LeetCode算法题-栈类
1.给定一个二叉树,返回它的中序遍历。
示例:
输入: [1,null,2,3]
1
\
2
/
3
输出: [1,3,2]
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/binary-tree-inorder-traversal
关键点和易错点:
(1)这道题如果用递归来做那么很简单,几行代码即可且很容易理解,难的是怎么用非递归的思想来做,这里有两种非递归的算法来做
(2)使用栈来协助,思想是把节点放到栈里去,由栈来控制节点的输出顺序,我的思想一个节点先push进去,如果有左节点则继续push左节点,一直到没有左节点,然后pop出一个节点,并指向它右节点进行新一轮push判断,如果是空则再pop直到队列为空且没有其它节点了,仔细想想这个过程其实就是左中右的顺序
(3)另外一种难想的算法是莫里斯遍历算法,它的思想是把它变成一个线索二叉树,如下:
1
/ \
2 3
/ \ /
4 5 6
变成
4
\
2
\
5
\
1
\
3
/
6
变化算法:
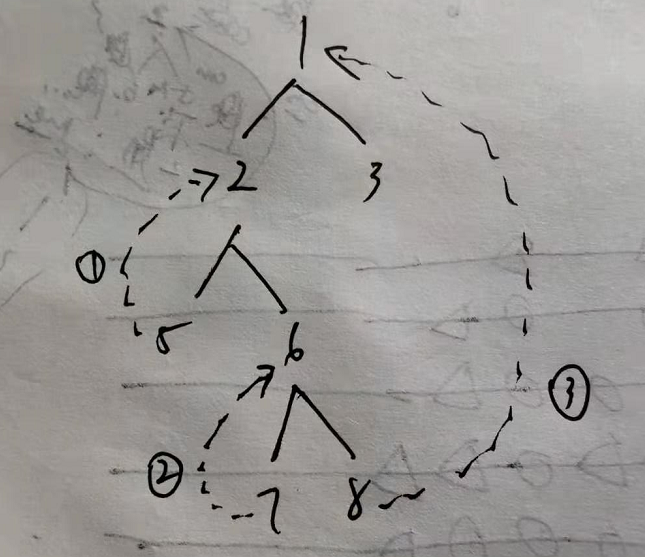
(1)把1置为cur,如果cur有左孩子,则左孩子置为pre,所以2置为pre,然后寻找2的最右节点,比如2个最右节点是5,则pre为5,然后用pre的右孩子指向cur,接着cur被置为2,又开始一轮,就是4指向2,接着cur是4,这时cur没有左孩子了,直接添加到输出列表,且将cur = cur.right,可以看到这时其实是开始回溯了
(2)按(1)这样可以看到其实是有环路的,所以程序里我们会用环路来判断当前是不是出于回溯状态,然后根据这个条件将之前增加的指向(比如之前的5的右孩子指针指向1)置回去,这样便不改变原有树的结构了
以下再给个图,以方便看到这里回溯的思想:
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, x): # self.val = x # self.left = None # self.right = None class Solution(object): def inorderTraversal(self, root): """ :type root: TreeNode :rtype: List[int] """ ret_list = [] stack = [] while root or len(stack) > 0: while root: stack.append(root) root = root.left tmp = stack.pop(-1) ret_list.append(tmp.val) root = tmp.right return ret_list
使用莫里斯遍历的算法:
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, x): # self.val = x # self.left = None # self.right = None class Solution(object): def inorderTraversal(self, root): """ :type root: TreeNode :rtype: List[int] """ ret_list = [] cur = root while cur: if cur.left is None: ret_list.append(cur.val) cur = cur.right else: pre = cur.left while pre.right is not None and pre.right is not cur: pre = pre.right if pre.right is None: pre.right = cur cur = cur.left else: ret_list.append(cur.val) pre.right = None cur = cur.right return ret_list
class Solution(object): def preorderTraversal(self, root): """ :type root: TreeNode :rtype: List[int] """ ret_list = [] stack = [] while root or len(stack) > 0: while root: ret_list.append(root.val) stack.append(root) root = root.left tmp = stack.pop(-1) root = tmp.right return ret_list
使用莫里斯遍历算法(跟之前中序遍历几乎一样,只是改了输出位置):
class Solution(object): def preorderTraversal(self, root): """ :type root: TreeNode :rtype: List[int] """ ret_list = [] cur = root while cur: if cur.left is None: ret_list.append(cur.val) cur = cur.right else: pre = cur.left while pre.right is not None and pre.right is not cur: pre = pre.right if pre.right is None: ret_list.append(cur.val) pre.right = cur cur = cur.left else: pre.right = None cur = cur.right return ret_list
class Solution(object): def postorderTraversal(self, root): """ :type root: TreeNode :rtype: List[int] """ ret_list = [] stack = [] right_stack = [] while root or len(stack) > 0: while root: stack.append(root) root = root.left tmp = stack.pop(-1) if tmp.right: right_stack_len = len(right_stack) if right_stack_len > 0 and right_stack[right_stack_len-1] is tmp: ret_list.append(right_stack.pop(-1).val) else: right_stack.append(tmp) stack.append(tmp) root = tmp.right else: ret_list.append(tmp.val) return ret_list
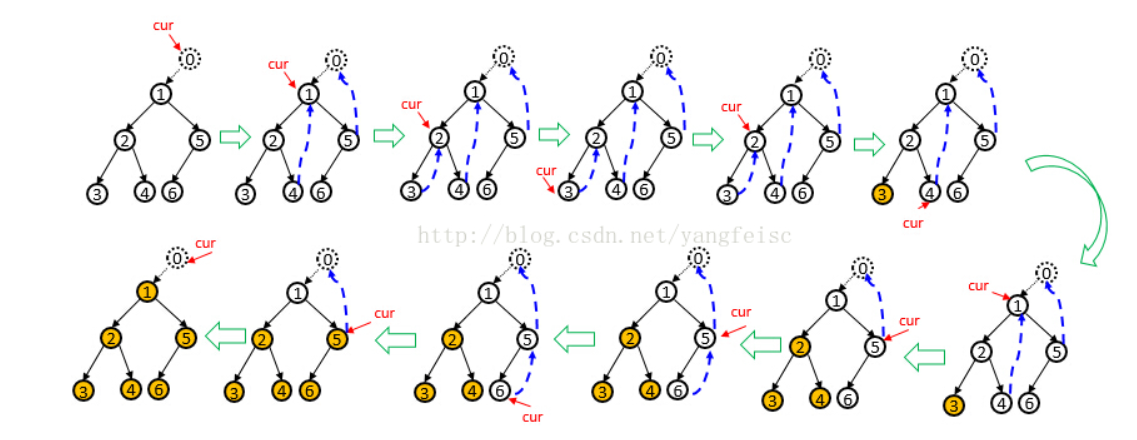
class Solution(object): def postorderTraversal(self, root): """ :type root: TreeNode :rtype: List[int] """ ret_list = [] vir_node = TreeNode(0) vir_node.left = root cur = vir_node while cur: if cur.left is None: cur = cur.right else: pre = cur.left while pre.right is not None and pre.right is not cur: pre = pre.right if pre.right is None: pre.right = cur cur = cur.left else: tmp_list = [] pre.right = None t = cur.left while t: tmp_list.append(t.val) t = t.right ret_list.extend(tmp_list[::-1]) cur = cur.right vir_node.left = None return ret_list
class Solution(object): def evalRPN(self, tokens): """ :type tokens: List[str] :rtype: int """ stack = [] for i in tokens: if i in "+-*/": sec_val = stack.pop(-1) fir_val = stack.pop(-1) if i == "+": stack.append(fir_val+sec_val) elif i == "-": stack.append(fir_val-sec_val) elif i == "*": stack.append(fir_val*sec_val) elif i == "/": stack.append(int(float(fir_val)/float(sec_val))) else: stack.append(int(i)) return stack.pop(-1)
class Solution(object): def zigzagLevelOrder(self, root): """ :type root: TreeNode :rtype: List[List[int]] """ ret_list = [] if not root: return ret_list flag = 0 queue_t = [] queue_t.append(root) queue_t.append(None) tmp_list = [] while len(queue_t) > 0: node = queue_t.pop(0) if not node: flag += 1 if flag % 2 != 0: ret_list.append(tmp_list) else: ret_list.append(tmp_list[::-1]) if len(queue_t) == 0: break queue_t.append(None) tmp_list = [] continue tmp_list.append(node.val) if node.left: queue_t.append(node.left) if node.right: queue_t.append(node.right) return ret_list
双栈代码:
class Solution(object): def zigzagLevelOrder(self, root): """ :type root: TreeNode :rtype: List[List[int]] """ ret_list = [] if not root: return ret_list left_stack = [] right_stack = [] left_stack.append(root) tmp_list = [] while len(left_stack) > 0 or len(right_stack) > 0: tmp_list = [] if len(left_stack) > 0: while len(left_stack) > 0: node = left_stack.pop(-1) tmp_list.append(node.val) if node.left: right_stack.append(node.left) if node.right: right_stack.append(node.right) else: while len(right_stack) > 0: node = right_stack.pop(-1) tmp_list.append(node.val) if node.right: left_stack.append(node.right) if node.left: left_stack.append(node.left) ret_list.append(tmp_list) return ret_list
class MinStack(object): def __init__(self): """ initialize your data structure here. """ self.data = [] self.helper = [] def push(self, x): """ :type x: int :rtype: None """ self.data.append(x) if len(self.helper) == 0 or x <= self.helper[-1]: self.helper.append(x) def pop(self): """ :rtype: None """ tmp = self.data.pop(-1) if len(self.helper) > 0 and tmp == self.helper[-1]: self.helper.pop(-1) def top(self): """ :rtype: int """ if len(self.data) > 0: return self.data[-1] def getMin(self): """ :rtype: int """ if len(self.helper): return self.helper[-1]
class Solution(object): def calculate(self, s): """ :type s: str :rtype: int """ ret_list = self.translate_postfix_expre(s) return self.cal_postfix_expre(ret_list) def translate_postfix_expre(self, s): symbol_stack = [] ret_list = [] num = None for c in s: if c == ' ': continue elif c in '+-()': if num is not None: ret_list.append(num) num = None if c in '+-': while len(symbol_stack) > 0 and symbol_stack[-1] != '(': ret_list.append(symbol_stack.pop(-1)) symbol_stack.append(c) elif c == ')': while len(symbol_stack) > 0 and symbol_stack[-1] != '(': ret_list.append(symbol_stack.pop(-1)) symbol_stack.pop(-1) else: symbol_stack.append(c) else: if num is None: num = 0 num = num * 10 + int(c) if num is not None: ret_list.append(num) while len(symbol_stack) > 0: ret_list.append(symbol_stack.pop(-1)) return ret_list def cal_postfix_expre(self, s_list): num_stack = [] for i in s_list: if i == '+' or i == '-': sec_num = num_stack.pop(-1) fir_num = num_stack.pop(-1) if i == '+': num_stack.append(fir_num+sec_num) else: num_stack.append(fir_num-sec_num) else: num_stack.append(i) return num_stack[-1]
拆括号方式:
class Solution(object): def calculate(self, s): """ :type s: str :rtype: int """ convert_stack = [] num = 0 ret_result = 0 pre_op = '+' actual_pre_op = '+' for i in s: if i == ' ': continue elif i in '+-': actual_pre_op = i ret_result = ret_result + num if pre_op == '+' else ret_result - num num = 0 if len(convert_stack) > 0 and convert_stack[-1] == True: pre_op = '+' if i == '-' else '-' else: pre_op = i elif i == '(': if len(convert_stack) > 0: if actual_pre_op == '-': convert_stack.append(not convert_stack[-1]) else: convert_stack.append(convert_stack[-1]) else: if actual_pre_op == '-': convert_stack.append(True) else: convert_stack.append(False) elif i == ')': convert_stack.pop(-1) else: num = num * 10 + int(i) if num > 0: ret_result = ret_result + num if pre_op == '+' else ret_result - num return ret_result
class MyStack(object): def __init__(self): """ Initialize your data structure here. """ self.q1 = [] def push(self, x): """ Push element x onto stack. :type x: int :rtype: None """ q1_size = len(self.q1) self.q1.append(x) while q1_size > 0: self.q1.append(self.q1.pop(0)) q1_size -= 1 def pop(self): """ Removes the element on top of the stack and returns that element. :rtype: int """ return self.q1.pop(0) def top(self): """ Get the top element. :rtype: int """ return self.q1[0] def empty(self): """ Returns whether the stack is empty. :rtype: bool """ if len(self.q1) == 0: return True return False
class Solution(object): def removeDuplicates(self, S): """ :type S: str :rtype: str """ stack = [] for c in S: if len(stack) > 0 and stack[-1] == c: stack.pop() else: stack.append(c) return ''.join(stack)

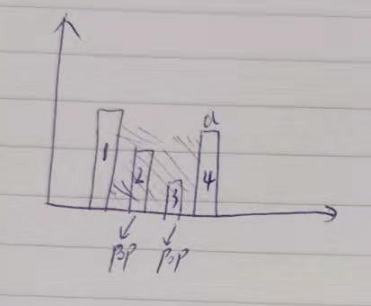
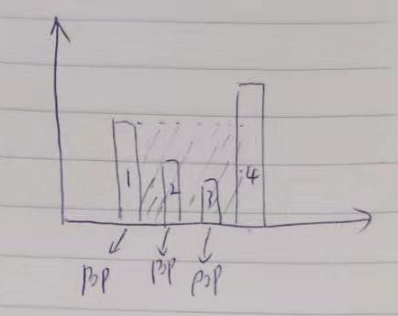

class Solution(object): def trap(self, height): """ :type height: List[int] :rtype: int """ stack = [] result = 0 des_tmp = 0 x_num = 0 for i in height: x_num += 1 if len(stack) > 0 and stack[-1][1] < i: while len(stack) > 1 and stack[-1][1] < i: des_tmp += stack[-1][1] stack.pop() if len(stack) == 1 and stack[-1][1] < i: result += ((x_num - stack[-1][0] - 1) * stack[-1][1]) stack.pop() stack.append((x_num, i)) while len(stack) > 1: last_one = stack.pop() last_sec_one = stack[-1] result += ((last_one[0] - last_sec_one[0] - 1) * last_one[1]) return result-des_tmp
class Solution(object): def simplifyPath(self, path): """ :type path: str :rtype: str """ ret = [] path_list = path.split('/') for l in path_list: if l == "" or l == ".": continue elif l == "..": if len(ret) > 0: ret.pop() else: ret.append(l) return "/"+"/".join(ret)
class Solution(object): def largestRectangleArea(self, heights): """ :type heights: List[int] :rtype: int """ stack = [] max_area = 0 heights_len = len(heights) for i in range(0, heights_len): if len(stack) == 0: if heights[i]*(heights_len-i) > max_area: stack.append([heights[i], 1]) else: num = 1 while len(stack) > 0 and stack[-1][0] > heights[i]: tmp = stack.pop() num = tmp[1] + 1 max_area = max(tmp[0]*tmp[1], max_area) for j in range(0, len(stack)): stack[j][1] += 1 if len(stack) == 0 or stack[-1][0] != heights[i]: if heights[i]*(heights_len-i-1+num) > max_area: stack.append([heights[i], num]) while len(stack) > 0: tmp = stack.pop() max_area = max(tmp[0]*tmp[1], max_area) return max_area
正确的通过计算宽度来做的:
class Solution(object): def largestRectangleArea(self, heights): """ :type heights: List[int] :rtype: int """ stack = [-1] max_area = 0 heights_len = len(heights) for i in range(0, heights_len): while len(stack) > 1 and heights[stack[-1]] >= heights[i]: tmp = stack.pop() max_area = max(heights[tmp] * (i-stack[-1]-1), max_area) stack.append(i) while len(stack) > 1: tmp = stack.pop() max_area = max(heights[tmp] * (heights_len-stack[-1]-1), max_area) return max_area
class Solution(object): def backspaceCompare(self, S, T): """ :type S: str :type T: str :rtype: bool """ s_stack = [] t_stack= [] for tmp_s in S: if tmp_s == '#': if len(s_stack) > 0: s_stack.pop() else: s_stack.append(tmp_s) for tmp_t in T: if tmp_t == '#': if len(t_stack) > 0: t_stack.pop() else: t_stack.append(tmp_t) if len(s_stack) != len(t_stack): return False while len(s_stack) > 0: if s_stack.pop() != t_stack.pop(): return False return True
尾部遍历方法:
class Solution(object): def backspaceCompare(self, S, T): """ :type S: str :type T: str :rtype: bool """ i = len(S) -1 j = len(T) - 1 while i >= 0 or j >= 0: def find_vaild_c(X, point): flag = 0 while point >= 0 and flag <= 0: if X[point] == '#': flag -= 1 else: flag += 1 if flag <= 0: point -= 1 return point i = find_vaild_c(S, i) j = find_vaild_c(T, j) if not ((i < 0 and j < 0) or (i >= 0 and j >= 0 and S[i] == T[j])): return False i -= 1 j -= 1 return True
class Solution(object): def isValidSerialization(self, preorder): """ :type preorder: str :rtype: bool """ null_num = 0 stack = [] target_list = preorder.split(',') target_list_num = len(target_list) if target_list_num % 2 == 0: return False if target_list[0] == "#": if target_list_num == 1: return True else: return False else: stack.append(target_list[0]) pre = target_list[0] for i in range(1, target_list_num): if len(stack) == 0: return False if pre == "#": stack.pop() if target_list[i] == "#": null_num += 1 else: stack.append(target_list[i]) pre = target_list[i] if target_list_num/2 != null_num-1: return False return True
第二次解法优化了下,删掉了一些特性,简化了代码:
class Solution(object): def isValidSerialization(self, preorder): """ :type preorder: str :rtype: bool """ target_list = preorder.split(',') target_list_num = len(target_list) if target_list_num % 2 == 0: return False stack = [] pre = "" for t in target_list: if pre == "#": if len(stack) == 0: return False stack.pop() if t != "#": stack.append(t) pre = t if len(stack) != 0: return False return True
看到别人的更简洁的根据前序遍历出栈的特性做的:
class Solution(object): def isValidSerialization(self, preorder): """ :type preorder: str :rtype: bool """ target_list = preorder.split(',') target_list_num = len(target_list) if target_list_num % 2 == 0: return False stack = [] for t in target_list: while t == "#" and len(stack) > 0 and stack[-1] == "#": stack.pop() if len(stack) == 0: return False stack.pop() stack.append(t) if len(stack) != 1 or stack[-1] != '#': return False return True
根据每个非#节点一定会有两条边原理来做的:
class Solution(object): def isValidSerialization(self, preorder): """ :type preorder: str :rtype: bool """ preorder = preorder.split(",") edges = 1 for item in preorder: edges -= 1 if edges < 0: return False if item != "#": edges += 2 return edges == 0
class Solution(object): def nextGreaterElements(self, nums): """ :type nums: List[int] :rtype: List[int] """ split_point = -1 nums_len = len(nums) stack = [] result = [-1] * nums_len for i in range(0, nums_len): while len(stack) > 0 and nums[i] > nums[stack[-1]]: result[stack[-1]] = nums[i] stack.pop() if len(stack) == 0: split_point = i stack.append(i) j = 0 while len(stack) > 0 and j <= split_point: while len(stack) > 0 and nums[j] > nums[stack[-1]]: result[stack[-1]] = nums[j] stack.pop() j += 1 return result
class Solution(object): def find132pattern(self, nums): """ :type nums: List[int] :rtype: bool """ nums_len = len(nums) if nums_len < 3: return False min_nums = [0] * nums_len min_nums[0] = nums[0] stack = [] for i in range(1, nums_len): min_nums[i] = min(min_nums[i-1], nums[i]) for i in range(nums_len-1, 0, -1): if nums[i] > min_nums[i]: while len(stack) > 0 and stack[-1] <= min_nums[i]: stack.pop() if len(stack) > 0 and nums[i] > stack[-1]: return True stack.append(nums[i]) return False
class Solution(object): def removeKdigits(self, num, k): """ :type num: str :type k: int :rtype: str """ stack = [] zero_flag = 0 tmp = k num_len = len(num) i = 0 while i < num_len: while i < num_len and num[i] == '0': i += 1 zero_flag = i if i < num_len and tmp > 0: tmp -= 1 else: break i += 1 k = i - zero_flag for i in range(zero_flag, num_len): while len(stack) > 0 and i < num_len and int(stack[-1]) > int(num[i]) and k > 0: stack.pop() k -= 1 stack.append(num[i]) if k <= 0: break while k > 0 and len(stack) > 0: stack.pop() k -= 1 result = ''.join(stack) if i+1 < num_len: result += num[i+1:] if result == "": result = "0" return result
第二版优化后的提交代码(1步骤合并到2步骤):
class Solution(object): def removeKdigits(self, num, k): """ :type num: str :type k: int :rtype: str """ stack = [] num_len = len(num) i = 0 while i < num_len: if k <= 0: break while len(stack) > 0 and int(stack[-1]) > int(num[i]) and k > 0: stack.pop() k -= 1 if num[i] != "0" or (num[i] == "0" and len(stack) > 0): stack.append(num[i]) i += 1 while k > 0 and len(stack) > 0: stack.pop() k -= 1 if len(stack) == 0: while i < num_len and num[i] == "0": i += 1 result = ''.join(stack) if i < num_len: result += num[i:] if result == "": result = "0" return result
class Solution(object): def sumSubarrayMins(self, A): """ :type A: List[int] :rtype: int """ A_len = len(A) pre = [None]*A_len nex = [None]*A_len stack = [] for i in xrange(A_len): while stack and A[i] < A[stack[-1]]: stack.pop() pre[i] = stack[-1] if stack else -1 stack.append(i) stack = [] for i in xrange(A_len-1, -1, -1): while stack and A[i] <= A[stack[-1]]: stack.pop() nex[i] = stack[-1] if stack else A_len stack.append(i) result = 0 MOD = 10**9 + 7 for i in xrange(A_len): result = (result + (i-pre[i])*(nex[i]-i)*A[i]) % MOD return result
第二种解法:
class Solution(object): def sumSubarrayMins(self, A): """ :type A: List[int] :rtype: int """ A_len = len(A) stack_accumulate = 0 total = 0 MOD = 10**9 + 7 stack = [] for item in A: count = 1 while stack and stack[-1][0] >= item: (tmp_val, tmp_count) = stack.pop() count += tmp_count stack_accumulate -= tmp_val * tmp_count stack_accumulate += item * count total += stack_accumulate stack.append((item, count)) return total % MOD
class Solution(object): def longestWPI(self, hours): """ :type hours: List[int] :rtype: int """ hours_len = len(hours) tran_hours = [None]*hours_len for i in xrange(hours_len): tran_hours[i] = 1 if hours[i] > 8 else -1 pre_sum = [0]*(hours_len+1) for i in xrange(hours_len): pre_sum[i+1] = pre_sum[i] + tran_hours[i] stack = [] for i in xrange(hours_len+1): if not stack or pre_sum[i] < pre_sum[stack[-1]]: stack.append(i) max_len = 0 for i in xrange(hours_len, 0, -1): if i <= max_len: break while stack and pre_sum[i] > pre_sum[stack[-1]]: max_len = max(max_len, i-stack[-1]) stack.pop() return max_len
class Solution(object): def asteroidCollision(self, asteroids): """ :type asteroids: List[int] :rtype: List[int] """ stack = [] for item in asteroids: if item > 0: stack.append(item) else: add_value = 1 while stack and stack[-1]>0: add_value = stack[-1] + item if add_value == 0: stack.pop() break elif add_value < 0: stack.pop() else: break if add_value != 0 and not (stack and stack[-1] > 0): stack.append(item) return stack
# """ # This is the interface that allows for creating nested lists. # You should not implement it, or speculate about its implementation # """ #class NestedInteger(object): # def __init__(self, value=None): # """ # If value is not specified, initializes an empty list. # Otherwise initializes a single integer equal to value. # """ # # def isInteger(self): # """ # @return True if this NestedInteger holds a single integer, rather than a nested list. # :rtype bool # """ # # def add(self, elem): # """ # Set this NestedInteger to hold a nested list and adds a nested integer elem to it. # :rtype void # """ # # def setInteger(self, value): # """ # Set this NestedInteger to hold a single integer equal to value. # :rtype void # """ # # def getInteger(self): # """ # @return the single integer that this NestedInteger holds, if it holds a single integer # Return None if this NestedInteger holds a nested list # :rtype int # """ # # def getList(self): # """ # @return the nested list that this NestedInteger holds, if it holds a nested list # Return None if this NestedInteger holds a single integer # :rtype List[NestedInteger] # """ class Solution(object): def deserialize(self, s): """ :type s: str :rtype: NestedInteger """ stack = [] s_len = len(s) if s[0] != '[': return NestedInteger(int(s)) num, symbol, is_num = 0, 1, False for c in s: if c >= '0' and c <= '9': num = num * 10 + int(c) is_num = True elif c == '-': symbol = -1 elif c == '[': stack.append(NestedInteger()) elif c == ',' or c == ']': if is_num is True: stack[-1].add(NestedInteger(symbol*num)) num, symbol, is_num = 0, 1, False if c == ']' and len(stack) > 1: tmp = stack.pop() stack[-1].add(tmp) return stack[-1]
# """ # This is the interface that allows for creating nested lists. # You should not implement it, or speculate about its implementation # """ #class NestedInteger(object): # def isInteger(self): # """ # @return True if this NestedInteger holds a single integer, rather than a nested list. # :rtype bool # """ # # def getInteger(self): # """ # @return the single integer that this NestedInteger holds, if it holds a single integer # Return None if this NestedInteger holds a nested list # :rtype int # """ # # def getList(self): # """ # @return the nested list that this NestedInteger holds, if it holds a nested list # Return None if this NestedInteger holds a single integer # :rtype List[NestedInteger] # """ class NestedIterator(object): def __init__(self, nestedList): """ Initialize your data structure here. :type nestedList: List[NestedInteger] """ self.stack = [] self.stack.append(nestedList) def next(self): """ :rtype: int """ return self.stack.pop() def hasNext(self): """ :rtype: bool """ while self.stack: tmp_type = type(self.stack[-1]) if tmp_type is int: return True elif tmp_type is list: tmp = self.stack.pop() self.stack.extend(tmp[::-1]) else: tmp = self.stack.pop() if tmp.isInteger(): self.stack.append(tmp.getInteger()) else: tmp_list = tmp.getList() self.stack.extend(tmp_list[::-1]) return False # Your NestedIterator object will be instantiated and called as such: # i, v = NestedIterator(nestedList), [] # while i.hasNext(): v.append(i.next())
class Solution(object): def reverseParentheses(self, s): """ :type s: str :rtype: str """ stack = [] for c in s: if c == ')': tmp = [] while stack[-1] != '(': tmp.append(stack.pop()) stack.pop() stack.extend(tmp) else: stack.append(c) return ''.join(stack)
分治递归提交代码:
class Solution(object): def reverseParentheses(self, s): """ :type s: str :rtype: str """ s_len = len(s) record_symbol = [None]*s_len stack = [] for i in xrange(s_len): if s[i] == '(': stack.append(i) elif s[i] == ')': pre_symbol = stack.pop() record_symbol[pre_symbol] = i record_symbol[i] = pre_symbol result = [] self.reverse(s, result, 0, s_len-1, record_symbol, True) return ''.join(result) def reverse(self, s, result, begin, end, record_symbol, pos_seq): """ :type s: str :type result: list :type begin: int :type end: int :type pos_seq: bool """ if pos_seq: i = begin while i <= end: if s[i] == '(': self.reverse(s, result, i+1, record_symbol[i]-1, record_symbol, False) i = record_symbol[i] elif s[i] != ')': result.append(s[i]) i += 1 else: i = end while i >= begin: if s[i] == ')': self.reverse(s, result, record_symbol[i]+1, i-1, record_symbol, True) i = record_symbol[i] elif s[i] != '(': result.append(s[i]) i -= 1
class FreqStack(object): def __init__(self): self.map_to_count = {} self.map_to_list = {} self.cur_max = 0 def push(self, x): """ :type x: int :rtype: None """ if x in self.map_to_count: self.map_to_count[x] += 1 else: self.map_to_count[x] = 1 if self.map_to_count[x] <= self.cur_max: self.map_to_list[self.map_to_count[x]].append(x) else: self.cur_max += 1 self.map_to_list[self.cur_max] = [x] def pop(self): """ :rtype: int """ cur_max_num = self.map_to_list[self.cur_max].pop() if not len(self.map_to_list[self.cur_max]): self.cur_max -= 1 self.map_to_count[cur_max_num] -= 1 return cur_max_num # Your FreqStack object will be instantiated and called as such: # obj = FreqStack() # obj.push(x) # param_2 = obj.pop()
class Solution(object): def decodeAtIndex(self, S, K): """ :type S: str :type K: int :rtype: str """ s_len = len(S) char_all_count = 0 for c in S: if c.isalpha(): char_all_count += 1 else: char_all_count *= (int(c)) for i in xrange(s_len-1, -1, -1): K %= char_all_count if K == 0 and S[i].isalpha(): return S[i] if S[i].isalpha(): char_all_count -= 1 else: char_all_count /= int(S[i])
class Solution(object): def oddEvenJumps(self, A): """ :type A: List[int] :rtype: int """ A_len = len(A) def build_next_arr(B): stack = [] tmp_next = [None]*A_len for i in B: while stack and i > stack[-1]: tmp_next[stack.pop()] = i stack.append(i) return tmp_next B = sorted(range(A_len), key=lambda x: A[x]) odd_next = build_next_arr(B) B.sort(key=lambda x: -A[x]) even_next = build_next_arr(B) odd_jump = [False]*A_len even_jump = [False]*A_len odd_jump[A_len-1] = True even_jump[A_len-1] = True for i in xrange(A_len-2, -1, -1): if odd_next[i] is not None: odd_jump[i] = even_jump[odd_next[i]] if even_next[i] is not None: even_jump[i] = odd_jump[even_next[i]] return sum(odd_jump)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号