
python 爬取顶会论文信息
import requests
from bs4 import BeautifulSoup
import pymysql
#保存单个界面数据
def getInfo(url):
# url='https://openaccess.thecvf.com/WACV2021'
header={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Mobile Safari/537.36'
}
html=requests.get(url=url,headers=header).text
soup=BeautifulSoup(html,'lxml')
dl=soup.find('dl')
print(dl.find('dt'))
info=dl.find_all(class_='bibref pre-white-space')
for i in info:
print('----------------------------------------------------------------------------------------------------------')
print(i.text)
# info0=i.find(class_='bibref pre-white-space').get_text()
# print(info0)
#处理数据
info1=i.text.strip('@InProceedings{,}')
info2=info1.replace('=','')
info2=info2.replace("'","''")
info2=info2.replace('{','')
info2=info2.replace('}',',')
info2=info2.replace('author',',')
info2=info2.replace('title','')
info2=info2.replace('book','')
info2=info2.replace('month','')
info2=info2.replace('year','')
info2=info2.replace('pages','')
info2=info2.replace('\n','')
info2=info2.replace(' ','')
info2=",,"+info2+","
print(info2)
info3=info2.split(',,')
print(info3)
#保存数据
list=[]
for i in info3:
list.append(i.strip(' '))
print(i.strip(' '))
print(str(list[1]))
#链接数据库
conn=pymysql.connect(host='ip',port=3306,user='用户名',password='密码',database='表明')
cursor=conn.cursor()
sql_select="select * from paper where title='"+str(list[3])+"'"
if(cursor.execute(sql_select)!=1):
sql="insert into paper(author,title,booktitle,month,year,pages) values('"+str(list[2])+"','"+str(list[3])+"','"+str(list[4])+"','"+str(list[5])+"','"+str(list[6])+"','"+str(list[7])+"')"
a=cursor.execute(sql)
re=cursor.fetchall()
print(re)
conn.commit()
cursor.close()
conn.close()
url='https://openaccess.thecvf.com/menu'
headers={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Mobile Safari/537.36'
}
html=requests.get(url=url,headers=headers).text
print(html)
soup=BeautifulSoup(html,'lxml')
dds=soup.find_all('dd')
for dd in dds:
for d in dd.find_all('a'):
url_MainConference=url.strip('menu')+str(d['href']).strip('/')
print(url_MainConference.strip('.py'))
getInfo(url_MainConference.strip('.py '))
先描述一下getInfo(url)的功能:获得特定url中每篇顶会论文的标题、作者、期刊、日期和页数,并将这些数据存储到数据库。
首先通过request.get()获得html,然后通过BeautifulSoup解析html
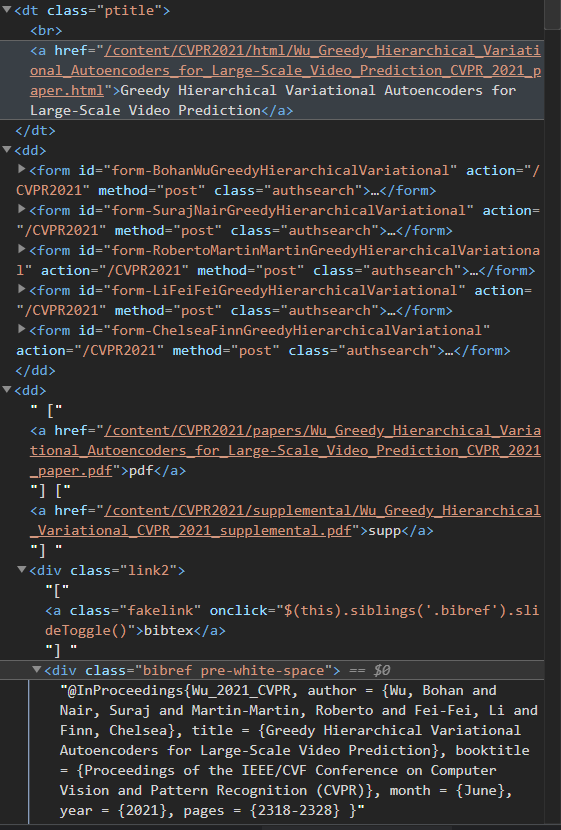
通过页面发现所需的内容在class为bibref pre-white-space的div,通过find_all(class_='bibref pre-white-space') 找到class为bibref pre-white-space的所有标签及其下的内容,通过get_text()获得字符内容,最后通过replace和strip对获得的字符进行处理,然后存入数据库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号