Python自动化学习笔记(五)——函数(传参、参数类型)、全局变量、常用模块(json模块、os模块、time模块)
1.函数
1.1 return的作用
- 把函数处理结果返回
- 结束函数,函数里面遇到return立马结束
1.2 return包含多个值
返回多个值时,系统用一个元组来接收多个返回值,示例如下:
1 def get_user(): 2 s='abc,123' 3 username,password=s.split(',') 4 return username,password 5 6 a=get_user() 7 print(a)
输出结果为:('abc', '123'),a的类型为一个元组
1.3函数的参数类型详解
位置参数、默认参数、可变参数、关键字参数
- 必填参数,位置参数,必传
- 默认值参数,非必传,默认参数调用的时候,既可以按顺序提供默认参数,也可以不按顺序提供部分默认参数。当不按顺序提供部分默认参数时,需要把参数名写上
- 可变参数,非必传,允许传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。形参使用*args形式
- 关键字参数,非必传,允许传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。形参使用**args形式,传参的时候必须得用k=v这种形式来传
一个默认参数的函数例子
1 #一个读写文件的函数,传入content则写入,不传则读取文件 2 def op_file(filename,content=None): 3 with open(filename,'a+',encoding='utf-8') as fw: 4 fw.seek(0) #移动文件指针 5 if content: 6 fw.write(content) #指针移动到文件头部,还是会追加到文件末尾 7 else: 8 return fw.read()
一个可变参数的函数例子
1 def mysql2(*info): 2 print(info) 3 mysql2() #转为一个空元组传入 4 #mysql2(user='root') #调用方法错误 5 mysql2('root',123) #输出('root', 123),转为元组传入函数 6 info=[1,2] 7 mysql2(*info) #将list中的元素拆开传入函数,输出(1,2) 8 9 def calc(a,b): #只有位置参数的函数 10 print(a+b) 11 return a+b 12 l=[1,2] 13 calc(*l) #也可以这样传参,将list中的元素拆开传入函数,输出3
一个关键字参数的函数例子
1 def mysql(**mysql_info): 2 print(mysql_info) 3 4 mysql() #传入一个空字典,输出为{} 5 #mysql('ip','user') #错误传入方式 6 mysql(ip='ip',user='user') #关键字形式传入,输出{'ip': 'ip', 'user': 'user'} 7 8 info={'ip':'ip1','user':'user1'} 9 mysql(**info) #字典拆开再传入,输出{'ip': 'ip1', 'user': 'user1'} 10 11 def mysql1(ip,user):#只有位置参数的函数 12 print(ip,user) 13 mysql1(**info) #也可以这样传参,字典拆开再传入字典的value,输出ip1 user1
一个同时包含位置参数和关键字参数的例子
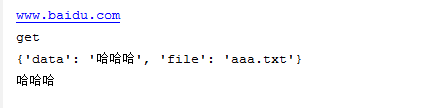
1 def request(url,method,**info): #位置参数和关键字参数都有的函数 2 print(url) 3 print(method) 4 print(info) 5 if info.get('data'): #关键字参数中是否传入data这个参数 6 data=info.get('data') 7 print(data) 8 request('www.baidu.com','get',data='哈哈哈',file='aaa.txt')
输出结果:
2.全局变量
应该尽量避免使用全局变量。不同的模块都可以自由的访问全局变量,容易出错。全局变量降低了代码的可读性,并且一直占用内存
代码示例:
1 name='小明' #字符串类型的全局变量 2 stus=[] #全局变量是list、字典、集合时,修改时不需要声明global 3 def a(): 4 name='哈哈哈' 5 print(name) #局部变量,不影响全局name的值,调用函数输出‘哈哈哈’ 6 7 def c(): 8 global name #声明name是全局的 9 stus.append('abc') #全局变量是list,没有声明global也可以修改,在函数外部打印stus会输出['abc'] 10 name='哈哈哈' #声明后修改全局变量的值 11 print(name) #调用函数输出‘哈哈哈’
3.常用内置模块
3.1 json模块
四个常用方法:
- dic=json.loads(json_str) #把字符串(json串)转成字典,传入一个json格式的字符串,返回一个字典
- str=json.dumps(dic,ensure_ascii=False) #把字典转成json串(字符串),传入一个字典,返回一个json格式的字符串;ensure_ascii=False意思是不进行ascii编码,如果省略此参数,字符串中的中文将是ASCII编码后的
- dic=json.load(f) #直接从文件里读出来json再转成字典返回,传入f为文件句柄,返回一个字典
- json.dump(dic,f,ensure_ascii=False,indent=4) #直接将字典按json格式写入文件,不需要先转成json,返回None,传入一个字典dic和文件句柄f,并按照缩进四格来格式化
loads方法示例代码
1 import json 2 json_str=''' 3 {"name":"xiaohei","age":18,"sex":"男","age":18} 4 ''' 5 res=json.loads(json_str) #把字符串(json串)转成字典 6 print(res)
输出:

dumps方法示例代码
1 import json 2 dic={"name":"xiaohei","age":18,"sex":"男","age":18} 3 #把字典转成json串(字符串) 4 res=json.dumps(dic,ensure_ascii=False,indent=4) #把字典转成json串(字符串) 5 print(res)
输出:

load&dump方法示例代码


1 import json 2 dic = { 3 "xiaohei":{ 4 "age":18, 5 "password":12345, 6 "sex":"男", 7 "addr":"北京" 8 }, 9 "xiaoming":{ 10 "age":18, 11 "password":12345, 12 "sex":"男", 13 "addr":"北京" 14 }, 15 "xiaodong":{ 16 "age":18, 17 "password":12345, 18 "sex":"男", 19 "addr":"北京" 20 } 21 } 22 #直接从文件里读出来json再转成字典返回 23 with open('user_new.json',encoding='utf-8') as f: 24 res=json.load(f) 25 print(res) 26 27 #直接将字典按json格式写入文件,不需要先转成json 28 with open('user_new.json','w',encoding='utf-8') as fw: 29 res=json.dump(dic,fw,ensure_ascii=False,indent=4)
3.2 os模块
常用方法:
- os.listdir('e:/') #列出目录下的所有文件和文件夹
- os.remove() #删除文件
- os.rename()#重命名文件
- os.mkdir(r'testday5') #创建文件夹 r代表原字符串
- os.makedirs(r'test\testday5') #递归创建,父目录不存在时一起创建
- res=os.path.exists(r'test\testday5') #文件或文件夹是否存在
- res=os.path.isfile(r'test\testday5') #判断是否为文件
- res=os.path.isdir(r'test\testday5') #判断是否为文件夹
- res=os.path.split(r'test\testday5\aa') #将路径和文件名区分开,返回一个包含两个元素的元组
- res=os.path.dirname(r'test\testday5') #获取父目录
- res=os.getcwd() #获取当前目录
- os.chdir('../day5') #切换目录
- print(os.environ) #获取计算机的环境变量
- res=os.path.join('test','abc','a.txt') #拼接路径,不需要指定分隔符
- res=os.path.abspath('..') #根据相对路径获取绝对路径
- res=os.system('ipconfig') #执行操作系统命令,无法获取结果,#命令执行成功返回0,失败返回1
- res=os.popen('ipconfig').read() #执行操作系统命令,并获取结果
3.3 time模块
#格式化好的时间 20181202
#时间戳 计算机诞生的时间到现在过了多少秒
#时间元组 格式化好的时间和时间戳相互转换的媒介
常用方法:
- time.time() #获取当前时间戳
- time.strftime('%Y-%m-%d %H:%M:%S')) #按指定格式获取格式化好的当前时间
- time.gmtime(234466755) #指定时间戳转换为时间元组
- time.gmtime(int(time.time())) #将标准时区的当前时间戳转换为时间元组
- time.localtime(int(time.time())) #将当前时区的当前时间戳转换为时间元组
- time.strftime('%Y-%m-%d %H:%M:%S',time1) #时间元组time1转成格式化时间,不传时间元组,则转换当前时间
- time.strptime('20181023153856','%Y%m%d%H%M%S') #格式化时间先转成时间元组
- time.mktime(timep) #时间元组转为时间戳
- time.sleep(seconds) #程序休眠几秒
代码示例,时间戳和格式化时间相互转换的两个函数:
1 import os 2 #时间戳转格式化时间 3 def timestampToStr(timestamp=None,format='%Y-%m-%d %H:%M:%S'): 4 if timestamp: #传入timestamp,则转换指定的时间戳 5 time1=time.gmtime(timestamp) #时间戳转换为时间元组, 6 res = time.strftime(format, time1) # 时间元组转成格式化时间 7 8 else: #没有传入timestamp,默认返回格式化好的当前时间 9 res = time.strftime(format) # 获取当前格式化的时间 10 return res 11 12 #格式化时间转时间戳 13 def strTotimestamp(str=None,format='%Y-%m-%d %H:%M:%'): 14 if str: #传入时间,则转换指定的时间 15 timep = time.strptime(str, format) # 格式化时间先转成时间元组 16 res = time.mktime(timep) 17 else: #没有传入时间,默认返回当前的时间戳 18 res=time.time() #获取当前时间戳 19 return int(res)
4.列表生成式,浅拷贝,深拷贝,了解一下
4.1列表生成式
1 s=[1,2,3,4,5] 2 for i in s: 3 print(i+1) 4 5 res=[i+1 for i in s] 6 print(res) #等同于上面2.3行的循环,[[i+1 for i in s]]被称为列表生成式,可以使代码更简洁
4.2浅拷贝&深拷贝
#浅拷贝:两个变量指向同一块内存地址:
list1=[1,2]
list2=list1 #两个变量的内存地址一致,修改list2时,list1的值也会修改,本质上其实是一个变量
#深拷贝:开辟一块新的内存地址
list1=[1,2]
list2=list[:]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号