spark学习笔记7 将完整的代码编译打包交付到spark集群运行
sbt安装
sbt 是一款 spark 用来对 scala 编写的程序打包的工具
输入如下的命令可以对sbt进行安装
echo "deb https://dl.bintray.com/sbt/debian /" | sudo tee -a /etc/apt/sources.list.d/sbt.list
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 2EE0EA64E40A89B84B2DF73499E82A75642AC823
sudo apt-get update
sudo apt-get install sbt
apt-get install那个执行完毕之后,输入sbt,这时sbt不会立即启动而会花费很长的时间来下载sbt所需要的依赖关系
等待结束之后会出现交互式命令行:
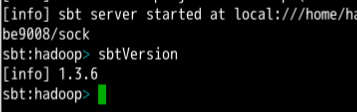
完整地写scala代码
上次,序号是6的学习,我用的是shell
这里为了实现与上次相同的效果,程序是这个样子的(重点就是sc对象要自己来建,因为在sparkshell里面sc对象是现成的,写.scala的代码sc对象就要我自己来创建)
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
object WordCount {
def main(args:Array[String]){
val appName = "WordCount"
val conf = new SparkConf().setAppName(appName)
val sc = new SparkContext(conf)
val inputFiles = "file:///home/hadoop/shakespear/*"
val stopWordFile = "file:///home/hadoop/stopword.txt"
val inputRDD = sc.textFile(inputFiles)
val stopRDD = sc.textFile(stopWordFile)
val targetList: Array[String] = Array[String]("""\t\().,?[]!;|""")
def replaceAndSplit(s: String): Array[String] = {
for(c <- targetList)
s.replace(c, " ")
s.split("\\s+")
}
val inputRDDv1 = inputRDD.flatMap(replaceAndSplit)
val stopList = stopRDD.map(x => x.trim()).collect()
val inputRDDv2 = inputRDDv1.filter(x => !stopList.contains(x))
val inputRDDv3 = inputRDDv2.map(x => (x,1))
val inputRDDv4 = inputRDDv3.reduceByKey(_ + _)
inputRDDv4.saveAsTextFile("/tmp/v4output")
val inputRDDv5 = inputRDDv4.map(x => x.swap)
val inputRDDv6 = inputRDDv5.sortByKey(false)
val inputRDDv7 = inputRDDv6.map(x => x.swap).keys
val top100 = inputRDDv7.take(100)
val outputFile = "/tmp/result"
val result = sc.parallelize(top100)
result.saveAsTextFile(outputFile)
}
}
指明依赖关系以及具体版本
给程序编译打包的工具是我上面装的sbt,用这个东西,需要在.scala源码文件所在项目的根目录下创建一个.sbt文件。这个.sbt文件是用来指明依赖关系以及依赖的具体版本的。
我使用的实验楼的实验环境,scala版本是2.11.8,spark版本是2.4.4
name := "WordCount"
version := "1.0.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.4"
 # sbt编译打包处理
项目的结构比较简单。
使用sbt编译并打包的命令是
sbt package
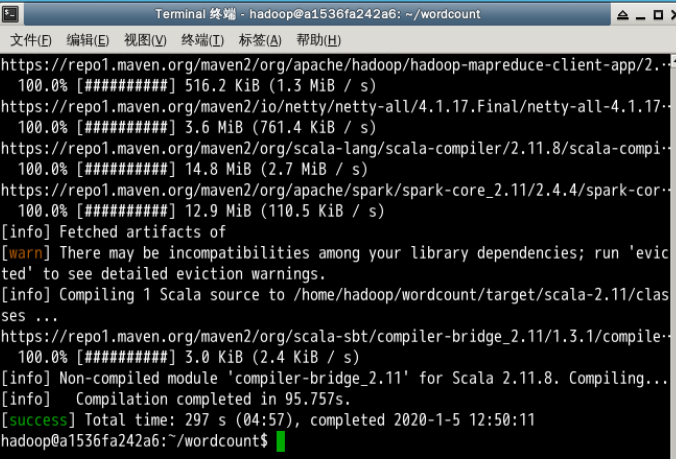
这个命令需要在项目的根目录下执行,这个命令会执行很久,因为这个编译打包的工具要用网。。。
然后,终于,很艰难地success了
# sbt编译打包处理
项目的结构比较简单。
使用sbt编译并打包的命令是
sbt package
这个命令需要在项目的根目录下执行,这个命令会执行很久,因为这个编译打包的工具要用网。。。
然后,终于,很艰难地success了
 # 使用spark yarn交付至spark集群运行
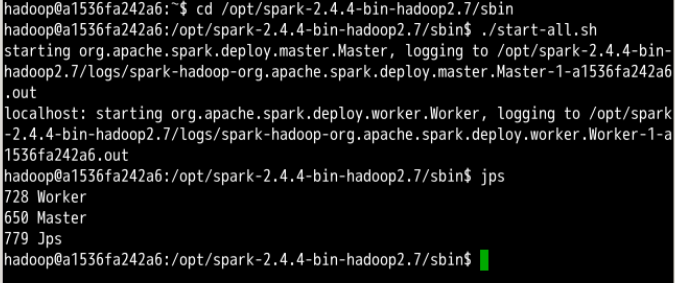
这是单机部署的spark,有一个master节点和一个worker节点
# 使用spark yarn交付至spark集群运行
这是单机部署的spark,有一个master节点和一个worker节点
 然后,让spark集群(好吧这里就是master和worker两个节点)运行刚才sbt编译打包好的程序的命令是:spark-submit
刚才.sbt配置文件里面的项目名是WordCount
所以,在hadoop用户下,根据刚才项目的结构,使用spark-submit运行的命令是这样的:
```
spark-submit --class "WordCount" ~/wordcount/target/scala-2.11/wordcount_2.11-1.0.0.jar
```
结果和上次用shell做的结果是一样的,但是最大的问题在于这是一台机器的两个节点并不是真实场景下的多机的spark集群做的并行计算,所以这么搞现在是可以的,但是早晚还是得用几台虚拟机一起做
然后,让spark集群(好吧这里就是master和worker两个节点)运行刚才sbt编译打包好的程序的命令是:spark-submit
刚才.sbt配置文件里面的项目名是WordCount
所以,在hadoop用户下,根据刚才项目的结构,使用spark-submit运行的命令是这样的:
```
spark-submit --class "WordCount" ~/wordcount/target/scala-2.11/wordcount_2.11-1.0.0.jar
```
结果和上次用shell做的结果是一样的,但是最大的问题在于这是一台机器的两个节点并不是真实场景下的多机的spark集群做的并行计算,所以这么搞现在是可以的,但是早晚还是得用几台虚拟机一起做
参考资料
apt-key Debian packages密钥管理命令
apt-get软件包管理命令 和 apt-key命令
Linux的tee命令

 浙公网安备 33010602011771号
浙公网安备 33010602011771号