Spark学习10_1 sparkMllib入门与相关资料索引
资料
Spark机器学习库(MLlib)中文指南
关于spark机器学习的知乎专栏
Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
基本Kmeans算法介绍及其实现
spark MLlib 概念 1:相关系数( PPMCC or PCC or Pearson's r皮尔森相关系数) and Spearman's correlation(史匹曼等级相关系数)
皮尔森相关系数定义: 协方差与标准差乘积的商。
机器学习中的算法(2)-支持向量机(SVM)基础
mllib
对于我这种以前就是听一听机器学习里面的名词没深入的学过的人来说,这简直就是个庞然大物,今天这个就是个入门,后面在这里要补上很多东西。
下面是对于sparkMllib的介绍:
MLlib(Machine Learning Library) 是 Spark 的机器学习(ML)库。其目标是使实用的机器学习具有可扩展性并且变得容易,它能够较容易地解决一些实际的大规模机器学习问题。在较高的水平上,它提供了以下工具:
- ML Algorithms (ML 算法): 常用的学习算法,如分类,回归,聚类和协同过滤
- Featurization (特征): 特征提取,变换,降维和选择
- Pipelines (管道): 用于构建,评估和调整 ML Pipelines 的工具
- Persistence (持久性): 保存和加载算法,模型和 Pipelines
- Utilities (实用): 线性代数,统计学,数据处理等
统计
这是个简单的例子
//导入统计学支持需要的包
import org.apache.spark.mllib.stat.{MultivariateStatisticalSummary, Statistics}
import org.apache.spark.mllib.linalg.{Vector, Vectors}
import org.apache.spark.rdd.RDD
//denseArray是统计学学库支持的
val array1: Array[Double] = Array[Double](60, 70, 80, 0)
val array2: Array[Double] = Array[Double](80, 50, 0, 90)
val array3: Array[Double] = Array[Double](60, 70, 80, 0)
val denseArray1 = Vectors.dense(array1)
val denseArray2 = Vectors.dense(array2)
val denseArray3 = Vectors.dense(array3)
val seqDenseArray: Seq[Vector] = Seq(denseArray1, denseArray2, denseArray3)
//用三个数组生成的向量序列生成RDD
val basicTestRDD: RDD[Vector] = sc.parallelize[Vector](seqDenseArray)
//获取统计信息
val summary: MultivariateStatisticalSummary = Statistics.colStats(basicTestRDD)
// 每一列的平均分数,即每门课三位学生的平均分数
println(summary.mean)
// 每一列的方差
println(summary.variance)
// 每一列中不为0的成绩数量
println(summary.numNonzeros)
相关性分析
计算两组数据之间的相关性。MLlib 对 Pearson 相关系数和 Spearman 等级相关系数算法提供支持。
下面这个例子假定的场景是有八个用户,他们在服务器上有各自早晚的学习时间的记录,要分析上午用户学习的时间和晚上用户学习时间之间的相关性。
然后就是通过这些数据生成RDD
val morningStudyTime: RDD[Double] = sc.parallelize(List(55, 54, 60, 60, 45, 20, 85, 40), 2)
val nightStudyTime: RDD[Double] = sc.parallelize(List(80, 90, 80, 90, 70, 20, 100, 60), 2)
选择 Pearson 相关系数算法,并调用corr()函数进行计算,并输出结果
val corrType = "pearson"
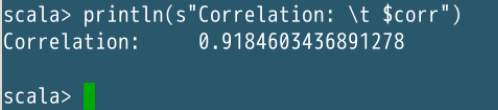
val corr: Double = Statistics.corr(morningStudyTime, nightStudyTime, corrType)
println(s"Correlation: \t $corr")
KMeans聚类算法
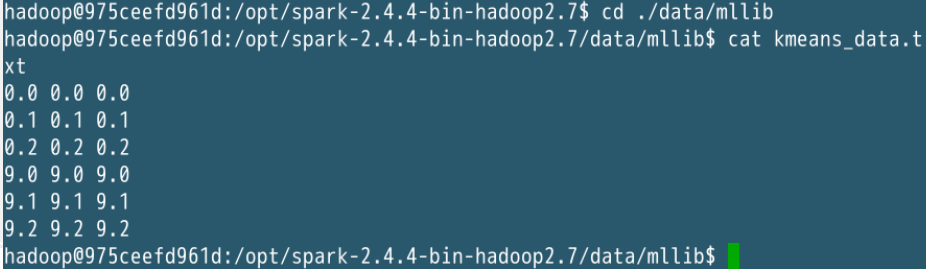
数据是这样的:
导入包
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
import org.apache.spark.mllib.linalg.Vectors
创建RDD,进而创建Vector,这里使用的数据源是官方自带的,供测试用的数据源
// 读取数据文件,创建RDD
val dataFile = "/opt/spark-2.4.4-bin-hadoop2.7/data/mllib/kmeans_data.txt"
val lines = sc.textFile(dataFile)
// 创建Vector,将每行的数据用空格分隔后转成浮点值返回numpy的array
val data = lines.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache()
使用train函数,生成模型
val numClusters = 2
val numIterations = 20
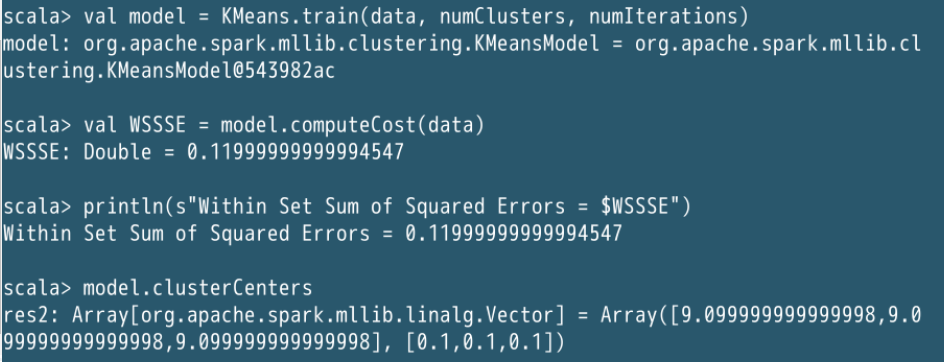
val model = KMeans.train(data, numClusters, numIterations)
统计聚类错误的样本比例,输出聚集中心
val WSSSE = model.computeCost(data)
println(s"Within Set Sum of Squared Errors = $WSSSE")
//输出模型的聚集中心
model.clusterCenters
SVM算法
这个看了一下算法的简介,现在没有太看懂,其实敲完了代码也没有懂,因为api里不涉及这个算法本身。
看不懂,我就学,脑袋学掉了碗大个疤。
先学下api怎么用
首先,需要用到这些包
import org.apache.spark.mllib.classification.{SVMModel, SVMWithSGD}
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import org.apache.spark.mllib.util.MLUtils
数据文件是官方提供的测试数据,
val dataFile = "/opt/spark-2.4.4-bin-hadoop2.7/data/mllib/sample_libsvm_data.txt"
val data = MLUtils.loadLibSVMFile(sc, dataFile)
分割数据,一部分(80%)用来训练,一部分(20%)用来测试
// 随机分割数据,第一个参数指定了分割的比例,第二个参数是一个随机数种子
val splits = data.randomSplit(Array(0.8, 0.2), seed = 9L)
val training = splits(0).cache()
val test = splits(1)
// 打印分割后的数据量
println("TrainingCount:"+training.count())
println("TestingCount:"+test.count())
开始训练,调用SVMWithSGD中的train()函数,这个函数的第一个参数为 RDD 训练数据输入,第二个参数为迭代次数,这里我们设置迭代 100 次,此外这个函数还有其他的参数来设置 SGD 步骤,正则化参数,每轮迭代输入的样本比例,正则化类型等:
val model = SVMWithSGD.train(training, 100)
得到的 SVM 模型后,我们需要进行后续的操作并把结果输出,清除默认的阈值,清除后会输出预测的数字:
model.clearThreshold()
使用测试数据进行预测计算
val scoreAndLabels = test.map { point =>
val score = model.predict(point.features)
(score, point.label)
}
输出结果,包含预测的数字结果和 0/1 结果:
for ((score, label) <- scoreAndLabels.collect())
println(score+","+label)

其他算法实例的文件目录位置
ml和mllib算法实例的位置
/opt/spark-2.4.4-bin-hadoop2.7/examples/src/main/scala/org/apache/spark/examples/mllib
/opt/spark-2.4.4-bin-hadoop2.7/examples/src/main/scala/org/apache/spark/examples/ml/
官方提供的算法测试数据的位置
/opt/spark-2.4.4-bin-hadoop2.7/data/mllib

 浙公网安备 33010602011771号
浙公网安备 33010602011771号