内存吞金兽(Elasticsearch)的那些事儿 -- 数据结构及巧妙算法
系列目录
内存吞金兽(Elasticsearch)的那些事儿 -- 认识一下
内存吞金兽(Elasticsearch)的那些事儿 -- 数据结构及巧妙算法
内存吞金兽(Elasticsearch)的那些事儿 -- 架构&三高保证
内存吞金兽(Elasticsearch)的那些事儿 -- 写入&检索原理
内存吞金兽(Elasticsearch)的那些事儿 -- 常见问题痛点及解决方案
ES 本质上是一个支持全文搜索的分布式内存数据库,特别适合用于构建搜索系统。ES 之所以能有非常好的全文搜索性能,最重要的原因就是采用了倒排索引。倒排索引是一种特别为搜索而设计的索引结构,倒排索引先对需要索引的字段进行分词,然后以分词为索引组成一个查找树,这样就把一个全文匹配的查找转换成了对树的查找,这是倒排索引能够快速进行搜索的根本原因。
倒排索引
一图胜千言

再举个例子
假设我们有这样两个商品,一个是烟台红富士苹果,一个是苹果手机 iPhone XS Max。
|
DOCID
|
SKUID
|
标题
|
|---|---|---|
| 666 | 1234 | 烟台红富士苹果 |
| 888 | 1235 | 苹果手机 iPhone XS Max |
这个表里面的 DOCID 就是唯一标识一条记录的 ID,和数据库里面的主键是类似的。
倒排索引的存储
|
TERM
|
DOCID
|
|---|---|
| 烟台 | 666 |
| 红富士 | 666 |
| 苹果 | 666,888 |
| 手机 | 888 |
| iPhone | 888 |
| XS | 888 |
| Max | 888 |
可以看到,这个倒排索引的表,它是以单词作为索引的 Key,然后每个单词的倒排索引的值是一个列表,这个列表的元素就是含有这个单词的商品记录的 DOCID。
当我们往 ES 写入商品记录的时候,ES 会先对需要搜索的字段,也就是商品标题进行分词。分词就是把一段连续的文本按照语义拆分成多个单词。然后 ES 按照单词来给商品记录做索引,就形成了上面那个表一样的倒排索引。当我们搜索关键字“苹果手机”的时候,ES 会对关键字也进行分词,比如说,“苹果手机”被分为“苹果”和“手机”。然后,ES 会在倒排索引中去搜索我们输入的每个关键字分词,搜索结果应该是:
|
TERM
|
DOCID
|
|---|---|
| 苹果 | 666,888 |
| 手机 | 888 |
666 和 888 这两条记录都能匹配上搜索的关键词,但是 888 这个商品比 666 这个商品匹配度更高,因为它两个单词都能匹配上,所以按照匹配度把结果做一个排序,最终返回的搜索结果就是:
苹果Apple iPhone XS Max
烟台红富士苹果
这个搜索过程,其实就是对上面的倒排索引做了二次查找,一次找“苹果”,一次找“手机”。注意,整个搜索过程中,我们没有做过任何文本的模糊匹配。ES 的存储引擎存储倒排索引时,肯定不是像我们上面表格中展示那样存成一个二维表,实际上它的物理存储结构和 MySQL 的 InnoDB 的索引是差不多的,都是一颗查找树。
elasticsearch中的数据结构
(当然也是lucene的数据结构
升级版倒排索引
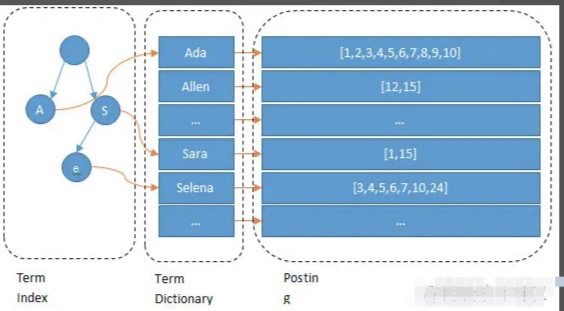
组成三部分
term dictionary
会根据分词器对文字进行分词(也就是图上所看到的Ada/Allen/Sara..),这些分词汇总起来叫做Term Dictionary
优化手段
该部分的词会非常非常多,所以es内部对其进行了排序,使用二分查找法来查,故而就不需要遍历整个词集
posting list
通过分词找到对应的记录,这些文档ID保存在PostingList
优化手段
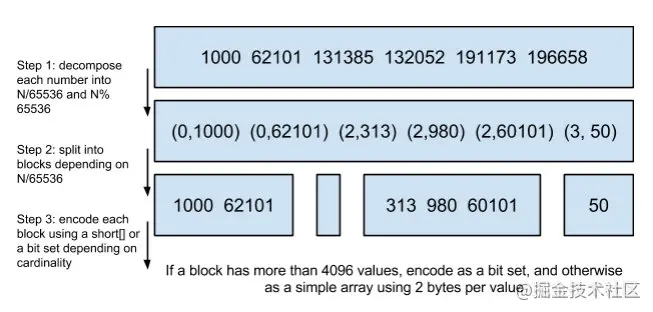
为节约磁盘空间和快速得出交并集结果 。使用FOR以及RBM编码技术对内容压缩
FOR原理

RBM原理
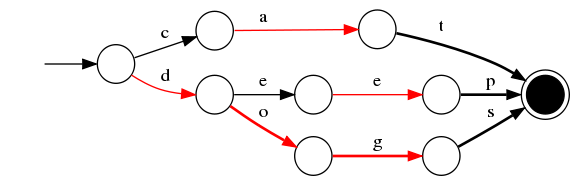
term index
由于Term Dictionary的词实在太多了,不可能把Term Dictionary所有的词都放在内存中,于是elastic还抽了一层叫做Term Index,这层只存储 部分 词的前缀,Term Index会存在内存中(检索会特别快)
这里遗留一个问题,如果Term Index树还是很大怎么办?
找的时候咋找
字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。大大减少了磁盘随机读的次数
优化手段
为节省内存 ,该部分在内存中是以FST(https://cs.nyu.edu/~mohri/pub/fla.pdf)的形式保存的
- 1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
- 2)查询速度快。O(len(str))的查询时间复杂度。
更多优化
当对多个字段进行检索时,利用了bitmap按位与进行归并优化(本身也是用bitmap的方式进行了存储
# 假设条件为name=fsdm and age=18取出来的数据如下 [1, 3, 5] -> 10101 [1, 2, 4, 5] -> 11011 # 这样两个二进制数组求与便可得出结果: 10001 -> [1, 5] |
注:在特定场景非bitmap存储时,使用跳表来进行联合查询
为啥快
- 磁盘东西尽量搬内存
- 各种奇技淫巧算法
- 苛刻态度使用内存
本文来自博客园,作者:房上的猫,转载请注明原文链接:https://www.cnblogs.com/lsy131479/p/15184315.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号