MySQL数据库基本操作笔记
SQL
定义:结构化查询语言。定义了所有关系型数据库的操作规则,每种数据库的操作方式不一样,有各自的方言
注释:
| 方法 |
解释 |
| 单行注视 |
-- 内容 |
| 单行注释 |
#内容 |
| 多行 |
/* 内容 */ |
启动/关闭MySQL
| 系统 |
命令 |
| Windows |
net start mysql |
|
net stop mysql |
| Linux |
systemctl start mysqld.service |
|
systemctl stop mysqld.service |
MySQL登录
| 方法 |
操作 |
| 1 |
mysql -u root -p |
| 2 |
mysql -h127.0.0.1 -u root -p |
| 3 |
mysql --host=127.0.0.1 --user=root --password=1234 |
操作
| 名词 |
操作 |
| C |
create(创建) |
| R |
retrieve(查找) |
| U |
update(更新) |
| D |
delete(删除) |
| DDL(Define) |
create drop alter 等 |
| DML(Modify) |
insert delete update等 |
| DQL(Query) |
select where 等 |
| DCL |
GRANT REVOKE 等 |
查看数据库配置
| 语法 |
描述 |
| show character set |
显示所有可用的字符集及每个字符集的描述和默认校对 |
| show collation |
显示所有可用的校对以及字符集 |
DDL
| 操作 |
语法 |
| 查询所有数据库 |
show database; |
| 查询具体数据库 |
show create database database_name; |
| 创建库 |
create database database_name character set utf8; |
| 修改数据库字符 |
alter database database_name character set utf8; |
| 删除数据库 |
drop database if exists database_name; |
| 使用数据库 |
use database_name; |
| 查询正在使用的数据库 |
select database(); |
- 扩展
- 指定字符集
create database if not exists table_name default charset utf8 collate utf8_general_ci;
表
| 操作 |
语法 |
| 选择数据库 |
use database_name; |
| 查询所有表 |
show tables; |
| 查询具体表 |
desc table_name; |
| 查询表字符集 |
show create table table_name; |
| 创建表 |
create table if not exists table_name |
| 删除表 |
drop table if exists table_name |
| 复制表 |
create table table_name like exists_table_name; |
| 修改表名 |
alter table table_name rename to new_table_rename; |
| 修改表字符集 |
alter table table_name charset=utf8 collate=utf8_general_ci; |
| 修改列(列名和数据类型) |
alter table table_name change 旧列名 新列名 新数据类型; |
| 修改列数据类型 |
alter table table_name modify 列名 新数据类型; |
| 删除列 |
alter table table_name drop table_name; |
| 添加列 |
alter table table_name add column column_name type |
| 类型 |
描述 |
| int |
整数 int(20) |
| double |
小数score double(5,2) |
| date |
日期 yyyy-MM-dd |
| datetime |
yyyy-MM-dd HH::mm:ss |
| timestamp |
格式同datetime。没赋值则默认为当前系统时间,自动赋值 |
| varchar |
字符串,varchar(100) |
#例子
create database if not exists `test` default charset utf8mb4 collate utf8mb4_general_ci;
use test;
CREATE TABLE `student` (
`student_id` int(20) NOT NULL,
`student_name` varchar(200) DEFAULT NULL,
`student_birthday` date DEFAULT NULL,
`insert_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`student_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
DML:增删表中数据
| 方法 |
操作 |
| 添加数据 |
insert into 表名(列1,列2) values(值1,值2); |
|
若数据类型非数字型,需要用单/双引号包裹 |
| 删除数据 |
delete from 表名 where 条件; |
|
truncate table 表名; |
| 修改数据 |
update 表名 set 列1=值1 列2=值2 where 条件; |
DQL:查询语句
- 排序
| 关键字 |
描述 |
| order by |
ASC 升序,DESC 降序。order by name ASC age DESC |
| distinct |
字段列去重 |
| as |
字段列取别名 |
| ifnull |
null参与的运算都为null,ifnull(字段名,0)将null字段设为0 |
- 聚合函数,将一列数据作为整体并进行纵向计算
| 函数 |
操作 |
| count |
select count(列名) from 表名 where 条件 |
|
select count(主键)from 表名 where 条件 |
|
select count(ifnull(列名,0))from 表名 where 条件 |
|
select count(*) from 表名 where 条件 |
| min |
select min(列名)from 表名 where 条件 |
| max |
select max(列名)from 表名 where 条件 |
| sum |
select sum (列名)from 表名 where 条件 |
| avg |
select avg (列名)from 表名 where 条件 |
注意:聚合函数count 计算,排除NULL,所以推荐后第三种(infull)和第四种count(*)方法
count(*)只要横向的行有一个不为null数据,则该列不为null。会参与count统计
- 分组查询:分组后按组为整体,单行个人信息就没有意义了,可以把
每一组看作一行信息来查询。需要结合聚合函数 统计组信息
| 方法 |
关键字 |
| 分组 |
group by |
| 分组前限定 |
where |
| 分组后限定 |
having |
| 分组相关聚合函数 |
count,min, max,sum,avg |
| 方法 |
解释 |
| limit 偏移量,记录数 |
偏移量是从0位置开始记数;记录数为返回结果条数 |
| 分页语法 |
limit 开始索引,每页显示条数 |
| 计算索引 |
开始索引=(当前页码-1)*每页显示条数 |
| limit |
limit是MySQL分页方言 |
-- 从第二行开始,返回2行记录
select * from user limit 1,2;
-- 从第一行开始,返回2行记录;
select * from user limit 0,2;
-- 从第一行开始,返回2行记录;
select * from user limit 2;
约束:对表中的数据进行限定,保证数据的正确性,完整性,有效性
| 关键字 |
描述 |
not null |
非空约束,添加用户数据时该字段为null则无法添加 |
| 建表时添加 |
name varchar(20) not null; |
| 建表后删除 |
alter table user modify name varchar(20); |
| 建表后添加 |
alter table user modify name varchar(20) not null; |
|
|
unique |
唯一约束,添加用户数据设unique的字段重复则无法添加 |
| 建表时添加 |
phone_number varchar(20) unique; |
| 建表后删除 |
alter table user drop index phone_number; |
| 建表后添加 |
alter table user modify phone_number varchar(20) unique; |
|
MySQL中认为null不是一样的,所以使用unique后,可以在数据中有两个null行 |
|
|
primary key |
主键是非空且唯一的意思。一张表只有一个主键字段 |
| 建表时添加 |
id int(20) primary key |
| 建表后删除 |
alter table user drop primary key; |
| 建表后添加 |
alter table user modify id int(20) primary key; |
|
|
auto_increment |
常与数值型主键一起用,有此属性则该字段为null也可以添加 |
|
它自动增长是跟据上一个数字增长,手动添加此列为199,则下一值为200 |
| 建表时添加 |
id int(20) primary key auto_increment; |
| 建表后删除 |
alter table user modify id int(20) ; |
| 建表后添加 |
alter table user modify id int(20) auto_increment; |
|
|
foreign key |
子表(外键列):依赖外键的表 父表(主表列):表中主键为子表的外键 |
| 建表时添加 |
constraint 外键名 foreign key 外键列的名称 references 主表(主表列名称) |
| 建表后删除 |
alter table 子表名 drop foreign key 外键列的名称; |
| 建表后添加 |
alter table 子表名 add + <键表时添加foreign key语句> |
MyISAM引擎
- MyISAM的索引文件仅仅保存数据记录的地址,地址是由主键运算过来的
- 在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。
InnoDB引擎
- InnoDB的数据文件本身就是索引文件,所以
表必须有主键 (如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。)
- InnoDB表数据文件本身就是主索引
- InnoDB的辅助索引data域存储相应记录主键的值
- 聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
索引优化
- 联合索引(为多个字段建立一个索引),最左前缀原则(查询条件为联合索引顺序)
- 对 where,on,group by,order by 中出现的列使用索引
- 为较长的字符串使用前缀索引(order by与group by 无效)
- 区分度高的列作为索引
- 对于like 模糊查询,不要把%放在前面
- 正则表达式不能使用索引
- 索引会提高查询效率,但索引过多会影响插入,删除操作效率
- 不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大
- 用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
查询优化
- MySQL 经过
语法解析和预处理 生成语法树,会进行查询优化 ,它尝试预测查询使用某种执行计划时的成本 ,并选择成本最小的。因此多张表关联查询时,并不一定按照SQL中的指定的顺序进行
- 避免使用
select *或者查询加上limit ,MySQL客户端与服务端通信协议是半双工 ,同一时间只能单向通信(客户端→服务端 或服务端→客户端 )
- count()不会统计null行,count(*)
- 优化关联查询,大数据情况下,表与表之间使用一个
冗余 字段来关联,比直接使用join 性能更好
- 如果使用关联查询,确保
on 和using 字句中的列上有索引,order by 与group by 只涉及一个列时才有可能使用索引来优化
建表优化
- 数据类型
小而简单 ,越小的类型占用越小的磁盘 内存 cpu处理周期 ,如整型 比字符的操作代价低
- 索引列应该建为
not null
- 少用
decimal 类型,处理百万分之一的数据可以用bigint ,将数据乘100万然后使用bigint存储,可以避免浮点数计算不准确及decimal 精确计算代价高的问题
- 慎用枚举类型,缺点之一枚举列字符串列表是固定的,增加、删除字符串(枚举列)时,必须使用
Alter Table
Foreign Key相关
-
tips
- 两个字段类型及大小必须严格匹配
- 外键字段须是另一表的主键,否则得为在另一表中建立外键字段的索引
- MyISAM 引擎只会建立索引,而InnoDB才能建外键
- 外键名字不能重复
- Charset和Collate在表级和字段级上必须一致
-
级联
-
CASCADE 父表update/delete时,同步update/delete子表记录,删除主表自动删除子表,更新主表自动更新子表。
-
SET NULL 父表update/delete时,将子表上匹配记录列设为null(注意子表外键不能为not null),删除主表自动更新从表值为null;更新主表自动更新从表值为null
-
NO ACTION 子表有匹配记录时,不允许对父表对应列进行update/delete操作
-
RESTRIC 同no action,都是立即检查外键约束
-
SET DEFAULT 父表变更时,自动将外键列设置为一个默认值,但InnoDB不能识别。
-
级联删除
ON DELETE CASCADE ON UPDATE CASCADE 同步更新删除ON DELETE RESTRIC ON UPDATE RESTRIC 有子表父表不能更新和删除ON DELETE RESTRIC ON UPDATE CASCADE 有子表不能删除,可以同步更新ON DELETE CASCADE ON UPDATE RESTRIC 同步删除,不能同步更新
数据库备份
-
备份指令
mysqldump -u root -p 数据库名 > 备份路径
-
还原数据库
- use 数据库名;
- source 备份数据库文件目录小的文档;
多表查询
| 方法 |
关键字 |
步骤 |
隐式内连接 |
inner(省略),where |
select 字段 from 左表 右表 where 连接条件 |
|
|
|
显示内连接 |
inner join, on |
select 字段 from 左表 inner join 右表 on 连接条件 where 查询条件 |
|
|
查哪些表(from)→连接条件(on)→查询条件(where)→查询字段(select) |
|
|
|
左外连接 |
left join,on |
select 字段 from 左表 left join 右表 on 连接条件 where 查询条件 |
|
|
会显示左表全部信息,右表没有匹配用NULL显示,右外连接是显示右表全部 |
外连接比内连接的优势是,没有匹配列会以NULL显示列信息
子查询
| 分类 |
关键字 |
例子 |
| 单行单列 |
where |
select 字段 from 表 where 字段=子查询 |
|
需求 |
工资最高的员工信息;相关表(工资表,员工表) |
|
子查询 |
select id ,max(salary) from salary; |
|
父查询 |
select * from emp where id=子查询.id |
|
|
|
| 单列多行 |
in |
select 查询字段 from 表 where 字段 in(子查询) |
|
需求 |
查询开发部与市场部所有员工信息;相关表(部门表,员工表) |
|
子查询 |
select id from dep where name in '开发部,市场部' |
|
父查询 |
select * from emp where id in(子查询) |
|
|
|
| 多列多行 |
from |
select 字段 from 表,子查询结果表 where 查询条件 |
|
需求 |
查询2018年入职的员工,包含部门名称;相关表(员工表,部门表) |
|
子查询 |
select * from emp where joid_date='2018*'; |
|
父查询 |
select * from detp,子查询表 where dept.id=子查询表dept_id |
子查询结果是单列,子查询结果在where后作为条件
子查询结果是多列,子查询结果则在from后作为二次查询条件
常见问题
- SQL注入
- 原因:使用Statement对象的executeXXX(sql)方法时,sql语句中的条件是直接来自用户的输入内容字符串拼接,输入的内容变为了SQL语法的一部分,会改变它的语义
- 解决:使用Prestatement对象来查询数据库,它是Statement接口的子接口
- Prestatement会先把sql语句传递给数据库,数据库会进行预编译,然后通过setXXX为sql语句中的占位符赋值,执行executeXXX()方法。
| 方法 |
描述 |
| executeUpdate |
执行DML的增删改操作,返回影响行数 |
| executeQuery |
执行DQL操作,返回结果集 |
- 优势:
- Statement对象的查询操作,每执行一条SQL语句都会发送给数据库,数据库先编译SQL,再执行,n条SQL语句编译n次
- Prestatement对象会先将SQL语句发送给数据库进行预编译,PreStatement对象会引用预编译的结果,可以多次传入不同的参数给Prestatement对象并执行,数据库只编译一次,提高了执行效率
正则表达式
转义字符为\\ 如\\- \\.
函数
注:使用函数在简化代码的同时也会导致 可移植性降低
- 拼接函数
concat()
- 除去多余空
RTrim()或LTrim()
- 返回当前日期和时间
Now
- 将文本转换为大写
Upper
- 提取日期,不要具体时间
Date(日期列)
- 返回年数
Year() ,返回月数Month()
事物
| 关键字 |
含义 |
transaction |
指一组SQL语句 |
rollback |
回滚,撤销 |
commit |
提交 |
savepoint |
保留点。可回退至某一保留点,而不事回滚整个事物 |
null与空值
- 杯子为容器,空值代表杯子是真空的,null代表杯子中装满了空气
- 插入操作,not null字段不能插入null,但是可以插入''(空值),所以可一把not null字段看作空值字段
- 加减操作,null字段与任何数相加或相减都会报null异常,
null+1 等于null1 ,将这个结果插入int类型字段,则会报错
- 误区
- 设计表时,NULL与DEFAULT实际上是两个属性,未设置not null,则是null类型。例,
count int default 0 默认为0,但是在插入值前其实是null,在业务层直接用null加减计算会报nullpointexception
-- 创建表
create table if not exists question
(
id int auto_increment primary key,
title varchar(50),
description Text,
gmt_create bigint,
gmt_modify bigint,
creator int,
comment_count int default 0,
view_count int default 0,
like_count int default 0
);
-- 查看表结构
desc question;

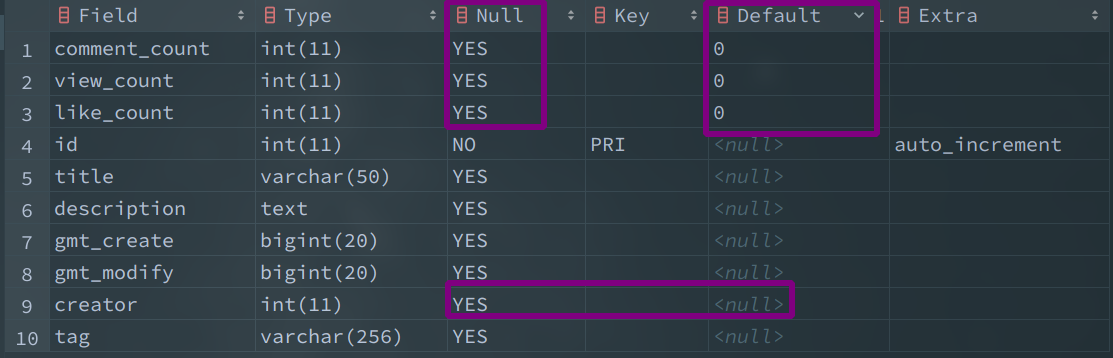
- 修改表结构(需要先清空表中的数据)。
alter table question modify comment_count int(11) not null default 0;
- 进阶
- 在MySQL中,含有空值的列很难进行查询优化,而且对表索引时不会存储NULL值的,所以如果索引的字段可以为NULL,索引的效率会下降很多。因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号