


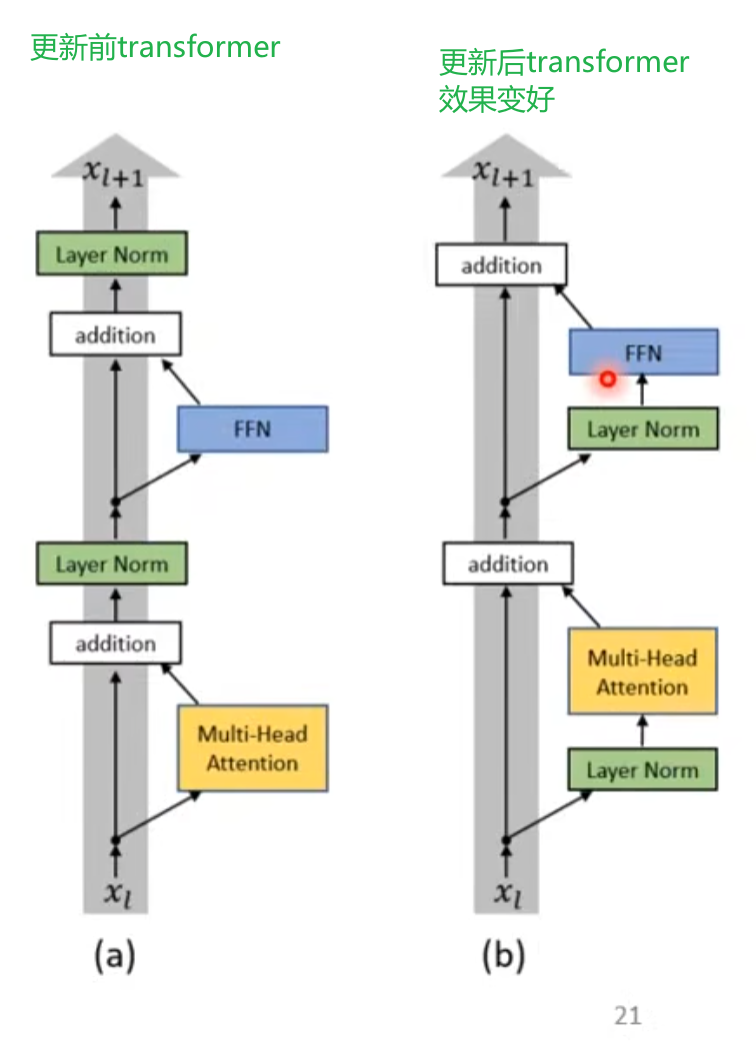
Transformer架构
Transformer架构
Transformer是基于自注意力的序列到序列模型,与RNN的序列到序列模型不同,Transformer支持并行计算。
序列到序列:应用一
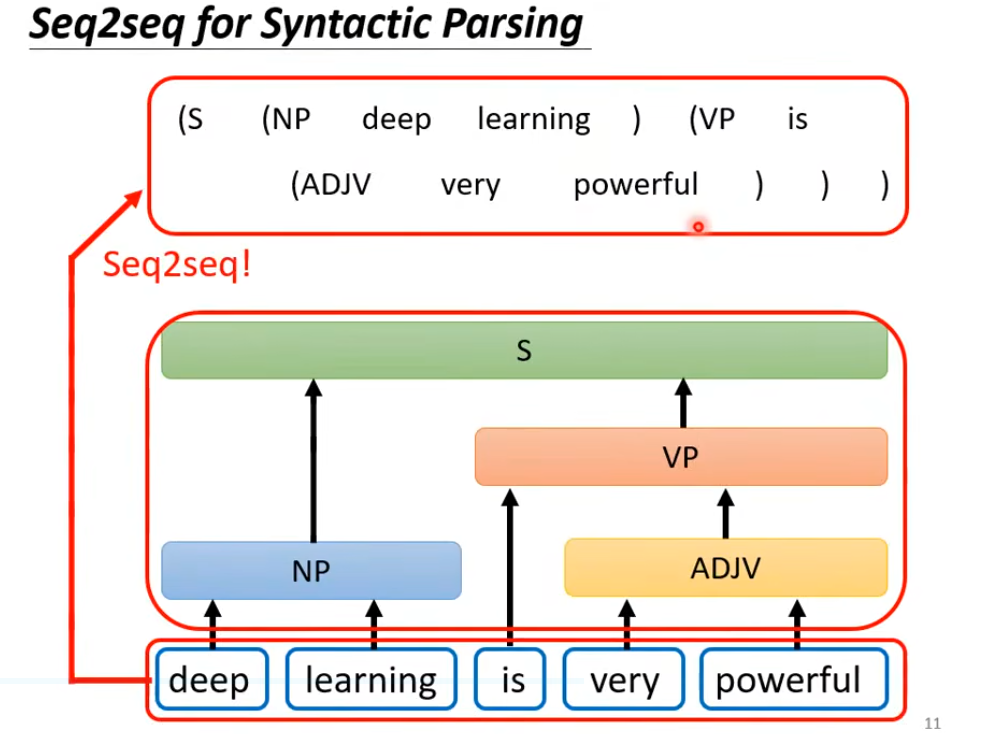
一.Seq2seq的架构
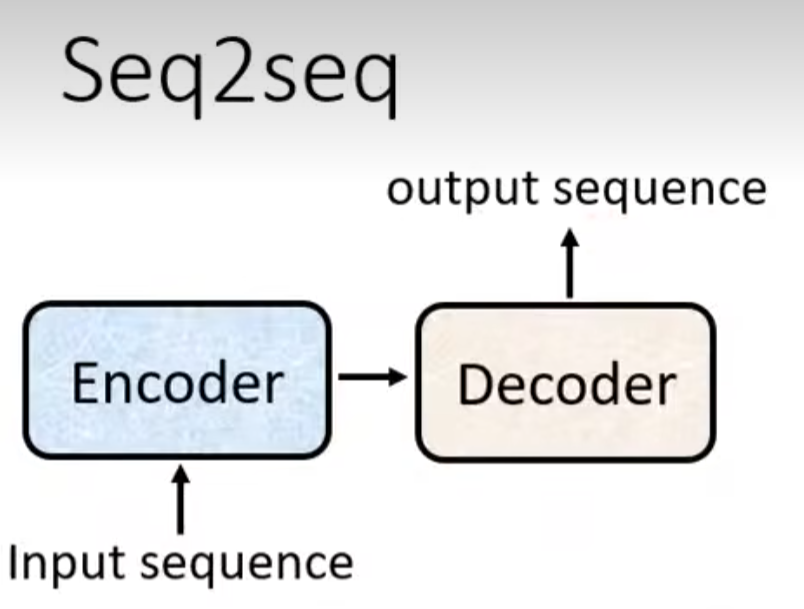
二.Transformer
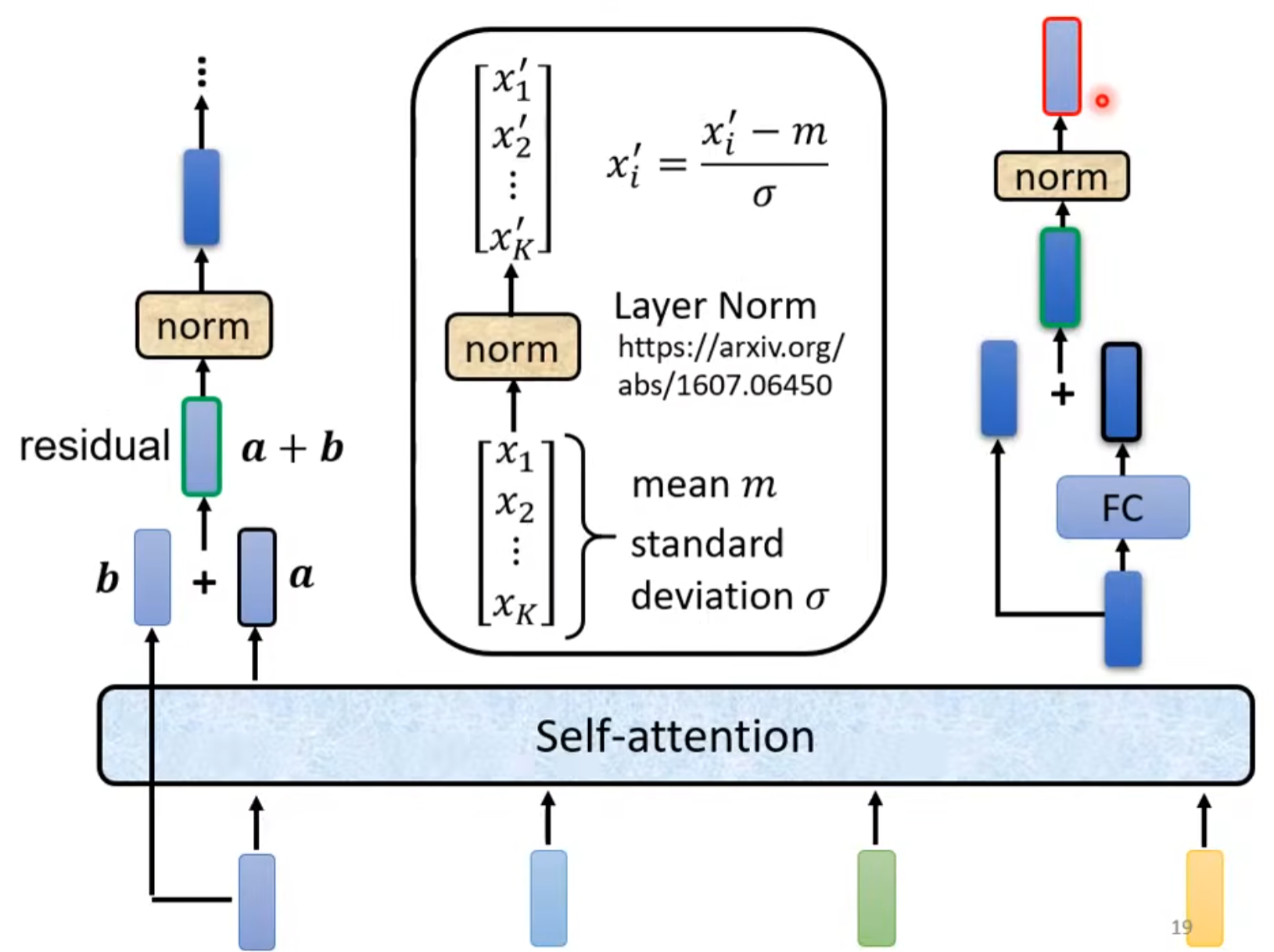
Transformer架构里面的encoder用的是self-attention机制。
(1)编码器encoder
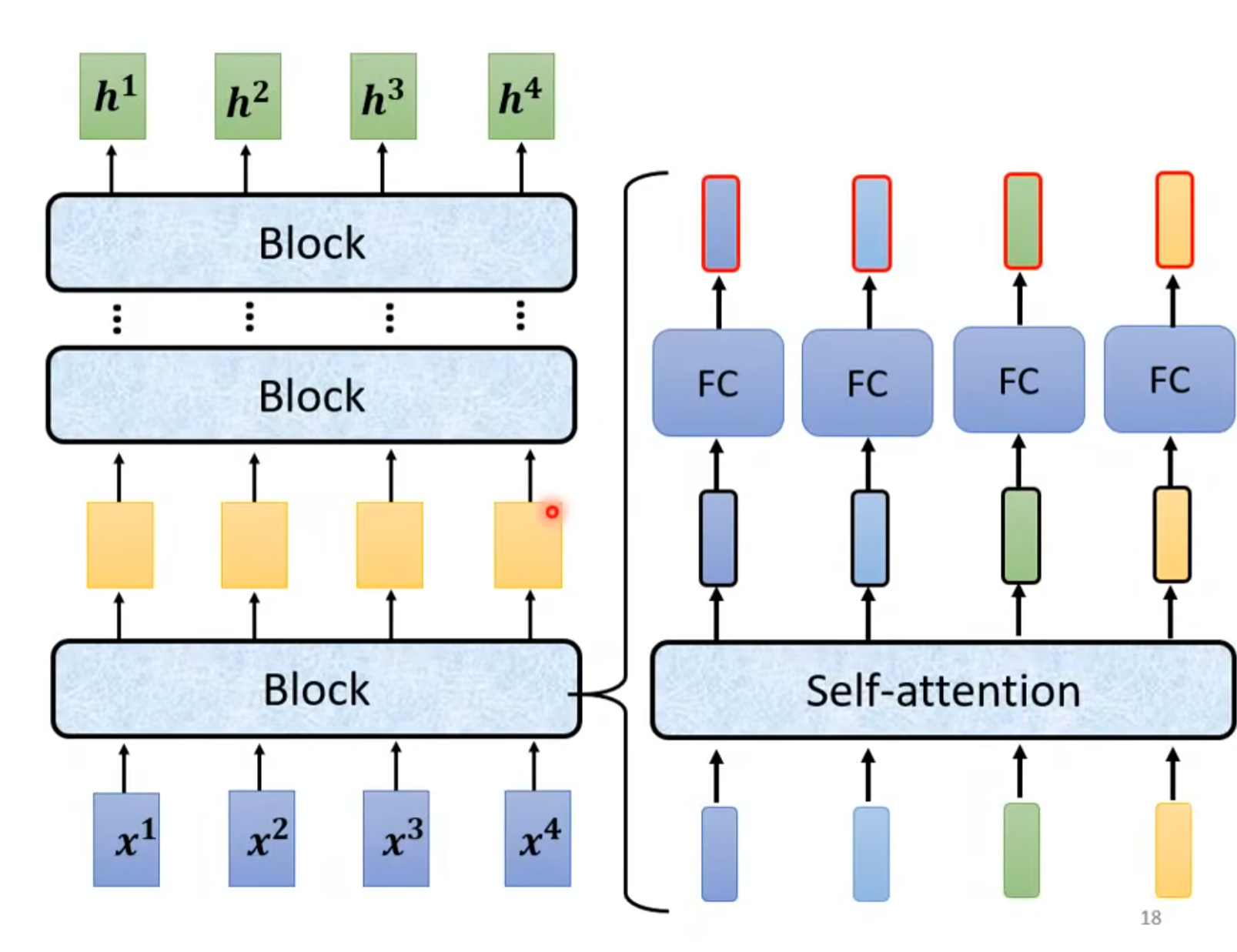
encoder里的架构如上,block不是一层而是有很多层在block里
(2)decoder解码器
自回归解码器
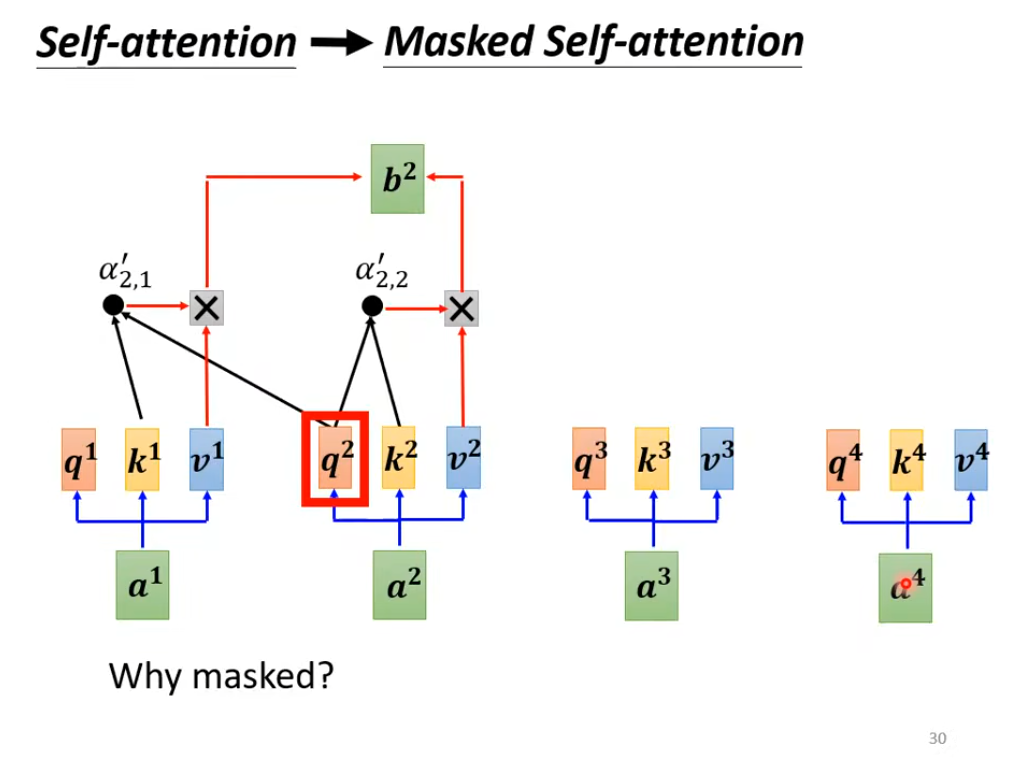
Masked Self-attention:只考虑a1、a2不考虑a3、a4
只能考虑他左边的东西a1、a2
解码器把编码器的输出先"读"进去,要让解码器产生输出,就得给他一个代表开始的特殊符号<BOS>,这是一个特殊的词元(token)。
解码器的输入是它在前一个时间点的输出,它会把自己的输出作为接下来的输入,因此当解码器产生一个句子的时候,它有可能看到错误的内容。比如机器的器识别成天气的气,那么接下来解码器就会根据错误的识别结果产生输出,造成误差传播(error propagation),一步错步步错,从而可能无法再产生正确的结果。
Transformer解码器的详细结构入下图所示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号