InstructGPT(1)
gpt-3文章末尾提到过如下类似观点:“最终有用的系统应是目标驱动的,而非仅仅是概率预测,这可能是当前gpt系列预训练方式一个较大的局限性所在”。InstructGPT文章中就指出了,这种局限性会带来许多坏处:捏造事实、生成有偏见或有害的文本、不遵循用户指令等。因为本质上这些模型的训练目标是“预测给定token sequence上的下一个token”,这与“有帮助且安全地遵循用户指令”的目标常常是不一致的。因此,InstructGPT旨在通过某种方案,使模型的行为与用户的意图保持一致。这包括:
1、显性意图:明确遵循指令;
2、隐性意图:保持真实(Truthful)、无偏见(Unbiased)、无害(Harmless)。论文将其概括为 “Helpful, Honest, Harmless” (3H) 原则
怎么解决上述这些问题呢?InstructGPT引入了RLHF(Reinforcement Learning from Human Feedback)三阶段微调框架,基于人类的偏好对模型进行优化,分别为:(1)SFT(2)RM(3)RL,在进行这三个阶段的阐述之前,需要先对训练所用的Prompt数据集构造方法进行阐述
由于当时的gpt-3主要接收的是补全型Prompt(例如文章续写),用户在API很少提供类似于请做XXXXX任务这样的指令型Prompt,如下图所示,gpt-3和InstructGPT两者API收集到的Prompt格式对比:


所以需要人为地去构造一个指令型的Prompt数据集。OpenAI组建了一支标注团队,在要求他们要优先考虑真实性和无害性的基础上,使用三类方案进行数据集人工构造:
1、Plain:标注团队随机发挥,创造任意的指令型Prompt,如为5岁孩子编写刷牙歌、用txt格式输出世界前5大河流等等,唯一要保证的就是要具有多样性,尽可能覆盖多类别的任务
2、Few-shot:标注团队给出一个指令型Prompt的同时,也要给出若干个输入输出组合,比如:
指令:"将口语转化为正式商务邮件"
输入:"嘿,那事咋样了?" → 输出:"尊敬的先生/女士,请问此事目前进展如何?"
输入:"给我回电话" → 输出:"恳请您在方便时回电商讨。"
3、对于一些开发者来说,他们会在OpenAI的官网上进行API申请用于自己的任务,等待的人会进行Waiting List。当然,他们需要填写各类的申请理由,标注团队根据WL中的申请用例进行Prompt构造,这样也算符合实际应用场景,如:
用户需求:"需要客服自动化"
→ 标注员创建:"处理客户投诉:'我收到的商品破损了'"
用户需求:"教育辅助"
→ 标注员创建:"解释光合作用给初中生听"
有了这些人工构造的数据集后,使用上述的微调步骤在gpt-3上训练得到一个最初版本的InstructGPT,将其部署到Playground上提供给用户进行使用,用户在使用的过程中会不断提供新的指令型Prompt给API,那么这样后续的数据集会进一步扩大,由人为编写的prompt和OpenAI API收集的prompt组成,且随着使用后者会占大头(OpenAI为了安全和隐私考虑,避开了生产环境和个人信息相关的数据;为了数据质量和多样性考虑,规定了每个用户共享Prompt数;为了防止个人Prompt风格影响模型判断,在划分数据集时,不是随机打乱所有提示,而是按用户ID来划分。某个用户的所有提示要么全在训练集,要么全在验证集,要么全在测试集),数据集的任务构成如下图,可见还是具有非常丰富的多样性的:

按照上述方案,OpenAI从这些Prompt中生成了用于RLHF的三个阶段的不同数据集:(1)SFT数据集:包含约13k条训练Prompt,来自于API与标注员人工标注;(2)RM数据集:包含约33k条训练Prompt,来自于API与标注员人工标注;(3)PPO数据集,包含约 31k条训练Prompt
任务原理:有了数据集后,开始介绍RLHF的完整流程,整体演示图如下:
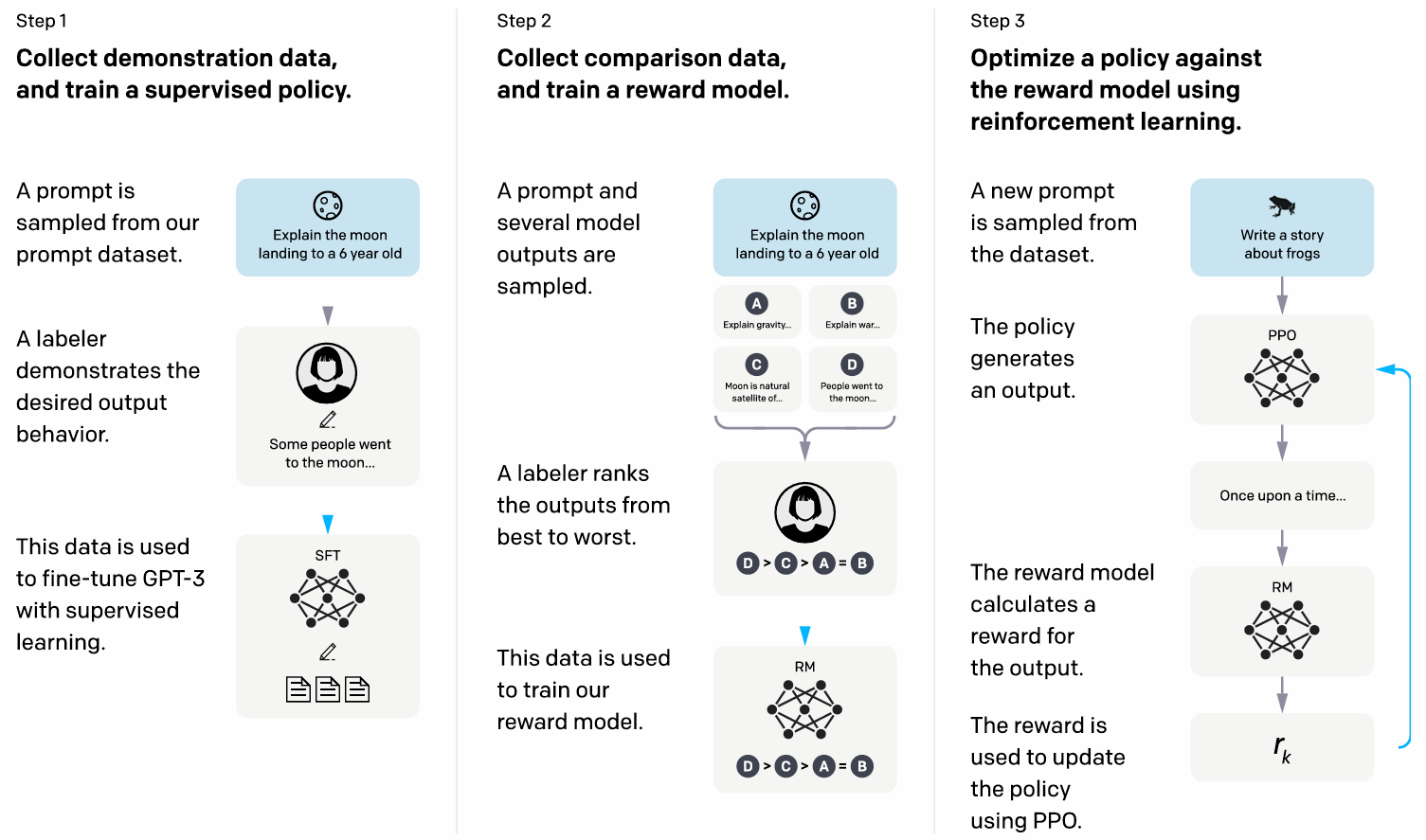
由图和上文可知,RLHF可分为三个步骤:
1、有监督微调(SFT):拿到一条training prompt后,需要标注员编写期望的output,构建[Prompt, Output]类型格式数据进行模型SFT微调,用来训练初始版本的InstructGPT或者进一步微调优化初始版本的InstructGPT
2、奖励模型训练(Reward Model, RM),拿到一条training prompt后,当前的模型给出若干条outputs,标注员按照最好到最差进行人工排序,使用排序后的数据训练这个奖励模型,使其具有人类偏好
PPO(Proximal Policy Optimization)
在强化学习中,有两种学习策略的方式:1、基于价值:先学习每个状态或状态-动作对的“价值”(即未来能获得的累积奖励),然后根据价值选择最优动作;2、基于策略:直接学习一个策略函数,这个函数可以直接输出在某个状态下采取每个动作的概率。其中基于策略的方法的代表就是策略梯度,它的核心思想非常直观:如果某个动作导致了高奖励,我们就增加这个动作在未来被选中的概率;如果导致了低奖励(或者惩罚),就降低它的概率。在策略梯度中,我们希望最大化期望的累计奖励目标函数如下:
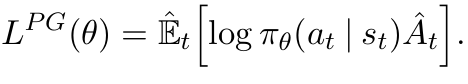
在策略梯度中,可以根据梯度上升进行策略更新:

这里的At为一个优势函数,衡量了在状态st下采取动作at比平均水平好多少,如果这个函数大于0,则增加at出现的概率,反之则减少
策略梯度方法在更新策略时,学习率的选择非常关键。如果太小,学习会非常慢,效率低下;如果步长太大,策略可能会发生剧烈变化,导致性能急剧下降。这是因为它们通常是在线(On-Policy)学习算法。这意味着它们用当前策略收集数据,然后用这些数据来更新。一旦策略更新了,之前收集的数据就“过期”了,因为它们不再符合新的策略分布。如果新旧策略差异太大,那么用旧数据计算出的梯度方向可能对新策略来说是完全错误的,导致策略朝着错误的方向优化
为了解决上述不稳定问题,有研究人员提出了信赖域策略优化(Trust Region Policy Optimization, TRPO)算法:每次策略更新,都必须保证新策略与旧策略之间的差异在一个“信赖阈值”之内,这个差异通常用KL散度来衡量。TRPO的目标函数为:

因为TRPO为一个约束优化问题,需要计算二阶导数,或者使用共轭梯度法来近似求解,这在计算上非常昂贵,而且难以与深度学习框架(如PyTorch)的自动微分机制完美结合,对大规模神经网络代价极高。而PPO在保持TRPO稳定性的同时,大大简化其实现难度,使其能够像普通的策略梯度方法一样,使用一阶优化器(如Adam)进行训练
PPO不像TRPO那样通过KL散度来严格约束,而是通过一个更直接的方式————剪裁(Clipping),来限制新旧策略之间的比率。添加上这个“剪裁”机制后,目标函数称之为PPO-Clip:

这个目标函数分为以下几项:
1、原始的策略梯度优化项G1,只不过把原本的策略的对数换成了新旧策略的比值:

如果At大于0,则这个动作是优的,我们希望比值更大,即新策略更有可能做出这个动作,反之则更不可能出现这个动作
2、剪裁后的策略梯度优化项G2,如果新旧策略比值超出了[1-ε, 1+ε]这个闭区间的话,则被强行拉回这个区间:
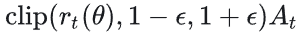
3、min函数:取G1和G2中的最小值,当At大于0时,PPO-Clip鼓励这个比值增大,但是不会超过上限1+ε;反之也是,如果当At小于0时,PPO-Clip鼓励这个比值减小,但是不会低于下限1-ε。通过这种方式,PPO巧妙地为新旧策略的差异设置了限制,使得新策略与旧策略不至于偏差太大
在PPO目标函数中,At这个优势函数表明了在某个特定状态下采取某个特定动作,比平均基线好多少。学习这个优势函数之前,需要先了解价值函数与Q函数:
1、价值函数:表明在某个状态s下采取策略π能够获得的期望累计奖励,可用于衡量一个状态的好坏:

其中,γ为折扣因子,表明未来奖励的重要度
2、Q函数(动作价值函数): 表明在某个状态s下采取某个动作a,且遵循策略π能够获得的期望累计奖励,可用于衡量某个状态下进行某个动作的好坏:
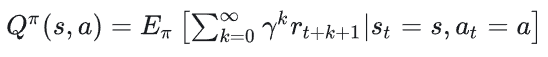
实际应用中,常用一个NN来拟合代替这些价值函数,我们称之为评论家Critic网络
于是,可以定义优势函数为:
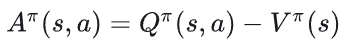
V为在某个状态下,按策略进行随机选择动作的平均期望奖励,可以看作当前策略的平均水平;Q则是在某个状态下,采取动作a的预期奖励。那么两者的差值则可以理解为:在状态s下采取动作a比按照当前策略的平均水平,能多获得(或少获得)多少奖励,如果大于0,则该动作值得鼓励,反之则加以惩罚,这正符合优势函数的定义。在策略梯度中,优势函数能够用来降低方差,通过引入一个平均线V,使得梯度更新只关注那些特别好或者坏的动作,而不是所有动作的绝对奖励。
但是在实际计算中,不会直接计算Q和V,而是进行时序差分(Temporal Difference, TD)误差来进行估计,比如TD(0):

上述公式为:当前观察到的瞬时奖励 + 未来状态估计平均价值 - 当前状态估计平均价值,这代表了对当前状态价值估计的“惊喜”程度。但是这种方法只考虑了下一步的价值和奖励,可能导致高偏差,对于长期延迟奖励(reward delay 很长的环境),TD误差可能无法及时传递,收敛速度慢,前期状态几乎没有收到梯度信号,学习很慢。对于两种价值函数估计方法TD和MC(Monte Carlo)来说:前者每一次轨迹采样都会引入一个估计值,相当于一个噪声,虽然每次采样更新都会向着真值进行收敛,但是整体而言噪声引起的效应无法去除,是有偏的,而TD由于只引入了当前回报与未来价值估计两个随机性,其方差较小;而后者公式如下:

每一次轨迹采样都是完整轨迹的累计回报,假设能够进行无限次采样,则整体会向真值收敛,且没有引入噪声,是无偏的。但是MC每一次采样包含一条轨迹上所有随机奖励的波动,方差较大。
为了平衡偏差与方差,PPO中使用一种广义优势估计(Generalized Advantage Estimation, GAE)的方法。GAE结合了TD和MC的优点,通过一个参数λ进行这种平衡:

其中:

当λ=0时,比较明显优势函数退化为TD;当λ=1时,此时优势函数退化为MC,此处可能有点不明显,我做了如下公式推导(一些写法不太标准轻喷):

GAE允许通过参数进行对偏差和方差进行加权调整,根据实际情况进行优势估计
一般而言,PPO的目标函数会加上一个熵奖励(Entropy):

其中:
1、第一项为PPO-Clip
2、第二项为价值函数误差项,用于训练Critic网络:

其中的Vtarget可以是MC计算的未来总奖励,也可以是GAE计算得出的优势再加上当前价值估计
3、第三项是在策略π在状态s下的熵值,反映了该策略的随机性:
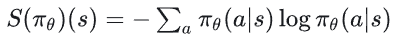
4、c1、c2为赋权超参数
为什么需要这个熵项:在RL中,智能体需要权衡探索与趋利两者的关系,趋利使得智能体根据目前的最优策略选择最高收益的动作进行执行,而探索则驱使智能体不要沉浸在当前的策略中,去尝试一些不确定的动作,以便发现更好的策略或者一些未知奖励。引入这个正熵项,证明PPO鼓励训练过程保持一定随机性
On-Policy要求策略更新时使用的数据必须为当前策略生成的,传统的On-Policy算法(如REINFORCE)就严格遵循这一规定。但是在PPO中,将每一次当前待更新策略生成的序列数据打包为mini-batch。为什么PPO可以这样操作呢?因为PPO剪裁机制保证了未来多次更新中,新策略不会偏离旧策略太远,这保证了旧的数据在分布上是一定程度有效的,可以被重复利用,这样也可以避免其陷入整体轨迹的局限性中,打乱后,模型必须从单步样本的统计规律中去拟合,而不是背轨迹。此外,这种策略也可以使其在与环境交互次数相同的情况下,能够学习到更好的策略
PPO整体架构是经典的Actor-Critic模式,Actor和Critic都被设计为一个NN:
Actor:负责去学习策略π,输入状态为s,输出为每个动作的概率分布,其目标为最大化PPO-Clip目标函数
Critic:负责学习价值函数V(s),输入状态为s,输出为该状态的估计价值,其目标为最小化价值函数误差,一般为均方误差
这两个网络一般共享一部分底层的网络层,但是有各自的输出层:
Critic为Actor提供优势函数的估计(基于价值函数V(s)),帮助Actor判断哪些动作是优是劣,从而指导Actor进行策略更新
Actor在环境env中执行新的动作,采样新的轨迹,收集新的经验数据,这些数据又被用来训练Critic,使其拟合一个更符合真实场景的价值函数
PPO能够通过一个足够好的近似方法,巧妙地平衡了TRPO的理论优势与一阶优化的工程优势,但是PPO仍有一些不足之处:
1、虽然通过mini-batch在同样的环境交互次数上实现了更多次的更新,但是本质上仍然是一个On-Policy算法,这意味着每次策略更新后,之前收集的数据就变得部分无效了,仍然需要重新与环境交互收集新数据。,样本效率仍然不如真正的离线(Off-Policy)算法(如SAC、DDPG)
2、PPO中包含许多超参数需要设置,这对实验和调优有更高的要求
3、不像TRPO中严格的约束项,PPO使用clip启发式地修改了目标函数,这并不是一个严格的约束,在剪裁处是不可导的,在理论上不如TRPO完美
4、PPO的目标函数梯度估计依赖于优势函数,而优势函数依赖于回报R,如果是在一个奖励稀疏环境,即智能体可能要执行到最后一个状态才能得到有效的回报,那么这时候进行mini-batch,许多batch中的优势函数值都可能是0,这造成更新梯度几乎没信号,训练可能会遇到困难,需要结合其他优化技术,如奖励整形(Reward Shaping)、好奇心驱动探索(Exploration with Intrinsic Motivation)
InstructGPT(2)
现在回到InstructGPT的学习,上文提到RLHF分为三个步骤:
1、SFT:文中在gpt-3上进行有监督微调,没有什么特殊的。具体的,训练轮次为16个epoch;使用余弦学习率衰减(cosine LR schedule)将学习率衰减到原始学习率的10%,没有使用warmup,同时对于不同大小的模型还使用geometric search进行候选学习率搜索;在残差连接上使用0.2的dropout。最终根据RM上的评分进行SFT微调模型结果的选择,OpenAI发现在一个epoch训练后模型就会在验证集上过拟合,但是即便这样,更多的轮次仍然有助于提高RM分数和人工偏好评分
2、RM:文中的做法是以一个在多个数据集SFT后的gpt3-6B模型为基础,相比于175B的模型而言,后者可能能够实现更好的泛化性能,但是其训练的不稳定、计算效率慢等缺点都不太适合作为PPO中的RM。文中将最后一层unembedding layer去除后,进行单个epoch的训练,发现训练对学习率不敏感,50%的变动范围仍能保留性能。但是训练对epoch敏感,多轮次会导致过拟合,泛化性能明显恶化。在训练中,batch size为每批不同prompt的数量,每一个prompt有\(K=4 \sim 9\)个labels,训练时将这些回答labels按照从好到坏从前到后排列,类似做一个对比学习:

3、RL:使用PPO在设置的环境中进行微调:
(1)环境:设置一种bandit环境(即单步决策环境,在一个状态执行一个动作,立刻获得奖励,没有长期依赖或者延迟奖励),在这里,状态为一个随机的用户prompt,动作为模型执行一个completion,将prompt和completion输入RM中,则得到reward,结束这一步
(2)考虑一种KL penalty,通过\(\beta\)参数进行控制,使得RL后的模型不偏离SFT的原始模型太多
(3)引入模型在预训练数据上的梯度,防止模型在RLHF中为了学习人类偏好而失去原有的通用语言能力,称为PPO-ptx


 浙公网安备 33010602011771号
浙公网安备 33010602011771号