2020年中青杯全国大学生数学建模竞赛题目【本科组】——纪念第一次训练模型!
一、题目:
B题(本科生组):股指与国家经济
自1990年12月19日上海证券交易所挂牌成立,经过30年的快速发展,中国证券市场已经具有相当规模,在多方面取得了举世瞩目的成就,对国民经济的资源配置起着日益重要的作用。截至2019年年底,上海和深圳两个证券交易所交易的股票约4000种。目前,市场交易制度、信息披露制度和证券法规等配套制度体系已经建立起来,投资者日趋理性和成熟,机构投资者迅速发展已具规模,政府对证券市场交易和上市公司主体行为的监管已见成效。
随着近年来我国资本市场的发展和证券交易规模的不断扩大,越来越多的资金投资于证券市场,与此同时市场价格的波动也十分剧烈,而波动作为证券市场中最本质的属性和特征,市场的波动对于人们风险收益的分析、股东权益最大化和监管层的有效监管都有着至关重要的作用,因此研究证券市场波动的规律性,分析引起市场波动的成因,是证券市场理论研究和实证分析的重要内容,也可以为投资者、监管者和上市公司等提供有迹可循的依据。
问题一:投资者购买目标指数中的资产,如果购买全部,从理论上讲能够完美跟踪指数,但是当指数成分股较多时,购买所有资产的成本过于高昂,同时也需要很高的管理成本,在实际中一般不可行。
(1)在附件数据的分析和处理的过程中,请对缺损数据进行补全。
(2)投资者购买成分股时,过多过少都不太合理。对于附件的成分股数据,请您通过建立模型,给出合理选股方案和投资组合方案。
问题二:尝试给出合理的评价指标来评估问题一中的模型,并给出您的分析结果。
问题三:通过附件股指数据和您补充的数据,对当前的指数波动和未来一年的指数波动进行合理建模,并给出您合理的投资建议和策略。
附件:十支股票的相关重要参数。二、代码分析:
①首先看一下我的文件夹目录:

大致说明一下:在这些文件及文件夹里面,本科生组放在的是桌面上!然后是整体在Pycharm里打开,所有生成的.idea是在第一级目录!只有【附件:十支股票参数.xlsx】是必须要的,另外的文件夹都是通过os模块创建的!
②因为是第一次要训练模型,百度了一波,发现股票的数据集都是csv,于是将这个Excel换成了csv!
"""
1、将excel文件转化为:以各指数成分股票命名的csv文件,方便后面的pandas以及matplotlib和numpy的操作
"""
# 步骤一:将excel文件转化为csv文件
import os
import csv
from openpyxl import load_workbook
# 打开excel文件
wb = load_workbook('附件:十支股票参数.xlsx')
# 列出文件中所有的表名
sheets = wb.sheetnames
path = 'csv数据集'
if not os.path.exists(path):
os.mkdir(path)
def create_csvs(title,path):
name = title
path = path
f = open(path + '/' + name + '.csv',mode="a+",newline='',encoding="utf-8-sig")
csv_write = csv.writer(f)
csv_write.writerow(['Date', 'Open', 'High', 'Low','Close','Turnover'])
f.close()
for sheet in sheets:
create_csvs(sheet,path)
f = open(path + '/' + sheet + '.csv',mode="a+",newline='',encoding="utf-8-sig")
csv_write = csv.writer(f)
table = wb[sheet]
rows = table.max_row
cols = table.max_column
for row in range(5,rows+1):
data = []
for col in range(cols+1):
data.append(str(table.cell(row,col+1).value).replace(r'/','-'))
csv_write.writerow(data[:6])
f.close()
代码很好理解:通过wb.sheetnames将Excel中的所有表名都显示出来,接着通过定义两个函数分别生成csv模板以及将我们的Excel中的几栏数据写入到对应的CSV文件中!最后是通过for循环,将10支股票生成的csv文件都放到一个文件夹【csv数据集】中!(这个文件夹是通过os模块创建的!)
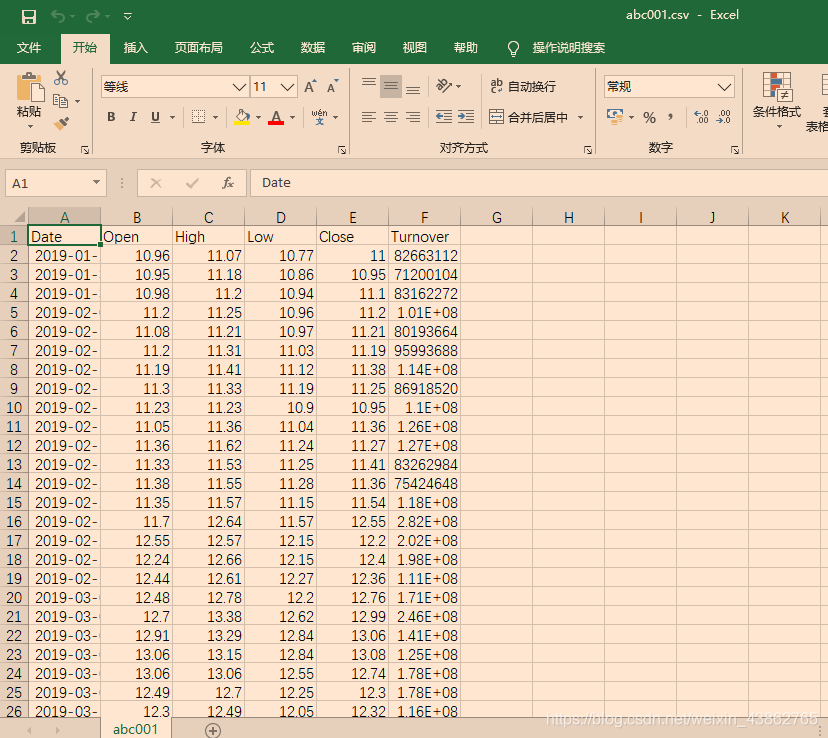
csv数据集文件夹图片:

csv文件图片:
③初步使用LSTM模型进行预测:
# 数据预处理以及绘制图形需要的模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 构建长短时神经网络需要的方法
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, LSTM, BatchNormalization
import os
# 需要之前50次的数据来预测下一次的数据
need_num = 50
# 训练数据的大小
training_num = 200
# 迭代10次
epoch = 10
batch_size = 32
path = 'pics'
if not os.path.exists(path):
os.mkdir(path)
# 训练数据的处理,我们选取整个数据集的前200个数据作为训练数据,后面的数据为测试数据
# 从csv读取数据
csvs = ['csv数据集/abc001.csv','csv数据集/abc002.csv','csv数据集/abc003.csv','csv数据集/abc004.csv','csv数据集/abc005.csv','csv数据集/abc006.csv','csv数据集/abc007.csv','csv数据集/abc008.csv','csv数据集/abc009.csv','csv数据集/abc010.csv']
for j in csvs:
dataset = pd.read_csv(j)
# 我们需要预测开盘数据,因此选取所有行、第2列数据
dataset = dataset.iloc[:, 4:5].values
# 训练数据就是上面已经读取数据的前200行
training_dataset = dataset[:training_num]
# 因为数据跨度几十年,随着时间增长,人民币金额也随之增长,因此需要对数据进行归一化处理
# 将所有数据归一化为0-1的范围
sc = MinMaxScaler(feature_range=(0, 1))
'''
fit_transform()对部分数据先拟合fit,
找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),
然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
'''
training_dataset_scaled = sc.fit_transform(X=training_dataset)
x_train = []
y_train = []
# 每10个数据为一组,作为测试数据,下一个数据为标签
for i in range(need_num, training_dataset_scaled.shape[0]):
x_train.append(training_dataset_scaled[i - need_num: i])
y_train.append(training_dataset_scaled[i, 0])
# 将数据转化为数组
x_train, y_train = np.array(x_train), np.array(y_train)
# 因为LSTM要求输入的数据格式为三维的,[training_number, time_steps, 1],因此对数据进行相应转化
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
# 构建网络,使用的是序贯模型
model = Sequential()
# return_sequences=True返回的是全部输出,LSTM做第一层时,需要指定输入shape
model.add(LSTM(units=128, return_sequences=True, input_shape=[x_train.shape[1], 1]))
model.add(BatchNormalization())
model.add(LSTM(units=128))
model.add(BatchNormalization())
model.add(Dense(units=1))
# 进行配置
model.compile(optimizer='adam',
loss='mean_squared_error')
model.fit(x=x_train, y=y_train, epochs=epoch, batch_size=batch_size)
# 进行测试数据的处理
# 前200个为测试数据,但是将150,即200-50个数据作为输入数据,因为这样可以获取
# 测试数据的潜在规律
inputs = dataset[training_num - need_num:]
inputs = inputs.reshape(-1, 1)
# 这里使用的是transform而不是fit_transform,因为我们已经在训练数据找到了
# 数据的内在规律,因此,仅使用transform来进行转化即可
inputs = sc.transform(X=inputs)
x_validation = []
for i in range(need_num, inputs.shape[0]):
x_validation.append(inputs[i - need_num:i, 0])
x_validation = np.array(x_validation)
x_validation = np.reshape(x_validation, (x_validation.shape[0], x_validation.shape[1], 1))
# 这是真实的股票价格,是源数据的[200:]即剩下的80个数据的价格
real_stock_price = dataset[training_num:279]
# 进行预测
predictes_stock_price = model.predict(x=x_validation)
# 使用 sc.inverse_transform()将归一化的数据转换回原始的数据,以便我们在图上进行查看
predictes_stock_price = sc.inverse_transform(X=predictes_stock_price)
# 绘制数据图表,红色是真实数据,蓝色是预测数据
plt.plot(real_stock_price, color='red', label='Real Stock Price')
plt.plot(predictes_stock_price, color='blue', label='Predicted Stock Price')
plt.title(label='Close Price Prediction')
plt.xlabel(xlabel='Time')
plt.ylabel(ylabel=j+'Close')
plt.savefig(path + '/' + j.replace(r'csv数据集/','').replace(r'.csv','') + '-Close.png')
plt.legend()
plt.show()其中呢,我们需要修改这个代码几次,因为上面的这个代码得出的是【10支股票收盘的预测价格】,我们需要将Close换成Open/High/Low/Tow/Turnover,以及dataset = dataset.iloc[:, 4:5].values所代表的切片的列数!
虽然结果有点差强人意,但是好歹是预测了:
④使用均值-方差模型进行波动评价:
数统的小姐姐提供的思路,我觉得可行,就写了一下代码:
import csv
import os
files = os.listdir('csv数据集')
path = '处理后csv数据集'
if not os.path.exists(path):
os.mkdir(path)
max_a = []
max_b = []
for file in files:
Date = [row[0] for row in csv.reader(open('csv数据集' + '/' + file,mode="r",encoding="utf-8"))]
Open = [row[1] for row in csv.reader(open('csv数据集' + '/' + file,mode="r",encoding="utf-8"))]
High = [row[2] for row in csv.reader(open('csv数据集' + '/' + file,mode="r",encoding="utf-8"))]
Low = [row[3] for row in csv.reader(open('csv数据集' + '/' + file,mode="r",encoding="utf-8"))]
Close = [row[4] for row in csv.reader(open('csv数据集' + '/' + file,mode="r",encoding="utf-8"))]
Turnover = [row[5] for row in csv.reader(open('csv数据集' + '/' + file,mode="r",encoding="utf-8"))]
f = open(path + '/' + file,mode="a+",newline="",encoding="utf-8-sig")
csv_write = csv.writer(f)
csv_write.writerow(['Date','Open','High','Low','Close','Turnover','收盘-开盘(a)','最高-最低(b)'])
sum_a = 0 # 求均值
sum_b = 0
variance_a = 0 # 求方差
variance_b = 0
for i in range(1,len(Date)-1):
a = float(Close[i]) - float(Open[i])
sum_a += a
b = float(High[i]) - float(Low[i])
sum_b += b
for j in range(1,len(Date)-1):
a = float(Close[j]) - float(Open[j])
b = float(High[j]) - float(Low[j])
variance_a += ((a-sum_a/280)**2)
variance_b += ((b-sum_b/280)**2)
for k in range(1,len(Date)):
a = float(Close[k]) - float(Open[k])
b = float(High[k]) - float(Low[k])
csv_write.writerow([Date[k],Open[k],High[k],Low[k],Close[k],Turnover[k],a,b])
csv_write.writerow('\n')
csv_write.writerow(['a的均值','a的方差','a(均值/方差)','b的均值','b的方差','b(均值/方差)'])
max_a.append(sum_a/variance_a)
max_b.append(sum_b/variance_b)
csv_write.writerow([sum_a/279,variance_a/279,sum_a/variance_a,sum_b/279,variance_b/279,sum_b/variance_b])
f.close()
# 给10支股票打分
fp = open(path + '/'+'10支股票打分情况.txt',mode="w",encoding='utf-8')
fp.write("10支股票(均值/方差)最大值:"+"\n")
fp.write("\t"+"①收益(a)最高分:"+"\n")
fp.write("\t"+str(max(max_a)) + "\n")
fp.write("\t"+"②风险(b)最高分:"+"\n")
fp.write("\t"+str(max(max_b)) + "\n")
fp.write("*"*100+"\n")
fp.write("10支股票(均值/方差)所有数值:"+"\n")
fp.write("\t"+"①收益(a)数值情况:"+"\n")
fp.write("\t"+str(max_a) + "\n")
fp.write("\t"+"②风险(b)数值情况:"+"\n")
fp.write("\t"+str(max_b) + "\n")
fp.write("*"*100+"\n")
fp.write("下面是收益(a)相对最高分时的打分情况"+"\n")
sum_a_average = 0
sum_b_average = 0
for i in range(len(max_a)):
fp.write("\t"+files[i].replace(r'.csv','')+":"+"\t"+str((max_a[i]/max(max_a))*100)+"\n")
sum_a_average += (max_a[i]/max(max_a))*100
fp.write("\t"+"收益打分平均值:"+"\t"+str(sum_a_average/10)+"\n")
fp.write("*"*100+"\n")
fp.write("下面是风险(b)相对最高分时的打分情况"+"\n")
for i in range(len(max_b)):
fp.write("\t"+files[i].replace(r'.csv','')+":"+"\t"+str((max_b[i]/max(max_b))*100)+"\n")
sum_b_average += (max_b[i]/max(max_b))*100
fp.write("\t"+"风险打分平均值:"+"\t"+str(sum_b_average/10)+"\n")思路是:计算收益(a) = 收盘-开盘,风险(b) = 最高-最低!然后呢得出10支股票的每一行的数据,写到新的csv文件的对应的列后面!接着,计算整列的a以及b分别对应的均值以及方差!写到csv文件的结尾处!然后,遍历10支股票的(均值/方差)最大值并设置成100分,分别得出10支股票的得分!
看一下打分情况:
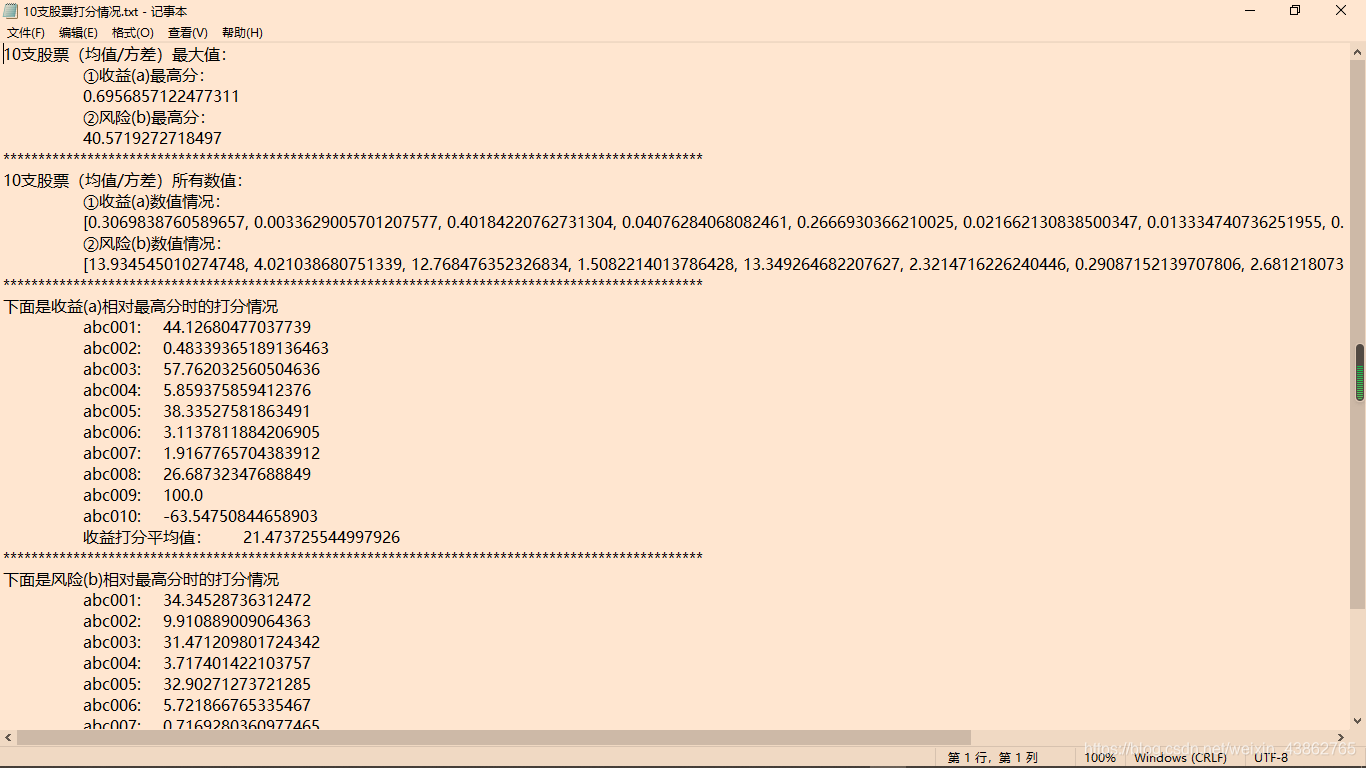
后面的分析数统队友的事了,反正我也看不懂~~~
⑤新的模型测试:
# 根据股票历史的开盘价、收盘价和成交量等特征值,从数学角度来预测股票未来的收盘价
import pandas as pd
import numpy as np
import math
import os
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 从文中获取数据
files = os.listdir('csv数据集')
path = '第二种模型预测图片'
if not os.path.exists(path):
os.mkdir(path)
for file in files:
origDf = pd.read_csv('csv数据集'+'/'+file, encoding='utf-8-sig')
df = origDf[['Close', 'High', 'Low', 'Open', 'Turnover']]
featureData = df[['Open', 'High', 'Turnover','Low']]
# 划分特征值和目标值
feature = featureData.values
"""
设置了要预测的目标列是收盘价。在后续的代码中,需要将计算出开盘价、最高价、最低价和成交量
这四个特征值和收盘价的线性关系,并在此基础上预测收盘价。
"""
target = np.array(df['Turnover'])
# 划分训练集/测试集
feature_train, feature_test, target_train, target_test = train_test_split(feature, target, test_size=0.05)
"""
通过调用train_test_split方法把包含在csv文件中的股票数据分成训练集和测试集,
这个方法前两个参数分别是特征列和目标列,而第三个参数0.05则表示测试集的大小是总量的0.05。
该方法返回的四个参数分别是特征值的训练集、特征值的测试集、要预测目标列的训练集和目标列的测试集。
"""
pridectedDays = int(math.ceil(0.05 * len(origDf))) # 预测天数
lrTool = LinearRegression() # 建了一个线性回归预测的对象
lrTool.fit(feature_train, target_train) # 调用fit方法训练特征值和目标值的线性关系,请注意这里的训练是针对训练集的
# 用特征值的测试集来预测目标值(即收盘价)。也就是说,是用多个交易日的股价来训练lrTool对象,并在此基础上预测后续交易日的收盘价
predictByTest = lrTool.predict(feature_test)
# 组装数据
index = 0
# 在前95%的交易日中,设置预测结果和收盘价一致
while index < len(origDf) - pridectedDays:
# 把训练集部分的预测股价设置成收盘价
df.ix[index, 'predictedVal'] = origDf.ix[index, 'Turnover']
# 设置了训练集部分的日期
df.ix[index, 'Date'] = origDf.ix[index, 'Date']
index = index + 1
predictedCnt = 0
# 在后5%的交易日中,用测试集推算预测股价
while predictedCnt < pridectedDays:
df.ix[index, 'predictedVal'] = predictByTest[predictedCnt]
# 把df中表示测试结果的predictedVal列设置成相应的预测结果,同时也在后面的程序语句逐行设置了每条记录中的日期
df.ix[index, 'Date'] = origDf.ix[index, 'Date']
predictedCnt = predictedCnt + 1
index = index + 1
plt.figure()
# 分别绘制了预测股价和真实收盘价,在绘制的时候设置了不同的颜色,也设置了不同的label标签值
df['predictedVal'].plot(color="red", label='predicted Data')
df['Turnover'].plot(color="blue", label='Real Data')
# 通过调用legend方法,根据收盘价和预测股价的标签值,绘制了相应的图例
plt.legend(loc='best') # 绘制图例
# 设置x坐标的标签
# 设置了x轴显示的标签文字是日期,为了不让标签文字显示过密,设置了“每20个日期里只显示1个”的显示方式
major_index = df.index[df.index % 20 == 0]
major_xtics = df['Date'][df.index % 20 == 0]
plt.xticks(major_index, major_xtics)
plt.setp(plt.gca().get_xticklabels(), rotation=30)
# 带网格线,且设置了网格样式
plt.grid(linestyle='-.')
plt.savefig(path + '/' + file.replace(r".csv",'-Turnover.png'))
plt.show()
"""预测股价和真实价之间有差距,但涨跌的趋势大致相同。而且在预测时没有考虑到涨跌停的因素,所以预测结果的涨跌幅度比真实数据要大"""相对于之前的LSTM模型来说,这个训练和测试更直观一点!代码跟之前一样,也需要手动的修改几次!
这边的情况是:将数据集的95%作为训练集,剩下的5%作为测试集,然后分别用红线和蓝线表示!
然后,我们就可以根据这个进行预测第280行数据(原文件中280行数据可能是错的!所以要补全~)
⑥以上这么多是问题一以及问题二的解决思路!至于问题三,队友用SPSS预测的!说实话,我没思路~~~
三、总结
写下这篇博客的目的:
- 六一儿童节快乐~~~
- 纪念一下自己的第一次模型使用~~(为后面的学习找到理由)
- 代码写了几个小时,难道不能亮出来么~~~
本文代码及材料见Github仓库!(点击就可以实现跳转~)
微信公众号:【空谷小莜蓝】,一个普通985的精神小伙创建的公众号,大家可以关注一下哈~~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号