

0409 - 大问题分解 Divide and Conquer
前言
我前面总结了一个方法论,就是关于如何克服困难,平衡心态的。
现在再来一个方法论:要分而治之,大问题要学会分解成小问题
https://www.cnblogs.com/luckydoog/p/18816854
我接了一个 riscv 实现 md5 算法的单子
这个单子,其实也不是很好做的,挺有挑战性的。
演示效果
https://www.bilibili.com/video/BV1H6dKYKEYM/
核心方案
特别重要的一点,是要 细分步骤,要把大问题慢慢分解成一个个小问题来做
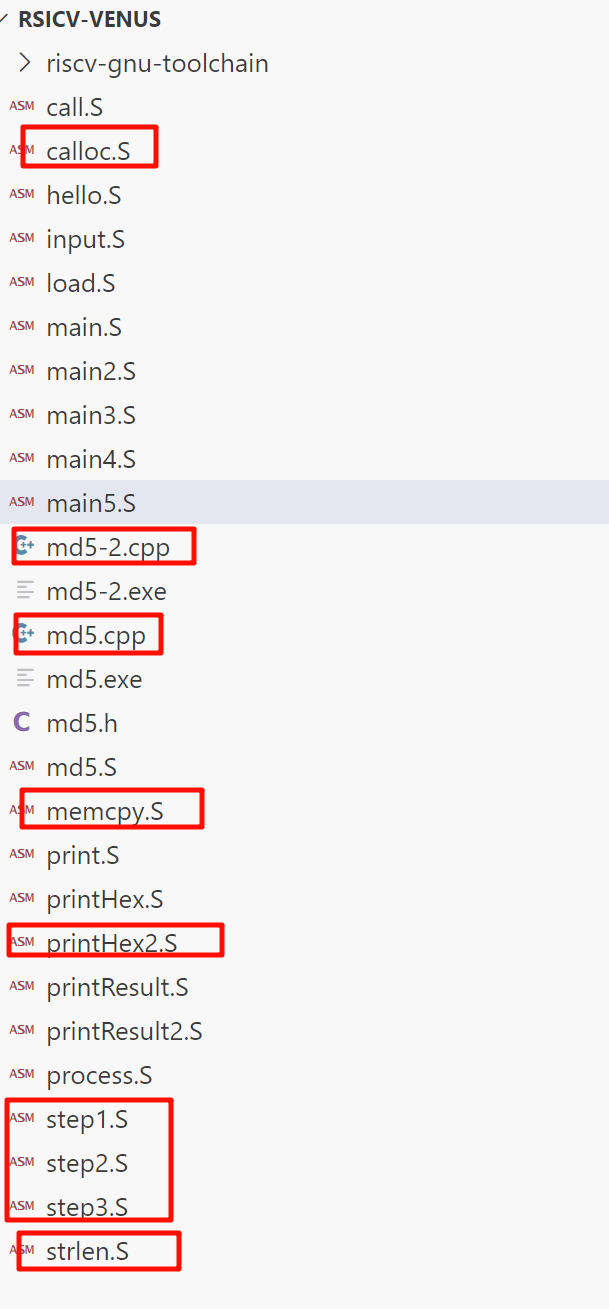
看我有这么多的中间文件
我的大步骤是:
-
先做一个C语言的md5算法
-
用在线工具,把C语言代码转成riscv汇编
-
增加汇编代码函数+小调试
-
综合+大调试
一、C语言md5
在第一个大步骤里
一开始问kimi的C语言代码,执行完不太理想。
然后我又把问题分解,我是否可以在网上先搜搜资料,然后找一个最合适的参考。
这个是我找的的最简洁的版本了,代码量只有 150 行,而且没有那么多的辅助函数。
看看人家的 star 数量,代码质量肯定不差的。
这是我改过很多次以后,精简版本的代码,便于网上工具将其转成RISC-V汇编。
/*
* Simple MD5 implementation
*
* Compile with: gcc -o md5 -O3 -lm md5.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
// leftrotate function definition
#define LEFTROTATE(x, c) (((x) << (c)) | ((x) >> (32 - (c))))
// These vars will contain the hash
uint32_t h0, h1, h2, h3;
// Message (to prepare)
char *input="CS110P";
// Note: All variables are unsigned 32 bit and wrap modulo 2^32 when calculating
// r specifies the per-round shift amounts
uint32_t r[] = {7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22,
5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20,
4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23,
6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21};
// Use binary integer part of the sines of integers (in radians) as constants// Initialize variables:
uint32_t k[] = {
0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee,
0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501,
0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be,
0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821,
0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa,
0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8,
0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed,
0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a,
0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c,
0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05,
0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665,
0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039,
0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1,
0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1,
0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391};
void process(uint8_t *msg,int new_len){
// Process the message in successive 512-bit chunks:
//for each 512-bit chunk of message:
int offset;
for(offset=0; offset<new_len; offset += (512/8)) {
// break chunk into sixteen 32-bit words w[j], 0 ≤ j ≤ 15
uint32_t *w = (uint32_t *) (msg + offset);
// Initialize hash value for this chunk:
uint32_t a = h0;
uint32_t b = h1;
uint32_t c = h2;
uint32_t d = h3;
// Main loop:
uint32_t i;
for(i = 0; i<64; i++) {
uint32_t f, g;
if (i < 16) {
f = (b & c) | ((~b) & d);
g = i;
} else if (i < 32) {
f = (d & b) | ((~d) & c);
g = (5*i + 1) % 16;
} else if (i < 48) {
f = b ^ c ^ d;
g = (3*i + 5) % 16;
} else {
f = c ^ (b | (~d));
g = (7*i) % 16;
}
uint32_t temp = d;
d = c;
c = b;
b = b + LEFTROTATE((a + f + k[i] + w[g]), r[i]);
a = temp;
}
// Add this chunk's hash to result so far:
h0 += a;
h1 += b;
h2 += c;
h3 += d;
}
}
void md5() {
h0 = 0x67452301;
h1 = 0xefcdab89;
h2 = 0x98badcfe;
h3 = 0x10325476;
// Pre-processing: adding a single 1 bit
//append "1" bit to message
/* Notice: the input bytes are considered as bits strings,
where the first bit is the most significant bit of the byte.[37] */
// Pre-processing: padding with zeros
//append "0" bit until message length in bit ≡ 448 (mod 512)
//append length mod (2 pow 64) to message
int initial_len = strlen(input);
int new_len = ((((initial_len + 8) / 64) + 1) * 64) - 8;
uint8_t *msg = (uint8_t*)calloc(new_len + 64, 1); // also appends "0" bits
// (we alloc also 64 extra bytes...)
memcpy(msg, input, initial_len);
msg[initial_len] = 128; // write the "1" bit
uint32_t bits_len = 8*initial_len; // note, we append the len
memcpy(msg + new_len, &bits_len, 4); // in bits at the end of the buffer
process(msg,new_len);
}
void printResult(){
uint8_t* p=NULL;
p=(uint8_t *)&h0;
printf("%2.2x%2.2x%2.2x%2.2x", p[0], p[1], p[2], p[3]);
p=(uint8_t *)&h1;
printf("%2.2x%2.2x%2.2x%2.2x", p[0], p[1], p[2], p[3]);
p=(uint8_t *)&h2;
printf("%2.2x%2.2x%2.2x%2.2x", p[0], p[1], p[2], p[3]);
p=(uint8_t *)&h3;
printf("%2.2x%2.2x%2.2x%2.2x", p[0], p[1], p[2], p[3]);
}
int main(int argc, char **argv) {
md5();
printResult();
return 0;
}
二、在线转码
我在网上搜搜 C to riscv assembly
没想到还真给我搜到了
Converting C code to assembly? : r/RISCV
不过,转码并不是那么容易的
还有很多问题,比如各种printf, memcpy, strlen 库都是没有的,怎么办?
三、自己实现库函数汇编+小调试
先分析
我分析了一下,主要要实现的函数有4个
-
strlen
-
memcpy
-
calloc
-
printResult
再搜搜
于是先在网上搜别人是怎么做的:
然后像 strlen 和 memcpy 都是从这里找的
Example RISC-V Assembly Programs – Stephen Marz
小调试
搜到以后,直接拿过来肯定是不行的,还要慢慢调试
我就遇到了很多问题,比如跳转的label不对、strncpy和memcpy内部实现的不同、calloc 的第三个参数怎么处理?
这些问题看似复杂,本质都是一样的,只要分解出来,就是不难的,要有耐心。
每写一个代码,都要代入到模拟器里去调试验证,一旦验证成功了,就要固定下来一个版本。
strlen的测试代码
.data
src: .asciiz "hello world"
.text
main:
la a0,src
call strlen
mv a1,a0
call printInt
call exit
strlen:
# a0 = const char *str
li t0, 0 # i = 0
sl_1b: # Start of for loop
add t1, t0, a0 # Add the byte offset for str[i]
lb t1, 0(t1) # Dereference str[i]
beqz t1, sl_1f # if str[i] == 0, break for loop
addi t0, t0, 1 # Add 1 to our iterator
j sl_1b # Jump back to condition (1 backwards)
sl_1f: # End of for loop
mv a0, t0 # Move t0 into a0 to return
ret # Return back via the return address register
printInt:
li a0,1
ecall
ret
exit:
li a0,10
ecall
执行结果为11,正确

memcpy
.data
src: .asciiz "Hello"
dst: .asciiz "world"
.text
main:
la a0,dst
la a1,src
li a2,5
call memcpy
la a1,dst
call printString
call exit
printString:
li a0,4
ecall
ret
exit:
li a0,10
ecall
memcpy:
# a0 = char *dst
# a1 = const char *src
# a2 = unsigned long n
# t0 = i
li t0, 0 # i = 0
1b: # first for loop
bge t0, a2, 1f # break if i >= n
add t1, a1, t0 # src + i
lb t1, 0(t1) # t1 = src[i]
add t2, a0, t0 # t2 = dst + i
sb t1, 0(t2) # dst[i] = src[i]
addi t0, t0, 1 # i++
j 1b # back to beginning of loop
1f:
# we don't have to move anything since
# a0 hasn't changed.
ret # return via return address register
calloc
.text
main:
li a0,1
call calloc
sb a0,0(a0)
mv a1,a0
call printInt
call exit
# 9 sbrk allocates a1 bytes on the heap, returns pointer to start in a0
calloc:
mv a1,a0 # let a1 = a0, that is nitems
li a0,9 # sbrk
ecall
li t0, 0 # i = 0
c_1b: # first for loop
bge t0, a1, c_1f # break if i >= nitems
add t1, a0, t0 # arr + i
sb zero, 0(t1) # arr[i] = 0
addi t0, t0, 1 # i++
j c_1b # back to beginning of loop
c_1f:
ret # return via return address register
printInt:
li a0,1
ecall
ret
exit:
li a0,10
ecall
printHex
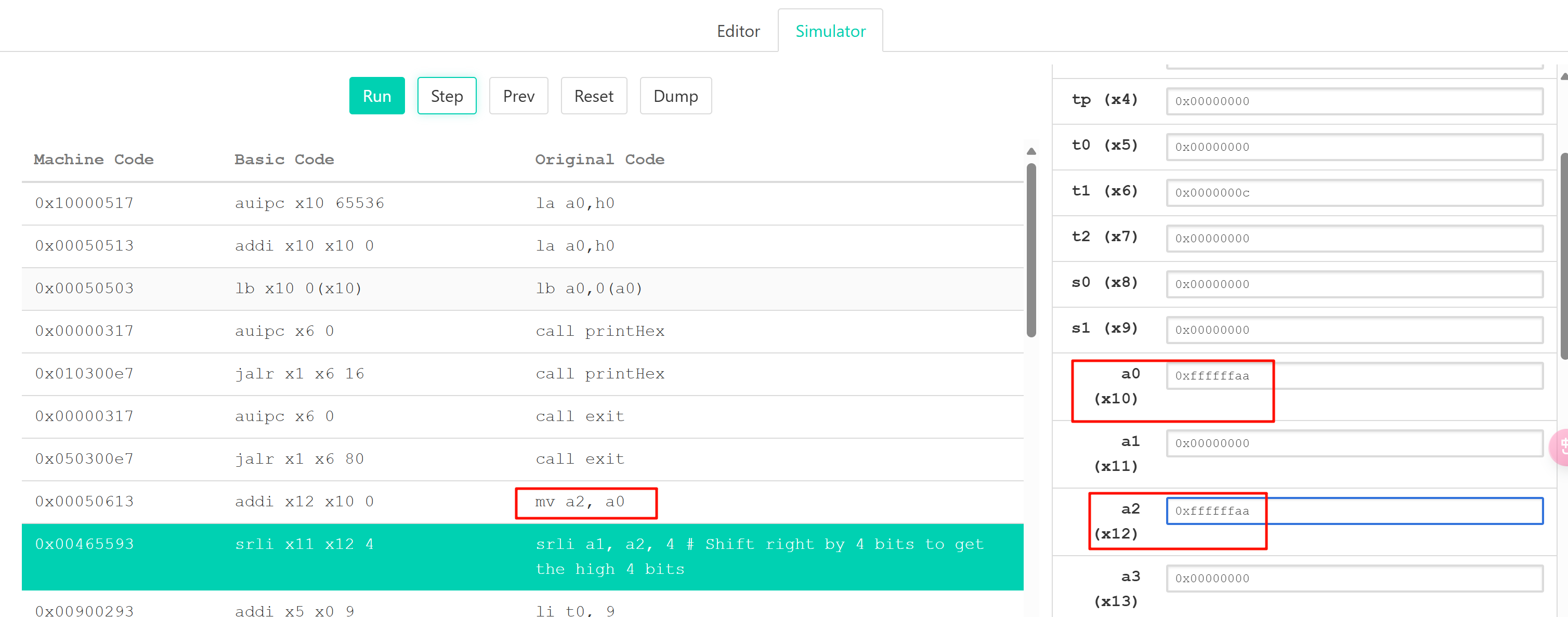
以这个函数为例,有一些问题,是需要特殊测试才能发现的。
一开始是没有 andi a2, a0,0xff 这一行代码的,后来我调试的时候发现,如果不给高位置0的话,a2 高位是默认ffff的,这样就会影响。
.data
h0: .word 0xaa # A
.text
main:
la a0,h0
lb a0,0(a0)
call printHex
call exit
printHex:
# Save the input byte in a2
andi a2, a0,0xff
# Process the high 4 bits
srli a1, a2, 4 # Shift right by 4 bits to get the high 4 bits
li t0, 9
ble a1, t0, add_30_high # If a1 <= 9, add 0x30
addi a1, a1, 55 # If a1 > 9, add 55
j print_char_high
add_30_high:
addi a1, a1, 0x30 # Add 0x30 to convert to ASCII
print_char_high:
li a0, 11 # ecall code for print character
ecall # Print the character
# Process the low 4 bits
andi a1, a2, 0xf # Mask the low 4 bits
li t0, 9
ble a1, t0, add_30_low # If a1 <= 9, add 0x30
addi a1, a1, 55 # If a1 > 9, add 55
j print_char_low
add_30_low:
addi a1, a1, 0x30 # Add 0x30 to convert to ASCII
print_char_low:
li a0, 11 # ecall code for print character
ecall # Print the character
ret # Return from the function
exit:
li a0,10
ecall
调试截图:
四、综合大调试
看起来很大的项目,其实也都是从若干个小项目整合起来的。这是我悟道的一个很重要的哲学原理。
古话说:
千里之行,始于足下,合抱之木,起于累土。
综合的工作,其实是把C语言md5代码,转成riscv汇编以后,然后分段分析
我是分成了3段
- 数据定义: 如 input 字符串、K、h0-h3、移位数组等
- md5函数:数据预处理,获取字符串长度、calloc、memcpy 之类的
- process:核心处理流程,循环编码
然后 main 函数里调用md5,再调用printResult把结果打印出来。
这部分有大量的调试,容易把人绕晕。一定要在前期,就做好代码的版本固定工作。不然一旦涉及到代码修改,改错一个地方,就GG了,会导致人的耐心急剧下降,然后满盘皆输。
一定要管理好复杂度。
也挺晚的了,我就不细说了。
Code can speak for itself.
.data
input:
.asciiz "CS110P"
debug:
.asciiz "strlen="
# Per-round shift amounts
r:
.word 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22
.word 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20
.word 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23
.word 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21
# 64-element table constructed from the sine function
k:
.word 0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee
.word 0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501
.word 0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be
.word 0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821
.word 0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa
.word 0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8
.word 0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed
.word 0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a
.word 0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c
.word 0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70
.word 0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05
.word 0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665
.word 0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039
.word 0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1
.word 0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1
.word 0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391
# Initial buffer value
h0: .word 0x67452301 # A
h1: .word 0xefcdab89 # B
h2: .word 0x98badcfe # C
h3: .word 0x10325476 # D
.text
main:
call md5
call printResult
call exit
process:
addi sp,sp,-80
sw s0,76(sp)
addi s0,sp,80
sw a0,-68(s0)
sw a1,-72(s0)
sw zero,-20(s0)
j .L2
.L9:
lw a5,-20(s0)
lw a4,-68(s0)
add a5,a4,a5
sw a5,-52(s0)
# lui a5,%hi(h0)
# lw a5,%lo(h0)(a5)
la a5,h0
lw a5,0(a5)
sw a5,-24(s0)
# lui a5,%hi(h1)
# lw a5,%lo(h1)(a5)
la a5,h1
lw a5,0(a5)
sw a5,-28(s0)
# lui a5,%hi(h2)
# lw a5,%lo(h2)(a5)
la a5,h2
lw a5,0(a5)
sw a5,-32(s0)
# lui a5,%hi(h3)
# lw a5,%lo(h3)(a5)
la a5,h3
lw a5,0(a5)
sw a5,-36(s0)
sw zero,-40(s0)
j .L3
.L8:
lw a4,-40(s0)
li a5,15
bgtu a4,a5,.L4
lw a4,-28(s0)
lw a5,-32(s0)
and a4,a4,a5
lw a5,-28(s0)
not a3,a5
lw a5,-36(s0)
and a5,a3,a5
or a5,a4,a5
sw a5,-44(s0)
lw a5,-40(s0)
sw a5,-48(s0)
j .L5
.L4:
lw a4,-40(s0)
li a5,31
bgtu a4,a5,.L6
lw a4,-36(s0)
lw a5,-28(s0)
and a4,a4,a5
lw a5,-36(s0)
not a3,a5
lw a5,-32(s0)
and a5,a3,a5
or a5,a4,a5
sw a5,-44(s0)
lw a4,-40(s0)
mv a5,a4
slli a5,a5,2
add a5,a5,a4
addi a5,a5,1
andi a5,a5,15
sw a5,-48(s0)
j .L5
.L6:
lw a4,-40(s0)
li a5,47
bgtu a4,a5,.L7
lw a4,-28(s0)
lw a5,-32(s0)
xor a5,a4,a5
lw a4,-36(s0)
xor a5,a4,a5
sw a5,-44(s0)
lw a4,-40(s0)
mv a5,a4
slli a5,a5,1
add a5,a5,a4
addi a5,a5,5
andi a5,a5,15
sw a5,-48(s0)
j .L5
.L7:
lw a5,-36(s0)
not a4,a5
lw a5,-28(s0)
or a5,a4,a5
lw a4,-32(s0)
xor a5,a4,a5
sw a5,-44(s0)
lw a4,-40(s0)
mv a5,a4
slli a5,a5,3
sub a5,a5,a4
andi a5,a5,15
sw a5,-48(s0)
.L5:
lw a5,-36(s0)
sw a5,-56(s0)
lw a5,-32(s0)
sw a5,-36(s0)
lw a5,-28(s0)
sw a5,-32(s0)
lw a4,-24(s0)
lw a5,-44(s0)
add a4,a4,a5
# lui a5,%hi(k)
lw a3,-40(s0)
slli a3,a3,2
# addi a5,a5,%lo(k)
la a5,k
add a5,a3,a5
lw a5,0(a5)
add a4,a4,a5
lw a5,-48(s0)
slli a5,a5,2
lw a3,-52(s0)
add a5,a3,a5
lw a5,0(a5)
add a5,a4,a5
# lui a4,%hi(r)
lw a3,-40(s0)
slli a3,a3,2
# addi a4,a4,%lo(r)
la a4,r
add a4,a3,a4
lw a4,0(a4)
sll a3,a5,a4
sub a4,zero,a4
andi a4,a4,31
srl a5,a5,a4
or a5,a5,a3
lw a4,-28(s0)
add a5,a4,a5
sw a5,-28(s0)
lw a5,-56(s0)
sw a5,-24(s0)
lw a5,-40(s0)
addi a5,a5,1
sw a5,-40(s0)
.L3:
lw a4,-40(s0)
li a5,63
bleu a4,a5,.L8
# lui a5,%hi(h0)
# lw a4,%lo(h0)(a5)
la a5,h0
lw a4,0(a5)
lw a5,-24(s0)
add a4,a4,a5
# lui a5,%hi(h0)
# sw a4,%lo(h0)(a5)
la a5,h0
sw a4,0(a5)
# lui a5,%hi(h1)
# lw a4,%lo(h1)(a5)
la a5,h1
lw a4,0(a5)
lw a5,-28(s0)
add a4,a4,a5
# lui a5,%hi(h1)
# sw a4,%lo(h1)(a5)
la a5,h1
sw a4,0(a5)
# lui a5,%hi(h2)
# lw a4,%lo(h2)(a5)
la a5,h2
lw a4,0(a5)
lw a5,-32(s0)
add a4,a4,a5
# lui a5,%hi(h2)
# sw a4,%lo(h2)(a5)
la a5,h2
sw a4,0(a5)
# lui a5,%hi(h3)
# lw a4,%lo(h3)(a5)
la a5,h3
lw a4,0(a5)
lw a5,-36(s0)
add a4,a4,a5
# lui a5,%hi(h3)
# sw a4,%lo(h3)(a5)
la a5,h3
sw a4,0(a5)
lw a5,-20(s0)
addi a5,a5,64
sw a5,-20(s0)
.L2:
lw a4,-20(s0)
lw a5,-72(s0)
blt a4,a5,.L9
nop
lw s0,76(sp)
addi sp,sp,80
jr ra
md5:
addi sp,sp,-32
sw ra,28(sp)
sw s0,24(sp)
addi s0,sp,32
li a4,1732583424
addi a4,a4,769
# lui a5,%hi(h0)
# sw a4,%lo(h0)(a5)
la a5,h0
sw a4,0(a5)
li a4,-271732736
addi a4,a4,-1143
# lui a5,%hi(h1)
# sw a4,%lo(h1)(a5)
la a5,h1
sw a4,0(a5)
li a4,-1732583424
addi a4,a4,-770
# lui a5,%hi(h2)
# sw a4,%lo(h2)(a5)
la a5,h2
sw a4,0(a5)
li a4,271732736
addi a4,a4,1142
# lui a5,%hi(h3)
# sw a4,%lo(h3)(a5)
la a5,h3
sw a4,0(a5)
# lui a5,%hi(input)
# lw a5,%lo(input)(a5)
la a5,input
mv a0,a5
call strlen
mv a5,a0
sw a5,-20(s0)
lw a5,-20(s0)
addi a5,a5,8
srai a4,a5,31
andi a4,a4,63
add a5,a4,a5
srai a5,a5,6
addi a5,a5,1
slli a5,a5,6
addi a5,a5,-8
sw a5,-24(s0)
lw a5,-24(s0)
addi a5,a5,64
li a1,1
mv a0,a5
call calloc
mv a5,a0
sw a5,-28(s0)
# lui a5,%hi(input)
# lw a5,%lo(input)(a5)
la a5,input
lw a4,-20(s0)
mv a2,a4
mv a1,a5
lw a0,-28(s0)
call memcpy
lw a5,-20(s0)
lw a4,-28(s0)
add a5,a4,a5
li a4,-128
sb a4,0(a5)
lw a5,-20(s0)
slli a5,a5,3
sw a5,-32(s0)
lw a5,-24(s0)
lw a4,-28(s0)
add a5,a4,a5
addi a4,s0,-32
li a2,4
mv a1,a4
mv a0,a5
call memcpy
lw a1,-24(s0)
lw a0,-28(s0)
call process
nop
lw ra,28(sp)
lw s0,24(sp)
addi sp,sp,32
jr ra
memcpy:
# a0 = char *dst
# a1 = const char *src
# a2 = unsigned long n
# t0 = i
li t0, 0 # i = 0
1b: # first for loop
bge t0, a2, 1f # break if i >= n
add t1, a1, t0 # src + i
lb t1, 0(t1) # t1 = src[i]
add t2, a0, t0 # t2 = dst + i
sb t1, 0(t2) # dst[i] = src[i]
addi t0, t0, 1 # i++
j 1b # back to beginning of loop
1f:
# we don't have to move anything since
# a0 hasn't changed.
ret # return via return address register
# 9 sbrk allocates a1 bytes on the heap, returns pointer to start in a0
calloc:
mv a1,a0 # let a1 = a0, that is nitems
li a0,9 # sbrk
ecall
li t0, 0 # i = 0
c_1b: # first for loop
bge t0, a1, c_1f # break if i >= nitems
add t1, a0, t0 # arr + i
sb zero, 0(t1) # arr[i] = 0
addi t0, t0, 1 # i++
j c_1b # back to beginning of loop
c_1f:
ret # return via return address register
strlen:
# a0 = const char *str
li t0, 0 # i = 0
sl_1b: # Start of for loop
add t1, t0, a0 # Add the byte offset for str[i]
lb t1, 0(t1) # Dereference str[i]
beqz t1, sl_1f # if str[i] == 0, break for loop
addi t0, t0, 1 # Add 1 to our iterator
j sl_1b # Jump back to condition (1 backwards)
sl_1f: # End of for loop
mv a0, t0 # Move t0 into a0 to return
ret # Return back via the return address register
exit:
li a0,10
ecall
printResult:
la a3,h0
lb a0,0(a3)
call printHex
lb a0,1(a3)
call printHex
lb a0,2(a3)
call printHex
lb a0,3(a3)
call printHex
la a3,h1
lb a0,0(a3)
call printHex
lb a0,1(a3)
call printHex
lb a0,2(a3)
call printHex
lb a0,3(a3)
call printHex
la a3,h2
lb a0,0(a3)
call printHex
lb a0,1(a3)
call printHex
lb a0,2(a3)
call printHex
lb a0,3(a3)
call printHex
la a3,h3
lb a0,0(a3)
call printHex
lb a0,1(a3)
call printHex
lb a0,2(a3)
call printHex
lb a0,3(a3)
call printHex
ret
printHex:
# Save the input byte in a2
andi a2, a0,0xff
# Process the high 4 bits
srli a1, a2, 4 # Shift right by 4 bits to get the high 4 bits
li t0, 9
ble a1, t0, add_30_high # If a1 <= 9, add 0x30
addi a1, a1, 55 # If a1 > 9, add 55
j print_char_high
add_30_high:
addi a1, a1, 0x30 # Add 0x30 to convert to ASCII
print_char_high:
li a0, 11 # ecall code for print character
ecall # Print the character
# Process the low 4 bits
andi a1, a2, 0xf # Mask the low 4 bits
li t0, 9
ble a1, t0, add_30_low # If a1 <= 9, add 0x30
addi a1, a1, 55 # If a1 > 9, add 55
j print_char_low
add_30_low:
addi a1, a1, 0x30 # Add 0x30 to convert to ASCII
print_char_low:
li a0, 11 # ecall code for print character
ecall # Print the character
ret # Return from the function

 浙公网安备 33010602011771号
浙公网安备 33010602011771号