
数据科学与大数据技术作业三_102302107_林诗樾
第三次作业
一、作业内容
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
(1)代码
import requests
import os
from bs4 import BeautifulSoup
import re
from urllib.parse import urljoin
import time
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
class WeatherImageSpider:
def __init__(self, max_pages=7, max_images=107): # 根据学号102302107调整:页数7,图片107
self.max_pages = max_pages
self.max_images = max_images
self.downloaded_count = 0
self.base_url = "http://www.weather.com.cn/"
self.images_dir = "images"
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
})
if not os.path.exists(self.images_dir):
os.makedirs(self.images_dir)
def download_image(self, img_url, filename):
"""下载单张图片"""
try:
response = self.session.get(img_url, timeout=10)
if response.status_code == 200:
filepath = os.path.join(self.images_dir, filename)
with open(filepath, 'wb') as f:
f.write(response.content)
print(f"下载成功: {img_url} -> {filename}")
return True
except Exception as e:
print(f"下载失败 {img_url}: {e}")
return False
def extract_images_from_page(self, url):
"""从页面提取图片链接"""
try:
response = self.session.get(url, timeout=10)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
images = []
# 查找各种图片标签
for img in soup.find_all('img'):
src = img.get('src') or img.get('data-src')
if src:
full_url = urljoin(url, src)
# 过滤有效图片
if any(ext in full_url.lower() for ext in ['.jpg', '.jpeg', '.png', '.gif', '.webp']):
if 'icon' not in full_url.lower() and 'logo' not in full_url.lower():
images.append(full_url)
return list(set(images)) # 去重
except Exception as e:
print(f"提取页面图片失败 {url}: {e}")
return []
def get_pages_to_crawl(self):
"""获取要爬取的页面列表"""
# 中国气象网的主要板块
sections = [
"weather/", "forecast/", "alarm/", "radar/",
"satellite/", "typhoon/", "disaster/"
]
return [urljoin(self.base_url, section) for section in sections[:self.max_pages]]
def run_single_thread(self):
"""单线程爬取"""
print("开始单线程爬取图片...")
print(f"限制参数: 最大页数={self.max_pages}, 最大图片数={self.max_images}")
pages = self.get_pages_to_crawl()
for i, page_url in enumerate(pages):
if self.downloaded_count >= self.max_images:
print(f"已达到图片数量限制 {self.max_images},停止爬取")
break
print(f"正在爬取页面 [{i + 1}/{len(pages)}]: {page_url}")
image_urls = self.extract_images_from_page(page_url)
print(f"在该页面找到 {len(image_urls)} 张图片")
for j, img_url in enumerate(image_urls):
if self.downloaded_count >= self.max_images:
break
# 生成文件名
ext = '.jpg'
if '.png' in img_url.lower():
ext = '.png'
elif '.gif' in img_url.lower():
ext = '.gif'
filename = f"image_{self.downloaded_count + 1}{ext}"
if self.download_image(img_url, filename):
self.downloaded_count += 1
time.sleep(0.5) # 礼貌延迟
print(f"单线程爬取完成,共下载 {self.downloaded_count} 张图片")
class MultiThreadWeatherSpider(WeatherImageSpider):
def __init__(self, max_pages=7, max_images=107, max_workers=3):
super().__init__(max_pages, max_images)
self.max_workers = max_workers
self.lock = threading.Lock()
def download_worker(self, img_url):
"""多线程下载工作函数"""
if self.downloaded_count >= self.max_images:
return None
# 生成文件名
ext = '.jpg'
if '.png' in img_url.lower():
ext = '.png'
elif '.gif' in img_url.lower():
ext = '.gif'
filename = f"mt_image_{self.downloaded_count + 1}{ext}"
success = self.download_image(img_url, filename)
if success:
with self.lock:
if self.downloaded_count < self.max_images: # 双重检查
self.downloaded_count += 1
return img_url
return None
def run_multi_thread(self):
"""多线程爬取"""
print("开始多线程爬取图片...")
print(f"限制参数: 最大页数={self.max_pages}, 最大图片数={self.max_images}")
pages = self.get_pages_to_crawl()
all_image_urls = []
# 先收集所有图片链接
for i, page_url in enumerate(pages):
print(f"收集图片链接 [{i + 1}/{len(pages)}]: {page_url}")
image_urls = self.extract_images_from_page(page_url)
all_image_urls.extend(image_urls)
if len(all_image_urls) >= self.max_images * 2: # 收集足够多的链接
break
print(f"共收集到 {len(all_image_urls)} 个图片链接")
all_image_urls = all_image_urls[:self.max_images * 2] # 限制数量
# 使用线程池下载
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
futures = []
for img_url in all_image_urls:
if self.downloaded_count >= self.max_images:
break
future = executor.submit(self.download_worker, img_url)
futures.append(future)
time.sleep(0.1) # 控制提交速度
# 等待完成
completed = 0
for future in as_completed(futures):
try:
result = future.result(timeout=30)
completed += 1
if result and completed % 10 == 0:
print(f"已完成 {completed}/{len(futures)} 个下载任务")
except Exception as e:
print(f"下载任务异常: {e}")
print(f"多线程爬取完成,共下载 {self.downloaded_count} 张图片")
if __name__ == "__main__":
print("=" * 60)
print("作业①:中国气象网图片爬虫")
print("学号: 102302107 -> 页数限制: 7, 图片数量限制: 107")
print("=" * 60)
# 单线程爬取
print("\n1. 单线程爬取开始...")
spider_single = WeatherImageSpider(max_pages=7, max_images=107)
spider_single.run_single_thread()
# 多线程爬取(使用不同的图片目录)
print("\n2. 多线程爬取开始...")
spider_multi = MultiThreadWeatherSpider(max_pages=7, max_images=107)
spider_multi.images_dir = "images_mt" # 使用不同的目录
if not os.path.exists(spider_multi.images_dir):
os.makedirs(spider_multi.images_dir)
spider_multi.run_multi_thread()
print("\n" + "=" * 60)
print("作业①完成!")
print("=" * 60)
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
运行结果:
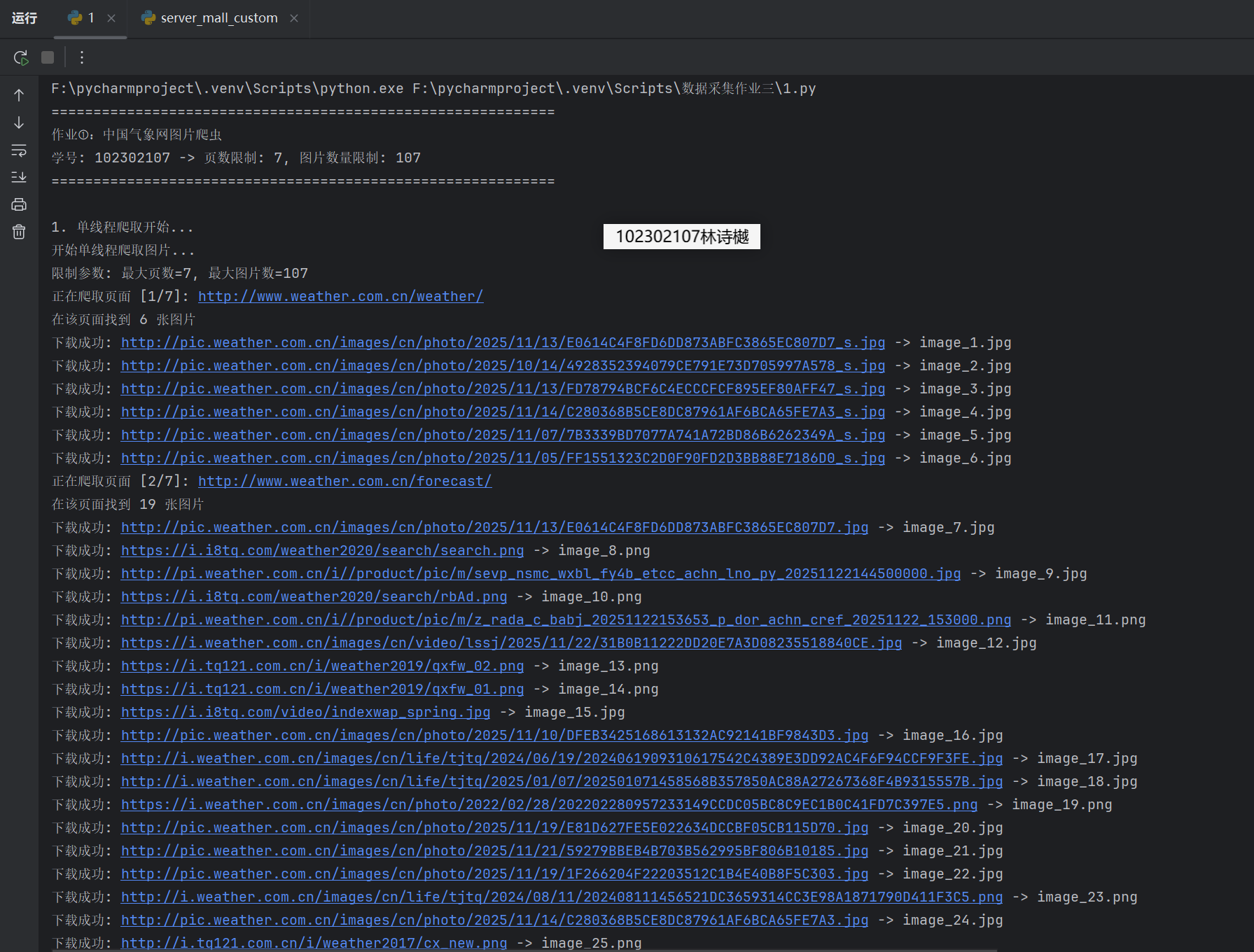
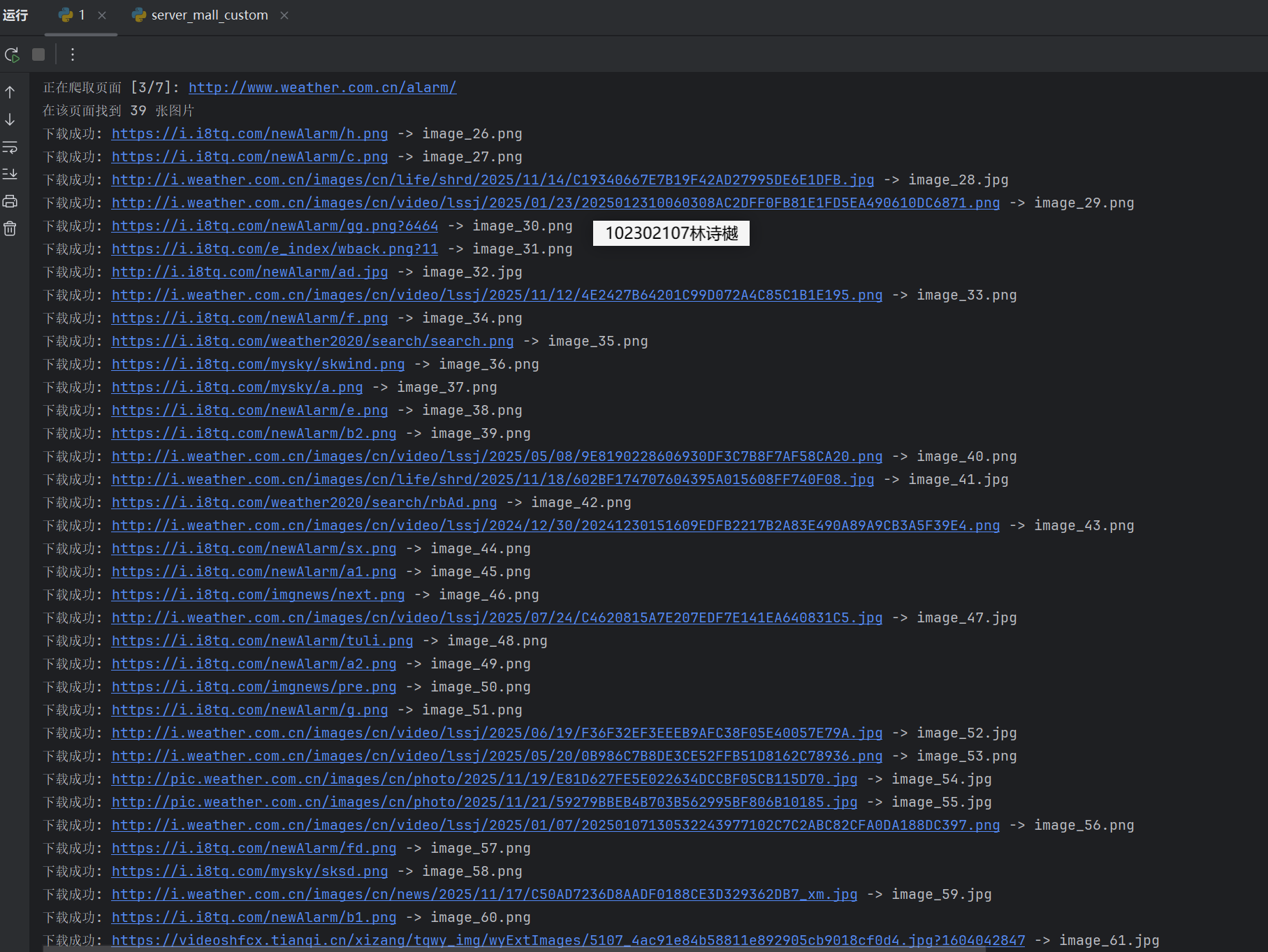
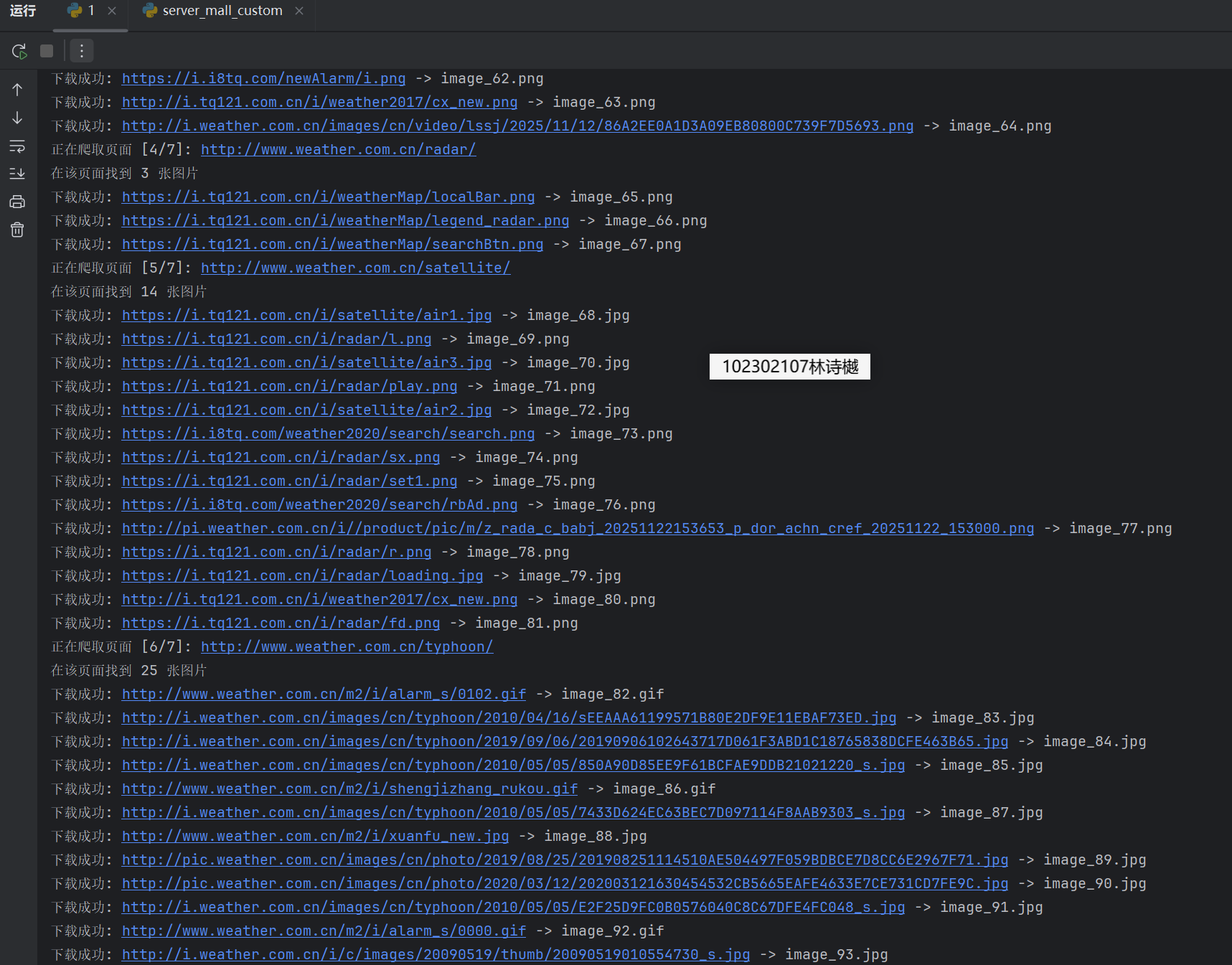
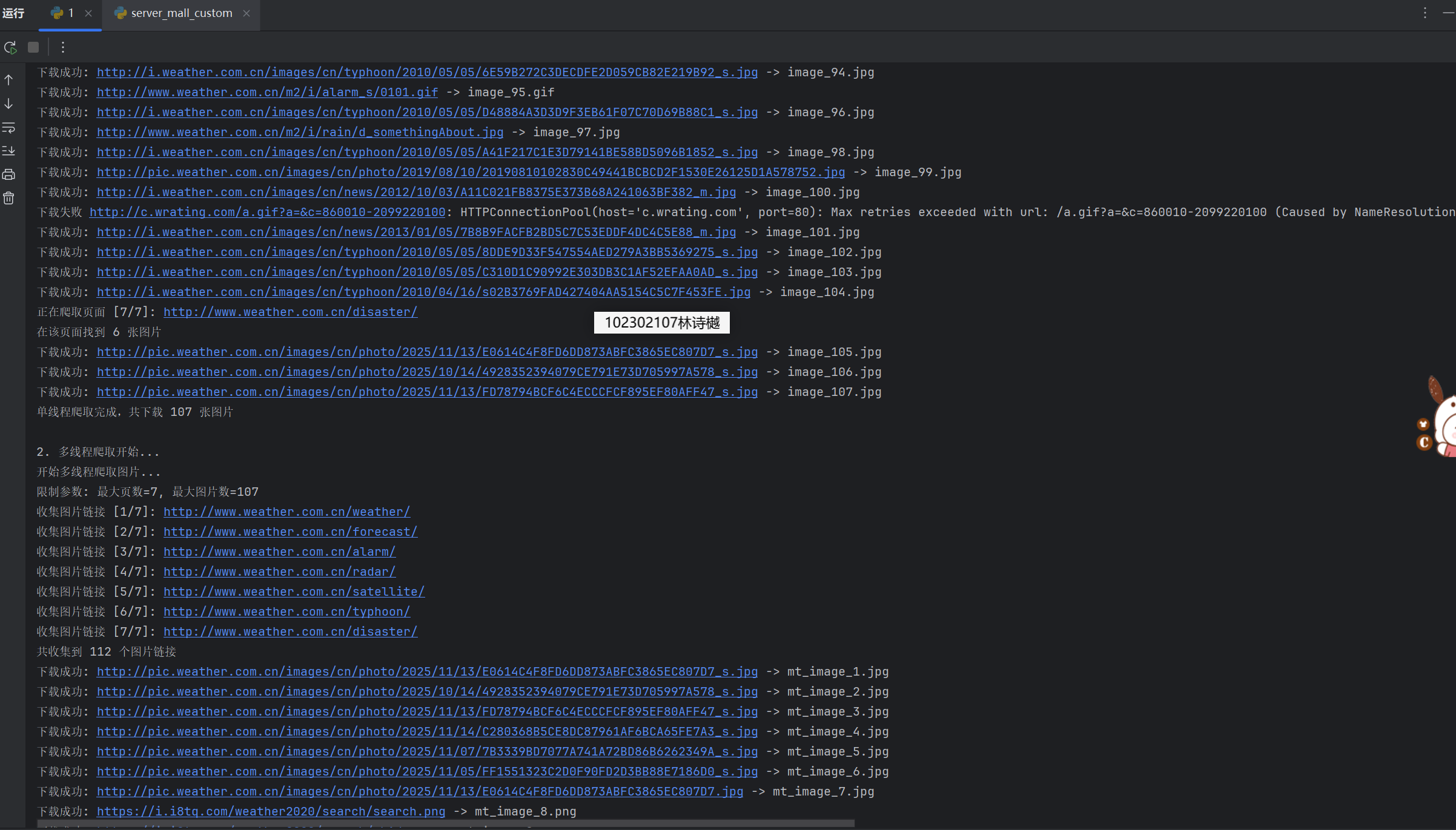
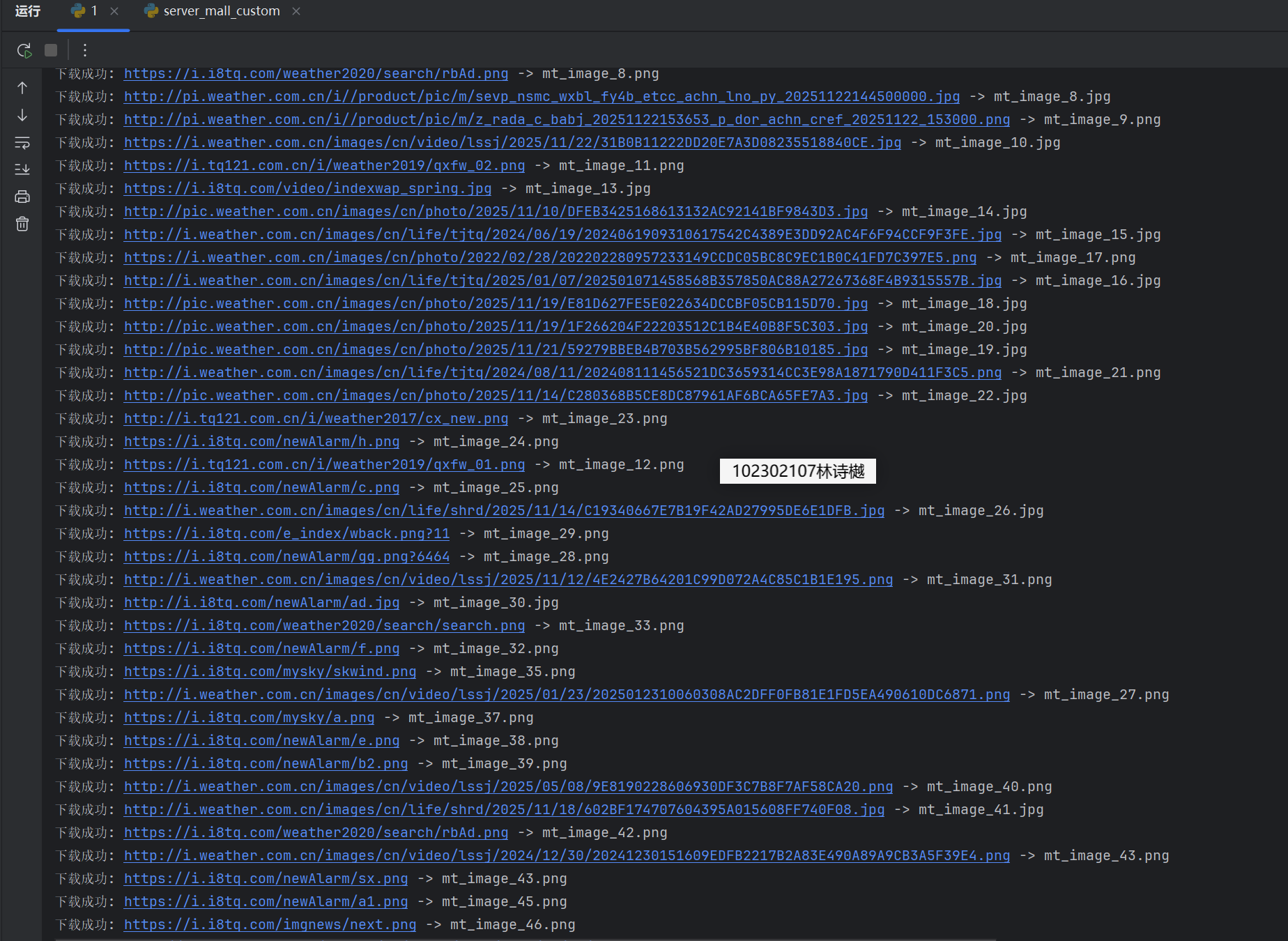
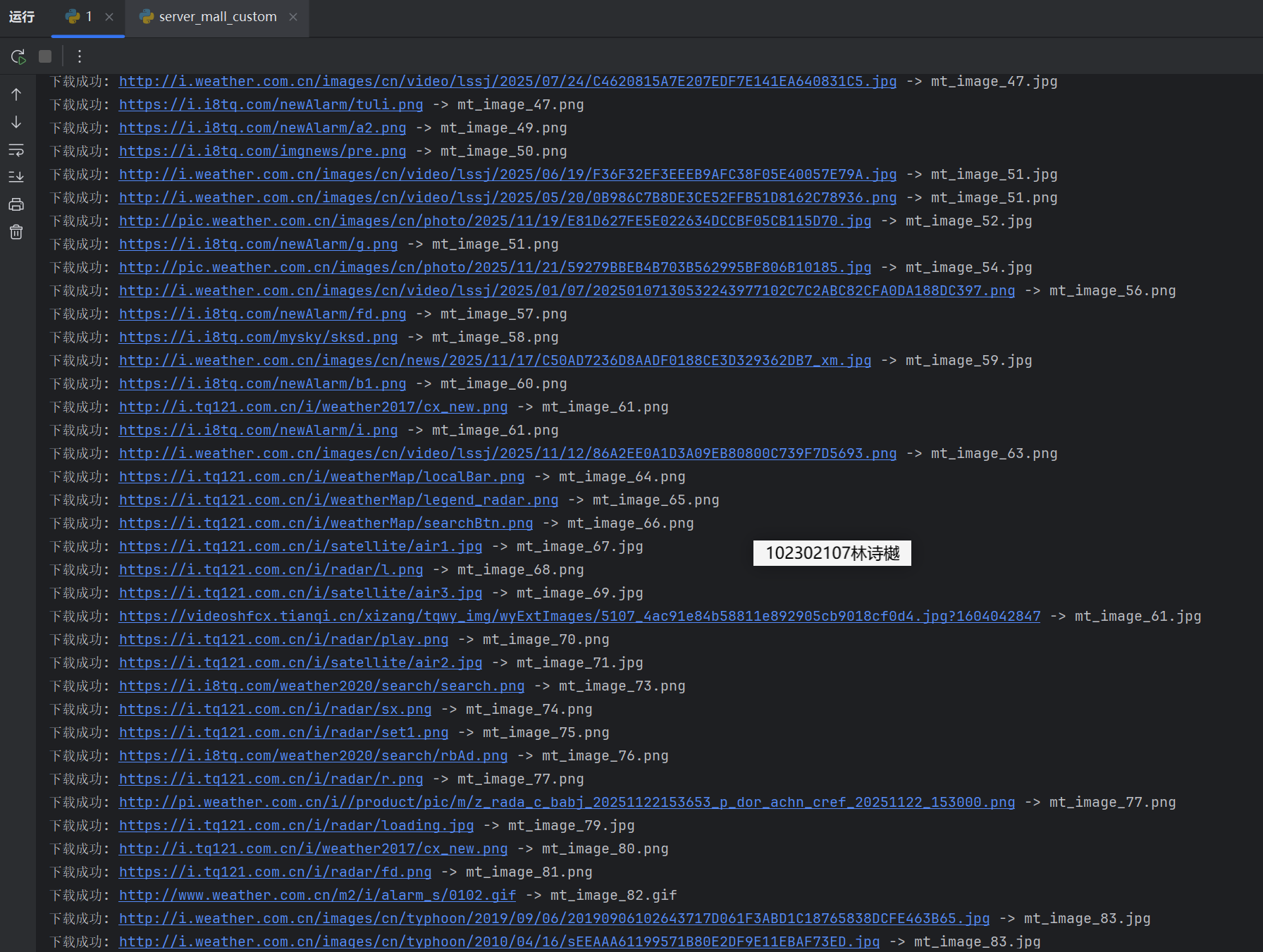
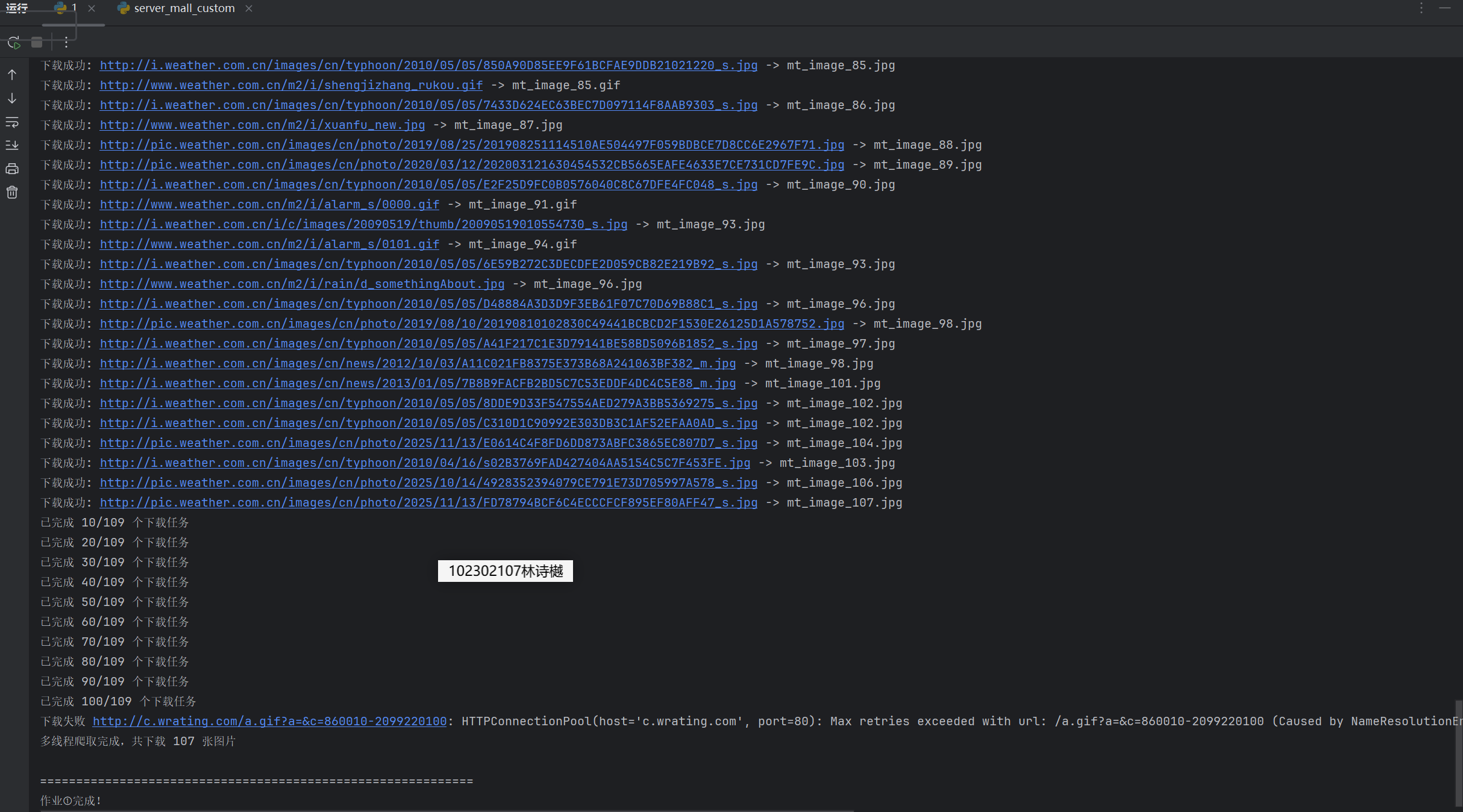
Gitee文件夹链接:https://gitee.com/ls-yue/2025_crawl_project/blob/master/作业3/weather_spider.py
(2)心得体会:通过本次气象图片爬取作业,我深刻体会到多线程技术在网络爬虫中的巨大优势。单线程爬取虽然逻辑简单,但效率低下;而多线程通过并发请求显著提升了下载速度。在实现过程中,我掌握了线程池的管理、资源竞争的处理以及异常控制机制。同时,面对网站反爬机制时,合理设置请求间隔和模拟真实浏览器行为至关重要。这次实践让我对Python并发编程有了更深入的理解。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
(1)代码:
(a)编辑eastmoney_stock/settings.py:
# Scrapy settings for eastmoney_stock project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "eastmoney_stock"
SPIDER_MODULES = ["eastmoney_stock.spiders"]
NEWSPIDER_MODULE = "eastmoney_stock.spiders"
ADDONS = {}
# 启用MySQL Pipeline
ITEM_PIPELINES = {
'eastmoney_stock.pipelines.MySQLPipeline': 300,
'eastmoney_stock.pipelines.JsonPipeline': 200,
'eastmoney_stock.pipelines.CsvPipeline': 100,
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "eastmoney_stock (+http://www.yourdomain.com)"
# Obey robots.txt rules
# MySQL配置
MYSQL_HOST = 'localhost'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '744983'
MYSQL_DATABASE = 'stock_db'
MYSQL_PORT = 3306
# 爬虫配置
ROBOTSTXT_OBEY = False
# Concurrency and throttling settings
#CONCURRENT_REQUESTS = 16
CONCURRENT_REQUESTS_PER_DOMAIN = 1
DOWNLOAD_DELAY = 1
# 其他设置...
FEED_FORMAT = 'json'
FEED_URI = 'stock_data.json'
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "eastmoney_stock.middlewares.EastmoneyStockSpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "eastmoney_stock.middlewares.EastmoneyStockDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# "eastmoney_stock.pipelines.EastmoneyStockPipeline": 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
FEED_EXPORT_ENCODING = "utf-8"
(b)编辑eastmoney_stock/pipelines.py:
import pymysql
import logging
from itemadapter import ItemAdapter
import json
import csv
class MySQLPipeline:
def __init__(self, mysql_config):
self.mysql_config = mysql_config
self.connection = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_config={
'host': crawler.settings.get('MYSQL_HOST', 'localhost'),
'user': crawler.settings.get('MYSQL_USER', 'root'),
'password': crawler.settings.get('MYSQL_PASSWORD', ''),
'database': crawler.settings.get('MYSQL_DATABASE', 'stock_db'),
'port': crawler.settings.get('MYSQL_PORT', 3306),
'charset': crawler.settings.get('MYSQL_CHARSET', 'utf8mb4'),
'cursorclass': pymysql.cursors.DictCursor
}
)
def open_spider(self, spider):
"""爬虫启动时连接数据库"""
try:
self.connection = pymysql.connect(**self.mysql_config)
self.cursor = self.connection.cursor()
self.create_table()
logging.info("✓ MySQL数据库连接成功")
except Exception as e:
logging.error(f"✗ 数据库连接失败: {e}")
# 尝试创建数据库
self.create_database_if_not_exists()
def create_database_if_not_exists(self):
"""如果数据库不存在则创建"""
try:
# 连接但不指定数据库
temp_config = self.mysql_config.copy()
temp_config.pop('database', None)
connection = pymysql.connect(**temp_config)
with connection.cursor() as cursor:
cursor.execute(
f"CREATE DATABASE IF NOT EXISTS {self.mysql_config['database']} CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci")
logging.info(f"✓ 创建数据库: {self.mysql_config['database']}")
connection.commit()
connection.close()
# 重新连接指定数据库
self.connection = pymysql.connect(**self.mysql_config)
self.create_table()
except Exception as e:
logging.error(f"✗ 创建数据库失败: {e}")
def create_table(self):
"""创建股票数据表(使用英文表头)"""
create_table_sql = """
CREATE TABLE IF NOT EXISTS stock_data (
id INT AUTO_INCREMENT PRIMARY KEY,
stock_code VARCHAR(20) NOT NULL COMMENT '股票代码',
stock_name VARCHAR(100) NOT NULL COMMENT '股票名称',
latest_price DECIMAL(10,2) COMMENT '最新报价',
change_percent VARCHAR(20) COMMENT '涨跌幅',
change_amount DECIMAL(10,2) COMMENT '涨跌额',
volume VARCHAR(50) COMMENT '成交量',
amplitude VARCHAR(20) COMMENT '振幅',
high_price DECIMAL(10,2) COMMENT '最高价',
low_price DECIMAL(10,2) COMMENT '最低价',
open_price DECIMAL(10,2) COMMENT '今开价',
prev_close DECIMAL(10,2) COMMENT '昨收价',
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
UNIQUE KEY unique_stock (stock_code)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='股票数据表'
"""
try:
self.cursor.execute(create_table_sql)
self.connection.commit()
logging.info("✓ 股票数据表创建/验证成功")
except Exception as e:
logging.error(f"✗ 创建表失败: {e}")
def process_item(self, item, spider):
"""处理每个item并存入MySQL"""
try:
# 构建插入SQL(使用英文字段名)
sql = """
INSERT INTO stock_data (
stock_code, stock_name, latest_price, change_percent,
change_amount, volume, amplitude, high_price, low_price, open_price, prev_close
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
stock_name = VALUES(stock_name),
latest_price = VALUES(latest_price),
change_percent = VALUES(change_percent),
change_amount = VALUES(change_amount),
volume = VALUES(volume),
amplitude = VALUES(amplitude),
high_price = VALUES(high_price),
low_price = VALUES(low_price),
open_price = VALUES(open_price),
prev_close = VALUES(prev_close)
"""
# 准备数据
values = (
item.get('stock_code', ''),
item.get('stock_name', ''),
item.get('latest_price', 0),
item.get('change_percent', ''),
item.get('change_amount', 0),
item.get('volume', ''),
item.get('amplitude', ''),
item.get('high', 0),
item.get('low', 0),
item.get('open', 0),
item.get('prev_close', 0)
)
self.cursor.execute(sql, values)
self.connection.commit()
# 在控制台输出插入信息
logging.info(f"✓ 插入/更新股票数据: {item.get('stock_code', '')} - {item.get('stock_name', '')}")
except Exception as e:
logging.error(f"✗ 数据库操作失败: {e}")
try:
self.connection.rollback()
# 尝试重新连接
self.connection.ping(reconnect=True)
except:
self.open_spider(spider)
return item
def close_spider(self, spider):
"""爬虫关闭时关闭数据库连接并显示统计信息"""
if self.connection:
try:
# 显示数据统计
self.cursor.execute("SELECT COUNT(*) as total FROM stock_data")
result = self.cursor.fetchone()
logging.info(f"📊 数据库统计: 共存储 {result['total']} 条股票数据")
self.cursor.close()
self.connection.close()
logging.info("✓ 数据库连接已关闭")
except Exception as e:
logging.error(f"关闭数据库时出错: {e}")
class JsonPipeline:
"""JSON格式输出管道"""
def open_spider(self, spider):
self.file = open('stock_data.json', 'w', encoding='utf-8')
self.file.write('[\n')
self.first_item = True
logging.info("✓ JSON输出文件已创建")
def close_spider(self, spider):
self.file.write('\n]')
self.file.close()
logging.info("✓ JSON文件已保存")
def process_item(self, item, spider):
line = '' if self.first_item else ',\n'
self.first_item = False
json_line = json.dumps(dict(item), ensure_ascii=False, indent=2)
self.file.write(line + json_line)
return item
class CsvPipeline:
"""CSV格式输出管道"""
def open_spider(self, spider):
self.file = open('stock_data.csv', 'w', newline='', encoding='utf-8-sig')
self.writer = csv.writer(self.file)
# 写入中英文表头
self.writer.writerow([
'序号', '股票代码', '股票名称', '最新报价', '涨跌幅',
'涨跌额', '成交量', '振幅', '最高', '最低', '今开', '昨收'
])
self.writer.writerow([
'id', 'stock_code', 'stock_name', 'latest_price', 'change_percent',
'change_amount', 'volume', 'amplitude', 'high', 'low', 'open', 'prev_close'
])
logging.info("✓ CSV输出文件已创建")
def close_spider(self, spider):
self.file.close()
logging.info("✓ CSV文件已保存")
def process_item(self, item, spider):
self.writer.writerow([
'', # 序号由数据库自增
item.get('stock_code', ''),
item.get('stock_name', ''),
item.get('latest_price', ''),
item.get('change_percent', ''),
item.get('change_amount', ''),
item.get('volume', ''),
item.get('amplitude', ''),
item.get('high', ''),
item.get('low', ''),
item.get('open', ''),
item.get('prev_close', '')
])
return item
(c)编辑eastmoney_stock/items.py:
import scrapy
class StockItem(scrapy.Item):
# 定义数据字段
id = scrapy.Field() # 序号
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
latest_price = scrapy.Field() # 最新报价
change_percent = scrapy.Field() # 涨跌幅
change_amount = scrapy.Field() # 涨跌额
volume = scrapy.Field() # 成交量
amplitude = scrapy.Field() # 振幅
high = scrapy.Field() # 最高
low = scrapy.Field() # 最低
open = scrapy.Field() # 今开
prev_close = scrapy.Field() # 昨收
update_time = scrapy.Field() # 更新时间
(d)创建数据库查看脚本(check_mysql_data.py):
#!/usr/bin/env python3
"""
MySQL数据查看脚本
学号: 102302107
"""
import pymysql
import pandas as pd
def connect_mysql():
"""连接MySQL数据库"""
try:
connection = pymysql.connect(
host='localhost',
user='root',
password='744983',
database='stock_db',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
return connection
except Exception as e:
print(f"数据库连接失败: {e}")
return None
def show_table_structure(connection):
"""显示表结构"""
try:
with connection.cursor() as cursor:
cursor.execute("DESCRIBE stock_data")
result = cursor.fetchall()
print("=" * 80)
print("MySQL数据库表结构")
print("=" * 80)
print(f"{'字段名':<15} {'类型':<20} {'允许空':<8} {'键':<5} {'默认值':<10} {'备注'}")
print("-" * 80)
for row in result:
print(
f"{row['Field']:<15} {row['Type']:<20} {row['Null']:<8} {row['Key']:<5} {str(row['Default'] or ''):<10} {row.get('Comment', '')}")
except Exception as e:
print(f"查询表结构失败: {e}")
def show_stock_data(connection, limit=10):
"""显示股票数据"""
try:
with connection.cursor() as cursor:
cursor.execute(f"SELECT * FROM stock_data ORDER BY id DESC LIMIT {limit}")
result = cursor.fetchall()
print(f"\n{'=' * 80}")
print(f"最新 {limit} 条股票数据")
print(f"{'=' * 80}")
# 使用pandas美化输出
if result:
df = pd.DataFrame(result)
# 重命名列名为中文
df = df.rename(columns={
'id': '序号',
'stock_code': '股票代码',
'stock_name': '股票名称',
'latest_price': '最新报价',
'change_percent': '涨跌幅',
'change_amount': '涨跌额',
'volume': '成交量',
'amplitude': '振幅',
'high_price': '最高',
'low_price': '最低',
'open_price': '今开',
'prev_close': '昨收',
'update_time': '更新时间'
})
print(df.to_string(index=False))
else:
print("暂无数据")
# 显示统计信息
cursor.execute("SELECT COUNT(*) as total FROM stock_data")
count_result = cursor.fetchone()
print(f"\n📊 数据统计: 共 {count_result['total']} 条记录")
except Exception as e:
print(f"查询数据失败: {e}")
def main():
"""主函数"""
print("MySQL股票数据查看工具")
print("学号: 102302107")
print()
connection = connect_mysql()
if not connection:
return
try:
# 显示表结构
show_table_structure(connection)
# 显示数据
show_stock_data(connection, limit=15)
except Exception as e:
print(f"执行错误: {e}")
finally:
if connection:
connection.close()
if __name__ == "__main__":
main()
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
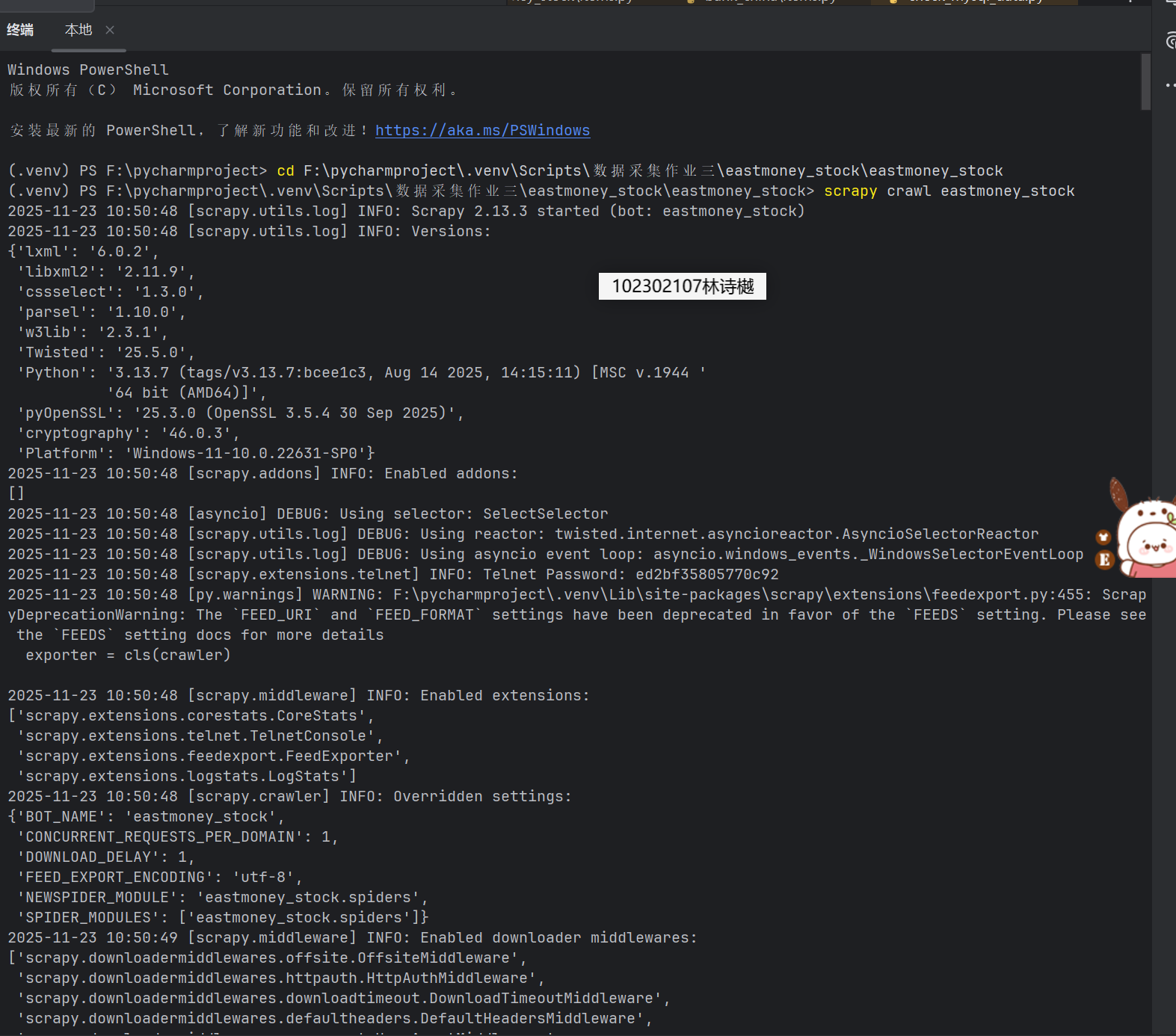
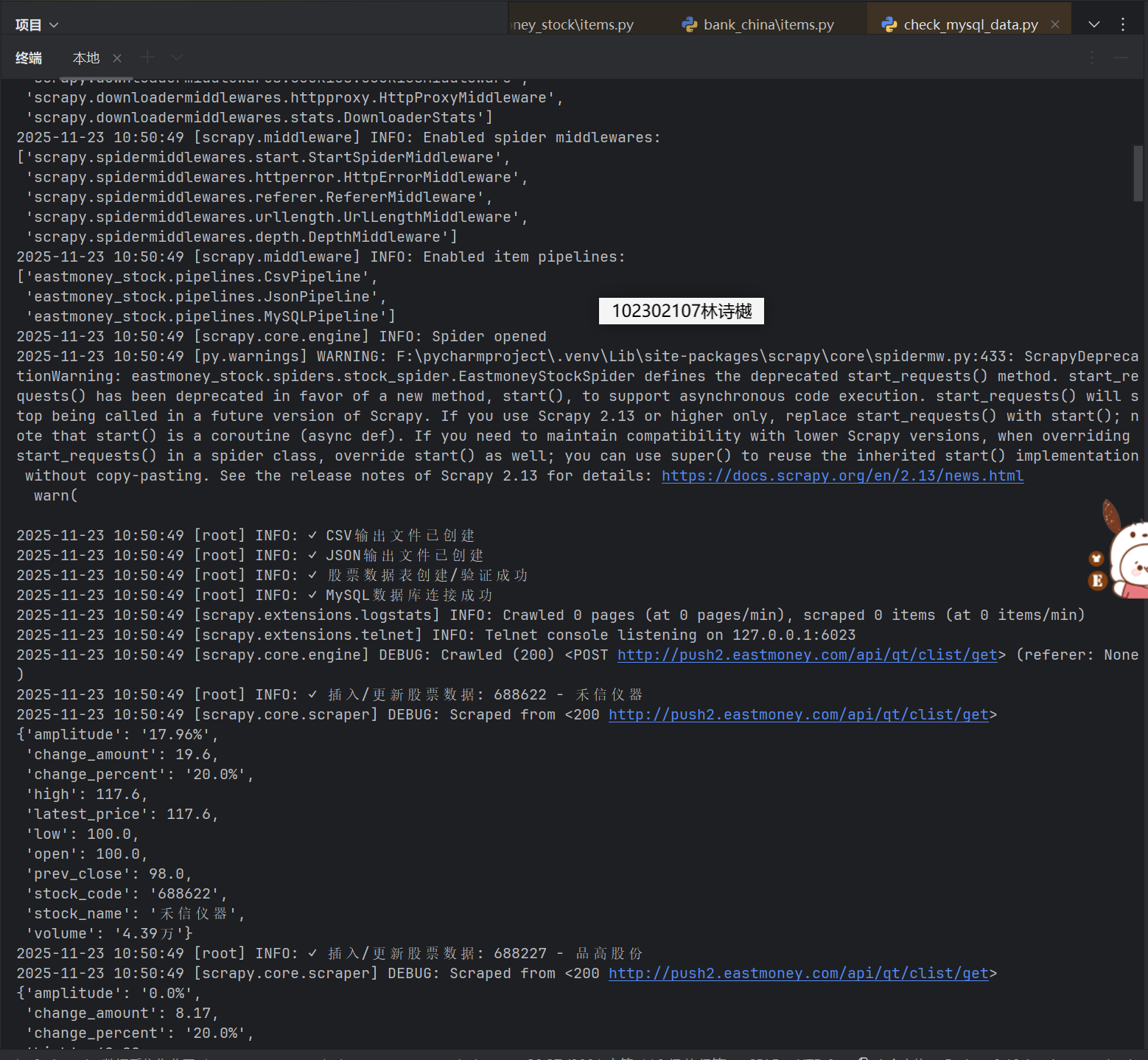
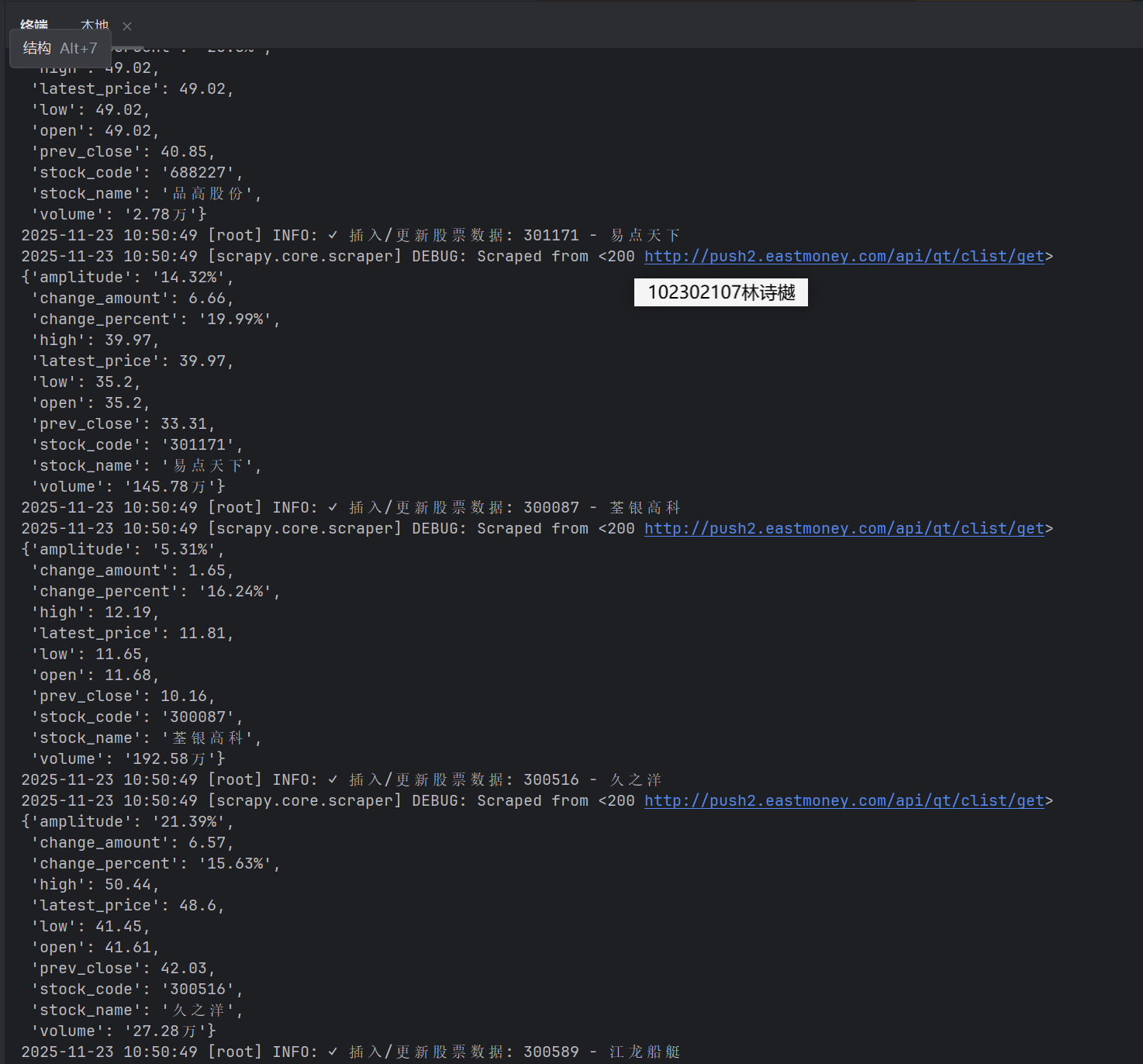
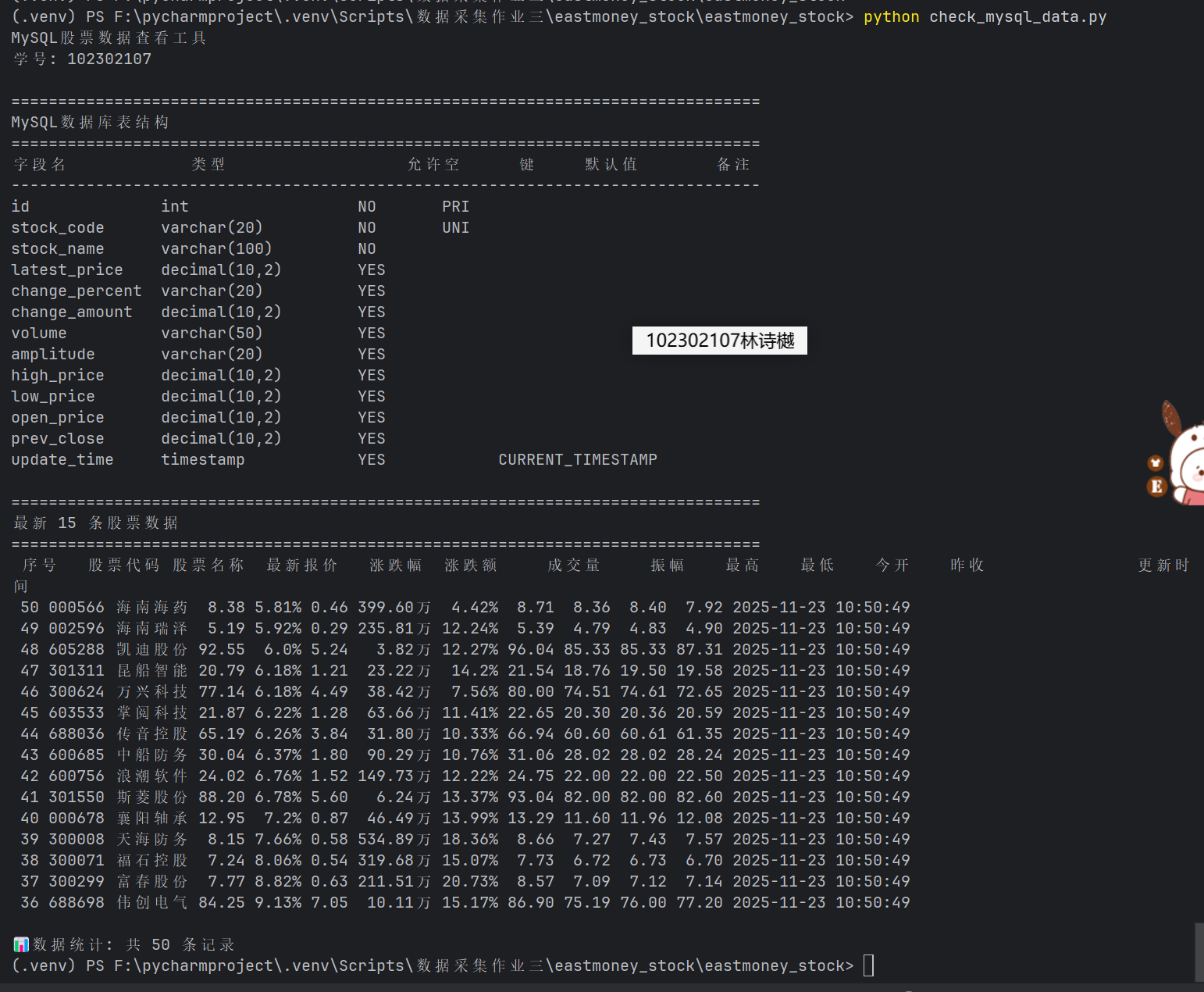
Gitee文件夹链接:https://gitee.com/ls-yue/2025_crawl_project/tree/master/作业3/eastmoney_stock
(2)心得体会:本次股票数据爬取让我全面掌握了Scrapy框架的应用。从Item定义、Spider编写到Pipeline设计,体验了完整的爬虫开发流程。通过XPath选择器精准提取股票信息,并实现MySQL数据持久化,加深了我对结构化数据处理的认知。特别是在处理动态加载内容时,学会了分析API接口而非盲目解析页面。管道机制的灵活运用让数据清洗和存储更加优雅,为后续复杂项目奠定了基础。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
(1)代码
(a)bank_china/items.py
import scrapy
class ForexItem(scrapy.Item):
# 定义外汇数据字段
currency = scrapy.Field() # 货币名称
tbp = scrapy.Field() # 现汇买入价
cbp = scrapy.Field() # 现钞买入价
tsp = scrapy.Field() # 现汇卖出价
csp = scrapy.Field() # 现钞卖出价
update_time = scrapy.Field() # 更新时间
(b)bank_china/pipelines.py
import pymysql
import logging
from itemadapter import ItemAdapter
import json
import csv
class MySQLPipeline:
def __init__(self, mysql_config):
self.mysql_config = mysql_config
self.connection = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_config={
'host': crawler.settings.get('MYSQL_HOST', 'localhost'),
'user': crawler.settings.get('MYSQL_USER', 'root'),
'password': crawler.settings.get('MYSQL_PASSWORD', '123456'),
'database': crawler.settings.get('MYSQL_DATABASE', 'forex_db'),
'port': crawler.settings.get('MYSQL_PORT', 3306),
'charset': crawler.settings.get('MYSQL_CHARSET', 'utf8mb4'),
'cursorclass': pymysql.cursors.DictCursor
}
)
def open_spider(self, spider):
"""爬虫启动时连接数据库"""
try:
self.connection = pymysql.connect(**self.mysql_config)
self.cursor = self.connection.cursor()
self.create_table()
logging.info("✓ 外汇MySQL数据库连接成功")
except Exception as e:
logging.error(f"✗ 数据库连接失败: {e}")
self.create_database_if_not_exists()
def create_database_if_not_exists(self):
"""如果数据库不存在则创建"""
try:
temp_config = self.mysql_config.copy()
temp_config.pop('database', None)
connection = pymysql.connect(**temp_config)
with connection.cursor() as cursor:
cursor.execute(
f"CREATE DATABASE IF NOT EXISTS {self.mysql_config['database']} CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci")
logging.info(f"✓ 创建数据库: {self.mysql_config['database']}")
connection.commit()
connection.close()
self.connection = pymysql.connect(**self.mysql_config)
self.create_table()
except Exception as e:
logging.error(f"✗ 创建数据库失败: {e}")
def create_table(self):
"""创建外汇数据表"""
create_table_sql = """
CREATE TABLE IF NOT EXISTS forex_rates (
id INT AUTO_INCREMENT PRIMARY KEY,
currency VARCHAR(50) NOT NULL COMMENT '货币名称',
tbp DECIMAL(10,4) COMMENT '现汇买入价',
cbp DECIMAL(10,4) COMMENT '现钞买入价',
tsp DECIMAL(10,4) COMMENT '现汇卖出价',
csp DECIMAL(10,4) COMMENT '现钞卖出价',
update_time VARCHAR(50) COMMENT '更新时间',
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '爬取时间',
UNIQUE KEY unique_currency (currency)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='外汇牌价表'
"""
try:
self.cursor.execute(create_table_sql)
self.connection.commit()
logging.info("✓ 外汇数据表创建/验证成功")
except Exception as e:
logging.error(f"✗ 创建外汇表失败: {e}")
def process_item(self, item, spider):
"""处理每个外汇item并存入MySQL"""
try:
sql = """
INSERT INTO forex_rates (currency, tbp, cbp, tsp, csp, update_time)
VALUES (%s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
tbp = VALUES(tbp),
cbp = VALUES(cbp),
tsp = VALUES(tsp),
csp = VALUES(csp),
update_time = VALUES(update_time)
"""
values = (
item.get('currency', ''),
item.get('tbp', 0),
item.get('cbp', 0),
item.get('tsp', 0),
item.get('csp', 0),
item.get('update_time', '')
)
self.cursor.execute(sql, values)
self.connection.commit()
logging.info(f"✓ 插入/更新外汇数据: {item.get('currency', '')}")
except Exception as e:
logging.error(f"✗ 外汇数据插入失败: {e}")
try:
self.connection.rollback()
self.connection.ping(reconnect=True)
except:
self.open_spider(spider)
return item
def close_spider(self, spider):
"""爬虫关闭时关闭数据库连接"""
if self.connection:
try:
self.cursor.execute("SELECT COUNT(*) as total FROM forex_rates")
result = self.cursor.fetchone()
logging.info(f"📊 外汇数据统计: 共存储 {result['total']} 条记录")
self.cursor.close()
self.connection.close()
logging.info("✓ 外汇数据库连接已关闭")
except Exception as e:
logging.error(f"关闭外汇数据库时出错: {e}")
class ForexJsonPipeline:
"""外汇JSON格式输出管道"""
def open_spider(self, spider):
self.file = open('forex_data.json', 'w', encoding='utf-8')
self.file.write('[\n')
self.first_item = True
logging.info("✓ 外汇JSON输出文件已创建")
def close_spider(self, spider):
self.file.write('\n]')
self.file.close()
logging.info("✓ 外汇JSON文件已保存")
def process_item(self, item, spider):
line = '' if self.first_item else ',\n'
self.first_item = False
json_line = json.dumps(dict(item), ensure_ascii=False, indent=2)
self.file.write(line + json_line)
return item
class ForexCsvPipeline:
"""外汇CSV格式输出管道"""
def open_spider(self, spider):
self.file = open('forex_data.csv', 'w', newline='', encoding='utf-8-sig')
self.writer = csv.writer(self.file)
# 写入中英文表头
self.writer.writerow(['货币', '现汇买入价', '现钞买入价', '现汇卖出价', '现钞卖出价', '更新时间'])
self.writer.writerow(['currency', 'tbp', 'cbp', 'tsp', 'csp', 'update_time'])
logging.info("✓ 外汇CSV输出文件已创建")
def close_spider(self, spider):
self.file.close()
logging.info("✓ 外汇CSV文件已保存")
def process_item(self, item, spider):
self.writer.writerow([
item.get('currency', ''),
item.get('tbp', ''),
item.get('cbp', ''),
item.get('tsp', ''),
item.get('csp', ''),
item.get('update_time', '')
])
return item
(c)bank_china/settings.py
# Scrapy settings for bank_china project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "bank_china"
SPIDER_MODULES = ["bank_china.spiders"]
NEWSPIDER_MODULE = "bank_china.spiders"
ADDONS = {}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "bank_china (+http://www.yourdomain.com)"
# Obey robots.txt rules
# 启用MySQL Pipeline
ITEM_PIPELINES = {
'bank_china.pipelines.MySQLPipeline': 300,
'bank_china.pipelines.ForexJsonPipeline': 200,
'bank_china.pipelines.ForexCsvPipeline': 100,
}
# MySQL数据库配置
MYSQL_HOST = 'localhost'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '744983'
MYSQL_DATABASE = 'forex_db'
MYSQL_PORT = 3306
MYSQL_CHARSET = 'utf8mb4'
# 爬虫配置
ROBOTSTXT_OBEY = False
# Concurrency and throttling settings
#CONCURRENT_REQUESTS = 16
CONCURRENT_REQUESTS_PER_DOMAIN = 1
DOWNLOAD_DELAY = 2
CONCURRENT_REQUESTS = 1
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "bank_china.middlewares.BankChinaSpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "bank_china.middlewares.BankChinaDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# "bank_china.pipelines.BankChinaPipeline": 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
FEED_EXPORT_ENCODING = "utf-8"
# 日志设置
LOG_LEVEL = 'INFO'
(d)bank_china/spiders/forex_spider.py
import scrapy
from bank_china.items import ForexItem
from bs4 import BeautifulSoup
import re
from datetime import datetime
class BankChinaForexSpiderOptimized(scrapy.Spider):
name = "bank_china_forex"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
"""解析外汇牌价页面"""
self.logger.info("开始解析中国银行外汇数据")
soup = BeautifulSoup(response.text, 'html.parser')
# 查找包含外汇数据的表格
table = soup.find('table', class_='BOC_main publish')
if not table:
self.logger.error("未找到外汇数据表格")
return
# 提取表头验证
headers = []
header_row = table.find('tr')
if header_row:
headers = [th.get_text().strip() for th in header_row.find_all('th')]
self.logger.info(f"表格列头: {headers}")
# 提取数据行
rows = table.find_all('tr')[1:] # 跳过表头
for row in rows:
cols = row.find_all('td')
if len(cols) >= 7: # 确保有足够的列
item = self.parse_row_data(cols)
if item:
yield item
def parse_row_data(self, cols):
"""解析单行数据"""
item = ForexItem()
try:
# 按照作业要求的格式解析
item['currency'] = self.clean_text(cols[0].get_text()) # 货币名称
item['tbp'] = self.parse_number(cols[1].get_text()) # 现汇买入价
item['cbp'] = self.parse_number(cols[2].get_text()) # 现钞买入价
item['tsp'] = self.parse_number(cols[3].get_text()) # 现汇卖出价
item['csp'] = self.parse_number(cols[4].get_text()) # 现钞卖出价
item['update_time'] = self.clean_text(cols[6].get_text()) # 发布时间
# 验证数据完整性
if not item['currency'] or item['tbp'] is None:
return None
self.logger.debug(f"解析成功: {item['currency']} - {item['tbp']}")
return item
except Exception as e:
self.logger.error(f"解析行数据失败: {e}")
return None
def clean_text(self, text):
"""清理文本"""
if text:
return re.sub(r'\s+', ' ', text).strip()
return ""
def parse_number(self, text):
"""解析数字"""
try:
cleaned = re.sub(r'[^\d.]', '', text)
if cleaned:
return float(cleaned)
except ValueError:
pass
return None
(e)创建外汇数据库查看脚本(forex_check_mysql.py)
#!/usr/bin/env python3
"""
增强版外汇数据查看脚本(解决编码问题)
学号: 102302107
"""
import pymysql
import pandas as pd
import sys
def safe_connect_mysql():
"""安全连接MySQL数据库(处理编码问题)"""
try:
connection = pymysql.connect(
host='localhost',
user='root',
password='744983',
database='forex_db',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
print("✓ MySQL数据库连接成功")
return connection
except Exception as e:
print(f"✗ 数据库连接失败: {e}")
return None
def show_enhanced_forex_data(connection, limit=20):
"""显示增强的外汇数据视图"""
try:
with connection.cursor() as cursor:
# 获取数据统计
cursor.execute("""
SELECT
COUNT(*) as total_count,
COUNT(DISTINCT currency) as unique_currencies,
MIN(crawl_time) as first_crawl,
MAX(crawl_time) as last_crawl
FROM forex_rates
""")
stats = cursor.fetchone()
print("=" * 100)
print("外汇数据统计概览")
print("=" * 100)
print(f"总记录数: {stats['total_count']}")
print(f"唯一货币数: {stats['unique_currencies']}")
print(f"首次爬取: {stats['first_crawl']}")
print(f"最后更新: {stats['last_crawl']}")
print()
# 获取最新数据
cursor.execute(f"""
SELECT
id as 序号,
currency as 货币名称,
ROUND(tbp, 4) as 现汇买入价,
ROUND(cbp, 4) as 现钞买入价,
ROUND(tsp, 4) as 现汇卖出价,
ROUND(csp, 4) as 现钞卖出价,
update_time as 更新时间,
crawl_time as 爬取时间
FROM forex_rates
ORDER BY crawl_time DESC, id DESC
LIMIT {limit}
""")
result = cursor.fetchall()
if result:
df = pd.DataFrame(result)
print(f"最新 {len(result)} 条外汇数据:")
print("-" * 120)
print(df.to_string(index=False, max_colwidth=15))
# 显示汇率统计
print("\n汇率统计:")
numeric_cols = ['现汇买入价', '现钞买入价', '现汇卖出价', '现钞卖出价']
stats_df = df[numeric_cols].describe()
print(stats_df.round(4))
else:
print("暂无外汇数据")
except Exception as e:
print(f"查询数据失败: {e}")
def check_table_structure(connection):
"""检查表结构"""
try:
with connection.cursor() as cursor:
cursor.execute("SHOW CREATE TABLE forex_rates")
result = cursor.fetchone()
print("\n表结构信息:")
print("-" * 50)
print(result['Create Table'])
except Exception as e:
print(f"获取表结构失败: {e}")
def main():
"""主函数"""
print("增强版外汇数据查看工具")
print("学号: 102302107")
print("=" * 60)
connection = safe_connect_mysql()
if not connection:
print("请确保:")
print("1. MySQL服务正在运行")
print("2. 数据库 'forex_db' 已创建")
print("3. 用户名和密码正确")
return
try:
show_enhanced_forex_data(connection, limit=15)
check_table_structure(connection)
except Exception as e:
print(f"执行错误: {e}")
finally:
if connection:
connection.close()
print("\n✓ 数据库连接已关闭")
if __name__ == "__main__":
main()
(f)创建独立运行脚本(run_forex_spider.py)
#!/usr/bin/env python3
"""
作业③:外汇数据爬虫独立运行脚本(修复编码版本)
学号: 102302107
"""
import os
import sys
import subprocess
import logging
# 设置全局UTF-8编码环境
os.environ['PYTHONIOENCODING'] = 'utf-8'
os.environ['PYTHONUTF8'] = '1'
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def setup_directories():
"""创建必要的目录"""
if not os.path.exists('forex_data'):
os.makedirs('forex_data')
print("创建目录: forex_data")
def run_forex_spider():
"""运行外汇爬虫(修复编码问题)"""
print("=" * 60)
print("作业③:外汇数据爬虫")
print("学号: 102302107")
print("=" * 60)
setup_directories()
if not os.path.exists("bank_china"):
print("错误: bank_china 项目目录不存在")
return False
original_dir = os.getcwd()
os.chdir("bank_china")
try:
# 设置完整的环境变量确保UTF-8编码
env = os.environ.copy()
env['PYTHONIOENCODING'] = 'utf-8'
env['PYTHONUTF8'] = '1'
env['LANG'] = 'en_US.UTF-8'
env['LC_ALL'] = 'en_US.UTF-8'
# 使用二进制模式捕获输出,避免编码问题
result = subprocess.run([
sys.executable, "-c",
"""
import sys
import os
# 强制设置标准输出编码
sys.stdout.reconfigure(encoding='utf-8')
sys.stderr.reconfigure(encoding='utf-8')
# 运行Scrapy爬虫
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'bank_china_forex', '-o', '../forex_data/forex_data.json'])
"""
], capture_output=True, timeout=120, env=env)
print("外汇爬虫执行完成")
# 处理输出 - 使用错误忽略策略
if result.stdout:
try:
output = result.stdout.decode('utf-8', errors='ignore')
if output.strip():
print("输出信息:")
# 只显示关键信息,避免过多输出
lines = output.split('\n')
for line in lines:
if any(keyword in line for keyword in ['DEBUG', 'INFO', 'WARNING', 'ERROR', 'Scraped']):
print(line[-200:]) # 限制行长度
except UnicodeDecodeError:
# 如果UTF-8解码失败,尝试其他编码
try:
output = result.stdout.decode('gbk', errors='ignore')
if output.strip():
print("输出信息(GBK):")
print(output[-500:])
except:
print("无法解码输出信息")
# 处理错误输出
if result.stderr:
try:
error_output = result.stderr.decode('utf-8', errors='ignore')
if error_output.strip():
# 过滤掉编码警告,只显示真正的错误
error_lines = [line for line in error_output.split('\n')
if 'codec' not in line and 'decode' not in line and line.strip()]
if error_lines:
print("错误信息:")
for line in error_lines[-5:]: # 只显示最后5行错误
print(line)
except:
pass
# 检查生成的文件
json_file = "../forex_data/forex_data.json"
if os.path.exists(json_file):
size = os.path.getsize(json_file)
print(f"✓ 成功生成数据文件: {json_file} ({size} 字节)")
# 验证JSON文件格式
try:
import json
with open(json_file, 'r', encoding='utf-8') as f:
data = json.load(f)
print(f"✓ JSON文件验证通过,包含 {len(data)} 条记录")
return True
except Exception as e:
print(f"⚠ JSON文件格式警告: {e}")
return True # 文件存在即算成功
else:
print("✗ 未生成数据文件")
return False
except subprocess.TimeoutExpired:
print("外汇爬虫超时")
return False
except Exception as e:
print(f"运行外汇爬虫时出错: {e}")
return False
finally:
os.chdir(original_dir)
def check_mysql_data():
"""检查MySQL中的数据"""
print("\n" + "=" * 60)
print("检查MySQL数据库中的外汇数据")
print("=" * 60)
try:
# 尝试导入检查脚本
sys.path.append('.')
from forex_check_mysql import main as check_main
check_main()
return True
except ImportError:
print("⚠ 数据查看脚本不存在,跳过数据库检查")
return True
except Exception as e:
print(f"数据库检查失败: {e}")
return False
def main():
"""主函数"""
print("开始运行外汇数据爬虫...")
success = run_forex_spider()
if success:
print("✓ 外汇数据爬取完成")
# 尝试检查数据库
check_mysql_data()
print("\n下一步操作:")
print("1. 查看生成的数据文件: forex_data/forex_data.json")
print("2. 运行 python forex_check_mysql.py 查看数据库数据")
print("3. 检查MySQL中的forex_rates表")
else:
print("✗ 外汇数据爬取失败")
return 0 if success else 1
if __name__ == "__main__":
sys.exit(main())
(g)创建数据导出脚本(生成要求的表格格式)(export_forex_table.py)
#!/usr/bin/env python3
"""
修复版外汇数据表格导出脚本
学号: 102302107
"""
import json
import csv
import pymysql
from prettytable import PrettyTable
from datetime import datetime
import os
class ForexDataExporter:
def __init__(self):
self.data = []
def load_from_json(self, filename='forex_data.json'):
"""从JSON文件加载数据"""
try:
with open(filename, 'r', encoding='utf-8') as f:
self.data = json.load(f)
print(f"✓ 从JSON文件加载 {len(self.data)} 条记录")
return True
except Exception as e:
print(f"✗ 加载JSON文件失败: {e}")
return False
def load_from_mysql(self):
"""从MySQL数据库加载数据"""
try:
connection = pymysql.connect(
host='localhost',
user='root',
password='744983',
database='forex_db',
charset='utf8mb4'
)
with connection.cursor() as cursor:
cursor.execute("""
SELECT currency, tbp, cbp, tsp, csp, update_time
FROM forex_rates
ORDER BY currency
""")
results = cursor.fetchall()
for row in results:
self.data.append({
'currency': row[0],
'tbp': float(row[1]) if row[1] is not None else None,
'cbp': float(row[2]) if row[2] is not None else None,
'tsp': float(row[3]) if row[3] is not None else None,
'csp': float(row[4]) if row[4] is not None else None,
'update_time': row[5]
})
connection.close()
print(f"✓ 从MySQL加载 {len(self.data)} 条记录")
return True
except Exception as e:
print(f"✗ 数据库连接失败: {e}")
return False
def format_number(self, value):
"""格式化数字,处理None值"""
if value is None:
return 'N/A'
return f"{value:.2f}"
def display_console_table(self, limit=20):
"""在控制台显示表格"""
if not self.data:
print("暂无数据")
return
table = PrettyTable()
table.field_names = ["Currency", "TBP", "CBP", "TSP", "CSP", "Time"]
table.align = "r"
table.align["Currency"] = "l"
for i, item in enumerate(self.data[:limit]):
table.add_row([
item['currency'],
self.format_number(item['tbp']),
self.format_number(item['cbp']),
self.format_number(item['tsp']),
self.format_number(item['csp']),
item['update_time'] or 'N/A'
])
print("\n" + "=" * 80)
print("中国银行外汇牌价表")
print("=" * 80)
print(table)
print(f"显示 {min(limit, len(self.data))} 条记录,共 {len(self.data)} 条")
def export_to_html(self, filename='forex_table.html'):
"""导出为HTML表格文件(修复版)"""
html_content = """
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>中国银行外汇牌价</title>
<style>
table { border-collapse: collapse; width: 100%; margin: 20px 0; font-family: Arial, sans-serif; }
caption { font-size: 1.5em; font-weight: bold; margin: 10px 0; }
th, td { border: 1px solid #ddd; padding: 12px; text-align: right; }
th { background-color: #4CAF50; color: white; text-align: center; }
th:first-child, td:first-child { text-align: left; }
tr:nth-child(even) { background-color: #f2f2f2; }
tr:hover { background-color: #ddd; }
.footer { margin-top: 20px; font-style: italic; color: #666; }
</style>
</head>
<body>
<table>
<caption>中国银行外汇牌价表</caption>
<tr>
<th>Currency</th>
<th>TBP</th>
<th>CBP</th>
<th>TSP</th>
<th>CSP</th>
<th>Time</th>
</tr>
"""
for item in self.data:
# 修复:正确的格式化方法
tbp = self.format_number(item['tbp'])
cbp = self.format_number(item['cbp'])
tsp = self.format_number(item['tsp'])
csp = self.format_number(item['csp'])
time_val = item['update_time'] or 'N/A'
html_content += f"""
<tr>
<td>{item['currency']}</td>
<td>{tbp}</td>
<td>{cbp}</td>
<td>{tsp}</td>
<td>{csp}</td>
<td>{time_val}</td>
</tr>
"""
html_content += f"""
</table>
<div class="footer">总计: {len(self.data)} 种货币 | 生成时间: {datetime.now().strftime("%Y-%m-%d %H:%M:%S")} | 学号: 102302107</div>
</body>
</html>
"""
with open(filename, 'w', encoding='utf-8') as f:
f.write(html_content)
print(f"✓ HTML表格已导出到: {filename}")
def export_to_csv(self, filename='forex_table.csv'):
"""导出为CSV文件"""
with open(filename, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['Currency', 'TBP', 'CBP', 'TSP', 'CSP', 'Time'])
for item in self.data:
writer.writerow([
item['currency'],
self.format_number(item['tbp']),
self.format_number(item['cbp']),
self.format_number(item['tsp']),
self.format_number(item['csp']),
item['update_time'] or ''
])
print(f"✓ CSV表格已导出到: {filename}")
def export_simple_html(self, filename='simple_forex_table.html'):
"""导出简化版HTML(类似图片中的格式)"""
html_simple = """
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>中国银行外汇牌价表</title>
<style>
table {{ border-collapse: collapse; width: 80%; margin: 20px auto; }}
caption {{ font-size: 1.2em; font-weight: bold; margin: 10px; }}
td, th {{ border: 1px solid #000; padding: 8px; text-align: center; }}
th {{ background-color: #f0f0f0; }}
</style>
</head>
<body>
<table>
<caption>中国银行外汇牌价表</caption>
<tr>
<td>Currency</td>
<td>TBP</td>
<td>CBP</td>
<td>TSP</td>
<td>CSP</td>
<td>Time</td>
</tr>
"""
for item in self.data:
tbp = self.format_number(item['tbp'])
cbp = self.format_number(item['cbp'])
tsp = self.format_number(item['tsp'])
csp = self.format_number(item['csp'])
time_val = item['update_time'] or 'N/A'
html_simple += f"""
<tr>
<td>{item['currency']}</td>
<td>{tbp}</td>
<td>{cbp}</td>
<td>{tsp}</td>
<td>{csp}</td>
<td>{time_val}</td>
</tr>
"""
html_simple += """
</table>
</body>
</html>
"""
with open(filename, 'w', encoding='utf-8') as f:
f.write(html_simple)
print(f"✓ 简化版HTML表格已导出到: {filename}")
def main():
"""主函数"""
exporter = ForexDataExporter()
print("外汇数据表格导出工具(修复版)")
print("学号: 102302107")
print("=" * 50)
# 尝试从不同来源加载数据
if not exporter.load_from_mysql():
print("尝试从JSON文件加载...")
if not exporter.load_from_json():
print("没有找到数据,请先运行外汇爬虫")
return
if not exporter.data:
print("没有找到数据")
return
# 显示控制台表格
exporter.display_console_table(limit=25)
# 导出文件
exporter.export_to_html()
exporter.export_simple_html() # 新增:导出简化版
exporter.export_to_csv()
print("\n导出完成!")
print("生成的文件:")
print("- forex_table.html (美化版HTML表格)")
print("- simple_forex_table.html (简化版HTML表格)")
print("- forex_table.csv (CSV格式表格)")
if __name__ == "__main__":
main()
输出信息:
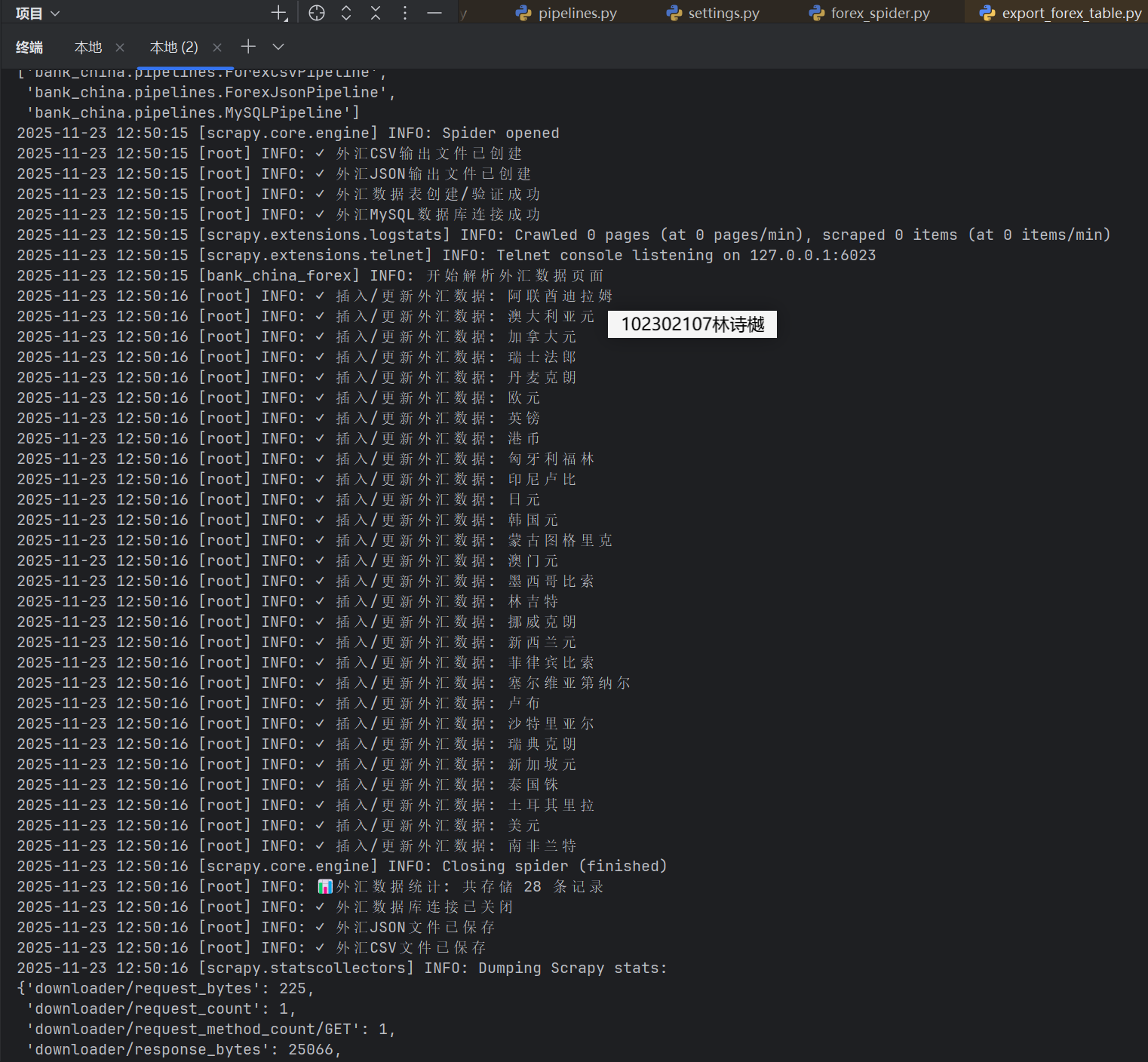
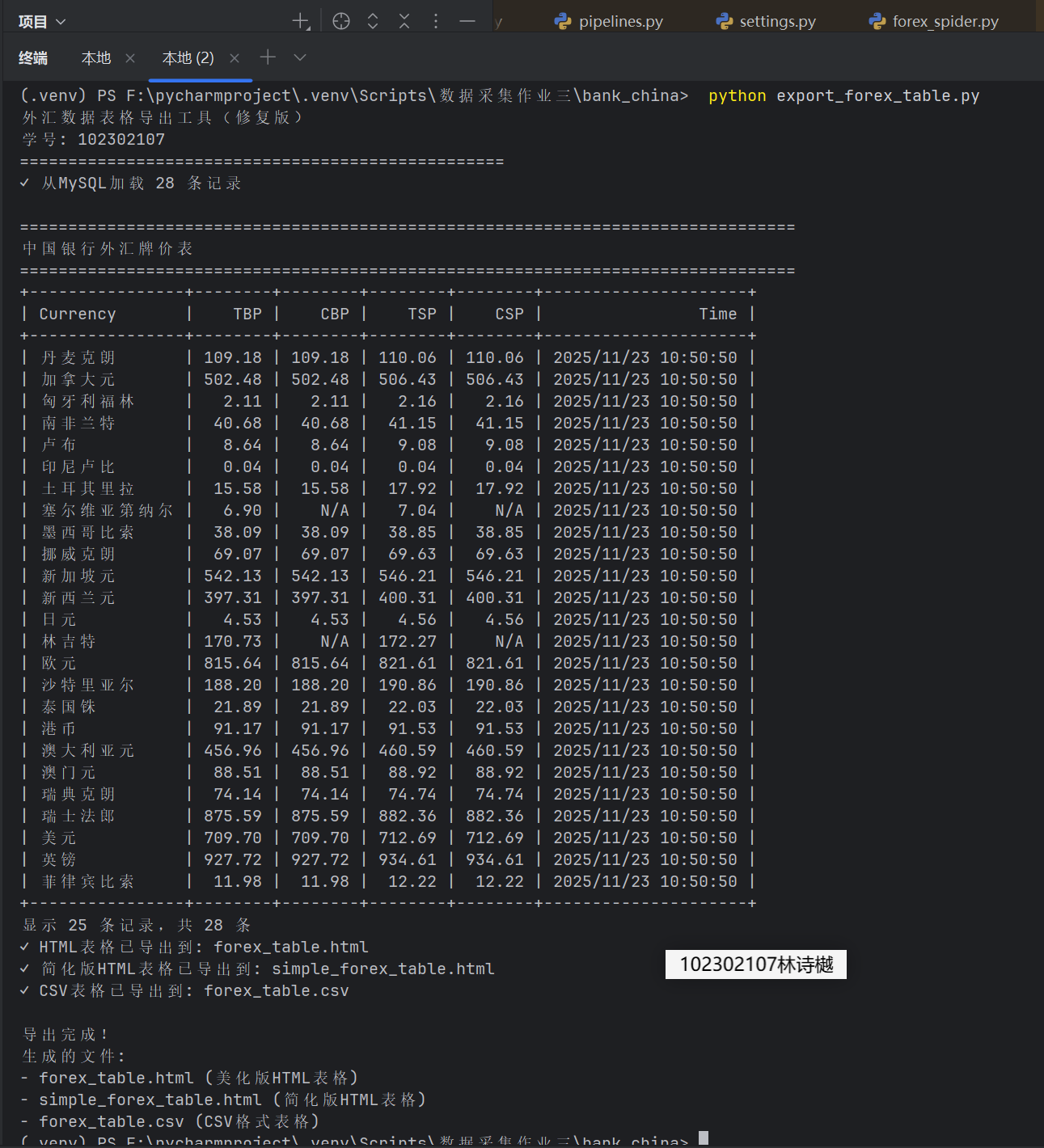
(2)心得体会:外汇爬虫项目让我认识到金融数据采集的特殊性。精确的数据解析和稳定的存储方案至关重要。通过构建完整的数据管道,实现了从网页抓取到多格式输出的全流程。在处理汇率数据时,特别注重了数值精度和单位统一。MySQL与JSON/CSV的多后端存储设计,展现了数据导出灵活性。该项目不仅提升了我的爬虫技能,更培养了金融数据处理的项目思维。
Gitee文件夹链接:https://gitee.com/ls-yue/2025_crawl_project/tree/master/作业3/bank_china

 浙公网安备 33010602011771号
浙公网安备 33010602011771号