

实验五
1
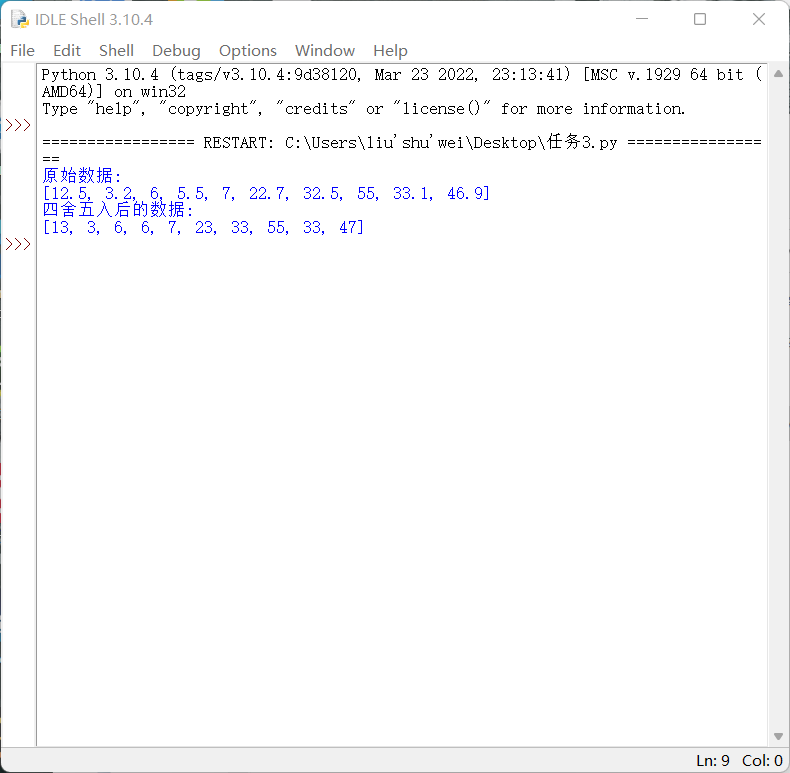
1 with open('data3.txt','r',encoding='utf-8') as f : 2 with open('data3_processed.txt', 'w', encoding='utf-8') as f1: 3 data=f.read().strip().split('\n') 4 data.pop(0) 5 data1=[eval(i) for i in data] 6 data2=[] 7 for i in data1: 8 if i - int(i) >= 0.5: 9 data2.append(int(i) + 1) 10 else: 11 data2.append(int(i)) 12 data3=[int(i)for i in data2] 13 f1.write(f'原始数据\t四舍五入后的数据\n') 14 for j in range(len(data)): 15 f1.write(f'{data1[j]}\t\t{data2[j]}\n') 16 print(f'原始数据:\n{data1}\n四舍五入后的数据:\n{data2}')

4
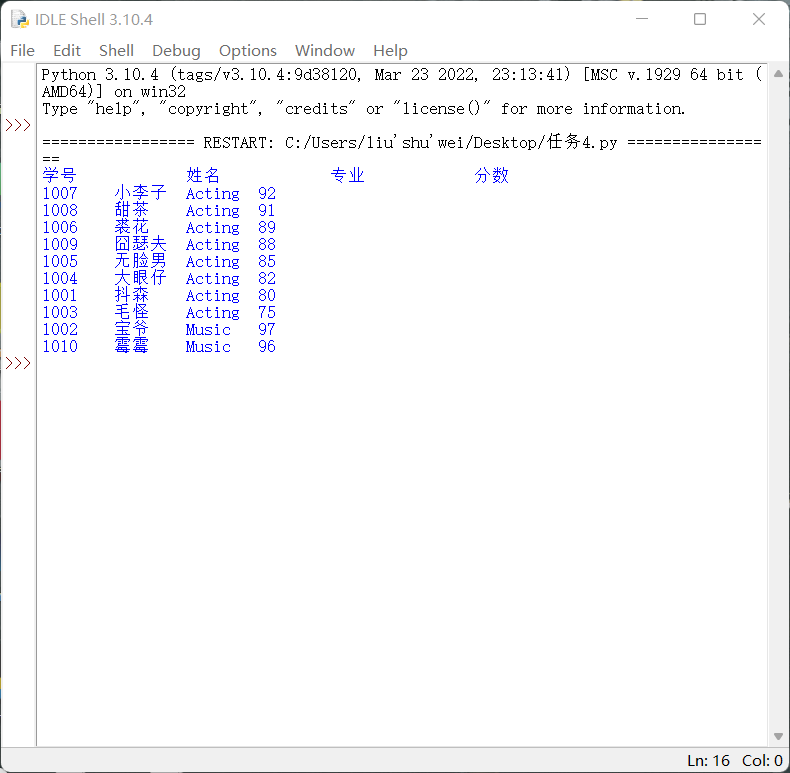
1 with open('data4.txt','r',encoding='utf-8')as f: 2 with open('data4_processed.txt','w',encoding='utf-8')as f1: 3 data=f.readlines() 4 data1=[i.strip('\n').split('\t') for i in data] 5 x=data1.pop(0) 6 data2=[sorted(data1,key=lambda x: (x[2], -int(x[3])))] 7 print('\t\t'.join(x)) 8 f1.write('\t\t'.join(x)+'\n') 9 for i in data2: 10 for j in i: 11 print('\t'.join(j)) 12 f1.write('\t'.join(j)+'\n')

5
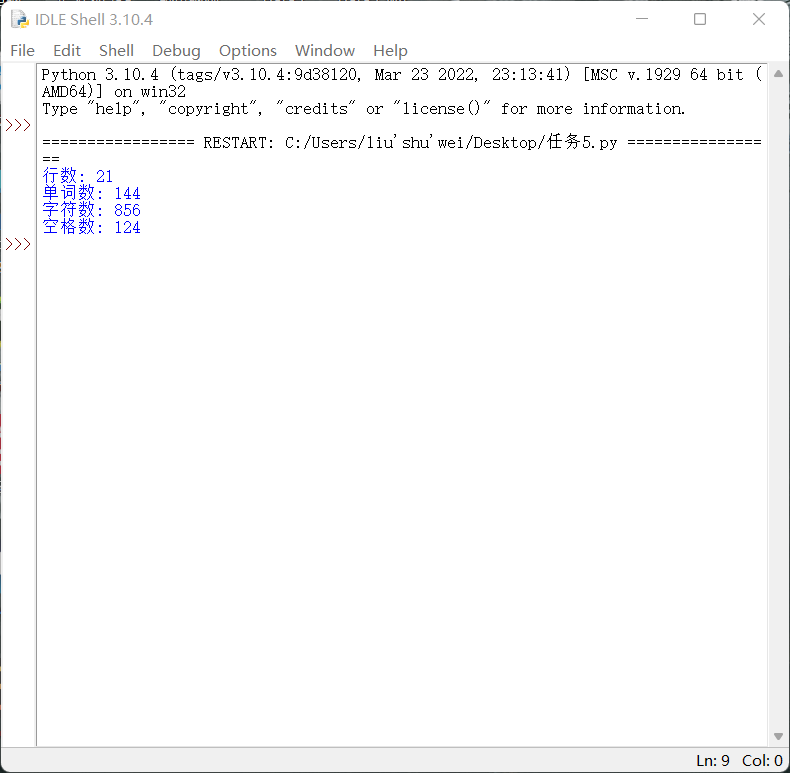
1 with open('data5.txt','r',encoding='utf-8')as f: 2 with open('data5_with_line.txt', 'w', encoding='utf-8') as f1: 3 a=f.read().strip('\n') 4 b = len(a.splitlines()) 5 print('行数:', b) 6 e = len(a.split()) 7 print('单词数:', e) 8 c = 0 9 for c, number in enumerate(a): 10 c += 1 11 print('字符数:', c)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号