


Serializable标记性接口
介绍 类的序列化由实现java.io.Serializable接口的类启用。不实现此接口的类将不会使任何状态序列化或反序列化。
可序列化类的所有子类型都是可序列化的。 序列化接口没有方法或字段,仅用于标识可串行化的语 义。 序列化:将对象的数据写入到文件(写对象) 反序列化:将文件中对象的数据读取出来(读对象)
public class Student implements Serializable { private static final long serialVersionUID = 1014100089306623762L; //姓名 private String name; //年龄 private Integer age; public Student() { } public Student(String name, Integer age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}'; } }
测试类
public class Test01 { public static void main(String[] args) throws Exception { Student s = new Student(); System.out.println(s); //创建对象操作流 --> 序列化 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("C:\\Users\\admin\\Desktop\\obj.txt")); //创建集合,且添加学生对象 ArrayList<Student> list = new ArrayList<>(); list.add(new Student("悔创阿里杰克马", 51)); list.add(new Student("会点一点长几颗", 26)); list.add(new Student("容颜老去蒋青青", 32)); list.add(new Student("将里最丑刘一飞", 27)); //将集合写入到文件 oos.writeObject(list); //创建对象输入流 --> 反序列化 ObjectInputStream ois = new ObjectInputStream(new FileInputStream("C:\\Users\\admin\\Desktop\\obj.txt")); //读取数据 Object o = ois.readObject(); //向下转型 ArrayList<Student> al = (ArrayList<Student>) o; //遍历集合 for (int i = 0; i < al.size(); i++) { //根据索引取出集合的每一个元素 Student stu = al.get(i); System.out.println(stu); } } }
看结果
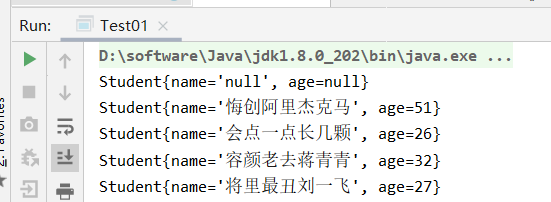
文件obj.txt的内容

我们将Student注释掉Serializable接口

看结果

报了一个未序列化异常
为什么要定义serialversionUID变量
简单看一下 Serializable接口的说明

Cloneable 标记性接口
一个类实现 Cloneable 接口来指示 Object.clone() 方法,该方法对于该类的实例进行字段的复制是合法的。在不实现 Cloneable 接口的实例上调用对象的克隆方法会导致异常 CloneNotSupportedException 被抛出。
简言之:克隆就是依据已经有的数据,创造一份新的完全一样的数据拷贝
克隆的前提条件: 被克隆对象所在的类必须实现 Cloneable 接口 必须重写 clone 方法

clone的基本使用
public class ArrayList_Clone { public static void main(String[] args) { ArrayList<String> list = new ArrayList<String>(); list.add("人生就是旅途"); list.add("也许终点和起点会重合"); list.add("但是一开始就站在起点等待终点"); list.add("那么其中就没有美丽的沿途风景和令人难忘的过往"); //调用方法进行克隆 Object o = list.clone(); System.out.println(o == list); System.out.println(o); System.out.println(list); } }
结果

ArrayList的clone源码分析
/** * Returns a shallow copy of this <tt>ArrayList</tt> instance. (The * elements themselves are not copied.) * * @return a clone of this <tt>ArrayList</tt> instance */ public Object clone() { try { ArrayList<?> v = (ArrayList<?>) super.clone(); v.elementData = Arrays.copyOf(elementData, size); v.modCount = 0; return v; } catch (CloneNotSupportedException e) { // this shouldn't happen, since we are Cloneable throw new InternalError(e); } }
两种不同的克隆方法,浅克隆(ShallowClone)和深克隆(DeepClone)。
浅克隆是指拷贝对象时仅仅拷贝对象本身(包括对象中的基本变量),而不拷贝对象包含的引用指向的对象。
深克隆不仅拷贝对象本身,而且拷贝对象包含的引用指向的所有对象。举例来说更加清楚:
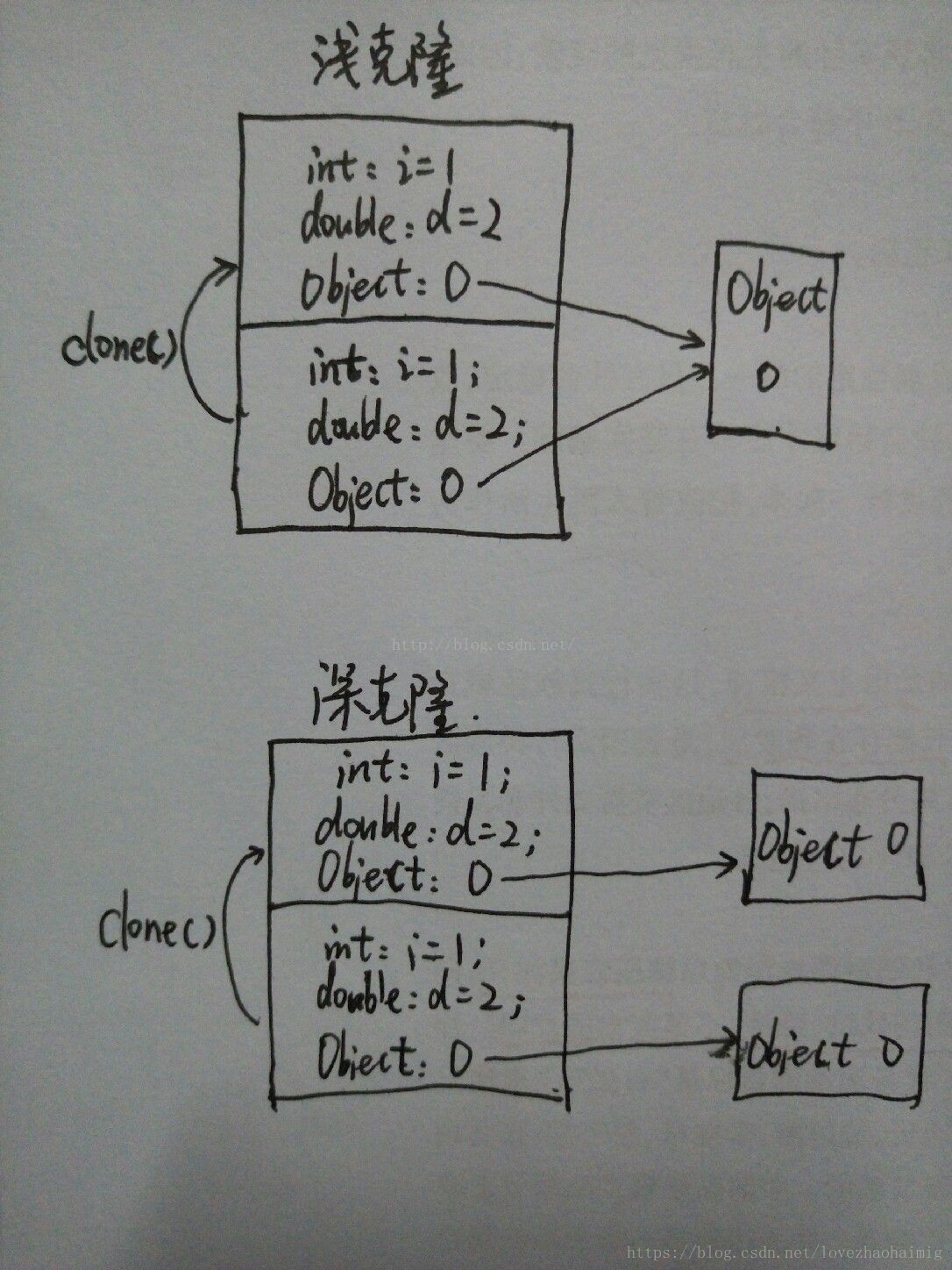
浅克隆
学生技能类
//学生的技能类 public class Skill implements Cloneable{ private String skillName; public Skill() { } public Skill(String skillName) { this.skillName = skillName; } public String getSkillName() { return skillName; } public void setSkillName(String skillName) { this.skillName = skillName; } @Override public String toString() { return "Skill{" + "skillName='" + skillName + '\'' + '}'; } }
学生类
public class Student implements Cloneable{ //姓名 private String name; //年龄 private Integer age; //技能 private Skill skill; public Student() { } public Student(String name, Integer age, Skill skill) { this.name = name; this.age = age; this.skill = skill; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public Skill getSkill() { return skill; } public void setSkill(Skill skill) { this.skill = skill; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", skill=" + skill + '}'; } //浅克隆 @Override public Student clone() throws CloneNotSupportedException { return (Student) super.clone(); } }
测试类
public class Test01 { public static void main(String[] args) throws CloneNotSupportedException { //用自定义对象演示 深浅拷贝 Skill skill = new Skill("倒拔垂杨柳"); Student s = new Student("鲁智深", 31, skill); //调用clone方法进行克隆 Student obj = s.clone(); //比较地址 System.out.println(s == obj); System.out.println("被克隆对象: " + s); System.out.println("克隆出来的对象: " + obj); System.out.println("----华丽的分割线----"); /** * 存在的问题: 基本数据类型可以达到完全复制,引用数据类型则不可以 * 原因: 在学生对象s被克隆的时候,其属性skill(引用数据类型)仅仅是拷贝了一份引用,因此当skill的值发生改 * 变时,被克隆对象s的属性skill也将跟随改变 */ //克隆之后,更改skill中的数据 skill.setSkillName("荷花酒"); //更改克隆后对象的数据 obj.setName("扈三娘"); obj.setAge(19); System.out.println("被克隆对象: " + s); System.out.println("克隆出来的对象: " + obj); } }
看结果
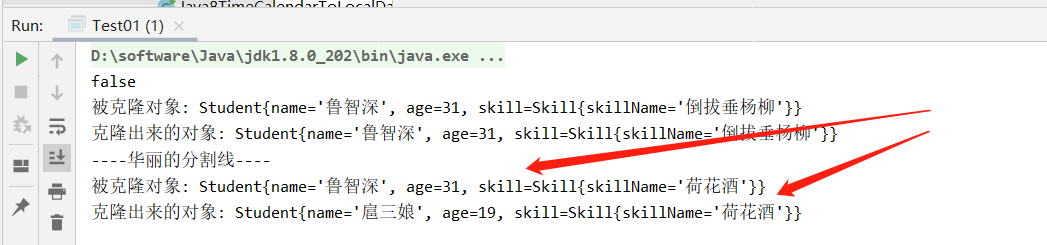
在学生对象s被克隆的时候,其属性skill(引用数据类型)仅仅是拷贝了一份引用,因此当skill的值发生改变时,被克隆对象s的属性skill也将跟随改变
深克隆
学生技能类
public class Skill implements Cloneable{ private String skillName; public Skill() { } public Skill(String skillName) { this.skillName = skillName; } public String getSkillName() { return skillName; } public void setSkillName(String skillName) { this.skillName = skillName; } @Override public String toString() { return "Skill{" + "skillName='" + skillName + '\'' + '}'; } //重写克隆方法,将权限修饰符改成public @Override public Skill clone() throws CloneNotSupportedException { return (Skill) super.clone(); } }
学生类
public class Student implements Cloneable{ //姓名 private String name; //年龄 private Integer age; //技能 private Skill skill; public Student() { } public Student(String name, Integer age, Skill skill) { this.name = name; this.age = age; this.skill = skill; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public Skill getSkill() { return skill; } public void setSkill(Skill skill) { this.skill = skill; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", skill=" + skill + '}'; } //深克隆 @Override public Student clone() throws CloneNotSupportedException { //调用超类Object中方法clone进行对象克隆,得到一个新的学生对象 Student newStu = (Student) super.clone(); //调用学生类其属性skill的clone方法,对属性进行克隆 Skill s = this.skill.clone(); //再将克隆的Skill设置给克隆出来的学生对象 newStu.setSkill(s); //返回克隆出来的学生对象 return newStu; } }
测试类
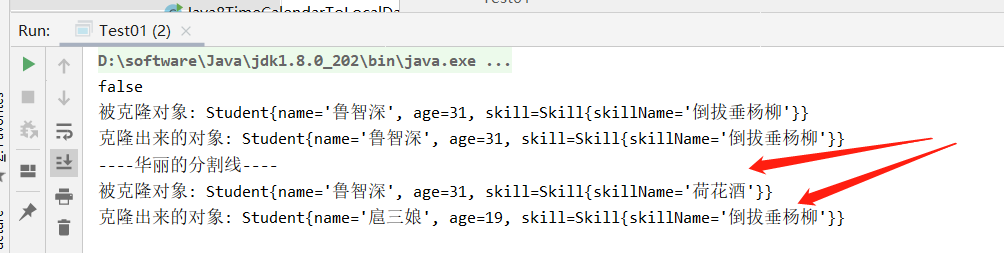
public class Test01 { public static void main(String[] args) throws CloneNotSupportedException { //用自定义对象演示 深浅拷贝 Skill skill = new Skill("倒拔垂杨柳"); Student s = new Student("鲁智深", 31, skill); //调用clone方法进行克隆 Student obj = s.clone(); //比较地址 System.out.println(s == obj); System.out.println("被克隆对象: " + s); System.out.println("克隆出来的对象: " + obj); System.out.println("----华丽的分割线----"); //克隆之后,更改skill中的数据 skill.setSkillName("荷花酒"); //更改克隆后对象的数据 obj.setName("扈三娘"); obj.setAge(19); System.out.println("被克隆对象: " + s); System.out.println("克隆出来的对象: " + obj); } }
看结果
RandomAccess标记接口
看源码
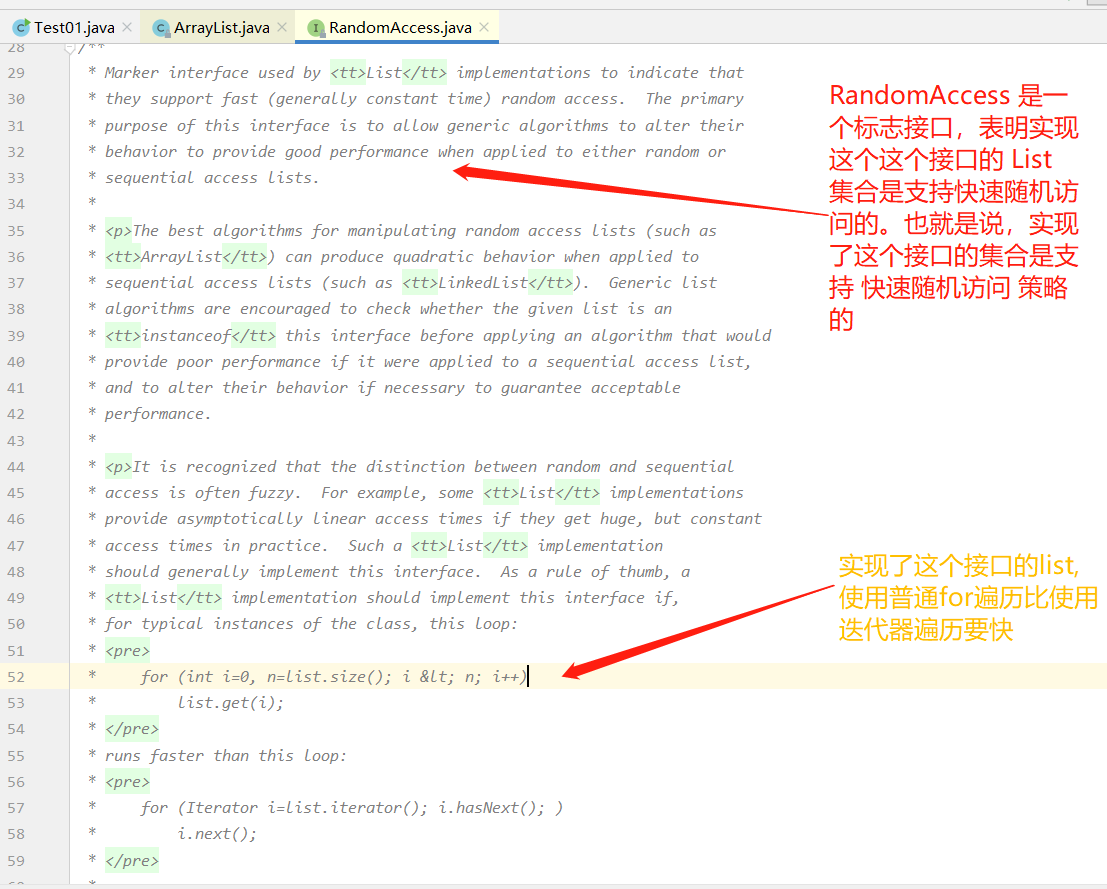
用处是当要实现某些算法时,会判断当前类是否实现了RandomAccess接口,会选择不同的算法。
接口RandomAccess中内容是空的,只是作为标记用。比如List下的ArrayList和LinkedList。其中ArrayList实现了RandomAccess。而LinkedList没有。
我们可以利用instanceof来判断哪一个是实现了RandomAccess。分辨出两个集合。其中ArrayList使用for循环遍历快,而LinkedList使用迭代器快。那么通过分辨,不同的集合使用不同的遍历方式。
案例演示-ArrayList
添加1000万条数据,并获取
public class Test01 { public static void main(String[] args) { //创建ArrayList集合 List<String> list = new ArrayList<>(); //添加1000万条数据 for (int i = 0; i < 10000000; i++) { list.add(i + "a"); } System.out.println("----通过索引(随机访问:)----"); long startTime = System.currentTimeMillis(); for (int i = 0; i < list.size(); i++) { //仅仅为了演示取出数据的时间,因此不对取出的数据进行打印 list.get(i); } long endTime = System.currentTimeMillis(); System.out.println("随机访问: " + (endTime - startTime)); System.out.println("----通过迭代器(顺序访问:)----"); startTime = System.currentTimeMillis(); Iterator<String> it = list.iterator(); while (it.hasNext()) { //仅仅为了演示取出数据的时间,因此不对取出的数据进行打印 it.next(); } endTime = System.currentTimeMillis(); System.out.println("顺序访问: " + (endTime - startTime)); } }
看结果
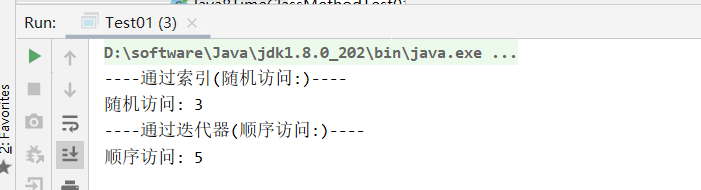
可以看出,for循环遍历元素时间上是少于迭代器的,证明RandomAccess 接口确实是有这个效果。
当然,现在的语言和机器性能这么高,两种方式遍历数据的性能差距几乎可以忽略不计,尤其是数据量不大的情况下。所以,日常使用中没必要过分追求哪种方式好,按照自己的习惯来就行。
案例演示-LinkedList
添加10W条数据,并获取
public class Test02 { public static void main(String[] args) { //创建LinkedList集合 List<String> list = new LinkedList<>(); //添加10W条数据 for (int i = 0; i < 100000; i++) { list.add(i + "a"); } System.out.println("----通过索引(随机访问:)----"); long startTime = System.currentTimeMillis(); for (int i = 0; i < list.size(); i++) { //仅仅为了演示取出数据的时间,因此不对取出的数据进行打印 list.get(i); } long endTime = System.currentTimeMillis(); System.out.println("随机访问: " + (endTime - startTime)); System.out.println("----通过迭代器(顺序访问:)----"); startTime = System.currentTimeMillis(); Iterator<String> it = list.iterator(); while (it.hasNext()) { //仅仅为了演示取出数据的时间,因此不对取出的数据进行打印 it.next(); } endTime = System.currentTimeMillis(); System.out.println("顺序访问: " + (endTime - startTime)); } }
看结果

为什么LinkedList随机访问比顺序访问要慢这么多?
源码分析
随机访问
每次LinkedList对象调用get方法获取元素,都会执行以下代码
list.get(i);
public E get(int index) { checkElementIndex(index); return node(index).item; }
/** * Returns the (non-null) Node at the specified element index. */ Node<E> node(int index) { // assert isElementIndex(index); //node方法每次被调用的时候都会根据集合size进行折半动作 //判断get方法中的index是小于集合长度的一半还是大于 if (index < (size >> 1)) { Node<E> x = first; //如果小于就从链表的头部一个个的往后找 for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; //如果大于就从链表的尾部一个个的往前找 for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
顺序访问
获取迭代器的时候,会执行以下代码
Iterator<String> it = list.iterator();
跟进去
public Iterator<E> iterator() { return listIterator(); }
继续
public ListIterator<E> listIterator() { return listIterator(0); }
继续
public ListIterator<E> listIterator(final int index) { rangeCheckForAdd(index); return new ListItr(index); }
LinkedList迭代器实现类
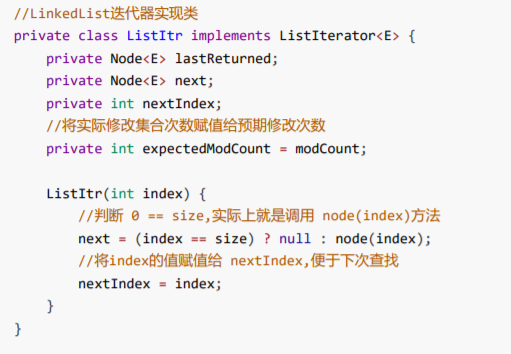


小结: 由于随机访问的时候源码底层每次都需要进行折半的动作,再经过判断是从头还是从尾部一个个寻找。
而顺序访问只会在获取迭代器的时候进行一次折半的动作,以后每次都是在上一次的基础上获取下一个元素。 因此顺序访问要比随机访问快得多
实际开发应用场景
if(list instanceof RandomAccess){ //使用for遍历 for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); } }else { //使用迭代器遍历 Iterator<String> it = list.iterator(); while (it.hasNext()) { it.next(); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号