OO Unit1 Expression Simplification
设计
本单元三次作业我都采用了为优化服务、为计算服务的架构,采用这样架构的原因是:最后的输出实际上只是对原表达式的数据运算结果进行输出,不涉及原输入的文法的存储,因此完全略去了对存储的需求,采用边解析边计算的策略。
这样的架构优势在于:
-
只涉及对一个存储单元的运算,只需要实现对存储单元的运算即可,运算结构相对统一
-
为优化服务,优化只涉及存储单元内部的运算
-
顶层结构简单,解析部分外只有计算类
这样简化的结构也带来一些问题:
-
可扩展性较差,每次作业都只是当前需求的局部较优解,很难适应新的需求
-
存储结构上耦合度过高,导致需求变化后存储结构都面临重构
-
继承关系较少,抽象层次不够清晰
hw1
第一次作业难度较低,主要体现了整体设计上的方法:递归下降法。这一文法分析策略适用于上下文无关文法,也就是LL文法。我们的文法实际上是一种一元相关的Markov chain,每一个词法单元唯一确定了后面的词法结构,因此只需要完成对各个语法结构的解析即可。句法结构的下降体现于此,递归则体现在括号,括号内的层次又作为了高层次结构,需要再次递归,对括号内句法进行分析。规定了括号层数,实际上规定了递归表达式的递归树深度不能超过1。
hw2
第二次作业难度骤增,为了更好体现工厂模式,我对解析过程进行了重构
-
工厂模式:解析层次上,设置了一个工厂类产生Factor,可以作为函数参数的类实现getParameter
-
优化导向:存储层次上,设置三个层次结构,优化有关的层次结构集中于MetaData一个部分,也就是相同x指数对应的三角多项式(Trigonometric polynomial)内部进行合并
这样的设计实际上有一定的冗余度,而且并没有在存储层次上进行分割与抽离,只是从结构上看起来更像OOP了一点,并没有实质上将不同对象的特征进行提取
UML类图如下,这个图中可以很清晰的看到递归下降的过程。
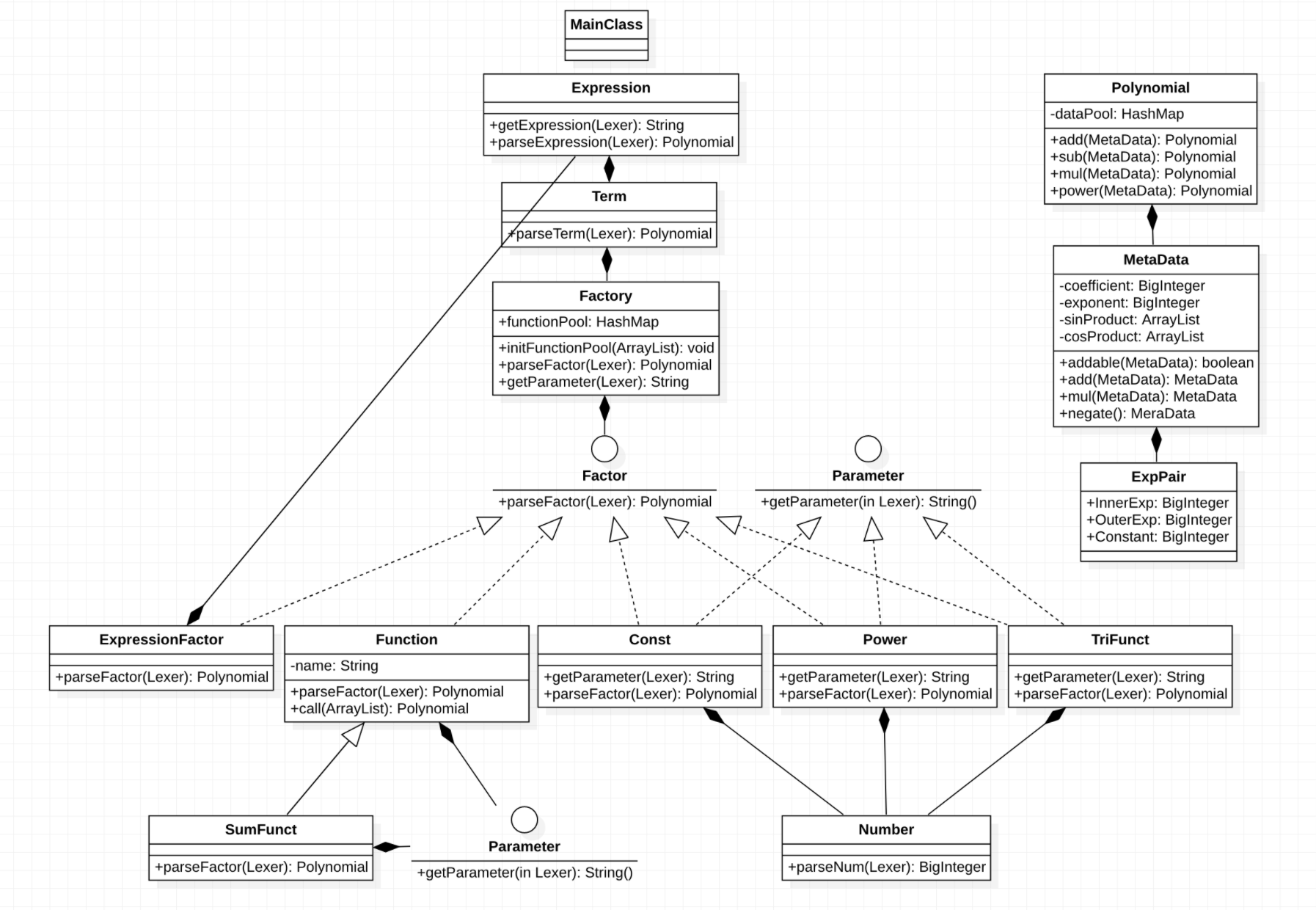
存储层次结构的复杂度如下:
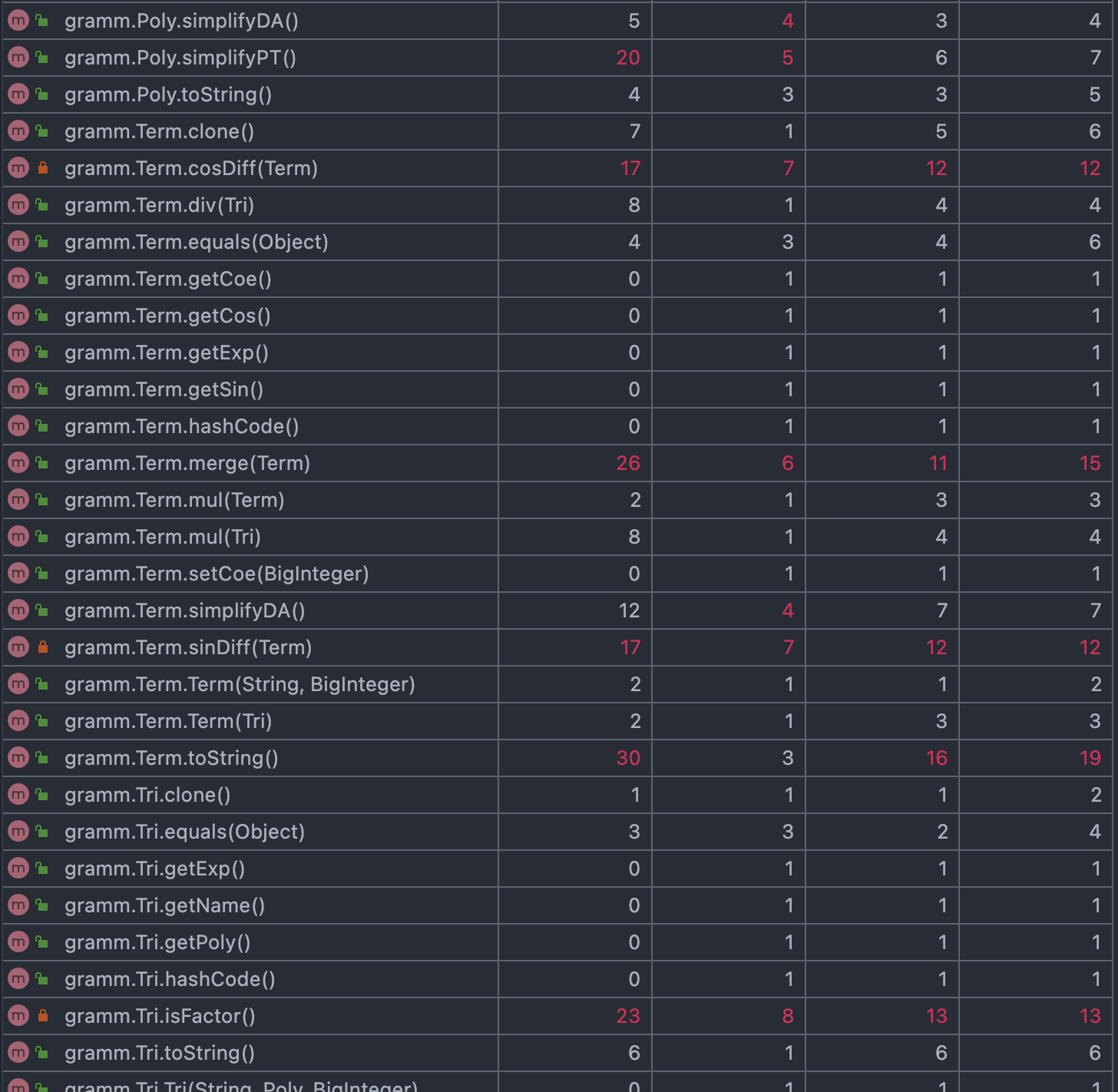
可以看到,把优化的任务集中在一个类上,导致了优化相关的部分(sinMergeable、Mergeable、simplify)等复杂度都过高了,这一点为后面出现bug与debug都埋下了一定的隐患。
hw3
第三次作业虽然需求上完全可以在第二次的基础上增量开发,但我感受到了极简主义的召唤,以及预估了原结构优化的难度之大,故进行了整体重构。
我将所有解析的过程重新归于Parser处理,同样采用解析的同时计算的策略,同时为了一般化处理,我将三角函数内部视为一个多项式进行存储,比较时比较二者差异即可
这次的重构在我看来充满争议性,优势在于:
-
简化了不必要的类,解析任务集中统一化,避免了套用工厂模式之嫌(化作了抽象工厂,更简单啦)
-
存储层次结构使用HashMap实现,找key的过程更简化,省去了无用而繁琐的维持有序的过程
问题在于:
-
因为是最后一次单元,故没有考虑可扩展性
-
parser表示压力山大
UML类图如下:
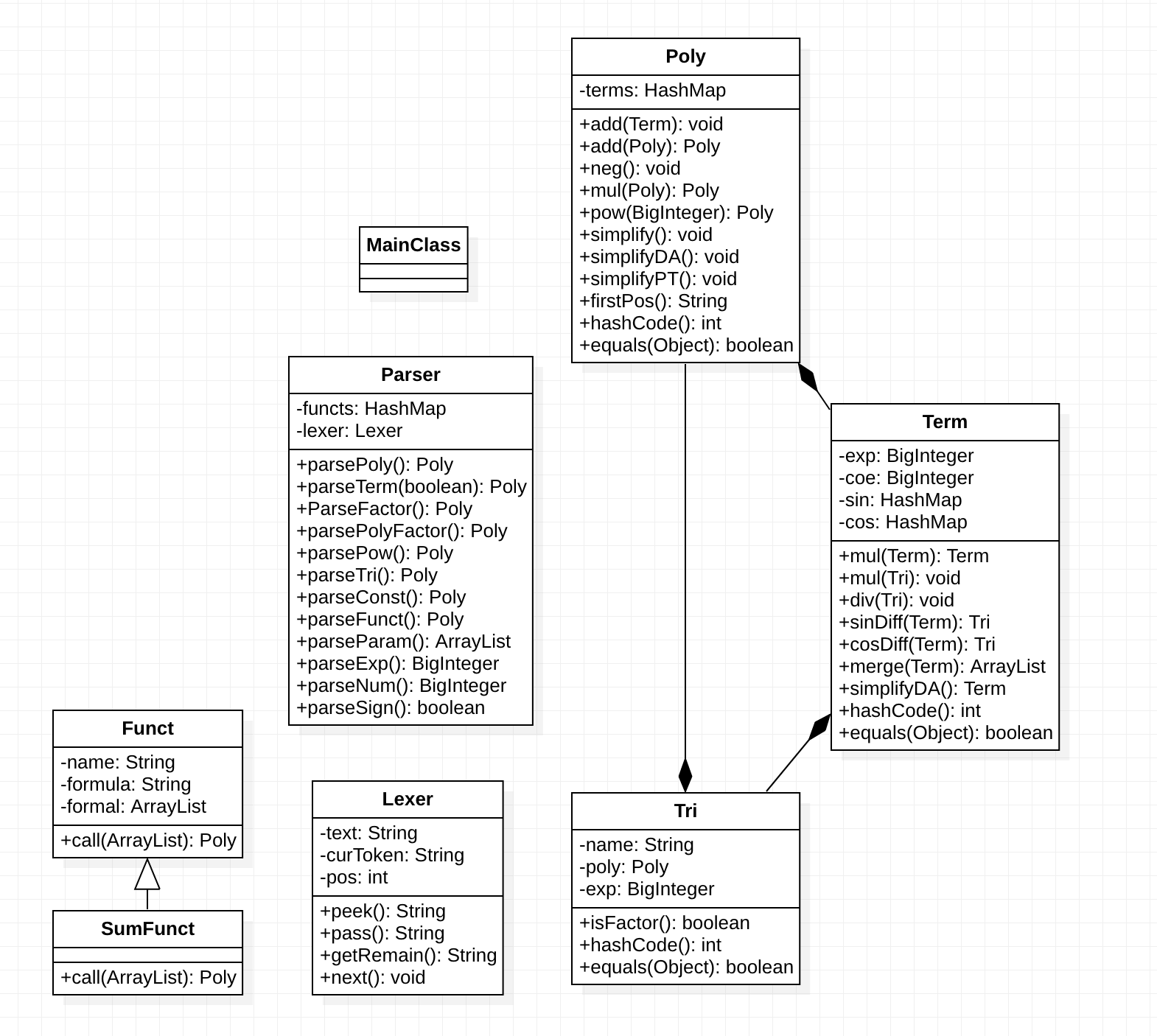
复杂度分析:
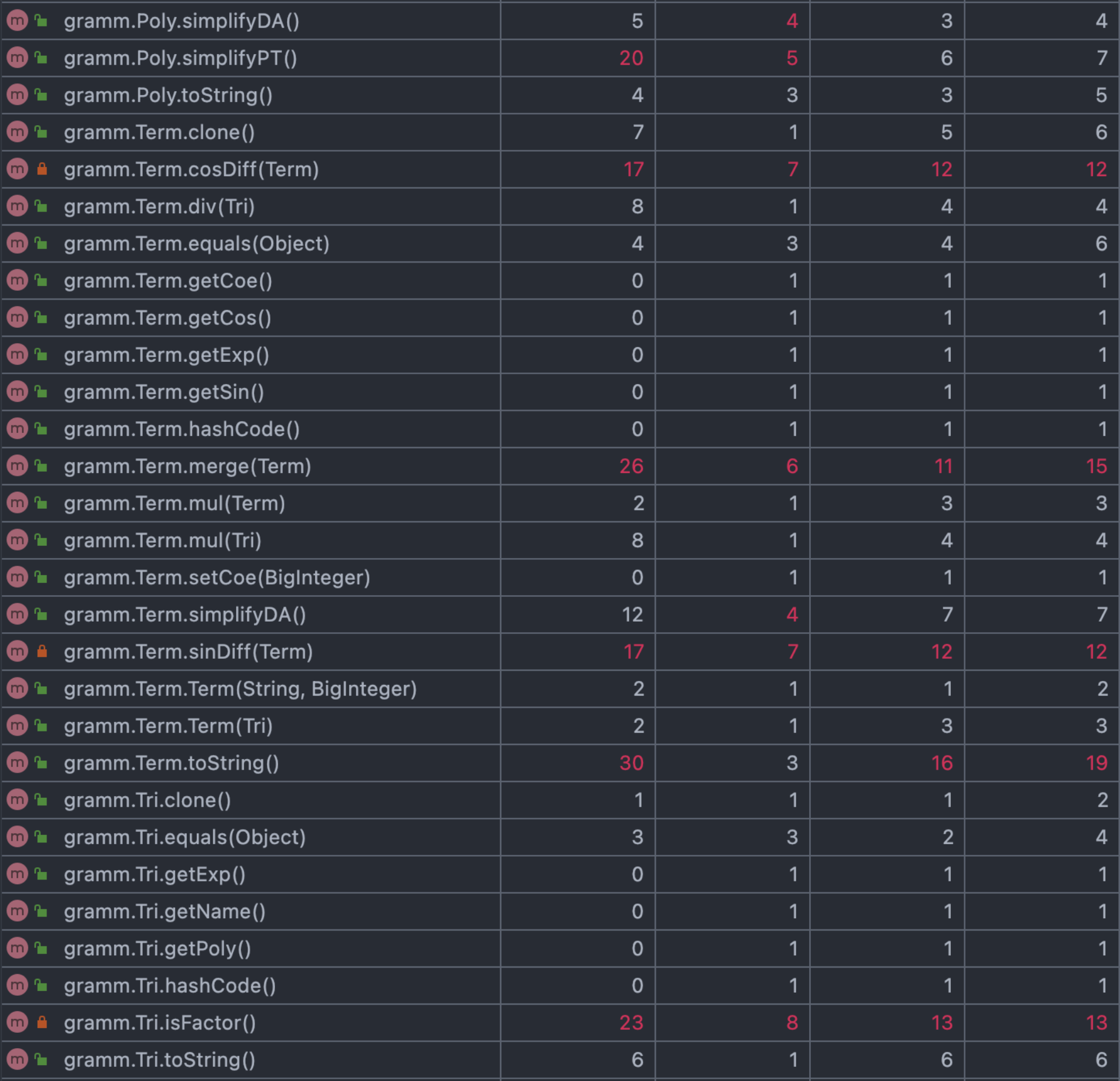
本次作业我做了勾股定理(Pythagorean theorem),优化asin(x)**2+bcos(x)**2与二倍角(Double angle),优化2**n*sin(x)**n*cos(x)**n
上图中复杂度较高的部分都是我用于化简的部分,因此带来了较高的复杂度我认为是难以避免的。同时我设计了全局优化开关,可以通过开关控制是否优化,因此若是优化部分出锅可以通过关闭全局优化开关简单解决
测试
本单元三次作业我采用了两种不同的测试方案。
随机生成普通数据
第一次作业特殊情况与优化较少,边缘数据使用随机生成的数据可以达到较好的覆盖,因此我使用java内置随机数生成随机生成数据进行测试。随机数生成的过程实际就是解析的逆过程,可以称之为“递归上升法”句法构造,生成的数据也可以通过参数的设置完成customerize。
//随机数据生成
import java.util.Random;
public class Generater {
public static final int MAX_RECURSION_DEPTH = 1;
public static final int MAX_FACTOR_COUNT = 100;
public static final int MAX_POLY_INDEX = 20;
public static final int MAX_POWER_INDEX = 20;
private static final int MAX_NUM_LEN = 5;
private Random random;
public Generater() { this.random = new Random();}
//最长长度与长度等级
public String generatePoly(int maxLen, int lenLvl, int curdepth) {
StringBuilder sb = new StringBuilder();
int r = random.nextInt();
if (r % 3 == 0) { sb.append('+'); }
else if (r % 3 == 1) { sb.append('-'); }
sb.append(generateTerm(maxLen * 2 / 3, lenLvl - 1, curdepth));
String s = generateTerm(maxLen * 2 / 3, lenLvl - 1, curdepth);
// 1/EPLL probability of termination each time
while (sb.length() + s.length() + 1 < maxLen && r % lenLvl != 0) {
if (r % 2 == 0) { sb.append('+'); }
else { sb.append('-'); }
sb.append(s);
s = generateTerm(maxLen * 2 / 3, lenLvl - 1, curdepth);
}
return sb.toString();
}
public String generateTerm(int maxLen, int lenLvl, int curdepth) {
StringBuilder sb = new StringBuilder();
int r = random.nextInt();
if (r % 3 == 0) { sb.append('+'); }
else if (r % 3 == 1) { sb.append('-'); }