C#AI系列(2):深度学习项目构建及实战TorchSharp准备篇
TorchSharp 是 .NET 基金会官方出品的深度学习库,将 PyTorch 的 C++ 核心 LibTorch 封装成 C#/F# API,且极大程度的保留 Python 般的开发手感。从张量运算、自动求导到模型构建、训练与推理,接口语义与 PyTorch 几乎是都能对应。
在上一篇我们说到了在TensorFlow.Net搭建机器学习模型的案例。尽管TorchSharp和TensorFlow功能相似,但很多地方写法和习惯会有区别,下面我们尝试从头开始使用TorshSharp做一个对向量分类进行训练和预测的神经网络。感兴趣的可以和TensorFlow.Net的搭建方式做一个对比。
更加完整丰富的机器学习模型案例的代码已全部开源,关注公众号回复AISharp即可查看仓库地址。
一、组件环境准备
开始之前,我们准备好依赖项,去nuget里拉取TorchSharp-cpu和TorchSharp两个组件,其中一个是本地代码库,另一个是c# 语言对其调用以及高级功能的封装。
| 包名 | 含义与作用 |
|---|---|
TorchSharp-cpu |
一个包内集成了 Native 本地代码库 和针对 CPU及多平台 (Windows, Linux, macOS) 的支持。 |
TorchSharp |
主要的 C# API 封装,提供与 PyTorch 设计哲学一致的核心张量操作与模型构建功能。 |
二、核心代码组成-TorchSharp
2.1 数据准备
假设问题:在二维平面坐标系的原点绘制一个半径为5的圆,希望创建一个模型判定目标点是位于圆的内部还是外部。
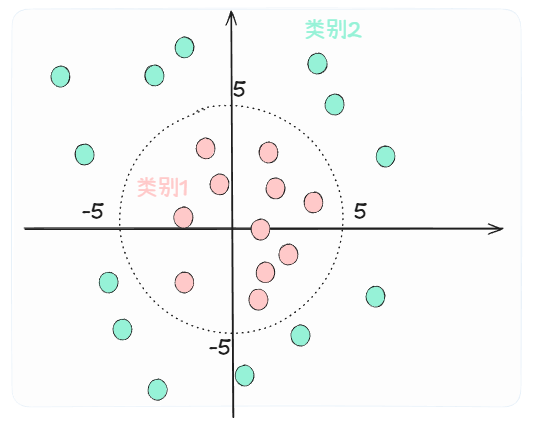
TorchSharp主要使用的数据对象类型是Tensor(反而TensorFlow使用的却叫NDArray)。我们首先生成一些随机数据作为训练集,并合并成输入、输出两个Tensor。
// 生成数据
// 1. 生成圆形边界二分类数据
int samplesPerClass = 1000;
float radius = 5.0f; // 圆的半径
List<Tensor> innerPoints = new List<Tensor>();
List<Tensor> outerPoints = new List<Tensor>();
// 生成数据点
for (int i = 0; i < samplesPerClass * 2; i++)
{
// 在 [-10, 10] 范围内随机生成点
float pt_x = (float)(new Random().NextDouble() * 20 - 10);
float pt_y = (float)(new Random().NextDouble() * 20 - 10);
// 计算到原点的距离
float distance = (float)Math.Sqrt(pt_x * pt_x + pt_y * pt_y);
if (distance < radius)
{
// 圆内点 -> 类别0
innerPoints.Add(torch.tensor(new float[] { pt_x, pt_y }));
}
else
{
// 圆外点 -> 类别1
outerPoints.Add(torch.tensor(new float[] { pt_x, pt_y }));
}
// 如果已经收集够样本,就退出
if (innerPoints.Count >= samplesPerClass && outerPoints.Count >= samplesPerClass)
break;
}
// 合并所有数据
// 确保两类样本数量平衡(取较小的数量)
int minCount = Math.Min(innerPoints.Count, outerPoints.Count);
innerPoints = innerPoints.Take(minCount).ToList();
outerPoints = outerPoints.Take(minCount).ToList();
// 合并数据
Tensor x_inner = torch.stack(innerPoints.ToArray());
Tensor x_outer = torch.stack(outerPoints.ToArray());
Tensor x = torch.cat([x_inner, x_outer], 0);
// 创建标签:圆内=0, 圆外=1
Tensor y_inner = torch.zeros(minCount, ScalarType.Int64);
Tensor y_outer = torch.ones(minCount, ScalarType.Int64);
Tensor y = torch.cat([y_inner, y_outer], 0);
这样我们就得到了一个输入x存储了点的二维坐标;另一个是y存储了x中对应坐标是位于圆内部还是外部。而且这考虑样本的平衡性,我们另这两个分类数量相等。
2.3 模型构建
TorchSharp模型构建与TensorFlow使用时类似,需要设定网络每一层的结构。对于每层连接、激活函数、以及Dropout等特殊处理,都需要定义一个Module<Tensor, Tensor>对象。每个Module<Tensor, Tensor>对象都自带了forward方法负责将上一层的数据前向的传播到下一层。
对于带权重的线性连接层,使用静态方法Linear()创建,节点层使用激活函数的静态方法如Sigmoid()创建,Dropout层同理使用Dropout()。
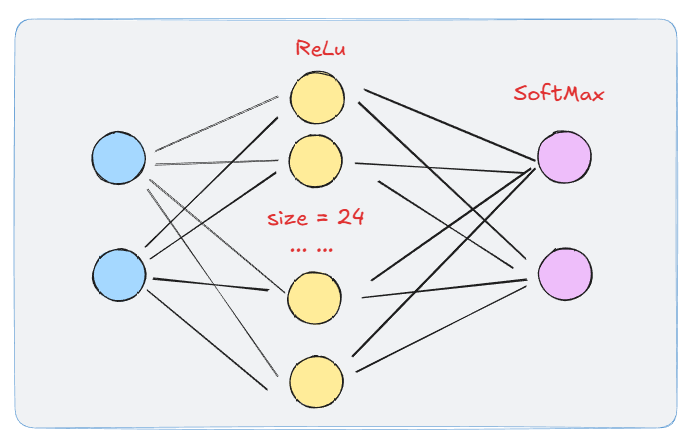
可以手动定义一个序列模型:
var model = Sequential(
Linear(2, 24),
Relu(),
Linear(24, 2),
Softmax(1) // 为了更好分类将各输出拉到概率分布
);
结构所示如下:
或者创建一个类来定义:
// 自定义Module类
public class ClassificationModel_torch : Module<Tensor, Tensor>
{
Module<Tensor, Tensor>? features1 = null;
Module<Tensor, Tensor>? features2 = null;
public ClassificationModel_torch(string modelName): base(modelName)
{
features1 = Sequential(....); //自定义内部featrure1
features2 = Sequential(....); //自定义内部featrure2
RegisterComponents(); //必须加上
}
// 自定义forward结构
public override Tensor forward(Tensor input)
{
var tensorOut1=features1.forward(input);
// 可加入中间层处理
// ...
var tensorOut2=features2.forward(tensorOut1);
return tensorOut2;
}
}
如果采用自定义模型继承的方式构建,那么在模型内部需要调用RegisterComponents()方法。RegisterComponents()是通过反射的机制来实现模型注册的,如果不调用,代码也能正常的运行不会报错,但在某些情况下会出现如epoch完成后梯度不更新等问题。
2.4 模型训练
TorchSharp训练前需要定义优化函数及损失函数。最基础的实现就是自定义循环来跑各个epoch,示意代码如下:
model.train();
var opt = torch.optim.Adam(model.parameters(), lr: 5e-3);
var loss = torch.nn.functional.cross_entropy;
for (int i = 0; i < 4000; i++)
{
// 这的batchsize等价于全部输入
// 要具体实现batchsize训练,可以自定义一个dataLoader来分组
var pred = model.forward(x);
var l = loss(pred, y);
opt.zero_grad();
l.backward();
opt.step();
Console.WriteLine($"Step {i}: loss = {l.ToSingle():F4}");
}
如果需要的话可以在每次训练中打印loss和accuracy习惯信息,训练结果如下:
--- Epoch 1500/1500 ---
Train: epoch 1500 Loss: 0.316395, Accuracy: 99.87%
2.5 模型预测及数据获取
模型训练完成后,我们自定义一些数据来测试下效果:
// 传入之前的模型和要预测的数据
var TestQuadrantPrediction=(Module<Tensor,Tensor> model, float x, float y)=>{
// 创建使用完后主动释放Tensor
using Tensor input = torch.tensor(new float[] { x, y }, new long[] { 1, 2 });
// 不计算梯度
using (no_grad())
{
// 切换到计算模式
// 部分模块在训练和计算时的行为会有差异如 Dropout、BatchNorm 等。
model.eval();
var result = return model.forward(input);
}
}
// 然后我们可以输出分类的概率矩阵,并通过分析该矩阵得到目标的分类
// 对于这类简单问题的预测结果还是比较准确的:
预设位置及坐标:内部,(1, 3.2)=> 预测的位置及分类概率:内部, 概率 [1.000, 0.000]
预设位置及坐标:内部,(-2, 3)=> 预测的位置及分类概率:内部, 概率 [1.000, 0.000]
预设位置及坐标:外部,(-5, -6)=> 预测的位置及分类概率:外部, 概率 [0.000, 1.000]
预设位置及坐标:外部,(7, -1)=> 预测的位置及分类概率:外部, 概率 [0.000, 1.000]
预设位置及坐标:边缘,(0, 5)=> 预测的位置及分类概率:内部, 概率 [0.659, 0.341]
预设位置及坐标:外部,(0, 6)=> 预测的位置及分类概率:外部, 概率 [0.000, 1.000]
预设位置及坐标:外部,(3.5, 4.5)=> 预测的位置及分类概率:外部, 概率 [0.002, 0.998]
训练完成持久化后,后面我们就可以将这个模型整合到我们的代码里去执行其他任务了。
五、最后
以上分享了在C#中基于TorchSharp简单创建一个人工神经网络模型并训练数据预测数据的丰富。其实在C#中用TorchSharp很多地方与python使用Pytorch很像,为了保持一致性,与TensorFlow.Net相似,TorchSharp在大部分的地方也是通过调用静态方法的方式保留了原来函数式的写法。
尽管在C# 的托管环境中运行,但TorchSharp可能仍然需要注意一下内存的管理。TorchSharp内存管理主要有三种方法:
- 依赖.NET垃圾回收机制:最简单但效率最低,仅适用于小模型;
- 通过using语句显式释放资源:性能更好但代码繁琐;
- 利用torch.NewDisposeScope()进行分组式自动释放:兼顾效率与代码简洁性。
当遇到内存问题时,可尝试减小批处理规模,同时注意数据加载器和自定义数据集中张量的生命周期管理,避免意外释放或内存泄漏。
如果你在阅读过程中有任何疑问,或者在实际操作中遇到了困难,欢迎随时与我们交流。我们非常期待听到你的反馈和建议,以便我们能够进一步完善内容,帮助更多开发者。请继续关注我们的公众号“萤火初芒”,我们将持续分享更多有趣且实用的技术内容,与大家一起学习交流,共同进步。
更加完整丰富的机器学习模型案例的代码已全部开源,关注公众号回复AISharp即可查看仓库地址。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号