

为了考业余无线电执照下了题库。
想从题库出发过一遍基本知识点,所以准备处理一下题库,让每道题变成简单好读的样子。
虽然ABC类题库是错开的,但实际上感觉直接看总题库比较好。
前200+题纯手工改格式,后来是在受不了了,所以决定学习一下正则修改(……)
虽然正则还没太学会,但题库已经处理成想要的样子了,发一下过程记录一下。
成品在这里。 _(:з」∠)_没几天就考试了。
开始和目标
这是题库的原始样子。
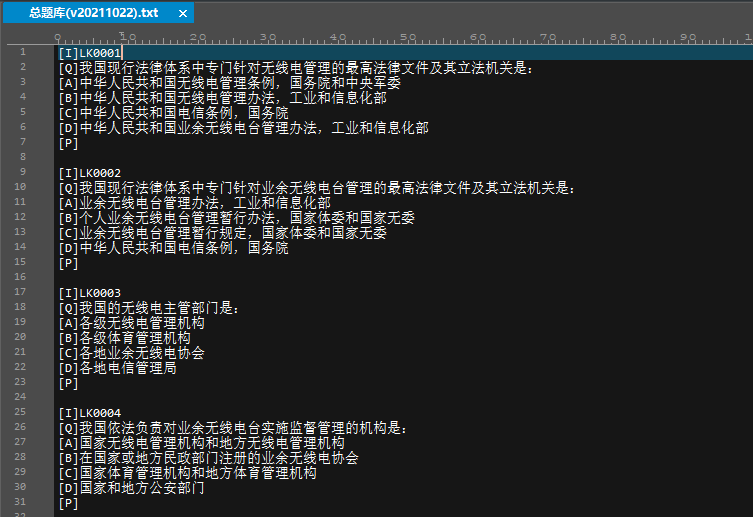
这是题库处理完的样子。
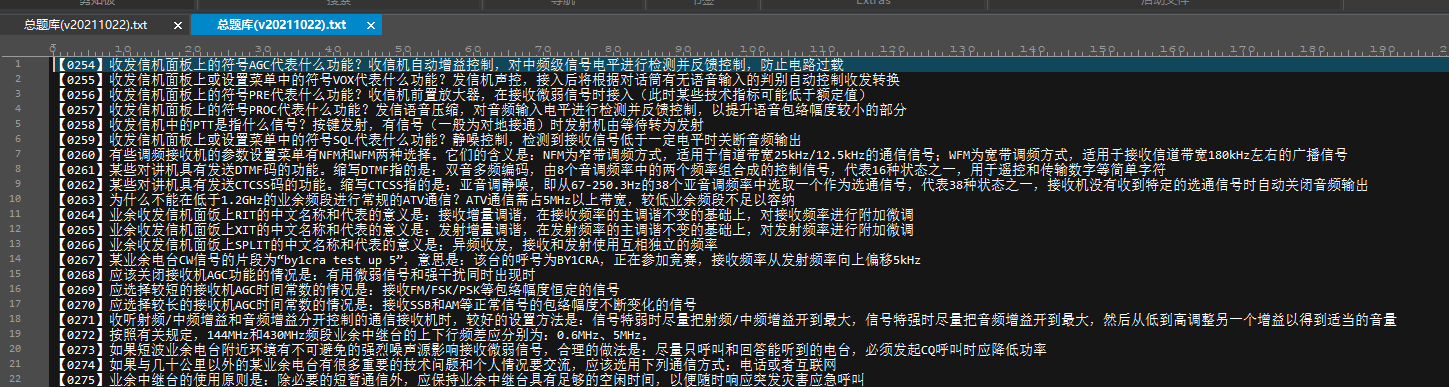
变动有:
- 删除错误的BCD选项以及P(所在行),因为在下载界面说了A是正选,所以删去错误答案。
- 变序号[I]LKxxxx为【xxxx】格式
- 删去[Q]和[A]
- 把一道题的编号、题目、正解放于一行。
删除指定行
勾选正则表达式,选择Perl(因为这个正则式是Perl的正则式)。
除了Perl还有别的选项,不同语言的正则规则稍有不同,可以点开![]() 查看语法规则。
查看语法规则。
UE还能收藏和查看历史呢。![]()
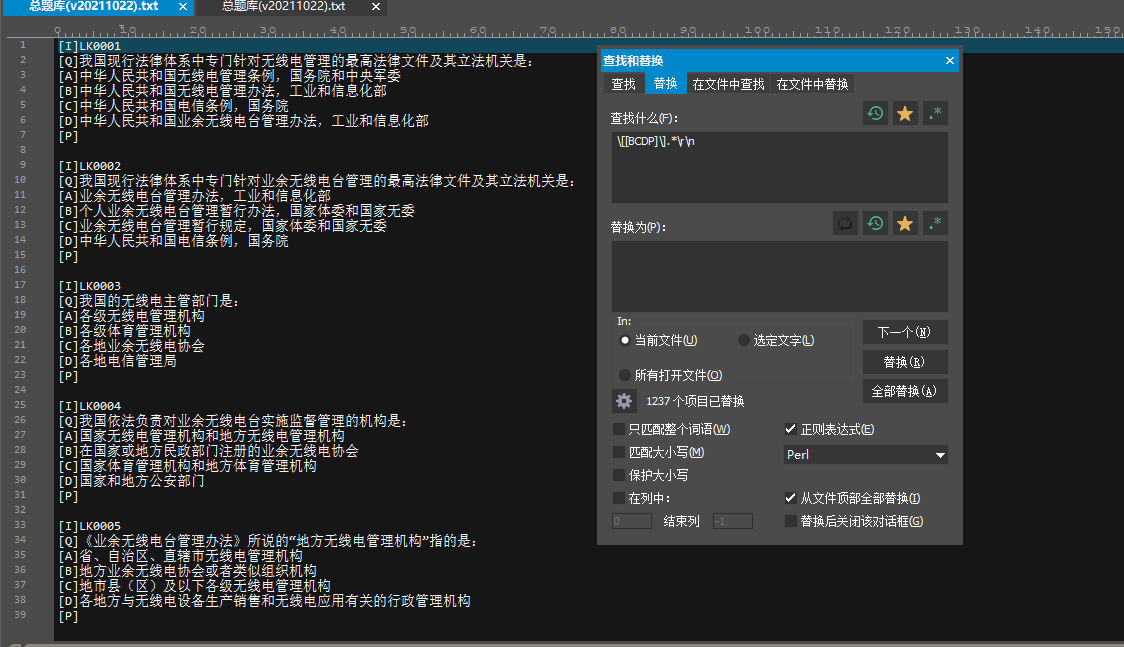
然后解释一下这个代码:\\[[BCDP]\].*\r\n
假设我要删去B那一行,[B]是固定的开头,后面的内容是不一样的,所以后面用.*表示,.表示任一字符,*表示前面的字符出现0或多次。
这样[B]后面的文字部分就搞定了。目光回到[B],问题在[]这个括号,这两个符号在正则表达式中是特殊字符,如果要匹配这两个字符就要对其进行转义。
\是Perl中正则的转义字符。使用方法是放在要转义的字符前面。于是这个式子就变成了\[B\]。
将上面两个表达式组合起来,也就是\[B\].*。这个式子其实以及可以实现删除指定行的功能了(配合查找,替换那栏空着其实就是实现了删除功能。)
它的含义是以[B]开头的字符串。
然后我想,我要删除的不只是[B]开头的行,还有[C][D][P],这三个和[B]的区别只是字母不同,所以把\[B\].*的B改成C、D、P就行。
但学过基础的正则就知道这是个麻烦的做法,正则里面有[abc]这种表达,作用是匹配abc中的任意一个字母。
所以\[B\].*的B,就可以用[BCDP]替代,这时候式子就变成了\[[BCDP]\].*。表示以[B]或[C]或[D]或[P]开头的任意一行。
注意,这里的[]和题库中[A]之类的是不一样的,这个[]是正则语法规则的描述,不是待处理文本的一部分。
此时的\[[BCDP]\].*和代码\[[BCDP]\].*\r\n的区别只剩下了句尾的\r\n。
\r是归位字符\n是换行字符。
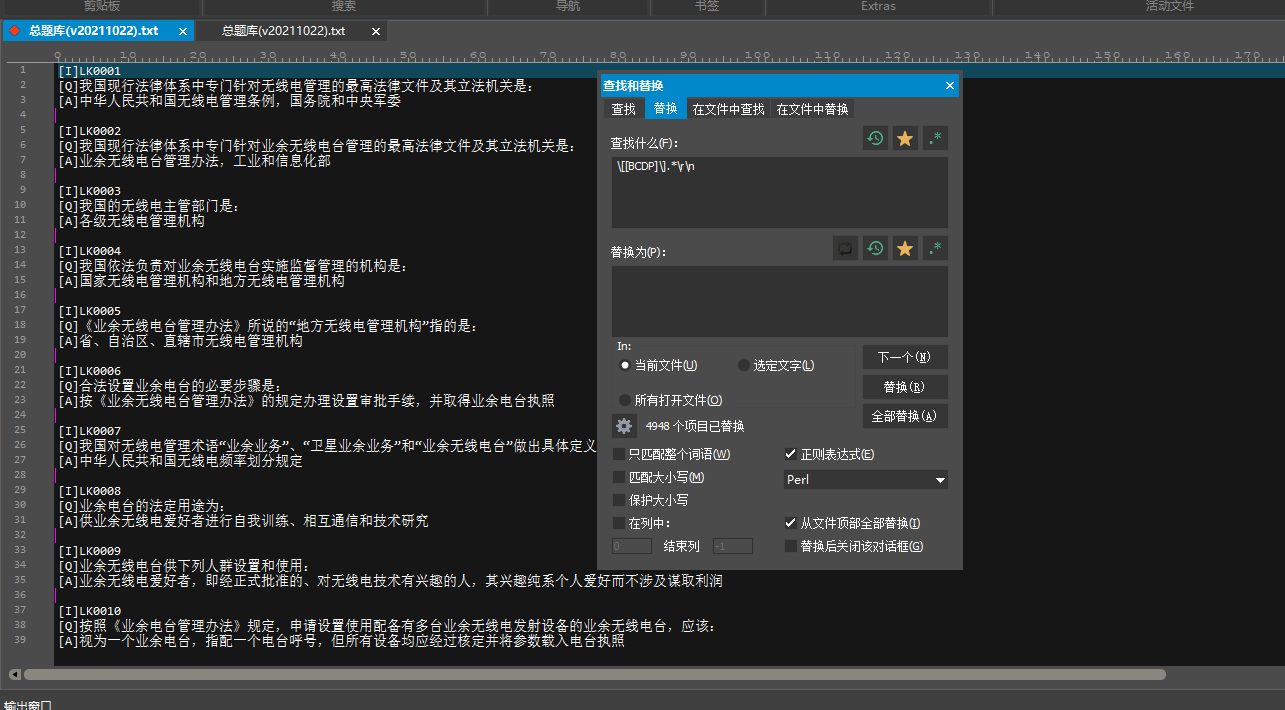
上面的代码把[B][C][D][P]行的内容清空了,但是那一行还是在的,所以就会产生很多的空行。
空行的存在是因为存在不可打印但显示位置的的字符,比如换行啥的。
删除空行,粗略理解一下就是删掉那行的回车键,Perl中的回车键就是\r\n两个组合。
至于为什么回车是\r\n两个,因为回车本身就是两个动作,\r回到句首(但是当行句首),也就是归位,\n是另起一行,合起来才是回车的效果。
不过这个不同语言好像也不太一样。
总之,这样就做到了删除多余行并消除空行的效果啦。
结果如下:
替换指定文本
这里我是想把[I]LKxxxx的格式变成【xxxx】的序号格式。想不到怎么一步到位,所以我拆成了【xxxx和】两步。
\r\n\[I\]LK有了上面的内容应该一看就明白,匹配的是一个空行+以[I]LK下一行。整个用【替换就行。这里实际上实现的是去上方空行和替换指定文本两个功能。
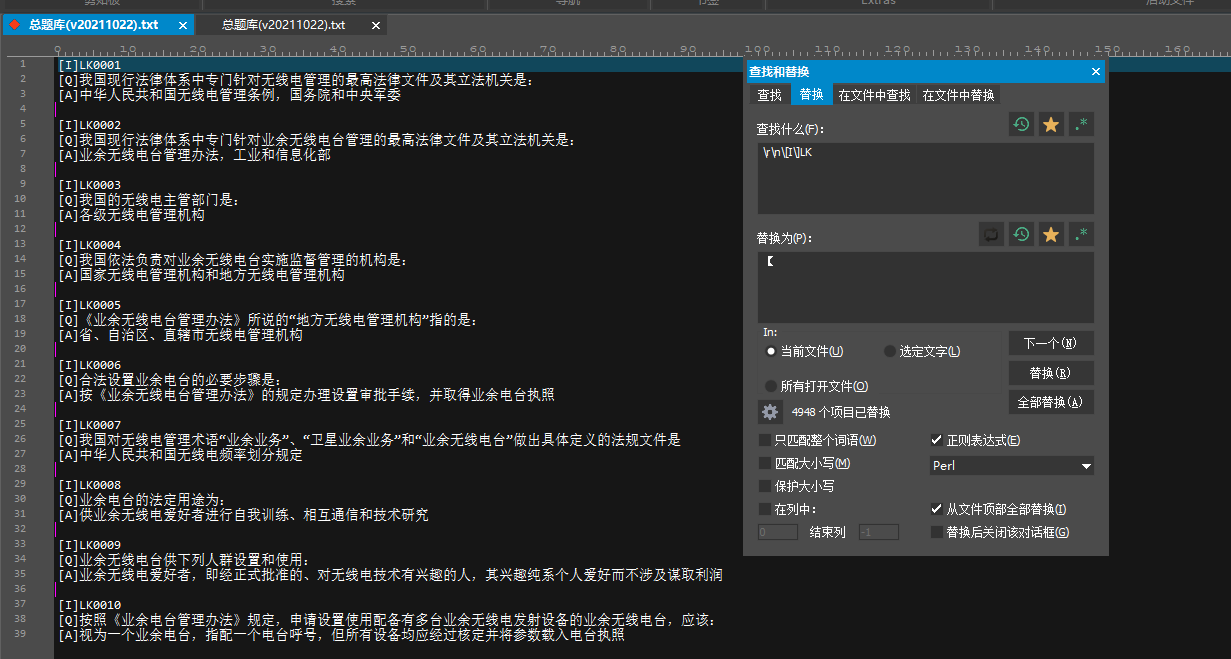
结果如下:
当然你会发现,LK0001没有改变,因为这一行是在第一行,没有上一行,不符合\r\n的筛选条件,可以回车一下使得它可以被选择到,或者直接手动改也行。
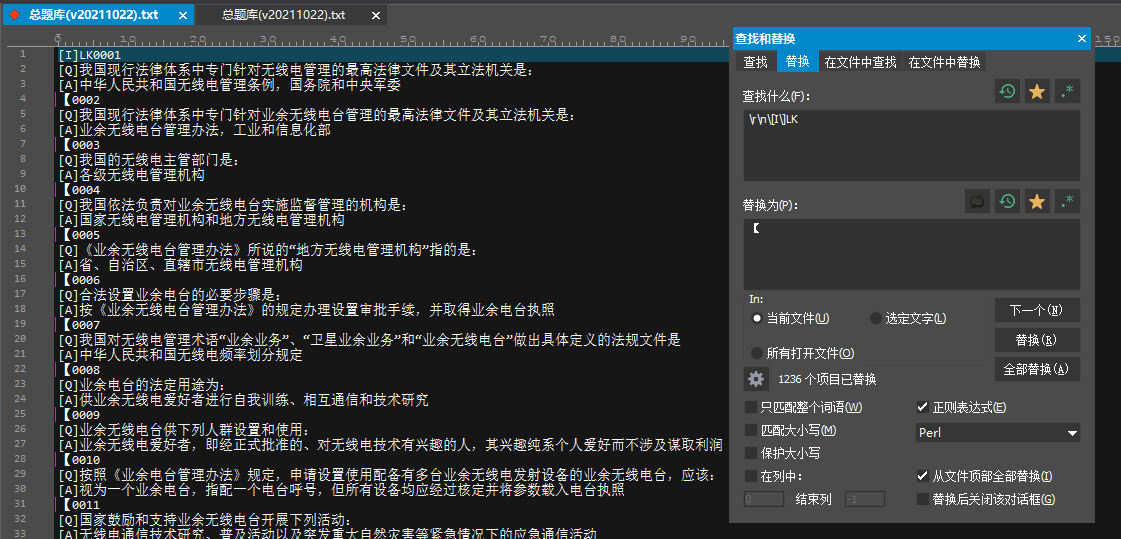
合并指定行为一行
\而另一部分的】,可以用类似方法实现替换。
r\n\[Q\]表示以[Q]为开头的行和其上方一行的\r\n,实际上实现了合并设为目标的两行为一行,并替换了指定文本。
由此其实可以得出的重要一点是,从正则表达式的角度讲,行和行之间其实就是一个\r\n或者别的回车字符的间隔,而这个间隔可以被查找被更改。
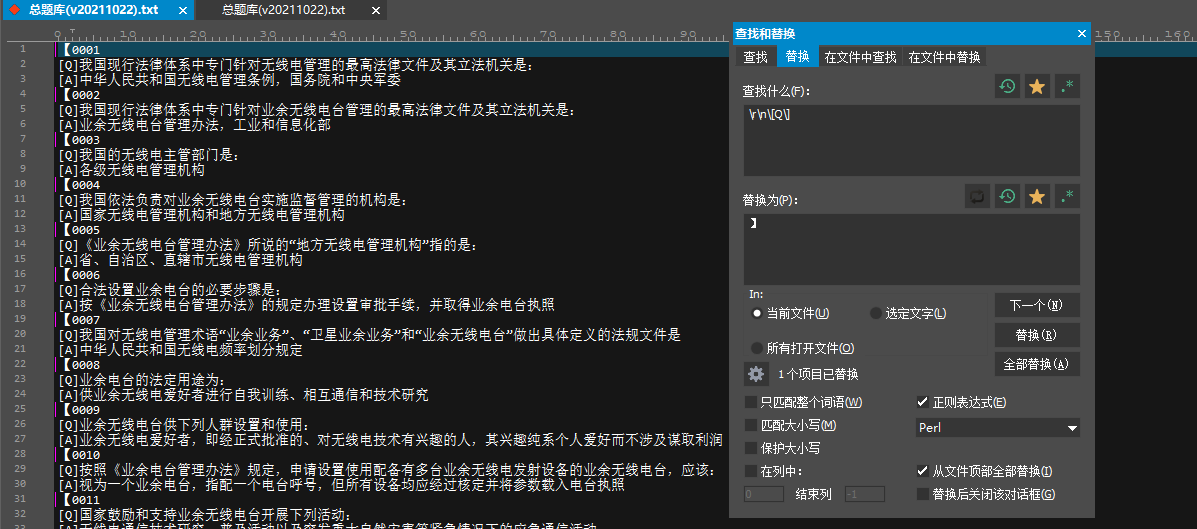
结果如下:
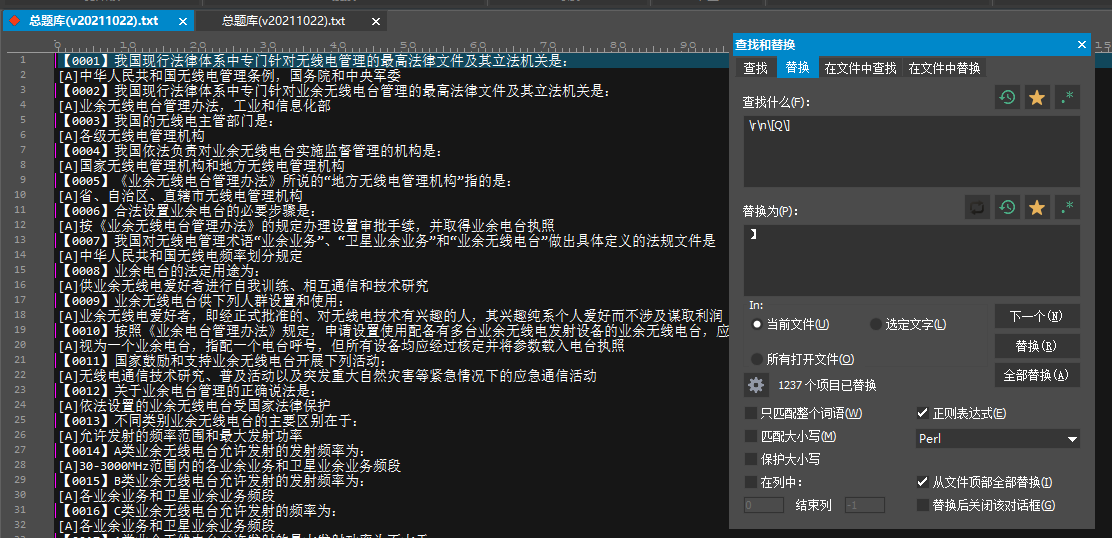
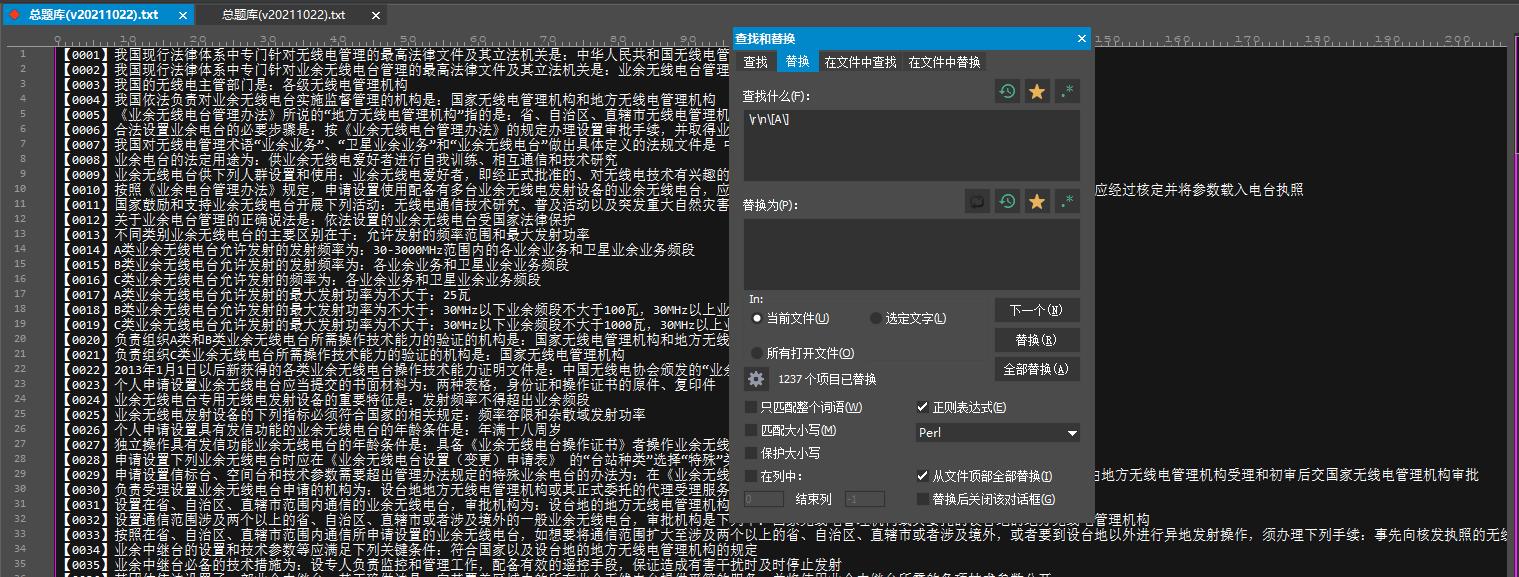
题库处理到这里,其实离目标只差最后一步,将题目和正解合为一行。
有了上面的思路,其实就是对着改一下:\r\n\[A\]
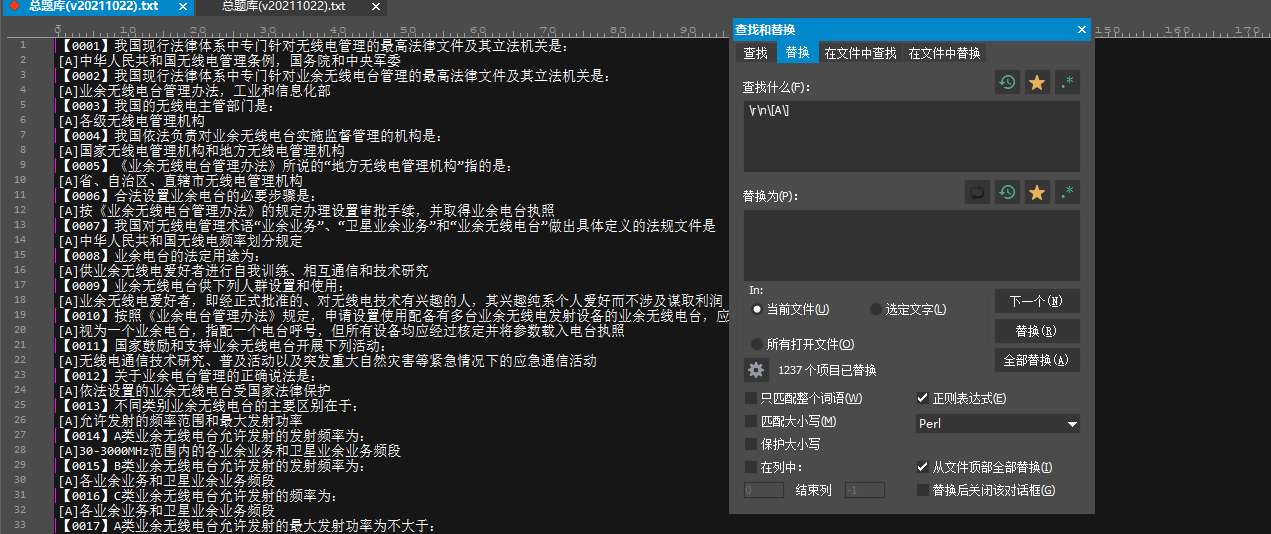
处理完毕。
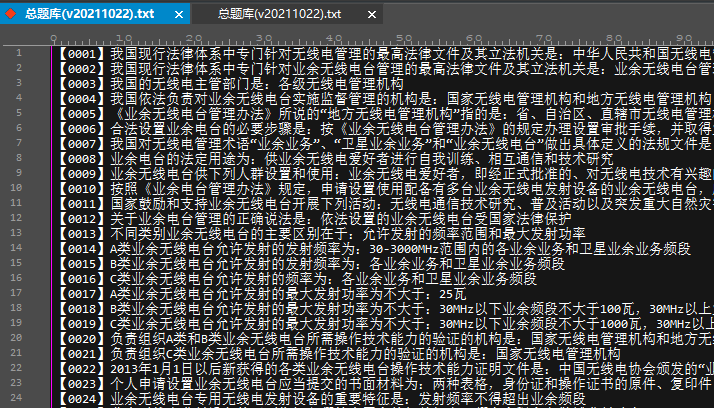
拆分指定行
寻求处理方法的时候学会了另一个好用的功能,虽然写这篇文章重现整个过程时没有用到,但是还是记录在下边。
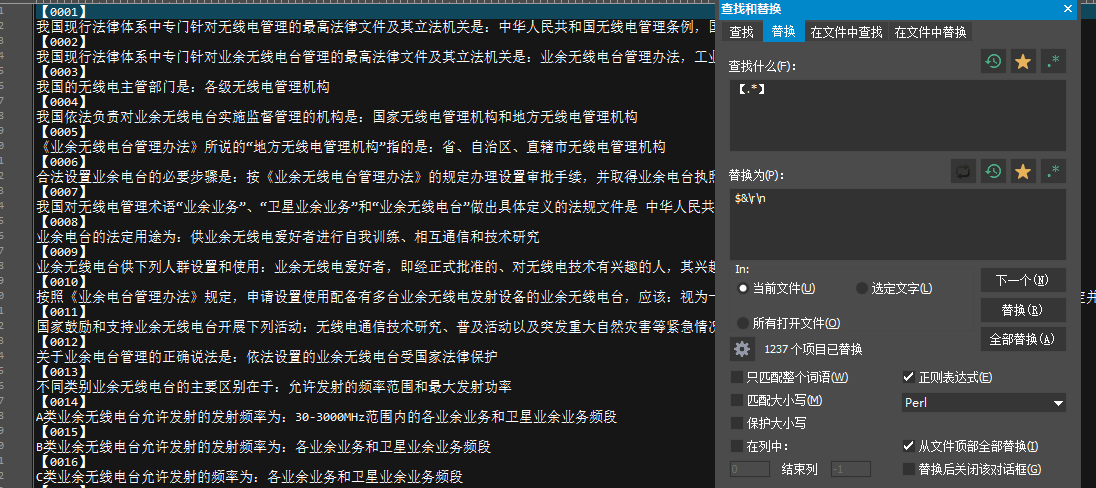
以下图为例,如果我们要将所有的【xxxx】格式的编号和后面的文字拆分为两行。
延续上文的思路,会很容易想到直接查找【xxxx】并在后面加个\r\n用于回车即可。
查找【.*】替换为【.*】\r\n。
如果这样做,那结果就是:
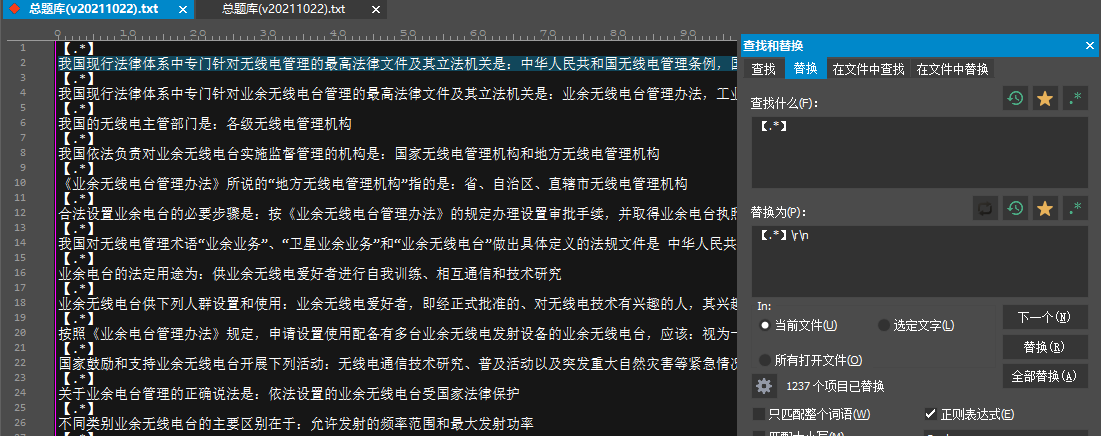
拆分行的功能确实是实现了,但是序号信息丢失了。追究其原因,.*在替换中失效了。
这里就需要引入一个新的概念“正则表达式变量”。
Perl中匹配到的字符串值会传给$&这个变量,所以这里查找【.*】应该替换为$&\r\n。
这样就可以实现拆分指定行功能了。
除此之外,Perl还有两个和匹配字符串有关的变量:$`(匹配字符串的前一部分字符串)和$'(匹配字符串的后一部分字符串)。三者合起来就是那一行的完整字符串。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号