
tun tap - netns - veth pair - bridge
tun tap - netns - veth pair - bridge
Linux tun:tap 详解
来源 https://zhuanlan.zhihu.com/p/293658778
在计算机网络中,tun与tap是操作系统内核中的虚拟网络设备。不同于普通靠硬件网络适配器实现的设备,这些虚拟的网络设备全部用软件实现,并向运行于操作系统上的软件提供与硬件的网络设备完全相同的功能。
tun/tap是什么?
tun是网络层的虚拟网络设备,可以收发第三层数据报文包,如IP封包,因此常用于一些点对点IP隧道,例如OpenVPN,IPSec等。
tap是链路层的虚拟网络设备,等同于一个以太网设备,它可以收发第二层数据报文包,如以太网数据帧。Tap最常见的用途就是做为虚拟机的网卡,因为它和普通的物理网卡更加相近,也经常用作普通机器的虚拟网卡。
如何操作tun/tap?
Linux tun/tap可以通过网络接口和字符设备两种方式进行操作。
当应用程序使用标准网络接口socket API操作tun/tap设备时,和操作一个真实网卡无异。
当应用程序使用字符设备操作tun/tap设备时,字符设备即充当了用户空间和内核空间的桥梁直接读写二层或三层的数据报文。在 Linux 内核 2.6.x 之后的版本中,tun/tap 对应的字符设备文件分别为:
tun:/dev/net/tun
tap:/dev/tap0
当应用程序打开字符设备时,系统会自动创建对应的虚拟设备接口,一般以tunX和tapX方式命名,虚拟设备接口创建成功后,可以为其配置IP、MAC地址、路由等。当一切配置完毕,应用程序通过此字符文件设备写入IP封包或以太网数据帧,tun/tap的驱动程序会将数据报文直接发送到内核空间,内核空间收到数据后再交给系统的网络协议栈进行处理,最后网络协议栈选择合适的物理网卡将其发出,到此发送流程完成。而物理网卡收到数据报文时会交给网络协议栈进行处理,网络协议栈匹配判断之后通过tun/tap的驱动程序将数据报文原封不动的写入到字符设备上,应用程序从字符设备上读取到IP封包或以太网数据帧,最后进行相应的处理,收取流程完成。
注意:当应用程序关闭字符设备时,系统也会自动删除对应的虚拟设备接口,并且会删除掉创建的路由等信息。
tun/tap的区别
tun/tap 虽然工作原理一致,但是工作的层次不一样。
tun是三层网络设备,收发的是IP层数据包,无法处理以太网数据帧,例如OpenVPN的路由模式就是使用了tun网络设备,OpenVPN Server重新规划了一个网段,所有的客户端都会获取到该网段下的一个IP,并且会添加对应的路由规则,而客户端与目标机器产生的数据报文都要经过OpenVPN网关才能转发。
tap是二层网络设备,收发以太网数据帧,拥有MAC层的功能,可以和物理网卡通过网桥相连,组成一个二层网络。例如OpenVPN的桥接模式可以从外部打一条隧道到本地网络。进来的机器就像本地的机器一样参与通讯,丝毫看不出这些机器是在远程。如果你有使用过虚拟机的经验,桥接模式也是一种十分常见的网络方案,虚拟机会分配到和宿主机器同网段的IP,其他同网段的机器也可以通过网络访问到这台虚拟机。
使用方式
Linux 提供了一些命令行程序方便我们来创建持久化的tun/tap设备,但是如果没有应用程序打开对应的文件描述符,tun/tap的状态一直会是DOWN,还好的是这并不会影响我们把它当作普通网卡去使用。
使用ip tuntap help查看使用帮助
Usage: ip tuntap { add | del | show | list | lst | help } [ dev PHYS_DEV ]
[ mode { tun | tap } ] [ user USER ] [ group GROUP ]
[ one_queue ] [ pi ] [ vnet_hdr ] [ multi_queue ] [ name NAME ]
Where: USER := { STRING | NUMBER }
GROUP := { STRING | NUMBER }
示例
# 创建 tap
ip tuntap add dev tap0 mode tap
# 创建 tun
ip tuntap add dev tun0 mode tun
# 删除 tap
ip tuntap del dev tap0 mode tap
# 删除 tun
ip tuntap del dev tun0 mode tun
tun/tap 设备创建成功后可以当作普通的网卡一样使用,因此我们也可以通过ip link命令来操作它。
# 例如使用ip link命令也可以删除tun/tap设备
ip link del tap0
ip link del tun0
Linux netns 详解
来源 https://zhuanlan.zhihu.com/p/293659403
Network Namespace (以下简称netns)是Linux内核提供的一项实现网络隔离的功能,它能隔离多个不同的网络空间,并且各自拥有独立的网络协议栈,这其中便包括了网络接口(网卡),路由表,iptables规则等。例如大名鼎鼎的docker便是基于netns实现的网络隔离,今天我们就来手动实验一下netns的隔离特性。
使用方式
使用ip netns help查看使用帮助
Usage: ip netns list
ip netns add NAME
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]
ip netns identify [PID]
ip netns pids NAME
ip [-all] netns exec [NAME] cmd ...
ip netns monitor
ip netns list-id
开始实验
我们将要构建如下图的网络
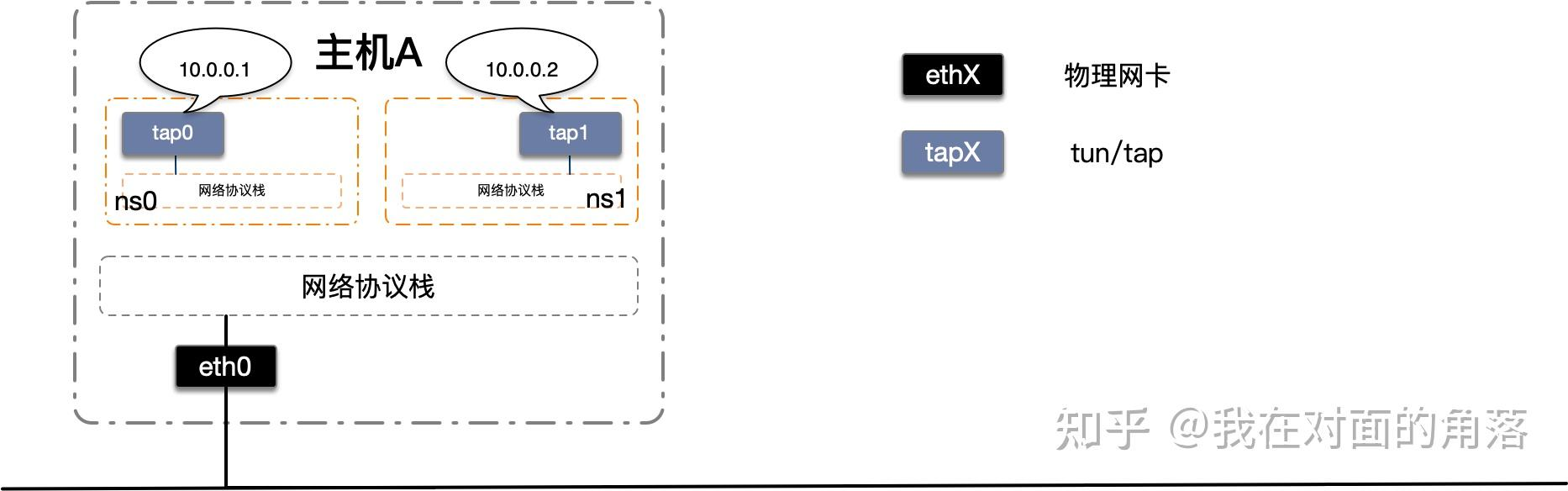
首先我们添加两个tap设备并配置上IP信息,然后添加两个netns,最后将tap设备移动到netns中
# 添加并启动虚拟网卡tap设备
ip tuntap add dev tap0 mode tap
ip tuntap add dev tap1 mode tap
ip link set tap0 up
ip link set tap1 up
# 配置IP
ip addr add 10.0.0.1/24 dev tap0
ip addr add 10.0.0.2/24 dev tap1
# 添加netns
ip netns add ns0
ip netns add ns1
# 将虚拟网卡tap0,tap1分别移动到ns0和ns1中
ip link set tap0 netns ns0
ip link set tap1 netns ns1
在宿主机器上使用ping 10.0.0.1测试与tap0的网络连通性
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
^C
--- 10.0.0.1 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 58ms
在宿主机器上使用ping 10.0.0.2测试与tap1的网络连通性
ping 10.0.0.2
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
^C
--- 10.0.0.2 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 36ms
由于长时间未收到ICMP的回复报文,我使用Ctrl+C退出了。
使用ip netns exec ns0 ping 10.0.0.2在命名空间ns0中测试与tap1的网络连通性
connect: 网络不可达
使用ip netns exec ns1 ping 10.0.0.1在命名空间ns1中测试与tap0的网络连通性
connect: 网络不可达
在netns中执行命令有两种方式,一种是先在宿主机器上执行ip netns exec <netns name> bash进入netns,然后就可以像是在本机一样执行命令了。另一种是每次在宿主机器上使用完整的命令,为了明显区分,我们这里都使用完整的命令,例如ip netns exec ns0 ping 10.0.0.2的含义为在命名空间ns0中执行ping 10.0.0.2命令
可以看到在宿主机器上访问netns是丢包,而在netns中互相访问是网络不可达了,这是为什么呢?让我们来检查一下netns吧。
使用ip netns exec ns0 ip a在ns0中查看网卡
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
16: tap0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 42:ad:98:a2:cc:81 brd ff:ff:ff:ff:ff:ff
使用ip netns exec ns1 ip a在ns1中查看网卡
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
17: tap1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 12:06:1d:06:41:57 brd ff:ff:ff:ff:ff:ff
可以看到不仅本地环回lo和tap设备的状态都是DOWN,甚至就连tap设备的IP信息也没有了,这是因为在不同的网络命名空间中移动虚拟网络接口时会重置虚拟网络接口的状态。
我们将ns0和ns1中的相关设备都重新启动并配置上IP
ip netns exec ns0 ip link set lo up
ip netns exec ns0 ip link set tap0 up
ip netns exec ns0 ip addr add 10.0.0.1/24 dev tap0
ip netns exec ns1 ip link set lo up
ip netns exec ns1 ip link set tap1 up
ip netns exec ns1 ip addr add 10.0.0.2/24 dev tap1
首先我们测试一下netns中本地网络是否正常
使用ip netns exec ns0 ping 10.0.0.1在命名空间ns0中测试本地网卡是否启动
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
64 bytes from 10.0.0.1: icmp_seq=1 ttl=64 time=0.036 ms
64 bytes from 10.0.0.1: icmp_seq=2 ttl=64 time=0.033 ms
64 bytes from 10.0.0.1: icmp_seq=3 ttl=64 time=0.084 ms
64 bytes from 10.0.0.1: icmp_seq=4 ttl=64 time=0.044 ms
^C
--- 10.0.0.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 65ms
rtt min/avg/max/mdev = 0.033/0.049/0.084/0.021 ms
使用ip netns exec ns1 ping 10.0.0.2在命名空间ns1中测试本地网卡是否启动
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=0.033 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=64 time=0.034 ms
64 bytes from 10.0.0.2: icmp_seq=3 ttl=64 time=0.065 ms
64 bytes from 10.0.0.2: icmp_seq=4 ttl=64 time=0.035 ms
^C
--- 10.0.0.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 65ms
rtt min/avg/max/mdev = 0.033/0.049/0.084/0.021 ms
可以看出本地网络没有问题,然后我们再来测试一下两个netns之间的网络连通性
使用ip netns exec ns0 ping 10.0.0.2在命名空间ns0中测试与tap1的网络连通性
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
^C
--- 10.0.0.2 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 84ms
使用ip netns exec ns1 ping 10.0.0.1在命名空间ns1中测试与tap0的网络连通性
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
^C
--- 10.0.0.1 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 30ms
可以看出没有任何ICMP回复包,netns确实把在同一台主机上的两张虚拟网卡隔离起来了。在这里我们只是简单的使用ping命令来测试网络的连通性,实际上可以做到更多,例如修改某一个netns的路由表或者防火墙规则,完全不会影响到其他的netns,当然也不会影响到宿主机器,在这里由于篇幅原因就不再展开实验了,感兴趣的同学可以实验一下。下一节我们将学习另一个网络设备veth pair,使用它来把两个netns连接起来,让两个隔离的netns之间可以互相通信。
Linux veth pair 详解
来源 https://zhuanlan.zhihu.com/p/293659939
Linux veth pair 详解
veth pair是成对出现的一种虚拟网络设备接口,一端连着网络协议栈,一端彼此相连。如下图所示:
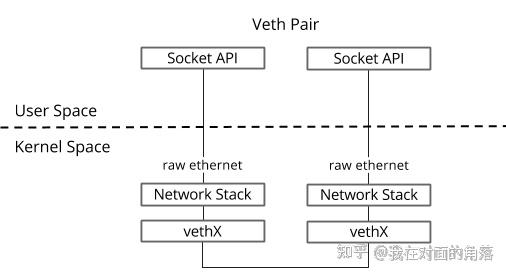
由于它的这个特性,常常被用于构建虚拟网络拓扑。例如连接两个不同的网络命名空间(netns),连接docker容器,连接网桥(Bridge)等,其中一个很常见的案例就是OpenStack Neutron底层用它来构建非常复杂的网络拓扑。
如何使用?
创建一对veth
ip link add <veth name> type veth peer name <peer name>
实验
我们改造上一节完成的netns实验,使用veth pair将两个的隔离netns连接起来。如下图所示:
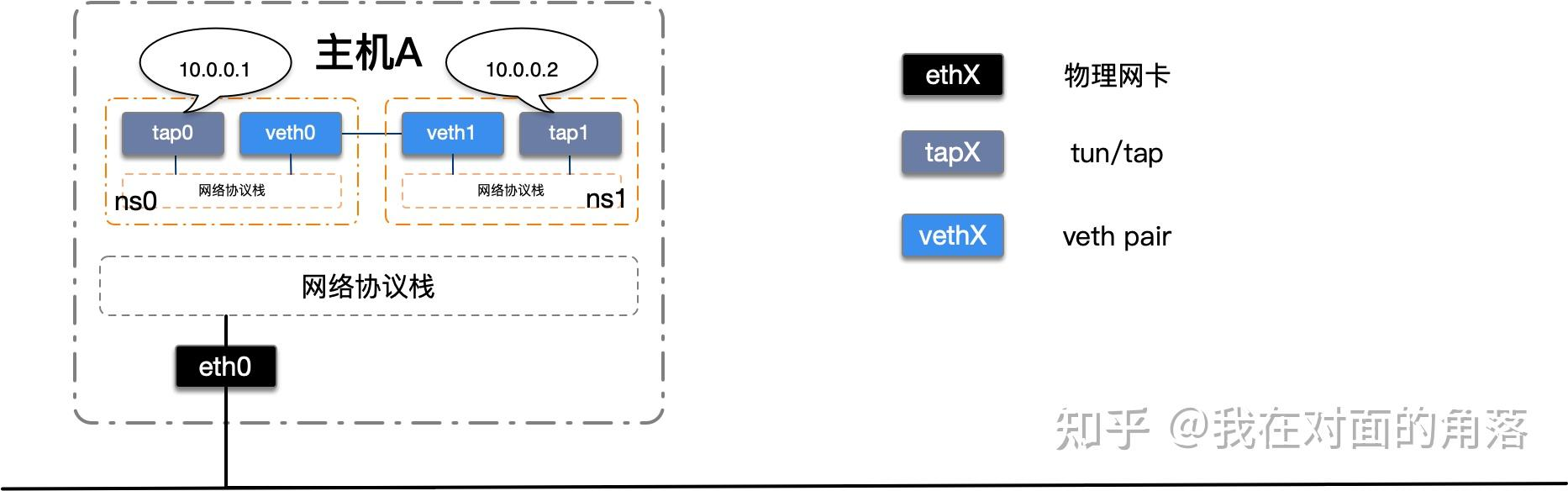
我们首先创建一对veth设备,将veth设备分别移动到两个netns中并启动。
# 创建一对veth
ip link add veth0 type veth peer name veth1
# 将veth移动到netns中
ip link set veth0 netns ns0
ip link set veth1 netns ns1
# 启动
ip netns exec ns0 ip link set veth0 up
ip netns exec ns1 ip link set veth1 up
接下来我们测试一下。
使用ip netns exec ns0 ping 10.0.0.2在命名空间ns0中测试与tap1的网络连通性。
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
From 10.0.0.1 icmp_seq=1 Destination Host Unreachable
From 10.0.0.1 icmp_seq=2 Destination Host Unreachable
From 10.0.0.1 icmp_seq=3 Destination Host Unreachable
^C
--- 10.0.0.2 ping statistics ---
5 packets transmitted, 0 received, +3 errors, 100% packet loss, time 77ms
pipe 4
使用ip netns exec ns1 ping 10.0.0.1在命名空间ns1中测试与tap0的网络连通性。
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
From 10.0.0.2 icmp_seq=1 Destination Host Unreachable
From 10.0.0.2 icmp_seq=2 Destination Host Unreachable
From 10.0.0.2 icmp_seq=3 Destination Host Unreachable
^C
--- 10.0.0.1 ping statistics ---
4 packets transmitted, 0 received, +3 errors, 100% packet loss, time 108ms
pipe 4
什么情况?为什么网络还是不通呢?答案就是路由配置有问题。
使用ip netns exec ns0 route -n查看ns0的路由表。
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 tap0
使用ip netns exec ns1 route -n查看ns1的路由表。
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 tap1
原来访问10.0.0.0/24的流量都从tap设备发出去了,又因为tap设备没有和其他设备相连,发出去的数据报文不会被处理,因此还是访问不到目标IP,我们来修改一下路由,让访问10.0.0.0/24的流量从veth设备发出。
#修改路由出口为veth
ip netns exec ns0 ip route change 10.0.0.0/24 via 0.0.0.0 dev veth0
ip netns exec ns1 ip route change 10.0.0.0/24 via 0.0.0.0 dev veth1
我们再来看一下路由
使用ip netns exec ns0 route -n查看ns0的路由表。
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 veth0
使用ip netns exec ns1 route -n查看ns1的路由表。
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1
最后我们再来测试一下。
使用ip netns exec ns0 ping 10.0.0.2在命名空间ns0中测试与tap1的网络连通性。
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=0.031 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=64 time=0.035 ms
64 bytes from 10.0.0.2: icmp_seq=3 ttl=64 time=0.037 ms
64 bytes from 10.0.0.2: icmp_seq=4 ttl=64 time=0.043 ms
^C
--- 10.0.0.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 103ms
rtt min/avg/max/mdev = 0.031/0.036/0.043/0.007 ms
使用ip netns exec ns1 ping 10.0.0.1在命名空间ns1中测试与tap0的网络连通性。
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
64 bytes from 10.0.0.1: icmp_seq=1 ttl=64 time=0.027 ms
64 bytes from 10.0.0.1: icmp_seq=2 ttl=64 time=0.047 ms
64 bytes from 10.0.0.1: icmp_seq=3 ttl=64 time=0.051 ms
64 bytes from 10.0.0.1: icmp_seq=4 ttl=64 time=0.042 ms
^C
--- 10.0.0.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 66ms
rtt min/avg/max/mdev = 0.027/0.041/0.051/0.012 ms
可以看到我们使用veth pair将两个隔离的netns成功的连接到了一起。
但是这样的网络拓扑存在一个弊端,随着网络设备的增多,网络连线的复杂度将成倍增长。 如果连接三个netns时,网络连线就成了下图的样子
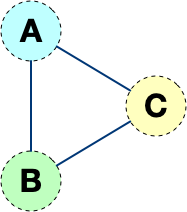
而如果连接四个netns时,网络连线就成了下图的样子
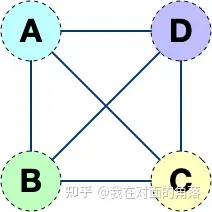
如果有五台设备。。。
有没有什么技术可以解决这个问题呢?答案是有的,Linux Bridge(网桥)。下一节我们将使用网桥来将多个隔离的netns连接起来,这样网络连线就非常清爽了。
Linux Bridge 详解
来源 https://zhuanlan.zhihu.com/p/293667316
Linux Bridge 详解
Linux Bridge(网桥)是用纯软件实现的虚拟交换机,有着和物理交换机相同的功能,例如二层交换,MAC地址学习等。因此我们可以把tun/tap,veth pair等设备绑定到网桥上,就像是把设备连接到物理交换机上一样。此外它和veth pair、tun/tap一样,也是一种虚拟网络设备,具有虚拟设备的所有特性,例如配置IP,MAC地址等。
Linux Bridge通常是搭配KVM、docker等虚拟化技术一起使用的,用于构建虚拟网络,因为此教程不涉及虚拟化技术,我们就使用前面学习过的netns来模拟虚拟设备。
如何使用Linux Bridge?
操作网桥有多种方式,在这里我们介绍一下通过bridge-utils来操作,由于它不是Linux系统自带的工具,因此需要我们手动来安装它。
# centos
yum install -y bridge-utils
# ubuntu
apt-get install -y bridge-utils
使用brctl help查看使用帮助
never heard of command [help]
Usage: brctl [commands]
commands:
addbr <bridge> add bridge
delbr <bridge> delete bridge
addif <bridge> <device> add interface to bridge
delif <bridge> <device> delete interface from bridge
hairpin <bridge> <port> {on|off} turn hairpin on/off
setageing <bridge> <time> set ageing time
setbridgeprio <bridge> <prio> set bridge priority
setfd <bridge> <time> set bridge forward delay
sethello <bridge> <time> set hello time
setmaxage <bridge> <time> set max message age
setpathcost <bridge> <port> <cost> set path cost
setportprio <bridge> <port> <prio> set port priority
show [ <bridge> ] show a list of bridges
showmacs <bridge> show a list of mac addrs
showstp <bridge> show bridge stp info
stp <bridge> {on|off} turn stp on/off
常用命令如
新建一个网桥:
brctl addbr <bridge>
添加一个设备(例如eth0)到网桥:
brctl addif <bridge> eth0
显示当前存在的网桥及其所连接的网络端口:
brctl show
启动网桥:
ip link set <bridge> up
删除网桥,需要先关闭它:
ip link set <bridge> down
brctl delbr <bridge>
或者使用ip link del 命令直接删除网桥
ip link del <bridge>
增加Linux Bridge时会自动增加一个同名虚拟网卡在宿主机器上,因此我们可以通过ip link命令操作这个虚拟网卡,实际上也就是操作网桥,并且只有当这个虚拟网卡状态处于up的时候,网桥才会转发数据。
实验
在上一节《Linux veth pair详解》我们使用veth pair将两个隔离的netns连接在了一起,在现实世界里等同于用一根网线把两台电脑连接在了一起,但是在现实世界里往往很少会有人这样使用。因为一台设备不仅仅只需要和另一台设备通信,它需要和很多很多的网络设备进行通信,如果还使用这样的方式,需要十分复杂的网络接线,并且现实世界中的普通网络设备也没有那么多网络接口。
那么,想要让某一台设备和很多网络设备都可以通信需要如何去做呢?在我们的日常生活中,除了手机和电脑,最常见的网络设备就是路由器了,我们的手机连上WI-FI,电脑插到路由器上,等待从路由器的DHCP服务器上获取到IP,他们就可以相互通信了,这便是路由器的二层交换功能在工作。Linux Bridge最主要的功能就是二层交换,是对现实世界二层交换机的模拟,我们稍微改动一下网络拓扑,如下图:
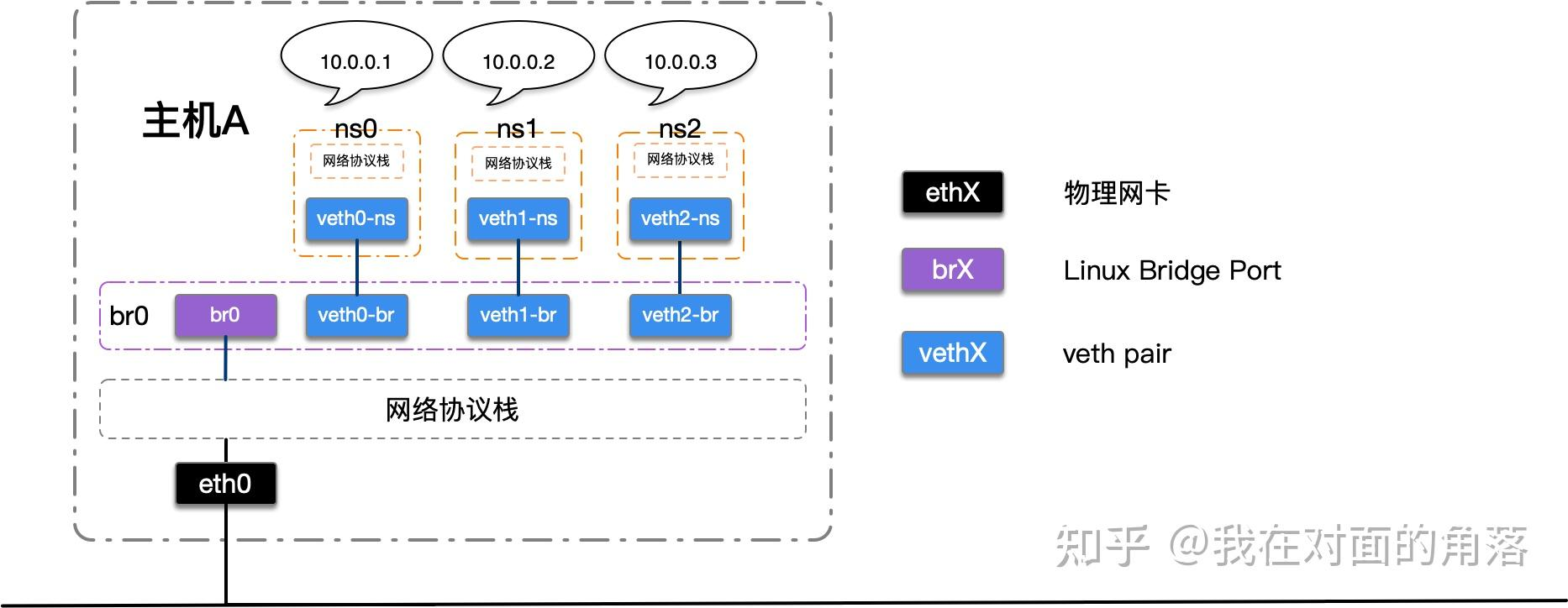
我们建立了一个网桥,三个netns,三对veth pair,分别一端在netns中,另一端连接在网桥上,为了简化拓扑,我去除了netns中的tap设备,将IP直接配置在veth上。
veth设备不仅仅可以可以充当“网线”,同时它也可以当作虚拟网卡来使用。
# 添加网桥
brctl addbr br0
# 启动网桥
ip link set br0 up
# 新增三个netns
ip netns add ns0
ip netns add ns1
ip netns add ns2
# 新增两对veth
ip link add veth0-ns type veth peer name veth0-br
ip link add veth1-ns type veth peer name veth1-br
ip link add veth2-ns type veth peer name veth2-br
# 将veth的一端移动到netns中
ip link set veth0-ns netns ns0
ip link set veth1-ns netns ns1
ip link set veth2-ns netns ns2
# 将netns中的本地环回和veth启动并配置IP
ip netns exec ns0 ip link set lo up
ip netns exec ns0 ip link set veth0-ns up
ip netns exec ns0 ip addr add 10.0.0.1/24 dev veth0-ns
ip netns exec ns1 ip link set lo up
ip netns exec ns1 ip link set veth1-ns up
ip netns exec ns1 ip addr add 10.0.0.2/24 dev veth1-ns
ip netns exec ns2 ip link set lo up
ip netns exec ns2 ip link set veth2-ns up
ip netns exec ns2 ip addr add 10.0.0.3/24 dev veth2-ns
# 将veth的另一端启动并挂载到网桥上
ip link set veth0-br up
ip link set veth1-br up
ip link set veth2-br up
brctl addif br0 veth0-br
brctl addif br0 veth1-br
brctl addif br0 veth2-br
测试网络连通性前,先临时禁用 bridge 上的 arptables iptables ip6tables
echo 0 > /proc/sys/net/bridge/bridge-nf-call-arptables
echo 0 > /proc/sys/net/bridge/bridge-nf-call-iptables
echo 0 > /proc/sys/net/bridge/bridge-nf-call-ip6tables
使用ip netns exec ns0 ping 10.0.0.2在命名空间ns0中测试与ns1的10.0.0.2的网络连通性
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=0.032 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=64 time=0.058 ms
64 bytes from 10.0.0.2: icmp_seq=3 ttl=64 time=0.052 ms
64 bytes from 10.0.0.2: icmp_seq=4 ttl=64 time=0.044 ms
^C
--- 10.0.0.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 54ms
rtt min/avg/max/mdev = 0.032/0.046/0.058/0.011 ms
使用ip netns exec ns0 ping 10.0.0.3在命名空间ns0中测试与ns2的10.0.0.3的网络连通性
PING 10.0.0.3 (10.0.0.3) 56(84) bytes of data.
64 bytes from 10.0.0.3: icmp_seq=1 ttl=64 time=0.054 ms
64 bytes from 10.0.0.3: icmp_seq=2 ttl=64 time=0.045 ms
64 bytes from 10.0.0.3: icmp_seq=3 ttl=64 time=0.058 ms
64 bytes from 10.0.0.3: icmp_seq=4 ttl=64 time=0.064 ms
^C
--- 10.0.0.3 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 81ms
rtt min/avg/max/mdev = 0.045/0.055/0.064/0.008 ms
使用ip netns exec ns1 ping 10.0.0.1在命名空间ns1中测试与ns0的10.0.0.1的网络连通性
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
64 bytes from 10.0.0.1: icmp_seq=1 ttl=64 time=0.031 ms
64 bytes from 10.0.0.1: icmp_seq=2 ttl=64 time=0.046 ms
64 bytes from 10.0.0.1: icmp_seq=3 ttl=64 time=0.038 ms
64 bytes from 10.0.0.1: icmp_seq=4 ttl=64 time=0.041 ms
^C
--- 10.0.0.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 81ms
rtt min/avg/max/mdev = 0.031/0.039/0.046/0.005 ms
使用ip netns exec ns1 ping 10.0.0.3在命名空间ns1中测试与ns2的10.0.0.3的网络连通性
PING 10.0.0.3 (10.0.0.3) 56(84) bytes of data.
64 bytes from 10.0.0.3: icmp_seq=1 ttl=64 time=0.060 ms
64 bytes from 10.0.0.3: icmp_seq=2 ttl=64 time=0.059 ms
64 bytes from 10.0.0.3: icmp_seq=3 ttl=64 time=0.044 ms
64 bytes from 10.0.0.3: icmp_seq=4 ttl=64 time=0.065 ms
^C
--- 10.0.0.3 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 65ms
rtt min/avg/max/mdev = 0.044/0.057/0.065/0.007 ms
使用ip netns exec ns2 ping 10.0.0.1在命名空间ns2中测试与ns0的10.0.0.1的网络连通性
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
64 bytes from 10.0.0.1: icmp_seq=1 ttl=64 time=0.032 ms
64 bytes from 10.0.0.1: icmp_seq=2 ttl=64 time=0.056 ms
64 bytes from 10.0.0.1: icmp_seq=3 ttl=64 time=0.043 ms
64 bytes from 10.0.0.1: icmp_seq=4 ttl=64 time=0.060 ms
^C
--- 10.0.0.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 69ms
rtt min/avg/max/mdev = 0.032/0.047/0.060/0.013 ms
使用ip netns exec ns2 ping 10.0.0.2在命名空间ns2中测试与ns1的10.0.0.2的网络连通性
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=0.030 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=64 time=0.055 ms
64 bytes from 10.0.0.2: icmp_seq=3 ttl=64 time=0.044 ms
64 bytes from 10.0.0.2: icmp_seq=4 ttl=64 time=0.042 ms
^C
--- 10.0.0.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 114ms
rtt min/avg/max/mdev = 0.030/0.042/0.055/0.011 ms
可以看到我们通过网桥的方式把三个隔离的netns连接在了一起,通过这种方式,我们还可以很方便的添加第四个netns,第五个netns...在这里我们就不展开了,感兴趣的同学可以尝试一下。
接下来我们来讲解一下docker的几种网络模式。
linux bridge - mac和vlan转发
来源 https://www.jianshu.com/u/d7eb9e00077c
如果bridge要支持vlan filter,需要满足如下条件
a. 打开kernel编译选项:CONFIG_BRIDGE_VLAN_FILTERING
b. 打开 vlan enable,比如打开网桥br1的vlan filter功能: echo 1 > /sys/class/net/br1/bridge/vlan_filtering
使能vlan filter后,只能通过bridge命令查看端口的vlan和fdb转发表
root@node2:~# bridge vlan
port vlan ids
br1 1 PVID Egress Untagged
vetha 1 PVID Egress Untagged
vethx 1 PVID Egress Untagged
root@node2:~# bridge fdb list br br1
33:33:00:00:00:01 dev br1 self permanent
66:e6:6f:a8:d4:97 dev vetha master br1 permanent
66:e6:6f:a8:d4:97 dev vetha vlan 10 master br1 permanent
66:e6:6f:a8:d4:97 dev vetha vlan 1 master br1 permanent
33:33:00:00:00:01 dev vetha self permanent
01:00:5e:00:00:01 dev vetha self permanent
12:27:96:8c:f4:58 dev vethx vlan 10 master br1 permanent
12:27:96:8c:f4:58 dev vethx master br1 permanent
12:27:96:8c:f4:58 dev vethx vlan 1 master br1 permanent
33:33:00:00:00:01 dev vethx self permanent
01:00:5e:00:00:01 dev vethx self permanent
给网桥和端口添加vlan的区别
#给端口添加vlan时,可指定master或者不指定,kernel 端会取出vetha的master设备(即网桥),
#调用网桥的 ndo_bridge_setlink 给端口添加vlan
bridge vlan add vid 10 dev vetha untagged pvid master
bridge vlan add vid 10 dev vetha untagged pvid
#给网桥添加vlan时,必须指定self,kernel端会调用网桥的ndo_bridge_setlink给网桥添加vlan
bridge vlan add vid 13 dev br1 untagged pvid self
关于两个参数: untagged pvid
untagged: 如果指定了此参数,则报文从此端口发出时,vlan会被剥掉。如果不指定,则报文会携带vlan发出去。
pvid:如果指定了此参数,则此端口收到不带vlan报文时,则会给报文添加pvid。如果不指定,则会给报文添加默认pvid 1。如果连pvid都没有,则收到不带vlan报文时,会被drop掉
接收报文处理
如果vlan filter功能没使能,则始终允许报文通过。
如果vlan filter功能使能了,需要根据报文是否携带vlan进行不同处理:
如果报文带vlan,则判断此vlan是否在vlan_bitmap中,如果存在,则返回true,如果不存在,则返回flase,表示不允许此报文通过。
如果报文不带vlan,将pvid赋给skb(如果pvid也不存在,则drop此报文),然后判断此vlan是否在vlan_bitmap中,如果存在,则返回true,如果不存在,则返回flase,表示不允许此报文通过。
发送报文处理
使能vlan filter功能后,报文在网桥内部转发过程中始终携带vlan,
如果要转发出端口时,会判断出端口是否允许此vlan的报文通过。
如果允许报文从此端口发出去,再根据untagged判断是否需要将vlan去掉。
实践部分
#创建网桥br1
brctl addbr br1
#使用网桥的vlan filter功能
echo 1 > /sys/class/net/br1/bridge/vlan_filtering
#添加两个namespace
ip netns add test1
ip netns add test2
#创建一对veth端口: vetha和vethb
ip link add vetha type veth peer vethb
#将vethb添加到ns test1,并设置ip 1.1.1.10
ip link set dev vethb netns test1
ip netns exec test1 ip link set dev vethb up
ip netns exec test1 ip address add dev vethb 1.1.1.10/24
将vetha添加到bridge br1
ip link set dev vetha up
brctl addif br1 vetha
#再创建一对veth端口: vethx和vethy
ip link add vethx type veth peer vethy
#将vethx添加到ns test2,并设置ip 1.1.1.11
ip link set dev vethy netns test2
ip netns exec test2 ip link set dev vethy up
ip netns exec test2 ip address add dev vethy 1.1.1.11/24
将vethx添加到bridge br1
ip link set dev vethx up
brctl addif br1 vethx
场景1 默认情况下,端口和网桥都有一个默认vlan 1,并且是pvid,和untagged模式。报文可以互通ping通
root@node2:~# bridge vlan
port vlan ids
br1 1 Egress Untagged
vetha 1 PVID Egress Untagged
vethx 1 PVID Egress Untagged
root@node2:~# ip netns exec test1 ping 1.1.1.11
PING 1.1.1.11 (1.1.1.11) 56(84) bytes of data.
64 bytes from 1.1.1.11: icmp_seq=1 ttl=64 time=0.142 ms
^C
--- 1.1.1.11 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.142/0.142/0.142/0.000 ms
场景2 去掉端口vetha的pvid和untagged参数,因为vetha端口没有了pvid,所以端口vetha收到报文后就被drop掉了
bridge vlan add vid 1 dev vetha
root@node2:~# bridge vlan
port vlan ids
br1 1 Egress Untagged
vetha 1
vethx 1 PVID Egress Untagged
root@node2:~# ip netns exec test1 ping 1.1.1.11
PING 1.1.1.11 (1.1.1.11) 56(84) bytes of data.
^C
--- 1.1.1.11 ping statistics ---
8 packets transmitted, 0 received, 100% packet loss, time 7151ms
场景3 只去掉端口 vethx 的 untagged 参数,报文从vethx发出去时,报文还携带vlan
root@node2:~# bridge vlan add vid 1 dev vetha pvid
root@node2:~# bridge vlan
port vlan ids
br1 1 Egress Untagged
vetha 1 PVID Egress Untagged
vethx 1 PVID
root@node2:~# ip netns exec test1 ping 1.1.1.11 -c1
PING 1.1.1.11 (1.1.1.11) 56(84) bytes of data.
^C
--- 1.1.1.11 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
#在test2 ns抓包,可看到报文携带vlan 1
root@node2:~# ip netns exec test2 tcpdump -vne -i vethy
tcpdump: listening on vethy, link-type EN10MB (Ethernet), capture size 262144 bytes
^C21:00:11.558978 4e:b4:a4:4e:a7:96 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 1, p 0, ethertype ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 1.1.1.11 tell 1.1.1.10, length 28
21:00:12.568679 4e:b4:a4:4e:a7:96 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 1, p 0, ethertype ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 1.1.1.11 tell 1.1.1.10, length 28
21:00:13.592686 4e:b4:a4:4e:a7:96 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 1, p 0, ethertype ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 1.1.1.11 tell 1.1.1.10, length 28
场景4 将默认vlan 1删除,创建新的vlan 10
bridge vlan del vid 1 dev vetha
bridge vlan del vid 1 dev vethx
bridge vlan add vid 10 dev vetha pvid untagged
bridge vlan add vid 10 dev vethx pvid untagged
root@node2:~# bridge vlan
port vlan ids
br1 1 Egress Untagged
vetha 10 PVID Egress Untagged
vethx 10 PVID Egress Untagged
//互相ping是可以通的,可以通过删除vethx 的Untagged标签,验证不通的情况
root@node2:~# ip netns exec test1 ping 1.1.1.11
PING 1.1.1.11 (1.1.1.11) 56(84) bytes of data.
64 bytes from 1.1.1.11: icmp_seq=1 ttl=64 time=0.139 ms
^C
--- 1.1.1.11 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.139/0.139/0.139/0.000 ms
vlan相关代码初始化
创建网桥设备时,会调用 br_dev_init->br_vlan_init,设置 vlan_proto 和默认pvid,并将pvid和网桥mac添加到fdb中。
int br_vlan_init(struct net_bridge *br)
{
br->vlan_proto = htons(ETH_P_8021Q);
br->default_pvid = 1;
return br_vlan_add(br, 1, BRIDGE_VLAN_INFO_PVID | BRIDGE_VLAN_INFO_UNTAGGED);
}
将接口添加到网桥上时,会调用 br_add_if->nbp_vlan_init,将网桥的pvid和接口mac地址添加到fdb中。
int nbp_vlan_init(struct net_bridge_port *p)
{
return p->br->default_pvid ?
nbp_vlan_add(p, p->br->default_pvid, BRIDGE_VLAN_INFO_PVID | BRIDGE_VLAN_INFO_UNTAGGED) : 0;
}
添加vlan流程
通过bridge命令给端口添加vlan时
bridge vlan add vid 1 dev vetha pvid
命令行端代码
static int vlan_modify(int cmd, int argc, char **argv)
struct {
struct nlmsghdr n;
struct ifinfomsg ifm;
char buf[1024];
} req = {
.n.nlmsg_len = NLMSG_LENGTH(sizeof(struct ifinfomsg)),
.n.nlmsg_flags = NLM_F_REQUEST,
.n.nlmsg_type = cmd,
.ifm.ifi_family = PF_BRIDGE,
};
#如果指定了 self
flags |= BRIDGE_FLAGS_SELF;
#如果指定了 master
flags |= BRIDGE_FLAGS_MASTER;
#如果指定了vlan范围
vid = atoi(*argv);
vid_end = atoi(p);
vinfo.flags |= BRIDGE_VLAN_INFO_RANGE_BEGIN;
#如果指定了 pvid
vinfo.flags |= BRIDGE_VLAN_INFO_PVID;
#如果指定了 untagged
vinfo.flags |= BRIDGE_VLAN_INFO_UNTAGGED;
afspec = addattr_nest(&req.n, sizeof(req), IFLA_AF_SPEC);
if (flags)
addattr16(&req.n, sizeof(req), IFLA_BRIDGE_FLAGS, flags);
add_vlan_info_range(&req.n, sizeof(req), vid, vid_end, vinfo.flags);
kernel端代码流程
static int rtnl_bridge_setlink(struct sk_buff *skb, struct nlmsghdr *nlh)
//根据 ifi_index 获取 dev
dev = __dev_get_by_index(net, ifm->ifi_index);
//获取 flags
br_spec = nlmsg_find_attr(nlh, sizeof(struct ifinfomsg), IFLA_AF_SPEC);
if (br_spec) {
nla_for_each_nested(attr, br_spec, rem) {
//获取 flags
if (nla_type(attr) == IFLA_BRIDGE_FLAGS) {
if (nla_len(attr) < sizeof(flags))
return -EINVAL;
have_flags = true;
flags = nla_get_u16(attr);
break;
//如果flags为空或者flags包含标志BRIDGE_FLAGS_MASTER,则使用网桥设备的ndo_bridge_setlink
//这个流程主要是给端口添加vlan
if (!flags || (flags & BRIDGE_FLAGS_MASTER)) {
struct net_device *br_dev = netdev_master_upper_dev_get(dev);
if (!br_dev || !br_dev->netdev_ops->ndo_bridge_setlink) {
err = -EOPNOTSUPP;
goto out;
}
//调用 ndo_bridge_setlink,对于网桥来说,就是 br_setlink
err = br_dev->netdev_ops->ndo_bridge_setlink(dev, nlh);
if (err)
goto out;
flags &= ~BRIDGE_FLAGS_MASTER;
}
//如果flags指定了BRIDGE_FLAGS_SELF,则使用dev本身的ndo_bridge_setlink,
//但是支持 ndo_bridge_setlink 的dev比较少,从代码看,只有bridge和ixgbe支持。
//这个flag主要是为了给网桥添加vlan
if ((flags & BRIDGE_FLAGS_SELF)) {
if (!dev->netdev_ops->ndo_bridge_setlink)
err = -EOPNOTSUPP;
else
err = dev->netdev_ops->ndo_bridge_setlink(dev, nlh);
if (!err)
flags &= ~BRIDGE_FLAGS_SELF;
}
int br_setlink(struct net_device *dev, struct nlmsghdr *nlh)
afspec = nlmsg_find_attr(nlh, sizeof(struct ifinfomsg), IFLA_AF_SPEC);
if (afspec) {
br_afspec((struct net_bridge *)netdev_priv(dev), p, afspec, RTM_SETLINK);
switch (cmd) {
case RTM_SETLINK:
//在端口上添加vlan
if (p) {
err = nbp_vlan_add(p, vinfo->vid, vinfo->flags);
if (err)
break;
//如果指定了master,也要将vlan添加到网桥上(但是从iproute2代码看,没有设置BRIDGE_VLAN_INFO_MASTER)
if (vinfo->flags & BRIDGE_VLAN_INFO_MASTER)
err = br_vlan_add(p->br, vinfo->vid,
vinfo->flags);
} else
//在网桥上添加vlan
err = br_vlan_add(br, vinfo->vid, vinfo