
Kakfa消费者——原理及分析
consumer 采用 pull(拉)模式从 broker 中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。
pull 模式不足之处是,如果 kafka 没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka 的消费者在消费数据时会传入一个时长参数 timeout,如果当前没有数据可供消费,consumer 会等待一段时间之后再返回,这段时长即为 timeout。
分区分配策略
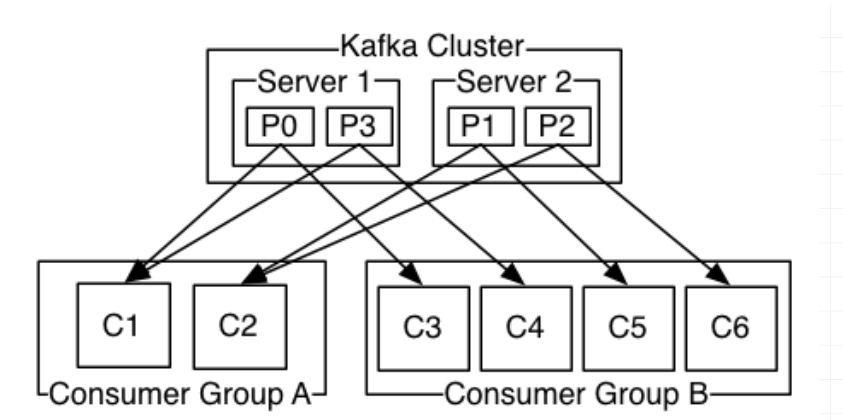
同一时刻,一条消息只能被组中的一个消费者实例消费,消费者组订阅这个主题,意味着主题下的所有分区都会被组中的消费者消费到,如果按照从属关系来说的话就是,主题下的每个分区只从属于组中的一个消费者,不可能出现组中的两个消费者负责同一个分区。如果分区数大于或者等于组中的消费者实例数,那自然没有什么问题,无非一个消费者会负责多个分区,(PS:当然,最理想的情况是二者数量相等,这样就相当于一个消费者负责一个分区);但是,如果消费者实例的数量大于分区数,那么按照默认的策略(PS:之所以强调默认策略是因为你也可以自定义策略),有一些消费者是多余的,一直接不到消息而处于空闲状态。
Kafka 有两种分配策略,一是 RoundRobin,一是 Range。
roundrobin(轮询)
roundronbin分配策略的具体实现是org.apache.kafka.clients.consumer.RoundRobinAssignor
轮询分配策略是基于所有可用的消费者和所有可用的分区的,如果所有的消费者实例的订阅都是相同的,那么这样最好了,可用统一分配,均衡分配
例如,假设有两个消费者C0和C1,两个主题t0和t1,每个主题有3个分区,分别是t0p0,t0p1,t0p2,t1p0,t1p1,t1p2
那么,最终分配的结果是这样的:
C0: [t0p0, t0p2, t1p1]
C1: [t0p1, t1p0, t1p2]
uploading-image-126242.png
假设,组中每个消费者订阅的主题不一样,分配过程仍然以轮询的方式考虑每个消费者实例,但是如果没有订阅主题,则跳过实例。当然,这样的话分配肯定不均衡。也就是说,消费者组是一个逻辑概念,同组意味着同一时刻分区只能被一个消费者实例消费,换句话说,同组意味着一个分区只能分配给组中的一个消费者。事实上,同组也可以不同订阅,这就是说虽然属于同一个组,但是它们订阅的主题可以是不一样的。
例如,假设有3个主题t0,t1,t2;其中,t0有1个分区p0,t1有2个分区p0和p1,t2有3个分区p0,p1和p2;有3个消费者C0,C1和C2;C0订阅t0,C1订阅t0和t1,C2订阅t0,t1和t2。那么,按照轮询分配的话,C0应该负责
首先,肯定是轮询的方式,其次,比如说有主题t0,t1,t2,它们分别有1,2,3个分区,也就是t0有1个分区,t1有2个分区,t2有3个分区;有3个消费者分别从属于3个组,C0订阅t0,C1订阅t0和t1,C2订阅t0,t1,t2;那么,按照轮询分配的话,C0应该负责t0p0,C1应该负责t1p0,其余均由C2负责。
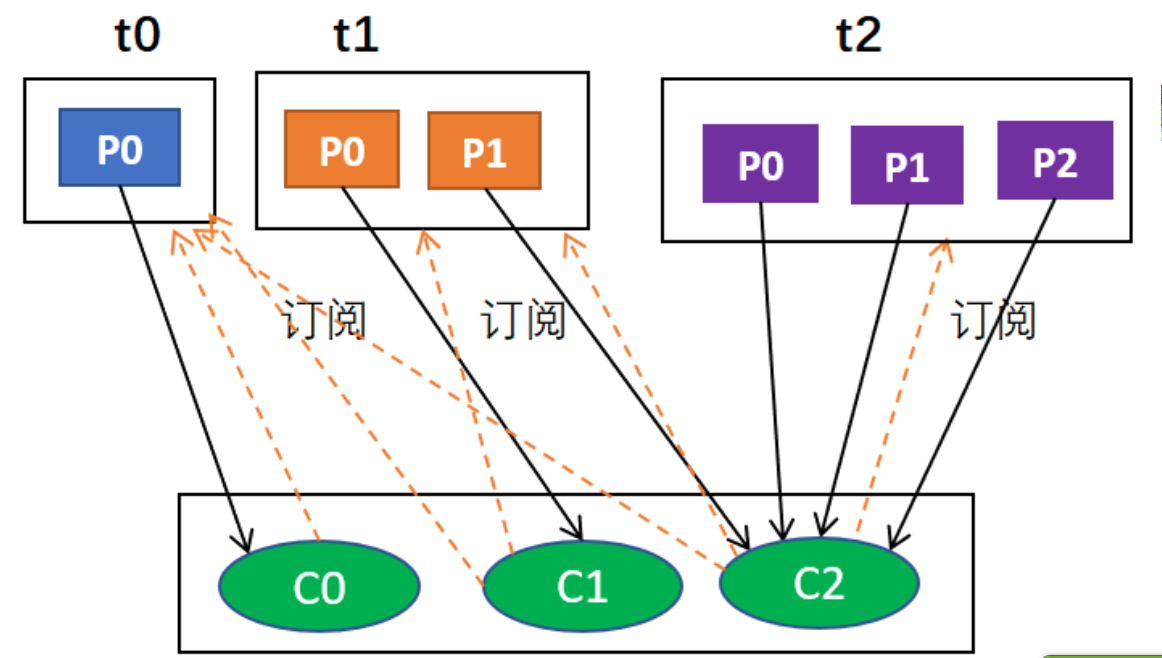
最后的结果是
C0: [t0p0]
C1: [t1p0]
C2: [t1p1, t2p0, t2p1, t2p2]
这是因为,按照轮询t0p1由C0负责,t1p0由C1负责,由于同组,C2只能负责t1p1,由于只有C2订阅了t2,所以t2所有分区由C2负责,综合起来就是这个结果
range
range策略对应的实现类是org.apache.kafka.clients.consumer.RangeAssignor,这是默认的分配策略
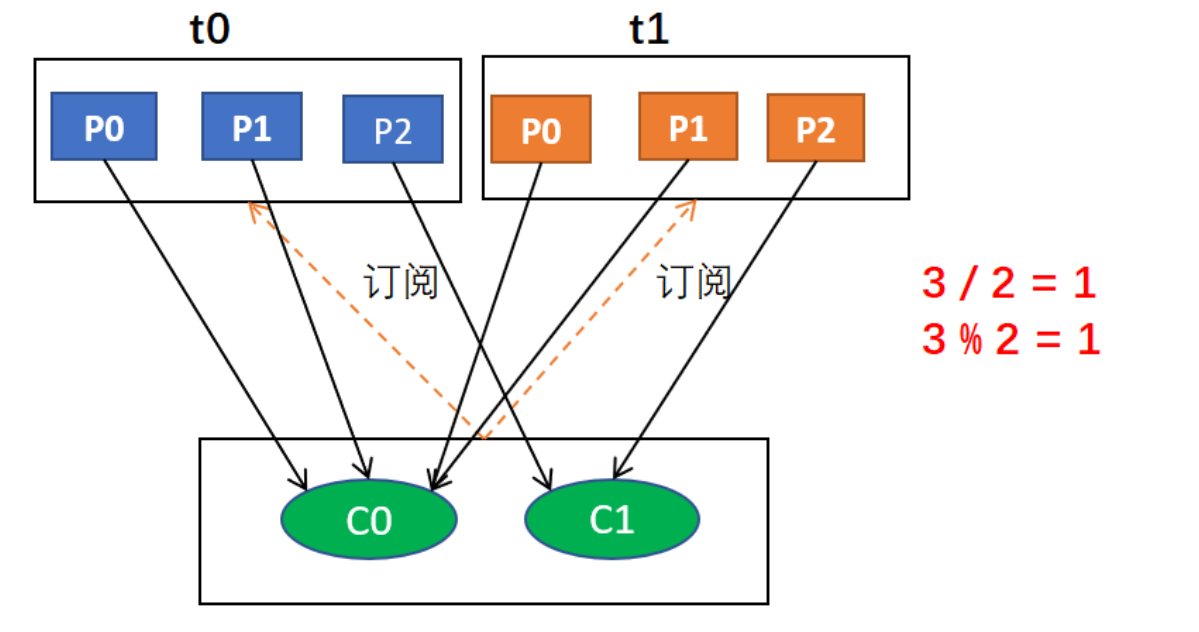
对于每个主题,我们以数字顺序排列可用分区,以字典顺序排列消费者。然后,将分区数量除以消费者总数,以确定分配给每个消费者的分区数量。如果没有平均划分(PS:除不尽),那么最初的几个消费者将有一个额外的分区。
简而言之,就是,
1、range分配策略针对的是主题(PS:也就是说,这里所说的分区指的某个主题的分区,消费者值的是订阅这个主题的消费者组中的消费者实例)
2、首先,将分区按数字顺序排行序,消费者按消费者名称的字典序排好序
3、然后,用分区总数除以消费者总数。如果能够除尽,则皆大欢喜,平均分配;若除不尽,则位于排序前面的消费者将多负责一个分区
例如,假设有两个消费者C0和C1,两个主题t0和t1,并且每个主题有3个分区,分区的情况是这样的:t0p0,t0p1,t0p2,t1p0,t1p1,t1p2
那么,基于以上信息,最终消费者分配分区的情况是这样的:
C0: [t0p0, t0p1, t1p0, t1p1]
C1: [t0p2, t1p2]
offset 的维护
Consumer 消费数据时的可靠性是很容易保证的,因为数据在 Kafka 中是持久化的,故不用担心数据丢失问题
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中,从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为__consumer_offsets。
自动提交 offset
为了使我们能够专注于自己的业务逻辑,Kafka 提供了自动提交 offset 的功能。
自动提交 offset 的相关参数:
enable.auto.commit:是否开启自动提交 offset 功能
auto.commit.interval.ms:自动提交 offset 的时间间隔
手动提交
虽然自动提交 offset 十分简介便利,但由于其是基于时间提交的,开发人员难以把握offset 提交的时机。因此 Kafka 还提供了手动提交 offset 的 API。
手动提交 offset 的方法有两种:分别是 commitSync(同步提交)和 commitAsync(异步提交)。两者的相同点是,都会将本次 poll 的一批数据最高的偏移量提交;不同点是,commitSync 阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而 commitAsync 则没有失败重试机制,故有可能提交失败。
自定义存储 offset
无论是同步提交还是异步提交 offset,都有可能会造成数据的漏消费或者重复消费。先提交 offset 后消费,有可能造成数据的漏消费;而先消费后提交 offset,有可能会造成数据的重复消费。
Kafka 0.9 版本之前,offset 存储在 zookeeper,0.9 版本及之后,默认将 offset 存储在 Kafka的一个内置的 topic 中。除此之外,Kafka 还可以选择自定义存储 offset。 offset 的维护是相当繁琐的,因为需要考虑到消费者的 Rebalace。 当有新的消费者加入消费者组、已有的消费者推出消费者组或者所订阅的主题的分区发生变化,就会触发到分区的重新分配,重新分配的过程叫做 Rebalance。 消费者发生 Rebalance 之后,每个消费者消费的分区就会发生变化。因此消费者要首先获取到自己被重新分配到的分区,并且定位到每个分区最近提交的 offset 位置继续消费。
要实现自定义存储 offset,需要借助 ConsumerRebalanceListener,以下为示例代码,其中提交和获取 offset 的方法,需要根据所选的 offset 存储系统自行实现。
import org.apache.kafka.clients.consumer.*; import org.apache.kafka.common.TopicPartition;
import java.util.*;
public class CustomConsumer {
private static Map<TopicPartition, Long> currentOffset = new HashMap<>();
public static void main(String[] args) {
//创建配置信息
Properties props = new Properties();
//Kafka 集群
props.put("bootstrap.servers", "hadoop102:9092");
//消费者组,只要 group.id 相同,就属于同一个消费者组
props.put("group.id", "test");
//关闭自动提交 offset
props.put("enable.auto.commit", "false");
//Key 和 Value 的反序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//创建一个消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//消费者订阅主题
consumer.subscribe(Arrays.asList("first"), new ConsumerRebalanceListener() {
//该方法会在 Rebalance 之前调用
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) { commitOffset(currentOffset);
}
//该方法会在 Rebalance 之后调用
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
currentOffset.clear();
for (TopicPartition partition : partitions) {
consumer.seek(partition, getOffset(partition));
// 定位到最近提交的 offset 位置继续消费
}
}
});
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
//消费者拉取数据
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); currentOffset.put(new TopicPartition(record.topic(), record.partition()), record.offset());
}
commitOffset(currentOffset);//异步提交
}
}
//获取某分区的最新 offset
private static long getOffset(TopicPartition partition) { return 0; }
//提交该消费者所有分区的 offset
private static void commitOffset(Map<TopicPartition, Long> currentOffset) {
} }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号