


Python词云作业
Python词云作业
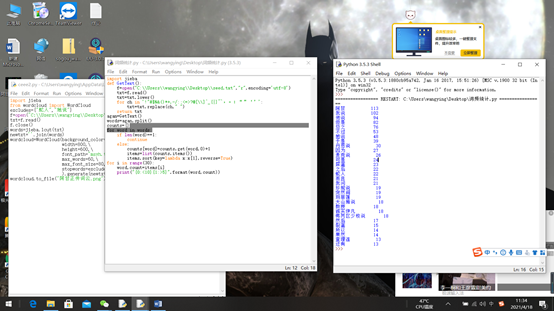
词频统计代码如下
import jieba
def GetText():
f=open("C:\\Users\\wangying\\Desktop\\seed.txt","r",encoding='utf-8')
txt=f.read()
txt=txt.lower()
for ch in '!"#$%&()*+,-/:;<=>?@[\\]^_{|}~`,。:“”‘’':
txt=txt.replace(ch," ")
return txt
agan=GetText()
words=agan.split()
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(30):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
词云生成代码如下
import jieba
from wordcloud import WordCloud
excludes={"但是","她说","总之",'之后','不过','而且','还有','然后','果然'}
f=open("C:\\Users\\wangying\\Desktop\\seed.txt","r",encoding='utf-8')
txt=f.read()
f.close()
words=jieba.lcut(txt)
newtxt=''.join(words)
wordcloud=WordCloud(background_color="black",\
width=800,\
height=600,\
font_path="msyh.ttc",\
max_words=60,\
max_font_size=80,\
stopwords=excludes,\
).generate(newtxt)
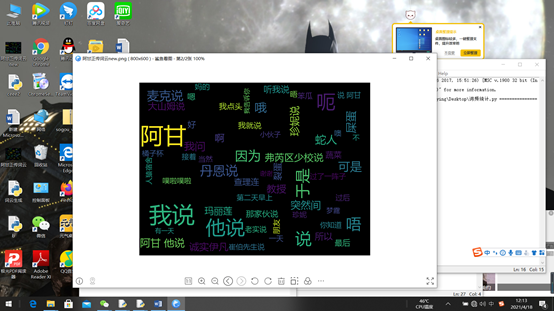
wordcloud.to_file("阿甘正传词云new.png")
操作步骤
一.安装jieba库和Wordcloud库
.使用pip方法安装
找到Python的scrip路径后复制在我的电脑属性环境设置中加入
在互联网上搜索国内的jieba库和Wordcloud库下载地址
复制在cmd中按下回车键开始下载
下载完成后即成功安装jieba库和Wordcloud库
二.使用jieba库进行词频统计
1.在互联网上复制阿甘正传这本小说的部分文本并保存于记事本中
2.参考Python语言程序设计这本书上词频统计的内容在Python 的idle中输入代码如上
3.F5运行后得到出现较多的词汇如图中所示
三.使用jieba库和Wordcloud库进行词云的生成
1.参考Python语言程序设计这本书上关于词云的内容并在Python的idle上输入代码如上
2将idle文件保存于桌面
3F5运行后在桌面得到词云图如图所示
过程中的问题及解决方法
一.开始使用cmd时显示无pip指令
上网搜索后将Python的scrip路径加入到我的电脑的属性的环境中后解决
二.使用pip下载jieba库和Wordcloud库过慢
由于pip中直接下载的库来自国外所以需找到国内库的网址下载
三.下载Wordcloud库时无法成功安装
由于pip版本过低导致,更新pip版本后,再下载Micosoftc++的最新版本后即可安装
四.用Python打开文件后无法读取
这是由于编码不匹配导致的,在open函数后加上encoding=utf-8后该问题解决
词云图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号