pandas对excel行合并,行数据更新, 数据库连接等示例
示例
import pandas as pd data_list = [ {'tier_1': 'alpha', 'tier_2': 'do', 'tier_3': 'copy', 'department': 'AAA'}, {'tier_1': 'alpha', 'tier_2': 'thing', 'tier_3': 'vv', 'department': 'AAA'}, {'tier_1': 'alpha', 'tier_2': 'thing', 'tier_3': 'vv', 'department': 'AAA'}, # duplicate {'tier_1': 'alpha', 'tier_2': 'thing', 'tier_3': 'cookie', 'department': 'AAA'}, {'tier_1': 'python', 'tier_2': 'code', 'tier_3': 'lg', 'department': 'BBB'}, {'tier_1': 'python', 'tier_2': 'c#', 'tier_3': 'nothing', 'department': 'BBB'}, {'tier_1': 'sock', 'tier_2': 'bea', 'tier_3': 'tea', 'department': 'CCC'}, ] df = pd.DataFrame(data_list) print(df) ''' output: tier_1 tier_2 tier_3 department 0 alpha do copy AAA 1 alpha thing vv AAA 2 alpha thing vv AAA 3 alpha thing cookie AAA 4 python code lg BBB 5 python c# nothing BBB 6 sock bea tea CCC ''' # 数据去重 df.drop_duplicates(subset=['tier_1', 'tier_2', 'tier_3', 'department'], inplace=True) print(df) ''' output: tier_1 tier_2 tier_3 department 0 alpha do copy AAA 1 alpha thing vv AAA 3 alpha thing cookie AAA 4 python code lg BBB 5 python c# nothing BBB 6 sock bea tea CCC ''' # 数据更新 df.loc[df[(df['tier_1'] == 'sock') & (df['department'] == 'CCC')].index, 'tier_1'] = 'busong' print(df) ''' output: tier_1 tier_2 tier_3 department 0 alpha do copy AAA 1 alpha thing vv AAA 3 alpha thing cookie AAA 4 python code lg BBB 5 python c# nothing BBB 6 busong bea tea CCC '''
# 使用group分组
df_group = pd.DataFrame(df.groupby(['tier_1', 'tier_2', 'tier_3', 'department']).size(), columns=['count'])
# 按字段排序 df_group.sort_values(['tier_1', 'tier_2'], ascending=True, inplace=True) df_group.to_excel('test.xlsx')
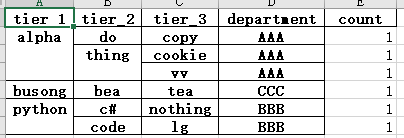
# method='pad' 进行行分解, 与上文行合并一直 df = pd.read_excel('test.xlsx') df.fillna(method='pad', inplace=True) print(df) '''output tier_1 tier_2 tier_3 department count 0 alpha do copy AAA 1 1 alpha thing cookie AAA 1 2 alpha thing vv AAA 1 3 busong bea tea CCC 1 4 python c# nothing BBB 1 5 python code lg BBB 1 '''
使用sqlalchemy配合pandas使用
from sqlalchemy import create_engine import pandas as pd import numpy as np import logging your_kwargs = {} def read(): # 读取数据示例 try: sql = '' engine = create_engine('postgresql://{user}:{password}@{host}/{database}'.format( **your_kwargs )) with engine.connect() as conn, conn.begin(): df = pd.read_sql(sql, conn) return df except Exception as e: logging.error(e) return np.nan def insert(data_list: [{}, {}]): # 插入数据到数据库 try: df = pd.DataFrame(data_list) engine = create_engine('postgresql://{user}:{password}@{host}/{database}'.format( **your_kwargs )) df.to_sql( name='tb_name', index=False, con=engine, if_exists='append', method='multi' ) except Exception as e: logging.error(e)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号