2. AI 输出内容导出Word!docx4j+poi-tl 实现Markdown转Word全流程
1.简介
我们在上一章介绍了如果想实现将markdown内容转换为word的话, 如果想要转换后的word内容排版好看的话, 就需要将其转换过程分为两步
markdown→htmlhtml→ooxml(Office Open XML) word内容,word元信息本身就是个xml)
上一章节我们使用flexmark将markdown内容转换为html内容, 完成了第一步, 本章节我们将介绍如何将html转换为ooxml
2. 环境信息
为了兼容更多的场景, 所以并没有用一些高版本的SDK, 信息如下
Java: 8
Docx4j: 8.3.10
3. Maven
<properties>
<docx4j.version>8.3.10</docx4j.version>
<jaxb2.version>1.11.1</jaxb2.version>
</properties>
<dependencies>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j-JAXB-Internal</artifactId>
<version>${docx4j.version}</version>
</dependency>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j-ImportXHTML</artifactId>
<version>${docx4j.version}</version>
</dependency>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j-JAXB-MOXy</artifactId>
<version>${docx4j.version}</version>
</dependency>
<dependency>
<groupId>org.jvnet.jaxb2_commons</groupId>
<artifactId>jaxb2-basics</artifactId>
<version>${jaxb2.version}</version>
</dependency>
</dependencies>
4. Html转Docx
import lombok.SneakyThrows;
import org.docx4j.Docx4J;
import org.docx4j.convert.in.xhtml.XHTMLImporterImpl;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.openpackaging.parts.WordprocessingML.MainDocumentPart;
import org.docx4j.wml.Body;
import java.io.File;
/**
* html 2 docx
*
* @author ludangxin
* @since 2025/10/14
*/
public class HtmlToDocx {
@SneakyThrows
public static void convertHtmlToDocx(String htmlContent, String outputFilePath) {
// 创建 Word 文档包
WordprocessingMLPackage wordMLPackage = WordprocessingMLPackage.createPackage();
MainDocumentPart mainDocumentPart = wordMLPackage.getMainDocumentPart();
// 设置 XHTML 导入器
XHTMLImporterImpl XHTMLImporter = new XHTMLImporterImpl(wordMLPackage);
// 将 HTML 内容导入到 Word 文档中
Body body = mainDocumentPart.getJaxbElement().getBody();
body.getContent().addAll(XHTMLImporter.convert(htmlContent, null));
// 保存 Word 文档
Docx4J.save(wordMLPackage, new File(outputFilePath), Docx4J.FLAG_NONE);
}
public static void main(String[] args) {
String html = "<html><head></head><body><h2>嘉文四世</h2>\n" + "<blockquote>\n" + "<p>德玛西亚</p>\n" + "</blockquote>\n" + "<p><strong>给我找些更强的敌人!</strong></p>\n" + "<table>\n" + "<thead>\n" + "<tr><th>列1</th><th>列2</th></tr>\n" + "</thead>\n" + "<tbody>\n" + "<tr><td>数据1</td><td>数据2</td></tr>\n" + "</tbody>\n" + "</table>\n" + "</body></html>";
convertHtmlToDocx(html, "demo.docx");
}
}
测试结果如下:

在根目录生成了docx文件, 文件内容如下
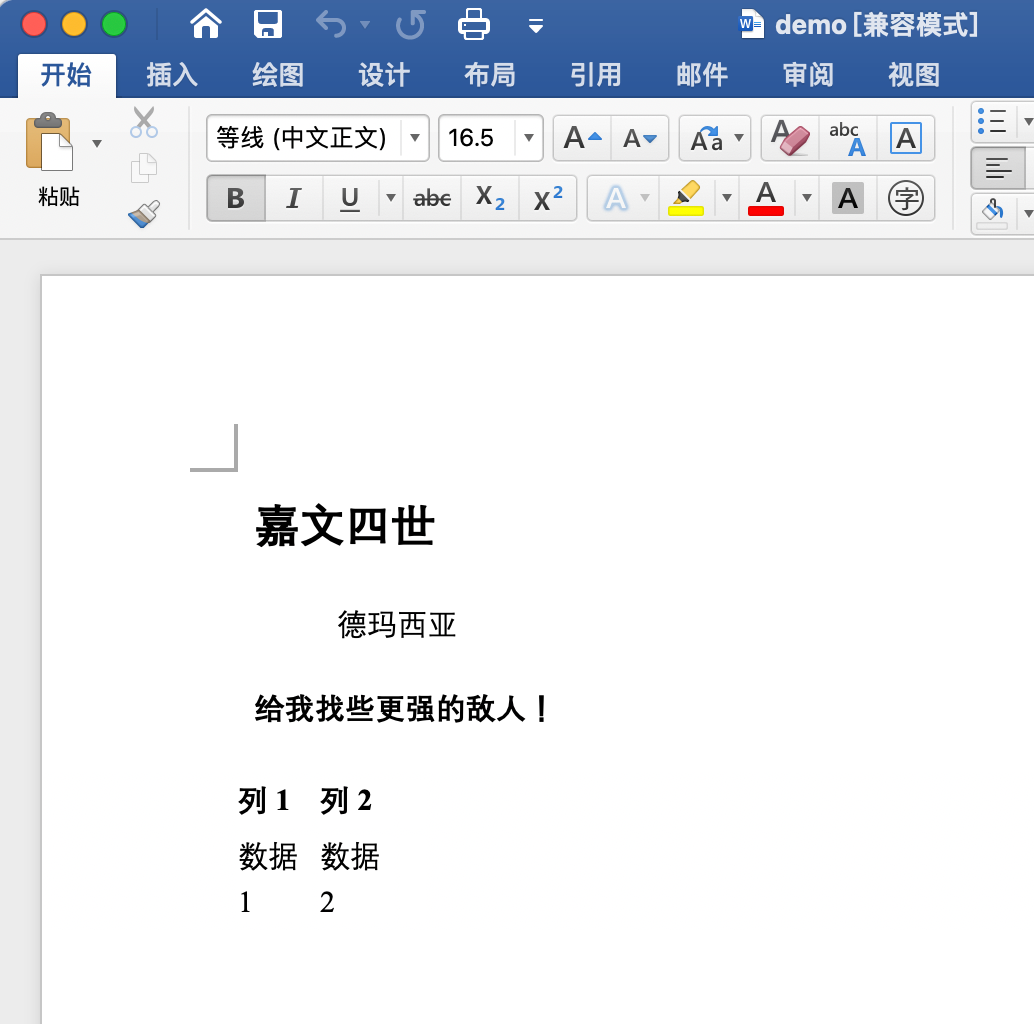
生成的文档内容是有样式的, 只不过像字体样式, 包括表格都是默认样式
但如果项目上要求输出的制式文档或者是模板文件, 对文字标题甚至是表格都有其样式要求的话, 那就得用一些高阶用法了
5. 自定义样式
如果想要自定义输出的内容样式, 其实就两个思路:
- 从输出的内容出发: 毕竟是html转的ooxml, 那么可以给html添加css样式给docx4j进行渲染, 但前提是一些简单的css样式
- 从word出发: word文件本身就有内置样式并且也可以自定义样式, 所以可以先在模板文件中定义好样式, 然后和输入的内容进行映射
5.1 Html添加Css
比如给表格添加样式, 让表格有边框并且有一定的样式,css样式如下:
table{border-collapse:collapse;border-spacing:0;width:100%;margin:1em 0;background-color:transparent;}table th{background-color:#f7f7f7;border:1px solid #ddd;padding:8px 12px;text-align:left}table td{border:1px solid #ddd;padding:8px 12px}
public static void main(String[] args) {
String html = "<html><head><style>table{border-collapse:collapse;border-spacing:0;width:100%;margin:1em 0;background-color:transparent;}table th{background-color:#f7f7f7;border:1px solid #ddd;padding:8px 12px;text-align:left}table td{border:1px solid #ddd;padding:8px 12px}</style></head><body><h2>嘉文四世</h2>\n" + "<blockquote>\n" + "<p>德玛西亚</p>\n" + "</blockquote>\n" + "<p><strong>给我找些更强的敌人!</strong></p>\n" + "<table>\n" + "<thead>\n" + "<tr><th>列1</th><th>列2</th></tr>\n" + "</thead>\n" + "<tbody>\n" + "<tr><td>数据1</td><td>数据2</td></tr>\n" + "</tbody>\n" + "</table>\n" + "</body></html>";
convertHtmlToDocx(html, "demo.docx");
}
测试结果如下:

此时其实如果想要输出的内容样式好看, 通过定义css基本可以满足了, 但如果是制式文档对行间距,字间距,字体型号,标题,等有严格的要求, 如果这些都通过css定义的话 有点麻烦, 毕竟人家制式的文档本身已经定义好了, 那么就可以使用下面的方式
5.2 Html映射WordStyleId
我们可以先看一下word的内置样式, 我这里使用的是mac office,windows 和 wps 有些许差异

从上图中可以看到, word其实是有很多内置样式的, 并且可以新建样式, 下面也可以筛选列表
我们经常在快捷样式列表中选择的样式其实就是从这里来的

我们先手动新增一个自定义的样式 如下:

然后通过docx4j获取所有的wordstyle列表 如下:
private static WordprocessingMLPackage wordMLPackage;
@BeforeAll
@SneakyThrows
public static void init_mainDocumentPart() {
File templateFile = new File("demo.docx");
wordMLPackage = WordprocessingMLPackage.load(templateFile);
}
@Test
@SneakyThrows
public void given_doc_template_when_extract_style_then_return_style_list() {
final StyleDefinitionsPart sdp = wordMLPackage.getMainDocumentPart().getStyleDefinitionsPart();
List<Style> styles = sdp.getContents().getStyle();
log.info("docx styles length: {}", styles.size());
for (Style style : styles) {
String styleId = style.getStyleId();
String name = style.getName().getVal();
final String type = style.getType();
log.info("styleId: {}, name: {}, type: {}", styleId, name, type);
}
}
测试结果如下: 除了内置的样式如一级标题id=1, 最后的两个自定义样式是我们新加的
为什么手动添加了一个, 而出现两个样式记录: 可能是在选在样式类型的时候选择的是“链接段落和字符”导致出现了一对多的情况
[main] INFO html2docx.DocxStyleTest -- docx styles length: 25
[main] INFO html2docx.DocxStyleTest -- styleId: a, name: Normal, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: 1, name: heading 1, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: 2, name: heading 2, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: 3, name: heading 3, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: 4, name: heading 4, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: a0, name: Default Paragraph Font, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: a1, name: Normal Table, type: table
[main] INFO html2docx.DocxStyleTest -- styleId: a2, name: No List, type: numbering
[main] INFO html2docx.DocxStyleTest -- styleId: a3, name: header, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: a4, name: 页眉 字符, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: 10, name: 标题 1 字符, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: 20, name: 标题 2 字符, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: 30, name: 标题 3 字符, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: 40, name: 标题 4 字符, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: a5, name: Normal Indent, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: a6, name: Subtitle, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: a7, name: 副标题 字符, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: a8, name: Title, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: a9, name: 标题 字符, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: aa, name: Emphasis, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: ab, name: Hyperlink, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: ac, name: Table Grid, type: table
[main] INFO html2docx.DocxStyleTest -- styleId: ad, name: caption, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: customBodyText, name: customBodyText, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: customBodyText0, name: customBodyText 字符, type: character
测试的时候发现一个奇怪的问题, 如果没有手动添加样式的话输出的内容如下:
[main] INFO html2docx.DocxStyleTest -- docx styles length: 22
[main] INFO html2docx.DocxStyleTest -- styleId: Normal, name: Normal, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: Heading1, name: heading 1, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: Heading2, name: heading 2, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: Heading3, name: heading 3, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: Heading4, name: heading 4, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: DefaultParagraphFont, name: Default Paragraph Font, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: Header, name: header, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: HeaderChar, name: Header Char, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: Heading1Char, name: Heading 1 Char, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: Heading2Char, name: Heading 2 Char, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: Heading3Char, name: Heading 3 Char, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: Heading4Char, name: Heading 4 Char, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: NormalIndent, name: Normal Indent, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: Subtitle, name: Subtitle, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: SubtitleChar, name: Subtitle Char, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: Title, name: Title, type: paragraph
[main] INFO html2docx.DocxStyleTest -- styleId: TitleChar, name: Title Char, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: Emphasis, name: Emphasis, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: Hyperlink, name: Hyperlink, type: character
[main] INFO html2docx.DocxStyleTest -- styleId: TableGrid, name: Table Grid, type: table
[main] INFO html2docx.DocxStyleTest -- styleId: TableNormal, name: Normal Table, type: table
[main] INFO html2docx.DocxStyleTest -- styleId: Caption, name: caption, type: paragraph
可以发现内置的style前后不一致,未添加自定义样式前一级标题的id为“Heading1”, 修改后就成了“1”, 可能是默认生成的文档还是英文的, 当修改保存了之后, 就被系统篡改成中文的了
ok, word样式我们定义好了
现在就通过docx4j应用一下自定义的word样式, 实现思路: 通过html标签的class属性 映射wrod的styleId
首先给html加上class信息如下图:
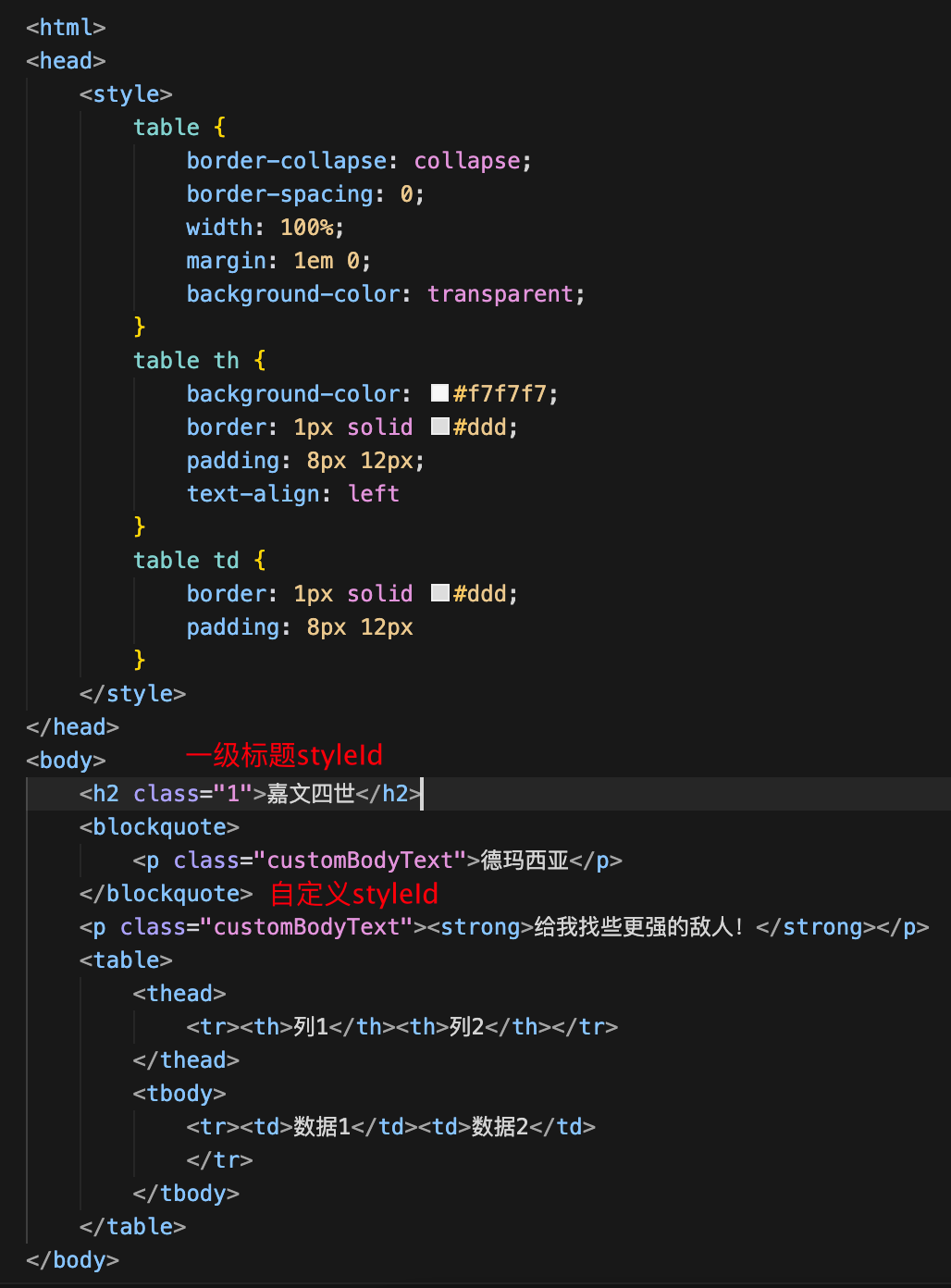
private static WordprocessingMLPackage wordMLPackage;
@BeforeAll
@SneakyThrows
public static void init_mainDocumentPart() {
File templateFile = new File("demo.docx");
wordMLPackage = WordprocessingMLPackage.load(templateFile);
}
@Test
@SneakyThrows
public void given_doc_template_and_class_when_mapping_custom_style_then_render_doc() {
final String html = "<html><head><style>table{border-collapse:collapse;border-spacing:0;width:100%;margin:1em 0;background-color:transparent}table th{background-color:#f7f7f7;border:1px solid#ddd;padding:8px 12px;text-align:left}table td{border:1px solid#ddd;padding:8px 12px}</style></head><body><h2 class=\"1\">嘉文四世</h2><blockquote><p class=\"customBodyText\">德玛西亚</p></blockquote><p class=\"customBodyText\"><strong>给我找些更强的敌人!</strong></p><table><thead><tr><th>列1</th><th>列2</th></tr></thead><tbody><tr><td>数据1</td><td>数据2</td></tr></tbody></table></body></html>";
final MainDocumentPart mainDocumentPart = wordMLPackage.getMainDocumentPart();
XHTMLImporterImpl importer = new XHTMLImporterImpl(wordMLPackage);
// CLASS_TO_STYLE_ONLY:只认 class,不管 style 和 <strong>/<em> 等标签,相当于「纯 CSS 类驱动样式」
// CLASS_PLUS_OTHER:class 是基础样式,style 和内联标签是补充 / 覆盖,相当于「类样式 + 局部微调样式」
// IGNORE_CLASS: 忽略class样式
importer.setParagraphFormatting(FormattingOption.CLASS_TO_STYLE_ONLY);
importer.setRunFormatting(FormattingOption.CLASS_TO_STYLE_ONLY);
importer.setTableFormatting(FormattingOption.CLASS_TO_STYLE_ONLY);
// html转ooxml
final List<Object> docxContent = importer.convert(html, null);
final List<Object> docxOldContent = mainDocumentPart.getContent();
// 清空模板内容 并 添加新的内容
docxOldContent.clear();
docxOldContent.addAll(docxContent);
Docx4J.save(wordMLPackage, new File("newDemo.docx"), Docx4J.FLAG_NONE);
}
测试结果如下:
一级标题和自定义样式都映射完成了

6. 占位符替换
结合上述的功能, 已经能很好的输出html到word中了, 但项目上又有新的需求了, 不光是将markdown→html→word, 还需要将大模型识别到的内容一同输出到模板文件中去, 也就是最终输出的内容有两部分
- 大模型提取到的人员信息, 如姓名工作住址等
- 大模型总结的人员描述信息(markdown)
其实第二步内容使用doc4j已经实现了, 现在需要通过占位符的方式输出人员基本信息到word中, 这个其实很好处理, 可以使用poi-tl实现占位符的替换
6.1 Maven
<dependency>
<groupId>com.deepoove</groupId>
<artifactId>poi-tl</artifactId>
<version>1.12.0</version>
</dependency>
6.2 实现
@Test
public void given_template_doc_and_content_when_replace_then_replace() {
final Configure templateEngineConfigure = Configure.builder().build();
File templateFile = new File("demo.docx");
File outputFile = new File("newDemo.docx");
Map<String, Object> data = new HashMap<>();
data.put("user", "嘉文四世");
data.put("summoner", "张铁牛");
data.put("position", "打野");
data.put("dialogue", "给我找些更强的敌人");
try (XWPFTemplate template = XWPFTemplate.compile(templateFile, templateEngineConfigure)) {
template.render(data).writeToFile(outputFile.getAbsolutePath());
}
catch (IOException e) {
log.error("failed to replace template word placeholder", e);
throw new RuntimeException(e);
}
}
模板内容如下:

测试结果如下:
不仅实现了占位符的替换, 而且也保留了占位符本身的样式, 这就很舒服了

7. 封装工具类
为了更方便的调用docx4j和poi-tl操作word, 我们可以封装一个工具类去更方便的调用, 比如可以通过传入一个map对象然后实现自动替换占位符和markdown内容渲染, 最好是通过链式调用一行代码就解决战斗, 没错 它来了
import com.deepoove.poi.XWPFTemplate;
import com.deepoove.poi.config.Configure;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.docx4j.convert.in.xhtml.FormattingOption;
import org.docx4j.convert.in.xhtml.XHTMLImporterImpl;
import org.docx4j.openpackaging.exceptions.Docx4JException;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.openpackaging.parts.WordprocessingML.MainDocumentPart;
import org.docx4j.wml.Body;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.nio.file.Files;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import java.util.function.BiFunction;
/**
* doc操作工具类
*
* @author ludangxin
* @since 2025/10/14
*/
@Slf4j
public class Docs {
@SneakyThrows
public static DocBuilder builder() {
return new DocBuilder().wordMLPackage(WordprocessingMLPackage.createPackage());
}
@SneakyThrows
public static DocBuilder builder(File file) {
return new DocBuilder().templateInputStream(Files.newInputStream(file.toPath()))
.wordMLPackage(WordprocessingMLPackage.load(file));
}
@SneakyThrows
public static DocBuilder builder(InputStream inputStream) {
return new DocBuilder().templateInputStream(inputStream)
.wordMLPackage(WordprocessingMLPackage.load(inputStream));
}
@SneakyThrows
public static DocBuilder builder(String filePath) {
return new DocBuilder().templateInputStream(Files.newInputStream(new File(filePath).toPath()))
.wordMLPackage(WordprocessingMLPackage.load(new File(filePath)));
}
public static class DocBuilder {
private InputStream templateInputStream;
private WordprocessingMLPackage wordMLPackage;
private XHTMLImporterImpl importer;
private FormattingOption paragraphFormatting;
private FormattingOption runFormatting;
private FormattingOption tableFormatting;
private String staticResourceBaseUri;
private String[] placeHolderPreSuffix = new String[]{"{{", "}}"};
private Configure templateEngineConfigure;
private boolean useHtmlDefaultStyle = true;
private boolean autoCloseStream = true;
private String globalCss = "table{border-collapse:collapse;border-spacing:0;width:100%;margin:1em 0;background-color:transparent;}table th{background-color:#f7f7f7;border:1px solid #ddd;padding:8px 12px;text-align:left}table td{border:1px solid #ddd;padding:8px 12px}";
/**
* <String, String, String>: htmlContent htmlKey resultHtmlContent
*/
private BiFunction<String, String, String> htmlContentProcessor;
private DocBuilder templateInputStream(InputStream templateInputStream) {
this.templateInputStream = templateInputStream;
return this;
}
private DocBuilder wordMLPackage(WordprocessingMLPackage wordMLPackage) {
this.wordMLPackage = wordMLPackage;
return this;
}
public DocBuilder importer(XHTMLImporterImpl importer) {
this.importer = importer;
return this;
}
public DocBuilder paragraphFormatting(FormattingOption paragraphFormatting) {
this.paragraphFormatting = paragraphFormatting;
return this;
}
public DocBuilder runFormatting(FormattingOption runFormatting) {
this.runFormatting = runFormatting;
return this;
}
public DocBuilder tableFormatting(FormattingOption tableFormatting) {
this.tableFormatting = tableFormatting;
return this;
}
public DocBuilder useHtmlDefaultStyle(boolean useHtmlDefaultStyle) {
this.useHtmlDefaultStyle = useHtmlDefaultStyle;
return this;
}
public DocBuilder staticResourceBaseUri(String staticResourceBaseUri) {
this.staticResourceBaseUri = staticResourceBaseUri;
return this;
}
public DocBuilder placeHolderPreSuffix(String placeHolderPrefix, String placeHolderSuffix) {
this.placeHolderPreSuffix = new String[]{placeHolderPrefix, placeHolderSuffix};
return this;
}
public DocBuilder templateEngineConfigure(Configure templateEngineConfigure) {
this.templateEngineConfigure = templateEngineConfigure;
return this;
}
public DocBuilder autoCloseStream(boolean autoCloseStream) {
this.autoCloseStream = autoCloseStream;
return this;
}
public DocBuilder globalCss(String globalCss) {
this.globalCss = globalCss;
return this;
}
public DocBuilder htmlContentProcessor(BiFunction<String, String, String> htmlContentProcessor) {
this.htmlContentProcessor = htmlContentProcessor;
return this;
}
public List<Object> buildWordML(String html) {
return this.buildWordML(html, null);
}
public void buildWord(String html, String outputFile) {
this.buildWord(html, new File(outputFile));
}
public void buildWord(String html, File outputFile) {
try {
this.getMainContent()
.addAll(this.buildWordML(html));
wordMLPackage.save(outputFile);
}
catch (Exception e) {
log.error("failed to build word file", e);
throw new RuntimeException(e);
}
}
public void buildWord(String html, OutputStream outputStream) {
try {
this.getMainContent()
.addAll(this.buildWordML(html));
wordMLPackage.save(outputStream);
}
catch (Exception e) {
log.error("failed to build word file", e);
throw new RuntimeException(e);
}
finally {
try {
if (autoCloseStream) {
outputStream.close();
}
}
catch (IOException ignored) {
}
}
}
public void buildWord(Map<String, Object> placeHolderData, OutputStream outputStream) {
try {
// 替换模板中的普通占位符
if (this.checkPlaceHolderDataType(placeHolderData) == 1) {
this.replacePlaceHolder(placeHolderData, outputStream);
}
// 替换模板中包含的html
if (this.checkPlaceHolderDataType(placeHolderData) == 2) {
this.replaceHtmlPlaceHolder(placeHolderData, outputStream);
}
// 替换普通/html占位符
if (this.checkPlaceHolderDataType(placeHolderData) == 3) {
final File tempDocFile = DocUtils.createTempDocFile();
this.replaceHtmlPlaceHolder(placeHolderData, tempDocFile);
this.replacePlaceHolder(placeHolderData, tempDocFile, tempDocFile);
DocUtils.writeAndDeleteFile(tempDocFile, outputStream);
}
}
catch (Exception e) {
log.error("failed to build word file", e);
throw new RuntimeException(e);
}
finally {
try {
if (autoCloseStream) {
outputStream.close();
}
}
catch (IOException ignored) {
}
}
}
public void buildWord(Map<String, Object> placeHolderData, File outputFile) {
// 替换模板中的普通占位符
if (this.checkPlaceHolderDataType(placeHolderData) == 1) {
this.replacePlaceHolder(placeHolderData, outputFile);
}
// 替换模板中包含的html
if (this.checkPlaceHolderDataType(placeHolderData) > 1) {
this.replaceHtmlPlaceHolder(placeHolderData, outputFile);
}
// 追加替换普通占位符
if (this.checkPlaceHolderDataType(placeHolderData) == 3) {
this.replacePlaceHolder(placeHolderData, outputFile, outputFile);
}
}
private List<Object> buildWordML(String html, String htmlKey) {
final XHTMLImporterImpl importer = this.getImporterOrDefault();
try {
if (globalCss != null && !globalCss.isEmpty()) {
html = DocUtils.addHtmlStyles(html, globalCss);
}
if (htmlContentProcessor != null) {
html = htmlContentProcessor.apply(html, htmlKey);
}
return importer.convert(html, staticResourceBaseUri);
}
catch (Exception e) {
log.error("failed to convert HTML to XHTML", e);
throw new RuntimeException(e);
}
}
private void replaceHtmlPlaceHolder(Map<String, Object> placeHolderData, File outputFile) {
this.doReplaceHtmlPlaceHolder(placeHolderData);
try {
// 替换html
wordMLPackage.save(outputFile);
}
catch (Docx4JException e) {
log.error("failed to build word file", e);
throw new RuntimeException(e);
}
}
private void replaceHtmlPlaceHolder(Map<String, Object> placeHolderData, OutputStream outputStream) {
this.doReplaceHtmlPlaceHolder(placeHolderData);
try {
// 替换html
wordMLPackage.save(outputStream);
}
catch (Docx4JException e) {
log.error("failed to build word file", e);
throw new RuntimeException(e);
}
finally {
try {
if (autoCloseStream) {
outputStream.close();
}
}
catch (IOException ignored) {
}
}
}
private void doReplaceHtmlPlaceHolder(Map<String, Object> placeHolderData) {
final List<Object> mainContent = this.getMainContent();
List<Object> newContent = new ArrayList<>();
for (Object p : mainContent) {
String text = DocUtils.extractText(p);
Optional<String> matchedKey = placeHolderData.keySet()
.stream()
.filter(key -> DocUtils.matchPlaceHolder(text, key, placeHolderPreSuffix[0], placeHolderPreSuffix[1]))
.findFirst();
if (matchedKey.isPresent()) {
String key = matchedKey.get();
Object value = placeHolderData.get(key);
if (DocUtils.isHtml(value)) {
final List<Object> wordFragment = this.buildWordML((String) value, key);
newContent.addAll(wordFragment);
}
else {
newContent.add(p);
}
}
else {
newContent.add(p);
}
}
// 替换模板内容
mainContent.clear();
mainContent.addAll(newContent);
}
private void replacePlaceHolder(Map<String, Object> data, File templateFile, File outputFile) {
final Configure templateEngineConfigure = this.getTemplateEngineConfigureOrDefault();
try (XWPFTemplate template = XWPFTemplate.compile(templateFile, templateEngineConfigure)){
template.render(data)
.writeToFile(outputFile.getAbsolutePath());
}
catch (IOException e) {
log.error("failed to replace template word placeholder", e);
throw new RuntimeException(e);
}
}
public void replacePlaceHolder(Map<String, Object> data, File outputFile) {
final Configure templateEngineConfigure = this.getTemplateEngineConfigureOrDefault();
if (templateInputStream == null) {
throw new NullPointerException("template file can not be null");
}
XWPFTemplate template = XWPFTemplate.compile(templateInputStream, templateEngineConfigure);
try {
template.render(data)
.writeToFile(outputFile.getAbsolutePath());
}
catch (IOException e) {
log.error("failed to replace template word placeholder", e);
throw new RuntimeException(e);
}
}
public void replacePlaceHolder(Map<String, Object> data, String outputFileAbsolutePath) {
final Configure templateEngineConfigure = this.getTemplateEngineConfigureOrDefault();
if (templateInputStream == null) {
throw new NullPointerException("template file can not be null");
}
XWPFTemplate template = XWPFTemplate.compile(templateInputStream, templateEngineConfigure);
try {
template.render(data)
.writeToFile(outputFileAbsolutePath);
}
catch (IOException e) {
log.error("failed to replace template word placeholder", e);
throw new RuntimeException(e);
}
}
public void replacePlaceHolder(Map<String, Object> data, OutputStream outputStream) {
final Configure templateEngineConfigure = this.getTemplateEngineConfigureOrDefault();
if (templateInputStream == null) {
throw new NullPointerException("template file can not be null");
}
try {
XWPFTemplate template = XWPFTemplate.compile(templateInputStream, templateEngineConfigure);
final XWPFTemplate render = template.render(data);
render.write(outputStream);
}
catch (IOException e) {
log.error("failed to replace template word placeholder", e);
throw new RuntimeException(e);
}
finally {
try {
if (autoCloseStream) {
outputStream.close();
}
}
catch (IOException ignored) {
}
}
}
private XHTMLImporterImpl getImporterOrDefault() {
if (importer == null) {
if (paragraphFormatting != null || runFormatting != null || tableFormatting != null) {
XHTMLImporterImpl importer = new XHTMLImporterImpl(wordMLPackage);
importer.setParagraphFormatting(paragraphFormatting == null ? FormattingOption.CLASS_PLUS_OTHER : paragraphFormatting);
importer.setRunFormatting(runFormatting == null ? FormattingOption.CLASS_PLUS_OTHER : runFormatting);
importer.setTableFormatting(tableFormatting == null ? FormattingOption.CLASS_PLUS_OTHER : tableFormatting);
return importer;
}
else {
return this.defaultImporter();
}
}
else {
return this.importer;
}
}
private Configure getTemplateEngineConfigureOrDefault() {
if (templateEngineConfigure == null) {
return this.defaultTemplateEngineConfigure();
}
else {
return this.templateEngineConfigure;
}
}
private Configure defaultTemplateEngineConfigure() {
return Configure.builder()
.buildGramer(placeHolderPreSuffix[0], placeHolderPreSuffix[1])
.build();
}
private XHTMLImporterImpl defaultImporter() {
XHTMLImporterImpl importer = new XHTMLImporterImpl(wordMLPackage);
if (useHtmlDefaultStyle) {
importer.setParagraphFormatting(FormattingOption.CLASS_PLUS_OTHER);
importer.setRunFormatting(FormattingOption.CLASS_PLUS_OTHER);
importer.setTableFormatting(FormattingOption.CLASS_PLUS_OTHER);
}
else {
importer.setParagraphFormatting(FormattingOption.CLASS_TO_STYLE_ONLY);
importer.setRunFormatting(FormattingOption.CLASS_TO_STYLE_ONLY);
importer.setTableFormatting(FormattingOption.CLASS_TO_STYLE_ONLY);
}
return importer;
}
private List<Object> getMainContent() {
MainDocumentPart mainDocumentPart = wordMLPackage.getMainDocumentPart();
if (globalCss != null && !globalCss.isEmpty()) {
mainDocumentPart.getStyleDefinitionsPart()
.setCss(globalCss);
}
Body body = mainDocumentPart.getJaxbElement()
.getBody();
return body.getContent();
}
/**
* 判断占位符数据类型
*
* @param placeHolderData 占位符数据
* @return 1: 数据不包含html 2: 数据全是html 3: 都包含
*/
private int checkPlaceHolderDataType(Map<String, Object> placeHolderData) {
boolean hasHtmlValFlag = false;
boolean hasCommonValFlag = false;
for (Object value : placeHolderData.values()) {
if (DocUtils.isHtml(value)) {
hasHtmlValFlag = true;
}
else {
hasCommonValFlag = true;
}
}
if (!hasHtmlValFlag && hasCommonValFlag) {
return 1;
}
if (hasHtmlValFlag && !hasCommonValFlag) {
return 2;
}
return 3;
}
}
}
8. 测试示例
import lombok.SneakyThrows;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import java.io.File;
import java.io.OutputStream;
import java.nio.file.Files;
import java.util.HashMap;
import java.util.Map;
/**
* docs test
*
* @author ludangxin
* @since 2025/11/4
*/
public class DocxTest {
private static final File TEMPLATE_FILE = new File("demo.docx");
private static final File OUTPUT_FILE = new File("output.docx");
private static final Map<String, Object> DATA = new HashMap<>();
@BeforeAll
public static void given_data() {
DATA.put("user", "嘉文四世");
DATA.put("summoner", "张铁牛");
DATA.put("position", "打野");
DATA.put("dialogue", "给我找些更强的敌人");
final String markdownContent = "- **背景故事**:嘉文四世是德玛西亚国王嘉文三世的独生子,其母凯瑟琳女士因难产而死。嘉文在宫廷中长大,接受了良好的德玛西亚式教育,并结识了赵信,向其学习战争艺术。他与盖伦年龄相仿,结为好兄弟。嘉文曾率军前往边境对抗诺克萨斯,却因战力分散而战败,幸得希瓦娜相救。后来,德玛西亚国内搜魔人兵团搜捕魔法师引发起义,嘉文三世惨遭弑杀,嘉文四世接掌了议会,之后他登基成为德玛西亚国王。\n" + "\n" + "- **角色定位**:在游戏中,嘉文四世的定位是坦克、战士,他常常需要带头冲入敌方阵地,因此相比输出更加需要增强防御能力。\n" + "\n" + "- 技能介绍\n" + " :\n" + " - **被动技能 - 战争律动**:普攻命中时,会对目标造成 8% 当前生命值的额外物理伤害,该效果作用于同一目标的冷却时间为 6 秒。\n" + " - **一技能 - 巨龙撞击**:用长矛穿透路径上的敌人,对其造成物理伤害,并减少其护甲,持续 3 秒。若长矛触及 “德邦军旗”,嘉文四世会被引向军旗,并击飞沿途敌人 0.75 秒。\n" + " - **二技能 - 黄金圣盾**:释放出一道帝王光环,使周围敌人减速,持续 2 秒,同时提供一个可以吸收伤害的护盾,持续 5 秒,附近每多一名敌方英雄,吸收伤害增加。\n" + " - **三技能 - 德邦军旗**:投掷一柄军旗,对敌人造成魔法伤害,并将军旗置于原地 8 秒,使附近队友获得攻击速度加成。在 “德邦军旗” 附近再次点击施放该技能,将会朝军旗施放 “巨龙撞击”。\n" + " - **终极技能 - 天崩地裂**:跃向敌方英雄,对目标及其附近的敌人造成物理伤害,并在目标周围形成环形障碍,持续 3.5 秒,再次点击施放可使障碍倒塌。\n" + "\n" + "- **皮肤信息**:嘉文四世拥有多款皮肤,包括孤胆英豪、暗星、福牛守护者等。";
// markdown 2 html (上一章博客的内容)
final String htmlContent = Markdowns.builder(markdownContent)
.buildHtmlContent();
DATA.put("description", htmlContent);
}
@Test
public void given_template_doc_and_content_when_replace_then_complete() {
Docs.builder(TEMPLATE_FILE).buildWord(DATA, OUTPUT_FILE);
}
@Test
@SneakyThrows
public void given_template_doc_and_content_when_replace_and_output_stream_then_complete() {
final OutputStream fileOutputStream = Files.newOutputStream(OUTPUT_FILE.toPath());
// 接收输出流
Docs.builder(TEMPLATE_FILE).autoCloseStream(true).buildWord(DATA, fileOutputStream);
}
}
模板内容如下:

测试结果如下:

9. 小结
本章使用docx4j和poi-tl实现将普通占位符内容和html文本内容转换为word, 并介绍了如何使用其特性实现自定义样式渲染, 最后封装链式调用的工具类和对应的单元测试代码, 结合上一章内容能够将各种形式的内容通过一行代码即可实现word的渲染
10. 源码
测试过程中的代码已全部上传至github, 欢迎点赞收藏 仓库地址: https://github.com/ludangxin/markdown2docx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号