

4、Kubernetes
4、Kubernetes
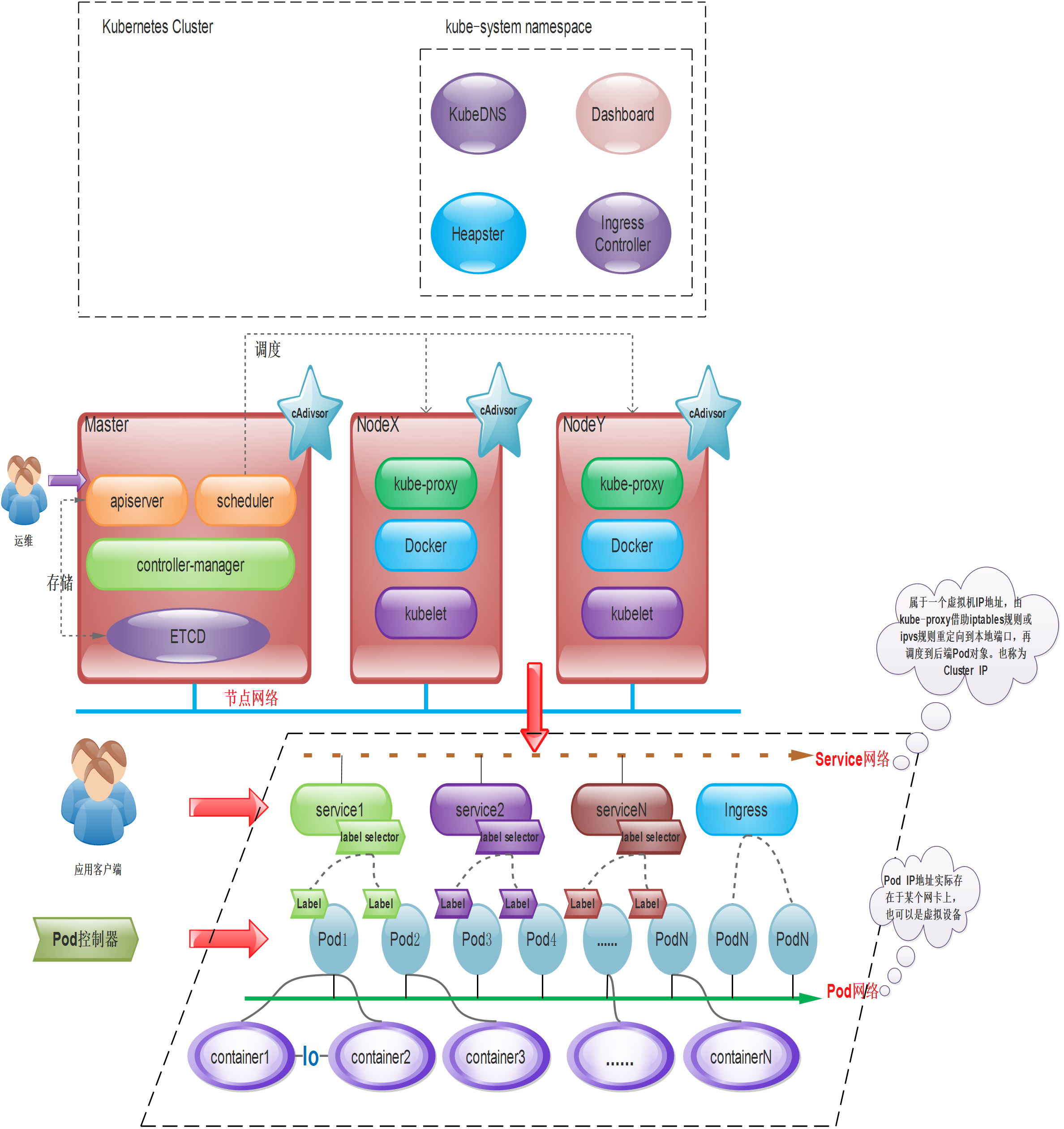
从上图,我们可以看到K8S组件和逻辑及其复杂,但是这并不可怕,我们从宏观上先了解K8S是怎么用的,再进行庖丁解牛。从上图我们可以看出:
- Kubernetes集群主要由Master和Node两类节点组成
- Master的组件包括:apiserver、controller-manager、scheduler和etcd等几个组件,其中apiserver是整个集群的网关。
- Node主要由kubelet、kube-proxy、docker引擎等组件组成。kubelet是K8S集群的工作与节点上的代理组件。
- 一个完整的K8S集群,还包括CoreDNS、Prometheus(或HeapSter)、Dashboard、Ingress Controller等几个附加组件。其中cAdivsor组件作用于各个节点(master和node节点)之上,用于收集及收集容器及节点的CPU、内存以及磁盘资源的利用率指标数据,这些统计数据由Heapster聚合后,可以通过apiserver访问。
1、定义
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
在Kubernetes中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
kubernetes是具有中心节点的架构,有master管理节点。由golang语言开发。
2、组件
2.1 master组件
2.1.1 kube-scheduler
监视新创建没有分配到node的pod,为pod选择node。
2.1.2 kube-apiserver
用于暴露kubernetes api,任何的资源请求/调用操作都是通过kube-apiserver提供的接口进行。
2.1.3 ETCD
etcd是kubernetes提供的默认存储系统,保存了所有的集群数据,使用时需要为ETCD数据提供备份计划。
2.1.4 kube-controller-manager
kube-controller-manager运行管理控制器,它们是集群中处理常规任务的后台线程。逻辑上,每个控制器是一个单独的进程,但为了降低复杂性,它们都被编译成单个二进制文件,并在单个进程中运行。
这些控制器包括:
-
节点(Node)控制器。
-
副本(Replication)控制器:负责维护系统中每个副本中的pod。
-
端点(Endpoints)控制器:填充Endpoints对象(即连接Services&Pods)。
-
Service Account和Token控制器:为新的Namespace创建默认帐户访问API Token。
2.1.5 cloud-controller-manager
云控制器管理器负责与底层云提供商的平台交互。云控制器管理器是Kubernetes版本1.6中引入的,还是Alpha的功能。
云控制器管理器仅运行云提供商特定的(controller loops)控制器循环。可以通过将--cloud-providerflag设置为external启动kube-controller-manager ,来禁用控制器循环。
cloud-controller-manager 具体功能:
- 节点(Node)控制器
- 路由(Route)控制器
- Service控制器
- 卷(Volume)控制器
2.1.6 插件 addons
插件(addon)是实现集群pod和Services功能的。Pod由Deployments,ReplicationController等进行管理。Namespace 插件对象是在kube-system Namespace中创建。
2.1.6.1 DNS
虽然不严格要求使用插件,但Kubernetes集群都应该具有集群 DNS。
群集 DNS是一个DNS服务器,能够为 Kubernetes services提供 DNS记录。
由Kubernetes启动的容器自动将这个DNS服务器包含在他们的DNS searches中。
2.1.6.2 用户界面
kube-ui提供集群状态基础信息查看。
2.1.6.3 容器资源监测
容器资源监控提供一个UI浏览监控数据。
2.1.6.4 Cluster-level Logging
Cluster-level logging,负责保存容器日志,搜索/查看日志。
2.2 node组件
节点组件运行在Node,提供Kubernetes运行时环境,以及维护Pod。
2.2.1 kubelet
kubelet是主要的节点代理,它会监视已分配给节点的pod。负责与其他节点通信,并进行本节点pod和容器的管理;负责维护容器的生命周期(创建pod、销毁pod),同时也负责volume(CVI)和网络(CNI)管理。
具体功能:
- 安装Pod所需的volume。
- 下载Pod的Secrets。
- Pod中运行的 docker(或experimentally,rkt)容器。
- 定期执行容器健康检查。
- Reports the status of the pod back to the rest of the system, by creating amirror podif necessary.
- Reports the status of the node back to the rest of the system.
2.2.2 kube-proxy
kube-proxy通过在主机上维护网络规则并执行连接转发来实现Kubernetes服务抽象。
- 通过在主机上维护网络规划并执行连接转发来实现service(iptables/ipvs)。
- 随时与api通信,把service或pod改变提交给api(不存储在master本地,需要保存在共享存储上),保存至etcd(可以是高可用集群)中,负责service实现,从内部pod至service和外部node到service访问。
2.2.3 docker
docker用于运行容器。
- 容器运行时(container runtime)
- 负责镜像管理以及pod和容器的真正运行
2.2.4 RKT
rkt运行容器,作为docker工具的替代方案。
2.2.5 supervisord
supervisord是一个轻量级的监控系统,用于保障kubelet和docker运行。
2.2.6 fluentd
fluentd是一个守护进程,可提供cluster-level logging.。
3、Add-one 附件
Add-one附件安装可使功能更加丰富。
- coredns/kube-dns
负责为整个集群提供DNS服务。
- Ingress Controller
为服务提供集群外部访问。
- Heapest/Metries-server
提供集群资源监控,监控容器可以使用Prometheus。
- Dashboard
提供GUI。
- Federation
提供跨可用区的集群。
- Fluented-elasticsearch
提供集群日志采集、存储与查询。
4、安装时可能问题
- 最新版docker可能不支持
- cgroups驱动建议改为systemd
- kubernetes1.8开始需关闭swap
5、名词释义
5.1 标签 label
为node节点添加多维度标签,用于区分不同场景的需要。
打完标签后的node,pod,deployment等资源都可以在标签选择器里进行匹配。
5.2 命名空间 namespace
对一组资源和对象的抽象组合。
namespace常用来隔离不同的用户;而同一种资源的不同版本可直接用label划分。
常见的pod、service、replication controller、deployment等都属于某个namespace;
node、persistent volume、namespace等资源则不属于任何namespace。
5.3 工作负载 workloads
工作负载分为pod和controllers。pod与controller之间通过label-selector相关联,是唯一的关联方式。
- pod通过controller实现应用的运行、伸缩、升级
- controller在集群中管理pod
5.4 pod
KubernetesPods是有生命周期的。他们可以被创建,而且销毁不会再启动。 如果您使用Deployment来运行您的应用程序,则它可以动态创建和销毁 Pod。
pod是kubernetes最小的管理单位,一个pod可以封装一个或多个容器;一个pod里的多个容器可以共享存储和网络,可以看作一个逻辑主机;多个容器共享一个network namespace,由此在一个pod里多个容器共享pod的端口和IP namespace,所以可通过localhost通信,注意不要端口冲突。
pod的label用于controller关联控制pod;node的label用于将pod调度到指定label的node节点。
5.4.1 pod分类
-
无控制器管理的自主式pod没有副本控制器控制,删除后不会自主创建
-
有控制器管理的pod|控制器按定义的策略控制pod,自动创建,自动删除
5.4.2 pod调度方法
nodename用于将pod调度到指定node上;nodeselector用于将pod调度到匹配label的node上。
5.4.3 pod的生命周期
pod的生命周期是从pod创建到终止。
- health check(健康检查)
- liveness probe:检查主容器存活状态(不健康按重启策略重启pod)
- readyness probe:检查主容器是否启动(不健康pod被设为Notready)
- 容器重启策略
- Always(默认策略):容器挂了总会重启
- OnFailures:容器状态错误时才会重启,正常终止不重启
- Never:容器挂掉永不重启
5.4.4 pod控制器
- ReplicaSet: 代用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能。
ReplicaSet主要三个组件组成:
(1)用户期望的pod副本数量
(2)标签选择器,判断哪个pod归自己管理
(3)当现存的pod数量不足,会根据pod资源模板进行新建
帮助用户管理无状态的pod资源,精确反应用户定义的目标数量,但是RelicaSet不是直接使用的控制器,而是使用Deployment。 - Deployment:工作在ReplicaSet之上,用于管理无状态应用[1],目前来说最好的控制器。支持滚动更新和回滚功能,还提供声明式配置。
- DaemonSet:用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统级后台任务。比如ELK服务
特性:服务是无状态的
服务必须是守护进程 - Job:只要完成就立即退出,不需要重启或重建。
- Cronjob:周期性任务控制,不需要持续后台运行,
- StatefulSet:管理有状态应用
5.5 service
5.5.1 service含义
一个Kubernetes的Service是一种抽象,它定义了一组Pods的逻辑集合和一个用于访问它们的策略 - 有的时候被称之为微服务。一个Service的目标Pod集合通常是由Label Selector 来决定的(下面有讲一个没有选择器的Service 有什么用处)。
举个例子,想象一个处理图片的后端运行了三个副本。这些副本都是可以替代的 - 前端不关心它们使用的是哪一个后端。尽管实际组成后端集合的Pod可能会变化,前端的客户端却不需要知道这个变化,也不需要自己有一个列表来记录这些后端服务。Service抽象能让你达到这种解耦。
不像 Pod 的 IP 地址,它实际路由到一个固定的目的地,Service 的 IP 实际上不能通过单个主机来进行应答。 相反,我们使用 iptables(Linux 中的数据包处理逻辑)来定义一个虚拟IP地址(VIP),它可以根据需要透明地进行重定向。 当客户端连接到 VIP 时,它们的流量会自动地传输到一个合适的 Endpoint。 环境变量和 DNS,实际上会根据 Service 的 VIP 和端口来进行填充。
kube-proxy支持三种代理模式: 用户空间,iptables和IPVS;它们各自的操作略有不同。
- Userspace
作为一个例子,考虑前面提到的图片处理应用程序。 当创建 backend Service 时,Kubernetes master 会给它指派一个虚拟 IP 地址,比如 10.0.0.1。 假设 Service 的端口是 1234,该 Service 会被集群中所有的 kube-proxy 实例观察到。 当代理看到一个新的 Service, 它会打开一个新的端口,建立一个从该 VIP 重定向到新端口的 iptables,并开始接收请求连接。
当一个客户端连接到一个 VIP,iptables 规则开始起作用,它会重定向该数据包到 Service代理 的端口。 Service代理 选择一个 backend,并将客户端的流量代理到 backend 上。
这意味着 Service 的所有者能够选择任何他们想使用的端口,而不存在冲突的风险。 客户端可以简单地连接到一个 IP 和端口,而不需要知道实际访问了哪些 Pod。
- iptables
再次考虑前面提到的图片处理应用程序。 当创建 backend Service 时,Kubernetes 控制面板会给它指派一个虚拟 IP 地址,比如 10.0.0.1。 假设 Service 的端口是 1234,该 Service 会被集群中所有的 kube-proxy 实例观察到。 当代理看到一个新的 Service, 它会配置一系列的 iptables 规则,从 VIP 重定向到 per-Service 规则。 该 per-Service 规则连接到 per-Endpoint 规则,该 per-Endpoint 规则会重定向(目标 NAT)到 backend。
当一个客户端连接到一个 VIP,iptables 规则开始起作用。一个 backend 会被选择(或者根据会话亲和性,或者随机),数据包被重定向到这个 backend。 不像 userspace 代理,数据包从来不拷贝到用户空间,kube-proxy 不是必须为该 VIP 工作而运行,并且客户端 IP 是不可更改的。 当流量打到 Node 的端口上,或通过负载均衡器,会执行相同的基本流程,但是在那些案例中客户端 IP 是可以更改的。
- IPVS
在大规模集群(例如10,000个服务)中,iptables 操作会显着降低速度。 IPVS 专为负载平衡而设计,并基于内核内哈希表。 因此,您可以通过基于 IPVS 的 kube-proxy 在大量服务中实现性能一致性。 同时,基于 IPVS 的 kube-proxy 具有更复杂的负载平衡算法(最小连接,局部性,加权,持久性)。
5.5.2 service原理
通过iptables或IPVS实现底层流量转发和负载均衡。
5.5.3 service作用
- 通过service为pod客户端提供访问pod的方法
- 通过label动态感知pod的IP地址变化等
- 定义pod的访问策略,防止pod失联
- 通过service实现pod负载均衡
5.5.4 service四种类型:
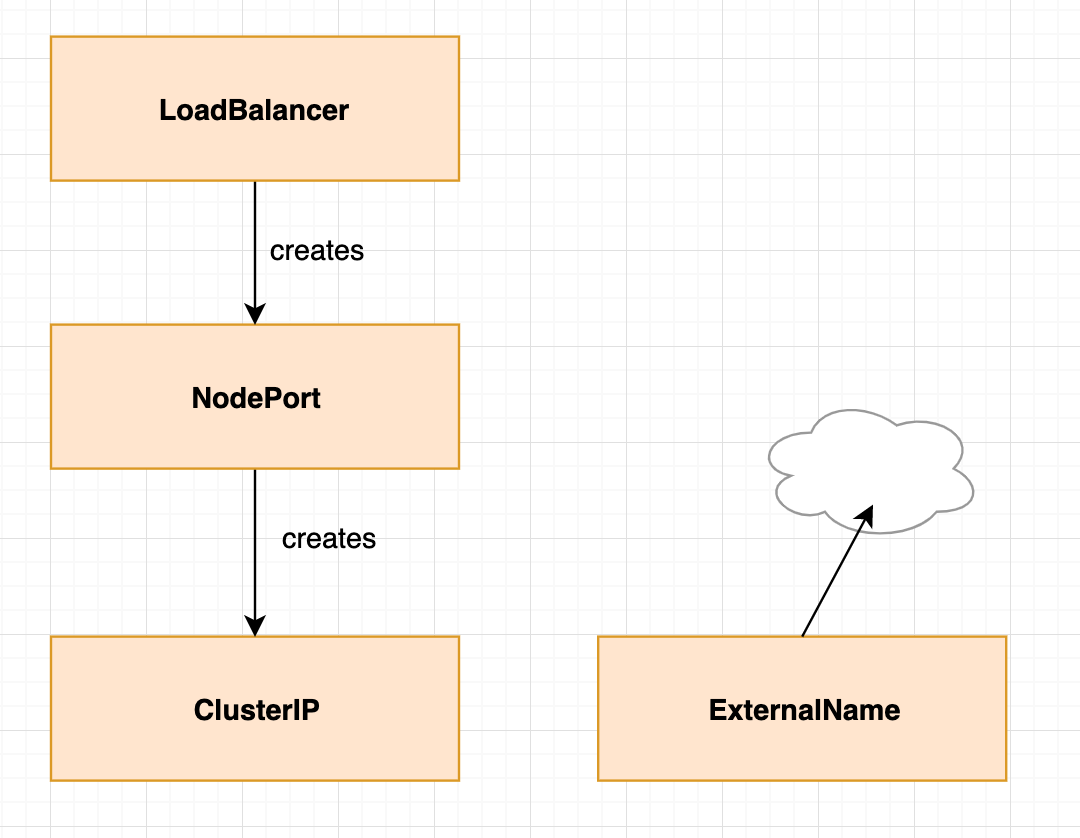
5.5.4.1 ClusterIp类型
默认类型,每个Node分配一个集群内部的Ip,内部可以互相访问,外部无法访问集群内部。
ClusterIP还可以细分为是否生成ClusterIP:
- 普通service:分配一个集群内部可访问的固定虚拟IP(ClusterIP),实现集群内部访问
- Headless service:通过DNS提供稳定的网络ID来访问,DNS将headless service后端直接解析为pod IP的列表
创建ClusterIP的Service yaml如下:
apiVersion: v1
kind: Service
metadata:
name: service-python
spec:
ports:
- port: 3000
protocol: TCP
targetPort: 443
selector:
run: pod-python
type: ClusterIP
使用 kuebctl get svc :
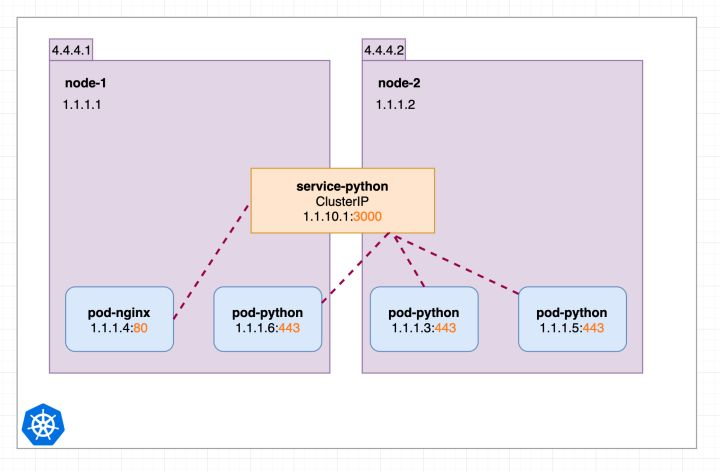
类型为ClusterIP的service,这个service有一个Cluster-IP,其实就一个VIP。具体实现原理依靠kubeproxy组件,通过iptables或是ipvs实现。
这种类型的service 只能在集群内访问。

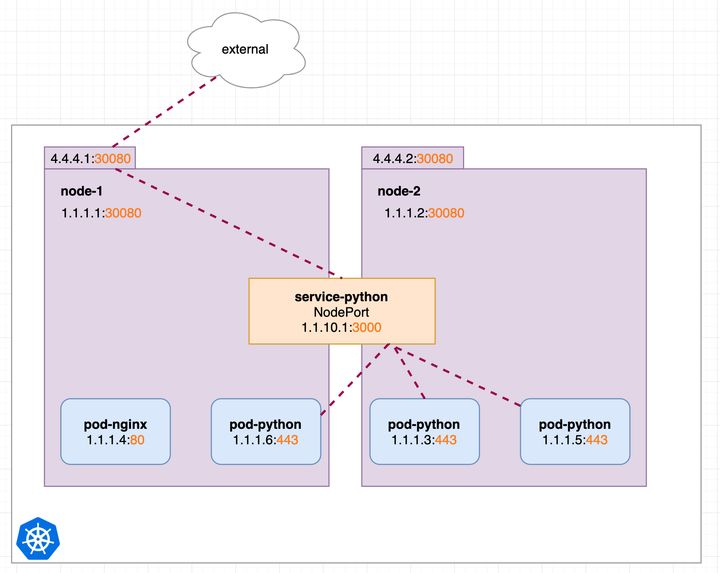
5.5.4.2 NodePort类型
基于ClusterIp,另外在每个Node上开放一个端口,可以从所有的位置访问这个地址。
我们的场景不全是集群内访问,也需要集群外业务访问。那么ClusterIP就满足不了了。NodePort当然是其中的一种实现方案。
创建NodePort 类型service 如下:
apiVersion: v1
kind: Service
metadata:
name: service-python
spec:
ports:
- port: 3000
protocol: TCP
targetPort: 443
nodePort: 30080
selector:
run: pod-python
type: NodePort
使用 kuebctl get svc :

此时我们可以通过http://4.4.4.1:30080或http://4.4.4.2:30080 对pod-python访问。该端口有一定的范围,比如默认Kubernetes 控制平面将在--service-node-port-range标志指定的范围内分配端口(默认值:30000-32767)。
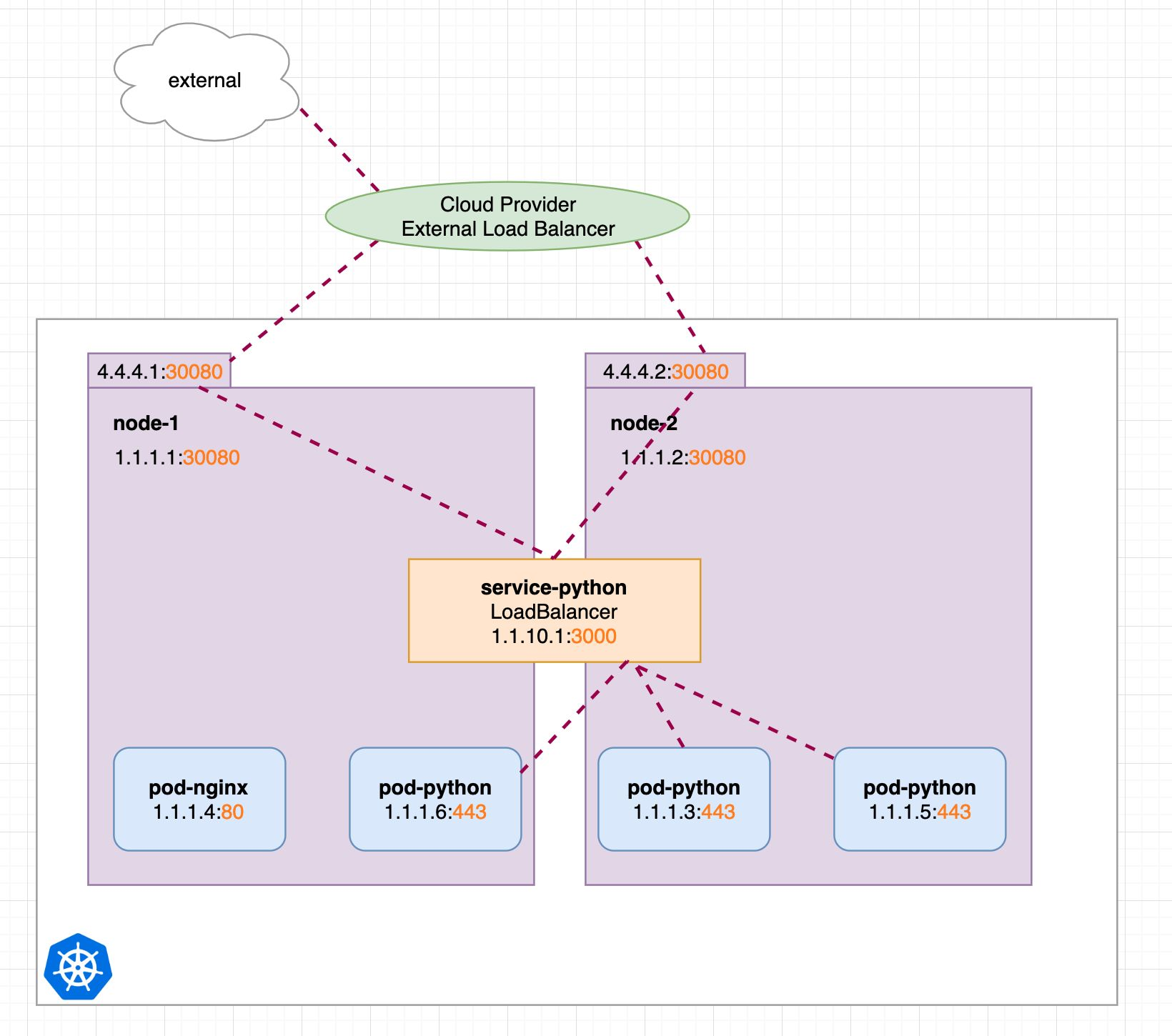
5.5.4.3 LoadBalance类型
基于NodePort,并且有云服务商在外部创建了一个负载均衡层,将流量导入到对应Port。要收费的。
LoadBalancer类型的service 是可以实现集群外部访问服务的另外一种解决方案。不过并不是所有的k8s集群都会支持,大多是在公有云托管集群中会支持该类型。负载均衡器是异步创建的,关于被提供的负载均衡器的信息将会通过Service的status.loadBalancer字段被发布出去。
创建 LoadBalancer service 的yaml 如下:
apiVersion: v1
kind: Service
metadata:
name: service-python
spec:
ports:
- port: 3000
protocol: TCP
targetPort: 443
nodePort: 30080
selector:
run: pod-python
type: LoadBalancer
使用 kuebctl get svc :

可以看到external-ip。我们就可以通过该ip来访问了。
当然各家公有云支持诸多的其他设置。大多是公有云负载均衡器的设置参数,都可以通过svc的注解来设置,例如下面的aws:
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-access-log-enabled: "true"
# Specifies whether access logs are enabled for the load balancer
service.beta.kubernetes.io/aws-load-balancer-access-log-emit-interval: "60"
# The interval for publishing the access logs. You can specify an interval of either 5 or 60 (minutes).
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-name: "my-bucket"
# The name of the Amazon S3 bucket where the access logs are stored
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-prefix: "my-bucket-prefix/prod"
# The logical hierarchy you created for your Amazon S3 bucket, for example `my-b
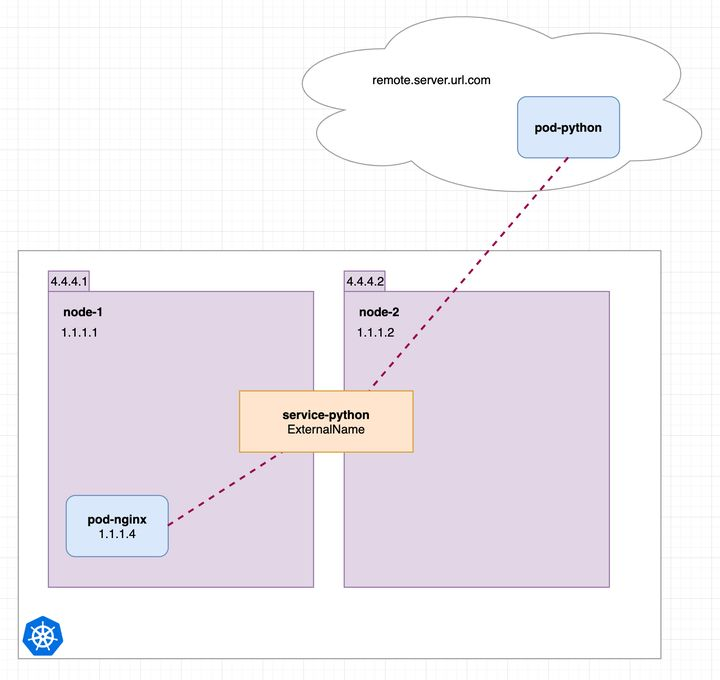
5.5.4.4 ExternalName类型
说明:您需要 CoreDNS 1.7 或更高版本才能使用
ExternalName类型。
将外部地址经过集群内部的再一次封装(实际上就是集群DNS服务器将CNAME解析到了外部地址上),实现了集群内部访问即可。例如你们公司的镜像仓库,最开始是用ip访问,等到后面域名下来了再使用域名访问。你不可能去修改每处的引用。但是可以创建一个ExternalName,首先指向到ip,等后面再指向到域名。所有需要访问仓库的地方,统一访问这个服务即可。
类型为 ExternalName 的service将服务映射到 DNS 名称,而不是典型的选择器,例如my-service或者cassandra。 您可以使用spec.externalName参数指定这些服务。
创建 ExternalName 类型的服务的 yaml 如下:
kind: Service
apiVersion: v1
metadata:
name: service-python
spec:
ports:
- port: 3000
protocol: TCP
targetPort: 443
type: ExternalName
externalName: remote.server.url.com
当查找主机 service-python.default.svc.cluster.local时,集群DNS服务返回CNAME记录,其值为my.database.example.com。 访问service-python的方式与其他服务的方式相同,但主要区别在于重定向发生在 DNS 级别,而不是通过代理或转发。
将生产工作负载迁移到Kubernetes集群并不容易。大多数我们不可以停止所有服务并在Kubernetes集群上启动它们。有时,尝试迁移轻量且不会破坏你服务的服务是很好的。在此过程中,一个可能不错的解决方案是使用现有的有状态服务(例如DB),并首先从无状态容器开始。
从Pod中访问外部服务的最简单正确的方法是创建ExternalName service。例如,如果您决定保留AWS RDS,但您还希望能够将MySQL容器用于测试环境。让我们看一下这个例子:
kind: Service
apiVersion: v1
metadata:
name: test-service
namespace: default
spec:
type: ExternalName
externalName: test.database.example.com
你已将Web应用程序配置为使用URL测试服务访问数据库,但是在生产集群上,数据库位于AWS RDS上,并且具有以下URL test.database.example.com。创建ExternalName service 并且你的Web Pod尝试访问test-service上的数据库之后,Kubernetes DNS服务器将返回值为test.database.example.com的CNAME记录。问题解决了。
ExternalName service 也可以用于从其他名称空间访问服务。例如:
kind: Service
apiVersion: v1
metadata:
name: test-service-1
namespace: namespace-a
spec:
type: ExternalName
externalName: test-service-2.namespace-b.svc.cluster.local
ports:
- port: 80
在这里,我可以使用名称空间a中定义的test-service-1访问命名空间b中的服务
test-service-2。
这个意义在哪里?
ExternalName service 也是一种service,那么ingress controller 会支持,那么就可以实现跨namespace的ingress。
6、kubernetes面试
6.1 问题:什么方式部署的k8s?需要注意什么?有哪些组件?
kubeadm方式、原生方式
注意环境统一,kubeadm软件安装时注意docker版本,最新版k8s不一定支持,kubeadm初始化时可能出现驱动检测警告,cgroups的驱动建议为systemd,还有k8s集群实际需要物理机的内存做支撑,所以kubernetes1.8后要关闭swap,否则会报错。
master组件:kube-scheduler、kube-apiserver、etcd、kube-controller-manager、cloud-controller-manager
node组件:kubelet、kube-proxy、docker、supervisord、fluentd
6.2 问题:kubernetes service有哪几种类型?同一集群内各微服务之间使用哪种方式相互调用?
NodePort、ClusterIP、LoadBalance、ExrernalName
label、erueka
6.3 ConfigMap和Secret是什么?区别是什么?pod如何使用ConfigMap?有几种使用方法?
ConfigMap可看作是一个挂载到pod中的存储卷,k8s集群可以使用ConfigMap来实现对容器中应用的配置管理。
Secret与ConfigMap类似,区别是Secret存储的是密文,ConfigMap但是明文。
所以ConfigMap可用作配置文件管理,而Secret可用于密码、秘钥、token等配置管理。
pod使用ConfigMap的使用方式:
- 直接在命令行中指定ConfigMap参数创建 (
--from-literal=key-value) - 通过指定配置文件创建,将一个配置文件创建为ConfigMap(
--from-fiel=文件路径) - 通过一个文件内多个键值对(
--from-env-file=文件路径) - 通过
kubectl create/apply -f yaml文件
两种使用方法:通过环境变量传递给pod或通过volume挂载到pod内。
6.4 Deployment和DaemonSet是什么?有什么区别?还有什么编排类型?
Deployment是一个集成了上线部署,滚动升级,创建副本等功能的控制器。
Deployment包含了ReplicaSet,多用于部署无状态应用。
DaemonSet只管理pod对象,通过nodeAffinity(喜好)和Toleration(容忍)两个调度器,保证每个节点上只有一个pod。若集群动态加入了新node,DaemonSet中的pod也会添加在新加node上,删除DaemonSet也会级联删除所有其创建的pod。DaemonSet确保全部(或某些)节点运行一个pod副本,当有节点加入集群会为节点新增pod,移除时pod会被回收,其典型应用场景为:①每个几点运行日志收集服务②每个节点运行监控服务③每个节点运行网络插件、存储插件。
区别:
- 在使用部署时,可伸缩性较好,因为DaemonSet是单节点单pod模式(Single-Pod-Per-Node)
- DaemonSet可以在一组专有机器上用污点和容忍运行一个service
- DaemonSet允许直接访问任何节点的80/443端口,Deployment必须设置个service对象
编排类型:Job、Crontab、StatefulSet
6.5 如何做数据持久化?PV、PVC、volumes、volumeMounts代表什么?
数据持久化依赖PV-PVC概念,创建PV卷(不属于任何namespace,能限制大小、读写权限),在对应namespace下创建PVC。然后kubectl apply创建PV,PVC,最后应用PVC,方便限制每个PVC子目录,若nfs迁移,改PV的url就好了。
Persistent Volume(PV)是集群之中的一块网络存储。跟 Node 一样,也是集群的资源。PV 跟 Volume (卷) 类似,不过会有独立于 Pod 的生命周期。这一 API 对象包含了存储的实现细节,例如 NFS、iSCSI 或者其他的云提供商的存储系统。Persistent Volume Claim (PVC) 是用户的一个请求。跟 Pod 类似,Pod 消费 Node 的资源,PVC 消费 PV 的资源。Pod 能够申请特定的资源(CPU 和内存);Claim 能够请求特定的尺寸和访问模式(例如可以加载一个读写,以及多个只读实例)。
6.6 如何做资源限制
在linux中,Cgroups给用户暴露出来的操作端口是文件系统,即它以文件和目录的方式组织在操作系统的/sys/fs/cgroups。
docker的资源限制也是如此,它在每个子系统下面为每个容器创建一个控制组(创建一个新目录),然后在启动容器进程后把这个进程的PID填到对应控制组的tasks文件中,具体要求控制的需要命令docker run -ti $要控制的参数 容器名 bin/bash。
6.7 什么是污点、亲和性?如何做pod调度?
希望把master节点保留给kubernetes系统组件使用,或者把一组具有特殊资源预留给某些pod时需要污点。pod就不会被调度到taint污点标记过的节点。使用kubeadm搭建的集群默认就给master节点添加了一个污点标记,由于master节点被标记了污点,所以想要pod能被调度到master上就要加容忍声明。
调度要通过nodename或nodeselector。
nodename用于将pod调度到指定的node上;nodeselector用于将pod调度到匹配label的node上。
6.8 kubernetes集群中出现网络不通如何解决?
- pod网络初始化集群时尽量避免使用C类地址(192.168段),容易造成路由冲突
- harbor最好单独使用一台服务器,kubernetes复用docker会造成IP错误导致pod网络不通
- 查看网关、路由、防火墙
6.9 kubernetes两台宿主机上的两台pod网络不通如何解决?
- 跨主机访问容器没有有效的路由,多个节点上的容器网段冲突
- 查看网关、路由、防火墙
6.10 flannel网络的支持几种模式?
- UDP模式(性能最差),通过TUN设备flannel 0实现
- UDP模式的主要功能:在操作系统的内核和用户应用程序之间传递IP包
- vxlan模式(性能较好)
- vxlan是虚拟可扩展局域网,是linux本身支持的一种网络虚拟技术
- vxlan可以在内核态实现封装和解封装工作,从而通过隧道机制构建出覆盖网络(overlay network)
- host-gw模式(性能最好)
- host-gw工作原理:flannel子网下一跳设置成该子网对应的宿主机IP地址,也就是说宿主机充当了这个容器通信路径的网关
6.11 kubernetes的三种外部访问方式
nodeport,loadbalance,ingress
- nodeport服务:引导外部流量到服务器
- 在所有节点(虚拟机)上开放一个特定端口,任何发送到该端口的流量都被转发到对应服务(大多数时候让kubernetes来选择端口)
- loadbalance服务:暴露服务到Internet的标准方式
- loadbalance会启动一个Network Load Balance,将给你一个独立的IP地址,转发所有的流量到你的服务(默认)
- 缺点:每一个用loadbalance暴露的服务都有自己的IP地址,成本高
- ingress服务
- 处在多个服务的前端,ingress控制器是启动一个HTTP(S)loadbalance。它允许你基于路径或子域名来路由流量到后端服务
无状态应用:所有pod无差别,使用同一个image,可运行在任意node上,随意扩容、裁剪pod数量 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号