
半监督学习:MixMatch和ReMixMatch
之前介绍了无监督学习(UL)以及自监督学习(self-supervise)的相关论文和方法。今天,介绍几篇关于半监督学习(SSL)相关的论文,包括MixMatch(NeurIPS 19)和ReMixMatch(ICLR 20)。需要注意的是,这里我们用SSL指代semi-supervised learning,其他地方有些作者也会用SSL来指代self-supervised learning。
Mixup
Mixup作为一种简单有效的数据增强方法,最近被广泛用在无监督、半监督等多个领域。假设 是两个随机选取的训练样本,作如下处理:
将 作为增强数据或者虚拟训练数据。Mixup可以提升模型的鲁棒性和泛化能力。
MixMatch
最近的许多半监督学习方法,通过在无标签数据上加一个损失项来使模型具有更好的泛化能力。损失项通常包含以下三种:1. 熵最小化(entropy minimization),鼓励模型在无标签数据上输出高置信度的预测结果;2. 一致性约束(consistency regularization),鼓励模型在数据有扰动之后输出相同的概率分布,3. 通用正则化(generic regularization),鼓励更好泛化和降低过拟合。MixMatch通过将现有方法融合到一个损失里面,取得了很好的效果。
Step1. 数据增强。对于单个有标签样本做1次增强: ,对于单个无标签样本做k次增强:
对于一个batch_size=B的数据,
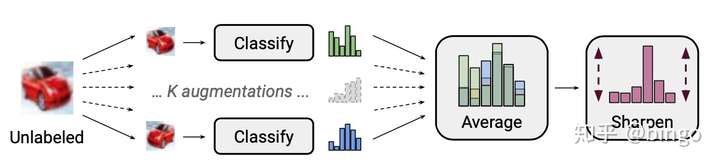 图1. 标签猜测和锐化过程。首先,将K个数据增强样本的预测结果进行平均,然后通过调整分布的"温度"进行锐化。
图1. 标签猜测和锐化过程。首先,将K个数据增强样本的预测结果进行平均,然后通过调整分布的"温度"进行锐化。
Step2. 标签猜测和锐化。如图1,对于无标签数据,得到K个数据增强样本之后,输入到模型产生预测结果,并且将这些结果进行平均: 。然后,通过调整"温度"进行锐化:
。
Step3. Mixup。这一步和mixup的区别在于 的处理:
。通过max操作,对于有标签数据,它们mixup之后的标签会更加接近原始标签。MixUp过程如下:
是我们对有标签和无标签数据进行增强之后得到的新训练数据。
Step4. 损失函数。对有标签的数据,使用交叉熵(cross-entropy)损失 ;对无标签数据,使用最小均方差(MSE)损失
。计算如下:
实验结果。如图2.
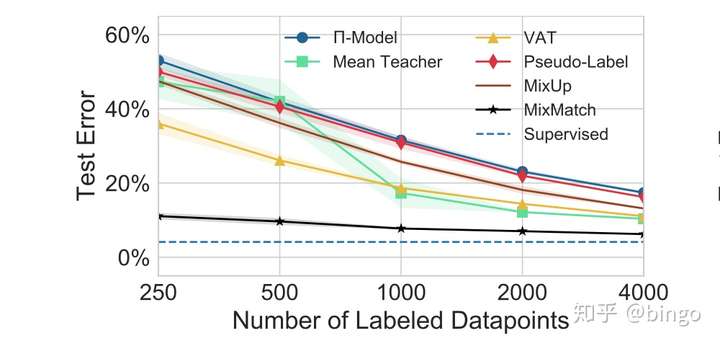 图2. CIFAR10错误率随着有标签数据变化图。可以看出,MixMatch的错误率明显低于对比方法。
图2. CIFAR10错误率随着有标签数据变化图。可以看出,MixMatch的错误率明显低于对比方法。
ReMixMatch
在MixMatch的基础上,原作者自己提出了改进版本:ReMixMatch,发表在ICLR 2020。
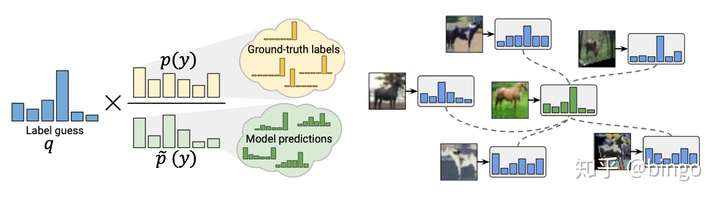 图3. (左):Distribution Alignment,将无标签数据的预测分布和有标签数据对齐;(右):Augmentation Anchor,使用弱增强样本(绿)的预测结果,作为强增强样本(蓝)的训练目标。
图3. (左):Distribution Alignment,将无标签数据的预测分布和有标签数据对齐;(右):Augmentation Anchor,使用弱增强样本(绿)的预测结果,作为强增强样本(蓝)的训练目标。
如图3,ReMixMatch的改进主要包括两部分:Distribution Alignment和Augmentation Anchor。
- Distribution Alignment。由于MixMatch的标签猜测可能存在噪声和不一致的情况,作者提出利用有标签数据的标签分布,对无标签猜测进行对齐。如图3,
是对当前无标签数据的标签猜测,
是一个运行平均版本(running average)的无标签猜测,
是有标签数据的标签分布。对齐之后的标签猜测如下:
- Augmentation Anchor。作者的假设是对样本进行简单增强(比如翻转和裁切)之后的预测结果,要比多次复杂变换更加可靠和稳定。因此,对于同一张图片,首先进行弱增强,得到预测结果
,然后对同一张图片进行复杂的强增强。弱增强和强增强共同使用一个标签猜测
进行Mixup和模型训练。
实验结果:
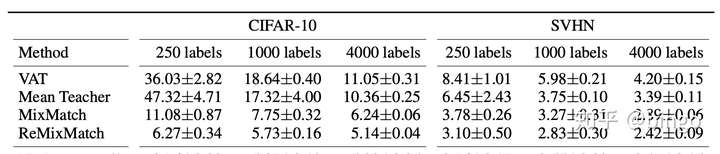 图4. ReMixMatch实验结果。
图4. ReMixMatch实验结果。
总结
Mixup同时对数据和标签进行插值操作,它的有效性在很多应用场景得到了验证。
MixMatch将多种半监督策略统一到一个损失函数中,取得了很好的效果。
ReMixMatch使用监督数据的标签分布对无监督数据的标签猜测进行对齐,同时将弱增强样本的预测结果作为强增强样本的训练目标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号