spark 笔记4 sparkRDD基本操作_连接_创建RDD_转换_行动
spark RDD
关于sparkRDD基本概念
- RDD:弹性分布式数据集,是spark对数据的核心抽象,也是spark数据处理的基本单位
spark处理数据之前会首先把数据转换成RDD然后在RDD上对数据进行操作 - spark对RDD的数据操作,其本身有两种对于RDD的算子:转换(transform)和行动(action),这两个分类下分别由各自对应的数个api函数
对于数据,spark的操作过程是:创建RDD、对RDD进行转化操作(transform)、用行动操作来求值(action) - 该数据操作流程的便捷性:spark底层节点的协商、容错、通信的细节,这样在上层对于数据的操作就变得更容易
学习对于RDD的基本操作
主从节点的启动
首先就像第一次学在笔记1里面记录的一样,启动spark主节点的服务,然后在localhost:8080查看spark主节点的参数并且记录下来

然后就可以使用这个主节点的参数,启动这个主节点的从节点
spark的初始化
在开发程序时,spark的初始化操作首先就是创建一个SparkConf对象,这个对象包含应用的一些信息,然后创建SparkContext,SparkContext可以让 Spark 知道如何访问集群
那么,代码是这个样子的
就是在指定app名和主节点所在的spark集群之后,使用这个conf对象指定给一个sparkcontext方法来创建一个sparkcontext
val conf = new SparkConf().setAppName("Shiyanlou").setMaster("spark://7576cf9c687e:7077")
new SparkContext(conf)
// 在每个JVM中,只有一个SparkContext能够被激活。若需要创建新的SparkContext,你必须调用sc.stop()来关闭当前已激活的那个
在spark-shell里做spark的初始化并不需要新建这两个对象,因为 Spark Shell 相当于一个 Spark 应用,启动时已经用过spark-shell --master spark://7576cf9c687e:7077来指定集群信息,所以 Spark Shell 启动后已经具备了一个 SparkContext 对象sc
RDD创建
Spark 上开发的应用程序都是由一个driver programe构成,这个所谓的驱动程序在 Spark 集群通过跑main函数来执行各种并行操作。集群上的所有节点进行并行计算需要共同访问一个分区元素的集合,这就是 RDD(RDD:resilient distributed dataset)弹性分布式数据集。RDD 可以存储在内存或磁盘中,具有一定的容错性,可以在节点宕机重启后恢复。
RDD 可以从 HDFS 中的文件创建,也可以从 Scala 或 Python 集合中创建。
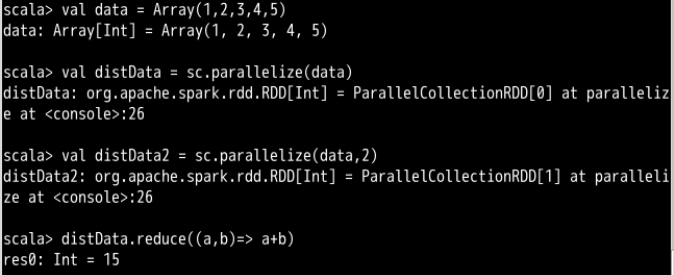
创建 RDD 有两种方式:一种是调用 SparkContext 的 parallelize() 方法将数据并行化生成 RDD,另外一种方法是从外部存储中的数据集生成 RDD(如 Linux 文件系统,HDFS,HBase 等)
调用parallelize()方法并行化生成RDD
如果要对已有的集合进行并行化,我们可以先创建一个列表,然后调用上面提到的sc的parallelize方法将该集合并行化。集合中的元素会被复制到一个 RDD 中。并行集合创建后可以进行 RDD 的分布式操作,一个很重要的参数是切片数(slices),表示数据集被切分的份数,Spark 会为每个切片运行一个任务并能够根据集群状况动态调整切片数量。使用parallelize方法的参数可以手动设置切片数。
这种并行集合生成RDD的办法会把所有的数据都放在内存里,所以除了开发原型和测试以外,一般不采用这种方式
就这样,把新建的数据列表传给parallelize这个函数,这个函数就会在这个数据集合的基础上为我们创建RDD,并且RDD的切片数同样可以通过parallelize函数来指定
使用外部存储中的数据集生成RDD
在实际开发中最常用的是从外部存储系统中读取数据创建 RDD。Spark 可以从任何 Hadoop 支持的存储上创建 RDD,比如本地的文件系统、HDFS、Cassandra、HBase 等。同时 Spark 还支持文本文件、SequenceFiles 等
注意事项
- 使用不同的 SparkContext 的函数接口可以在不同的外部存储场景下创建RDD。然后使用 testfile() 方法会返回一个 RDD 对象,然后就可以调用 RDD 中定义的方法
- 如果使用本地存储上的文本文件,这个文件必须可以被所有节点 worker 访问
- 支持目录,压缩文件及通配符
- 同上一节的并行集合一样,textFile 函数还有另外一个接口控制切片数目
// 从 protocols 文件中创建 RDD
val distFile = sc.textFile("/etc/protocols")
// RDD 操作:计算所有行的长度之和,最后结果为 2868
distFile.map(s => s.length).reduce((a,b) => a + b)
RDD的这个操作也是做的一个mapreduce,用map来把每一行映射成每一行的长度,reduce做的是把数据集合里面的元素相加
正式的、RDD的基础操作
对于RDD的基础操作有两种:transformations和actions
- 转换(transformations):将已存在的数据集 RDD 转换成新的数据集 RDD,例如 map。转换是惰性的,不会立刻计算结果,仅仅记录转换操作应用的目标数据集,当动作需要一个结果时才计算。
- 动作(actions) :在数据集 RDD 上进行计算后返回一个结果值给驱动程序,例如 reduce。
// 从 protocols 文件创建RDD
val distFile = sc.textFile("/etc/protocols")
// Map 操作,每行的长度
val lineLengths = distFile.map(s => s.length)
// Reduce 操作,获得所有行长度的和,即文件总长度,这里才会执行 map 运算
val totalLength = lineLengths.reduce((a, b) => a + b)
// 可以将转换后的 RDD 保存到集群内存中
lineLengths.persist()
上面这个例子里面,map操作敲进去的时候,并没有被执行,在敲完reduce求和的时候,map运算才被执行的,也就是说想要的到最后map出来的结果要执行完reduce才行
persist方法是把map完的那个RDD保留到内存里
WordCount的例子
val textFile = sc.textFile("/etc/protocols")
val counts = textFile.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_ + _)
counts.saveAsTextFile("/home/hadoop/counts")
首先,使用 SparkContext 的 textFile() 函数从本地读取 /etc/protocols 文件将其转化为记录着每一行内容的 RDD。
其次,使用 .flatMap(line => line.split(" ")) 把每一行的内容按照空格分隔开,将其转化为记录着每一个单词的 RDD。
然后,使用 .map(word => (word,1)) 把记录着每一个单词的 RDD 转化为 (word,1) 这种表示每一个单词出现一次的键值对形式的 RDD。
接着,使用 .reduceByKey(_ + _) 把具有相同键的 RDD 的次数进行相加,求出每个单词的词频。
最后,使用 saveAsTextFile() 函数把结果存入 /home/hadoop/counts 文件夹中。
在文件系统中查看文件
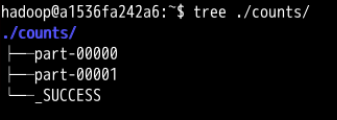
查看文件的内容

RDD转化操作transformation
转化的 RDD 都是惰性求值的,只有执行行动操作才会被真正的计算。Spark 只是在内部记录下需要转化的操作,真正有必要时才会执行这些操作,所以应该把 RDD 当做记录如何计算数据的指令列表。比如上面的例子中使用 textFile() 函数读取文件的内容,程序并没有真正的读取这个文件,否则加载大量的数据会占用极大的内存,在遇到执行操作 first() 需要获取第一行的数据时去执行读取文件的第一行并返回数据。从上面的例子中可以看出这样会极大的优化程序执行的效率。
一般转化操作分为两类,一类是对所有 RDD 的每一个元素进行转化,另一类是只对具有相同键的所有 RDD 进行转化。
- map()
参数是函数,函数应用于 RDD 每一个元素,返回值为新的 RDD。
![]()
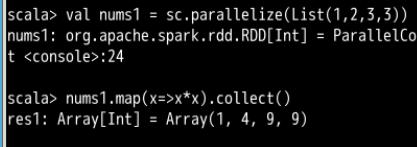
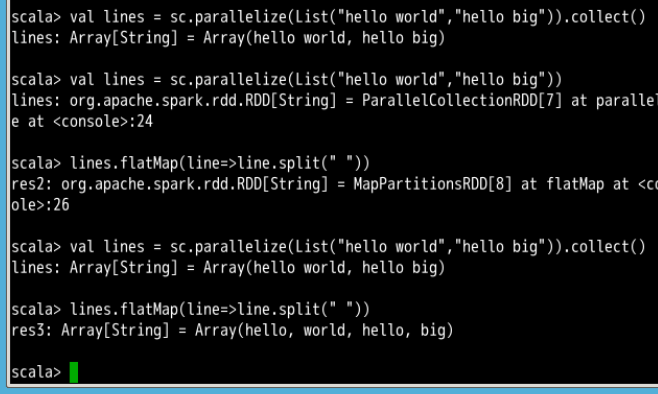
- flatMap()
参数是函数,把每个输入元素生成多个输出元素,函数应用于 RDD 每一个元素,将元素数据进行拆分变为迭代器,返回值为新的 RDD。通常用来切分单词
例子如下
![]()
而且通过上图的比对,加不加collect函数的区别体现在输出结果上,用了collect能够直观地看到结果 - filter()
参数是函数,使用函数过滤掉不符合条件的元素,返回新的 RDD
![]()
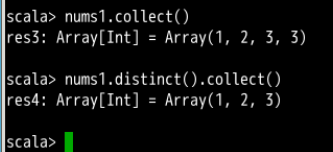
- distinct()
用来把RDD的元素进行去重
![]()
- union()
参数是RDD,生成包含两个RDD的所有数据的新RDD
![]()
- intersection()
参数是 RDD,生成包含两个 RDD 共同元素的新 RDD。
![]()
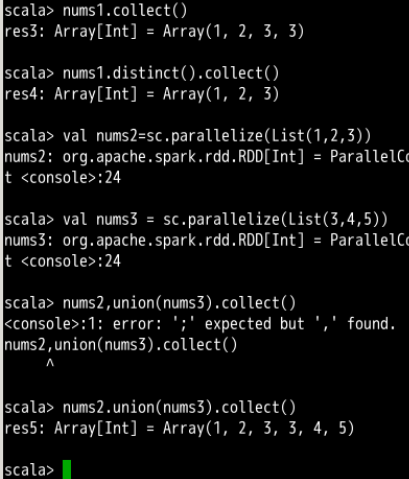
- subtract()
参数是 RDD,将原 RDD 里和参数 RDD 里相同的元素去掉生成新的 RDD。
![]()
这个比较有意思,实际上是nums2调用的方法,所以去掉的相同元素其实是,nums2里面拥有的和nums3一样的元素,剩下的nums2里面的元素



RDD行动操作actions
- collect()
这个刚才转化的例子里面有很多都用到了,作用是返回RDD里面的所有元素
![]()
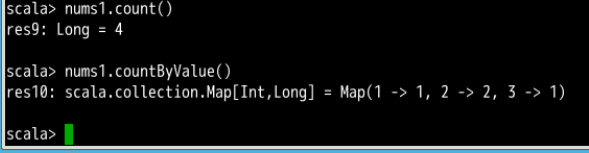
- count()
计算RDD中的元素的个数 - countByValue()
计算各个元素在RDD中出现的次数
![]()
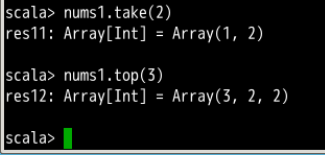
- take(num)
从 RDD 中返回 num 个元素。 - top(num)
从 RDD 中返回最前面的 num 个元素。
比对一下:
![]()
- reduce(func)
并行整合 RDD 中所有数据。reduce 将 RDD 中元素两两传递给输入函数求得一个新值,再把新值与 RDD 中的下一个值一起传递给输入函数直到最后一个值为止。
![]()
- fold(zero)(func)
和 reduce() 一样,但是需要提供初始值。fold有一个“zero”值,数据存在多少个分区中就有多少个“zero”值。该函数现计算每一个分区中的数据,再计算分区之间中的数据。所以,有多少个分区就会有多少个“zero”值被包含进来。看这个分区,需要调用partition
![]()
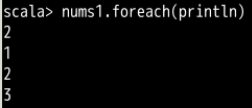
一共是4个分区,但是最后在8上加上的是Zero*5而不是乘4,目前还不太懂 - foreach(func)
对 RDD 中每个元素使用给定的元素
![]()
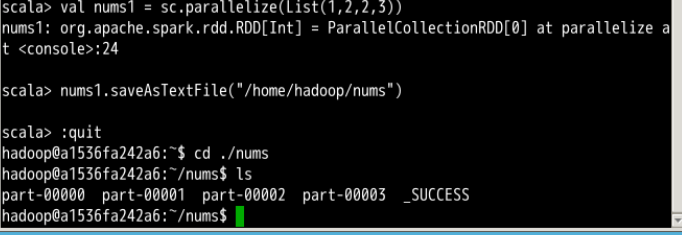
- 以文件格式存储
有 3 个方法可以做,分别是:saveAsTextFile(path)、saveAsSequenceFile(path)、saveAsObjectFile(path)
将 RDD 以不同的文件格式(文本文件、Sequence 格式文件、对象文件)存储在本地文件系统或 Hadoop 文件系统中
![]()



总结
基本编程步骤总结
所以,课程里面是这样总结的:
RDD 基本编程步骤可以总结为:
1.读取内、外部数据集创建 RDD。
2.对于 RDD 进行转化生成新的 RDD ,比如 map()、filter() 等。
3.对需要重用的数据执行 persist()/cache() 进行缓存。
4.执行行动操作获得最终结果,比如 count() 和 first()等。
没有做的实践操作
导入并使用jar包
还没有一个具体的应用场景,让我指定某个具体的jar包

集成编译环境下的配置操作


 浙公网安备 33010602011771号
浙公网安备 33010602011771号