
spark学习10_2之spark.ml
从 Spark 2.0 开始, spark.mllib 包中的基于 RDD 的 API 已经进入了维护模式。Spark 的主要的机器学习 API 现在是 spark.ml 包中的基于 DataFrame 的 API 。
所以除了Mllib之外spark里面还有一个ml库,也是用来支持机器学习的。今天也是粗略地学了一下这个库的API的使用,里面算法具体怎么干的,今天没有学。
概念
DataFrame
spark.ml这个库的API是基于DataFrame的,但是我不了解DataFrame。查到的技术博客里面说DataFrame就像是矩阵,不过每一个单元的元素可以不只是数字也可以是字符串,换句话说就是像excel表。
在DataFrame这个数据结构里列名叫columns行名叫index。
Word2Vec
这是一个模型,这个模型干的事怎么说呢,就顾名思义,把单词word转化成(to)向量(vector)。
为了了解这个东西的意思,教程里的解释是这样的
Word2Vec 是一个估计器(拟合一个 DataFrame 来产生转换器的算法),它采用一系列代表文档的词语来训练 Word2Vec 模型。这个模型把每一个词语映射到一个固定大小的向量。Word2Vec 模型使用文档中每个词语的平均数来把文档转换为向量,把这个向量作为预测特征用来计算文档相似度。
我找到一篇解释这个模型是怎么做到把单词转换成向量的博客:通俗理解word2vec
说实话,人家讲的挺清楚,我没有必要复制了。
朴素贝叶斯算法
朴素贝叶斯算法(Naive Bayesian algorithm) 是应用最为广泛的分类算法之一。
朴素贝叶斯方法是在贝叶斯算法的基础上进行了相应的简化,即假定给定目标值时属性之间相互条件独立。也就是说没有哪个属性变量对于决策结果来说占有着较大的比重,也没有哪个属性变量对于决策结果占有着较小的比重。虽然这个简化方式在一定程度上降低了贝叶斯分类算法的分类效果,但是在实际的应用场景中,极大地简化了贝叶斯方法的复杂性。
它具体干的事是,对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,在没有其它可用信息下,会选择条件概率最大的类别作为这个待分类项所对应的类别。
二分均值K算法(这个我连简介都没懂)
二分 K 均值算法是一种层次聚类算法,使用自顶向下的逼近:所有的观察值开始是一个簇,递归地向下一个层级分裂。分裂依据为选择能最大程度降低聚类代价函数(也就是误差平方和)的簇划分为两个簇。以此进行下去,直到簇的数目等于用户给定的数目 k 为止。二分 K 均值常常比传统 K 均值算法有更快的计算速度,但产生的簇群与传统 K 均值算法往往也是不同的。
API使用
Word2Vec
首先要引入3个包,分别是对Word2Vec模型本身的支持,以及向量和sparkSQL的支持
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
然后要生成一个DataFrame,下面是用三句话(字符串),创建一个RDD,然后用toDF方法把这个RDD转化成DataFrame
val documentDF = spark.createDataFrame(Seq(
"Hi I heard about Spark".split(" "),
"I wish Java could use case classes".split(" "),
"Logistic regression models are neat".split(" ")
).map(Tuple1.apply)).toDF("text")
再然后创建一个word2vec对象,要根据我们刚才的DataFrame(就那三句话)来给这个对象指定各个参数。
指定完成之后,把那个DataFrame传给新创建的Word2vec对象进行学习。
val word2Vec = new Word2Vec()
.setInputCol("text")
.setOutputCol("result")
.setVectorSize(3)
.setMinCount(0)
val model = word2Vec.fit(documentDF)
上面完成之后,还没有完成把单词转化成向量,要让模型调用transform方法,然后调用返回的结果才是单词转向量的结果。
val result = model.transform(documentDF)
result.collect().foreach { case Row(text: Seq[_], features: Vector) =>println(s"Text: [${text.mkString(", ")}] => \nVector: $features\n") }
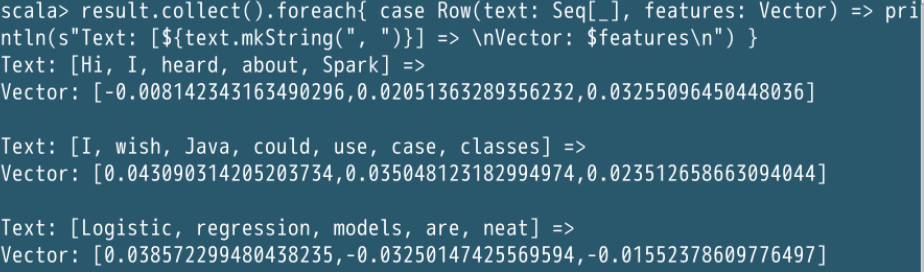
最后打印出来结果是这样的,说真的,我挺好奇这是怎么做的,后面一定要学一下。
朴素贝叶斯
这里要导入两个包,第一行那个就是朴素贝叶斯的包,第二行那个是用来评估结果的准确率的。
import org.apache.spark.ml.classification.NaiveBayes
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
然后这里的数据源用的是官方提供的数据,位置在:/opt/spark-2.4.4-bin-hadoop2.7/data/mllib/sample_libsvm_data.txt,非常非常大
然后导入数据,再创建对象
对象里把数据分为两份,其中 70% 作为训练数据集,30% 作为测试数据集
val data = spark.read.format("libsvm").load("/opt/spark-2.4.4-bin-hadoop2.7/data/mllib/sample_libsvm_data.txt")
val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3), seed = 1234L)
然后做法和上一个类似,也是调用相应的类,然后用fit方法传回一个模型。这里面用的是刚才那个70%的训练数据。
模型再用transform方法执行真正的算法,并返回一个预测结果。
val model = new NaiveBayes().fit(trainingData)
val predictions = model.transform(testData)
predictions.show()
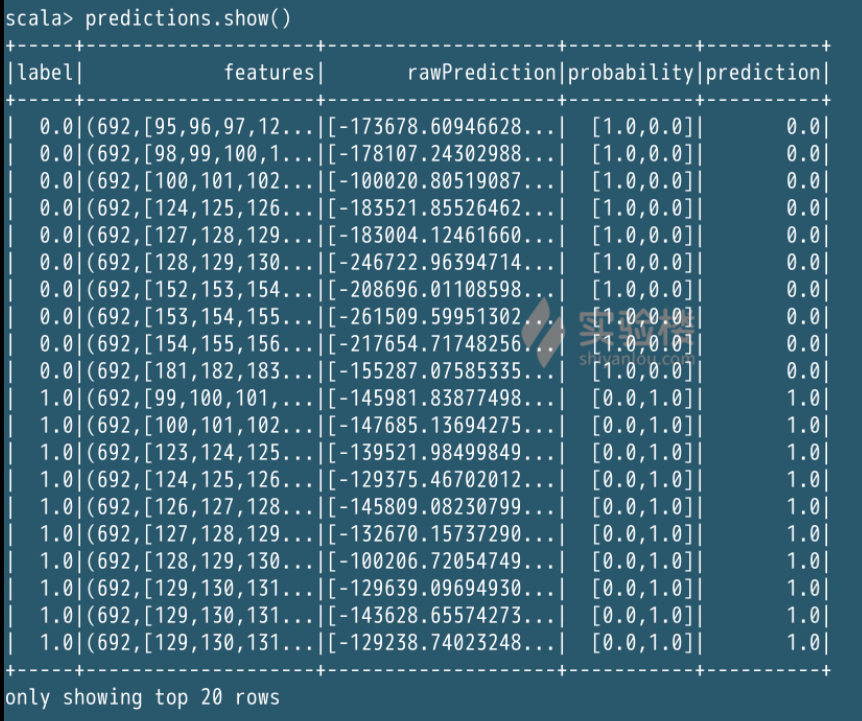
评估准确度的代码是这个样子的:
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
println(s"Test set accuracy = $accuracy")

二分均值K
这个算法需要引入的包是:
clustering.BisectingKMeans
import org.apache.spark.ml.clustering.BisectingKMeans
数据文件加载,并生成模型
val dataset = spark.read.format("libsvm").load("/opt/spark-2.4.4-bin-hadoop2.7/data/mllib/sample_kmeans_data.txt")
val bkm = new BisectingKMeans().setK(2).setSeed(1)
val model = bkm.fit(dataset)
代价评估
val cost = model.computeCost(dataset)
println(s"Within Set Sum of Squared Errors = $cost")

训练结果
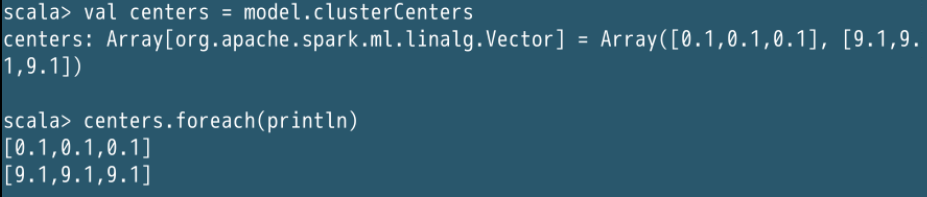
println("Cluster Centers: ")
val centers = model.clusterCenters
centers.foreach(println)
资料
DataFrame
Pandas 库之 DataFrame
通俗理解word2vec
word2vec笔记和实现
Spark RDD DF DS 的区别与联系
朴素贝叶斯算法的理解与实现
Bisecting KMeans (二分K均值)算法讲解及实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号