GPT-3
“预训练-微调”这个范式在许多具有挑战性的NLP任务上取得了重大进展,但是仍然存在许多局限性,最主要的一个是:虽然模型架构与任务无关,但是仍然需要任务特定的数据集和任务特定的微调,要在期望的任务上实现强大的性能,通常需要针对该任务包含数千到数十万个样本的数据集进行微调。
1、为每个任务收集数据成本高昂,不现实;
2、大模型在窄数据上微调,容易“学偏”(过拟合和虚假相关),benchmark高分可能“造假”,实际应用表现不佳;
3、人类只需几个例子就能学会,NLP系统应该追求这种流畅和通用
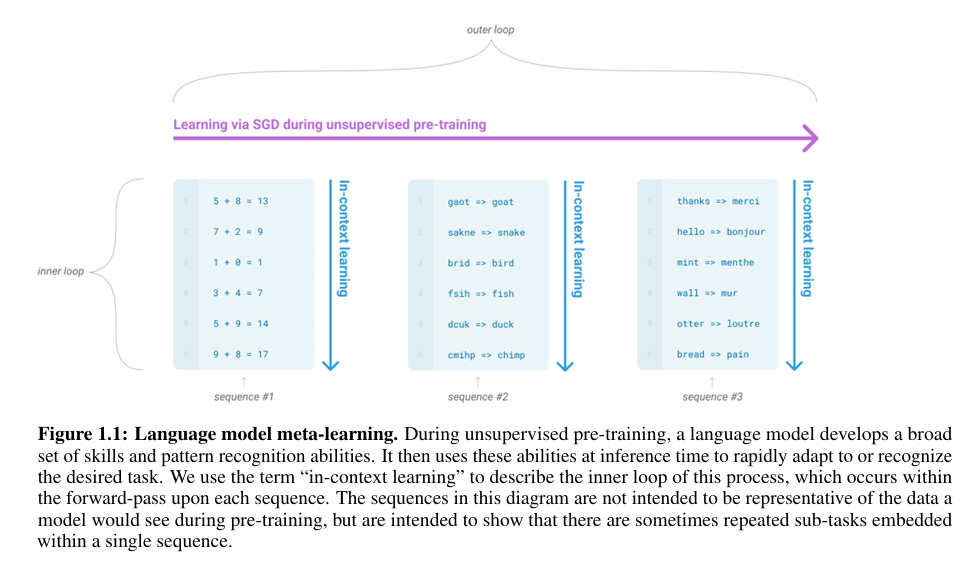
元学习或者说情境学习(In-Context Learning)是解决上述问题的理想途径,gpt-2便只在大量预构造的数据集上进行预训练,仅通过任务提示(Prompt)就能完成一些任务的潜力(Zero-shot),但是目前性能表现还是不够好,远远不如微调的效果(CoQa F1 值为55,与最先进的技术相比差了35)
文章还提到另外一个点,即扩大模型规模可能是解锁In-Context Learning潜力的钥匙。近年来,基于tansformer架构的语言模型参数量逐渐增大,每次都带来了下游任务性能的改进,并且有证据表明,与许多下游任务密切相关的对数损失(log loss)随着规模扩大遵循一个平滑的改进趋势
OpenAI通过训练了一个更大规模的模型——175B的gpt-3,并在如下三种设置下进行情景学习能力的探讨:
1、零样本(Zero-shot):只给任务指令,例如:把中文翻译为英文:
2、单样本(One-shot):给出任务指令加一个任务实例,例如:把中文翻译为英文: + 原文->译文
3、少样本(Few-shot):给出任务指令加若干个任务实例(通畅10-100个),例如:把中文翻译为英文: + 原文1->译文1 + ... + 原文n->译文n
OpenAI进行了一个简单任务的少样本学习过程,该任务要求模型从一个单词中去除无关的符号。由下图可知两点:1、模型的性能随着任务描述的加入以及上下文中示例数量K的增加而提高;2、少样本学习能力也随着模型规模的大小而显著提升。这些“学习”曲线不涉及任何梯度更新或微调,仅仅是作为条件给出的演示示例数量的增加。GPT-3在零样本设置下的CoQA上达到了81.5 F1,在单样本设置下的CoQA上达到了84.0 F1,在少样本设置下达到了85.0 F1。类似地,GPT-3在零样本设置下的TriviaQA上达到了64.3%的准确率,在单样本设置下达到68.0%,在少样本设置下达到71.2%。当然,在另一些任务中,即使是在GPT-3,在少样本下的性能仍然不足。如用于自然语言推理任务的数据集ANLIy,以及如RACE或QuACz这样的阅读理解数据集。OpenAI还训练了一系列较小的模型(参数从0.125B到13B),以便在零样本、单样本和少样本中将它们的性能与GPT-3进行比较。对于大多数任务,性能都随着模型规模呈现出相对平滑的缩放趋势,零样本、单样本和少样本性能之间的差距通常随着模型容量的增大而扩大。由第二张图可知,few-shot下, 随着模型规模的增大,性能稳步提升更大,相较于zero-shot和one-shot性能更好,一是证明了few-shot在in-context learning中的能力更强,二是证明了更大的模型更擅长in-context learning
由于gpt-3使用的预训练数据集Common Crawl规模巨大,很可能无意中包含了后续用于测试的数据,团队开发了工具来检测和量化这种影响,并对可能受污染的数据集进行标注或不予报告,保证了实验结果的可信度,尽管可能这种污染对gpt-3在大多数数据集上的性能影响较小
下图展示了一个将英语翻译为法语的例子,单样本像给数据标注员工布置任务,零样本则像直接给人类一个口头指令。GPT-3的目标不仅是提高benchmark分数,更是追求一种更接近人类智能的、灵活通用的问题解决方式。虽然少样本性能可能更接近SOTA,但单样本和零样本似乎才是与人类表现进行公平比较的更合理的setting,因为人类通常不需要看100个例子才能学会一个新任务
OpenAI训练了8个不同规模的模型(从125M到175B),从而进行Scaling Law的相关研究(模型的性能(损失)随规模增大遵循一个平滑、可预测的幂律关系)。下表中的具体参数(层数 n_layers、模型维度 d_model、前馈层维度 d_ff = 4 * d_model、头数等)并非通过大量神经架构搜索得来。而是基于如何最有效地利用算力以及在多个GPU上进行模型并行时,如何平衡各GPU的计算负载,避免通信瓶颈等原则考虑
训练数据集:训练一个超大规模模型,不仅需要海量的数据,更需要高质量、高多样性和去重后的数据:
1、原始Common Crawl数据包含大量低质量(如垃圾邮件、机器生成文本、格式错误内容)的文本。文中使用一个高质量参考语料库(可能包括书籍、高质量网页等)作为“黄金标准”,通过计算文本相似度(例如,使用嵌入向量)来筛选Common Crawl中与这些高质量文本相似的内容。这相当于用一个高质量的“滤网”过滤掉互联网数据中的大部分垃圾,过滤后数据量从45TB压缩到570GB,但平均质量大幅提升
2、网络数据中存在大量近似重复的内容(例如,同一新闻文章被不同网站转载时有微小修改,或内容聚合网站的列表)。精确匹配去重无法消除这些内容。文中使用模糊哈希或最小哈希(MinHash) 等技术,在文档级别识别并移除高度相似但不完全相同的文档,避免模型在几乎相同的内容上浪费训练时间和容量,同时保证评估有效性
3、采用混合高质量数据策略: 并非单纯的按数据源大小等比例采样,而是对高质量数据源进行上采样,提高模型看到高质量数据的概率。数据源包括扩展版WebText(来自Reddit高赞帖子的外链内容,主观质量高)、Books1 & Books2(两个大型图书语料库,包含长篇幅、逻辑连贯的文本)、Wikipedia(高质量、结构化的百科全书数据)。文中明确接受“用少量的过拟合风险来换取更高质量的训练数据”,这意味着宁愿让模型在高质量数据集上多学几遍(轻微过拟合),也要确保模型从最高质量的数据中充分学习其优秀的语言结构和知识。
4、文中也考虑了数据污染的情况,例如下游任务的测试集或开发集数据意外地出现在了模型的训练数据中,对于gpt-3这种在互联网上进行预训练的大模型,即使是偶然看到过测试数据,也可能导致其评估分数被大幅夸大,无法反映其真实的零/少样本学习能力。OpenAI努力搜索并移除已知的重叠部分。但是去重过程并不完美,有些污染未被清除,不过文中专门分析了残留污染对结果的影响程度,让读者可以自行判断。(PS:gpt-2曾经为了展示模型Zero-shot的能力,专门移除了Wikipedia相关数据,但是gpt-3重新引入了进来,虽然也进行了数据污染相关分析,但是这时候的目的似乎已经变为了“探索模型规模的极限,尽可能挖掘出最大规模模型的最佳性能”,所以Wikipedia这样高质量的数据是不可能错过的)
训练过程:在OpenAI发布的《Scaling laws for neural language models》中提到:更大的模型通常可以使用更大的batch size,但需要更小的学习率,在训练期间测量梯度噪声规模,并用它来指导选择批量大小。为了训练更大的模型而不耗尽内存,使用了张量并行和流水线并行的混合策略,所有模型都在V100 GPU上训练
局限性:
1、文本生成会出现重复、前后矛盾、逻辑断裂(non-sequitur);在需要常识物理和复杂推理(如比较、蕴含理解)的任务上表现接近随机水平。模型学到了语言的统计规律,但可能缺乏更深层的世界模型和逻辑推理链条。未来LLM可能需要隐含地指向需要更好的常识表示和推理能力集成
2、 纯自回归模型(从左到右生成)具有固有缺陷。它不擅长回顾、比较、填充等需要“双向”信息的任务。gpt-3模型设计牺牲了双向性,导致在WIC、ANLI、RACE等任务上表现不佳。未来可以构建超大规模的双向模型(如BERT风格的),并探索如何让双向模型也能进行少样本学习
3、当前的自回归预训练目标函数平等对待所有词元,无法区分信息的重要性。且最终有用的系统应是目标驱动的,而非仅仅是概率预测,这可能是当前gpt系列预训练方式一个较大的局限性所在。未来可以进行逆强化学习,从人类反馈中学习目标;或者进行多模态融合
4、语言模型普遍存在的另一个局限性是预训练期间的样本效率低下。虽然gpt-3在测试时样本效率方面向人类(单样本或零样本)更迈进了一步,但它在预训练期间看到的文本仍然比人类一生中看到的要多得多,提高预训练样本效率是未来工作的一个重要方向,未来可能通过提供额外物理世界信息,或通过算法改进来实现
5、这里存在一个问题:few-shot到底是“真正学习”了新任务,还是仅仅“识别”出了在预训练中已内化的任务?文中作者承认其不确定性,并认为即使只是“识别”,也是一个巨大的进步。在未来,理解少样本学习的工作原理也许本身就是一个重要的研究课题
6、像gpt-3这样175B参数的大模型部署和推理成本极高,在某些场景也许难以投入实际应用。未来可以进行蒸馏方面的探索,将大模型的知识压缩到小模型中,为特定任务提供高效解决方案
7、不可解释性、校准性差(对不确定性的估计不准)、数据偏见。这些可看作是深度学习均有的问题,是阻碍AI可信赖、公平部署的核心障碍,尤其是偏见问题
参考资料
《Language Models are Few-Shot Learners》
posted @
2025-08-24 17:30
Luna-Evelyn
阅读(
21 )
评论()
收藏
举报






 浙公网安备 33010602011771号
浙公网安备 33010602011771号