
Kafka 数据实时写入 StarRocks:深入解析 Routine Load 任务
本文介绍 Routine Load 的基本原理、以及如何通过 Routine Load 持续消费 Apache Kafka® 的消息并导入至 StarRocks 中。
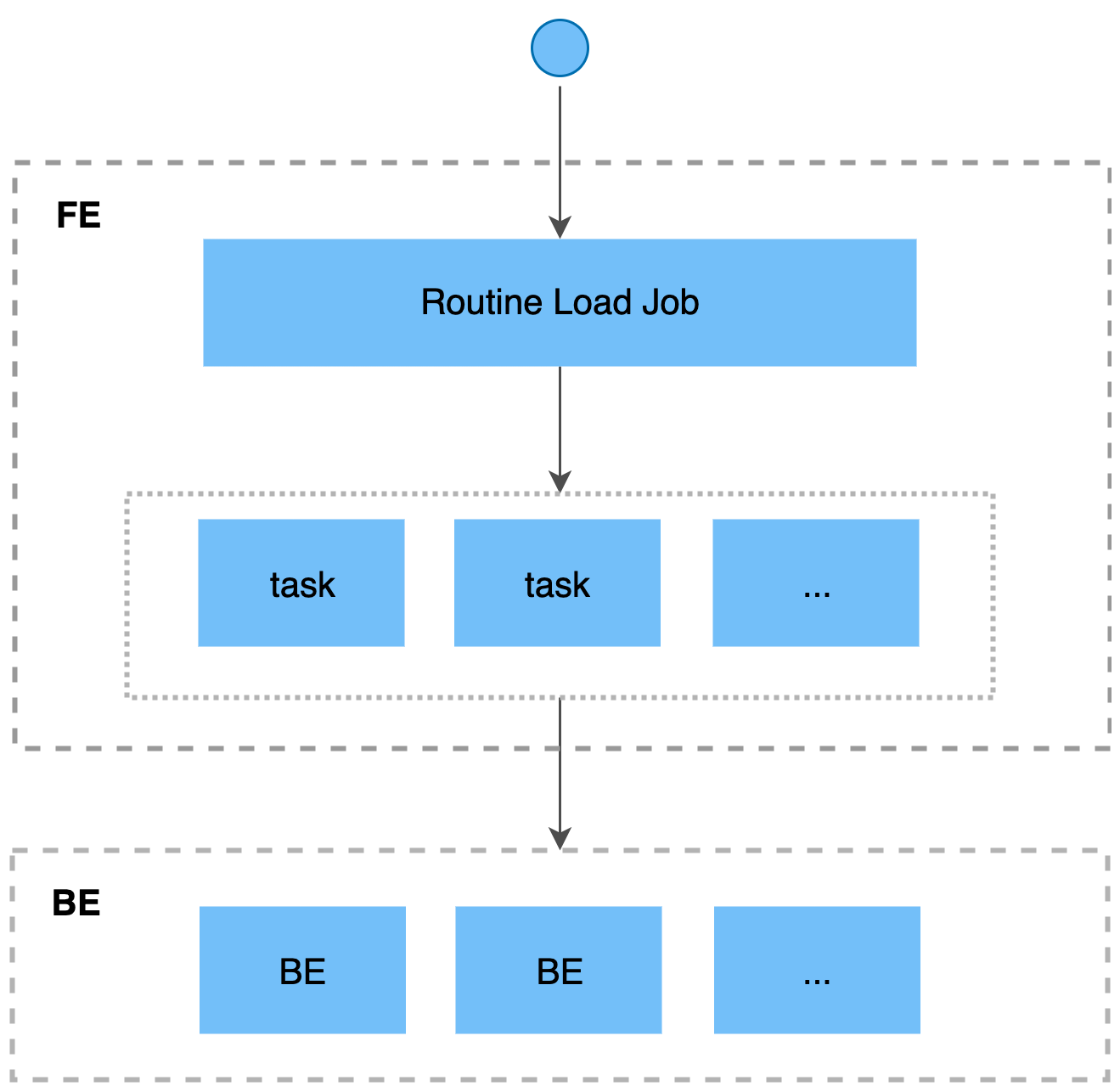
如果您需要将消息流不间断地导入至 StarRocks,则可以将消息流存储在 Kafka 的 Topic 中,并向 StarRocks 提交一个 Routine Load 导入作业。 StarRocks 会常驻地运行这个导入作业,持续生成一系列导入任务,消费 Kafka 集群中该 Topic 中的全部或部分分区的消息并导入到 StarRocks 中。
Routine Load 任务简介
概念
-
导入作业(Load job)
导入作业会常驻运行,当导入作业的状态为 RUNNING 时,会持续不断生成一个或多个并行的导入任务,不断消费 Kafka 集群中一个 Topic 的消息,并导入至 StarRocks 中。
-
导入任务(Load task)
导入作业会按照一定规则拆分成若干个导入任务。导入任务是执行导入的基本单位,作为一个独立的事务,通过 Stream Load 导入机制实现。若干个导入任务并行消费一个 Topic 中不同分区的消息,并导入至 StarRocks 中。
实际操作流程
这里通过简单的示例,介绍如何通过 Routine Load 持续消费 Kafka 中 JSON 格式的数据,并导入至 StarRocks 中。有关创建 Routine Load 的详细语法和参数说明,请参见 CREATE ROUTINE LOAD。
1、创建数据表
CREATE TABLE kafka_table ( id int, name varchar(20) ) ENGINE=OLAP DUPLICATE KEY(id) COMMENT "OLAP" DISTRIBUTED BY HASH(id) BUCKETS 3 PROPERTIES ( "replication_num" = "1", "in_memory" = "false", "storage_format" = "DEFAULT" );
2、创建任务
CREATE ROUTINE LOAD bigdata_test.kafka_table_load ON kafka_table COLUMNS(id,name) PROPERTIES ( "desired_concurrent_number"="3", "max_batch_interval"="20", "max_batch_rows"="300000", "max_batch_size"="209715200", "strict_mode"="false", "format"="json" ) FROM KAFKA ( "kafka_broker_list" = "broker_ip:port", "kafka_topic" = "topic", "kafka_partitions" = "0,1,2" );
3、查看任务状态等信息
show routine load;
-- 查看任务
SHOW ROUTINE LOAD TASK WHERE JobName ='kafka_table_load';
-- 暂停任务
PAUSE ROUTINE LOAD FOR kafka_table_load;
-- 恢复任务
RESUME ROUTINE LOAD FOR kafka_table_load;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号