Redis-缓存穿透/击穿/雪崩
1. 简介
如图所示,一个正常的请求
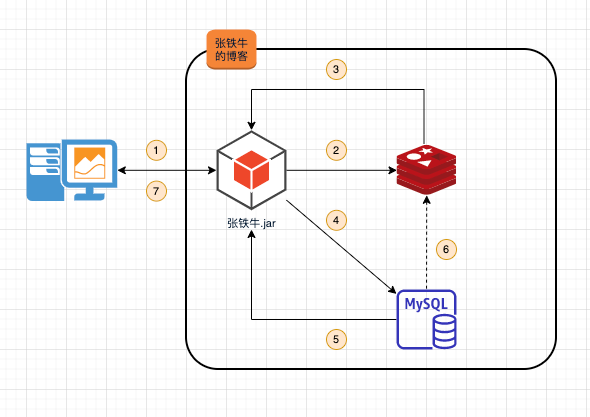
- 客户端请求张铁牛的博客。
- 服务首先会请求redis,查看请求的内容是否存在。
- redis将请求结果返回给服务,如果返回的结果有数据则执行
7;如果没有数据则会继续往下执行。 - 服务从数据库中查询请求的数据。
- 数据库将查询的结果返回给服务。
- 如果数据库有返回数据,则将返回的结果添加到redis。
- 将请求到的数据返回给客户端。
2. 缓存穿透
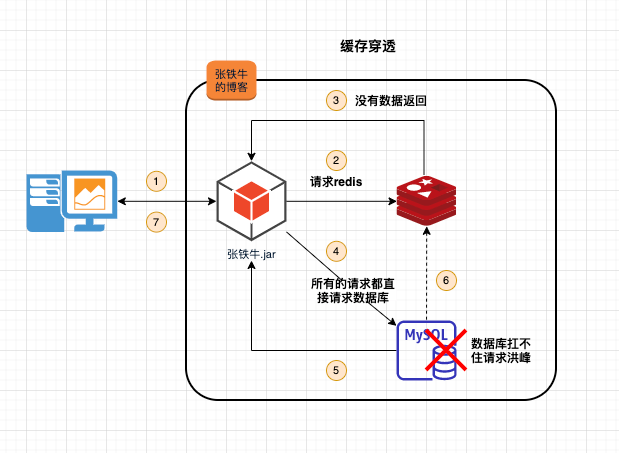
2.1描述
通过接口访问一个缓存和数据库都不存在的数据。
因为服务出于容错考虑,当请求从持久层查不到数据则不写入缓存,这将导致请求这个不存在的数据每次都要到持久层去查询,失去了缓存的意义。
此时,缓存起不到保护后端持久层的意义,就像被穿透了一样。导致数据库存在被打挂的风险。
2.2 解决方案
- 接口请求参数的校验。对请求的接口进行鉴权,数据合法性的校验等;比如查询的userId不能是负值或者包含非法字符等。
- 当数据库返回空值时,将空值缓存到redis,并设置合理的过期时间。
- 布隆过滤器。使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。
3. 缓存击穿
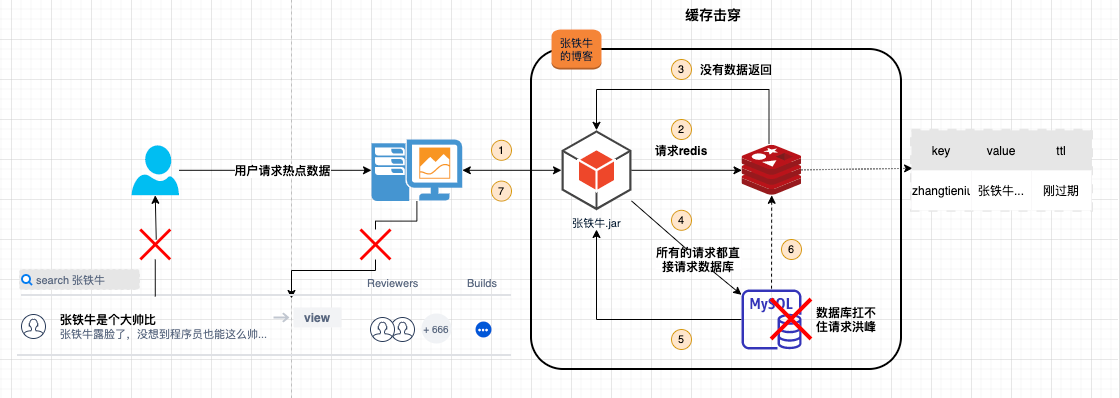
3.1 描述
某个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,导致数据库存在被打挂的风险。
3.2 解决方案
- 加互斥锁。当热点key过期后,大量的请求涌入时,只有第一个请求能获取锁并阻塞,此时该请求查询数据库,并将查询结果写入redis后释放锁。后续的请求直接走缓存。
- 设置缓存不过期或者后台有线程一直给热点数据续期。
4. 缓存雪崩
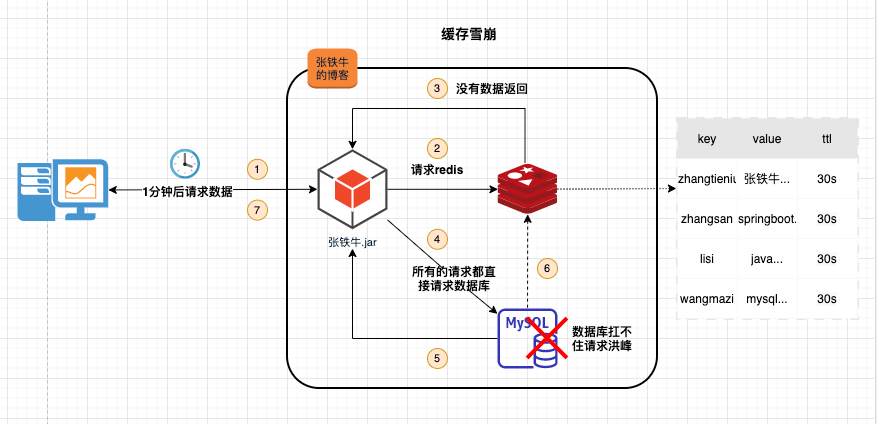
4.1 描述
大量的热点数据过期时间相同,导致数据在同一时刻集体失效。造成瞬时数据库请求量大、压力骤增,引起雪崩,导致数据库存在被打挂的风险。
4.1 解决方案
-
将热点数据的过期时间打散。给热点数据设置过期时间时加个随机值。
-
加互斥锁。当热点key过期后,大量的请求涌入时,只有第一个请求能获取锁并阻塞,此时该请求查询数据库,并将查询结果写入redis后释放锁。后续的请求直接走缓存。
-
设置缓存不过期或者后台有线程一直给热点数据续期。
5. 布隆过滤器
5.1 描述
布隆过滤器是防止缓存穿透的方案之一。布隆过滤器主要是解决大规模数据下不需要精确过滤的业务场景,如检查垃圾邮件地址,爬虫URL地址去重, 解决缓存穿透问题等。
布隆过滤器:在一个存在一定数量的集合中过滤一个对应的元素,判断该元素是否一定不在集合中或者可能在集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
5.2 数据结构
布隆过滤器是基于bitmap和若干个hash算法实现的。如下图所示:
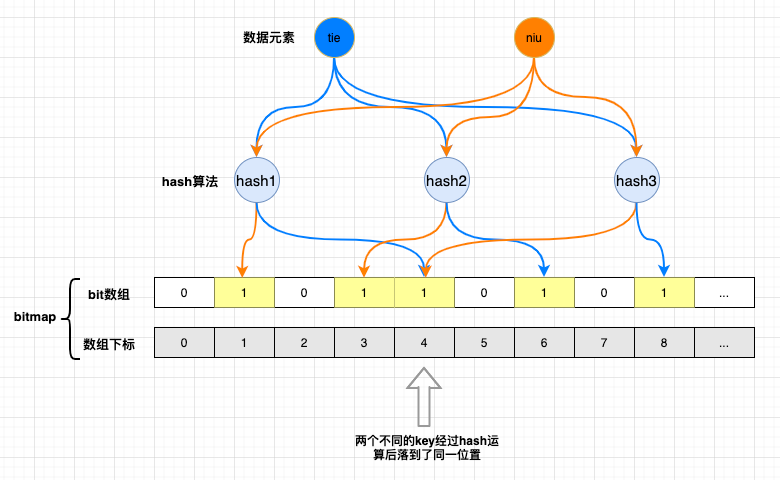
- 元素
tie经过hash1,hash2,hash3运算出对应的三个值落到了数组下标为4,6,8的位置上,并将其位置的默认值0,修改成1。 - 元素
niu同理落到了数组下标为1,3,4的位置上,并将其位置的默认值0,修改成1。
此时bitmap中已经存储了tie,niu数据元素。
当请求想通过布隆过滤器判断tie元素在程序中是否存在时,通过hash运算结果到数组对应下标位置上发现值已经都被置为1,此时返回true。
5.3 “一定不在集合中”
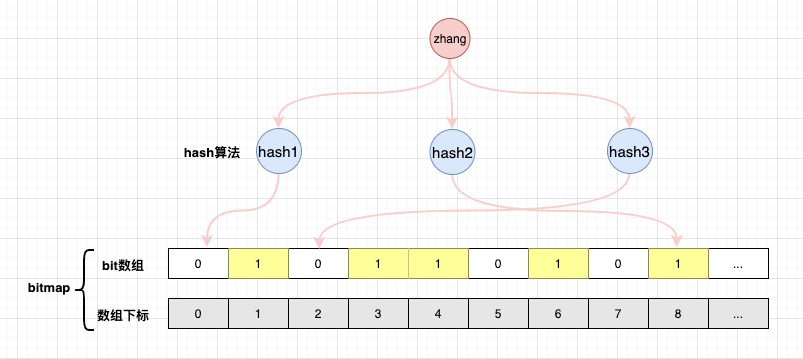
如图所示:
元素zhang通过布隆过滤器判断时,下标0,2都为0,则直接返回false。
也就是当判断不在bitmap中的元素时,经过hash运算得到的结果在bitmap中只要有一个为0,则该数据一定不存在。
5.4 “可能在集合中”
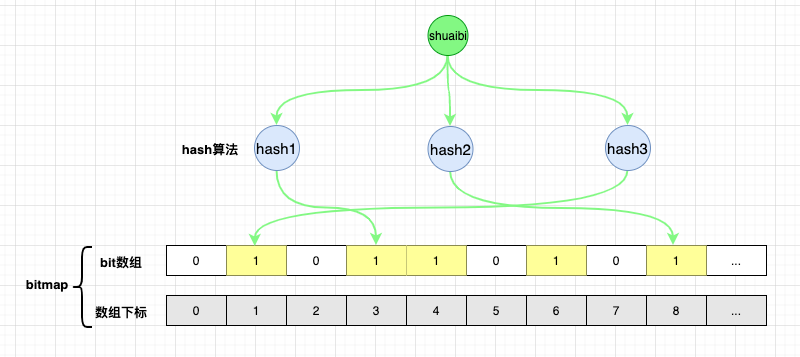
如图所示:
元素shuaibi通过布隆过滤器判断时,hash运算的结果落到了下标1,3,8上,此时对应下标位置的值都为1,则直接返回true。
这下就尴尬了,因为实际程序中并没有数据shuaibi,但布隆过滤器返回的结果显示有这个元素。这就是布隆过滤器的缺点,存在误判情况。
5.5 ”删除困难“
为什么布隆过滤器删除困难呢,如图所示:
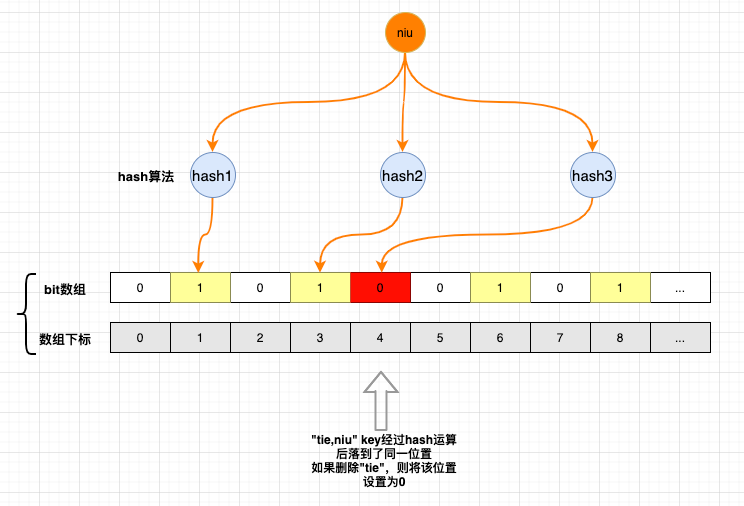
如果删除了“tie”元素,4号位被置为0,则会影响niu元素的判断,因为4号位为0,进行数据校验时返回0,则会认为程序中没有niu元素。
那小伙伴会问,4号位不置为0,行不行?
如果删除了元素,hash碰撞的数组下标不置为0,那么如果继续验证该元素的话,布隆过滤器会继续返回true,但实际上元素已经删除了。
所以布隆过滤器数据删除困难,如果要删除的话,可以参考Counting Bloom Filter。
5.6 为什么不使用HashMap呢?
如果用HashSet或Hashmap存储的话,每一个用户ID都要存成int,占4个字节即32bit。而一个用户在bitmap中只需要1个bit,内存节省了32倍。
并且大数据量会产生大量的hash冲突,结果就是产生hash冲突的数据,仍然会进行遍历挨个比对(即使转成红黑树),这样对内存空间和查询效率的提升,仍然是有限的。
当然:数据量不大时,尽管使用。而且hashmap方便进行CRUD😂

 浙公网安备 33010602011771号
浙公网安备 33010602011771号