TCP系列45—拥塞控制—8、SACK关闭的拥塞撤销与虚假快速重传
一、概述
这篇文章介绍一下TCP从Recovery状态恢复到Open状态的时候cwnd的更新。我们在tcp重传部分的文章中曾经介绍过虚假重传的概念,Linux在探测到虚假重传的时候就会执行拥塞撤销操作。所谓的拥塞撤销是指撤销虚假的快速重传或者RTO超时重传对拥塞窗口的影响。有多种方法可能会触发拥塞撤销如前面介绍的DSACK和FRTO以及后面要介绍的Eifel算法以及本文介绍的SACK关闭场景下的拥塞撤销,本文先介绍一种SACK关闭场景下的拥塞撤销。首先在介绍几个新的linux状态变量
undo_marker:这个是拥塞撤销标记,进入Recovery状态的时候进行标记,设置为SND.UNA,拥塞撤销后设置为0取消标记,以防止多次进行拥塞撤销。
retrans_stamp:第一次重传的时间戳,快速恢复的时候可以用来标记是否可以进行拥塞撤销,若值为0则可以进行拥塞撤销。Open状态下每次收到ack都会将这个变量置为0。
prior_ssthresh:从名字就可以看到prior_ssthresh这个状态变量用来保存ssthresh的先前值,当探测到虚假重传的时候,就可以用prior_ssthresh来更新ssthresh从而达到拥塞撤销的效果。prior_ssthresh的值一般在进入Recovery状态或者Loss状态时候更新,更新的时候如果当前TCP拥塞状态处于CWR或者Recovery状态那么设置prior_ssthresh=ssthresh,否则prior_ssthresh=max(ssthresh,3/4*cwnd)
当Recovery状态下的TCP收到ack number大于等于high_seq的ACK报文的时候
如果retrans_stamp标记可以进行拥塞撤销或者Eifel探测算法探测到虚假重传,并且undo_marker标记有效,则尝试执行拥塞撤销,更新cwnd=max(cwnd,2*ssthresh),ssthresh=max(ssthresh,prior_ssthresh),并取消undo_marker的标记,即设置undo_marker=0,防止后续重复进行拥塞撤销,并继续执行下面的第2步。本篇文章只介绍retrans_stamp触发的拥塞撤销,Eifel探测后面进行介绍。
如果收到的Ack=high_seq,而且当前SACK处于关闭状态,更新cwnd=min(cwnd,in_flight+dupthresh)。同时判断当前是否有未被ack number确认的重传,如果没有则设置retrans_stamp=0,表示可以进行拥塞撤销。不在执行下面的第2步状态切换,TCP继续停留在Recovery状态以避免false fast retransmits。但是不会在进行上一篇文章中描述的Recovery状态的cwnd的更新过程,也不会再去尝试快速重传过程。
那么更新TCP进入Open状态,并更新cwnd=ssthresh
其中第二点中false fast retransmits是指,如果SACK关闭,在Ack=high_seq时候就切换TCP到Open状态,有可能会导致在high_seq上收到dup ACK触发虚假快速重传,SACK使能的时候则不会有这种问题。本篇的主要目的是通过示例2说明三个问题:并不是所有的partial ACK都会触发快速重传;虚假快速重传的避免;SACK关闭场景下虚假快速重传的撤销;估计看了上面的说明还是没明白到底为什么这么处理,下面我们会通过示例2来演示说明这些操作背后的原因。
二、wireshark示例
这篇文章的示例不会在像上一篇一样详细的分析每个数据包的处理过程,因此,在读本篇示例前建议先读上一篇文章的示例。同样如上一篇文章一样,在执行示例前如下设置TCP参数。设置tcp_sack=0关闭SACK功能。
******@Inspiron:~$ sudo ip route add local 127.0.0.2 dev lo congctl reno initcwnd 12 ssthresh lock 10 #参考本系列destination metric文章******@Inspiron:~$ sudo ethtool -K lo tso off gso off #关闭tso gso以方便观察cwnd变化
1、SACK关闭场景下发送缓存不受限
在前一篇文章中我们说No48是因为发送缓存受限而不能发送新的数据包,因此这里我们先通过一个对比示例来看一下,这一次的业务模型与上一次完全相同即:server端建立连接后,休眠1000ms,然后应用层连续write30次,每次写入50bytes,写入间隔为3ms。client与server端建立连接后,立即发送一个请求报文,另外server端第4、5、11次write写入的数据(分别对应下图中的No9、No10和No16报文)在传输的过程中丢失。client端对收到的每个报文都会回复一个ACK确认包,client与server端的时延为50ms。但不同的是,我们通过SO_SNDBUF这个套接字选项,设置发送缓存为一个足够大的数据,下面示例SO_SNDBUF选项设置为40000(之前说过实际TCP内部会把这个设置值翻倍的)。最终TCP数据流交互结果如下图所示
No1-No47:我们可以看到这些数据流与上篇示例中的数据流是一样的,因此不再重复介绍,server端最终发出No47数据包后,packets_out=19,sacked_out=13, lost_out=1, retrans_out=1,cwnd = 6,ssthresh=6, cwnd_cnt=0,prr_delivered=12, prr_out=8, high_seq=851, retransmit_high=251。
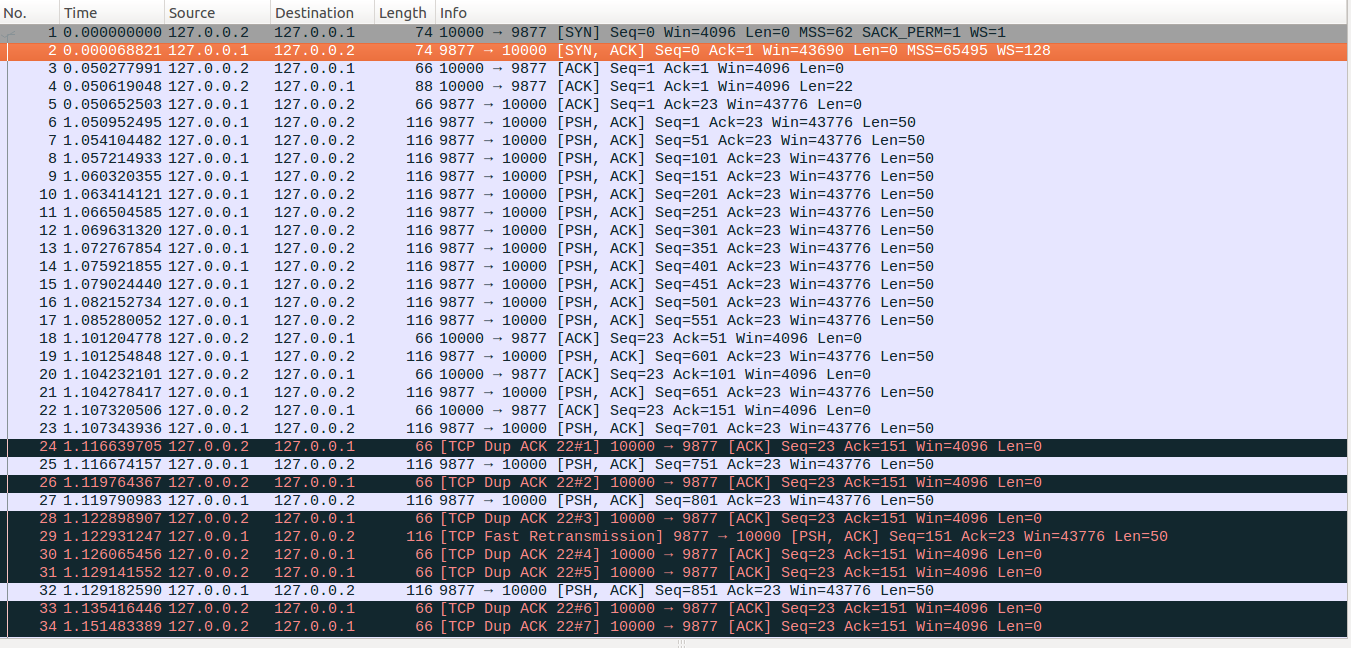

No48-No49:上篇中的示例,在收到No48的时候,server端的发送缓存中因为存放有未释放的tcp数据,导致缓存受限,应用层write休眠,因而没能发出新的数据包。但是本示例中的发送缓存设置了一个足够大的值,因此server端收到No48的时候,server端的缓存中仍然有待发送的数据,所以No48-No49的处理与No47-No48相同,最终发出No49后,sacked_out=sacked_out+1=14、 prr_delivered=prr_delivered+1=13、 packets_out=packets_out+1=20、prr_out=prr_out+1=9 、cwnd = 6。
No50-No52:这三个数据包的处理与上一篇中No49-No51相似。可以看到No50仍然是一个partial ACK,server收到这个partial ACK后,更新retrans_out=0, packets_out=packets_out-6=14, lost_out=0, sacked_out=sacked_out-5=9,接着server根据partial ACK把Seq为501(对应No16)的数据包标记为lost,更新lost_out=lost_out+1=1,retransmit_high = 551,此时 newly_acked_sacked =1, prr_delivered=prr_delivered+newly_acked_sacked=14、 in_flight = packets_out - ( sacked_out + lost_out) + retrans_out = 14 - (9+1) + 0=4,delta = ssthresh - in_flight = 2>0。因为No50的ack number确认了新的数据包且没有RACK重传丢失标记,因此sndcnt = min(delta, max(prr_delivered - prr_out,newly_acked_sacked) + 1) = min(2,max(14-9)+1)=2,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0)) = max(2,0)=2,最终更新cwnd = in_flight + sndcnt = 4+2=6。可以看到此时允许发出两个数据包,接着server端进入快速重传流程,发出No51数据包,退出重传后server尝试发送新的未发送数据包,发出No52数据包。此时packets_out=15,sacked_out=9, lost_out=1, retrans_out=1,cwnd = 6,ssthresh=6, cwnd_cnt=0,prr_delivered=14, prr_out=11, high_seq=851, retransmit_high=551
No53-No54:server端收到No53这个dup ACK后,更新sacked_out=sacked_out+1=10,prr_delivered = prr_delivered+1=15,此时in_flight=15-(10+1)+1=5, delta = ssthresh - in_flight =1,delta>0,因此sndcnt = min(delta, newly_acked_sacked)=min(1,1)=1,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(1,0)=1, cwnd = in_flight + sndcnt = 6,此时拥塞窗口还允许继续发送一个新的数据包,接着server端的tcp尝试进行快速重传,但是因为retransmit_high的限制退出快速重传流程,然后尝试发送新数据,即对应No54。然后更新prr_out=12,packets_out=16。
No55-No56:这组数据包的处理与No53-No54相同,发出No56后,packets_out=17,sacked_out=11, lost_out=1, retrans_out=1,cwnd = 6,ssthresh=6, cwnd_cnt=0,prr_delivered=16, prr_out=13, high_seq=851, retransmit_high=551
No57-No58:处理与上面No53-No54相同,发出No58后,packets_out=18,sacked_out=12, lost_out=1, retrans_out=1,cwnd = 6,ssthresh=6, cwnd_cnt=0,prr_delivered=17, prr_out=14, high_seq=851, retransmit_high=551
No59-No60:处理与上面No53-No54相同,发出No60后,packets_out=19,sacked_out=13, lost_out=1, retrans_out=1,cwnd = 6,ssthresh=6, cwnd_cnt=0,prr_delivered=18, prr_out=15, high_seq=851, retransmit_high=551
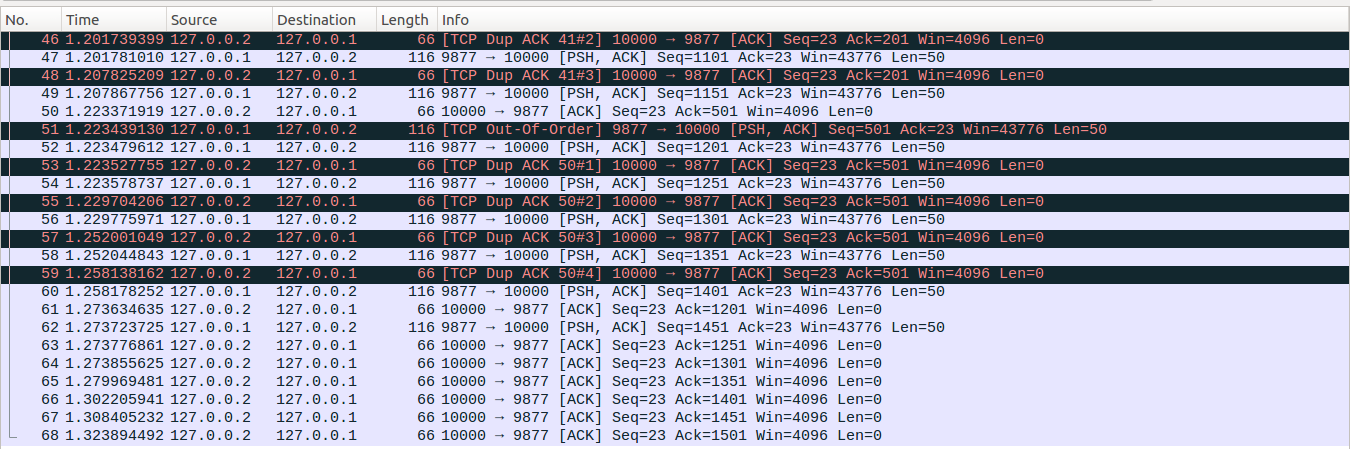
No61-No62:No61的Ack=1201>high_seq=851,因此server端的tcp快速回复过程结束,No61的Ack新确认了14个数据包,因此更新packets_out=packets_out-14=5,sacked_out = sacked_out-13=0,lost_out=0,retrans_out=0,cwnd_cnt=14。接着server端tcp从Recovery状态切换到Open状态,切换的时候,会重置sacked_out=0(实际上此时已经是0了),此时满足概述里面描述的从Recovery切换到Open状态cwnd更新的第三种场景,会更新cwnd=ssthresh=6。此时处于Open态,就不会像之前Recovey状态一样进入快速重传流程了。server端接着进入reno的拥塞避免处理过程,cwnd_cnt/cwnd向下取整后为2,因此更新cwnd_cnt=cwnd_cnt-2*cwnd=2,cwnd=cwnd+2=8。接着server端把缓存中最后的一个数据包发出,对应No62,更新packets_out=6。
No63:server端收到No63报文后,packets_out=5,接着进入reno的拥塞避免,但是因为此时处于application-limited状态,因此不会更新cwnd_cnt,其值依然为2。
No64-No68:这几个数据包的处理与No63相同,最终packets_out=0,sacked_out=0, lost_out=0, retrans_out=0,cwnd = 8,ssthresh=6, cwnd_cnt=2
实际上tcp_notsent_lowat设置项也可以达到类似发送缓存受限而让应用层write操作休眠的效果,这个参数限制了TCP缓存中已经存在的但是还没有发出去的数据量。
2、SACK关闭场景下的拥塞撤销
执行下面示例前,按照如下命令改变initcwnd和ssthresh的设置
ip route change local 127.0.0.2 dev lo initcwnd 6 ssthresh 5 congctl reno
如前面概述所说,这个示例的主要目的是说明三个问题:并不是所有的partial ACK都会触发快速重传;虚假快速重传的避免;SACK关闭场景下虚假快速重传的撤销;在执行这个示例前我们设置tcp_timestamps=0,以关闭Eifel探测算法。后面文章会介绍Eifel探测算法。
业务场景:server端在建立TCP连接后,休眠1s,然后以5ms为间隔连续写入9个数据包,随后休眠71ms,然后写入50bytes的数据,在休眠5ms写入50bytes的数据。server端开始写入的9个数据包第1个(No6)正常到达了client端,但是随后的数据包传输中发生了乱序,第2个数据包在第3、4、5个数据包之后到达,即No8、No9、No10这三个数据包依次到达client后,No7数据包才到达client,随后server端发出的其它数据包则没有发生乱序传输。client对server端的每个数据包都会回复一个ACK确认包,RTT大约为50ms。这种场景下,乱序传输触发快速重传,这意味这server端由dup ACK和partial ACK触发的都是虚假重传。最终如下图所示,对于非重点数据包前面文章都有对应的类似描述,因此此处我只会进行简要的描述,如果对于相关的状态变量或者看不懂简要描述的数据包请先从之前的文章看起。重点包我用红色字体标记了。
No1-No3:client与server建立连接,server端初始处于Open状态,cwnd=6,ssthresh=5。
No4-No5:client发送请求,server端回复一个ACK。
No6-No11:路由表中设置了初始cwnd=6,因此这六个数据包在应用层write操作的时候就可以立即发出。No11发出后packets_out=6, cwnd=6, ssthresh=5, server端处于拥塞避免阶段。
No12-No13:server端收到client回复的No6报文的确认包后,packets_out=5,更新cwnd_cnt=cwnd_cnt+1=1,此时拥塞控制允许发出一个新的数据包,因此发出No13报文,更新packets_out=6。
No14-No15:接着server端收到No14 dup ACK报文,进入Disorder状态,发出No15。更新sacked_out=1,packets_out=7。
No16-No17:与No14-No15处理类似,更新sacked_out=2,packets_out=8。
No18-No19:server收到No18后,更新sacked_out=3,此时已经满足当前的dupthresh门限,因此server端从Disorder状态切换到Recovery状态,初始化prr_delivered=0,prr_out=0,重置cwnd_cnt = 0(这个变量在进入Disorder状态的时候并没有清空,因此Disorder只是怀疑可能会丢包,还可以切换回到Open状态),更新high_seq=451,undo_marker=SND.UNA=51,prior_ssthresh=max(ssthresh,3/4*cwnd) =5, ssthresh=max(cwnd/2,2)=3, prior_cwnd=cwnd=6。接着把No7数据包标记为lost,更新lost_out=1,retransmit_high=101。然后更新prr_delivered=1,此时in_flight=packets_out - ( sacked_out + lost_out) + retrans_out=8-(3+1)=4,delta = ssthresh - in_flight = 3-4=-1<0,sndcnt = (ssthresh * prr_delivered + prior_cwnd - 1)/prior_cwnd - prr_out=(3*1+6-1)/6-0=1, sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(1,1)=1,因此更新cwnd=in_flight+1=5,然后进行快速重传发出No19数据包。重传完No19后,更新retrans_stamp为当前的TCP时间戳,prr_out=1,retrans_out=1,此时in_flight=5>=cwnd,因此退出快速重传流程(实际上此时retransmit_high也不允许linux在额外重传多余的数据包了,但是linxu实现上先判断拥塞窗口然后在判断retransmit_high的限制)。
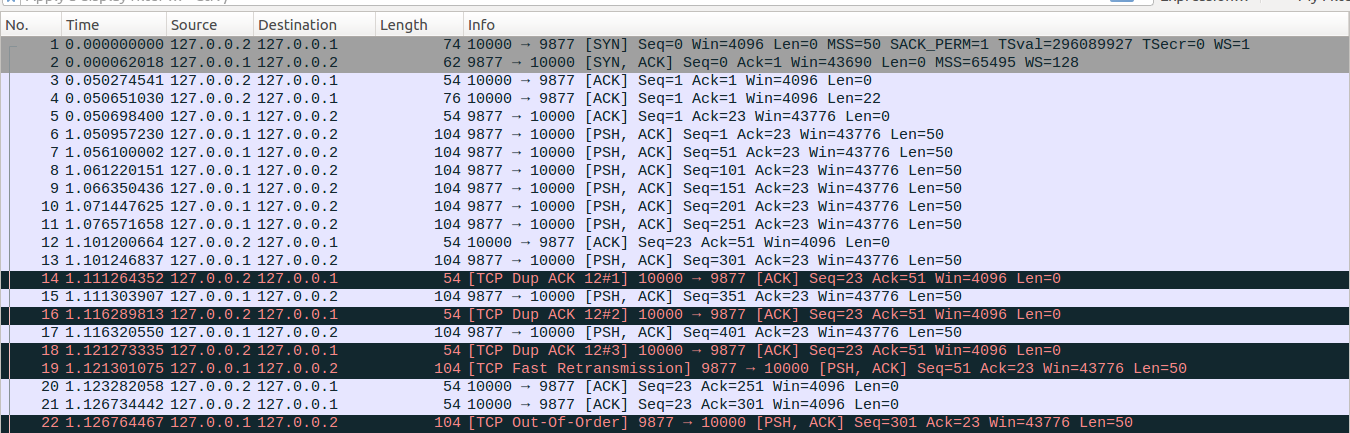
No20:接着这里有意思了,No20是一个partial ACK,经常会有人说partial ACK会立即触发重传,我们来实际更新计算更新一下相关状态变量看看。server端在收到No20数据包后,No20新确认了四个报文,因此更新packets_out=packets_out-4=4,sacked_out=sacked_out-3=0,lost_out=1(实际上lost_out是先更新为0,然后又更新为1的,并不是保持1不变),retrans_out=0,prr_delivered=2,此时in_flight=packets_out - ( sacked_out + lost_out) + retrans_out=4-(0+1)+0=3,delta = ssthresh - in_flight = 3-3=0>=0,而且No20这个partial ACK确认了新的数据,而没有被RACK标记为丢失,因此更新sndcnt = min(delta, max(prr_delivered - prr_out,newly_acked_sacked) + 1)=min(0,max(2-1,1)+1)=min(0,2)=0,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(0,0)=0,cwnd=in_flight+0=3。可以看到此时拥塞窗口已经不允许TCP重传报文或者发送新数据了。所以说partial ACK下也不一定会立即进行重传。
No21-No22:server端在收到No21的时候,更新packets_out=3,retrans_out=0,lost_out=1(同样lost_out是先更新为0,然后又更新为1的,并不是保持1不变), retrans_out=0,prr_delivered=3,in_flight=packets_out - ( sacked_out + lost_out) + retrans_out=3-(0+1)+0=2,delta=1>=0,同样No21确认了新的数据包且没有被RACK标记为丢失,因此sndcnt = min(delta, max(prr_delivered - prr_out,newly_acked_sacked) + 1)=min(1,max(3-1,1)+1)=min(1,3)=1,sndcnt = max(sndcnt, (fast_rexmit ? 1 : 0))=max(1,0)=1,cwnd=in_flight+1=3。因此此时拥塞窗口允许TCP发出一个数据包。接着server端的TCP进入快速重传流程,发出No22数据包,更新retrans_out=1,prr_out=2。
No23-No24:这组数据包的处理与No21-No22相同,发出No24后,packets_out=2,sacked_out=0,lost_out=1,retrans_out=1,prr_delivered=4, prr_out=3,cwnd=3, ssthresh=3。
No25-No26:这组数据包的处理与No21-No22相同,发出No26后,packets_out=1,sacked_out=0,lost_out=1,retrans_out=1,prr_delivered=5, prr_out=4,cwnd=3, ssthresh=3。
No27:此时server端休眠唤醒,开始进行write操作,先写入50bytes数据后在休眠5ms。No27即对应这次write操作,发出No27后,packets_out=2,sacked_out=0,lost_out=1,retrans_out=1,prr_delivered=5, prr_out=5,cwnd=3, ssthresh=3。
No28:server端收到No28后,更新packets_out=1,lost_out=0,retrans_out=0,之前初始进入Recovery状态的时候,high_seq=451,正好与No28的ack number相同,这时候已经满足概述里面"当Recovery状态下的TCP收到ack number大于等于high_seq的ACK报文的时候"这个条件了,此时先进行第一步的处理但是retrans_stamp当前值不为0(No19时候设置的),Eifel探测算法也不允许进行拥塞撤销,因此接着进行第二步骤,此时No28的Ack=high_seq,而且当前SACK处于关闭状态,因此更新cwnd=min(cwnd,in_flight+dupthresh)=min(3,1+3)=3。此时已经没有还未被ack number确认的重传了,因此更新retrans_stamp=0,server端继续停留在Reovery状态,但是此场景下不再尝试进行快速重传,接着server端尝试发送新的数据包,但是当前发送缓存为空,因而没有数据包发出。
No29:server端的应用休眠醒来,进行最后一次write操作,数据包发出后即对应No29。此时packets_out=2, sacked_out=0, lost_out=0,retrans_out=0,prr_delivered=5, prr_out=4,cwnd=3, ssthresh=3。prr_delivered=5, prr_out=6,prr_delivered和prr_out这两个变量实际上已经没有用了,因为当Ack=high_seq的时候已经不会在如前一篇文章介绍的那样更新Recovery状态下的cwnd了。当Recovery切换到Open状态的时候这两个变量也不会清空,但是每次进入Recovery状态,这两个变量会重置为0。后面不再关注这两个变量了。
No30:No30实际上是client对No19的ACK确认包,server端收到这个ACK确认包的时候,先判断第一步,此时undo_marker标记(在No19处进行的标记)允许进行拥塞撤销,并且retrans_stamp=0,当前可以进行拥塞撤销操作,因此更新cwnd=max(cwnd,2*ssthresh)=max(3,2*3)=6, ssthresh=max(ssthresh,prior_ssthresh)=max(3,5)=5,然后更新undo_marker=0,以防止后续重复进行撤销操作。接着进行第二步处理,此时No19的Ack=high_seq,而且当前SACK处于关闭状态,因此更新cwnd=min(cwnd,in_flight+dupthresh)=min(6,5)=5,这里第二步同样会设置retrans_stamp=0,不过retrans_stamp这个变量本来就是0的。server端继续停留在Reovery状态,但是此场景下不再尝试进行快速重传,接着server端尝试发送新的数据包,但是当前发送缓存为空,因而没有数据包发出。
No31:server端收到这个ACK后,同样先判断第一步,但是此时undo_marker=0,已经不允许在进行拥塞撤销操作了。接着同样执行第二步更新cwnd=min(cwnd,in_flight+dupthresh)=min(5,5)=5,retrans_stamp=0,同样继续停留在Recovery状态,尝试发送新的数据,但是没有待发送的数据。
No32-No33:这两个数据包的处理与No31相同,不再重复描述。
No34:server端收到No34这个数据包的时候,更新packets_out=1,判断第一步undo_marker不允许撤销,判断第二步,但是No34的Ack>high_seq,因此不会执行第二步,接着执行第三步更新TCP进入Open状态,并更新cwnd=ssthresh=5。
No35:No35与No34处理类似,最后packets_out=0, sacked_out=0, lost_out=0,retrans_out=0, cwnd=5, ssthresh=5。

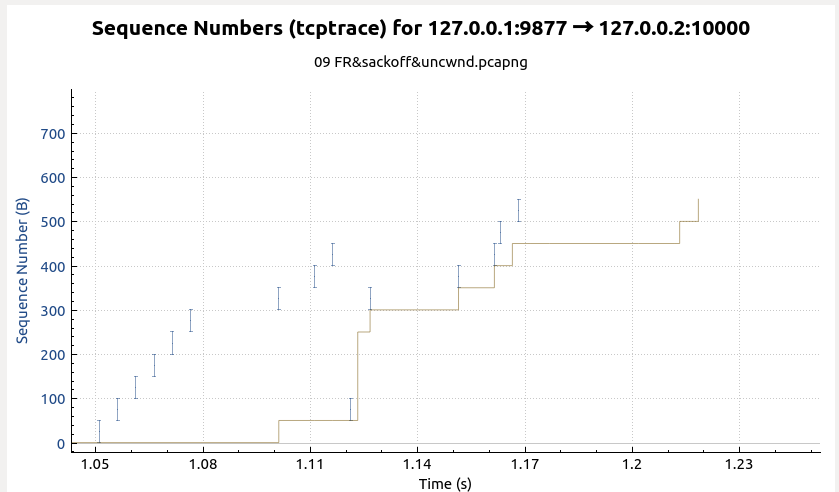
从上面这个示例可以看到关闭SACK的情况下,乱序传输触发的快速重传会产生大量的partial ACK,从而触发虚假快速重传。TCP在探测到这种虚假重传的时候会进行拥塞撤销操作。另外关闭SACK的情况下,如果TCP在Ack=high_seq情况下就退出Recovery状态进入Open后,可能会收到大量的dup ACK(如图中No30-No33),然后又立即虚假触发快速重传进入Recovery状态,因此要避免这种false fast retransmits,即在Ack=high_seq的时候继续停留在Recovery状态下。而在SACK功能打开的情况下,因为SACK下的快速重传是使用SACK块来认定快速重传的(不清楚的话请参考前面SACK下快速重传的文章),因此就不会触发虚假快速重传。最后给出这次业务交互的时序图,试着从里面找出Recovery point、初始快速重传、没有触发快速重传的partial ACK、触发了快速重传的partial ACK这几个关键点吧。
补充说明:
1、本篇主要代码点tcp_try_undo_recovery

 浙公网安备 33010602011771号
浙公网安备 33010602011771号