-deploy purgedata {ceph-node} [{ceph-node}]
ceph-deploy forgetkeys
rm ceph.*
这里执行
ceph-deploy purge node1 node2 node3
ceph-deploy purgedata node1 node2 node3
的时候提示
ImportError: No module named pkg_resources
解决方法:
yum install python-setuptools
如果执行purge,则必须重新安装Ceph。 最后一个rm命令删除在先前安装期间由本地ceph-deploy写出的所有文件。
Step 3. 创建一个集群
先创建如下图所示的ceph集群,1 monitor + 1 manager + 3 osd daemon
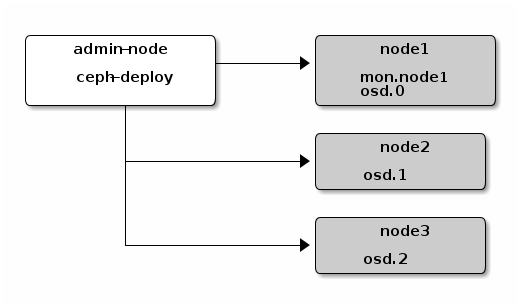
1.创建
ceph-deploy new node1
这个命令结束后,会在my-cluster目录下看到:ceph.conf, ceph.mon.keyring, log文件
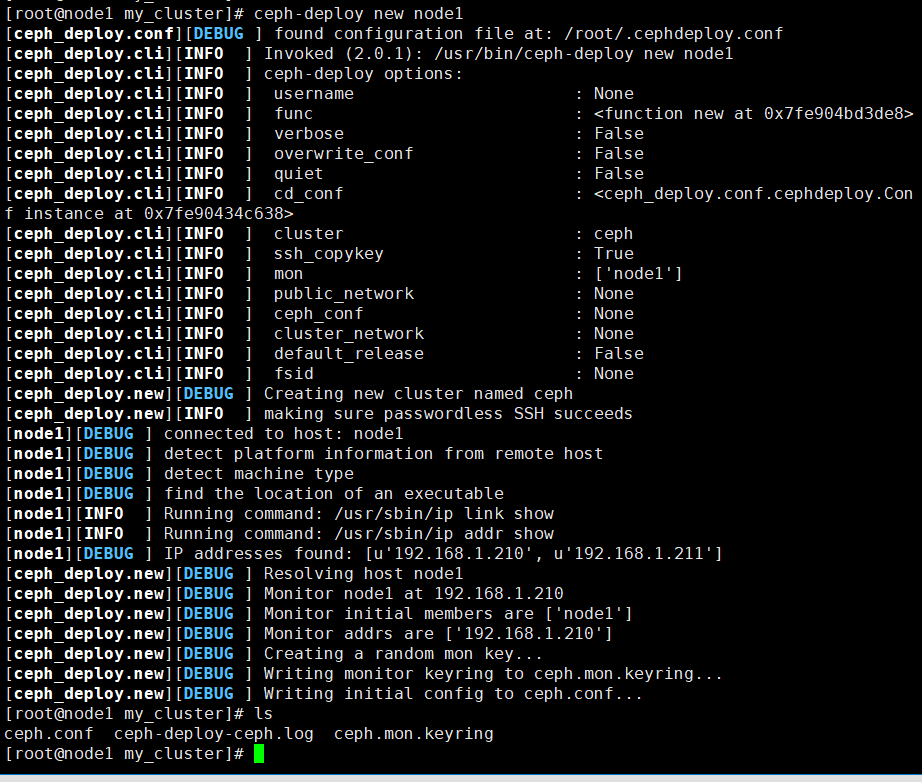
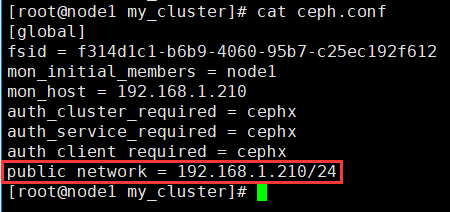
2. 添加public network的配置到ceph.conf
添加下面这句话到 ceph.conf 文件的 [global] 段
public network = 192.168.1.210/24
or
public network = 192.168.1.210/255.255.255.0
如果要在IPv6环境中部署,请将以下内容添加到本地目录中的ceph.conf:
echo ms bind ipv6 = true >> ceph.conf
3. 安装Ceph的packages
ceph-deploy install node1 node2 node3
安装过程中出现的问题
# 如果安装一直有问题,清空/etc/yum.repo,然后将yum源换掉:http://mirrors.ustc.edu.cn/help/epel.html
问题:
[ceph_deploy][ERROR ] RuntimeError: NoSectionError: No section: 'ceph'
解决方法:
yum remove ceph-release
rm /etc/yum.repos.d/ceph.repo.rpmsave
问题:
[ceph_deploy][ERROR ] RuntimeError: Failed to execute command: yum -y install ceph ceph-radosgw
解决方法:
yum -y install ceph ceph-radosgw
ceph安装缺少python-werkzeug包
安装包下载地址:http://rpmfind.net/linux/rpm2html/search.php?query=python-werkzeug
rpm -ivh python-werkzeug-0.9.1-2.el7.noarch.rpm
问题:[ceph_deploy][ERROR ] RuntimeError: Failed to execute command: ceph –version
解决:ceph1 安装速度过慢,已经超时了,直接手动安装 yum -y install ceph ceph-radosgw
安装成功!!!

4. 部署第一个monitor并产生keyring
ceph-deploy mon create-initial
注意:
若出现类似于”Unable to find /etc/ceph/ceph.client.admin.keyring”这样的错误,则要确定在ceph.conf文件中的mon_host的IP应该是public IP,而不是其他IP.
当这一步结束时,my-cluster目录会出现如下的keyring:

5. 使用ceph-deploy拷贝配置文件和admin key到ceph nodes.
这样就可以使用ceph CLI来执行命令了,而不用每次都指定monitor的地址和ceph.client.admin.keyring.
ceph-deploy admin node1 node2 node3
6. 部署一个manager daemon. (Luminous开始要求的)
ceph-deploy mgr create node1
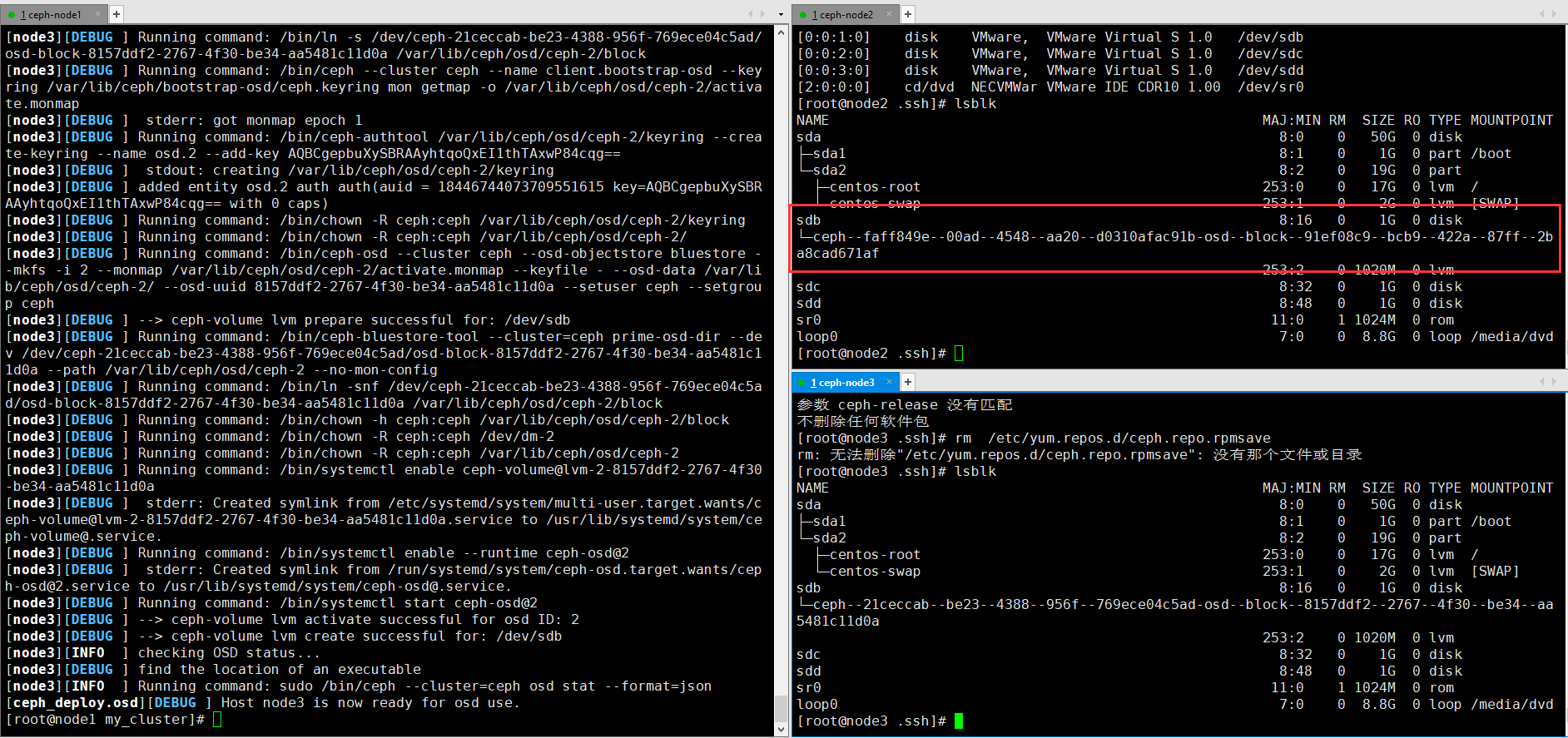
7. 添加osd
添加3个OSD。 出于说明的目的,我们假设您在每个节点中都有一个名为/ dev / vdb的未使用磁盘。 确保设备当前未使用且不包含任何重要数据。
ceph-deploy osd create -data {device} {ceph-node}
ceph-deploy osd create --data /dev/sdb node1
ceph-deploy osd create --data /dev/sdb node2
ceph-deploy osd create --data /dev/sdb node3
注意:如果要在LVM卷上创建OSD,则--data的参数必须是 volume_group/lv_name,而不是卷的块设备的路径。
8. 健康验证
ssh node1 sudo ceph health 您的群集应报告HEALTH_OK。 您可以使用以下命令查看更完整的群集状态: ssh node1 sudo ceph -s
查询结果如下:

Step 4. 扩展集群
启动并运行基本群集后,下一步是展开群集。 将Ceph元数据服务器添加到node1。 然后将Ceph Monitor和Ceph Manager添加到node2和node3,以提高可靠性和可用性。

对比第一阶段的工作,第二阶段要扩展的是:
- 添加1个metadata server
- 添加2个monitor
- 添加2个manager
- 添加1个RGW
1. 添加一个metadata server
如果要使用CephFS,就必须至少添加一个metadata server.
ceph-deploy mds create node1
2. 添加2个monitors,达到3个monitors
Ceph存储集群需要至少运行一个Ceph Monitor和Ceph Manager。 为了实现高可用性,Ceph存储集群通常运行多个Ceph监视器,因此单个Ceph监视器的故障不会导致Ceph存储集群崩溃。 Ceph使用Paxos算法,该算法需要大多数监视器(即大于N / 2,其中N是监视器的数量)才能形成法定人数。 虽然这不是必需的,但监视器的数量往往更好。
ceph-deploy mon add node2
ceph-deploy mon add node3
在添加新的monitor之后,ceph会开始同步这些monitor,并形成一个quorum. 要检查quorum的状态,可运行:
ceph quorum_status --format json-pretty
[root@node1 my_cluster]# ceph quorum_status --format json-pretty { "election_epoch": 12, "quorum": [ 0, 1, 2 ], "quorum_names": [ "node1", "node2", "node3" ], "quorum_leader_name": "node1", "monmap": { "epoch": 3, "fsid": "f314d1c1-b6b9-4060-95b7-c25ec192f612", "modified": "2018-11-13 16:04:02.221558", "created": "2018-11-13 15:35:34.338001", "features": { "persistent": [ "kraken", "luminous", "mimic", "osdmap-prune" ], "optional": [] }, "mons": [ { "rank": 0, "name": "node1", "addr": "192.168.1.210:6789/0", "public_addr": "192.168.1.210:6789/0" }, { "rank": 1, "name": "node2", "addr": "192.168.1.212:6789/0", "public_addr": "192.168.1.212:6789/0" }, { "rank": 2, "name": "node3", "addr": "192.168.1.214:6789/0", "public_addr": "192.168.1.214:6789/0" } ] } }
当给Ceph安装多个monitor之后,应该在每个monitor主机上都安装并配置NTP,以保证时间的同步。ntp的配置这里从略,只简单概述一下原理:将2台monitor所在机器配置成向第3台monitor机器做ntp的同步,而第3台monitor上通过crontab来定时调用ntpdate命令向Internet上的ntp时钟源做同步。
3. 添加2个managers,达到3个managers
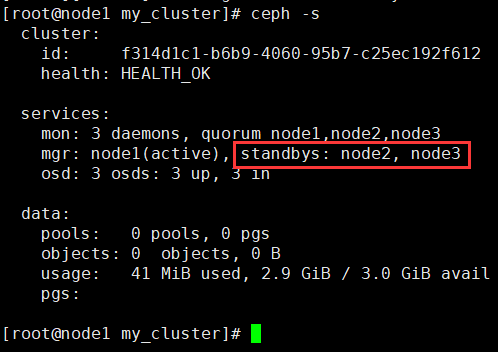
Ceph Manager daemon工作在active/standby的模式。添加多manager,可以保证如果一个manager或host宕掉,另一个manager可以无缝接管过来。
ceph-deploy mgr create node2 node3
可以通过ceph -s命令看到active和standby的manager.
4. 添加一个RGW实例
要部署Ceph Object Gateway组件,就必须部署一个RGW实例。
ceph-deploy rgw create node1
GW instance监听在7480端口。若需改变端口号,可修改ceph.conf文件。
[client] rgw frontends = civetweb port=80
若要使用IPv6地址,可以如下修改ceph.conf
[client] rgw frontends = civetweb port=[::]:80
存储/检索object数据
要存储object数据,ceph client必须:
1. 设置一个object name
2. 指定一个pool
注意:
关于ceph client,将在下篇博客介绍。
Ceph client获取最新的cluster map; 而CRUSH算法计算怎样将一个object对应到一个placement group,然后再怎样将这个palcement group动态赋给一个OSD daemon.
要找到这个object的位置,可以执行如下命令:
ceph osd map {poolname} {object-name}
作为练习,让我们创建一个对象。 在命令行上使用rados put命令指定对象名称,包含某些对象数据的测试文件的路径和池名称。 例如:
rados put {object-name} {file-path} --pool=mytest
ceph osd pool create mypool 8 # 8是该pool的PG的数量 echo "Hello, World" > 1.txt rados put my-obj-1 1.txt --pool=mypool
检查Ceph集群确实存储了这个object:
rados -p mypool ls
确定object的位置:
ceph osd map {pool-name} {object-name}
[root@node1 luxiaodai]# ceph osd map mypool my-obj-1
osdmap e26 pool 'mypool' (5) object 'my-obj-1' -> pg 5.ced445fe (5.6) -> up ([0,1,2], p0) acting ([0,1,2], p0)
若要删除这个object,可以这样:
rados rm my-obj-1 --pool=mypool
如果你要删除池,使用下面命令,出于安全原因,您需要根据提示提供其他参数; 删除池会破坏数据
ceph osd pool rm mypool
删除需要修改配置文件,加入红色部分,必须在mon节点上执行
[root@node1 my_cluster]# ceph osd pool delete mypool Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool mypool. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it. [root@node1 my_cluster]# ceph osd pool delete mypool mypool --yes-i-really-really-mean-it Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool [root@node1 my_cluster]# vim /etc/ceph/ceph.conf [root@node1 my_cluster]# cat /etc/ceph/ceph.conf [global] fsid = f314d1c1-b6b9-4060-95b7-c25ec192f612 mon_initial_members = node1 mon_host = 192.168.1.210 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx public network = 192.168.1.210/24 [mon] mon allow pool delete = true [root@node1 my_cluster]# systemctl restart ceph-mon.target [root@node1 my_cluster]# ceph osd pool delete mypool mypool --yes-i-really-really-mean-it pool 'mypool' removed
现在,集群部署好了,object也能成功创建了,但是却并不利于用户的使用。用户使用存储,一般不直接通过原始的object,而是主要有3种使用方式:
- 块设备
- 文件系统
- 对象存储(比上述原生的object多了一些封装,常见的有通过S3 API或Swift API进行对象的存取)
BLOCK DEVICE QUICK START
1. 安装Ceph
首先要确保是Linux kernel以及合适的版本。
在admin node上运行以下命令,将Ceph安装到ceph-client node上:
ceph-deploy install host
然后,运行以下命令将Ceph配置文件和ceph.client.admin.keyring拷贝到ceph-client上。
ceph-deploy admin host
2. 创建一个块设备的pool
在之前的文章中,已经创建了一个叫做mypool的pool,现在需要运行以下命令以使得该pool可以作为RBD使用:
rbd pool init mypool
3. 配置一个block device(块设备)
1.创建一个block device image
rbd create foo --size 4096 --image-feature layering [-m {mon-IP}] [-k /path/to/ceph.client.admin.keyring] [-p {pool-name}]
rbd create test --pool mypool --size 4096 --image-feature layering -m 192.168.1.210 -k /etc/ceph/ceph.client.admin.keyring
如要查看所创建的rbd,可以这样:
rbd info test -p mypool
结果如下:

2.map一个block device image
sudo rbd map foo --name client.admin [-m {mon-IP}] [-k /path/to/ceph.client.admin.keyring] [-p {pool-name}]
rbd map mypool/test --name client.admin -m 192.168.1.210 -k /etc/ceph/ceph.client.admin.keyring
3.创建一个文件系统并挂载

注意: 这里的rbd map和mount命令只是当时起作用。若系统重启了,则需要重新手动做。 若要开机自动做,可参考官方文档:rbdmap manpage.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号