现代大模型架构
架构图

- 将AE与AR模型同Transformer进行联系,那么Transformer的Encoder可看作为AE,而其Decoder(例如在文本翻译、文本续写这类NLG任务)可看作AR,而完整的类Transformer结构则是seq2seq
- PS: 个人感觉此处可以再补充一点,Transformer的Decoder符合以下特征时,才是典型AR:
- 目标是预测下一个token(基于前面的上下文):
- 模型结构硬性地只允许看“前面的 token”(使用 masked self-attention)
- 训练/推理是一步步进行的(逐步解码)
AR(Decoder-only)
- 自回归模型,一般用于预测下一个词概率,擅长生成式NLP任务,AR模型使用注意力机制,预测下一个token
- 仅仅为单向编码(前向或者后向),不能进行双向上下文的充分理解
- 一些下游的语言理解任务一般需要双向的上下文信息(情感分析、句子匹配、段落理解),这导致AR语言模型与有效的预训练之间存在gap
- 缺点为需要大量文本数据进行x训练从而提高生成文本的高质量
AE(Encoder-only)
- 自编码模型,一般用于自然语言理解任务,情感分析、句子匹配、段落理解等
- 使用双向self-attention,每个token在建模时能够访问整个序列中所有token的表示,不受顺序方向的限制
- 在使用MLM进行预训练时,有两个问题:
- 1、基于其他token的信息重建mask部分的token,此时假设是各个被重建的mask部分是相互独立的,但是在实际的文本中,high-order依赖和long-range依赖是非常常见的。high-order: 比如
The doctor who treated the patient later received an award for his work.中,被mask掉的词是doctor、patient、award、work,这时候AE模型并不会对doctor+patient+work->award这种高阶依赖关系进行捕捉,而是把这几个mask独立开,依赖于另外的词汇; long_range: 例如The doctor helped the patient before [MASK] left the hospital,需要建立一个entity->pronou的指代链条,AE模型没有刻意强化前后文之间的链式依赖,导致泛化性虽然增加,但是具体指代不准确 - 2、预训练基于MLM任务进行学习,但是在下游任务微调时,使用的是完整的输入,
[MASK]的出现使得两个任务之间产生了distribution shift,h易导致 pretrain–finetune discrepancy问题
- 1、基于其他token的信息重建mask部分的token,此时假设是各个被重建的mask部分是相互独立的,但是在实际的文本中,high-order依赖和long-range依赖是非常常见的。high-order: 比如
- 缺点是它无法直接生成文本输出,因此在需要生成文本的任务中不太适用
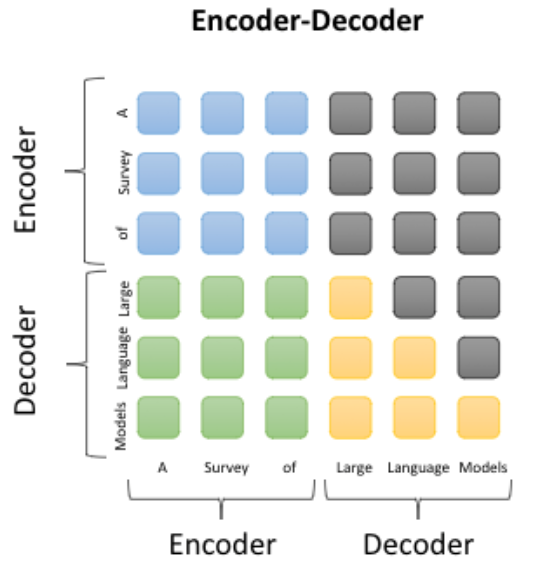
Encoder-Decoder
-
Encoder-Decoder 架构的核心思想是利用编码器对输入序列进行编码,提取其特征和语义信息,并将编码结果传递给解码器。然后,解码器根据编码结果生成相应的输出序列。这种架构的优点是能够更好地处理输入序列和输出序列之间的关系,从而提高机器翻译和对话生成等任务的准确性。通常用于序列到序列(Seq2Seq)任务,如机器翻译、对话生成等
-
缺点是模型复杂度较高,训练时间和计算资源消耗较大。
-
特点:输入输出分开encoder和decoder处理,encoder和decoder参数独立
Causal-Decoder
- 也称为因果解码器,属于Decoder only结构
- 输入和输出均为单向注意力。在生成新的输出时,只会考虑到之前的输出,而不会考虑到未来的输出,进行自回归训练
- 在处理需要全局上下文的任务时,它可能不如Prefix Decoder表现得好
- 与传统的transformer decoder相比,可以看作为简化版,去掉cross-attention和encoder,输入输出全部输入decoder
Prefix-Decoder
- 也称为非因果解码器,属于Decoder only结构
- 输入部分使用双向注意力,输出部分使用单向注意力。在生成新的输出时,会考虑到所有之前生成的输出
特点:Prefix Decoder在处理输入序列时,模型可以同时考虑序列中的所有词。生成输出时会考虑整个输入序列,而不仅仅是之前的输出。这使得它在处理需要全局上下文的任务时表现更好。训练阶段,通常使用自回归方式进行训练,即在生成当前词时,使用之前生成的所有词。Encoder和Decoder则共享了同一个Transformer结构,共享参数。
代表模型:GLM、ChatGLM、ChatGLM2、U-PaLM - 特点:输入输出一起进入Decoder,只不过在处理输出部分时的时候让其满足causal-decoder的形式,进行自回归训练


 浙公网安备 33010602011771号
浙公网安备 33010602011771号