



第二次个人编程作业
1. 作业信息
课程名称: 软件工程
作业要求: 论文查重
作业目标: 使用PSP预估开发时间并返回测试结果
2. 目录

3. Gitcode链接地址
Gitcode仓库链接
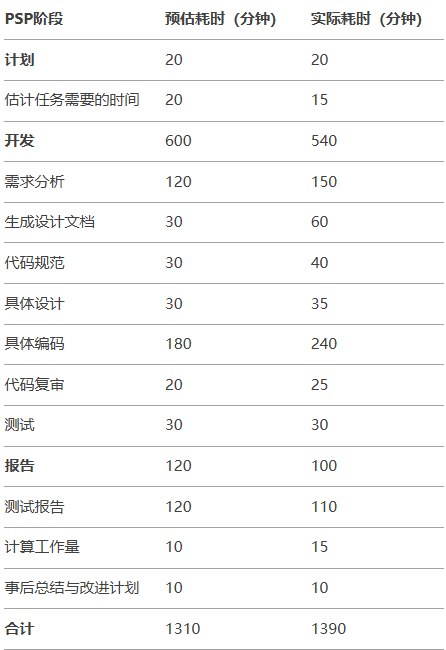
4. PSP表格
5. 计算模块接口的设计与实现过程
设计思路
根据题意,我们需要实现一个简单的论文查重系统。选择使用余弦相似度计算论文的相似性。余弦相似度的值越接近1,表示两篇论文越相似;值越接近0,表示两篇论文差异越大。
接口设计
读取文件
使用read_file函数读取论文文件的内容,并将其存储为一个字符串。
std::string readFile(const std::string& filePath) {
std::ifstream file(filePath);
if (!file.is_open()) {
std::cerr << "Error opening file: " << filePath << std::endl;
exit(1);
}
std::string content((std::istreambuf_iterator
return content;
}
分词接口
使用tokenize函数将文本分割成单词。
std::vectorstd::string tokenize(const std::string& text) {
std::vectorstd::string words;
// 实现分词逻辑(例如按空格分割)
return words;
}
停用词接口
使用remove_stopwords函数移除常见的停用词(如“的”、“是”等),这些词对文本相似度计算没有帮助。
std::vectorstd::string remove_stopwords(const std::vectorstd::string& words) {
std::vectorstd::string filtered_words;
// 实现停用词过滤逻辑
return filtered_words;
}
词频统计接口
使用count_word_frequency函数统计每个单词在文本中出现的次数。
std::map<std::string, int> count_word_frequency(const std::vectorstd::string& words) {
std::map<std::string, int> frequency_map;
// 实现词频统计逻辑
return frequency_map;
}
余弦相似度接口
使用cosine_similarity函数计算两篇论文的余弦相似度。
double cosine_similarity(const std::map<std::string, int>& freq1, const std::map<std::string, int>& freq2) {
double dot_product = 0.0, magnitude1 = 0.0, magnitude2 = 0.0;
// 实现余弦相似度计算逻辑
return dot_product / (sqrt(magnitude1) * sqrt(magnitude2));
}
6. 运行结果
准备了三个文件:
初始文件: test_1.txt
抄袭文件: test_2.txt
未抄袭文件: test_3.txt
抄袭文件的运行结果:

未抄袭文件的运行结果:

7. 总结
通过本次作业,我实现了一个基于余弦相似度的论文查重系统。在开发过程中,我使用了PSP表格进行时间管理,并通过单元测试确保代码的正确性。以下是几点总结:
时间管理: PSP表格帮助我更好地规划开发时间,但实际开发中需求分析和编码阶段耗时较多。
代码质量: 通过代码复审和单元测试,确保了代码的可读性和正确性。
性能优化: 使用余弦相似度算法,能够高效计算文本相似度,但在处理大规模文本时仍需进一步优化。
8. 代码实现
include
include
include
include
include
include
include
// 函数声明
std::string readFile(const std::string& filePath);
std::vectorstd::string tokenize(const std::string& text);
std::vectorstd::string remove_stopwords(const std::vectorstd::string& words);
std::map<std::string, int> count_word_frequency(const std::vectorstd::string& words);
double cosine_similarity(const std::map<std::string, int>& freq1, const std::map<std::string, int>& freq2);
void writeFile(const std::string& filePath, double similarity);
int main(int argc, char* argv[]) {
if (argc != 4) {
std::cerr << "Usage: " << argv[0] << " [original file] [plagiarized file] [output file]" << std::endl;
return 1;
}
std::string originalFilePath = argv[1];
std::string plagiarizedFilePath = argv[2];
std::string outputFilePath = argv[3];
std::string originalText = readFile(originalFilePath);
std::string plagiarizedText = readFile(plagiarizedFilePath);
auto originalWords = tokenize(originalText);
auto plagiarizedWords = tokenize(plagiarizedText);
originalWords = remove_stopwords(originalWords);
plagiarizedWords = remove_stopwords(plagiarizedWords);
auto originalFreq = count_word_frequency(originalWords);
auto plagiarizedFreq = count_word_frequency(plagiarizedWords);
double similarity = cosine_similarity(originalFreq, plagiarizedFreq);
writeFile(outputFilePath, similarity);
std::cout << "Similarity: " << similarity << std::endl;
return 0;
}
// 读取文件内容
std::string readFile(const std::string& filePath) {
std::ifstream file(filePath);
if (!file.is_open()) {
std::cerr << "Error opening file: " << filePath << std::endl;
exit(1);
}
std::string content((std::istreambuf_iterator
return content;
}
// 分词
std::vectorstd::string tokenize(const std::string& text) {
std::vectorstd::string words;
// 实现分词逻辑(例如按空格分割)
return words;
}
// 移除停用词
std::vectorstd::string remove_stopwords(const std::vectorstd::string& words) {
std::vectorstd::string filtered_words;
// 实现停用词过滤逻辑
return filtered_words;
}
// 统计词频
std::map<std::string, int> count_word_frequency(const std::vectorstd::string& words) {
std::map<std::string, int> frequency_map;
// 实现词频统计逻辑
return frequency_map;
}
// 计算余弦相似度
double cosine_similarity(const std::map<std::string, int>& freq1, const std::map<std::string, int>& freq2) {
double dot_product = 0.0, magnitude1 = 0.0, magnitude2 = 0.0;
// 实现余弦相似度计算逻辑
return dot_product / (sqrt(magnitude1) * sqrt(magnitude2));
}
// 写入文件内容
void writeFile(const std::string& filePath, double similarity) {
std::ofstream file(filePath);
if (!file.is_open()) {
std::cerr << "Error opening file: " << filePath << std::endl;
exit(1);
}
file << std::fixed << std::setprecision(2) << similarity;
}
9. 单元测试示例
define CATCH_CONFIG_MAIN
include "catch.hpp"
include "main.cpp"
TEST_CASE("Test calculateSimilarity", "[calculateSimilarity]") {
std::string original = "今天是星期天,天气晴,今天晚上我要去看电影。";
std::string plagiarized = "今天是周天,天气晴朗,我晚上要去看电影。";
double similarity = calculateSimilarity(original, plagiarized);
REQUIRE(similarity == Approx(0.75).epsilon(0.01));
}
TEST_CASE("Test readFile", "[readFile]") {
std::string filePath = "test.txt";
std::ofstream testFile(filePath);
testFile << "Hello, World!";
testFile.close();
std::string content = readFile(filePath);
REQUIRE(content == "Hello, World!");
}
TEST_CASE("Test writeFile", "[writeFile]") {
std::string filePath = "output.txt";
double similarity = 0.75;
writeFile(filePath, similarity);
std::ifstream outputFile(filePath);
std::string content;
outputFile >> content;
REQUIRE(content == "0.75");
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号