

SICP JavaScript 描述
SICP JavaScript 描述
来源 http://sicp-js.flygon.net/#
一、使用函数构建抽象
原文:1 Building Abstractions with Functions
译者:飞龙
心灵的行为,其中它对简单的想法施加其力量,主要有以下三种:1.将几个简单的想法组合成一个复合的想法,从而形成所有复杂的想法。2.第二个是将两个想法,无论是简单的还是复杂的,放在一起,并将它们放在一起,以便一次看到它们,而不将它们合并成一个,从而获得它们所有的关系想法。3.第三个是将它们与实际存在的所有其他想法分开:这被称为抽象,从而形成所有的一般想法。
——约翰·洛克,《人类理解论》(1690)
我们将要研究计算过程的概念。计算过程是存在于计算机中的抽象实体。随着它们的发展,过程操纵其他抽象的东西,称为数据。过程的演变由一组称为程序的规则指导。人们创建程序来指导过程。实际上,我们用我们的咒语召唤计算机的精神。
计算过程确实很像巫师对精神的想法。它看不见,摸不着。它根本不是由物质组成的。然而,它是非常真实的。它可以进行智力工作。它可以回答问题。它可以通过在银行分发钱或控制工厂中的机器人手臂来影响世界。我们用来施法的程序就像巫师的咒语。它们是从奥秘和神秘的编程语言中的符号表达式中精心组成的,这些语言规定了我们希望我们的过程执行的任务。
计算过程在一个正确工作的计算机中精确和准确地执行程序。因此,像巫师的学徒一样,新手程序员必须学会理解和预料他们施法的后果。即使是程序中的小错误(通常称为bug)也可能产生复杂和意想不到的后果。
幸运的是,学习编程远比学习巫术危险得多,因为我们处理的精神被方便地以安全的方式包含在其中。然而,现实世界的编程需要谨慎、专业知识和智慧。例如,计算机辅助设计程序中的一个小错误可能导致飞机或大坝的灾难性崩溃,或者工业机器人的自我毁灭。
优秀的软件工程师有能力组织程序,以便他们可以相当确信所得到的过程将执行预期的任务。他们可以预先可视化系统的行为。他们知道如何构造程序,以便意想不到的问题不会导致灾难性后果,而当问题出现时,他们可以调试他们的程序。设计良好的计算系统,就像设计良好的汽车或核反应堆一样,都是以模块化的方式设计的,以便部件可以分别构建、更换和调试。
JavaScript 编程
我们需要一个适当的语言来描述过程,为此我们将使用编程语言 JavaScript。正如我们的日常思维通常用我们的母语(如英语、瑞典语或中文)表达一样,对数量现象的描述用数学符号表示,我们的过程思维将用 JavaScript 表示。JavaScript 于 1995 年开发,用作控制万维网浏览器行为的编程语言,通过嵌入在网页中的脚本。该语言最初由 Brendan Eich 构思,最初名为Mocha,后来更名为LiveScript,最终改名为 JavaScript。名称“JavaScript”是 Oracle Corporation 的商标。
尽管 JavaScript 最初是作为网页脚本语言而诞生的,但它是一种通用编程语言。JavaScript 解释器是一台执行 JavaScript 语言描述的过程的机器。第一个 JavaScript 解释器是由 Eich 在网景通信公司为网景导航器网页浏览器实现的。JavaScript 从 Scheme 和 Self 编程语言继承了其核心特性。Scheme 是 Lisp 的一个方言,并且曾被用作本书原始版本的编程语言。JavaScript 从 Scheme 继承了其最基本的设计原则,如词法作用域的一流函数和动态类型。
JavaScript 与其(最终)命名的语言 Java 只有表面上的相似之处;Java 和 JavaScript 都使用语言 C 的块结构。与通常使用编译到低级语言的 Java 和 C 相反,JavaScript 程序最初是由网页浏览器解释的。在网景导航器之后,其他网页浏览器提供了对该语言的解释器,包括微软的 Internet Explorer,其 JavaScript 版本称为JScript。JavaScript 在控制网页浏览器方面的流行性促使了一项标准化工作,最终导致了ECMAScript的产生。ECMAScript 标准的第一版由盖伊·刘易斯·斯蒂尔(Guy Lewis Steele Jr.)领导,并于 1997 年 6 月完成(ECMA 1997)。第六版,即 ECMAScript 2015,由艾伦·韦尔夫斯-布洛克(Allen Wirfs-Brock)领导,并于 2015 年 6 月被 ECMA 大会采纳(ECMA 2015)。
将 JavaScript 程序嵌入网页的做法鼓励了网页浏览器的开发人员实现 JavaScript 解释器。随着这些程序变得更加复杂,解释器在执行它们时变得更加高效,最终采用了诸如即时(JIT)编译等复杂的实现技术。截至本文撰写时(2021 年),大多数 JavaScript 程序都嵌入在网页中,并由浏览器解释,但 JavaScript 越来越多地被用作通用编程语言,使用诸如 Node.js 等系统。
ECMAScript 2015 拥有一系列功能,使其成为研究重要的编程构造和数据结构以及将它们与支持它们的语言特性相关联的绝佳媒介。它的词法作用域的一流函数及其通过 lambda 表达式的语法支持直接而简洁地访问函数抽象,动态类型允许适应保持接近 Scheme 原始状态。除了这些考虑之外,在 JavaScript 中编程非常有趣。
1.1 编程的元素
强大的编程语言不仅仅是指示计算机执行任务的手段。语言还作为一个框架,我们在其中组织关于过程的想法。因此,当我们描述一种语言时,我们应该特别关注语言提供的手段,用于将简单的想法组合成更复杂的想法。每种强大的语言都有三种机制来实现这一点:
-
原始表达式,代表语言关注的最简单的实体,
-
组合手段,通过这种手段,可以从更简单的元素构建复合元素,以及
-
抽象手段,通过这种手段,可以将复合元素命名并作为单元进行操作。
在编程中,我们处理两种元素:函数和数据。(后来我们会发现它们实际上并不那么不同。)非正式地说,数据是我们想要操作的“东西”,而函数是描述操作数据规则的描述。因此,任何强大的编程语言都应该能够描述原始数据和原始函数,并且应该有方法来组合和抽象函数和数据。
在本章中,我们只处理简单的数值数据,以便我们可以专注于构建函数的规则。¹在后面的章节中,我们将看到这些相同的规则允许我们构建函数来操作复合数据。
1.1.1 表达式
开始编程的一种简单方法是检查与 JavaScript 语言解释器的一些典型交互。您键入一个语句,解释器会通过显示其求值结果来做出响应。
您可能键入的一种语句是表达式语句,它由一个表达式后跟一个分号组成。一种原始表达式是数字。(更准确地说,您键入的表达式由表示十进制数字的数字组成。)如果您向 JavaScript 提供程序
486;解释器将通过打印²来做出响应
486表示数字的表达式可以与运算符(如+或*)结合,形成一个复合表达式,表示对这些数字应用相应原始函数的应用。例如,
137 + 349;
486
1000 - 334;
666
5 * 99;
495
10 / 4;
2.5
2.7 + 10;
12.7这样的表达式,其中包含其他表达式作为组成部分,被称为组合。由运算符符号在中间形成的组合,左右两侧是操作数表达式,被称为运算符组合。运算符组合的值是通过将运算符指定的函数应用于操作数的值来获得的。
将运算符放在操作数之间的约定称为中缀表示法。它遵循您在学校和日常生活中最熟悉的数学表示法。与数学一样,运算符组合可以是嵌套的,也就是说,它们可以有自身是运算符组合的操作数:
(3 * 5) + (10 - 6);
19通常情况下,括号用于分组运算符组合,以避免歧义。当省略括号时,JavaScript 也遵循通常的约定:乘法和除法比加法和减法更紧密地绑定。例如,
3 * 5 + 10 / 2;代表
(3 * 5) + (10 / 2);我们说*和/比+和-有更高的优先级。加法和减法的序列从左到右读取,乘法和除法的序列也是如此。因此,
1 - 5 / 2 * 4 + 3;代表
(1 - ((5 / 2) * 4)) + 3;我们说+、-、*和/是左结合的。
在原则上,这种嵌套的深度和 JavaScript 解释器可以求值的表达式的整体复杂性没有限制。我们人类可能会被仍然相对简单的表达式所困惑,比如
3 * 2 * (3 - 5 + 4) + 27 / 6 * 10;解释器会立即求值为 57。我们可以通过以以下形式编写这样的表达式来帮助自己
3 * 2 * (3 - 5 + 4)
+
27 / 6 * 10;以视觉上分隔表达式的主要组件。
即使是复杂的表达式,解释器始终以相同的基本循环运行:它读取用户键入的语句,求值语句,并打印结果。这种操作模式通常被称为解释器运行在读取-求值-打印循环中。特别要注意的是,不需要明确指示解释器打印语句的值。³
1.1.2 命名和环境
编程语言的一个关键方面是它提供了使用名称来引用计算对象的手段,我们的第一种手段是常量。我们说名称标识了一个值为对象的常量。
在 JavaScript 中,我们使用常量声明为常量命名。
const size = 2;使解释器将值 2 与名称size关联起来。⁴一旦名称size与数字 2 关联起来,我们可以通过名称引用值 2:
size;
2
5 * size;
10以下是对const的进一步使用示例:
const pi = 3.14159;
const radius = 10;
pi * radius * radius;
314.159
const circumference = 2 * pi * radius;
circumference;
62.8318常量声明是我们语言中最简单的抽象手段,因为它允许我们使用简单的名称来引用复合操作的结果,例如上面计算的circumference。一般来说,计算对象可能具有非常复杂的结构,要记住并重复它们的细节每次想要使用它们将会非常不方便。事实上,复杂的程序是通过逐步构建越来越复杂的计算对象而构建的。解释器使得这种逐步程序构建特别方便,因为名称-对象关联可以在连续的交互中逐步创建。这个特性鼓励程序的逐步开发和测试,并且在很大程度上负责 JavaScript 程序通常由大量相对简单的函数组成。
应该清楚的是,将值与名称关联并稍后检索这些值的可能性意味着解释器必须维护一种记忆,以跟踪名称-对象对。这种记忆称为环境(更确切地说是程序环境,因为我们将在后面看到,计算可能涉及多种不同的环境)。
1.1.3 求值运算符组合
在本章中,我们的一个目标是分离有关过程式思维的问题。例如,让我们考虑一下,在求值运算符组合时,解释器本身正在遵循一个过程。
-
要求值运算符组合,请执行以下操作:
-
1. 求值组合的操作数表达式。
-
2. 应用由运算符表示的函数到操作数的值。
-
即使这个简单的规则也说明了一般过程中的一些重要点。首先,观察到第一步规定,为了完成组合的求值过程,我们必须首先对组合的每个操作数执行求值过程。因此,求值规则在本质上是递归的;也就是说,它包括作为其步骤之一的需要调用规则本身。
注意递归的想法如何简洁地表达了在深度嵌套组合的情况下,否则将被视为一个相当复杂的过程。例如,求值
(2 + 4 * 6) * (3 + 12);需要将求值规则应用于四种不同的组合。我们可以通过将组合表示为树的形式来获得这个过程的图像,如下图所示。每个组合都由一个节点表示,其分支对应于从中衍生出的运算符和组合的操作数。终端节点(即没有从它们衍生出的分支的节点)表示运算符或数字。从树的角度来看求值,我们可以想象操作数的值从终端节点向上渗透,然后在更高的层次上组合。一般来说,我们将看到递归是一种处理分层、树状对象的非常强大的技术。事实上,“向上渗透值”形式的求值规则是一种称为树累积的一般过程的例子。
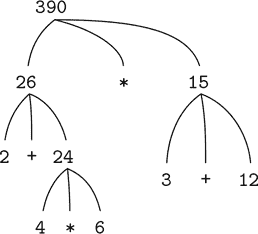
图 1.1 树表示,显示每个子表达式的值。
接下来,观察到第一步的重复应用使我们到达需要求值的点,不是组合,而是诸如数字或名称的原始表达式。我们通过规定以下来处理原始情况:
-
数字的值是它们所代表的数字,而
-
名称的值是环境中与这些名称关联的对象。
要注意的关键点是环境在确定表达式中名称的含义方面的作用。在 JavaScript 这样的交互式语言中,谈论表达式的值,比如x + 1,而不指定任何关于提供名称x含义的环境信息是没有意义的。正如我们将在第 3 章中看到的,环境的一般概念作为提供求值所发生的上下文将在我们理解程序执行方面发挥重要作用。
请注意,上面给出的求值规则不处理声明。例如,求值const x = 3;不会将等号=应用于两个参数,其中一个是名称x的值,另一个是 3,因为声明的目的恰好是将x与一个值关联起来。(也就是说,const x = 3;不是一个组合。)
const中的字母以粗体呈现,以表明它是 JavaScript 中的关键字。关键字具有特定的含义,因此不能用作名称。语句中的关键字或关键字组合指示 JavaScript 解释器以特殊方式处理语句。每种这样的语法形式都有其自己的求值规则。各种类型的语句和表达式(每种都有其关联的求值规则)构成了编程语言的语法。
1.1.4 复合函数
我们已经确定了 JavaScript 中必须出现的一些元素:
-
数字和算术运算是原始数据和函数。
-
组合的嵌套提供了一种组合操作的方法。
-
将名称与值关联的常量声明提供了有限的抽象手段。
现在我们将学习函数声明,这是一种更强大的抽象技术,通过它可以给复合操作命名,然后作为一个单元引用。
我们首先来看如何表达“平方”的概念。我们可以说,“对某物求平方,就是将其乘以自身。”在我们的语言中,这可以表达为
function square(x) {
return x * x;
}我们可以这样理解:
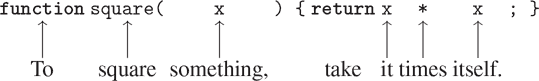
我们这里有一个复合函数,它被命名为square。该函数表示将某物乘以自身的操作。要被乘的东西被赋予一个本地名称x,它扮演的角色与自然语言中的代词相同。求值声明会创建这个复合函数,并将其与名称square关联起来。⁶
函数声明的最简单形式是
function name(parameters) { return expression; }名称是一个符号,用于将函数定义与环境关联起来。⁷ 参数是函数体内用于引用函数对应参数的名称。参数被括在括号内,并用逗号分隔,就像在应用被声明的函数时一样。在最简单的形式中,函数声明的函数体是一个单一的返回语句,⁸它由关键字return后跟将产生函数应用值的返回表达式组成,当参数被实际参数替换时,函数将被应用。与常量声明和表达式语句一样,返回语句以分号结束。
声明了square之后,我们现在可以在函数应用表达式中使用它,并使用分号将其转换为语句。
square(21);
441函数应用是——在操作符组合之后——我们遇到的将表达式组合成更大表达式的第二种组合。函数应用的一般形式是
function-expression(argument-expressions)应用的function-expression指定要应用于逗号分隔的argument-expressions的函数。为了求值函数应用,解释器遵循了与 1.1.3 节中描述的操作符组合的过程非常相似的过程。
-
要求值函数应用,执行以下操作:
-
1.求值应用的子表达式,即函数表达式和参数表达式。
-
2.将函数表达式的值应用于参数表达式的值。
-
square(2 + 5);
49在这里,参数表达式本身是一个复合表达式,操作符组合2 + 5。
square(square(3));
81当然,函数应用表达式也可以作为参数表达式。
我们还可以使用square作为定义其他函数的构建块。例如,x² + y²可以表示为
square(x) + square(y)我们可以轻松地声明一个名为sum_of_squares⁹的函数,它给定任意两个数字作为参数,产生它们的平方和:
function sum_of_squares(x, y) {
return square(x) + square(y);
}
sum_of_squares(3, 4);
25现在我们可以使用sum_of_squares作为构建更多函数的构建块:
function f(a) {
return sum_of_squares(a + 1, a * 2);
}
f(5);
136除了复合函数,任何 JavaScript 环境都提供了内置于解释器或从库加载的原始函数。除了由操作符提供的原始函数之外,本书中使用的 JavaScript 环境还包括其他原始函数,例如计算其参数的自然对数的函数math_log¹⁰。这些额外的原始函数与复合函数完全相同;求值应用math_log(1)的结果是数字 0。事实上,通过查看上面给出的sum_of_squares的定义,无法确定square是内置于解释器中,从库加载,还是定义为复合函数。
1.1.5 函数应用的替换模型
为了求值函数应用,解释器遵循 1.1.4 节中描述的过程。也就是说,解释器求值应用的元素,并将函数(即应用的函数表达式的值)应用于参数(即应用的参数表达式的值)。
我们可以假设原始函数的应用由解释器或库处理。对于复合函数,应用过程如下:
- 要将复合函数应用于参数,求值函数的返回表达式,其中每个参数都替换为相应的参数。¹¹
为了说明这个过程,让我们求值应用
f(5)其中f是 1.1.4 节中声明的函数。我们首先检索f的返回表达式:
sum_of_squares(a + 1, a * 2)然后我们用参数 5 替换参数a:
sum_of_squares(5 + 1, 5 * 2)因此,问题简化为求值具有两个参数和函数表达式sum_of_squares的应用。求值此应用涉及三个子问题。我们必须求值函数表达式以获得要应用的函数,并且我们必须求值参数表达式以获得参数。现在5 + 1产生 6,5 * 2产生 10,因此我们必须将sum_of_squares函数应用于 6 和 10。这些值替换为sum_of_squares的主体中的参数x和y,将表达式简化为
square(6) + square(10)如果我们使用square的声明,这将简化为
(6 * 6) + (10 * 10)这通过乘法减少到
36 + 100最后
136我们刚刚描述的过程称为函数应用的替换模型。就本章中的函数而言,它可以被视为确定函数应用“含义”的模型。但是,有两点应该强调:
-
替换的目的是帮助我们思考函数应用,而不是提供解释器实际工作方式的描述。典型的解释器不会通过操纵函数的文本来替换参数的值来求值函数应用。实际上,“替换”是通过使用参数的本地环境来完成的。当我们在第 3 和第 4 章中详细研究解释器的实现时,我们将更全面地讨论这一点。
-
在本书的过程中,我们将提出一系列越来越复杂的解释器工作模型,最终在第 5 章中实现一个解释器和编译器的完整实现。替换模型只是这些模型中的第一个,是一种开始正式思考求值过程的方式。一般来说,在科学和工程中建模现象时,我们从简化的、不完整的模型开始。随着我们更详细地研究事物,这些简单的模型变得不足以满足需求,必须被更精细的模型所取代。替换模型也不例外。特别是,当我们在第 3 章中讨论使用带有“可变数据”的函数时,我们将看到替换模型崩溃了,必须被更复杂的函数应用模型所取代。
应用顺序与正常顺序
根据 1.1.4 节中给出的求值描述,解释器首先求值函数和参数表达式,然后将得到的函数应用于得到的参数。这不是执行求值的唯一方法。另一种求值模型将不会求值参数,直到它们的值被需要为止。相反,它首先用参数表达式替换参数,直到获得只涉及运算符和原始函数的表达式,然后执行求值。如果我们使用这种方法,那么
f(5)将按照扩展的顺序进行。
sum_of_squares(5 + 1, 5 * 2)
square(5 + 1) + square(5 * 2)
(5 + 1) * (5 + 1) + (5 * 2) * (5 * 2)随后是减少
6 * 6 + 10 * 10
36 + 100
136这与我们先前的求值模型得出相同的答案,但过程是不同的。特别是,5 + 1和5 * 2的求值在这里分别执行两次,对应于表达式的减少
x * x分别用5 + 1和5 * 2替换x。
这种替代的“完全展开然后减少”求值方法被称为正常顺序求值,与解释器实际使用的“求值参数然后应用”方法相对应,后者被称为应用顺序求值。可以证明,对于可以使用替换进行建模的函数应用(包括本书前两章中的所有函数)并产生合法值,正常顺序和应用顺序求值会产生相同的值。(参见练习 1.5,其中有一个“非法”值的例子,正常顺序和应用顺序求值得出的结果不同。)
JavaScript 使用应用顺序求值,部分原因是为了避免像上面所示的5 + 1和5 * 2这样的表达式的多次求值所获得的额外效率,更重要的是,当我们离开可以通过替换建模的函数领域时,正常顺序求值变得更加复杂。另一方面,正常顺序求值可以是一个非常有价值的工具,我们将在第 3 和第 4 章中探讨它的一些影响。
1.1.6 条件表达式和谓词
到目前为止,我们可以定义的函数类的表达能力非常有限,因为我们无法进行测试并根据测试结果执行不同的操作。例如,我们无法声明一个通过测试数字是否为非负来计算绝对值的函数,并根据规则分别采取不同的操作
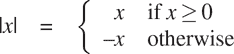
这个结构是一个案例分析,并且可以用 JavaScript 的条件表达式来写成
function abs(x) {
return x >= 0 ? x : - x;
}这可以用英语表达为“如果x大于或等于零,则返回x;否则返回–x。”条件表达式的一般形式是
predicate ? consequent-expression : alternative-expression条件表达式以predicate开头,即其值为 JavaScript 中的两个特殊布尔值true或false的表达式。原始布尔表达式true和false分别以布尔值true和false进行简单求值。predicate后面跟着一个问号,consequent-expression,一个冒号,最后是alternative-expression。
为了求值条件表达式,解释器首先求值表达式的谓词。如果谓词求值为true,解释器求值结果表达式并返回其值作为条件表达式的值。如果谓词求值为false,它求值替代表达式并返回其值作为条件表达式的值。
单词“谓词”用于返回true或false的运算符和函数,以及求值为true或false的表达式。绝对值函数abs使用原始谓词>=,这是一个接受两个数字作为参数并测试第一个数字是否大于或等于第二个数字的运算符,根据情况返回true或false。
如果我们更喜欢单独处理零的情况,我们可以通过写一个函数来指定计算一个数字的绝对值
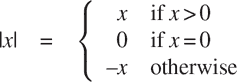
在 JavaScript 中,我们通过在其他条件表达式中将替代表达式作为条件表达式的替代表达式来嵌套条件表达式来表示具有多个情况的案例分析:
function abs(x) {
return x > 0
? x
: x === 0
? 0
: - x;
}括号不需要在替代表达式x === 0 ? 0 : - x周围,因为条件表达式的语法形式是右结合的。解释器忽略空格和换行符,这里插入是为了可读性,以使?和:在案例分析的第一个谓词下对齐。案例分析的一般形式是
p[1]
? e[1]
: p[2]
? e[2]
⁝
: p[n]
? e[n]
: final-alternative-expression我们将谓词p[i]和其结果表达式e[i]一起称为子句。案例分析可以看作是一系列子句,后跟最终的替代表达式。根据条件表达式的求值,案例分析首先求值谓词p[1]。如果它的值为false,则求值p[2]。如果p[2]的值也为false,则求值p[3]。这个过程一直持续,直到找到一个值为true的谓词,此时解释器将返回子句的相应结果表达式e的值作为案例分析的值。如果没有找到任何p为true,则案例分析的值是最终替代表达式的值。
除了应用于数字的原始谓词,如>=、>、<、<=、===和!==之外,还有逻辑组合操作,它们使我们能够构造复合谓词。最常用的三个是这些:
-
表达式[1] && 表达式[2]这个操作表示逻辑连接,大致意思与英语单词“and”相同。这种语法形式是语法糖,用于
表达式[1] ? 表达式[2] : false。 -
表达式[1] 表达式[2]这个操作表示逻辑析取,大致意思与英语单词“or”相同。这种语法形式是语法糖。
表达式[1] ? true : 表达式[2]。 -
! 表达式这个操作表示逻辑否定,大致意思与英语单词“not”相同。当表达式求值为
false时,表达式的值为true,当表达式求值为true时,表达式的值为false。
注意&&和||是语法形式,而不是运算符;它们的右侧表达式并不总是被求值。另一方面,运算符!遵循第 1.1.3 节的求值规则。它是一个 一元 运算符,这意味着它只接受一个参数,而迄今为止讨论的算术运算符和原始谓词都是 二元 运算符,接受两个参数。运算符!在其参数之前;我们称它为 前缀运算符。另一个前缀运算符是数值否定运算符,其示例是上面的abs函数中的表达式- x。
作为这些谓词如何使用的一个例子,表达一个数x在范围5 < x < 10中的条件可以表示为
x > 5 && x < 10&&的语法形式的优先级低于比较运算符>和<,条件表达式的语法形式... ?... :...的优先级低于迄今为止我们遇到的任何其他运算符,这是我们在上面的abs函数中使用的一个特性。
作为另一个例子,我们可以声明一个谓词,测试一个数字是否大于或等于另一个数字
function greater_or_equal(x, y) {
return x > y || x === y;
}或者作为
function greater_or_equal(x, y) {
return ! (x < y);
}函数greater_or_equal应用于两个数字时,与运算符>=的行为相同。一元运算符的优先级高于二元运算符,这使得这个例子中的括号是必需的。
练习 1.1
下面是一系列的陈述。解释器对每个陈述的响应中打印的结果是什么?假设要按照呈现的顺序进行求值。
10;
5 + 3 + 4;
9 - 1;
6 / 2;
2 * 4 + (4 - 6);
const a = 3;
const b = a + 1;
a + b + a * b;
a === b;
b > a && b < a * b ? b : a;
a === 4
? 6
: b === 4
? 6 + 7 + a
: 25;
2 + (b > a ? b : a);
(a > b
? a
: a < b
? b
: -1)
*
(a + 1);最后两个陈述中条件表达式周围的括号是必需的,因为条件表达式的语法形式的优先级低于算术运算符+和*。
练习 1.2
将以下表达式翻译成 JavaScript
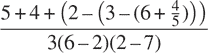
练习 1.3
声明一个以三个数字作为参数并返回两个较大数字的平方和的函数。
练习 1.4
注意我们的求值模型允许应用其函数表达式为复合表达式的应用。使用这一观察来描述a_plus_abs_b的行为:
function plus(a, b) { return a + b; }
function minus(a, b) { return a - b; }
function a_plus_abs_b(a, b) {
return (b >= 0 ? plus : minus)(a, b);
}练习 1.5
Ben Bitdiddle 发明了一个测试,以确定他所面对的解释器是使用应用序求值还是正则序求值。他声明了以下两个函数:
function p() { return p(); }
function test(x, y) {
return x === 0 ? 0 : y;
}然后他求值了这个陈述
test(0, p());Ben 会观察到使用应用序求值的解释器会有什么行为?他会观察到使用正则序求值的解释器会有什么行为?解释你的答案。(假设条件表达式的求值规则在解释器使用正常或应用序时是相同的:谓词表达式首先被求值,结果决定是求值结果还是替代表达式。)
1.1.7 例子:牛顿法求平方根
如上所述,函数很像普通的数学函数。它们指定由一个或多个参数确定的值。但是数学函数和计算机函数之间有一个重要的区别。计算机函数必须是有效的。
作为一个例子,考虑计算平方根的问题。我们可以定义平方根函数为
√x = y,满足y ≥ 0和y² = x
这描述了一个完全合法的数学函数。我们可以用它来识别一个数字是否是另一个数字的平方根,或者推导关于平方根的一般事实。另一方面,这个定义并不描述一个计算机函数。事实上,它几乎没有告诉我们如何实际找到给定数字的平方根。重新用伪 JavaScript 重新表述这个定义也不会有所帮助:
function sqrt(x) {
return the y with y >= 0 && square(y) === x;
}这只是在回避问题。
数学函数和计算机函数之间的对比反映了描述事物属性和描述如何做事物的一般区别,有时也被称为声明性知识和命令性知识之间的区别。在数学中,我们通常关注声明性(是什么)描述,而在计算机科学中,我们通常关注命令性(如何)描述。¹⁷
如何计算平方根?最常见的方法是使用牛顿的迭代逼近法,该方法指出,每当我们对数字x的平方根的值有一个猜测y时,我们可以通过对y和x / y进行平均来进行简单的操作,得到一个更好的猜测(更接近实际平方根)。¹⁸ 例如,我们可以计算 2 的平方根如下。假设我们的初始猜测是 1:
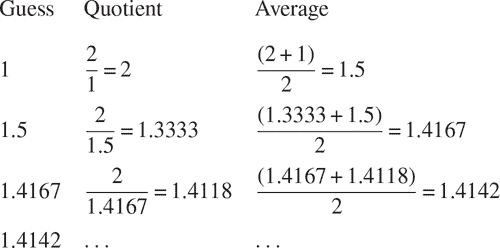
继续这个过程,我们得到越来越好的近似值。
现在让我们用函数的术语来形式化这个过程。我们从被开方数(我们试图计算其平方根的数字)的值和猜测的值开始。如果猜测对我们的目的来说足够好,我们就完成了;如果不是,我们必须用一个改进的猜测重复这个过程。我们将这个基本策略写成一个函数:
function sqrt_iter(guess, x) {
return is_good_enough(guess, x)
? guess
: sqrt_iter(improve(guess, x), x);
}通过将猜测与被开方数和旧猜测的商进行平均来改进猜测:
function improve(guess, x) {
return average(guess, x / guess);
}其中
function average(x, y) {
return (x + y) / 2;
}我们还必须说明“足够好”的含义。以下内容可以用于说明,但实际上并不是一个非常好的测试。(见练习 1.7。)这个想法是改进答案,直到它足够接近,以至于它的平方与被开方数之间的差异小于预定的容差(这里是 0.001):¹⁹
function is_good_enough(guess, x) {
return abs(square(guess) - x) < 0.001;
}最后,我们需要一种开始的方法。例如,我们总是可以猜测任何数字的平方根是 1:
function sqrt(x) {
return sqrt_iter(1, x);
}如果我们将这些声明输入解释器,我们可以像使用任何函数一样使用sqrt:
sqrt(9);
3.00009155413138
sqrt(100 + 37);
11.704699917758145
sqrt(sqrt(2) + sqrt(3));
1.7739279023207892
square(sqrt(1000));
1000.000369924366sqrt程序还说明了我们迄今为止介绍的简单函数语言足以编写任何纯数值程序,这些程序可以在 C 或 Pascal 中编写。这可能看起来令人惊讶,因为我们的语言中没有包括任何迭代(循环)结构,指导计算机一遍又一遍地做某事。另一方面,函数sqrt_iter演示了如何使用除了普通调用函数的能力之外,还可以实现迭代。²⁰
练习 1.6
Alyssa P. Hacker 不喜欢条件表达式的语法,涉及到字符?和:。“为什么我不能只声明一个普通的条件函数,其应用方式就像条件表达式一样呢?”她问道。²¹ Alyssa 的朋友 Eva Lu Ator 声称这确实可以做到,并声明了一个conditional函数如下:
function conditional(predicate, then_clause, else_clause) {
return predicate ? then_clause : else_clause;
}Eva 为 Alyssa 演示程序:
conditional(2 === 3, 0, 5);
`5`
conditional(1 === 1, 0, 5);
`0`高兴的是,Alyssa 使用conditional来重写平方根程序:
function sqrt_iter(guess, x) {
return conditional(is_good_enough(guess, x),
guess,
sqrt_iter(improve(guess, x),
x));
}当 Alyssa 尝试使用这个方法来计算平方根时会发生什么?解释。
练习 1.7
用于计算平方根的is_good_enough测试对于找到非常小的数字的平方根不会非常有效。此外,在实际计算机中,算术运算几乎总是以有限的精度进行。这使得我们的测试对于非常大的数字是不够的。解释这些陈述,并举例说明测试对于小数字和大数字的失败。实现is_good_enough的另一种策略是观察guess从一次迭代到下一次迭代的变化,并在变化是猜测的一个非常小的分数时停止。设计一个使用这种结束测试的平方根函数。这对于小数字和大数字效果更好吗?
练习 1.8
牛顿的立方根方法是基于这样一个事实:如果y是x的立方根的近似值,那么更好的近似值由这个值给出
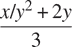
使用这个公式来实现一个类似于平方根函数的立方根函数。(在第 1.3.4 节中,我们将看到如何将牛顿方法作为这些平方根和立方根函数的抽象来实现。)
1.1.8 函数作为黑盒抽象
函数sqrt是我们第一个例子,它是由一组相互定义的函数定义的过程。请注意,sqrt_iter的声明是递归的;也就是说,函数是根据自身定义的。能够根据自身定义函数的想法可能会让人感到不安;可能不清楚这样的“循环”定义到底如何有意义,更不用说指定计算机执行的明确定义的过程了。这将在第 1.2 节中更加仔细地讨论。但首先让我们考虑一下sqrt示例所说明的一些其他重要点。
注意,计算平方根的问题自然地分解为许多子问题:如何判断猜测是否足够好,如何改进猜测,等等。每个任务都由一个单独的函数完成。整个sqrt程序可以被看作是一组函数(在图 1.2 中显示),它反映了将问题分解为子问题的过程。
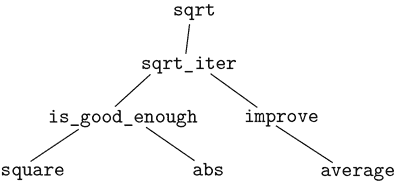
图 1.2 sqrt程序的功能分解。
这种分解策略的重要性不仅仅在于将程序分成部分。毕竟,我们可以将任何大型程序分成部分——前十行,接下来的十行,再接下来的十行,依此类推。相反,关键在于每个函数都能够完成一个可识别的任务,可以用作定义其他函数的模块。例如,当我们根据square定义is_good_enough函数时,我们可以将square函数视为“黑盒”。我们当时并不关心函数如何计算其结果,只关心它计算平方的事实。计算平方的细节可以被抑制,以便在以后考虑。实际上,就is_good_enough函数而言,square不完全是一个函数,而是一个函数的抽象,所谓的函数抽象。在这个抽象级别上,任何计算平方的函数都是一样好的。
因此,仅考虑它们返回的值,下面两个平方一个数字的函数应该是无法区分的。每个函数都接受一个数字参数,并将该数字的平方作为值返回。
function square(x) {
return x * x;
}
function square(x) {
return math_exp(double(math_log(x)));
}
function double(x) {
return x + x;
}因此,函数应该能够抑制细节。函数的用户可能并没有自己编写函数,而是从另一个程序员那里获得的一个黑盒。用户不需要知道函数的实现方式就能使用它。
本地名称
函数实现的一个细节不应该影响函数的用户,那就是实现者对函数参数的名称的选择。因此,以下函数不应该有区别:
function square(x) {
return x * x;
}
function square(y) {
return y * y;
}这个原则——函数的含义应该与其作者使用的参数名称无关——表面上似乎是不言自明的,但其后果是深远的。最简单的结果是函数的参数名称必须局限于函数体内。例如,在我们的平方根函数的is_good_enough声明中,我们使用了square:
function is_good_enough(guess, x) {
return abs(square(guess) - x) < 0.001;
}is_good_enough的作者的意图是确定第一个参数的平方是否在给定的公差范围内与第二个参数相匹配。我们看到is_good_enough的作者使用名称guess来指代第一个参数,x指代第二个参数。square的参数是guess。如果square的作者使用x(如上所述)来指代该参数,我们可以看到is_good_enough中的x必须是与square中的不同的x。运行函数square不应该影响is_good_enough使用的x的值,因为is_good_enough在square计算完成后可能需要该值。
如果参数不是局限于各自函数体的局部变量,那么square中的参数x可能会与is_good_enough中的参数x混淆,而is_good_enough的行为将取决于我们使用的square的版本。因此,square将不会是我们所期望的黑匣子。
函数的参数在函数声明中有一个非常特殊的角色,即参数的名称是什么并不重要。这样的名称称为绑定,我们说函数声明绑定了它的参数。如果一个名称没有被绑定,我们说它是自由的。一个绑定声明名称的语句集被称为该名称的作用域。在函数声明中,作为函数参数声明的绑定名称具有函数体作为它们的作用域。
在上面的is_good_enough声明中,guess和x是绑定的名称,但abs和square是自由的。is_good_enough的含义应该与我们为guess和x选择的名称无关,只要它们与abs和square不同即可。(如果我们将guess重命名为abs,我们将通过捕获名称abs引入一个错误。它将从自由变为绑定。)然而,is_good_enough的含义并不独立于其自由名称的选择。然而,它肯定取决于(不包括在此声明中的)名称abs是指计算数字的绝对值的函数。如果我们在其声明中用math_cos(原始余弦函数)替换abs,is_good_enough将计算一个不同的函数。
内部声明和块结构
到目前为止,我们已经有一种名称隔离的方式:函数的参数是局限于函数体的。求平方根的程序展示了我们希望控制名称使用的另一种方式。现有的程序由独立的函数组成:
function sqrt(x) {
return sqrt_iter(1, x);
}
function sqrt_iter(guess, x) {
return is_good_enough(guess, x)
? guess
: sqrt_iter(improve(guess, x), x);
}
function is_good_enough(guess, x) {
return abs(square(guess) - x) < 0.001;
}
function improve(guess, x) {
return average(guess, x / guess);
}这个程序的问题在于,对于sqrt的用户来说,唯一重要的函数是sqrt。其他函数(sqrt_iter,is_good_enough和improve)只会混淆他们的思维。他们可能不会在另一个程序中声明任何名为is_good_enough的其他函数,以便与求平方根程序一起工作,因为sqrt需要它。这个问题在由许多独立程序员构建大型系统时尤为严重。例如,在构建大型数值函数库时,许多数值函数是作为连续逼近计算的,因此可能有名为is_good_enough和improve的辅助函数。我们希望将子函数局部化,将它们隐藏在sqrt内部,以便sqrt可以与其他连续逼近并存,每个都有自己的私有is_good_enough函数。
为了实现这一点,我们允许函数具有局部于该函数的内部声明。例如,在求平方根的问题中,我们可以写
function sqrt(x) {
function is_good_enough(guess, x) {
return abs(square(guess) - x) < 0.001;
}
function improve(guess, x) {
return average(guess, x / guess);
}
function sqrt_iter(guess, x) {
return is_good_enough(guess, x)
? guess
: sqrt_iter(improve(guess, x), x);
}
return sqrt_iter(1, x);
}任何匹配的大括号对都指定了一个块,并且块内的声明对该块是局部的。这种声明的嵌套,称为块结构,基本上是最简单的名称封装问题的正确解决方案。但这里潜在的想法更好。除了内部化辅助函数的声明外,我们还可以简化它们。由于x在sqrt的声明中被绑定,因此在sqrt内部声明的is_good_enough、improve和sqrt_iter函数在x的作用域内。因此,不需要显式地将x传递给这些函数中的每一个。相反,我们允许x在内部声明中成为一个自由名称,如下所示。然后,x从调用封闭函数sqrt的参数中获取其值。这种规则称为词法作用域。²⁴
function sqrt(x) {
function is_good_enough(guess) {
return abs(square(guess) - x) < 0.001;
}
function improve(guess) {
return average(guess, x / guess);
}
function sqrt_iter(guess) {
return is_good_enough(guess)
? guess
: sqrt_iter(improve(guess));
}
return sqrt_iter(1);
}我们将广泛使用块结构来帮助我们将大型程序分解为可处理的部分。²⁵ 块结构的概念起源于编程语言 Algol 60。它出现在大多数高级编程语言中,是帮助组织大型程序构建的重要工具。
1.2 函数及其生成的过程
我们现在已经考虑了编程的元素:我们使用了原始算术运算,我们组合了这些运算,并通过将它们声明为复合函数来抽象化这些复合运算。但这还不足以使我们能够说我们知道如何编程。我们的情况类似于学会了国际象棋中棋子如何移动的规则,但对典型的开局、战术或策略一无所知的人。就像初学国际象棋的人一样,我们还不知道领域中的常见使用模式。我们缺乏哪些着法是值得做的(哪些函数值得声明)的知识。我们缺乏预测做出着法(执行函数)后的后果的经验。
能够可视化所考虑行动的后果对于成为专业程序员至关重要,就像在任何综合的创造性活动中一样。例如,要成为专业摄影师,必须学会如何观察一个场景,并知道每个区域在曝光和处理选项的每种可能选择下在打印品上会显得多暗。只有这样,才能向后推理,规划构图、光线、曝光和处理,以获得期望的效果。编程也是如此,我们在规划进程采取的行动,并通过程序控制进程。要成为专家,我们必须学会可视化各种类型函数生成的过程。只有在我们培养了这样的技能之后,才能学会可靠地构建表现出所需行为的程序。
函数是计算过程的局部演变的模式。它指定了过程的每个阶段是如何建立在前一个阶段之上的。我们希望能够对由函数指定局部演变的过程的整体或全局行为做出陈述。这在一般情况下非常难以做到,但我们至少可以尝试描述一些典型的过程演变模式。
在本节中,我们将研究一些简单函数生成的常见“形状”。我们还将调查这些过程消耗时间和空间等重要计算资源的速率。我们将考虑的函数非常简单。它们的作用类似于摄影中的测试图案:作为过度简化的原型模式,而不是实际示例。
1.2.1 线性递归和迭代
我们首先考虑阶乘函数的定义。
n != n · (n – 1) *·* (n – 2) ... 3 · 2 · 1计算阶乘有很多方法。一种方法是利用这样的观察:对于任何正整数n,n!等于n乘以(n – 1)!:
n! = n · [(n – 1) · (n – 2) ... 3 · 2 · 1] = n · (n – 1)!因此,我们可以通过计算(n – 1)!并将结果乘以n来计算n!。如果我们添加规定 1! 等于 1,这一观察直接转化为计算机函数:
function factorial(n) {
return n === 1
? 1
: n * factorial(n - 1);
}我们可以使用第 1.1.5 节的替换模型来观察这个函数计算6!的过程,如图 1.3 所示。

图 1.3 计算 6! 的线性递归过程。
现在让我们以不同的角度来计算阶乘。我们可以通过指定首先将 1 乘以 2,然后将结果乘以 3,然后乘以 4,依此类推,直到达到n,来描述计算n!的规则。更正式地说,我们保持一个运行乘积,以及一个从 1 计数到n的计数器。我们可以通过以下规则描述计算过程:
product ← counter · product
counter ← counter + 1并规定当计数器超过n时,n!是乘积的值。
再次,我们可以将我们的描述重新构造为计算阶乘的函数:²⁶
function factorial(n) {
return fact_iter(1, 1, n);
}
function fact_iter(product, counter, max_count) {
return counter > max_count
? product
: fact_iter(counter * product,
counter + 1,
max_count);
}与之前一样,我们可以使用替换模型来可视化计算 6! 的过程,如图 1.4 所示。

图 1.4 计算 6! 的线性迭代过程。
比较这两个过程。从某种角度来看,它们似乎几乎没有什么不同。两者都在相同的域上计算相同的数学函数,并且每个都需要与n成比例的步骤来计算n!。事实上,这两个过程甚至执行相同的乘法序列,得到相同的部分积序列。另一方面,当我们考虑这两个过程的“形状”时,我们发现它们的演变方式完全不同。
考虑第一个过程。替换模型显示了一个扩展后跟着收缩的形状,如图 1.3 中的箭头所示。扩展发生在过程构建一系列延迟操作(在本例中是一系列乘法)时。收缩发生在实际执行操作时。这种过程,以一系列延迟操作为特征,被称为递归过程。执行这个过程需要解释器跟踪稍后要执行的操作。在计算n!时,延迟乘法的链的长度,因此需要跟踪它的信息量,与步骤数量一样,随n线性增长(与n成比例)。这样的过程被称为线性递归过程。
相比之下,第二个过程不会增长和缩小。在每一步中,无论n是多少,我们都只需要跟踪名称product、counter和max_count的当前值。我们称这个过程为迭代过程。一般来说,迭代过程是指其状态可以由固定数量的状态变量以及描述状态变量如何在过程从一个状态转移到另一个状态时更新的固定规则以及(可选的)结束测试来总结。在计算n!时,所需的步骤数量随n增长而线性增长。这样的过程被称为线性迭代过程。
两个过程之间的对比可以从另一个角度看出。在迭代的情况下,状态变量提供了在任何时候过程状态的完整描述。如果我们在步骤之间停止计算,只需向解释器提供三个状态变量的值,就可以恢复计算。而在递归过程中则不然。在这种情况下,还有一些额外的“隐藏”信息,由解释器维护,不包含在状态变量中,它指示了在处理延迟操作链时的“位置”。链越长,就必须维护的信息就越多。
在对比迭代和递归时,我们必须小心,不要混淆递归过程的概念和递归函数的概念。当我们将一个函数描述为递归时,我们指的是函数声明引用(直接或间接)函数本身的语法事实。但是当我们描述一个遵循某种模式的过程时,比如说线性递归,我们说的是过程如何演变,而不是函数的语法如何编写。将递归函数fact_iter称为生成迭代过程可能看起来令人不安。然而,这个过程确实是迭代的:它的状态完全由它的三个状态变量捕获,解释器只需要跟踪三个名称就能执行这个过程。
区分过程和函数可能令人困惑的一个原因是,大多数常见语言的实现(包括 C、Java 和 Python)都是设计成这样的方式,即任何递归函数的解释都会消耗随着函数调用次数增加而增长的内存,即使所描述的过程原则上是迭代的。因此,这些语言只能通过专门的“循环结构”(如do、repeat、until、for和while)来描述迭代过程。我们将在第 5 章中考虑的 JavaScript 实现不具有这个缺陷。即使迭代过程是由递归函数描述的,它也将在恒定空间中执行迭代过程。具有这种属性的实现被称为尾递归。使用尾递归实现,迭代可以使用普通的函数调用机制来表达,因此特殊的迭代结构只有作为语法糖才有用。
练习 1.9
以下两个函数中的每一个都定义了一个方法,用函数inc来增加其参数 1,和函数dec来减少其参数 1,来实现两个正整数的加法。
function plus(a, b) {
return a === 0 ? b : inc(plus(dec(a), b));
}
function plus(a, b) {
return a === 0 ? b : plus(dec(a), inc(b));
}使用替换模型,说明每个函数生成的过程在求值plus(4, 5);时。这些过程是迭代的还是递归的?
练习 1.10
以下函数计算了一个称为 Ackermann 函数的数学函数。
function A(x, y) {
return y === 0
? 0
: x === 0
? 2 * y
: y === 1
? 2
: A(x - 1, A(x, y - 1));
}以下语句的值是多少?
A(1, 10);
A(2, 4);
A(3, 3);考虑以下函数,其中A是上面声明的函数:
function f(n) {
return A(0, n);
}
function g(n) {
return A(1, n);
}
function h(n) {
return A(2, n);
}
function k(n) {
return 5 * n * n;
}给出函数f,g和h的简洁数学定义,用于正整数值n。例如,k(n)计算5n²。
1.2.2 树递归
另一种常见的计算模式称为树递归。例如,考虑计算斐波那契数列,其中每个数字是前两个数字的和:
0, 1, 1, 2, 3, 5, 8, 13, 21, ...一般来说,斐波那契数可以通过以下规则定义
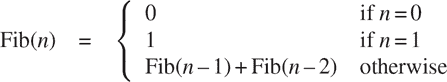
我们可以立即将这个定义转化为一个递归函数,用于计算斐波那契数:
function fib(n) {
return n === 0
? 0
: n === 1
? 1
: fib(n - 1) + fib(n - 2);
}考虑这个计算的模式。要计算fib(5),我们计算fib(4)和fib(3)。要计算fib(4),我们计算fib(3)和fib(2)。一般来说,演变的过程看起来像一棵树,如图 1.5 所示。注意到在每个级别(除了底部)分支分成两个,这反映了fib函数每次被调用时调用自身两次的事实。
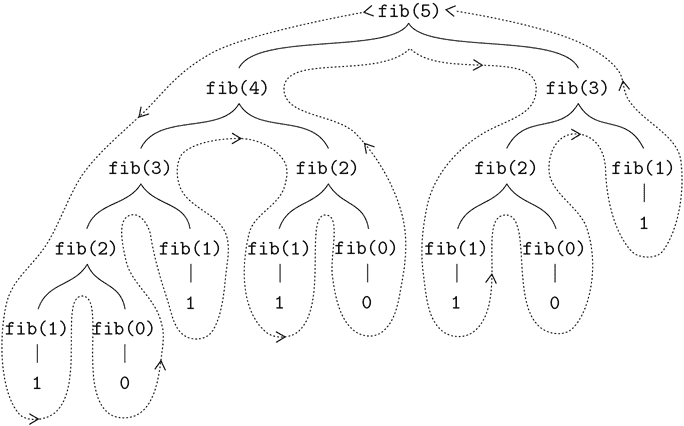
图 1.5 计算fib(5)时生成的树递归过程。
这个函数作为一个典型的树递归很有启发性,但它是计算斐波那契数的一种可怕的方式,因为它做了很多冗余的计算。注意在图 1.5 中,fib(3)的整个计算——几乎一半的工作——是重复的。事实上,不难证明函数将计算fib(1)或fib(0)(通常情况下上述树中的叶子数)的次数恰好是Fib(n + 1)。为了了解这有多糟糕,可以证明Fib(n)的值随着n的增长呈指数增长。更准确地说(见练习 1.13),Fib(n)是最接近ϕⁿ/√5的整数,其中
ϕ = (1 + √5)/2 ≈ 1.6180是黄金比例,满足方程
ϕ² = ϕ + 1因此,这个过程所需的步骤数随着输入的增长呈指数增长。另一方面,所需的空间只是线性增长,因为我们只需要在计算的任何时候跟踪树中在我们上面的哪些节点。一般来说,树递归过程所需的步骤数将与树中的节点数成正比,而所需的空间将与树的最大深度成正比。
我们还可以制定一个迭代的过程来计算斐波那契数。这个想法是使用一对整数a和b,初始化为Fib(1) = 1和Fib(0) = 0,并反复应用同时的转换
a ← a + b
b ← a不难证明,经过这种转换n次后,a和b分别等于Fib(n + 1)和Fib(n)。因此,我们可以使用以下函数迭代地计算斐波那契数
function fib(n) {
return fib_iter(1, 0, n);
}
function fib_iter(a, b, count) {
return count === 0
? b
: fib_iter(a + b, a, count - 1);
}这种计算Fib(n)的第二种方法是线性迭代。这两种方法所需的步骤数的差异——一个与n成正比,一个与Fib(n)本身一样快地增长——是巨大的,即使对于小的输入也是如此。
我们不应该因此得出树递归过程是无用的结论。当我们考虑操作层次结构化数据而不是数字的过程时,我们会发现树递归是一种自然而强大的工具。³⁰但即使在数值运算中,树递归过程也可以帮助我们理解和设计程序。例如,尽管第一个fib函数比第二个函数效率低得多,但它更直接,几乎只是斐波那契数列定义的 JavaScript 翻译。要制定迭代算法,需要注意到计算可以重塑为具有三个状态变量的迭代。
例子:找零
只需要一点巧妙就能想出迭代的斐波那契算法。相比之下,考虑以下问题:我们有多少种不同的方法可以找零 1.00 美元(100 美分),给定半美元、25 美分、10 美分、5 美分和 1 美分的硬币(分别为 50 美分、25 美分、10 美分、5 美分和 1 美分)?更一般地,我们能否编写一个函数来计算任意给定金额的找零方式?
这个问题有一个简单的解决方案,作为一个递归函数。假设我们把可用的硬币类型按照某种顺序排列。那么以下关系成立:
使用n种硬币来改变金额a的方式数等于
-
使用除第一种硬币之外的所有硬币来改变金额
a的方式,再加上 -
使用所有
n种硬币来改变金额a - d的方式,其中d是第一种硬币的面额。
要看到这是为什么,观察一下找零的方式可以分为两组:那些不使用第一种硬币的和那些使用的。因此,某个金额的找零方式的总数等于不使用第一种硬币的金额的找零方式的数量,加上假设我们使用第一种硬币的找零方式的数量。但后者的数量等于使用第一种硬币后剩下的金额的找零方式的数量。
因此,我们可以递归地将改变给定金额的问题减少到改变较小金额或使用更少种类的硬币的问题。仔细考虑这个减少规则,并让自己相信,我们可以用它来描述一个算法,如果我们指定以下退化情况:³¹
-
如果
a恰好为 0,我们应该将其视为 1 种找零的方式。 -
如果
a小于 0,我们应该将其视为 0 种找零的方式。 -
如果
n为 0,我们应该将其视为 0 种找零的方式。
我们可以很容易地将这个描述转化为一个递归函数:
function count_change(amount) {
return cc(amount, 5);
}
function cc(amount, kinds_of_coins) {
return amount === 0
? 1
: amount < 0 || kinds_of_coins === 0
? 0
: cc(amount, kinds_of_coins - 1)
+
cc(amount - first_denomination(kinds_of_coins),
kinds_of_coins);
}
function first_denomination(kinds_of_coins) {
return kinds_of_coins === 1 ? 1
: kinds_of_coins === 2 ? 5
: kinds_of_coins === 3 ? 10
: kinds_of_coins === 4 ? 25
: kinds_of_coins === 5 ? 50
: 0;
}(first_denomination函数以可用硬币种类的数量作为输入,并返回第一种硬币的面额。在这里,我们将硬币按从大到小的顺序排列,但任何顺序都可以。)现在我们可以回答关于找零一美元的最初问题:
count_change(100);
292函数count_change生成了一个树形递归过程,其中包含与我们对fib的第一个实现类似的冗余。另一方面,设计一个更好的算法来计算结果并不明显,我们将这个问题留作挑战。树形递归过程可能非常低效,但通常易于指定和理解的观察,这导致人们提出,通过设计一个“智能编译器”,可以将树形递归函数转换为计算相同结果的更有效的函数,从而获得两全其美的最佳结果。³²
练习 1.11
一个函数f由以下规则定义:如果n < 3,f(n) = n,如果n > 3,f(n) = f(n - 1) + 2f(n - 2) + 3f(n - 3)。编写一个通过递归过程计算f的 JavaScript 函数。编写一个通过迭代过程计算f的函数。
练习 1.12
以下数字模式称为帕斯卡三角形。
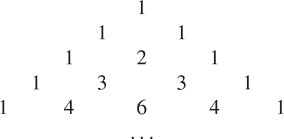
三角形边缘的数字都是 1,三角形内部的每个数字都是它上面两个数字的和。³³编写一个通过递归过程计算帕斯卡三角形元素的函数。
练习 1.13
证明Fib(n)是最接近ϕⁿ/√5的整数,其中ϕ=(1+√5)/2。提示:使用归纳法和斐波那契数的定义来证明Fib(n)=(ϕⁿ-ψⁿ)/√5,其中ψ=(1-√5)/2。
1.2.3 增长的顺序
前面的例子说明了过程在消耗计算资源的速率上可能有很大的不同。描述这种差异的一种方便的方法是使用增长的顺序的概念,以获得一个粗略的度量,即随着输入变大,过程所需的资源。
让n成为衡量问题规模的参数,R(n)是过程对规模为n的问题所需的资源量。在我们之前的例子中,我们取n为要计算给定函数的数字,但还有其他可能性。例如,如果我们的目标是计算一个数字的平方根的近似值,我们可能会取n为所需的精度位数。对于矩阵乘法,我们可能会取n为矩阵中的行数。一般来说,关于问题的一些属性是值得分析给定过程的。同样,R(n)可能衡量使用的内部存储寄存器的数量,执行的基本机器操作的数量等等。在一次只执行固定数量的操作的计算机中,所需的时间将与执行的基本机器操作的数量成正比。
我们说R(n)的增长顺序是Θ(f(n)),写作R(n) = Θ(f(n))(读作“theta f(n)”),如果存在正常数k[1]和k[2],独立于n,使得
k[1] f(n) ≤ R(n) ≤ k[2] f(n)对于任何足够大的n值。(换句话说,对于大的n,值R(n)夹在k[1]f(n)和k[2]f(n)之间。)
例如,在第 1.2.1 节中描述的用于计算阶乘的线性递归过程,步数与输入n成比例增长。因此,此过程所需的步数增长为Θ(n)。我们还看到所需的空间增长为Θ(n)。对于迭代阶乘,步数仍然是Θ(n),但空间是Θ(1)——即常数。[^34] 在第 1.2.2 节中描述的黄金比例ϕ,树递归的斐波那契计算需要Θ(ϕⁿ)步和Θ(n)空间。
增长顺序只提供了对过程行为的粗略描述。例如,需要n²步的过程和需要1000n²步的过程以及需要3n² + 10n + 17步的过程都具有Θ(n²)的增长顺序。另一方面,增长顺序提供了一个有用的指示,告诉我们当问题的规模改变时,我们可以期望过程的行为如何改变。对于Θ(n)(线性)过程,将问题规模加倍将大致使资源使用量加倍。对于指数过程,问题规模的每个增量将通过一个常数因子来增加资源利用率。在第 1.2 节的其余部分,我们将研究两种增长顺序为对数的算法,因此问题规模加倍将使资源需求增加一个常数量。
练习 1.14
绘制树,说明第 1.2.2 节中的count_change函数生成的过程,用于找零 11 美分。随着要找零的金额增加,该过程使用的空间和步数的增长顺序是多少?
练习 1.15
如果x足够小,则可以利用近似值sin x ≈ x来计算角的正弦(以弧度表示),以及三角恒等式
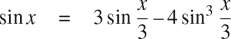
减小sin的参数大小。(对于本练习而言,如果角的大小不大于 0.1 弧度,则被认为是“足够小”。)这些想法被纳入以下函数:
function cube(x) {
return x * x * x;
}
function p(x) {
return 3 * x - 4 * cube(x);
}
function sine(angle) {
return ! (abs(angle) > 0.1)
? angle
: p(sine(angle / 3));
}-
a. 当计算
sine(12.15)时,函数p被应用了多少次? -
b. 当计算
sine(a)时,由sine函数生成的过程的空间和步数的增长顺序是多少(作为a的函数)?
1.2.4 指数
考虑计算给定数字的指数的问题。我们希望有一个函数,它以基数b和正整数指数n作为参数,并计算bⁿ。一种方法是通过递归定义来实现这一点
bⁿ = b bⁿ^(–1)
b⁰ = 1这很容易转化为函数
function expt(b, n) {
return n === 0
? 1
: b * expt(b, n - 1);
}这是一个线性递归过程,需要Θ(n)步和Θ(n)空间。就像阶乘一样,我们可以很容易地制定一个等效的线性迭代:
function expt(b, n) {
return expt_iter(b, n, 1);
}
function expt_iter(b, counter, product) {
return counter === 0
? product
: expt_iter(b, counter - 1, b * product);
}这个版本需要Θ(n)步和Θ(1)空间。
通过使用连续平方,我们可以用更少的步骤计算指数。例如,不是计算b⁸为
b · (b · (b · (b · (b · (b · (b · b))))))我们可以使用三次乘法来计算它:
b² = b · b
b⁴ = b² · b²
b⁸ = b⁴ · b⁴这种方法适用于 2 的幂次方。如果我们使用规则
bⁿ = (b^(n/2))²如果n是偶数
bⁿ = b · b^(n–1)如果n是奇数
我们可以将这种方法表达为一个函数:
function fast_expt(b, n) {
return n === 0
? 1
: is_even(n)
? square(fast_expt(b, n / 2))
: b * fast_expt(b, n - 1);
}其中用于测试整数是否为偶数的谓词是根据运算符%定义的,该运算符在整数除法后计算余数,通过
function is_even(n) {
return n % 2 === 0;
}fast_expt产生的过程在空间和步数上都以对数方式增长。观察到使用fast_expt计算b²ⁿ只需要比计算bⁿ多一次乘法。因此,我们可以大约每次允许新的乘法时,我们可以计算的指数大小加倍。因此,对于n的指数所需的乘法数量大约与以 2 为底的n的对数一样快。该过程具有Θ(log n)增长。³⁵
当n变大时,Θ(log n)增长和Θ(n)增长之间的差异变得明显。例如,n=1000时,fast_expt只需要 14 次乘法。³⁶也可以使用连续平方的想法设计一个迭代算法,该算法使用对数数量的步骤计算指数(参见练习 1.16),尽管通常情况下,这与递归算法一样,不那么直接。³⁷
练习 1.16
设计一个函数,它演变出一个使用连续平方并使用对数数量步骤的迭代指数过程,就像fast_expt一样。(提示:使用观察到的事实(b^(n/2))² = (b²)^(n/2),除了指数n和基数b之外,还保留一个额外的状态变量a,并定义状态转换,使得乘积abⁿ从一个状态到另一个状态保持不变。在过程开始时,a被认为是 1,并且答案由过程结束时的a的值给出。通常,定义一个从一个状态到另一个状态保持不变的不变量数量的技术是思考设计迭代算法的强大方法。)
练习 1.17
本节中的幂运算算法是基于通过重复乘法进行幂运算。类似地,可以通过重复加法执行整数乘法。下面的乘法函数(假设我们的语言只能加法,不能乘法)类似于expt函数:
function times(a, b) {
return b === 0
? 0
: a + times(a, b - 1);
}该算法的步骤数量与b成正比。现在假设我们还包括double函数,它可以将整数加倍,以及halve函数,它可以将(偶数)整数除以 2。使用这些函数,设计一个类似于fast_expt的乘法函数,它使用对数数量的步骤。
练习 1.18
使用练习 1.16 和 1.17 的结果,设计一个函数,该函数生成一个迭代过程,用于以加法,加倍和减半的术语乘以两个整数,并且使用对数数量的步骤。³⁸
练习 1.19
有一个巧妙的算法可以在对数步骤内计算斐波那契数。回顾第 1.2.2 节中fib_iter过程中状态变量a和b的转换:a, a + b和b, a。将这个转换称为T,观察到反复应用Tⁿ次,从 1 和 0 开始,会产生一对Fib(n + 1)和Fib(n)。换句话说,斐波那契数是通过从一对(1, 0)开始应用Tⁿ,即T的n次幂,产生的。现在考虑T是变换T[pq]中p = 0和q = 1的特殊情况,其中T[pq]根据a ← bq + aq + ap和b ← bp + aq转换对(a, b)。证明如果我们两次应用这样的变换T[pq],其效果与使用相同形式的单个变换T[p′q′]相同,并计算p′和q′。这给了我们一个明确的方法来平方这些变换,因此我们可以使用连续平方来计算Tⁿ,就像fast_expt函数中一样。将所有这些放在一起,完成以下函数,可以在对数步骤内运行:³⁹
function fib(n) {
return fib_iter(1, 0, 0, 1, n);
}
function fib_iter(a, b, p, q, count) {
return count === 0
? b
: is_even(count)
? fib_iter(a,
b,
(??), // compute p′
(??), // compute q′
count / 2)
: fib_iter(b * q + a * q + a * p,
b * p + a * q,
p,
q,
count - 1);
}1.2.5 最大公约数
两个整数a和b的最大公约数(GCD)被定义为能够整除a和b且没有余数的最大整数。例如,16 和 28 的 GCD 是 4。在第 2 章中,当我们研究如何实现有理数算术时,我们需要能够计算 GCD 以将有理数化简为最低项。 (要将有理数化简为最低项,我们必须将分子和分母都除以它们的 GCD。例如,16/28 化简为 4/7。)找到两个整数的 GCD 的一种方法是对它们进行因式分解并搜索公因数,但有一个著名的算法效率更高。
该算法的思想基于这样的观察:如果a除以b的余数为r,那么a和b的公约数恰好与b和r的公约数相同。因此,我们可以使用方程式
GCD(a, b) = GCD(b, r)将计算 GCD 的问题逐步减少为计算更小的整数对的 GCD 的问题。例如,
GCD(206, 40) = GCD(40, 6)
= GCD(6, 4)
= GCD(4, 2)
= GCD(2, 0)
= 2将 GCD(206, 40)减少到 GCD(2, 0),即为 2。可以证明,从任意两个正整数开始,进行重复的减少操作最终总会产生一个第二个数字为 0 的对。然后 GCD 就是对中的另一个数字。这种计算 GCD 的方法被称为欧几里得算法。⁴⁰
很容易将欧几里得算法表达为一个函数:
function gcd(a, b) {
return b === 0 ? a : gcd(b, a % b);
}这产生了一个迭代过程,其步数随涉及的数字的对数增长。
欧几里得算法所需的步骤数量具有对数增长与斐波那契数有有趣的关系:
拉梅定理:如果欧几里得算法需要k步来计算一对的 GCD,那么一对中较小的数字必须大于或等于第k个斐波那契数。⁴¹
我们可以使用这个定理来估计欧几里得算法的增长顺序。让n为函数的两个输入中较小的那个。如果过程需要k步,那么我们必须有n ≥ Fib(k) ≈ ϕ^k/√5。因此,步数k随着n的对数(以ϕ为底)增长。因此,增长顺序为Θ(log n)。
练习 1.20
函数生成的过程当然取决于解释器使用的规则。例如,考虑上面给出的迭代gcd函数。假设我们使用正则序求值来解释这个函数,就像在 1.1.5 节中讨论的那样。(条件表达式的正则序求值规则在练习 1.5 中描述。)使用替换方法(用于正则序),说明在求值gcd(206, 40)时生成的过程,并指出实际执行的remainder操作。在正则序求值gcd(206, 40)时实际执行了多少次remainder操作?在应用序求值中呢?
1.2.6 示例:素性测试
本节描述了检查整数n的素性的两种方法,一种具有Θ(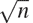 )的增长阶数,另一种是具有
)的增长阶数,另一种是具有Θ(log n)的“概率”算法。本节末尾的练习建议基于这些算法进行编程项目。
寻找除数
自古以来,数学家们一直对素数问题着迷,许多人一直致力于确定测试数字是否为质数的方法。测试一个数是否为质数的一种方法是找到这个数的除数。以下程序找到给定数字n的最小整数除数(大于 1)。它通过以 2 开始的连续整数测试n是否可被整除的方式来直接进行。
function smallest_divisor(n) {
return find_divisor(n, 2);
}
function find_divisor(n, test_divisor) {
return square(test_divisor) > n
? n
: divides(test_divisor, n)
? test_divisor
: find_divisor(n, test_divisor + 1);
}
function divides(a, b) {
return b % a === 0;
}我们可以通过以下方式测试一个数是否为质数:n是质数当且仅当n是其自身的最小除数。
function is_prime(n) {
return n === smallest_divisor(n);
}find_divisor的结束测试基于这样一个事实,即如果n不是质数,它必须有一个小于或等于√n的除数。⁴²这意味着算法只需要测试 1 和√n之间的除数。因此,识别n为质数所需的步骤数量将具有Θ(√n)的增长阶数。
费马测试
Θ(log n)素性测试基于数论中称为费马小定理的结果。⁴³
费马小定理: 如果n是一个质数,a是小于n的任意正整数,则a的n次幂与n模同余。
(如果两个数除以n的余数相同,则它们被称为n模同余。当一个数a除以n的余数也被称为a模n的余数,或者简称为a模n。)
如果n不是质数,那么一般来说,大多数小于n的数a都不满足上述关系。这导致了用于测试素性的以下算法:给定一个数n,选择一个小于n的随机数a,并计算aⁿ模n的余数。如果结果不等于a,那么n肯定不是质数。如果它等于a,那么n很可能是质数。现在选择另一个随机数a,并用相同的方法进行测试。如果它也满足方程,则我们可以更加确信n是质数。通过尝试更多的a值,我们可以增加对结果的信心。这个算法被称为费马测试。
为了实现费马测试,我们需要一个计算一个数的指数模另一个数的函数:
function expmod(base, exp, m) {
return exp === 0
? 1
: is_even(exp)
? square(expmod(base, exp / 2, m)) % m
: (base * expmod(base, exp - 1, m)) % m;
}这与 1.2.4 节中的fast_expt函数非常相似。它使用连续平方,因此步骤数量随指数对数增长。⁴⁴
费马测试是通过随机选择一个介于 1 和n-1之间的数字a来执行的,并检查a的n次幂的模n的余数是否等于a。随机数a是使用原始函数math_random选择的,该函数返回小于 1 的非负数。因此,要获得 1 和n-1之间的随机数,我们将math_random的返回值乘以n-1,用原始函数math_floor向下舍入结果,然后加 1。
function fermat_test(n) {
function try_it(a) {
return expmod(a, n, n) === a;
}
return try_it(1 + math_floor(math_random() * (n - 1)));
}以下函数根据参数指定的次数运行测试。如果测试每次都成功,则其值为true,否则为false。
function fast_is_prime(n, times) {
return times === 0
? true
: fermat_test(n)
? fast_is_prime(n, times - 1)
: false;
}概率方法
费马测试在性质上与大多数熟悉的算法不同,大多数算法计算的答案是保证正确的。在这里,获得的答案只是可能正确。更准确地说,如果n曾经未通过费马测试,我们可以肯定n不是质数。但是,n通过测试的事实,虽然是一个极为强有力的指示,但仍不能保证n是质数。我们想说的是,对于任何数字n,如果我们进行足够多次测试并发现n总是通过测试,那么我们的素性测试中的错误概率可以尽可能小。
不幸的是,这个断言并不完全正确。确实存在一些可以欺骗费马测试的数字:不是质数但具有性质aⁿ对n取模等于a对n取模的数字n,其中所有整数a < n。这样的数字非常罕见,因此费马测试在实践中是相当可靠的。费马测试有一些无法被欺骗的变体。在这些测试中,与费马方法一样,通过选择一个随机整数a < n并检查依赖于n和a的某些条件来测试整数n的素性。(有关这种测试的示例,请参见练习 1.28。)另一方面,与费马测试相反,可以证明对于任何n,除非n是质数,否则大多数整数a < n都不满足条件。因此,如果n对某个随机选择的a通过了测试,那么n是质数的可能性甚至更大。如果n对两个随机选择的a通过了测试,那么n是质数的可能性超过 4 分之 3。通过使用更多和更多随机选择的a值运行测试,我们可以使错误的概率尽可能小。
对于可以证明错误几率变得任意小的测试的存在引起了对这种类型算法的兴趣,这种算法被称为概率算法。在这个领域有大量的研究活动,概率算法已经成功地应用到许多领域。
练习 1.21
使用smallest_divisor函数找出以下数字的最小除数:199、1999、19999。
练习 1.22
假设有一个没有参数的原始函数get_time,它返回自 1970 年 1 月 1 日星期四 UTC 时间 00![]() 00 以来经过的毫秒数。以下
00 以来经过的毫秒数。以下timed_prime_test函数在调用整数 n 时打印 n 并检查 n 是否为质数。如果 n 是质数,则该函数打印三个星号,然后是执行测试所用的时间量。
function timed_prime_test(n) {
display(n);
return start_prime_test(n, get_time());
}
function start_prime_test(n, start_time) {
return is_prime(n)
? report_prime(get_time() - start_time)
: true;
}
function report_prime(elapsed_time) {
display(" *** ");
display(elapsed_time);
}使用这个函数,编写一个名为search_for_primes的函数,它检查指定范围内连续奇数的素性。使用你的函数找到大于 1000 的三个最小素数;大于 10,000;大于 100,000;大于 1,000,000。注意测试每个素数所需的时间。由于测试算法的增长阶为Θ(),你应该期望在 10,000 左右的素数测试大约需要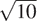 倍于在 1000 左右的素数测试。你的计时数据是否支持这一点?100,000 和 1,000,000 的数据对的预测有多好的支持?你的结果是否符合程序在你的机器上运行时间与计算所需步骤数量成正比的概念?
倍于在 1000 左右的素数测试。你的计时数据是否支持这一点?100,000 和 1,000,000 的数据对的预测有多好的支持?你的结果是否符合程序在你的机器上运行时间与计算所需步骤数量成正比的概念?
练习 1.23
本节开头显示的smallest_divisor函数进行了许多不必要的测试:在检查数字是否可被 2 整除后,没有必要检查它是否可被任何更大的偶数整除。这表明用于test_divisor的值不应该是 2, 3, 4, 5, 6, ...而应该是 2, 3, 5, 7, 9,为了实现这个改变,声明一个函数next,如果它的输入等于 2,则返回 3,否则返回它的输入加 2。修改smallest_divisor函数,使用next(test_divisor)代替test_divisor + 1。使用包含这个修改版本的smallest_divisor的timed_prime_test,对在练习 1.22 中找到的 12 个素数进行测试。由于这个修改减少了测试步骤的数量,你应该期望它运行大约快两倍。这个期望是否得到确认?如果没有,两个算法的速度比率是多少,你如何解释它与 2 不同的事实?
练习 1.24
修改练习 1.22 的timed_prime_test函数,使用fast_is_prime(费马方法),并测试你在那个练习中找到的 12 个素数。由于费马测试具有Θ(log n)的增长,你会预期测试接近 1,000,000 的素数所需的时间与测试接近 1000 的素数相比如何?你的数据是否支持这一点?你能解释你发现的任何差异吗?
练习 1.25
Alyssa P. Hacker 抱怨我们在编写expmod时做了很多额外的工作。她说,毕竟,既然我们已经知道如何计算指数,我们本来可以简单地写成
function expmod(base, exp, m) {
return fast_expt(base, exp) % m;
}她是正确的吗?这个函数对我们的快速素数测试器是否有用?解释一下。
练习 1.26
路易斯·里森纳在做练习 1.24 时遇到了很大的困难。他的fast_is_prime测试似乎比他的is_prime测试运行得更慢。路易斯叫他的朋友伊娃·卢·阿托过来帮忙。当他们检查路易斯的代码时,他们发现他已经重写了expmod函数,使用了显式乘法,而不是调用square:
function expmod(base, exp, m) {
return exp === 0
? 1
: is_even(exp)
? ( expmod(base, exp / 2, m)
* expmod(base, exp / 2, m)) % m
: (base * expmod(base, exp - 1, m)) % m;
}“我不明白那会有什么不同,”路易斯说。“我明白,”伊娃说。“通过那样写函数,你已经将Θ(log n)的过程转变为Θ(n)的过程。”解释一下。
练习 1.27
证明脚注 45 中列出的卡迈克尔数确实愚弄了费马测试。也就是说,编写一个函数,它接受一个整数n,并测试对于每个a < n,aⁿ是否与a模n同余,并在给定的卡迈克尔数上尝试你的函数。
练习 1.28
一个无法被愚弄的费马测试的变体被称为米勒-拉宾测试(Miller 1976; Rabin 1980)。这是从费马小定理的另一种形式开始的,该定理陈述了如果n是一个质数,a是小于n的任意正整数,则a的(n - 1)次方与n模同余于 1。通过米勒-拉宾测试来测试一个数n的素性,我们选择一个随机数a < n,并使用expmod函数将a的(n - 1)次方模n。然而,每当我们在expmod中执行平方步骤时,我们检查是否发现了“非平凡的模n的平方根”,即不等于 1 或n - 1的平方等于模n的 1 的数。可以证明,如果存在这样一个非平凡的模 1 的平方根,那么n不是质数。也可以证明,如果n是一个不是质数的奇数,那么至少有一半的数a < n,通过这种方式计算a^(n–1)将会显示出模n的非平凡的平方根。(这就是为什么米勒-拉宾测试无法被愚弄的原因。)修改expmod函数以便在发现非平凡的模 1 的平方根时发出信号,并使用这个来实现米勒-拉宾测试,方法类似于fermat_test。通过测试各种已知的质数和非质数来检查你的函数。提示:使expmod发出信号的一个方便的方法是让它返回 0。
1.3 用高阶函数制定抽象
我们已经看到,函数实际上是描述数字的复合操作的抽象,与特定数字无关。例如,当我们声明
function cube(x) {
return x * x * x;
}我们不是在谈论特定数字的立方,而是在谈论获得任何数字的立方的方法。当然,我们可以不声明这个函数,总是写诸如
3 * 3 * 3
x * x * x
y * y * y并且从不明确提到cube。这将使我们处于严重的不利地位,迫使我们总是在语言中原语的特定操作级别上工作(在这种情况下是乘法),而不是在更高级别的操作上工作。我们的程序可以计算立方,但我们的语言缺乏表达立方概念的能力。我们应该从一个强大的编程语言中要求的一件事是,通过为常见模式分配名称来构建抽象的能力,然后直接使用这些抽象。函数提供了这种能力。这就是为什么除了最原始的编程语言之外,所有的编程语言都包括声明函数的机制。
然而,即使在数值处理中,如果我们被限制为参数必须是数字的函数,我们在创建抽象的能力上也会受到严重限制。通常相同的编程模式会与许多不同的函数一起使用。为了将这样的模式表达为概念,我们需要构建可以接受函数作为参数或返回函数作为值的函数。操作函数的函数称为高阶函数。本节展示了高阶函数如何作为强大的抽象机制,大大增加了我们语言的表达能力。
1.3.1 函数作为参数
考虑以下三个函数。第一个计算从a到b的整数的和:
function sum_integers(a, b) {
return a > b
? 0
: a + sum_integers(a + 1, b);
}第二个计算给定范围内整数的立方和:
function sum_cubes(a, b) {
return a > b
? 0
: cube(a) + sum_cubes(a + 1, b);
}第三个计算序列中一系列项的和
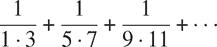
这收敛到π/8(非常慢):⁴⁹
function pi_sum(a, b) {
return a > b
? 0
: 1 / (a * (a + 2)) + pi_sum(a + 4, b);
}这三个函数显然共享一个共同的基本模式。它们在大部分情况下是相同的,只是函数的名称不同,用于计算要添加的项的a的函数不同,以及提供a的下一个值的函数不同。我们可以通过在相同的模板中填充槽来生成每个函数:
function name(a, b) {
return a > b
? 0
: term(a) + name(next(a), b);
}这种常见模式的存在是有力的证据,表明有一个有用的抽象正在等待被提出。事实上,数学家很久以前就确定了级数求和的抽象,并发明了“Σ符号”,例如
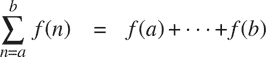
来表达这个概念。Σ符号的力量在于它允许数学家处理求和概念本身,而不仅仅是特定的和,例如,制定关于独立于被求和的特定系列的一般结果。
同样,作为程序设计师,我们希望我们的语言足够强大,以便我们可以编写一个表达求和概念本身而不仅仅是计算特定和的函数。在我们的函数语言中,我们可以很容易地采用上面显示的常见模板,并将“插槽”转换为参数:
function sum(term, a, next, b) {
return a > b
? 0
: term(a) + sum(term, next(a), next, b);
}注意,sum以它的参数下限和上限a和b以及函数term和next作为参数。我们可以像使用任何函数一样使用sum。例如,我们可以使用它(以及一个将其参数增加 1 的函数inc)来定义sum_cubes:
function inc(n) {
return n + 1;
}
function sum_cubes(a, b) {
return sum(cube, a, inc, b);
}使用这个,我们可以计算 1 到 10 的整数的立方和:
sum_cubes(1, 10);
3025借助一个计算项的恒等函数,我们可以定义sum_integers:
function identity(x) {
return x;
}
function sum_integers(a, b) {
return sum(identity, a, inc, b);
}然后我们可以计算 1 到 10 的整数的和:
sum_integers(1, 10);
55我们也可以用同样的方法定义pi_sum:⁵⁰
function pi_sum(a, b) {
function pi_term(x) {
return 1 / (x * (x + 2));
}
function pi_next(x) {
return x + 4;
}
return sum(pi_term, a, pi_next, b);
}使用这些函数,我们可以计算π的近似值:
8 * pi_sum(1, 1000);
3.139592655589783一旦我们有了sum,我们就可以将其用作构建进一步概念的基础。例如,函数f在限制a和b之间的定积分可以使用以下公式在数值上近似:
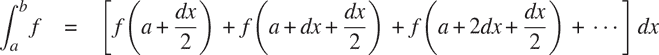
对于小的dx值。我们可以直接表示这个函数:
function integral(f, a, b, dx) {
function add_dx(x) {
return x + dx;
}
return sum(f, a + dx / 2, add_dx, b) * dx;
}
integral(cube, 0, 1, 0.01);
0.24998750000000042
integral(cube, 0, 1, 0.001);
0.249999875000001(函数cube在 0 和 1 之间的积分的确切值为 1/4。)
练习 1.29
辛普森法则是一种比上面所示方法更准确的数值积分方法。使用辛普森法则,函数f在a和b之间的积分可以近似为
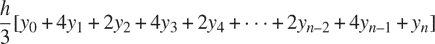
其中h = (b - a)/n,对于一些偶数n,y[k] = f(a + kh)。 (增加n会增加近似的准确性。)声明一个函数,它以f, a, b和n作为参数,并使用辛普森法则计算积分的值。使用你的函数来计算cube在 0 和 1 之间的积分(n = 100和n = 1000),并将结果与上面所示的integral函数的结果进行比较。
练习 1.30
上面的sum函数生成一个线性递归。可以重写该函数,使求和以迭代方式执行。通过填写以下声明中的缺失表达式,展示如何做到这一点:
function sum(term, a, next, b) {
function iter(a, result) {
return 〈??〉
? 〈??〉
: iter(〈??〉, 〈??〉);
}
return iter(〈??〉, 〈??〉);
}练习 1.31
-
a.
sum函数只是许多类似抽象中最简单的一个。⁵¹编写一个名为product的类似函数,它返回给定范围内点的函数值的乘积。展示如何用product来定义factorial。还使用product来使用公式计算π的近似值⁵²![c1-fig-5019.jpg]()
-
b. 如果你的
product函数生成一个递归过程,写一个生成迭代过程的函数。如果它生成一个迭代过程,写一个生成递归过程的函数。
练习 1.32
-
a. 证明
sum和product(练习 1.31)都是更一般的称为accumulate的特殊情况,它使用一些一般的累积函数来组合一系列项:accumulate(combiner, null_value, term, a, next, b);函数
accumulate接受与sum和product相同的项和范围规范,以及一个combiner函数(两个参数)作为参数,该函数指定如何将当前项与前面项的累积组合在一起,以及一个null_value,用于指定项用完时要使用的基本值。编写accumulate并展示如何将sum和product都声明为对accumulate的简单调用。b. 如果您的
accumulate函数生成递归过程,请编写一个生成迭代过程的函数。如果它生成迭代过程,请编写一个生成递归过程的函数。
练习 1.33
您可以通过引入对要组合的项进行筛选的概念来获得accumulate的更通用版本(练习 1.32)。也就是说,仅组合满足指定条件的范围中的值导出的那些项。生成的filtered_accumulate抽象接受与 accumulate 相同的参数,以及指定筛选器的一个参数的附加谓词。编写filtered_accumulate作为一个函数。展示如何使用filtered_accumulate来表达以下内容:
-
a. 在区间
a到b中素数的平方的和(假设您已经编写了is_prime谓词) -
b. 所有小于
n的正整数的乘积,这些整数与n互质(即,所有正整数i < n,使得GCD(i, n) = 1)。
1.3.2 使用 Lambda 表达式构建函数
在使用sum时,似乎非常笨拙地声明诸如pi_term和pi_next之类的微不足道的函数,以便我们可以将它们用作高阶函数的参数。与其声明pi_next和pi_term,不如直接指定“返回其输入加 4 的函数”和“返回其输入的倒数乘以其输入加 2 的函数”更方便。我们可以通过引入lambda 表达式作为一种用于创建函数的语法形式来实现这一点。使用 lambda 表达式,我们可以描述我们想要的内容
x => x + 4和
x => 1 / (x * (x + 2))然后我们可以表达我们的pi_sum函数,而不声明任何辅助函数:
function pi_sum(a, b) {
return sum(x => 1 / (x * (x + 2)),
a,
x => x + 4,
b);
}再次使用 lambda 表达式,我们可以编写integral函数,而无需声明辅助函数add_dx:
function integral(f, a, b, dx) {
return sum(f,
a + dx / 2,
x => x + dx,
b)
*
dx;
}通常,lambda 表达式用于创建函数,方式与函数声明相同,只是没有为函数指定名称,并且省略了return关键字和大括号(如果只有一个参数,则可以省略参数列表周围的括号,就像我们看到的例子一样)。⁵³
(parameters) => expression生成的函数与使用函数声明语句创建的函数一样。唯一的区别是它没有与环境中的任何名称关联。我们认为
function plus4(x) {
return x + 4;
}等同于⁵⁴
const plus4 = x => x + 4;我们可以按照以下方式阅读 lambda 表达式:
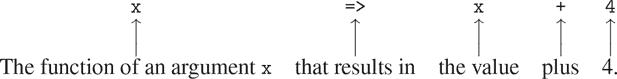
像任何具有函数作为其值的表达式一样,lambda 表达式可以用作应用程序中的函数表达式,例如
((x, y, z) => x + y + square(z))(1, 2, 3);
12或者,更一般地,在我们通常使用函数名称的任何上下文中。⁵⁵ 请注意,=>的优先级低于函数应用,因此这里括号是必要的。
使用const创建本地名称
lambda 表达式的另一个用途是创建本地名称。我们在函数中经常需要本地名称,而不仅仅是已绑定为参数的名称。例如,假设我们希望计算函数
f (x, y) = x(1 + xy)² + y(1 – y) + (1 + xy)(1 – y)我们也可以表达为
a = 1 + xy
b = 1 – y
f (x, y) = xa² + yb + ab在编写一个计算f的函数时,我们希望将局部名称不仅包括x和y,还包括像a和b这样的中间量的名称。实现这一点的一种方法是使用辅助函数来绑定局部名称:
function f(x, y) {
function f_helper(a, b) {
return x * square(a) + y * b + a * b;
}
return f_helper(1 + x * y, 1 - y);
}当然,我们可以使用 lambda 表达式来指定一个匿名函数来绑定我们的局部名称。然后函数体变成了对该函数的单个调用:
function f_2(x, y) {
return ( (a, b) => x * square(a) + y * b + a * b
)(1 + x * y, 1 - y);
}通过在函数体内使用常量声明,更方便地声明局部名称的一种方法是使用常量声明。使用const,函数可以写成
function f_3(x, y) {
const a = 1 + x * y;
const b = 1 - y;
return x * square(a) + y * b + a * b;
}在块内部使用const声明的名称将其所在的最近块的主体作为其作用域。⁵⁶^,⁵⁷
条件语句
我们已经看到,在函数声明中声明局部名称通常是有用的。当函数变得很大时,我们应该尽可能地保持名称的范围狭窄。例如考虑练习 1.26 中的expmod。
function expmod(base, exp, m) {
return exp === 0
? 1
: is_even(exp)
? ( expmod(base, exp / 2, m)
* expmod(base, exp / 2, m)) % m
: (base * expmod(base, exp - 1, m)) % m;
}这个函数是不必要的低效,因为它包含了两个相同的调用:
expmod(base, exp / 2, m);虽然在这个例子中可以很容易地使用square函数来修复这个问题,但在一般情况下并不容易。如果不使用square,我们可能会尝试引入一个表达式的局部名称,如下所示:
function expmod(base, exp, m) {
const half_exp = expmod(base, exp / 2, m);
return exp === 0
? 1
: is_even(exp)
? (half_exp * half_exp) % m
: (base * expmod(base, exp - 1, m)) % m;
}这将使函数不仅效率低下,而且实际上是非终止的!问题在于常量声明出现在条件表达式之外,这意味着即使满足基本情况exp === 0,它也会被执行。为了避免这种情况,我们提供了条件语句,并允许返回语句出现在语句的分支中。使用条件语句,我们可以将函数expmod写成如下形式:
function expmod(base, exp, m) {
if (exp === 0) {
return 1;
} else {
if (is_even(exp)) {
const half_exp = expmod(base, exp / 2, m);
return (half_exp * half_exp) % m;
} else {
return (base * expmod(base, exp - 1, m)) % m;
}
}
}条件语句的一般形式是
if (predicate) { consequent-statements } else { alternative-statements }对于条件表达式,解释器首先求值predicate。如果它求值为true,解释器按顺序求值consequent-statements,如果它求值为false,解释器按顺序求值alternative-statements。返回语句的求值从周围的函数返回,忽略返回语句后的任何语句和条件语句后的任何语句。请注意,任何在任一部分中发生的常量声明都是该部分的局部声明,因为每个部分都被括号括起来,因此形成自己的块。
练习 1.34
假设我们声明
function f(g) {
return g(2);
}然后我们有
f(square);
`4`
f(z => z * (z + 1));
`6`如果我们(刻意地)要求解释器求值应用f(f)会发生什么?解释。
1.3.3 函数作为一般方法
我们在 1.1.4 节介绍了复合函数作为一种抽象数值操作模式的机制,使其独立于特定的数字。通过高阶函数,比如 1.3.1 节的integral函数,我们开始看到一种更强大的抽象:用于表达计算的一般方法,独立于特定的函数。在本节中,我们将讨论两个更复杂的例子——查找函数的零点和不动点的一般方法,并展示这些方法如何直接表达为函数。
通过半区间法找到方程的根
半区间方法是一种简单但强大的技术,用于找到方程f(x)=0的根,其中f是一个连续函数。其思想是,如果我们给定了f(a)<0<f(b)的点a和b,那么f必须至少在a和b之间有一个零点。为了找到零点,让x为a和b的平均值,并计算f(x)。如果f(x)>0,则f必须在a和x之间有一个零点。如果f(x)<0,则f必须在x和b之间有一个零点。以此类推,我们可以确定f必须有一个零点的更小的区间。当我们达到一个足够小的区间时,过程停止。由于不确定性的区间在过程的每一步都减半,所以所需的最大步数增长为Θ(log(L/T)),其中L是原始区间的长度,T是误差容限(即我们将考虑“足够小”的区间的大小)。以下是实现这种策略的函数:
function search(f, neg_point, pos_point) {
const midpoint = average(neg_point, pos_point);
if (close_enough(neg_point, pos_point)) {
return midpoint;
} else {
const test_value = f(midpoint);
return positive(test_value)
? search(f, neg_point, midpoint)
: negative(test_value)
? search(f, midpoint, pos_point)
: midpoint;
}
}我们假设我们最初给定了函数f以及其值为负和正的点。我们首先计算两个给定点的中点。接下来,我们检查给定的区间是否足够小,如果是,我们就简单地返回中点作为我们的答案。否则,我们计算中点处f的值作为测试值。如果测试值为正,则我们继续从原始负点到中点的新区间进行该过程。如果测试值为负,则我们继续从中点到正点的区间。最后,有可能测试值为 0,这种情况下中点本身就是我们正在寻找的根。为了测试端点是否“足够接近”,我们可以使用类似于 1.1.7 节中用于计算平方根的函数:
function close_enough(x, y) {
return abs(x - y) < 0.001;
}search函数直接使用起来很麻烦,因为我们可能会无意中给出f的值没有所需符号的点,这样我们就会得到错误的答案。相反,我们将通过以下函数使用search,该函数检查哪个端点具有负函数值,哪个具有正函数值,并相应地调用search函数。如果函数在两个给定点上具有相同的符号,则无法使用半区间方法,在这种情况下,函数会发出错误信号。
function half_interval_method(f, a, b) {
const a_value = f(a);
const b_value = f(b);
return negative(a_value) && positive(b_value)
? search(f, a, b)
: negative(b_value) && positive(a_value)
? search(f, b, a)
: error("values are not of opposite sign");
}以下示例使用半区间方法在 2 和 4 之间近似π作为sinx=0的根:
half_interval_method(math_sin, 2, 4);
3.14111328125以下是另一个例子,使用半区间方法在 1 和 2 之间搜索方程x³ - 2x - 3 = 0的根:
half_interval_method(x => x * x * x - 2 * x - 3, 1, 2);
1.89306640625查找函数的固定点
如果x满足方程f(x)=x,则称数字x为函数f的固定点。对于一些函数f,我们可以通过从初始猜测开始并重复应用f来找到一个固定点,
f(x), f(f(x)), f(f(f(x))), ...直到值变化不是很大为止。利用这个想法,我们可以设计一个函数fixed_point,它以函数和初始猜测为输入,并产生函数的一个近似固定点。我们重复应用该函数,直到找到两个连续值的差小于某个预定的容差:
const tolerance = 0.00001;
function fixed_point(f, first_guess) {
function close_enough(x, y) {
return abs(x - y) < tolerance;
}
function try_with(guess) {
const next = f(guess);
return close_enough(guess, next)
? next
: try_with(next);
}
return try_with(first_guess);
}例如,我们可以使用这种方法来近似余弦函数的固定点,从 1 开始作为初始近似值:
fixed_point(math_cos, 1);
0.7390822985224023同样,我们可以找到方程y=siny+cosy的解:
fixed_point(y => math_sin(y) + math_cos(y), 1);
1.2587315962971173固定点过程让人想起了我们在 1.1.7 节中用于找平方根的过程。两者都基于反复改进猜测的想法,直到结果满足某些标准。实际上,我们可以很容易地将平方根计算公式化为固定点搜索。计算某个数x的平方根需要找到一个y,使得y² = x。将这个方程转化为等价形式y = x / y,我们意识到我们正在寻找函数⁶¹ y = x/y的一个固定点,因此我们可以尝试计算平方根
function sqrt(x) {
return fixed_point(y => x / y, 1);
}不幸的是,这种固定点搜索不会收敛。考虑一个初始猜测y[1]。下一个猜测是y[2] = x/y[1],下一个猜测是y[3] = x/y[2] = x/(x/y[1]) = y[1]。这导致了一个无限循环,其中两个猜测y[1]和y[2]一遍又一遍地重复,围绕答案振荡。
控制这种振荡的一种方法是防止猜测变化太大。由于答案总是在我们的猜测y和x / y之间,我们可以做一个新的猜测,这个猜测不像x / y那么远离y,通过平均y和x / y,这样在y之后的下一个猜测就是1/2 (y + x / y)而不是x / y。这种猜测序列的过程只是寻找y -> 1/2 (y + x / y)的固定点的过程。
function sqrt(x) {
return fixed_point(y => average(y, x / y), 1);
}(注意y = 1/2 (y + x / y)是方程y = x / y的简单变换;为了推导它,将y添加到方程的两边,然后除以 2。)
有了这个修改,平方根函数就可以工作了。实际上,如果我们展开定义,我们可以看到这里生成的平方根近似序列与我们原来的 1.1.7 节平方根函数生成的序列完全相同。这种平均连分数的方法通常有助于固定点搜索的收敛。
练习 1.35
证明黄金分割比ϕ(1.2.2 节)是变换x -> 1 + 1/x的一个固定点,并利用这一事实通过fixed_point函数计算ϕ。
练习 1.36
修改fixed_point,以便它打印生成的近似值序列,使用练习 1.22 中显示的原始函数display。然后通过找到xˣ = 1000的固定点来找到解,即x -> log(1000)/ log(x)。 (使用计算自然对数的原始函数math_log。)比较使用和不使用平均阻尼所需的步骤数。(请注意,您不能从 1 开始fixed_point,因为这将导致除以log(1) = 0。)
练习 1.37
无限连分数是一个形式的表达式
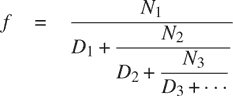
例如,可以证明,所有N[i]和D[i]都等于 1 的无限连分数展开产生1/ϕ,其中ϕ是黄金分割比(在 1.2.2 节中描述)。近似无限连分数的一种方法是在给定项数后截断展开。这种截断——所谓的k项有限连分数——具有形式
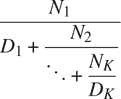
-
a.假设
n和d是一个参数(项索引i)的函数,返回连分数项的N[i]和D[i]。声明一个函数cont_frac,使得求值cont_frac(n, d, k)计算k项有限连分数的值。通过近似 1ϕ检查您的函数cont_frac(i => 1, i => 1, k);对于连续的
k值。为了获得精确到小数点后 4 位的近似值,您需要使k有多大? -
b. 如果您的
cont_frac函数生成递归过程,请编写一个生成迭代过程的函数。如果它生成迭代过程,请编写一个生成递归过程的函数。
练习 1.38
1737 年,瑞士数学家 Leonhard Euler 发表了一篇题为De Fractionibus Continuis的备忘录,其中包括了 e - 2的一个连分数展开,其中e是自然对数的底数。在这个分数中,N[i]都是 1,D[i]依次为 1、2、1、1、4、1、1、6、1、1、8,编写一个程序,使用练习 1.37 中的cont_frac函数来根据 Euler 的展开来近似e。
练习 1.39
1770 年,德国数学家 J.H. Lambert 发表了正切函数的连分数表示:
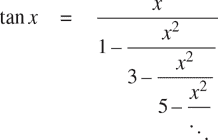
其中x以弧度为单位。声明一个函数tan_cf(x, k),根据 Lambert 的公式计算正切函数的近似值。与练习 1.37 一样,k指定要计算的项数。
1.3.4 作为返回值的函数
上述例子展示了将函数作为参数传递的能力如何显著增强了我们编程语言的表达能力。通过创建其返回值本身是函数的函数,我们可以实现更多的表达能力。
我们可以通过再次查看第 1.3.3 节末尾描述的不动点示例来说明这个想法。我们将一个新版本的平方根函数表述为一个不动点搜索,从观察到√x是函数y -> x / y的不动点开始。然后我们使用平均阻尼使近似值收敛。平均阻尼本身是一个有用的通用技术。也就是说,给定一个函数f,我们考虑其在x处的值等于x和f(x)的平均值的函数。
我们可以通过以下函数表达平均阻尼的想法:
function average_damp(f) {
return x => average(x, f(x));
}函数average_damp以函数f作为参数,并返回一个函数(由 lambda 表达式生成),当应用于数字x时,产生x和f(x)的平均值。例如,将average_damp应用于square函数会产生一个函数,其在某个数字x处的值是x和x²的平均值。将这个结果函数应用于 10 会返回 10 和 100 的平均值,即 55。
average_damp(square)(10);
55使用average_damp,我们可以重新表述平方根函数如下:
function sqrt(x) {
return fixed_point(average_damp(y => x / y), 1);
}注意这种表述如何明确了方法中的三个思想:不动点搜索、平均阻尼和函数y = x/y。比较这种平方根方法的表述与第 1.1.7 节中给出的原始版本是有益的。请记住,这些函数表达了相同的过程,注意当我们用这些抽象的术语表达过程时,这个想法变得更加清晰。一般来说,有许多方法可以将一个过程表述为一个函数。有经验的程序员知道如何选择特别明晰的过程表述,并且在有用的情况下,将过程的元素公开为可以在其他应用中重复使用的单独实体。作为重用的一个简单例子,注意x的立方根是函数y = x/y²的不动点,因此我们可以立即将我们的平方根函数推广为一个提取立方根的函数。
function cube_root(x) {
return fixed_point(average_damp(y => x / square(y)), 1);
}牛顿法
当我们首次介绍平方根函数时,在第 1.1.7 节中,我们提到这是牛顿法的一个特例。如果x -> g(x)是一个可微函数,那么方程g(x) = 0的解是函数x -> f (x)的不动点,其中
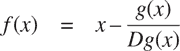
和Dg(x)是在x处求导的g的导数。牛顿法是使用我们上面看到的固定点方法来近似方程的解,通过找到函数f的固定点。⁶⁴ 对于许多函数g和对于足够好的x的初始猜测,牛顿法收敛得非常快,以便解决g(x) = 0。⁶⁵
为了将牛顿法实现为一个函数,我们必须首先表达导数的概念。注意,“导数”和平均阻尼一样,是将一个函数转换为另一个函数的东西。例如,函数x -> x³的导数是函数x -> 3x²。一般来说,如果g是一个函数,dx是一个小数,那么g的导数Dg是一个函数,其在任何数x处的值(在小dx的极限情况下)由
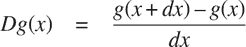
因此,我们可以将导数的概念(取dx为 0.00001)表示为函数
function deriv(g) {
return x => (g(x + dx) - g(x)) / dx;
}以及声明
const dx = 0.00001;像average_damp一样,deriv是一个以函数作为参数并返回函数作为值的函数。例如,要近似计算x³在 5 处的导数(其精确值为 75),我们可以计算
function cube(x) { return x * x * x; }
deriv(cube)(5);
75.00014999664018借助于deriv,我们可以将牛顿法表达为一个固定点过程:
function newton_transform(g) {
return x => x - g(x) / deriv(g)(x);
}
function newtons_method(g, guess) {
return fixed_point(newton_transform(g), guess);
}newton_transform函数表达了本节开头的公式,newtons_method可以很容易地根据这个定义。它的参数是一个计算我们想要找到零点的函数的函数,以及一个初始猜测。例如,要找到x的平方根,我们可以使用牛顿法来找到函数y -> y² – x的零点,从初始猜测为 1 开始。⁶⁶ 这提供了平方根函数的另一种形式:
function sqrt(x) {
return newtons_method(y => square(y) - x, 1);
}抽象和一级函数
我们已经看到了两种将平方根计算表达为更一般方法的实例,一种是作为固定点搜索,另一种是使用牛顿法。由于牛顿法本身被表达为一个固定点过程,我们实际上看到了两种计算平方根作为固定点的方法。每种方法都以一个函数开始,并找到函数的某个变换的固定点。我们可以将这个一般的想法本身表达为一个函数:
function fixed_point_of_transform(g, transform, guess) {
return fixed_point(transform(g), guess);
}这个非常一般的函数以一个计算某个函数的函数g,一个转换g的函数和一个初始猜测作为参数。返回的结果是转换函数的一个固定点。
使用这种抽象,我们可以将本节中第一个平方根计算(其中我们寻找y -> x / y的平均阻尼版本的固定点)重新表述为这种一般方法的一个实例:
function sqrt(x) {
return fixed_point_of_transform(
y => x / y,
average_damp,
1);
}同样,我们可以将本节中第二个平方根计算(牛顿法的一个实例,找到y -> y² – x的牛顿变换的固定点)表达为
function sqrt(x) {
return fixed_point_of_transform(
y => square(y) - x,
newton_transform,
1);
}我们在 1.3 节开始时观察到,复合函数是一个关键的抽象机制,因为它们允许我们将计算的一般方法表达为编程语言中的显式元素。现在我们已经看到了高阶函数如何允许我们操纵这些一般方法以创建进一步的抽象。
作为程序员,我们应该警惕机会,识别程序中的基本抽象,并在其上构建和泛化,以创建更强大的抽象。这并不是说我们应该总是以最抽象的方式编写程序;专业程序员知道如何选择适合其任务的抽象级别。但是,重要的是能够以这些抽象的方式思考,以便我们可以准备在新的上下文中应用它们。高阶函数的重要性在于它们使我们能够将这些抽象明确地表示为我们编程语言中的元素,以便它们可以像其他计算元素一样被处理。
一般来说,编程语言对计算元素的操作方式施加了限制。具有最少限制的元素被称为第一类状态。第一类元素的一些“权利和特权”是:
-
它们可以使用名称来引用。
-
它们可以作为函数的参数传递。
-
它们可以作为函数的结果返回。
-
它们可以包含在数据结构中。
JavaScript,像其他高级编程语言一样,授予函数完全的第一类状态。这对于高效实现提出了挑战,但由此产生的表达能力的增强是巨大的。
练习 1.40
声明一个函数cubic,它可以与newtons_method函数一起使用,形式如下:
newtons_method(cubic(a, b, c), 1)来近似三次方程x³+ax²+bx+c的零点。
练习 1.41
声明一个函数double,它以一个参数的函数作为参数,并返回一个应用原始函数两次的函数。例如,如果inc是一个将其参数加 1 的函数,则double(inc)应该是一个将其参数加 2 的函数。通过
double(double(double))(inc)(5);练习 1.42
设f和g是两个一元函数。g之后f的组合被定义为函数x -> f (g(x))。声明一个实现组合的函数compose。例如,如果inc是一个将其参数加 1 的函数,
compose(square, inc)(6);
49练习 1.43
如果f是一个数值函数,n是一个正整数,那么我们可以形成f的n次重复应用,它被定义为其在x处的值是f(f(...(f(x))...))。例如,如果f是函数x -> x + 1,那么f的n次重复应用是函数x -> x + n。如果f是平方数的操作,那么f的n次重复应用是将其参数提高到2ⁿ次幂的函数。编写一个函数,它以计算f的函数和一个正整数n作为输入,并返回计算f的n次重复应用的函数。您的函数应该能够像下面这样使用:
repeated(square, 2)(5);
625提示:您可能会发现使用练习 1.42 中的compose很方便。
练习 1.44
平滑函数的概念是信号处理中的重要概念。如果f是一个函数,dx是一个小数,那么f的平滑版本是一个函数,其在点x的值是f(x-dx)、f(x)和f(x+dx)的平均值。编写一个函数smooth,它以计算f的函数作为输入,并返回一个计算平滑f的函数。有时重复平滑一个函数(即平滑平滑的函数,依此类推)是有价值的,以获得n次平滑函数。展示如何使用练习 1.43 中的smooth和repeated生成任何给定函数的n次平滑函数。
练习 1.45
在 1.3.3 节中,我们看到通过天真地寻找y -> x / y的不动点来计算平方根并不收敛,这可以通过平均阻尼来修复。同样的方法也适用于寻找立方根,作为平均阻尼y -> x / y²的不动点。不幸的是,这个过程对于四次方根并不适用——单一的平均阻尼不足以使y -> x / y³的不动点搜索收敛。另一方面,如果我们进行两次平均阻尼(即使用y -> x / y³的平均阻尼的平均阻尼),不动点搜索就会收敛。进行一些实验,以确定计算n次方根所需的平均阻尼次数,作为基于y -> x/y^(n–1)的重复平均阻尼的不动点搜索。使用这个来实现一个简单的函数,使用fixed_point、average_damp和练习 1.43 的repeated函数来计算n次方根。假设你需要的任何算术运算都可以作为原语使用。
练习 1.46
本章描述的几种数值方法都是极其一般的计算策略迭代改进的实例。迭代改进说,为了计算某事物,我们从一个初始猜测开始,测试猜测是否足够好,否则改进猜测并继续使用改进后的猜测作为新的猜测。编写一个函数iterative_improve,它接受两个函数作为参数:一个用于判断猜测是否足够好的方法,一个用于改进猜测的方法。函数iterative_improve应该返回一个函数作为其值,该函数接受一个猜测作为参数,并持续改进猜测,直到猜测足够好为止。以iterative_improve的术语重写 1.1.7 节的sqrt函数和 1.3.3 节的fixed_point函数。
二、使用数据构建抽象
原文:2 Building Abstractions with Data
译者:飞龙
我们现在来到数学抽象的决定性步骤:我们忘记符号代表什么。...[数学家]不需要闲着;他可以用这些符号进行许多操作,而无需看它们所代表的东西。
——赫尔曼·维尔,《数学思维方式》
在第 1 章,我们集中讨论了计算过程和函数在程序设计中的作用。我们看到了如何使用原始数据(数字)和原始操作(算术操作),如何通过组合、条件语句和参数的使用来组合函数以形成复合函数,以及如何通过使用函数声明来抽象过程。我们看到函数可以被看作是一个过程的局部演变的模式,并且我们对一些常见的过程模式进行了分类、推理和简单的算法分析,这些过程模式体现在函数中。我们还看到,高阶函数通过使我们能够操纵,从而能够根据一般的计算方法进行推理,增强了我们语言的能力。这正是编程的本质的很大一部分。
在本章中,我们将研究更复杂的数据。第 1 章中的所有函数都是针对简单的数值数据进行操作,而简单的数据对于我们希望使用计算解决的许多问题是不够的。程序通常被设计来模拟复杂的现象,往往必须构建具有多个部分的计算对象,以模拟具有多个方面的现实世界现象。因此,虽然我们在第 1 章的重点是通过组合函数来构建抽象函数,但在本章中,我们转向编程语言的另一个关键方面:它提供了一种通过组合数据对象来构建复合数据的手段。
为什么我们希望在编程语言中使用复合数据?出于与希望使用复合函数相同的原因:提高我们设计程序的概念水平,增加设计的模块化,并增强我们语言的表达能力。正如声明函数的能力使我们能够处理比语言的原始操作更高概念水平的过程一样,构建复合数据对象的能力使我们能够处理比语言的原始数据对象更高概念水平的数据。
考虑设计一个系统来执行有理数的算术运算的任务。我们可以想象一个操作add_rat,它接受两个有理数并产生它们的和。就简单数据而言,有理数可以被看作是两个整数:一个分子和一个分母。因此,我们可以设计一个程序,其中每个有理数将由两个整数(一个分子和一个分母)表示,并且add_rat将由两个函数实现(一个产生和的分子,一个产生分母)。但这将是笨拙的,因为我们将需要明确地跟踪哪个分子对应哪个分母。在一个旨在对许多有理数执行许多操作的系统中,这些簿记细节将大大地使程序混乱,更不用说它们对我们的思维会产生什么影响了。如果我们能够“粘合”分子和分母以形成一对——一个复合数据对象,那将会好得多,这样我们的程序就可以以一种一致的方式来操作它,这种方式将有助于将有理数视为一个单一的概念单位。
复合数据的使用还使我们能够增加程序的模块化。如果我们可以直接将有理数作为对象进行操作,那么我们就可以将处理有理数本身的程序部分与有理数如何表示为整数对的细节分开。隔离处理数据对象如何表示的程序部分与处理数据对象如何使用的程序部分是一种称为数据抽象的强大设计方法。我们将看到数据抽象如何使程序更容易设计、维护和修改。
复合数据的使用实际上增加了我们编程语言的表达能力。考虑形成“线性组合”ax + by的想法。我们可能希望编写一个函数,接受a、b、x和y作为参数,并返回ax + by的值。如果参数是数字,这没有困难,因为我们可以轻松地声明函数。
function linear_combination(a, b, x, y) {
return a * x + b * y;
}但是,假设我们不仅关心数字。假设我们希望描述一个过程,只要定义了加法和乘法,就可以形成线性组合——对于有理数、复数、多项式或其他任何东西。我们可以将这表达为以下形式的函数。
function linear_combination(a, b, x, y) {
return add(mul(a, x), mul(b, y));
}add和mul不是原始函数+和*,而是更复杂的东西,它们将根据我们传递的参数a、b、x和y执行适当的操作。关键是linear_combination唯一需要知道的是函数add和mul将执行适当的操作。从linear_combination函数的角度来看,a、b、x和y是什么并不重要,甚至更不重要的是它们可能如何以更原始的数据形式表示。这个例子也说明了为什么我们的编程语言提供直接操作复合对象的能力是重要的:如果没有这一点,linear_combination这样的函数就无法将其参数传递给add和mul,而不必知道它们的详细结构。
我们通过实现上面提到的有理数算术系统来开始本章。这将为我们讨论复合数据和数据抽象提供背景。与复合函数一样,需要解决的主要问题是抽象作为一种处理复杂性的技术,我们将看到数据抽象如何使我们能够在程序的不同部分之间建立适当的抽象屏障。
我们将看到形成复合数据的关键在于编程语言应该提供某种“粘合剂”,使得数据对象可以组合成更复杂的数据对象。有许多可能的粘合剂。事实上,我们将发现如何使用没有特殊“数据”操作的函数来形成复合数据。这将进一步模糊“函数”和“数据”的区别,这在第 1 章末尾已经变得模糊。我们还将探讨一些表示序列和树的常规技术。处理复合数据的一个关键思想是闭包的概念——我们用于组合数据对象的粘合剂应该允许我们组合不仅是原始数据对象,还有复合数据对象。另一个关键思想是复合数据对象可以作为常规接口,以混合和匹配的方式组合程序模块。我们通过介绍一个利用闭包的简单图形语言来说明这些想法。
然后,我们将通过引入符号表达式来增强我们语言的表现力——数据的基本部分可以是任意符号,而不仅仅是数字。我们探索表示对象集的各种替代方案。我们将发现,就像给定的数值函数可以通过许多不同的计算过程来计算一样,给定数据结构可以用更简单的对象来表示的方式有很多种,表示的选择对操纵数据的过程的时间和空间要求有重要影响。我们将在符号微分、集合表示和信息编码的背景下研究这些想法。接下来,我们将解决处理可能由程序的不同部分以不同方式表示的数据的问题。这导致需要实现通用操作,这些操作必须处理许多不同类型的数据。在存在通用操作的情况下保持模块化需要比仅使用简单数据抽象建立更强大的抽象屏障。特别是,我们引入数据导向编程作为一种技术,允许单独设计数据表示,然后累加(即不修改)组合这些表示。为了说明这种系统设计方法的强大之处,我们通过将所学应用于在多项式上执行符号算术的包的实现来结束本章,其中多项式的系数可以是整数、有理数、复数,甚至其他多项式。
2.1 数据抽象简介
在 1.1.8 节中,我们注意到一个作为创建更复杂函数的元素使用的函数不仅可以被视为一组特定操作,还可以被视为一个函数抽象。也就是说,可以抑制函数的实现细节,并且可以用具有相同整体行为的任何其他函数来替换特定的函数本身。换句话说,我们可以进行一个抽象,将函数的使用方式与如何使用更基本的函数来实现函数的细节分离。复合数据的类似概念称为数据抽象。数据抽象是一种方法论,使我们能够将复合数据对象的使用方式与它是如何由更基本的数据对象构造出来的细节隔离开来。
数据抽象的基本思想是构造使用复合数据对象的程序,使其操作“抽象数据”。也就是说,我们的程序应该以一种不假设关于数据的任何信息的方式来使用数据,除了执行手头的任务所严格需要的信息。与此同时,“具体”数据表示是独立于使用数据的程序定义的。我们系统的这两部分之间的接口将是一组函数,称为选择器和构造器,它们以具体表示为基础实现抽象数据。为了说明这种技术,我们将考虑如何设计一组用于操作有理数的函数。
2.1.1 示例:有理数的算术运算
假设我们想要对有理数进行算术运算。我们希望能够对它们进行加法、减法、乘法和除法,并测试两个有理数是否相等。
让我们首先假设我们已经有一种方法,可以从分子和分母构造一个有理数。我们还假设,给定一个有理数,我们有一种方法来提取(或选择)它的分子和分母。让我们进一步假设构造器和选择器作为函数是可用的:
-
make_rat(n, d)返回其分子为整数n,分母为整数d的有理数。 -
numer(x)返回有理数x的分子。 -
denom(x)返回有理数x的分母。
我们在这里使用了一种强大的综合策略:wishful thinking。我们还没有说有理数是如何表示的,或者函数numer、denom和make_rat应该如何实现。即使如此,如果我们有了这三个函数,我们就可以通过以下关系来进行加法、减法、乘法、除法和相等性测试:
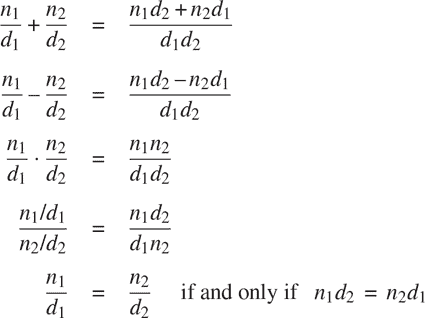
我们可以将这些规则表示为函数:
function add_rat(x, y) {
return make_rat(numer(x) * denom(y) + numer(y) * denom(x),
denom(x) * denom(y));
}
function sub_rat(x, y) {
return make_rat(numer(x) * denom(y) - numer(y) * denom(x),
denom(x) * denom(y));
}
function mul_rat(x, y) {
return make_rat(numer(x) * numer(y),
denom(x) * denom(y));
}
function div_rat(x, y) {
return make_rat(numer(x) * denom(y),
denom(x) * numer(y));
}
function equal_rat(x, y) {
return numer(x) * denom(y) === numer(y) * denom(x);
}现在我们已经定义了有理数的操作,这些操作是基于选择器定义的
和构造函数numer、denom和make_rat。但我们还没有定义这些。我们需要一种方法来将分子和分母粘合在一起形成一个有理数。
对
为了使我们能够实现数据抽象的具体层,我们的 JavaScript 环境提供了一种称为pair的复合结构,它可以用原始函数pair构造。此函数接受两个参数并返回一个包含两个参数作为部分的复合数据对象。给定一个对,我们可以使用原始函数head和tail提取部分。因此,我们可以如下使用pair、head和tail:
const x = pair(1, 2);
head(x);
`1`
tail(x);
`2`注意,对是一个可以被赋予名称并且可以被操作的数据对象,就像原始数据对象一样。此外,pair可以用来形成其元素为对的对,依此类推:
const x = pair(1, 2);
const y = pair(3, 4);
const z = pair(x, y);
head(head(z));
`1`
head(tail(z));
`3`在第 2.2 节中,我们将看到这种组合对的能力意味着对可以用作通用的构建块来创建各种复杂的数据结构。由对构造的数据对象称为列表结构数据。
表示有理数
对提供了一种自然的方式来完成有理数系统。简单地将有理数表示为两个整数的对:一个分子和一个分母。然后make_rat、numer和denom可以如下实现:²
function make_rat(n, d) { return pair(n, d); }
function numer(x) { return head(x); }
function denom(x) { return tail(x); }此外,为了显示我们计算的结果,我们可以通过打印分子、斜杠和分母来打印有理数。我们使用原始函数stringify将任何值(这里是一个数字)转换为字符串。JavaScript 中的运算符+是重载的;它可以应用于两个数字或两个字符串,在后一种情况下,它返回连接两个字符串的结果。³
function print_rat(x) {
return display(stringify(numer(x)) + " / " + stringify(denom(x)));
}现在我们可以尝试我们的有理数函数:⁴
const one_half = make_rat(1, 2);
print_rat(one_half);
"1 / 2"
const one_third = make_rat(1, 3);
print_rat(add_rat(one_half, one_third));
"5 / 6"
print_rat(mul_rat(one_half, one_third));
"1 / 6"
print_rat(add_rat(one_third, one_third));
"6 / 9"正如最后一个例子所示,我们的有理数实现没有将有理数化简为最低项。我们可以通过更改make_rat来解决这个问题。如果我们有一个像第 1.2.5 节中那样产生两个整数的最大公约数的gcd函数,我们可以使用gcd在构造对之前将分子和分母化简为最低项:
function make_rat(n, d) {
const g = gcd(n, d);
return pair(n / g, d / g);
}现在我们有
print_rat(add_rat(one_third, one_third));
"2 / 3"如所需。通过更改构造函数make_ rat而不更改实现实际操作的任何函数(如add_rat和mul_rat),已完成此修改。
练习 2.1
定义一个更好的make_rat版本,处理正数和负数参数。函数make_rat应该规范化符号,以便如果有理数是正数,则分子和分母都是正数,如果有理数是负数,则只有分子是负数。
2.1.2 抽象屏障
在继续介绍复合数据和数据抽象的更多示例之前,让我们考虑一下有理数示例引发的一些问题。我们用构造函数make_rat和选择器numer和denom来定义有理数运算。一般来说,数据抽象的基本思想是为每种数据对象类型确定一组基本操作,通过这些操作来表达对该类型数据对象的所有操作,然后在操作数据时只使用这些操作。
我们可以将有理数系统的结构设想为图 2.1 所示。水平线代表抽象屏障,隔离系统的不同“层级”。在每个层级,该屏障将使用数据抽象的程序(上方)与实现数据抽象的程序(下方)分开。使用有理数的程序仅通过有理数包提供的“供公共使用”的函数来操作它们:add_rat、sub_rat、mul_rat、div_rat和equal_rat。这些函数又仅仅是通过构造函数和选择器make_rat、numer和denom来实现的,它们本身是通过对偶实现的。对偶的具体实现细节对于有理数包的其余部分来说是无关紧要的,只要对偶可以通过pair、head和tail来操作。实际上,每个层级的函数都是定义抽象屏障并连接不同层级的接口。这个简单的想法有很多优点。其中一个优点是它使程序更容易维护和修改。任何复杂的数据结构都可以用编程语言提供的原始数据结构的多种方式来表示。当然,表示的选择会影响操作它的程序;因此,如果表示在以后的某个时间被更改,所有这样的程序可能都必须相应地进行修改。对于大型程序来说,这个任务可能会耗费大量时间和金钱,除非通过设计将对表示的依赖限制在非常少的程序模块中。
图 2.1 有理数包中的数据抽象屏障。
例如,解决将有理数化简为最低项的问题的另一种方法是在访问有理数的部分时执行化简,而不是在构造有理数时执行。这导致了不同的构造函数和选择器函数:
function make_rat(n, d) {
return pair(n, d);
}
function numer(x) {
const g = gcd(head(x), tail(x));
return head(x) / g;
}
function denom(x) {
const g = gcd(head(x), tail(x));
return tail(x) / g;
}这种实现与之前的实现的不同之处在于我们何时计算gcd。如果在我们典型的有理数使用中,我们多次访问相同有理数的分子和分母,那么在构造有理数时计算gcd会更好。如果不是,我们可能最好等到访问时计算gcd。无论如何,当我们从一种表示形式改变为另一种表示形式时,函数add_rat、sub_rat等都不需要进行任何修改。
将对表示的依赖限制在少数接口函数中有助于我们设计程序以及修改程序,因为它允许我们保持灵活性来考虑替代实现。继续我们的简单例子,假设我们正在设计一个有理数包,最初无法确定是在构造时还是在选择时执行gcd。数据抽象方法为我们提供了一种推迟决定而不失去在系统的其余部分上取得进展的方法。
练习 2.2
考虑在平面上表示线段的问题。每个线段都表示为一对点:起点和终点。声明一个构造器make_segment和选择器start_segment和end_segment,以点的形式定义线段的表示。此外,一个点可以表示为一对数字:x坐标和y坐标。因此,指定一个构造器make_point和选择器x_point和y_point来定义这种表示。最后,使用您的选择器和构造器,声明一个函数midpoint_segment,它以线段作为参数并返回其中点(坐标是端点坐标的平均值)。要尝试您的函数,您需要一种打印点的方法:
function print_point(p) {
return display("(" + stringify(x_point(p)) + ", "
+ stringify(y_point(p)) + ")");
}练习 2.3
在平面上实现矩形的表示。 (提示:您可能需要使用练习 2.2。)根据您的构造器和选择器,创建计算给定矩形的周长和面积的函数。现在实现矩形的不同表示。您能否设计您的系统,使得具有合适的抽象屏障,以便相同的周长和面积函数将使用任一表示?
2.1.3 数据的含义是什么?
我们在 2.1.1 节中开始了有理数的实现,通过实现有理数操作add_rat,sub_rat等,这些操作是根据三个未指定的函数make_rat,numer和denom来定义的。在那时,我们可以认为这些操作是根据数据对象——分子、分母和有理数——来定义的,后三个函数规定了它们的行为。
但是,数据究竟是什么意思?仅仅说“由给定的选择器和构造器实现的任何东西”是不够的。显然,并非每一组任意的三个函数都可以作为有理数实现的适当基础。我们需要保证,如果我们从一对整数n和d构造一个有理数x,那么提取x的numer和denom并将它们相除应该得到与n除以d相同的结果。换句话说,make_rat,numer和denom必须满足这样的条件,对于任何整数n和任何非零整数d,如果x是make_rat(n, d),那么
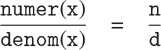
事实上,这是make_rat,numer和denom必须满足的唯一条件,以形成有理数表示的合适基础。一般来说,我们可以认为数据是由一些选择器和构造器的集合定义的,以及这些函数必须满足的指定条件,以便成为有效的表示。[5]
这种观点不仅可以用来定义“高级”数据对象,比如有理数,还可以用来定义更低级的对象。考虑一对的概念,我们用它来定义我们的有理数。我们从来没有说过一对是什么,只是语言提供了用于操作对的函数pair,head和tail。但我们只需要知道关于这三个操作的唯一事情是,如果我们使用pair将两个对象粘合在一起,我们可以使用head和tail来检索对象。也就是说,这些操作满足这样的条件,对于任何对象x和y,如果z是pair(x, y),那么head(z)是x,tail(z)是y。事实上,我们提到这三个函数是作为原语包含在我们的语言中的。然而,任何满足上述条件的三个函数的三元组都可以用作实现对的基础。这一点通过这样一个事实引人注目,即我们可以实现pair,head和tail而不使用任何数据结构,只使用函数。以下是定义:[6]
function pair(x, y) {
function dispatch(m) {
return m === 0
? x
: m === 1
? y
: error(m, "argument not 0 or 1 – pair");
}
return dispatch;
}
function head(z) { return z(0); }
function tail(z) { return z(1); }这种使用函数的方法与我们对数据的直观概念完全不同。然而,要证明这是表示对偶的有效方式,我们只需要验证这些函数是否满足上面给出的条件。
要注意的微妙之处是pair(x, y)返回的值是一个函数——即内部定义的函数dispatch,它接受一个参数,并根据参数是 0 还是 1 返回x或y。相应地,head(z)被定义为将 0 应用于z。因此,如果z是由pair(x, y)形成的函数,那么将 0 应用于z将产生x。因此,我们已经证明了head(pair(x, y))产生x,就像我们希望的那样。类似地,tail(pair(x, y))将由pair(x, y)返回的函数应用于 1,返回y。因此,这种对偶的函数实现是有效的实现,如果我们只使用pair、head和tail来访问对偶,我们无法将这种实现与使用“真实”数据结构的实现区分开。
展示对偶的函数表示的重点不在于我们的语言是否以这种方式工作(对偶的高效实现可能会使用 JavaScript 的原始向量数据结构),而在于它可以以这种方式工作。函数表示,虽然晦涩,但是是表示对偶的完全足够的方式,因为它满足对偶需要满足的唯一条件。这个例子还表明,能够操作函数作为对象自动提供了表示复合数据的能力。现在这可能看起来像是一种奇特现象,但是数据的函数表示将在我们的编程技能中扮演一个核心角色。这种编程风格通常被称为消息传递,当我们在第 3 章讨论建模和模拟的问题时,我们将把它作为一个基本工具来使用。
练习 2.4
这里是对对偶的另一种函数表示。对于这种表示,验证head(pair(x, y))对于任何对象x和y都产生x。
function pair(x, y) {
return m => m(x, y);
}
function head(z) {
return z((p, q) => p);
}tail的对应定义是什么?(提示:要验证这个定义是否有效,可以利用第 1.1.5 节的替换模型。)
练习 2.5
证明我们可以只使用数字和算术运算来表示非负整数对,如果我们将对偶a和b表示为乘积2^a3^b的整数。给出函数pair、head和tail的相应定义。
练习 2.6
如果将对偶表示为函数(练习 2.4)还不够令人费解,那么可以考虑,在一个可以操作函数的语言中,我们可以通过实现 0 和加 1 的操作来不使用数字(至少就非负整数而言):
const zero = f => x => x;
function add_1(n) {
return f => x => f(n(f)(x));
}这种表示被称为Church 数,以其发明者阿隆佐·邱奇命名,他是发明λ演算的逻辑学家。
直接定义one和two(不要用zero和add_1)。(提示:使用替换来计算add_1(zero))。直接定义加法函数plus(不要用重复应用add_1)。
2.1.4 扩展练习:区间算术
Alyssa P. Hacker 正在设计一个帮助人们解决工程问题的系统。她希望在她的系统中提供一个功能,可以处理不精确的数量(例如物理设备的测量参数),并且知道精度,这样当使用这种近似数量进行计算时,结果将是已知精度的数字。
电气工程师将使用 Alyssa 的系统来计算电气量。有时,他们需要使用以下公式计算两个电阻R[1]和R[2]的并联等效电阻R[p]的值

电阻值通常只能知道制造商保证的一定公差。例如,如果你购买一个标有“6.8 欧姆,公差 10%”的电阻器,你只能确定电阻器的电阻在 6.8 - 0.68 = 6.12 和 6.8 + 0.68 = 7.48 欧姆之间。因此,如果你有一个 6.8 欧姆 10%的电阻器与一个 4.7 欧姆 5%的电阻器并联,组合的电阻可以在大约 2.58 欧姆(如果两个电阻器在下限)到大约 2.97 欧姆(如果两个电阻器在上限)之间变化。
Alyssa 的想法是将“区间算术”实现为一组用于组合“区间”的算术操作(表示不精确数量的可能值范围的对象)。将两个区间相加、相减、相乘或相除的结果本身是一个区间,表示结果的范围。
Alyssa 假设存在一个称为“区间”的抽象对象,它有两个端点:一个下限和一个上限。她还假设,给定区间的端点,她可以使用数据构造函数make_interval构造区间。Alyssa 首先编写了一个函数来添加两个区间。她推断出和的最小值是两个下限的和,最大值是两个上限的和:
function add_interval(x, y) {
return make_interval(lower_bound(x) + lower_bound(y),
upper_bound(x) + upper_bound(y));
}Alyssa 还通过找到边界的最小值和最大值来计算两个区间的乘积,并将它们用作结果区间的边界。(函数math_min和math_max是原始函数,用于找到任意数量参数的最小值或最大值。)
function mul_interval(x, y) {
const p1 = lower_bound(x) * lower_bound(y);
const p2 = lower_bound(x) * upper_bound(y);
const p3 = upper_bound(x) * lower_bound(y);
const p4 = upper_bound(x) * upper_bound(y);
return make_interval(math_min(p1, p2, p3, p4),
math_max(p1, p2, p3, p4));
}要划分两个区间,Alyssa 将第一个乘以第二个的倒数。注意倒数区间的边界是上限的倒数和下限的倒数,按顺序排列。
function div_interval(x, y) {
return mul_interval(x, make_interval(1 / upper_bound(y),
1 / lower_bound(y)));
}练习 2.7
Alyssa 的程序是不完整的,因为她没有指定区间抽象的实现。这里是区间构造函数的定义:
function make_interval(x, y) { return pair(x, y); }定义选择器upper_bound和lower_bound来完成实现。
练习 2.8
使用类似 Alyssa 的推理,描述如何计算两个区间的差。定义一个相应的减法函数,称为sub_interval。
练习 2.9
区间的宽度是其上限和下限之间的差的一半。宽度是区间指定的数字的不确定性的度量。对于一些算术操作,组合两个区间的结果的宽度仅取决于参数区间的宽度,而对于其他一些算术操作,组合的宽度并不是参数区间的宽度的函数。证明两个区间的和(或差)的宽度仅取决于要添加(或减去)的区间的宽度。举例说明,这对于乘法或除法来说并不成立。
练习 2.10
专家系统程序员 Ben Bitdiddle 看着 Alyssa 的肩膀,评论说不清楚通过跨越零的区间进行除法意味着什么。修改 Alyssa 的程序以检查这种情况,并在发生时发出错误信号。
练习 2.11
顺便说一句,Ben 也神秘地评论说:“通过测试区间端点的符号,可以将mul_interval分解为九种情况,其中只有一种需要超过两次乘法。”使用 Ben 的建议重写这个函数。
调试完她的程序后,Alyssa 将其展示给一个潜在的用户,后者抱怨说她的程序解决了错误的问题。他想要一个能够处理以中心值和加法公差表示的数字的程序;例如,他想要处理像 3.5 ± 0.15 这样的区间,而不是[3.35, 3.65]。Alyssa 回到她的桌子上,通过提供一个替代构造函数和替代选择器来解决这个问题:
function make_center_width(c, w) {
return make_interval(c - w, c + w);
}
function center(i) {
return (lower_bound(i) + upper_bound(i)) / 2;
}
function width(i) {
return (upper_bound(i) - lower_bound(i)) / 2;
}不幸的是,Alyssa 的大多数用户都是工程师。真正的工程情况通常涉及只有小不确定性的测量,测量值是区间宽度与区间中点的比率。工程师通常会在设备参数上指定百分比的容差,就像前面给出的电阻器规格一样。
练习 2.12
定义一个构造函数make_center_percent,它接受一个中心和一个百分比容差,并产生所需的区间。你还必须定义一个选择器percent,它为给定的区间产生百分比容差。center选择器与上面显示的相同。
练习 2.13
证明在小百分比容差的假设下,有一个简单的公式可以用因子的容差来近似计算两个区间的乘积的百分比容差。你可以通过假设所有数字都是正数来简化这个问题。
经过相当多的工作,Alyssa P. Hacker 交付了她的成品系统。几年后,当她已经忘记了这一切时,她接到了一个愤怒的用户 Lem E. Tweakit 的电话。看来 Lem 已经注意到并联电阻的公式可以用两种代数上等价的方式来写:
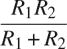
并且
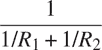
他写了以下两个程序,每个程序都以不同的方式计算并联电阻的公式:
function par1(r1, r2) {
return div_interval(mul_interval(r1, r2),
add_interval(r1, r2));
}
function par2(r1, r2) {
const one = make_interval(1, 1);
return div_interval(one,
add_interval(div_interval(one, r1),
div_interval(one, r2)));
}Lem 抱怨 Alyssa 的程序对于两种计算方式给出了不同的答案。这是一个严重的投诉。
练习 2.14
证明 Lem 是对的。研究系统对各种算术表达式的行为。创建一些区间A和B,并在计算表达式A / A和A / B时使用它们。通过使用宽度是中心值的小百分比的区间,你将获得最多的见解。以中心百分比形式检查计算结果(参见练习 2.12)。
练习 2.15
另一位用户 Eva Lu Ator 也注意到了不同的区间是由不同但代数上等价的表达式计算出来的。她说,使用 Alyssa 的系统计算区间的公式,如果可以以不重复代表不确定数字的名称的形式编写,将产生更紧的误差界限。因此,她说,par2比par1是一个“更好”的并联电阻程序。她是对的吗?为什么?
练习 2.16
一般来说,解释等价的代数表达式可能导致不同的答案。你能设计一个没有这个缺点的区间算术包吗,还是这个任务是不可能的?(警告:这个问题非常困难。)
2.2 分层数据和闭包性质
正如我们所看到的,一对提供了一个原始的“粘合剂”,我们可以用它来构造复合数据对象。图 2.2 显示了一种标准的可视化一对的方法——在这种情况下,是由pair(1, 2)形成的一对。在这种表示中,称为盒式和指针表示法,每个复合对象都显示为指向一个盒子的指针。一对的盒子有两部分,左部分包含一对的头部,右部分包含尾部。
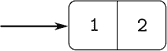
图 2.2 pair(1, 2)的盒式图表示。
我们已经看到pair不仅可以用来组合数字,还可以用来组合一对。 (你在做练习 2.2 和 2.3 时已经利用了这一事实,或者应该利用了。)因此,一对提供了一个通用的构建块,我们可以用它来构造各种数据结构。图 2.3 显示了使用一对组合数字 1、2、3 和 4 的两种方法。
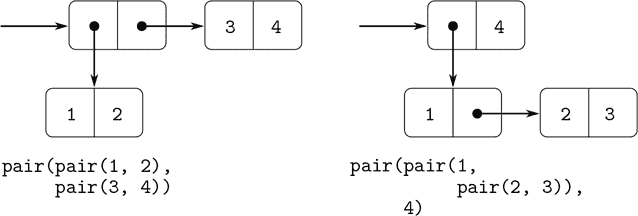
图 2.3 使用一对的两种组合 1、2、3 和 4 的方法。
创建元素为对的对的能力是列表结构作为表示工具的重要性的本质。我们将这种能力称为pair的闭包属性。一般来说,如果组合数据对象的操作满足闭包属性,那么使用该操作组合的结果本身可以使用相同的操作进行组合。⁷ 闭包是任何组合手段中权力的关键,因为它允许我们创建分层结构——由部分组成的结构,这些部分本身又由部分组成,依此类推。
从第 1 章开始,我们在处理函数时已经基本使用了闭包,因为除了非常简单的程序之外,所有程序都依赖于组合的元素本身可以是组合的事实。在本节中,我们将讨论闭包对于复合数据的影响。我们描述了一些使用对来表示序列和树的传统技术,并展示了一种图形语言,以生动的方式说明了闭包。
2.2.1 表示序列
我们可以使用对构建一种序列,即有序的数据对象集合。当然,有许多方法可以用对来表示序列。其中一种特别直接的表示方法如图 2.4 所示,其中序列 1, 2, 3, 4 被表示为一系列对。每对的head是链中对应的项目,而对的tail是链中的下一个对。最后一对的tail表示序列的结尾,在盒子和指针图中表示为对角线,而在程序中表示为 JavaScript 的原始值null。整个序列是通过嵌套的pair操作构建的:

图 2.4 序列 1, 2, 3, 4 表示为一系列对。
pair(1,
pair(2,
pair(3,
pair(4, null))));由嵌套的pair应用形成的这样一系列对称为列表,我们的 JavaScript 环境提供了一个名为list的原语来帮助构建列表。⁸ 上述序列可以通过list(1, 2, 3, 4)生成。一般来说,
list(`a[1]`, `a[2], ..., `a[n]`)等同于
pair(`a[1]`, pair(`a[2]`, pair(..., pair(a[n], null)...)))我们的解释器使用盒子和指针图的文本表示来打印对。pair(1, 2)的结果打印为1, 2],[图 2.4 中的数据对象打印为[1, [2, [3, [4, null]]]]:
const one_through_four = list(1, 2, 3, 4);
one_through_four;
[1, [2, [3, [4, null]]]]我们可以将head视为选择列表中的第一项,将tail视为选择除第一项外的所有子列表。可以使用嵌套的head和tail应用来提取列表中的第二、第三和后续项。构造函数pair使得像原始列表一样的列表,但在开头增加了一个额外的项目。
head(one_through_four);
1
tail(one_through_four);
[2, [3, [4, null]]]
head(tail(one_through_four));
2
pair(10, one_through_four);
[10, [1, [2, [3, [4, null]]]]]
pair(5, one_through_four);
[5, [1, [2, [3, [4, null]]]]]用于终止对链的值null可以被视为没有元素的序列,即空列表。⁹
盒子表示法有时很难阅读。在本书中,当我们想要指示数据结构的列表性质时,我们将使用另一种列表表示法:在可能的情况下,列表表示法使用list的应用,其求值将导致所需的结构。例如,代替盒子表示法
*[1, [[2, 3], [[4, [5, null]], [6, null]]]]*我们写
list(1, [2, 3], list(4, 5), 6)在列表表示法中。¹⁰
列表操作
使用对来表示列表中元素的序列的方法伴随着传统的编程技术,通过连续使用tail来遍历列表。例如,函数list_ref以列表和数字n作为参数,并返回列表的第n项。习惯上从 0 开始对列表的元素进行编号。计算list_ref的方法如下:
-
对于
n = 0,list_ref应返回列表的head。 -
否则,
list_ref应返回列表的tail的(n – 1)项。
function list_ref(items, n) {
return n === 0
? head(items)
: list_ref(tail(items), n - 1);
}
const squares = list(1, 4, 9, 16, 25);
list_ref(squares, 3);
16通常我们会遍历整个列表。为了帮助实现这一点,我们的 JavaScript 环境包括一个原始谓词is_null,用于测试其参数是否为空列表。返回列表中项目的数量的函数length说明了这种典型的使用模式:
function length(items) {
return is_null(items)
? 0
: 1 + length(tail(items));
}
const odds = list(1, 3, 5, 7);
length(odds);
`4`length函数实现了一个简单的递归计划。减少步骤是:
- 任何列表的
length都是tail的length加 1。
这将一直应用,直到达到基本情况:
- 空列表的
length为 0。
我们也可以以迭代的方式计算length:
function length(items) {
function length_iter(a, count) {
return is_null(a)
? count
: length_iter(tail(a), count + 1);
}
return length_iter(items, 0);
}另一种常规的编程技术是通过使用pair将元素附加到列表的前面来构造一个答案列表,同时使用tail在列表中行走,就像函数append中那样,该函数接受两个列表作为参数并组合它们的元素以生成一个新列表:
append(squares, odds);
list(1, 4, 9, 16, 25, 1, 3, 5, 7)
append(odds, squares);
list(1, 3, 5, 7, 1, 4, 9, 16, 25)函数append也是使用递归计划实现的。要append列表list1和list2,请执行以下操作:
-
如果
list1是空列表,则结果就是list2。 -
否则,
appendlist1的tail和list2,并将list1的head添加到结果中:
function append(list1, list2) {
return is_null(list1)
? list2
: pair(head(list1), append(tail(list1), list2));
}练习 2.17
定义一个函数last_pair,返回一个只包含给定(非空)列表的最后一个元素的列表:
last_pair(list(23, 72, 149, 34));
list(34)练习 2.18
定义一个函数reverse,它以列表作为参数并返回相同元素的逆序列表:
reverse(list(1, 4, 9, 16, 25));
list(25, 16, 9, 4, 1)练习 2.19
考虑第 1.2.2 节的找零程序。很高兴能够轻松更改程序使用的货币,这样我们就可以计算例如英镑的找零方式。按照程序的编写方式,货币的知识部分分布在函数first_denomination和函数count_change中(它知道有五种美国硬币)。最好能够提供要用于找零的硬币列表。
我们想要重写函数cc,使得它的第二个参数是要使用的硬币的值的列表,而不是指定要使用哪些硬币的整数。然后我们可以有定义每种货币的列表:
const us_coins = list(50, 25, 10, 5, 1);
const uk_coins = list(100, 50, 20, 10, 5, 2, 1);然后我们可以这样调用cc:
cc(100, us_coins);
292这将需要在一定程度上更改程序cc。它仍然具有相同的形式,但将以不同的方式访问其第二个参数,如下所示:
function cc(amount, coin_values) {
return amount === 0
? 1
: amount < 0 || no_more(coin_values)
? 0
: cc(amount, except_first_denomination(coin_values)) +
cc(amount - first_denomination(coin_values), coin_values);
}根据列表结构的原始操作定义函数first_denomination、except_first_denomination和no_more。列表coin_values的顺序是否会影响cc产生的答案?为什么?
练习 2.20
在高阶函数的存在下,函数不一定需要有多个参数;一个就足够了。如果我们有一个像plus这样自然需要两个参数的函数,我们可以编写一个函数的变体,逐个传递参数。将变体应用于第一个参数可能会返回一个函数,然后我们可以将其应用于第二个参数,依此类推。这种做法——称为柯里化,以美国数学家和逻辑学家 Haskell Brooks Curry 命名——在 Haskell 和 OCaml 等编程语言中非常常见。在 JavaScript 中,plus的柯里化版本如下。
function plus_curried(x) {
return y => x + y;
}编写一个函数brooks,它以柯里化函数作为第一个参数,并以柯里化函数应用的给定顺序逐个应用作为第二个参数的参数列表。例如,brooks的以下应用应该与plus_curried(3)(4)具有相同的效果:
brooks(plus_curried, list(3, 4));
`7`趁热打铁,我们也可以对函数brooks进行柯里化!编写一个函数brooks_curried,可以按以下方式应用:
brooks_curried(list(plus_curried, 3, 4));
`7`使用这个函数brooks_curried,求值以下两个语句的结果是什么?
brooks_curried(list(brooks_curried,
list(plus_curried, 3, 4)));
brooks_curried(list(brooks_curried,
list(brooks_curried,
list(plus_curried, 3, 4))));对列表进行映射
有一个非常有用的操作是对列表中的每个元素应用一些转换,并生成结果列表。例如,以下函数通过给定的因子来缩放列表中的每个数字:
function scale_list(items, factor) {
return is_null(items)
? null
: pair(head(items) * factor,
scale_list(tail(items), factor));
}
scale_list(list(1, 2, 3, 4, 5), 10);
*[10, [20, [30, [40, [50, null]]]]]*我们可以将这个一般的想法抽象出来,并将其作为一个通用模式表达为一个高阶函数,就像在 1.3 节中一样。这里的高阶函数称为map。函数map接受一个参数和一个列表,并返回通过将函数应用于列表中的每个元素产生的结果列表:
function map(fun, items) {
return is_null(items)
? null
: pair(fun(head(items)),
map(fun, tail(items)));
}
map(abs, list(-10, 2.5, -11.6, 17));
*[10, [2.5, [11.6, [17, null]]]]*
map(x => x * x, list(1, 2, 3, 4));
*[1, [4, [9, [16, null]]]]*现在我们可以通过map给出scale_list的新定义:
function scale_list(items, factor) {
return map(x => x * factor, items);
}函数map是一个重要的构造,不仅因为它捕捉了一个常见的模式,而且因为它在处理列表时建立了一个更高的抽象级别。在scale_list的原始定义中,程序的递归结构引起了对列表的逐个处理的注意。通过map定义scale_list抑制了那个细节级别,并强调了缩放将元素列表转换为结果列表。这两个定义之间的区别不是计算机执行了不同的过程(它没有),而是我们对过程的思考方式不同。实际上,map有助于建立一个抽象屏障,将转换列表的函数的实现与提取和组合列表元素的细节隔离开来。就像图 2.1 中显示的屏障一样,这种抽象给了我们改变序列如何实现的低级细节的灵活性,同时保留了将序列转换为序列的操作的概念框架。2.2.3 节扩展了这种将序列作为组织程序的框架的用法。
练习 2.21
函数square_list接受一个数字列表作为参数,并返回这些数字的平方列表。
square_list(list(1, 2, 3, 4));
*[1, [4, [9, [16, null]]]]*这里有两种不同的square_list的定义。通过填写缺失的表达式来完成它们:
function square_list(items) {
return is_null(items)
? null
: pair(〈??〉, 〈??〉);
}
function square_list(items) {
return map(〈??〉, 〈??〉);
}练习 2.22
Louis Reasoner 试图重写练习 2.21 的第一个square_list函数,以便它演变成一个迭代过程:
function square_list(items) {
function iter(things, answer) {
return is_null(things)
? answer
: iter(tail(things),
pair(square(head(things)),
answer));
}
return iter(items, null);
}不幸的是,用这种方式定义square_list会产生与期望的相反顺序的答案列表。为什么?
然后 Louis 尝试通过交换pair的参数来修复他的错误:
function square_list(items) {
function iter(things, answer) {
return is_null(things)
? answer
: iter(tail(things),
pair(answer,
square(head(things))));
}
return iter(items, null);
}这也不起作用。解释一下。
练习 2.23
函数for_each类似于map。它接受一个函数和一个元素列表作为参数。但是,for_each不会形成结果列表,而是依次对每个元素应用函数,从左到右。应用函数到元素后返回的值根本不会被使用——for_each用于执行动作的函数,比如打印。例如,
for_each(x => display(x), list(57, 321, 88));
57
321
88调用for_each(上面未显示)的返回值可以是任意的,比如true。给出for_each的实现。
2.2.2 分层结构
以列表的形式表示序列的表示自然地推广到表示元素本身可以是序列的序列。例如,我们可以将由[[1, [2, null]], [3, [4, null]]]构成的对象视为
pair(list(1, 2), list(3, 4));作为一个包含三个项目的列表,第一个项目本身是一个列表,1, [2, null]]。[图 2.5 显示了这个结构的表示形式。
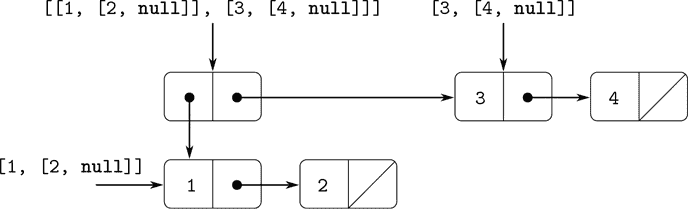
图 2.5 pair(list(1, 2), list(3, 4))形成的结构。
将元素为序列的序列视为树的另一种方式。序列的元素是树的分支,而元素本身是序列的元素是子树。图 2.6 显示了图 2.5 中的结构被视为树。
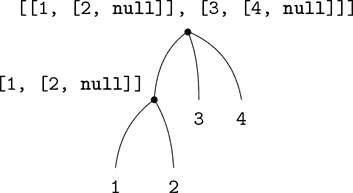
图 2.6 图 2.5 中的列表结构被视为树。
递归是处理树结构的自然工具,因为我们通常可以将树上的操作减少到对其分支的操作,这些操作反过来又减少到对分支的分支的操作,依此类推,直到达到树的叶子。例如,比较第 2.2.1 节的length函数和count_leaves函数,后者返回树的总叶子数:
const x = pair(list(1, 2), list(3, 4));
length(x);
`3`
count_leaves(x);
`4`
list(x, x);
list(list(list(1, 2), 3, 4), list(list(1, 2), 3, 4))
length(list(x, x));
`2`
count_leaves(list(x, x));
`8`要实现count_leaves,请回想一下计算length的递归计划:
-
列表
x的length是 1 加上x的tail的length。 -
空列表的
length为 0。
函数count_leaves类似。空列表的值是相同的:
- 空列表的
count_leaves为 0。
但在减少步骤中,我们剥离列表的head时,我们必须考虑到head本身可能是一个我们需要计算叶子的树。因此,适当的减少步骤是
- 树
x的count_leaves是x的head的count_leaves加上x的tail的count_leaves。
最后,通过取head,我们到达实际的叶子,因此我们需要另一个基本情况:
- 叶子的
count_leaves为 1。
为了帮助编写树的递归函数,我们的 JavaScript 环境提供了原始谓词is_pair,用于测试其参数是否为对。以下是完整的函数:¹¹
function count_leaves(x) {
return is_null(x)
? 0
: ! is_pair(x)
? 1
: count_leaves(head(x)) + count_leaves(tail(x));
}练习 2.24
假设我们求值表达式list(1, list(2, list(3, 4)))。给出解释器打印的结果,相应的框和指针结构,以及将其解释为树的解释(如图 2.6 中所示)。
练习 2.25
给出head和tail的组合,将从以下每个列表中挑选出 7 个,以列表表示:
list(1, 3, list(5, 7), 9)
list(list(7))
list(1, list(2, list(3, list(4, list(5, list(6, 7))))))练习 2.26
假设我们定义x和y为两个列表:
const x = list(1, 2, 3);
const y = list(4, 5, 6);求值以下每个表达式的结果是什么,以框表示法和列表表示法?
append(x, y)
pair(x, y)
list(x, y)练习 2.27
修改练习 2.18 的reverse函数,以生成一个deep_reverse函数,该函数以列表作为参数,并将其值作为其元素反转,并且所有子列表也进行深度反转。例如,
const x = list(list(1, 2), list(3, 4));
x;
list(list(1, 2), list(3, 4))
reverse(x);
list(list(3, 4), list(1, 2))
deep_reverse(x);
list(list(4, 3), list(2, 1))练习 2.28
编写一个名为fringe的函数,该函数以树(表示为列表)作为参数,并返回一个列表,其中的元素都是树的叶子,按从左到右的顺序排列。例如,
const x = list(list(1, 2), list(3, 4));
fringe(x);
list(1, 2, 3, 4)
fringe(list(x, x));
list(1, 2, 3, 4, 1, 2, 3, 4)练习 2.29
二进制移动由两个分支组成,左分支和右分支。每个分支都是一根特定长度的杆,从中悬挂着一个重量或另一个二进制移动。我们可以使用复合数据来表示二进制移动,通过从两个分支构造它(例如,使用list):
function make_mobile(left, right) {
return list(left, right);
}分支由length(必须是数字)和structure(可以是数字(表示简单重量)或另一个移动)组成:
function make_branch(length, structure) {
return list(length, structure);
}-
a.编写相应的选择器
left_branch和right_branch,它们返回移动的分支,以及branch_length和branch_structure,它们返回分支的组件。 -
b.使用您的选择器,定义一个名为
total_weight的函数,返回移动的总重量。 -
c.如果移动的顶部左分支施加的力矩等于顶部右分支施加的力矩(也就是说,如果左杆的长度乘以悬挂在该杆上的重量等于右侧对应的乘积),并且挂在其分支上的每个子移动都是平衡的,则称移动为平衡。设计一个谓词,测试二进制移动是否平衡。
-
d.假设我们更改移动的表示形式,使构造函数为
function make_mobile(left, right) { return pair(left, right); } function make_branch(length, structure) { return pair(length, structure); }您需要更改程序以转换为新表示形式吗?
对树进行映射
就像map是处理序列的强大抽象一样,map和递归一起是处理树的强大抽象。例如,scale_tree函数类似于 2.2.1 节的scale_list,它的参数是一个数字因子和一个叶子为数字的树。它返回一个相同形状的树,其中每个数字都乘以因子。scale_tree的递归计划类似于count_leaves的计划:
function scale_tree(tree, factor) {
return is_null(tree)
? null
: ! is_pair(tree)
? tree * factor
: pair(scale_tree(head(tree), factor),
scale_tree(tail(tree), factor));
}
scale_tree(list(1, list(2, list(3, 4), 5), list(6, 7)),
10);
list(10, list(20, list(30, 40), 50), list(60, 70))另一种实现scale_tree的方法是将树视为子树序列,并使用map。我们在序列上进行映射,依次缩放每个子树,并返回结果列表。在基本情况下,树是叶子时,我们只需乘以因子:
function scale_tree(tree, factor) {
return map(sub_tree => is_pair(sub_tree)
? scale_tree(sub_tree, factor)
: sub_tree * factor,
tree);
}许多树操作可以通过类似的序列操作和递归的组合来实现。
练习 2.30
声明一个类似于练习 2.21 的square_list函数的函数square_tree。也就是说,square_tree应该表现如下:
square_tree(list(1,
list(2, list(3, 4), 5),
list(6, 7)));
list(1, list(4, list(9, 16), 25), list(36, 49)))声明square_tree,既直接(即,不使用任何高阶函数),也使用map和递归。
练习 2.31
将您对练习 2.30 的答案抽象化,以生成一个具有square_tree属性的函数tree_map,可以声明为
function square_tree(tree) { return tree_map(square, tree); }练习 2.32
我们可以将集合表示为不同元素的列表,并且可以将集合的所有子集表示为列表的列表。例如,如果集合是list(1, 2, 3),那么所有子集的集合是
list(null, list(3), list(2), list(2, 3),
list(1), list(1, 3), list(1, 2),
list(1, 2, 3))完成以下函数声明,生成一个集合的子集,并清楚解释为什么它有效:
function subsets(s) {
if (is_null(s)) {
return list(null);
} else {
const rest = subsets(tail(s));
return append(rest, map( ?? , rest));
}
}2.2.3 序列作为常规接口
在处理复合数据时,我们强调了数据抽象如何使我们能够设计程序,而不会陷入数据表示的细节,并且抽象保留了对我们来说灵活性,可以尝试替代表示。在本节中,我们介绍了另一个处理数据结构的强大设计原则——使用常规接口。
在 1.3 节中,我们看到了程序抽象如何作为高阶函数实现,可以捕捉处理数字数据的程序中的常见模式。我们能够为处理复合数据制定类似操作的能力,关键取决于我们操作数据结构的风格。例如,考虑以下函数,类似于 2.2.2 节中的count_leaves函数,它以树作为参数,并计算奇数叶子的平方和:
function sum_odd_squares(tree) {
return is_null(tree)
? 0
: ! is_pair(tree)
? is_odd(tree) ? square(tree) : 0
: sum_odd_squares(head(tree)) +
sum_odd_squares(tail(tree));
}表面上,这个函数与以下函数非常不同,后者构造了一个所有偶数斐波那契数Fib(k)的列表,其中k小于或等于给定的整数n:
function even_fibs(n) {
function next(k) {
if (k > n) {
return null;
} else {
const f = fib(k);
return is_even(f)
? pair(f, next(k + 1))
: next(k + 1);
}
}
return next(0);
}尽管这两个函数在结构上非常不同,但对这两个计算的更抽象描述揭示了很多相似之处。第一个程序
-
枚举树的叶子;
-
过滤它们,选择奇数;
-
平方选定的每一个;和
-
使用
+累积结果,从 0 开始。
第二个程序
-
枚举从 0 到
n的整数; -
计算每个整数的斐波那契数;
-
过滤它们,选择偶数;和
-
使用
pair累积结果,从空列表开始。
信号处理工程师会自然地将这些过程概念化为信号流经过一系列阶段,每个阶段实现程序计划的一部分,如图 2.7 所示。在sum_odd_squares中,我们从一个枚举开始,它生成一个由给定树的叶子组成的“信号”。这个信号通过一个过滤器,它消除除奇数元素以外的所有元素。结果信号依次通过一个映射,它是一个应用square函数到每个元素的“转换器”。映射的输出然后被传递给一个累加器,它使用+组合元素,从初始 0 开始。even_fibs的计划是类似的。
图 2.7 函数sum_odd_squares(顶部)和even_fibs(底部)的信号流计划揭示了这两个程序之间的共同点。
不幸的是,上述两个函数声明未能展现出这种信号流结构。例如,如果我们检查sum_odd_squares函数,我们会发现枚举部分部分地由is_null和is_pair测试实现,部分地由函数的树递归结构实现。同样,累积部分地在测试中找到,部分地在递归中使用的加法中找到。一般来说,两个函数没有明显的部分与信号流描述中的元素相对应。我们的两个函数以不同的方式分解计算,将枚举分散到程序中,并将其与映射、过滤和累积混合在一起。如果我们能够组织我们的程序,使得信号流结构在我们编写的函数中显现出来,这将增加结果程序的概念清晰度。
序列操作
组织程序以更清晰地反映信号流结构的关键是集中于从一个过程阶段到下一个阶段流动的“信号”。如果我们将这些信号表示为列表,那么我们可以使用列表操作来实现每个阶段的处理。例如,我们可以使用第 2.2.1 节中的map函数来实现信号流图的映射阶段:
map(square, list(1, 2, 3, 4, 5));
list(1, 4, 9, 16, 25)通过过滤序列以选择仅满足给定谓词的元素来实现
function filter(predicate, sequence) {
return is_null(sequence)
? null
: predicate(head(sequence))
? pair(head(sequence),
filter(predicate, tail(sequence)))
: filter(predicate, tail(sequence));
}例如,
filter(is_odd, list(1, 2, 3, 4, 5));
list(1, 3, 5)累积可以通过实现
function accumulate(op, initial, sequence) {
return is_null(sequence)
? initial
: op(head(sequence),
accumulate(op, initial, tail(sequence)));
}
accumulate(plus, 0, list(1, 2, 3, 4, 5));
15
accumulate(times, 1, list(1, 2, 3, 4, 5));
120
accumulate(pair, null, list(1, 2, 3, 4, 5));
list(1, 2, 3, 4, 5)实现信号流图的所有剩下的部分就是枚举要处理的元素序列。对于even_fibs,我们需要生成给定范围内的整数序列,可以按如下方式实现:
function enumerate_interval(low, high) {
return low > high
? null
: pair(low,
enumerate_interval(low + 1, high));
}
enumerate_interval(2, 7);
list(2, 3, 4, 5, 6, 7)要枚举树的叶子,我们可以使用¹²
function enumerate_tree(tree) {
return is_null(tree)
? null
: ! is_pair(tree)
? list(tree)
: append(enumerate_tree(head(tree)),
enumerate_tree(tail(tree)));
}
enumerate_tree(list(1, list(2, list(3, 4)), 5));
list(1, 2, 3, 4, 5)现在我们可以像信号流图一样重新制定sum_odd_squares和even_fibs。对于sum_odd_squares,我们枚举树的叶子序列,过滤以保留序列中的奇数,对每个元素求平方,并求和结果:
function sum_odd_squares(tree) {
return accumulate(plus,
0,
map(square,
filter(is_odd,
enumerate_tree(tree))));
}对于even_fibs,我们枚举从 0 到n的整数,为每个整数生成斐波那契数,过滤结果序列以保留偶数元素,并将结果累积到列表中:
function even_fibs(n) {
return accumulate(pair,
null,
filter(is_even,
map(fib,
enumerate_interval(0, n))));
}将程序表达为序列操作的价值在于,这有助于我们制定模块化的程序设计,即由相对独立的部分组合而成的设计。我们可以通过提供一组标准组件的库以及用灵活方式连接组件的传统接口来鼓励模块化设计。
在工程设计中,模块化构建是控制复杂性的强大策略。例如,在实际的信号处理应用中,设计师经常通过级联从标准化的滤波器和传感器系列中选择的元素来构建系统。同样,序列操作提供了一系列标准程序元素的库,我们可以随意组合。例如,我们可以在一个程序中重用sum_odd_squares和even_fibs函数的部分,以构建前n + 1个斐波那契数的平方的列表:
function list_fib_squares(n) {
return accumulate(pair,
null,
map(square,
map(fib,
enumerate_interval(0, n))));
}
list_fib_squares(10);
list(0, 1, 1, 4, 9, 25, 64, 169, 441, 1156, 3025)我们可以重新排列这些部分,并在计算序列中奇数的平方的乘积时使用它们:
function product_of_squares_of_odd_elements(sequence) {
return accumulate(times,
1,
map(square,
filter(is_odd, sequence)));
}
product_of_squares_of_odd_elements(list(1, 2, 3, 4, 5));
225我们还可以用序列操作来制定常规的数据处理应用。假设我们有一个人员记录序列,我们想要找到薪水最高的程序员的薪水。假设我们有一个选择器salary,返回记录的薪水,和一个谓词is_programmer,测试记录是否是程序员。然后我们可以写
function salary_of_highest_paid_programmer(records) {
return accumulate(math_max,
0,
map(salary,
filter(is_programmer, records)));
}这些例子只是给出了可以表达为序列操作的广泛操作范围的一点提示。¹³
这里实现的序列作为列表,作为一个传统接口,允许我们组合处理模块。此外,当我们将结构统一表示为序列时,我们已经将程序中的数据结构依赖局限在了少量序列操作中。通过更改这些操作,我们可以尝试使用序列的替代表示,同时保持程序的整体设计不变。在第 3.5 节中,我们将利用这种能力,将序列处理范式推广到允许无限序列。
练习 2.33
填写缺失的表达式,以完成一些基本的列表操作的累积定义:
function map(f, sequence) {
return accumulate((x, y) => 〈??〉,
null, sequence);
}
function append(seq1, seq2) {
return accumulate(pair, 〈??〉, 〈??〉);
}
function length(sequence) {
return accumulate( 〈??〉, 0, sequence);
}练习 2.34
在给定x的值的情况下,用x求值多项式可以被制定为一个累积。我们求值多项式
a[n]xⁿ + a[n][–1]xⁿ^(–1) + ... + a[1]x + a[0]使用一种称为Horner's rule的著名算法,将计算结构化为
(... (a[n]x + a[n–1])x + ... + a[1]) x + a[0]换句话说,我们从a[n]开始,乘以x,加上a[n]–1,乘以x,依此类推,直到达到a[0].¹⁴ 填写以下模板,以生成使用 Horner's rule 计算多项式的函数。假设多项式的系数按顺序排列,从a[0]到a[n]。
function horner_eval(x, coefficient_sequence) {
return accumulate((this_coeff, higher_terms) => ?? ,
0,
coefficient_sequence);
}例如,要计算1 + 3x + 5x³ + x⁵在x = 2时,您需要计算
horner_eval(2, list(1, 3, 0, 5, 0, 1));练习 2.35
将 2.2.2 节中的count_leaves重新定义为累积:
function count_leaves(t) {
return accumulate( ?? , ?? , map( ?? , ?? ));
}练习 2.36
函数accumulate_n类似于accumulate,只是它的第三个参数是一个序列的序列,假定它们都有相同数量的元素。它将指定的累积函数应用于组合所有序列的第一个元素,所有序列的第二个元素,依此类推,并返回结果的序列。例如,如果s是一个包含四个序列的序列
list(list(1, 2, 3), list(4, 5, 6), list(7, 8, 9), list(10, 11, 12))然后accumulate_n(plus, 0, s)的值应该是序列list(22, 26, 30)。填写以下accumulate_n的定义中缺失的表达式:
function accumulate_n(op, init, seqs) {
return is_null(head(seqs))
? null
: pair(accumulate(op, init, 〈??〉),
accumulate_n(op, init, 〈??〉));
}练习 2.37
假设我们将向量v = (v[i])表示为数字序列,并将矩阵m = (m[ij])表示为向量序列(矩阵的行)。例如,矩阵
表示为以下序列:
list(list(1, 2, 3, 4),
list(4, 5, 6, 6),
list(6, 7, 8, 9))有了这种表示,我们可以使用序列操作简洁地表示基本的矩阵和向量操作。这些操作(在任何一本关于矩阵代数的书中都有描述)如下:

我们可以将点积定义为¹⁵
function dot_product(v, w) {
return accumulate(plus, 0, accumulate_n(times, 1, list(v, w)));
}填写以下函数中的缺失表达式,用于计算其他矩阵操作。(函数accumulate_n在练习 2.36 中声明。)
function matrix_times_vector(m, v) {
return map( ?? , m);
}
function transpose(mat) {
return accumulate_n( ?? , ?? , mat);
}
function matrix_times_matrix(n, m) {
const cols = transpose(n);
return map( ?? , m);
}练习 2.38
accumulate函数也被称为fold_right,因为它将序列的第一个元素与组合所有元素的结果结合。还有一个fold_left,它类似于fold_right,只是它是从相反方向组合元素的:
function fold_left(op, initial, sequence) {
function iter(result, rest) {
return is_null(rest)
? result
: iter(op(result, head(rest)),
tail(rest));
}
return iter(initial, sequence);
}以下是
fold_right(divide, 1, list(1, 2, 3));
fold_left(divide, 1, list(1, 2, 3));
fold_right(list, null, list(1, 2, 3));
fold_left(list, null, list(1, 2, 3));给出一个op应满足的属性,以确保fold_right和fold_left对于任何序列都会产生相同的值。
练习 2.39
根据练习 2.38 中的fold_right和fold_left,完成reverse(练习 2.18)的以下定义:
function reverse(sequence) {
return fold_right((x, y) => ?? , null, sequence);
}
function reverse(sequence) {
return fold_left((x, y) => ?? , null, sequence);
}嵌套映射
我们可以扩展序列范式,包括许多通常使用嵌套循环表达的计算。¹⁶考虑这个问题:给定一个正整数n,找到所有有序对的不同正整数i和j,其中1 j < i n,使得i + j是素数。例如,如果n为 6,则这些对是以下的:
i | 2 | 3 | 4 | 4 | 5 | 6 | 6 |
|---|---|---|---|---|---|---|---|
j |
1 | 2 | 1 | 3 | 2 | 1 | 5 |
i + j |
3 | 5 | 5 | 7 | 7 | 7 | 11 |
组织这个计算的一种自然方式是生成所有小于或等于n的正整数的有序对序列,过滤以选择其和为素数的那些对,然后对于通过过滤的每个对(i, j),产生三元组(i, j, i + j)。
以下是生成对序列的方法:对于每个整数i <= n,枚举小于i的整数j,对于这样的i和j生成对(i, j)。在序列操作方面,我们沿着序列enumerate_interval(1, n)进行映射。对于这个序列中的每个i,我们沿着序列enumerate_interval(1, i - 1)进行映射。对于后一个序列中的每个j,我们生成对list(i, j)。这给我们每个i的一系列对。将所有i的序列组合起来(通过累积使用append)产生所需的对序列:¹⁷
accumulate(append,
null,
map(i => map(j => list(i, j),
enumerate_interval(1, i - 1)),
enumerate_interval(1, n)));在这种程序中,映射和使用append进行累积的组合是如此常见,以至于我们将其作为一个单独的函数进行隔离:
function flatmap(f, seq) {
return accumulate(append, null, map(f, seq));
}现在过滤这些对的序列,找到其和为素数的对。过滤谓词对序列的每个元素进行调用;它的参数是一个对,并且它必须从对中提取整数。因此,应用于序列中的每个元素的谓词是
function is_prime_sum(pair) {
return is_prime(head(pair) + head(tail(pair)));
}最后,通过使用以下函数对过滤后的对进行映射,生成结果的序列,该函数构造一个由对的两个元素及其和组成的三元组:
function make_pair_sum(pair) {
return list(head(pair), head(tail(pair)),
head(pair) + head(tail(pair)));
}将所有这些步骤组合起来得到完整的函数:
function prime_sum_pairs(n) {
return map(make_pair_sum,
filter(is_prime_sum,
flatmap(i => map(j => list(i, j),
enumerate_interval(1, i - 1)),
enumerate_interval(1, n))));
}嵌套映射对于除了枚举间隔的序列之外的序列也是有用的。假设我们希望生成集合S的所有排列;也就是说,集合中项目的所有排序方式。例如,{1, 2, 3}的排列是{1, 2, 3},{1, 3, 2},{2, 1, 3},{2, 3, 1},{3, 1, 2}和{3, 2, 1}。以下是生成S的排列的计划:对于S中的每个项目x,递归生成S – x的排列序列,然后将x添加到每个排列的前面。这为S中的每个x产生了以x开头的排列序列。将所有x的这些序列组合起来得到S的所有排列:¹⁹
function permutations(s) {
return is_null(s) // empty set?
? list(null) // sequence containing empty set
: flatmap(x => map(p => pair(x, p),
permutations(remove(x, s))),
s);
}注意这种策略如何将生成S的排列的问题简化为生成比S元素更少的集合的排列的问题。在终端情况下,我们一直向下工作,直到空列表,它表示没有元素的集合。对于这个,我们生成list(null),它是一个具有一个项目的序列,即没有元素的集合。permutations中使用的remove函数返回给定序列中除了给定项目之外的所有项目。这可以表示为一个简单的过滤器:
function remove(item, sequence) {
return filter(x => ! (x === item),
sequence);
}练习 2.40
编写一个名为unique_pairs的函数,给定一个整数n,生成一对(i, j)的序列,其中1, j < i, n。使用unique_pairs来简化上面给出的prime_sum_pairs的定义。
练习 2.41
编写一个函数,找到所有小于或等于给定整数n的不同正整数i、j和k的有序三元组,它们的和为给定整数s。
练习 2.42
“八皇后问题”是问如何在国际象棋棋盘上放置八个皇后,以便没有一个皇后受到其他任何一个皇后的攻击(即,没有两个皇后在同一行,列或对角线上)。一个可能的解决方案如图 2.8 所示。解决这个难题的一种方法是逐列工作,将一个皇后放在每一列。一旦我们放置了k - 1个皇后,我们必须将第k个皇后放在一个位置,使得它不会攻击棋盘上已经存在的任何一个皇后。我们可以递归地制定这种方法:假设我们已经生成了在棋盘的前k - 1列中放置k - 1个皇后的所有可能方式的序列。对于这些方式中的每一种,通过在第k列的每一行放置一个皇后来生成一个扩展的位置集。现在过滤这些位置,只保留对其他皇后来说第k列中的皇后是安全的位置。这样就产生了在前k列中放置k个皇后的所有方式的序列。通过继续这个过程,我们将产生不止一个解决方案,而是所有解决方案。

图 2.8 八皇后问题的一个解决方案。
我们将这个解决方案实现为一个名为queens的函数,它返回在n n国际象棋棋盘上放置n个皇后的所有解决方案的序列。函数queens有一个内部函数queens_cols,它返回在棋盘的前k列中放置皇后的所有方式的序列。
function queens(board_size) {
function queen_cols(k) {
return k === 0
? list(empty_board)
: filter(positions => is_safe(k, positions),
flatmap(rest_of_queens =>
map(new_row =>
adjoin_position(new_row, k,
rest_of_queens),
enumerate_interval(1, board_size)),
queen_cols(k - 1)));
}
return queen_cols(board_size);
}在这个函数中,rest_of_queens是在前k - 1列中放置k - 1个皇后的一种方法,new_row是一个建议的行,用于放置第k列的皇后。通过实现代表棋盘位置集的函数adjoin_position,包括将新的行列位置添加到位置集的函数adjoin_position,以及代表空位置集的函数empty_board,来完成程序。您还必须编写函数is_safe,它确定一组位置中的第k列的皇后是否与其他皇后安全。(请注意,我们只需要检查新皇后是否安全——其他皇后已经保证彼此之间是安全的。)
练习 2.43
Louis Reasoner 在做练习 2.42 时遇到了很大的困难。他的queens函数似乎可以工作,但运行速度非常慢。(Louis 甚至没有等到它解决 6 6 的情况。)当 Louis 向 Eva Lu Ator 寻求帮助时,她指出他已经交换了flatmap中嵌套映射的顺序,将其写成
flatmap(new_row =>
map(rest_of_queens =>
adjoin_position(new_row, k, rest_of_queens),
queen_cols(k - 1)),
enumerate_interval(1, board_size));解释为什么这种交换会使程序运行缓慢。估计 Louis 的程序解决八皇后问题需要多长时间,假设练习 2.42 中的程序在时间T内解决了这个问题。
2.2.4 例子:一个图片语言
本节介绍了一种简单的绘图语言,它展示了数据抽象和闭包的强大力量,并且以一种基本的方式利用了高阶函数。该语言旨在使实验变得容易,例如图 2.9 中的图案,这些图案由重复的元素组成,这些元素被移动和缩放。在这种语言中,被组合的数据对象被表示为函数,而不是列表结构。正如pair满足闭包属性使我们能够轻松构建任意复杂的列表结构一样,这种语言中的操作也满足闭包属性,使我们能够轻松构建任意复杂的图案。

图 2.9 使用图片语言生成的设计。
图片语言
当我们在 1.1 节开始学习编程时,我们强调了通过关注语言的基本元素、组合方式和抽象方式来描述一种语言的重要性。我们将在这里遵循这个框架。
这种图片语言的优雅之处在于只有一种元素,称为画家。画家绘制的图像被移动和缩放以适应指定的平行四边形框架。例如,有一个我们称为wave的原始画家,它绘制了一个粗线条的图像,如图 2.10 所示。图像的实际形状取决于框架——图 2.10 中的所有四幅图像都是由相同的wave画家生成的,但是与四个不同的框架相关。画家可以比这更复杂:名为rogers的原始画家绘制了麻省理工学院的创始人威廉·巴顿·罗杰斯的画像,如图 2.11 所示。图 2.11 中的四幅图像是与图 2.10 中的wave图像相对应的四个框架绘制的。
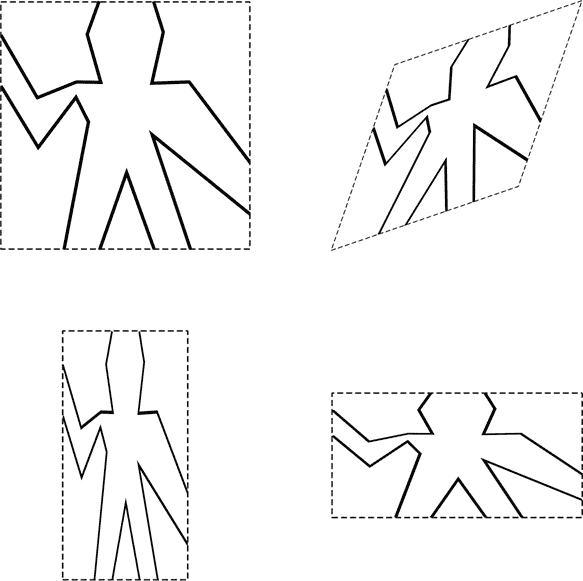
图 2.10 由wave画家生成的图像,与四个不同的框架相关。虚线框不是图像的一部分。

图 2.11 以与图 2.10 相同的四个框架为基础绘制的麻省理工学院创始人和第一任校长威廉·巴顿·罗杰斯的形象(原始图片由麻省理工学院博物馆提供)。
为了组合图像,我们使用各种操作从给定的画家构造新的画家。例如,beside操作接受两个画家,并产生一个新的复合画家,它在帧的左半部分绘制第一个画家的图像,在右半部分绘制第二个画家的图像。类似地,below接受两个画家,并产生一个复合画家,它在第一个画家的图像下方绘制第二个画家的图像。一些操作可以转换单个画家以产生新的画家。例如,flip_vert接受一个画家,并产生一个绘制其图像上下颠倒的画家,flip_horiz产生一个绘制原始画家图像从左到右翻转的画家。
图 2.12 显示了一个名为wave4的画家的绘制,它是从wave开始分两个阶段构建的:
const wave2 = beside(wave, flip_vert(wave));
const wave4 = below(wave2, wave2);通过这种方式构建复杂的图像,我们利用了画家在语言的组合方式下是闭合的这一事实。两个画家的beside或below本身就是一个画家;因此,我们可以将其用作制作更复杂画家的元素。与使用pair构建列表结构一样,数据在组合方式下的闭合对于能够仅使用少量操作创建复杂结构至关重要。
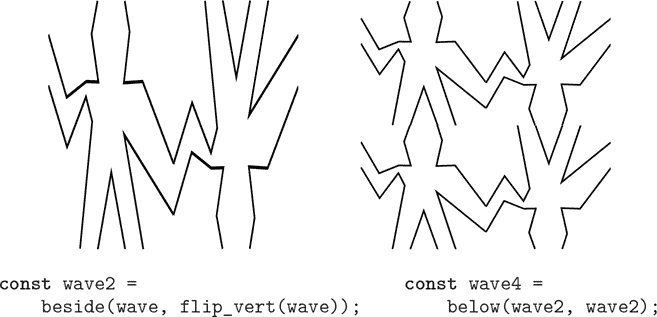
图 2.12 从图 2.10 的wave画家开始创建一个复杂的图形。
一旦我们能够组合画家,我们希望能够抽象出典型的组合画家模式。我们将画家操作实现为 JavaScript 函数。这意味着在图片语言中我们不需要特殊的抽象机制:由于组合的方式是普通的 JavaScript 函数,我们自动具有对画家操作进行任何操作的能力。例如,我们可以将wave4中的模式抽象为
function flipped_pairs(painter) {
const painter2 = beside(painter, flip_vert(painter));
return below(painter2, painter2);
}并将wave4声明为此模式的一个实例:
const wave4 = flipped_pairs(wave);我们还可以定义递归操作。以下是一个使画家向右分割和分支的操作,如图 2.13 和 2.14 所示:
function right_split(painter, n) {
if (n === 0) {
return painter;
} else {
const smaller = right_split(painter, n - 1);
return beside(painter, below(smaller, smaller));
}
}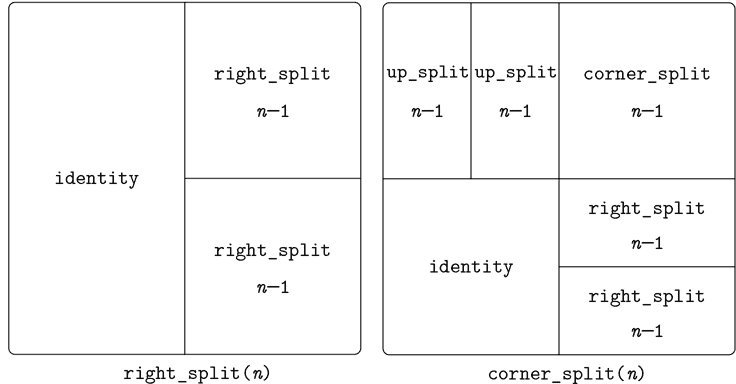
图 2.13 right_split和corner_split的递归计划。
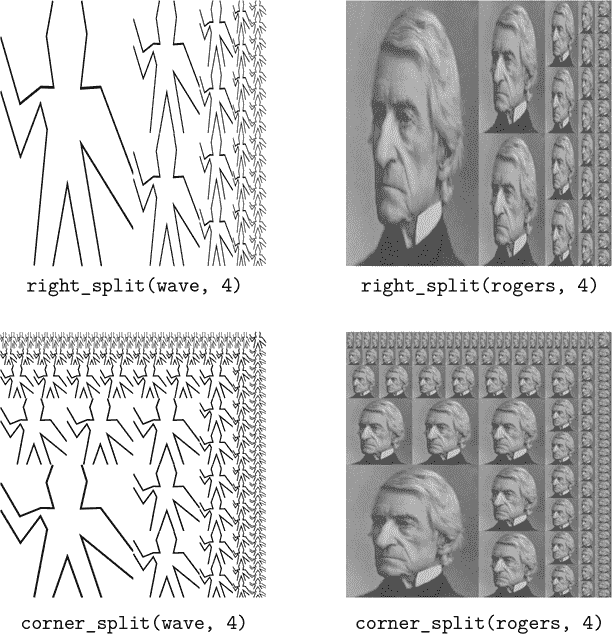
图 2.14 递归操作right_split应用于画家wave和rogers。将四个corner_split图形组合成对称的square_limit,如图 2.9 所示。
我们可以通过向上和向右分支来产生平衡的图案(参见练习 2.44 和图 2.13 和 2.14):
function corner_split(painter, n) {
if (n === 0) {
return painter;
} else {
const up = up_split(painter, n - 1);
const right = right_split(painter, n - 1);
const top_left = beside(up, up);
const bottom_right = below(right, right);
const corner = corner_split(painter, n - 1);
return beside(below(painter, top_left),
below(bottom_right, corner));
}
}通过适当放置四个corner_split的副本,我们可以获得一个名为square_limit的图案,其应用于wave和rogers如图 2.9 所示:
function square_limit(painter, n) {
const quarter = corner_split(painter, n);
const half = beside(flip_horiz(quarter), quarter);
return below(flip_vert(half), half);
}练习 2.44
声明由corner_split使用的函数up_split。它类似于right_split,只是它交换了below和beside的角色。
高阶操作
除了抽象出组合画家的模式之外,我们还可以在更高的层次上工作,抽象出组合画家操作的模式。也就是说,我们可以将画家操作视为要操作的元素,并且可以编写这些元素的组合方式——接受画家操作作为参数并创建新的画家操作的函数。
例如,flipped_pairs和square_limit都将画家的图像排列成方形图案的四个副本;它们之间的区别只在于它们如何定位这些副本。抽象这种画家组合的一种方法是使用以下函数,该函数接受四个一元画家操作并生成一个画家操作,该操作使用这四个操作对给定的画家进行变换并将结果排列成一个方形。²² 函数tl、tr、bl和br分别是要应用于左上角副本、右上角副本、左下角副本和右下角副本的变换。
function square_of_four(tl, tr, bl, br) {
return painter => {
const top = beside(tl(painter), tr(painter));
const bottom = beside(bl(painter), br(painter));
return below(bottom, top);
};
}然后可以根据square_of_four定义flipped_pairs如下:²³
function flipped_pairs(painter) {
const combine4 = square_of_four(identity, flip_vert,
identity, flip_vert);
return combine4(painter);
}和square_limit可以表示为²⁴
function square_limit(painter, n) {
const combine4 = square_of_four(flip_horiz, identity,
rotate180, flip_vert);
return combine4(corner_split(painter, n));
}练习 2.45
函数right_split和up_split可以表示为一般分割操作的实例。声明一个具有属性的函数split,使其求值
const right_split = split(beside, below);
const up_split = split(below, beside);生成具有与已声明的相同行为的函数right_split和up_split。
帧
在我们展示如何实现画家及其组合方式之前,我们必须首先考虑帧。一个帧可以由三个向量描述——一个原点向量和两个边缘向量。原点向量指定了帧的原点与平面上某个绝对原点的偏移量,而边缘向量指定了帧的角落与其原点的偏移量。如果边缘是垂直的,那么帧将是矩形的。否则,帧将是一个更一般的平行四边形。
图 2.15 显示了一个帧及其相关的向量。根据数据抽象,我们不需要具体说明帧是如何表示的,除了说有一个构造函数make_frame,它接受三个向量并生成一个帧,以及三个相应的选择器origin_frame、edge1_frame和edge2_frame(参见练习 2.47)。
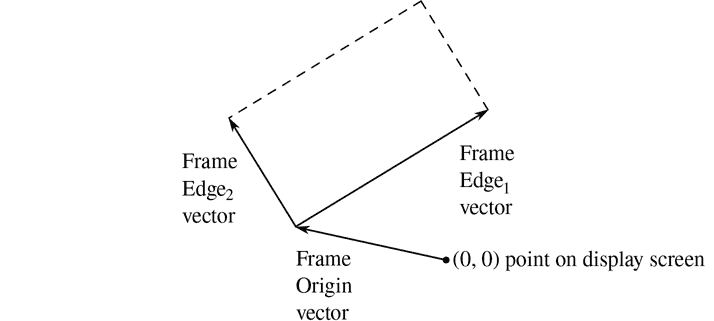
图 2.15 一个框架由三个向量描述——一个原点和两个边。
我们将使用单位正方形中的坐标(0 ≤ x, y ≤ 1)来指定图像。对于每个框架,我们关联一个 框架坐标映射,它将用于移动和缩放图像以适应框架。该映射通过将单位正方形映射到框架来将向量v = (x, y)映射到向量和
原点(框架) + x · 边[1] (框架) + y · 边[2] (框架)例如,(0, 0)被映射到框架的原点,(1, 1)被映射到对角于原点的顶点,(0.5, 0.5)被映射到框架的中心。我们可以使用以下函数创建框架的坐标映射:²⁵
function frame_coord_map(frame) {
return v => add_vect(origin_frame(frame),
add_vect(scale_vect(xcor_vect(v),
edge1_frame(frame)),
scale_vect(ycor_vect(v),
edge2_frame(frame))));
}观察将frame_coord_map应用于框架会返回一个函数,给定一个向量,返回一个向量。如果参数向量在单位正方形内,则结果向量将在框架内。例如,
frame_coord_map(a_frame)(make_vect(0, 0)); 返回与
origin_frame(a_frame);练习 2.46
从原点到一个点的二维向量v可以表示为一个对,包括一个x坐标和一个y坐标。通过给出一个构造函数make_vect和相应的选择器xcor_vect和ycor_vect来为向量实现数据抽象。根据你的选择器和构造函数,实现函数add_vect、sub_vect和scale_vect,执行向量加法、向量减法和将向量乘以标量的操作:
(x[1], y[1]) + (x[2], y[2]) = (x[1] + x[2], y[1] + y[2])
(x[1], y[1]) – (x[2], y[2]) = (x[1] – x[2], y[1] – y[2])
s · (x, y) = (sx, sy) 练习 2.47
以下是框架的两个可能的构造函数:
function make_frame(origin, edge1, edge2) {
return list(origin, edge1, edge2);
}
function make_frame(origin, edge1, edge2) {
return pair(origin, pair(edge1, edge2));
}对于每个构造函数,提供适当的选择器以生成框架的实现。
画家
画家表示为一个函数,给定一个框架作为参数,绘制一个特定的图像,移位和缩放以适应框架。也就是说,如果p是一个画家,f是一个框架,那么我们通过调用p传入f作为参数来在f中产生p的图像。
原始画家的实现细节取决于图形系统的特定特性和要绘制的图像类型。例如,假设我们有一个函数draw_line,它在屏幕上在两个指定点之间画一条线。然后我们可以根据线段列表创建线条绘制的画家,例如 图 2.10 中的wave画家,如下所示:²⁶
function segments_to_painter(segment_list) {
return frame =>
for_each(segment =>
draw_line(
frame_coord_map(frame)
(start_segment(segment)),
frame_coord_map(frame)
(end_segment(segment))),
segment_list);
}使用单位正方形的坐标给出线段。对于列表中的每个线段,画家使用框架坐标映射转换线段端点,并在转换后的点之间画一条线。
将画家表示为函数在图片语言中建立了强大的抽象屏障。我们可以创建和混合各种基于各种图形能力的原始画家。它们的实现细节并不重要。任何函数都可以作为画家,只要它以框架作为参数并绘制适合框架的内容。²⁷
练习 2.48
平面上的有向线段可以表示为一对向量——从原点到线段起点的向量,以及从原点到线段终点的向量。使用练习 2.46 中的向量表示来定义具有构造函数make_segment和选择器start_segment和end_segment的线段表示。
练习 2.49
使用segments_to_painter来定义以下原始画家:
-
a. 绘制指定框架的轮廓的画家。
-
b. 通过连接框架的对角线绘制
X的画家。 -
c. 连接框架边中点绘制菱形形状的画家。
-
d.
wave画家。
转换和组合画家
对画家的操作(如flip_vert或beside)通过创建一个画家来实现,该画家根据参数框架派生的框架调用原始画家。因此,例如,flip_vert不需要知道画家的工作方式就可以翻转它——它只需要知道如何将框架颠倒:翻转后的画家只是使用原始画家,但在倒置的框架中。
画家操作基于transform_painter函数,它接受一个画家和如何转换框架的信息作为参数,并产生一个新的画家。转换后的画家在给定一个框架时,会转换框架并在转换后的框架上调用原始画家。transform_painter的参数是指定新框架角落的点(表示为向量):当映射到框架中时,第一个点指定新框架的原点,另外两个点指定其边缘向量的端点。因此,在单位正方形内的参数指定了包含在原始框架内的框架。
function transform_painter(painter, origin, corner1, corner2) {
return frame => {
const m = frame_coord_map(frame);
const new_origin = m(origin);
return painter(make_frame(
new_origin,
sub_vect(m(corner1), new_origin),
sub_vect(m(corner2), new_origin)));
};
}以下是如何垂直翻转画家图像:
function flip_vert(painter) {
return transform_painter(painter,
make_vect(0, 1), // new origin
make_vect(1, 1), // new end of edge1
make_vect(0, 0)); // new end of edge2
}使用transform_painter,我们可以轻松定义新的转换。例如,我们可以声明一个画家,将其图像缩小到给定框架的右上角。
function shrink_to_upper_right(painter) {
return transform_painter(painter,
make_vect(0.5, 0.5),
make_vect(1, 0.5),
make_vect(0.5, 1));
}其他转换将图像逆时针旋转 90 度²⁸
function rotate90(painter) {
return transform_painter(painter,
make_vect(1, 0),
make_vect(1, 1),
make_vect(0, 0));
}或者将图像压缩到框架的中心:²⁹
function squash_inwards(painter) {
return transform_painter(painter,
make_vect(0, 0),
make_vect(0.65, 0.35),
make_vect(0.35, 0.65));
}框架转换也是定义两个或更多画家组合方式的关键。例如,beside函数接受两个画家,将它们转换为分别在参数框架的左半部分和右半部分绘制,并产生一个新的复合画家。当给复合画家一个框架时,它调用第一个转换后的画家在框架的左半部分绘制,并调用第二个转换后的画家在框架的右半部分绘制:
function beside(painter1, painter2) {
const split_point = make_vect(0.5, 0);
const paint_left = transform_painter(painter1,
make_vect(0, 0),
split_point,
make_vect(0, 1));
const paint_right = transform_painter(painter2,
split_point,
make_vect(1, 0),
make_vect(0.5, 1));
return frame => {
paint_left(frame);
paint_right(frame);
};
}观察画家数据抽象,特别是将画家表示为函数,使得beside易于实现。beside函数不需要了解组件画家的任何细节,只需要知道每个画家将在其指定的框架中绘制一些东西。
练习 2.50
声明转换flip_horiz,它可以水平翻转画家,并且可以逆时针旋转 180 度和 270 度。
练习 2.51
声明画家的below操作。below函数接受两个画家作为参数。给定一个框架,结果画家用第一个画家在框架底部绘制,并用第二个画家在顶部绘制。以两种不同的方式定义below——首先编写一个类似于上面给出的beside函数的函数,然后再根据beside和适当的旋转操作(来自练习 2.50)定义below。
语言水平的稳健设计
图片语言利用了我们介绍的关于函数和数据抽象的一些关键思想。基本数据抽象,画家,是使用函数表示实现的,这使得语言可以以统一的方式处理不同的基本绘图能力。组合的方式满足封闭性质,这使我们可以轻松地构建复杂的设计。最后,所有用于抽象函数的工具都可以用于抽象画家的组合方式。
我们还对语言和程序设计的另一个关键思想有了一瞥。这就是分层设计的方法,即复杂系统应该被构造为一系列使用一系列语言描述的级别。每个级别都是通过组合在该级别被视为原始的部分构建的,而在下一个级别,每个级别构建的部分都被用作原语。分层设计的每个级别使用适合该级别细节的原语、组合手段和抽象手段。
分层设计渗透到复杂系统的工程中。例如,在计算机工程中,电阻器和晶体管被组合(并使用模拟电路语言描述)以产生诸如与门和或门之类的部件,这些部件构成了数字电路设计语言的原语。这些部件被组合以构建处理器、总线结构和存储系统,然后使用适合计算机体系结构的语言将它们组合成计算机。计算机被组合成分布式系统,使用适合描述网络互连的语言,依此类推。
作为分层的一个微小示例,我们的图片语言使用原始元素(原始画家)来指定点和线,以提供像rogers这样的画家的形状。我们对图片语言的描述主要集中在组合这些原始元素上,使用几何组合器如beside和below。我们还在更高的级别上工作,将beside和below视为在一个语言中被操作的原语,这个语言的操作,比如square_of_four,捕捉了组合几何组合器的常见模式。
分层设计有助于使程序健壮,也就是说,这样做可以使规范的微小变化很可能只需要相应地对程序进行微小的修改。例如,假设我们想要根据图 2.9 中显示的wave来改变图像。我们可以在最低级别上改变wave元素的详细外观;我们可以在中间级别上改变corner_split复制wave的方式;我们可以在最高级别上改变square_limit如何排列四个角的方式。通常情况下,分层设计的每个级别都提供了一个不同的词汇表来表达系统的特征,并且提供了不同类型的改变能力。
练习 2.52
通过在上述每个级别上工作,对wave的square_limit进行更改,如图 2.9 所示。特别是:
-
a. 向练习 2.49 中的原始
wave画家添加一些段(例如添加一个微笑)。 -
b. 改变
corner_split构造的模式(例如,只使用一个up_split和right_split图像的副本,而不是两个)。 -
c. 修改使用
square_of_four来组装角落的square_limit版本,以便以不同的模式组装角落。(例如,你可以让大的 Mr. Rogers 从正方形的每个角向外看。)
2.3 符号数据
到目前为止,我们使用的所有复合数据对象最终都是由数字构建的。在本节中,我们通过引入使用字符字符串的能力来扩展我们的语言的表示能力。
2.3.1 字符串
到目前为止,我们已经使用字符串来显示消息,使用display和error函数(例如在练习 1.22 中)。我们可以使用字符串形成复合数据,并且有列表,比如
list("a", "b", "c", "d")
list(23, 45, 17)
list(list("Jakob", 27), list("Lova", 9), list("Luisa", 24))为了区分字符串和名称,我们用双引号将它们括起来。例如,JavaScript 表达式z表示名称z的值,而 JavaScript 表达式"z"表示由单个字符组成的字符串,即英语字母表中的最后一个字母的小写形式。
通过引号,我们可以区分字符串和名称:
const a = 1;
const b = 2;
list(a, b);
[1, [2, null]]
list("a", "b");
["a", ["b", null]]
list("a", b);
["a", [2, null]]在第 1.1.6 节,我们将===和!==作为数字的原始谓词引入。从现在开始,我们将允许===和!==的操作数为两个字符串。谓词===返回true,当且仅当两个字符串相同时,!==返回true,当且仅当两个字符串不同时。使用===,我们可以实现一个有用的函数称为member。它有两个参数:一个字符串和一个字符串列表或一个数字和一个数字列表。如果第一个参数不包含在列表中(即不与列表中的任何项===),则member返回null。否则,它返回列表中从第一次出现的字符串或数字开始的子列表:
function member(item, x) {
return is_null(x)
? null
: item === head(x)
? x
: member(item, tail(x));
}例如,值为
member("apple", list("pear", "banana", "prune"))是null,而
member("apple", list("x", "y", "apple", "pear"))是list("apple", "pear")。
练习 2.53
求出以下每个表达式的求值结果,使用框表示法和列表表示法?
list("a", "b", "c")
list(list("george"))
tail(list(list("x1", "x2"), list("y1", "y2")))
tail(head(list(list("x1", "x2"), list("y1", "y2"))))
member("red", list("blue", "shoes", "yellow", "socks"))
member("red", list("red", "shoes", "blue", "socks"))练习 2.54
如果两个列表包含相同顺序排列的相等元素,则称它们为equal。例如,
equal(list("this", "is", "a", "list"), list("this", "is", "a", "list"))是true,但
equal(list("this", "is", "a", "list"), list("this", list("is", "a"), "list"))是false。更准确地说,我们可以通过基本的===相等性递归地定义equal,即如果a和b都是字符串或数字并且它们===,或者如果它们都是对,使得head(a)等于head(b)并且tail(a)等于tail(b)。使用这个想法,实现equal作为一个函数。
练习 2.55
JavaScript 解释器在双引号"后读取字符,直到找到另一个双引号。两者之间的所有字符都是字符串的一部分,不包括双引号本身。但是如果我们想要一个字符串包含双引号呢?为此,JavaScript 还允许单引号来界定字符串,例如在'say your name aloud'中。在单引号字符串中,我们可以使用双引号,反之亦然,因此'say "your name" aloud'和"say 'your name' aloud"是有效的字符串,它们在位置 4 和 14 有不同的字符,如果我们从 0 开始计数。根据使用的字体,两个单引号可能不容易与双引号区分开。你能分辨出哪个是哪个,并计算出以下表达式的值吗?
' " ' === " "2.3.2 示例:符号微分
作为符号操作的示例和数据抽象的进一步说明,考虑设计一个执行代数表达式的符号微分的函数。我们希望该函数以代数表达式和变量作为参数,并返回表达式相对于变量的导数。例如,如果函数的参数是ax² + bx + c和x,则函数应返回2ax + b。符号微分在 Lisp 编程语言中具有特殊的历史意义。它是符号操作计算机语言开发背后的激励示例之一。此外,它标志着导致强大的符号数学工作系统开发的研究线的开始,这些系统如今被应用数学家和物理学家常规使用。
在开发符号微分程序时,我们将遵循数据抽象的相同策略,这与我们在开发第 2.1.1 节有理数系统时所遵循的策略相同。也就是说,我们将首先定义一个微分算法,该算法可以操作抽象对象,如“和”、“积”和“变量”,而不用担心这些对象如何表示。之后才会解决表示问题。
具有抽象数据的微分程序
为了简化问题,我们将考虑一个非常简单的符号微分程序,该程序处理的表达式仅使用加法和乘法两个参数进行构建。任何这种表达式的微分都可以通过应用以下简化规则来进行:
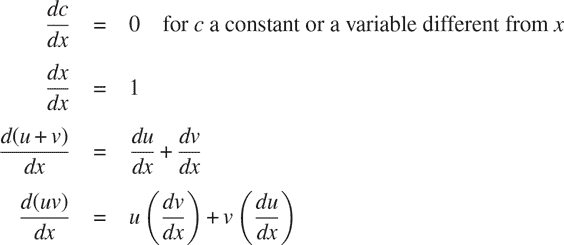
注意后两条规则的递归性质。也就是说,要获得和的导数,我们首先找到项的导数并将它们相加。每个项可能又是需要分解的表达式。分解成越来越小的部分最终会产生常数或变量的部分,它们的导数将是 0 或 1。
为了将这些规则体现在函数中,我们进行了一些希望的思考,就像我们在设计有理数实现时所做的那样。如果我们有一种表示代数表达式的方法,我们应该能够判断一个表达式是和、积、常数还是变量。我们应该能够提取表达式的部分。例如,对于和,我们希望能够提取加数(第一项)和被加数(第二项)。我们还应该能够从部分构造表达式。让我们假设我们已经有了实现以下选择器、构造函数和谓词的函数:
is_variable(e) | e是变量吗?| | --- | --- | | is_same_variable(v1, v2) | v1和v2是相同的变量吗?| | is_sum(e) | e是和吗?| | addend(e) | 和e的加数。| | augend(e) | 和e的被加数。| | make_sum(a1, a2) | 构造a1和a2的和。| | is_product(e) | e是乘积吗?| | multiplier(e) | 产品e的乘数。| | multiplicand(e) | 产品e的被乘数。| | make_product(m1, m2) | 构造m1和m2的乘积。|
使用这些和原始谓词is_number,它识别数字,我们可以将微分规则表达为以下函数:
function deriv(exp, variable) {
return is_number(exp)
? 0
: is_variable(exp)
? is_same_variable(exp, variable) ? 1 : 0
: is_sum(exp)
? make_sum(deriv(addend(exp), variable),
deriv(augend(exp), variable))
: is_product(exp)
? make_sum(make_product(multiplier(exp),
deriv(multiplicand(exp),
variable)),
make_product(deriv(multiplier(exp),
variable),
multiplicand(exp)))
: error(exp, "unknown expression type – deriv");
}这个deriv函数包含了完整的微分算法。由于它是用抽象数据表示的,所以无论我们选择如何表示代数表达式,只要我们设计一个合适的选择器和构造函数,它都能工作。这是我们接下来必须解决的问题。
表示代数表达式
我们可以想象许多使用列表结构来表示代数表达式的方法。例如,我们可以使用符号列表来反映通常的代数表示法,将ax + b表示为list("a", "*", "x", "+", "b")。但是,如果我们在 JavaScript 值中反映表达式的数学结构,将ax + b表示为list("+", list("*", "a", "x"), "b")会更方便。将二元运算符放在其操作数之前称为前缀表示,与第 1.1.1 节介绍的中缀表示相反。使用前缀表示,微分问题的数据表示如下:
-
变量只是字符串。它们由原始谓词
is_string识别:function is_variable(x) { return is_string(x); } -
如果表示它们的字符串相等,两个变量是相同的:
function is_same_variable(v1, v2) { return is_variable(v1) && is_variable(v2) && v1 === v2; } -
和积是作为列表构造的:
function make_sum(a1, a2) { return list("+", a1, a2); } function make_product(m1, m2) { return list("*", m1, m2); } -
和是一个列表,其第一个元素是字符串
"+":function is_sum(x) { return is_pair(x) && head(x) === "+"; } -
被加数是和列表的第二项:
function addend(s) { return head(tail(s)); } -
被加数是和列表的第三项:
function augend(s) { return head(tail(tail(s))); } -
乘积是一个列表,其第一个元素是字符串
"*":function is_product(x) { return is_pair(x) && head(x) === "*"; } -
乘数是产品列表的第二项:
function multiplier(s) { return head(tail(s)); } -
被乘数是产品列表的第三项:
function multiplicand(s) { return head(tail(tail(s))); }
因此,我们只需要将这些与由deriv体现的算法结合起来,就可以拥有一个可工作的符号微分程序。让我们看一些其行为的例子:
deriv(list("+", "x", 3), "x");
list("+", 1, 0)
deriv(list("*", "x", "y"), "x");
list("+", list("*", "x", 0), list("*", 1, "y"))
deriv(list("*", list("*", "x", "y"), list("+", "x", 3)), "x");
list("+", list("*", list("*", "x", "y"), list("+", 1, 0)),
list("*", list("+", list("*", "x", 0), list("*", 1, "y")),
list("+", "x", 3)))该程序生成的答案是正确的;但是,它们是未简化的。事实上
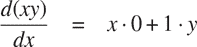
但我们希望程序知道x· 0 = 0,1 · y = y,0 + y = y。第二个例子的答案应该只是y。正如第三个例子所示,当表达式变得复杂时,这将成为一个严重的问题。
我们的困难很像我们在实现有理数时遇到的困难:我们没有将答案简化为最简形式。为了完成有理数的简化,我们只需要改变实现的构造函数和选择器。我们可以在这里采用类似的策略。我们不会改变deriv。相反,我们将改变make_sum,以便如果两个加数都是数字,make_sum将把它们相加并返回它们的和。此外,如果其中一个加数是 0,那么make_sum将返回另一个加数。
function make_sum(a1, a2) {
return number_equal(a1, 0)
? a2
: number_equal(a2, 0)
? a1
: is_number(a1) && is_number(a2)
? a1 + a2
: list("+", a1, a2);
}这使用了函数number_equal,它检查表达式是否等于给定的数字:
function number_equal(exp, num) {
return is_number(exp) && exp === num;
}同样,我们将改变make_product以内置规则,即 0 乘以任何数都是 0,1 乘以任何数都是它本身:
function make_product(m1, m2) {
return number_equal(m1, 0) || number_equal(m2, 0)
? 0
: number_equal(m1, 1)
? m2
: number_equal(m2, 1)
? m1
: is_number(m1) && is_number(m2)
? m1 * m2
: list("*", m1, m2);
}这是这个版本在我们的三个例子上的工作方式:
deriv(list("+", "x", 3), "x");
`1`
deriv(list("*", "x", "y"), "x");
"y"
deriv(list("*", list("*", "x", "y"), list("+", "x", 3)), "x");
list("+", list("*", "x", "y"), list("*", "y", list("+", "x", 3)))尽管这是一个很大的改进,但第三个例子表明,在我们得到一个将表达式放入我们可能同意的“最简形式”的程序之前,我们还有很长的路要走。代数简化的问题很复杂,因为,除其他原因外,对于一个目的来说可能是最简单的形式对于另一个目的来说可能不是。
练习 2.56
展示如何扩展基本的差异化器以处理更多种类的表达式。例如,实现差异化规则
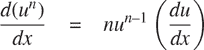
通过向deriv程序添加一个新子句并定义适当的函数is_exp、base、exponent和make_exp来实现这个表示法。(你可以使用字符串**来表示指数。)内置规则,任何数的 0 次方都是 1,任何数的 1 次方都是它本身。
练习 2.57
将差异化程序扩展到处理任意数量(两个或更多)项的和与积。然后上面的最后一个例子可以表示为
deriv(list("*", "x", "y", list("+", "x", 3)), "x");尝试只通过改变和积的表示形式,而不改变deriv函数来实现这一点。例如,和的addend将是第一项,augend将是其余项的和。
练习 2.58
假设我们想修改差异化程序,使其适用于普通的数学表示法,其中+和*是中缀而不是前缀运算符。由于差异化程序是根据抽象数据定义的,我们可以通过仅改变定义差异化器要操作的代数表达式的表示的谓词、选择器和构造函数来修改它,以便它适用于不同的表达式表示。
-
a. 展示如何以中缀形式来区分代数表达式,就像这个例子一样:
list("x", "+", list(3, "*", list("x", "+", list("y", "+", 2))))为了简化任务,假设
+和*总是带有两个参数,并且表达式是完全括号化的。 -
b. 如果我们允许更接近普通中缀表示法的符号,即省略不必要的括号并假定乘法比加法优先级高,那么问题就会变得更加困难,就像这个例子一样:
list("x", "+", "3", "*", list("x", "+", "y", "+", 2))你能设计适当的谓词、选择器和构造函数,使我们的导数程序仍然有效吗?
2.3.3 例子:表示集合
在前面的例子中,我们为两种复合数据对象构建了表示:有理数和代数表达式。在这些例子中,我们可以选择在构建时间或选择时间简化(减少)表达式,但除此之外,在列表方面选择这些结构的表示是直接的。当我们转向集合的表示时,表示的选择就不那么明显了。实际上,有许多可能的表示,它们在几个方面彼此之间有显著的不同。
非正式地,集合只是不同对象的集合。为了给出更精确的定义,我们可以采用数据抽象的方法。也就是说,我们通过指定在集合上使用的操作来定义“集合”。这些操作包括union_set,intersection_set,is_element_of_set和adjoin_set。函数is_element_of_set是一个谓词,用于确定给定元素是否是集合的成员。函数adjoin_set接受一个对象和一个集合作为参数,并返回一个包含原始集合元素和附加元素的集合。函数union_set计算两个集合的并集,即包含在任一参数中出现的每个元素的集合。函数intersection_set计算两个集合的交集,即仅包含同时出现在两个参数中的元素的集合。从数据抽象的角度来看,我们可以自由设计任何实现这些操作的表示,以与上述解释一致的方式实现。³³
无序列表的集合
一种表示集合的方法是将其元素列表化,其中没有元素出现超过一次。空集由空列表表示。在这种表示中,is_element_of_set类似于第 2.3.1 节的member函数。它使用equal而不是===,因此集合元素不必仅仅是数字或字符串:
function is_element_of_set(x, set) {
return is_null(set)
? false
: equal(x, head(set))
? true
: is_element_of_set(x, tail(set));
}使用这个,我们可以编写adjoin_set。如果要添加的对象已经在集合中,我们只需返回集合。否则,我们使用pair将对象添加到表示集合的列表中:
function adjoin_set(x, set) {
return is_element_of_set(x, set)
? set
: pair(x, set);
}对于intersection_set,我们可以使用递归策略。如果我们知道如何形成set2和set1的tail的交集,我们只需要决定是否在其中包含set1的head。但这取决于head(set1)是否也在set2中。以下是得到的函数:
function intersection_set(set1, set2) {
return is_null(set1) || is_null(set2)
? null
: is_element_of_set(head(set1), set2)
? pair(head(set1), intersection_set(tail(set1), set2))
: intersection_set(tail(set1), set2);
}在设计表示时,我们应该关注的一个问题是效率。考虑我们的集合操作所需的步骤数。由于它们都使用is_element_of_set,因此此操作的速度对整个集合实现的效率有重大影响。现在,为了检查对象是否是集合的成员,is_element_of_set可能需要扫描整个集合。(在最坏的情况下,对象可能不在集合中。)因此,如果集合有n个元素,is_element_of_set可能需要最多n步。因此,所需的步骤数随着Θ(n)增长。使用此操作的adjoin_set所需的步骤数也随着Θ(n)增长。对于intersection_set,它对set1的每个元素进行is_element_of_set检查,所需的步骤数随着涉及的集合大小的乘积增长,或者对于大小为n的两个集合,为Θ(n²)。union_set也是如此。
练习 2.59
为无序列表表示的集合实现union_set操作。
练习 2.60
我们规定集合将被表示为一个没有重复的列表。现在假设我们允许重复。例如,集合{1, 2, 3}可以表示为列表list(2, 3, 2, 1, 3, 2, 2)。设计函数is_element_of_set、adjoin_set、union_set和intersection_set,这些函数操作这种表示。每个函数的效率与非重复表示的相应函数相比如何?是否有应用程序会优先使用这种表示而不是非重复表示?
有序列表的集合
加速我们的集合操作的一种方法是更改表示,使得集合元素按升序列出。为此,我们需要某种方法来比较两个对象,以便我们可以说哪个更大。例如,我们可以按字典顺序比较字符串,或者我们可以同意一些方法来为对象分配唯一的数字,然后通过比较相应的数字来比较元素。为了保持我们的讨论简单,我们只考虑集合元素是数字的情况,这样我们可以使用>和<来比较元素。我们将通过按升序列出其元素来表示一组数字。而我们上面的第一种表示允许我们以任何顺序列出集合{1, 3, 6, 10}的元素,我们的新表示只允许列表list(1, 3, 6, 10)。
有序的一个优点在于is_element_of_set中显示出来:在检查项目是否存在时,我们不再需要扫描整个集合。如果我们到达一个大于我们要查找的项目的集合元素,那么我们就知道该项目不在集合中。
function is_element_of_set(x, set) {
return is_null(set)
? false
: x === head(set)
? true
: x < head(set)
? false
: // x > head(set)
is_element_of_set(x, tail(set));
}这节省了多少步?在最坏的情况下,我们要找的项目可能是集合中最大的项目,因此步数与无序表示的步数相同。另一方面,如果我们搜索许多不同大小的项目,有时我们可以期望能够在列表开头附近停止搜索,而其他时候我们仍然需要检查大部分列表。平均而言,我们应该期望需要检查集合中大约一半的项目。因此,所需的平均步数约为n/2。这仍然是Θ(n)的增长,但平均而言,与先前的实现相比,它可以节省我们约 2 倍的步数。
我们通过intersection_set获得了更令人印象深刻的加速。在无序表示中,这个操作需要Θ(n²)步,因为我们对set2的每个元素执行了完整的扫描。但是在有序表示中,我们可以使用更聪明的方法。首先比较两个集合的初始元素x1和x2。如果x1等于x2,那么这给出了交集的一个元素,其余的交集是两个集合的tail的交集。然而,假设x1小于x2。由于x2是set2中最小的元素,我们可以立即得出x1不可能出现在set2中,因此不在交集中。因此,交集等于set2与set1的tail的交集。同样,如果x2小于x1,那么交集由set1与set2的tail的交集给出。这是函数:
function intersection_set(set1, set2) {
if (is_null(set1) || is_null(set2)) {
return null;
} else {
const x1 = head(set1);
const x2 = head(set2);
return x1 === x2
? pair(x1, intersection_set(tail(set1), tail(set2)))
: x1 < x2
? intersection_set(tail(set1), set2)
: // x2 < x1
intersection_set(set1, tail(set2));
}
}要估计此过程所需的步数,观察到在每一步中,我们将交集问题减少到计算更小集合的交集——从set1或set2或两者中删除第一个元素。因此,所需的步数最多是set1和set2大小的总和,而不是无序表示的大小乘积。这是Θ(n)的增长,而不是Θ(n²)——即使对于中等大小的集合,这也是相当大的加速。
练习 2.61
使用有序表示法给出adjoin_set的实现。类似于is_element_of_set,展示如何利用排序来生成一个函数,平均需要的步骤数量大约是无序表示的一半。
练习 2.62
为作为有序列表表示的集合提供一个Θ(n)的union_set实现。
将集合表示为二叉树
我们可以通过以树的形式排列集合元素来比有序列表表示更好。树的每个节点都包含集合的一个元素,称为该节点的“条目”,以及指向两个其他(可能为空)节点的链接。 “左”链接指向小于节点处的元素,“右”链接指向大于节点处的元素。图 2.16 显示了表示集合{1, 3, 5, 7, 9, 11}的一些树。同一集合可以用多种不同的方式表示为树。我们对有效表示的唯一要求是左子树中的所有元素都小于节点条目,右子树中的所有元素都大于节点条目。
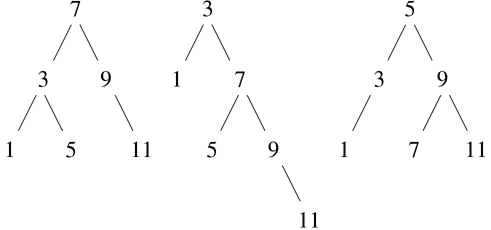
图 2.16 表示集合{1, 3, 5, 7, 9, 11}的各种二叉树。
树表示的优势在于:假设我们想要检查数字x是否包含在集合中。我们首先将x与顶部节点中的条目进行比较。如果x小于此条目,我们知道我们只需要搜索左子树;如果x大于此条目,我们只需要搜索右子树。现在,如果树是“平衡的”,这些子树的大小将约为原始大小的一半。因此,我们已经将搜索大小为n的树的问题减少到搜索大小为n/2的树。由于树的大小在每一步都减半,我们应该期望搜索大小为n的树所需的步骤数增长为Θ(log n)。对于大型集合,这将比以前的表示方式显著加快速度。
我们可以使用列表来表示树。每个节点将是一个包含三个项目的列表:节点处的条目,左子树和右子树。空列表的左子树或右子树表示那里没有连接的子树。我们可以通过以下函数描述这种表示法:
function entry(tree) { return head(tree); }
function left_branch(tree) { return head(tail(tree)); }
function right_branch(tree) { return head(tail(tail(tree))); }
function make_tree(entry, left, right) {
return list(entry, left, right);
}现在我们可以使用上述策略编写is_element_of_set:
function is_element_of_set(x, set) {
return is_null(set)
? false
: x === entry(set)
? true
: x < entry(set)
? is_element_of_set(x, left_branch(set))
: // x > entry(set)
is_element_of_set(x, right_branch(set));
}将项目添加到集合中的方法类似实现,并且需要Θ(log n)步骤。要添加项目x,我们将x与节点条目进行比较,以确定x应该添加到右侧还是左侧分支,并且在将x添加到适当的分支后,我们将这个新构造的分支与原始条目和另一个分支组合在一起。如果x等于条目,我们只需返回节点。如果我们被要求将x添加到空树中,我们生成一个具有x作为条目和空右侧和左侧分支的树。以下是函数:
function adjoin_set(x, set) {
return is_null(set)
? make_tree(x, null, null)
: x === entry(set)
? set
: x < entry(set)
? make_tree(entry(set),
adjoin_set(x, left_branch(set)),
right_branch(set))
: // x > entry(set)
make_tree(entry(set),
left_branch(set),
adjoin_set(x, right_branch(set)));
}上述声称搜索树可以在对数步骤中执行的假设是树是“平衡的”,即每棵树的左子树和右子树大致具有相同数量的元素,因此每个子树包含其父树元素的大约一半。但是我们如何确保我们构造的树是平衡的呢?即使我们从平衡树开始,使用adjoin_set添加元素可能会产生不平衡的结果。由于新添加元素的位置取决于元素与集合中已有项目的比较方式,我们可以预期,如果我们“随机”添加元素,树将平均平衡。但这并不是一个保证。例如,如果我们从空集开始,按顺序添加数字 1 到 7,我们最终得到图 2.17 中显示的高度不平衡的树。在这棵树中,所有左子树都是空的,因此它与简单的有序列表没有任何优势。解决这个问题的一种方法是定义一个操作,将任意树转换为具有相同元素的平衡树。然后我们可以在每隔几次adjoin_set操作之后执行此转换,以保持我们的集合平衡。还有其他解决这个问题的方法,其中大多数涉及设计新的数据结构,用于在Θ(log n)步骤中进行搜索和插入。³⁶
图 2.17 顺序添加 1 到 7 所产生的不平衡树。
练习 2.63
以下两个函数中的每一个都将二叉树转换为列表。
function tree_to_list_1(tree) {
return is_null(tree)
? null
: append(tree_to_list_1(left_branch(tree)),
pair(entry(tree),
tree_to_list_1(right_branch(tree))));
}
function tree_to_list_2(tree) {
function copy_to_list(tree, result_list) {
return is_null(tree)
? result_list
: copy_to_list(left_branch(tree),
pair(entry(tree),
copy_to_list(right_branch(tree),
result_list)));
}
return copy_to_list(tree, null);
}-
a. 这两个函数对每棵树都产生相同的结果吗?如果不是,结果有何不同?这两个函数为图 2.16 中的树产生了什么列表?
-
b. 这两个函数在将具有
n个元素的平衡树转换为列表所需的步骤数量的增长顺序相同吗?如果不是,哪一个增长更慢?
练习 2.64
以下函数list_to_tree将有序列表转换为平衡二叉树。辅助函数partial_tree以整数n和至少n个元素的列表作为参数,并构造包含列表的前n个元素的平衡树。partial_tree返回的结果是一个由pair组成的对,其head是构造的树,tail是未包含在树中的元素列表。
function list_to_tree(elements) {
return head(partial_tree(elements, length(elements)));
}
function partial_tree(elts, n) {
if (n === 0) {
return pair(null, elts);
} else {
const left_size = math_floor((n - 1) / 2);
const left_result = partial_tree(elts, left_size);
const left_tree = head(left_result);
const non_left_elts = tail(left_result);
const right_size = n - (left_size + 1);
const this_entry = head(non_left_elts);
const right_result = partial_tree(tail(non_left_elts), right_size);
const right_tree = head(right_result);
const remaining_elts = tail(right_result);
return pair(make_tree(this_entry, left_tree, right_tree),
remaining_elts);
}
}-
a. 用尽可能清晰的方式写一段简短的段落,解释
partial_tree是如何工作的。为列表list(1, 3, 5, 7, 9, 11)绘制list_to_tree生成的树。 -
b.
list_to_tree将n个元素的列表转换为所需的步骤数量的增长顺序是多少?
练习 2.65
使用练习 2.63 和 2.64 的结果,为作为(平衡)二叉树实现的集合提供union_set和intersection_set的Θ(n)实现。³⁷
集合和信息检索
我们已经研究了使用列表表示集合的选项,并且已经看到数据对象的表示选择对使用数据的程序的性能有很大影响。专注于集合的另一个原因是,这里讨论的技术在涉及信息检索的应用中一再出现。
考虑一个包含大量个体记录的数据库,例如公司的人事档案或会计系统中的交易。典型的数据管理系统花费大量时间访问或修改记录中的数据,因此需要一种有效的访问记录的方法。这是通过识别每个记录的一部分作为标识键来完成的。键可以是任何唯一标识记录的东西。对于人事档案,它可能是员工的 ID 号。对于会计系统,它可能是交易号。无论键是什么,当我们将记录定义为数据结构时,我们应该包括一个key选择器函数,用于检索与给定记录关联的键。
现在我们将数据库表示为一组记录。要定位具有给定键的记录,我们使用一个名为lookup的函数,它以键和数据库作为参数,并返回具有该键的记录,如果没有这样的记录则返回false。函数lookup的实现方式几乎与is_element_of_set相同。例如,如果记录集被实现为无序列表,我们可以使用
function lookup(given_key, set_of_records) {
return is_null(set_of_records)
? false
: equal(given_key, key(head(set_of_records)))
? head(set_of_records)
: lookup(given_key, tail(set_of_records));
}当然,有更好的方法来表示大型集合,而不是作为无序列表。记录必须“随机访问”的信息检索系统通常通过基于树的方法实现,例如之前讨论过的二叉树表示。在设计这样的系统时,数据抽象的方法论可以提供很大的帮助。设计者可以使用简单直接的表示方法(例如无序列表)创建一个初始实现。这对于最终的系统来说是不合适的,但它可以用来提供一个“快速脏数据”数据库,用于测试系统的其余部分。稍后,数据表示可以修改为更复杂的形式。如果数据库是根据抽象选择器和构造器访问的,那么这种表示的更改不需要对系统的其余部分进行任何更改。
练习 2.66
为记录集结构化为按键的数值顺序排列的二叉树的情况实现lookup函数。
2.3.4 示例:霍夫曼编码树
本节提供了使用列表结构和数据抽象来操作集合和树的实践。应用于将数据表示为一系列一和零(位)的方法。例如,用于在计算机中表示文本的 ASCII 标准代码将每个字符编码为七位序列。使用七位可以区分2⁷,或 128 个可能的不同字符。一般来说,如果我们想区分n个不同的符号,我们将需要使用log₂n位每个符号。如果我们的所有消息由八个符号 A、B、C、D、E、F、G 和 H 组成,我们可以选择每个字符三位的代码,例如
| A | 000 | C | 010 | E | 100 | G | 110 |
|---|---|---|---|---|---|---|---|
| B | 001 | D | 011 | F | 101 | H | 111 |
使用这个代码,消息
BACADAEAFABBAAAGAH被编码为 54 位的字符串
001000010000011000100000101000001001000000000110000111诸如 ASCII 和上面的 A 到 H 代码之类的代码被称为固定长度代码,因为它们用相同数量的位表示消息中的每个符号。有时使用可变长度代码是有利的,其中不同的符号可以由不同数量的位表示。例如,莫尔斯电码不使用相同数量的点和破折号来表示字母表中的每个字母。特别是,最常见的字母 E 由一个单点表示。一般来说,如果我们的消息中有一些符号出现非常频繁,而另一些符号出现非常少,如果我们为频繁的符号分配较短的代码,我们可以更有效地编码数据(即每个消息使用更少的位)。考虑以下字母 A 到 H 的替代代码:
| A | 0 | C | 1010 | E | 1100 | G | 1110 |
|---|---|---|---|---|---|---|---|
| B | 100 | D | 1011 | F | 1101 | H | 1111 |
使用这个编码,与上面相同的消息被编码为
100010100101101100011010100100000111001111这个字符串包含 42 位,因此与上面显示的固定长度编码相比,节省了超过 20%的空间。
使用可变长度编码的一个困难是在读取一系列零和一时,知道何时已经到达符号的结尾。摩尔斯电码通过在每个字母的点和划线序列之后使用特殊的分隔符编码(在这种情况下是暂停)来解决这个问题。另一个解决方案是设计编码,使得任何符号的完整编码都不是另一个符号的编码的开头(或前缀)。这样的编码称为前缀编码。在上面的例子中,A 由 0 编码,B 由 100 编码,因此没有其他符号可以以 0 或 100 开头的编码。
一般来说,如果我们使用可变长度的前缀编码,可以实现显著的节省,这些编码利用了消息中符号的相对频率。其中一种特定的方案称为哈夫曼编码方法,以其发现者大卫·哈夫曼命名。哈夫曼编码可以表示为一个二叉树,其叶子节点是被编码的符号。在树的每个非叶节点上,有一个包含所有位于节点下方的叶子中的符号的集合。此外,每个叶子上的符号被分配一个权重(即其相对频率),每个非叶节点包含一个权重,该权重是其下方所有叶子的权重之和。权重不用于编码或解码过程。我们将在下面看到它们如何用于帮助构建树。
图 2.18 显示了上面给出的 A 到 H 编码的哈夫曼树。叶子上的权重表明,该树是为了相对频率为 8 的 A、相对频率为 3 的 B 和其他每个字母的相对频率为 1 的消息而设计的。
图 2.18 哈夫曼编码树。
给定一个哈夫曼树,我们可以通过从根开始并向下移动,直到到达包含符号的叶子为止,找到任何符号的编码。每次向下移动左分支时,我们将 0 添加到编码中,每次向下移动右分支时,我们将 1 添加到编码中。(我们决定要跟随哪个分支,通过测试看哪个分支是符号的叶节点或包含符号在其集合中。)例如,从图 2.18 的树的根开始,我们通过向右、向左、向右、向右移动到达 D 的叶子;因此,D 的编码是 1011。
使用哈夫曼树解码比特序列时,我们从根开始,使用比特序列的连续零和一来确定是向左还是向右移动。每次到达叶子时,我们在消息中生成一个新的符号,然后我们从树的根重新开始,找到下一个符号。例如,假设我们有上面的树和序列 10001010。从根开始,我们向右移动(因为字符串的第一个位是 1),然后向左移动(因为第二位是 0),然后向左移动(因为第三位也是 0)。这将带我们到 B 的叶子,因此解码消息的第一个符号是 B。现在我们再次从根开始,因为字符串的下一个位是 0,所以我们向左移动。这将带我们到 A 的叶子。然后我们从树的根重新开始,使用剩下的字符串 1010,所以我们向右、左、右、左移动,到达 C。因此,整个消息是 BAC。
生成哈夫曼树
给定一组符号和它们的相对频率的“字母表”,我们如何构建“最佳”编码?(换句话说,哪棵树会用最少的位来编码消息?)赫夫曼提出了一个算法来做到这一点,并证明了所得到的编码确实是相对频率与编码构造时频率匹配的消息的最佳可变长度编码。我们将不在这里证明赫夫曼编码的最优性,但我们将展示赫夫曼树是如何构建的。
生成赫夫曼树的算法非常简单。其思想是安排树,使得频率最低的符号出现在距离根最远的地方。从包含符号和它们的频率的叶子节点集开始,这些频率是根据构造编码的初始数据确定的。现在找到两个权重最低的叶子并合并它们,以产生一个节点,该节点具有这两个节点作为其左右分支。新节点的权重是两个权重的总和。从原始集合中删除这两个叶子,并用这个新节点替换它们。现在继续这个过程。在每一步中,合并两个权重最小的节点,将它们从集合中删除,并用一个节点替换它们,该节点具有这两个节点作为其左右分支。当只剩下一个节点时,即整个树的根节点时,该过程停止。以下是图 2.18 的赫夫曼树是如何生成的:
| 初始叶子 | {(A 8) (B 3) (C 1) (D 1) (E 1) (F 1) (G 1) (H 1)} |
|---|---|
| 合并 | {(A 8) (B 3) ({C D} 2) (E 1) (F 1) (G 1) (H 1)} |
| 合并 | {(A 8) (B 3) ({C D} 2) ({E F} 2) (G 1) (H 1)} |
| 合并 | {(A 8) (B 3) ({C D} 2) ({E F} 2) ({G H} 2)} |
| 合并 | {(A 8) (B 3) ({C D} 2) ({E F G H} 4)} |
| 合并 | {(A 8) ({B C D} 5) ({E F G H} 4)} |
| 合并 | {(A 8) ({B C D E F G H} 9)} |
| 最终合并 | {({A B C D E F G H} 17)} |
该算法并不总是指定一个唯一的树,因为在每一步可能没有唯一的最小权重节点。此外,合并两个节点的顺序(即哪个将成为右分支,哪个将成为左分支)是任意的。
表示赫夫曼树
在下面的练习中,我们将使用一个使用赫夫曼树来编码和解码消息并根据上述算法生成赫夫曼树的系统。我们将首先讨论树是如何表示的。
树的叶子由包含字符串leaf,叶子上的符号和权重的列表表示:
function make_leaf(symbol, weight) {
return list("leaf", symbol, weight);
}
function is_leaf(object) {
return head(object) === "leaf";
}
function symbol_leaf(x) { return head(tail(x)); }
function weight_leaf(x) { return head(tail(tail(x))); }一棵一般的树将是一个字符串code_tree的列表,一个左分支,一个右分支,一组符号和一个权重。符号集将只是符号的列表,而不是一些更复杂的集合表示。当我们通过合并两个节点来构造一棵树时,我们得到树的权重是节点权重的总和,符号集是节点的符号集的并集。由于我们的符号集被表示为列表,我们可以使用我们在 2.2.1 节中定义的append函数来形成并集:
function make_code_tree(left, right) {
return list("code_tree", left, right,
append(symbols(left), symbols(right)),
weight(left) + weight(right));
}如果我们以这种方式制作一棵树,我们将有以下选择器:
function left_branch(tree) { return head(tail(tree)); }
function right_branch(tree) { return head(tail(tail(tree))); }
function symbols(tree) {
return is_leaf(tree)
? list(symbol_leaf(tree))
: head(tail(tail(tail(tree))));
}
function weight(tree) {
return is_leaf(tree)
? weight_leaf(tree)
: head(tail(tail(tail(tail(tree)))));
}函数symbols和weight必须根据它们是与叶子还是一般树一起调用而稍有不同。这些是通用函数(可以处理多种数据类型的函数)的简单示例,我们将在 2.4 和 2.5 节中有更多关于它们的话要说。
解码函数
以下函数实现了解码算法。它以零和一的列表以及赫夫曼树作为参数。
function decode(bits, tree) {
function decode_1(bits, current_branch) {
if (is_null(bits)) {
return null;
} else {
const next_branch = choose_branch(head(bits),
current_branch);
return is_leaf(next_branch)
? pair(symbol_leaf(next_branch),
decode_1(tail(bits), tree))
: decode_1(tail(bits), next_branch);
}
}
return decode_1(bits, tree);
}
function choose_branch(bit, branch) {
return bit === 0
? left_branch(branch)
: bit === 1
? right_branch(branch)
: error(bit, "bad bit – choose_branch");
}函数decode_1接受两个参数:剩余位的列表和树中的当前位置。它不断地“向下”移动树,根据列表中的下一个位是零还是一选择左侧或右侧分支。(这是通过函数choose_branch完成的。)当它到达叶子时,它返回该叶子上的符号作为消息中的下一个符号,将其与解码消息的其余部分连接起来,从树的根开始。请注意choose_branch的最后一个子句中的错误检查,如果函数在输入数据中找到除零或一之外的其他内容,则会发出投诉。
加权元素的集合
在我们对树的表示中,每个非叶节点包含一组符号,我们已经将其表示为一个简单的列表。然而,上面讨论的生成树算法要求我们还要处理叶子和树的集合,依次合并两个最小的项目。由于我们需要重复地在集合中找到最小的项目,因此方便起见,我们使用有序表示来表示这种类型的集合。
我们将一个叶子和树的集合表示为一个元素列表,按权重递增排列。用于构建集合的adjoin_set函数与练习 2.61 中描述的类似;然而,项目是按其权重进行比较的,并且要添加到集合中的元素从未在其中。
function adjoin_set(x, set) {
return is_null(set)
? list(x)
: weight(x) < weight(head(set))
? pair(x, set)
: pair(head(set), adjoin_set(x, tail(set)));
}以下函数接受一个符号-频率对的列表,例如
list(list("A", 4), list("B", 2), list("C", 1), list("D", 1))并构建一个初始的有序叶子集,准备根据 Huffman 算法合并:
function make_leaf_set(pairs) {
if (is_null(pairs)) {
return null;
} else {
const first_pair = head(pairs);
return adjoin_set(
make_leaf(head(first_pair), // symbol
head(tail(first_pair))), // frequency
make_leaf_set(tail(pairs)));
}
}练习 2.67
声明一个编码树和一个样本消息:
const sample_tree = make_code_tree(make_leaf("A", 4),
make_code_tree(make_leaf("B", 2),
make_code_tree(
make_leaf("D", 1),
make_leaf("C", 1))));
const sample_message = list(0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0);使用decode函数解码消息,并给出结果。
练习 2.68
encode函数以消息和树作为参数,并生成给定编码消息的位列表。
function encode(message, tree) {
return is_null(message)
? null
: append(encode_symbol(head(message), tree),
encode(tail(message), tree));
}函数encode_symbol由你编写,返回根据给定树对给定符号进行编码的位列表。你应该设计encode_symbol,以便如果符号根本不在树中,则发出错误信号。通过使用样本树对你在练习 2.67 中获得的结果进行编码,并查看它是否与原始样本消息相同来测试你的函数。
练习 2.69
以下函数以其参数为一个符号-频率对的列表(其中没有一个符号出现在多个对中),并根据 Huffman 算法生成 Huffman 编码树。
function generate_huffman_tree(pairs) {
return successive_merge(make_leaf_set(pairs));
}将转换成一个有序叶子集的make_leaf_set函数如上所示。使用make_code_tree编写successive_merge函数,以便连续合并集合中最小权重的元素,直到只剩下一个元素,即所需的 Huffman 树。(这个函数有点棘手,但并不是真的复杂。如果你发现自己设计了一个复杂的函数,那么你几乎肯定做错了什么。你可以充分利用我们使用有序集合表示的事实。)
练习 2.70
以下带有相关相对频率的八个符号字母表被设计用来高效地编码 1950 年代摇滚歌曲的歌词。(注意,“字母表”的“符号”不一定是单个字母。)
| A | 2 | NA | 16 |
|---|---|---|---|
| BOOM | 1 | SHA | 3 |
| GET | 2 | YIP | 9 |
| JOB | 2 | WAH | 1 |
使用generate_huffman_tree(练习 2.69)生成相应的 Huffman 树,并使用encode(练习 2.68)对以下消息进行编码:
找一份工作
Sha na na na na na na na na
找一份工作
Sha na na na na na na na na
Wah yip yip yip yip yip yip yip yip yip
Sha boom需要多少位来进行编码?如果我们对这个八个符号字母表使用固定长度编码,那么需要的最小位数是多少?
练习 2.71
假设我们有一个用于n个符号的赫夫曼树,并且符号的相对频率为1, 2, 4, ..., 2^(n–1)。为n=5绘制树;为n=10绘制树。在这样的树中(对于一般的n),编码最频繁的符号需要多少位?最不频繁的符号呢?
练习 2.72
考虑您在练习 2.68 中设计的编码函数。编码一个符号所需步骤的增长顺序是多少?确保包括在每个遇到的节点上搜索符号列表所需的步骤数。一般来说,回答这个问题是困难的。考虑相对频率如练习 2.71 中描述的n个符号的特殊情况,并给出编码字母表中最频繁和最不频繁的符号所需步骤数的增长顺序(作为n的函数)。
2.4 抽象数据的多重表示
我们引入了数据抽象,这是一种构建系统的方法,使得程序的大部分内容可以独立于实现程序操作的数据对象的选择而指定。例如,我们在 2.1.1 节中看到了如何将设计使用有理数的程序的任务与使用计算机语言的原始机制构造复合数据的任务分开。关键思想是建立一个抽象屏障——在这种情况下,有理数的选择器和构造器(make_rat、numer、denom)——它将有理数的使用方式与它们在列表结构方面的底层表示隔离开来。类似的抽象屏障将执行有理数算术的函数的细节(add_rat、sub_rat、mul_rat和div_rat)与使用有理数的“高级”函数隔离开来。生成的程序的结构如图 2.1 所示。
这些数据抽象屏障是控制复杂性的强大工具。通过隔离数据对象的底层表示,我们可以将设计大型程序的任务分解为可以分开执行的较小任务。但这种数据抽象还不够强大,因为对于数据对象来说,“底层表示”并不总是有意义的。
首先,一个数据对象可能有多个有用的表示方式,我们可能希望设计可以处理多个表示的系统。举个简单的例子,复数可以用两种几乎等效的方式表示:直角坐标形式(实部和虚部)和极坐标形式(幅度和角度)。有时直角坐标形式更合适,有时极坐标形式更合适。事实上,可以想象一个系统,其中复数以两种方式表示,并且用于操作复数的函数可以使用任一种表示。
更重要的是,编程系统通常是由许多人在较长时间内共同设计的,受到随时间变化的要求的影响。在这样的环境中,不可能让每个人事先就数据表示的选择达成一致。因此,除了将表示与使用隔离的数据抽象屏障之外,我们还需要将不同的设计选择与其他选择隔离开,并允许不同的选择在单个程序中共存。此外,由于大型程序通常是通过组合先前独立设计的模块创建的,我们需要一些约定,允许程序员将模块“增量”地合并到更大的系统中,即无需重新设计或重新实现这些模块。
在本节中,我们将学习如何处理可能由程序的不同部分以不同方式表示的数据。这需要构建通用函数——可以操作以多种方式表示的数据的函数。我们构建通用函数的主要技术是使用类型标签的数据对象,即包含有关如何处理它们的显式信息的数据对象。我们还将讨论数据导向编程,这是一种强大而方便的实现策略,用于通过加法组装具有通用操作的系统。
我们从简单的复数示例开始。我们将看到类型标签和数据导向风格如何使我们能够为复数设计独立的矩形和极坐标表示,同时保持抽象“复数”数据对象的概念。我们将通过定义复数的算术函数(add_complex、sub_complex、mul_complex和div_complex)来实现这一点,这些函数是基于通用选择器定义的,这些选择器可以访问复数的部分,而不考虑数字的表示方式。如图 2.19 所示,得到的复数系统包含两种不同的抽象屏障。 “水平”抽象屏障起到与图 2.1 中相同的作用。它们将“高级”操作与“低级”表示隔离开来。此外,还有一个“垂直”屏障,使我们能够分别设计和安装替代表示。

图 2.19 复数系统中的数据抽象屏障。
在第 2.5 节中,我们将展示如何使用类型标签和数据导向风格来开发通用算术包。这提供了函数(add、mul等),可以用于操作各种“数字”,并且在需要新类型的数字时可以轻松扩展。在第 2.5.3 节中,我们将展示如何在执行符号代数的系统中使用通用算术。
2.4.1 复数的表示
我们将开发一个系统,它可以对复数执行算术运算,这是一个简单但不切实际的示例,用于使用通用操作的程序。我们首先讨论复数的两种合理表示形式:有序对的矩形形式(实部和虚部)和极坐标形式(大小和角度)。第 2.4.2 节将展示如何通过使用类型标签和通用操作,使这两种表示可以在单个系统中共存。
与有理数一样,复数自然地表示为有序对。复数集可以被看作是一个二维空间,有两个正交轴,“实”轴和“虚”轴。(见图 2.20。)从这个角度来看,复数z = x + iy(其中i² = –1)可以被看作是平面上的点,其实部是x,虚部是y。复数的加法在这种表示中减少到坐标的加法:
Real-part(z[1] + z[2]) = Real-part(z[1]) + Real-part(z[2])
Imaginary-part(z[1] + z[2]) = Imaginary-part(z[1]) + Imaginary-part(z[2]) 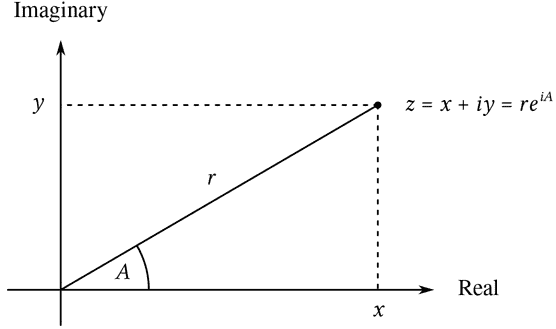
图 2.20 复数作为平面上的点。
当乘法复数时,更自然地考虑以极坐标形式表示复数,即大小和角度(图 2.20 中的r和A)。两个复数的乘积是通过拉伸一个复数的长度并通过另一个复数的角度旋转得到的向量:
Magnitude(z[1] · z[2]) = Magnitude(z[1]) · Magnitude(z[2])
Angle(z[1] · z[2]) = Angle(z[1]) + Angle(z[2]) 因此,复数有两种不同的表示形式,适用于不同的操作。然而,从使用复数的程序编写者的角度来看,数据抽象原则表明,无论计算机使用哪种表示形式,都应该提供操纵复数的所有操作。例如,通常有用的是能够找到由矩形坐标指定的复数的幅值。同样,通常有用的是能够确定由极坐标指定的复数的实部。
为了设计这样一个系统,我们可以遵循与在 2.1.1 节中设计有理数包时相同的数据抽象策略。假设复数的操作是根据四个选择器实现的:real_part、imag_part、magnitude和angle。还假设我们有两个用于构造复数的函数:make_from_real_imag返回具有指定实部和虚部的复数,make_from_mag_ang返回具有指定幅值和角度的复数。这些函数具有这样的属性,对于任何复数z,都有
make_from_real_imag(real_part(z), imag_part(z));和
make_from_mag_ang(magnitude(z), angle(z));产生等于z的复数。
使用这些构造函数和选择器,我们可以使用构造函数和选择器指定的“抽象数据”来实现复数的算术运算,就像我们在 2.1.1 节中对有理数所做的那样。如上面的公式所示,我们可以根据实部和虚部相加和相减复数,而根据幅值和角度相乘和相除复数:
function add_complex(z1, z2) {
return make_from_real_imag(real_part(z1) + real_part(z2),
imag_part(z1) + imag_part(z2));
}
function sub_complex(z1, z2) {
return make_from_real_imag(real_part(z1) - real_part(z2),
imag_part(z1) - imag_part(z2));
}
function mul_complex(z1, z2) {
return make_from_mag_ang(magnitude(z1) * magnitude(z2),
angle(z1) + angle(z2));
}
function div_complex(z1, z2) {
return make_from_mag_ang(magnitude(z1) / magnitude(z2),
angle(z1) - angle(z2));
}为了完成复数包,我们必须选择一种表示,并且必须根据原始数字和原始列表结构实现构造函数和选择器。有两种明显的方法可以做到这一点:我们可以将复数表示为“矩形形式”,即一对(实部,虚部),或者将其表示为“极坐标形式”,即一对(幅值,角度)。我们应该选择哪一种呢?
为了使不同的选择具体化,想象有两个程序员,Ben Bitdiddle 和 Alyssa P. Hacker,他们独立设计复数系统的表示。Ben 选择用矩形形式表示复数。通过这种选择,选择复数的实部和虚部是直接的,就像构造具有给定实部和虚部的复数一样。为了找到幅值和角度,或者构造具有给定幅值和角度的复数,他使用三角关系
x = r cos A
r = √(x² + y²)
y = r sin A
A = arctan(y, x) 这些关系将实部和虚部(x, y)与幅值和角度(r, A)联系起来。因此,Ben 的表示由以下选择器和构造函数给出:
function real_part(z) { return head(z); }
function imag_part(z) { return tail(z); }
function magnitude(z) {
return math_sqrt(square(real_part(z)) + square(imag_part(z)));
}
function angle(z) {
return math_atan2(imag_part(z), real_part(z));
}
function make_from_real_imag(x, y) { return pair(x, y); }
function make_from_mag_ang(r, a) {
return pair(r * math_cos(a), r * math_sin(a));
}相比之下,Alyssa 选择用极坐标形式表示复数。对她来说,选择幅值和角度是直接的,但她必须使用三角关系来获得实部和虚部。Alyssa 的表示是:
function real_part(z) {
return magnitude(z) * math_cos(angle(z));
}
function imag_part(z) {
return magnitude(z) * math_sin(angle(z));
}
function magnitude(z) { return head(z); }
function angle(z) { return tail(z); }
function make_from_real_imag(x, y) {
return pair(math_sqrt(square(x) + square(y)),
math_atan2(y, x));
}
function make_from_mag_ang(r, a) { return pair(r, a); }数据抽象的学科确保add_complex、sub_complex、mul_complex和div_complex的相同实现将适用于 Ben 的表示或 Alyssa 的表示。
2.4.2 标记数据
将数据抽象视为“最小承诺原则”的应用之一。在 2.4.1 节中实现复数系统时,我们可以使用 Ben 的矩形表示或 Alyssa 的极坐标表示。由选择器和构造函数形成的抽象屏障使我们能够在最后可能的时刻推迟对数据对象的具体表示的选择,从而在系统设计中保留最大的灵活性。
最小承诺原则可以被推到更极端的程度。如果我们愿意,甚至可以在设计选择器和构造器之后保持表示的模糊性,并选择同时使用本的表示和 Alyssa 的表示。然而,如果两种表示都包含在一个系统中,我们将需要一些方法来区分极坐标形式的数据和矩形形式的数据。否则,例如,如果我们被要求找到一对(3,4)的“大小”,我们将不知道是回答 5(解释为矩形形式的数字)还是 3(解释为极坐标形式的数字)。实现这种区分的一种简单方法是在每个复数中包含一个类型标签——字符串“矩形”或“极坐标”。然后,当我们需要操作一个复数时,我们可以使用标签来决定应用哪个选择器。
为了操作带标签的数据,我们将假设我们有函数type_tag和contents,它们从数据对象中提取标签和实际内容(在复数的情况下是极坐标或矩形坐标)。我们还假设有一个函数attach_tag,它接受标签和内容,并产生一个带标签的数据对象。实现这一点的一种简单方法是使用普通的列表结构:
function attach_tag(type_tag, contents) {
return pair(type_tag, contents);
}
function type_tag(datum) {
return is_pair(datum)
? head(datum)
: error(datum, "bad tagged datum – type_tag");
}
function contents(datum) {
return is_pair(datum)
? tail(datum)
: error(datum, "bad tagged datum – contents");
}使用type_tag,我们可以定义谓词is_rectangular和is_polar,分别识别矩形和极坐标数:
function is_rectangular(z) {
return type_tag(z) === "rectangular";
}
function is_polar(z) {
return type_tag(z) === "polar";
}有了类型标签,Ben 和 Alyssa 现在可以修改他们的代码,使得他们的两种不同表示可以在同一个系统中共存。每当 Ben 构造一个复数时,他将其标记为矩形。每当 Alyssa 构造一个复数时,她将其标记为极坐标。此外,Ben 和 Alyssa 必须确保他们的函数名称不冲突。一种方法是让 Ben 在他的每个表示函数的名称后附加后缀rectangular,让 Alyssa 在她的函数名称后附加polar。这是 Ben 修改后的矩形表示,来自第 2.4.1 节:
function real_part_rectangular(z) { return head(z); }
function imag_part_rectangular(z) { return tail(z); }
function magnitude_rectangular(z) {
return math_sqrt(square(real_part_rectangular(z)) +
square(imag_part_rectangular(z)));
}
function angle_rectangular(z) {
return math_atan(imag_part_rectangular(z),
real_part_rectangular(z));
}
function make_from_real_imag_rectangular(x, y) {
return attach_tag("rectangular", pair(x, y));
}
function make_from_mag_ang_rectangular(r, a) {
return attach_tag("rectangular",
pair(r * math_cos(a), r * math_sin(a)));
}这是 Alyssa 修改后的极坐标表示:
function real_part_polar(z) {
return magnitude_polar(z) * math_cos(angle_polar(z));
}
function imag_part_polar(z) {
return magnitude_polar(z) * math_sin(angle_polar(z));
}
function magnitude_polar(z) { return head(z); }
function angle_polar(z) { return tail(z); }
function make_from_real_imag_polar(x, y) {
return attach_tag("polar",
pair(math_sqrt(square(x) + square(y)),
math_atan(y, x)));
}
function make_from_mag_ang_polar(r, a) {
return attach_tag("polar", pair(r, a));
}每个通用选择器都被实现为一个函数,该函数检查其参数的标签,并调用处理该类型数据的适当函数。例如,要获得复数的实部,real_part检查标签以确定是使用 Ben 的real_part_rectangular还是 Alyssa 的real_part_polar。在任何一种情况下,我们使用contents来提取裸的、未标记的数据,并根据需要将其发送到矩形或极坐标函数:
function real_part(z) {
return is_rectangular(z)
? real_part_rectangular(contents(z))
: is_polar(z)
? real_part_polar(contents(z))
: error(z, "unknown type – real_part");
}
function imag_part(z) {
return is_rectangular(z)
? imag_part_rectangular(contents(z))
: is_polar(z)
? imag_part_polar(contents(z))
: error(z, "unknown type – imag_part");
}
function magnitude(z) {
return is_rectangular(z)
? magnitude_rectangular(contents(z))
: is_polar(z)
? magnitude_polar(contents(z))
: error(z, "unknown type – magnitude");
}
function angle(z) {
return is_rectangular(z)
? angle_rectangular(contents(z))
: is_polar(z)
? angle_polar(contents(z))
: error(z, "unknown type – angle");
}为了实现复数算术运算,我们可以使用第 2.4.1 节中的相同函数add_complex、sub_complex、mul_complex和div_complex,因为它们调用的选择器是通用的,所以可以与任何表示一起使用。例如,函数add_complex仍然是
function add_complex(z1, z2) {
return make_from_real_imag(real_part(z1) + real_part(z2),
imag_part(z1) + imag_part(z2));
}最后,我们必须选择是使用本的表示法还是 Alyssa 的表示法来构造复数。一个合理的选择是,每当我们有实部和虚部时构造矩形数,每当我们有大小和角度时构造极坐标数:
function make_from_real_imag(x, y) {
return make_from_real_imag_rectangular(x, y);
}
function make_from_mag_ang(r, a) {
return make_from_mag_ang_polar(r, a);
}生成的复数系统的结构如图 2.21 所示。该系统已被分解为三个相对独立的部分:复数算术运算、Alyssa 的极坐标实现和 Ben 的矩形实现。极坐标和矩形实现可以由本和 Alyssa 分别编写,并且这两者都可以作为第三个程序员在抽象构造器/选择器接口的基础表示来实现复数算术函数。
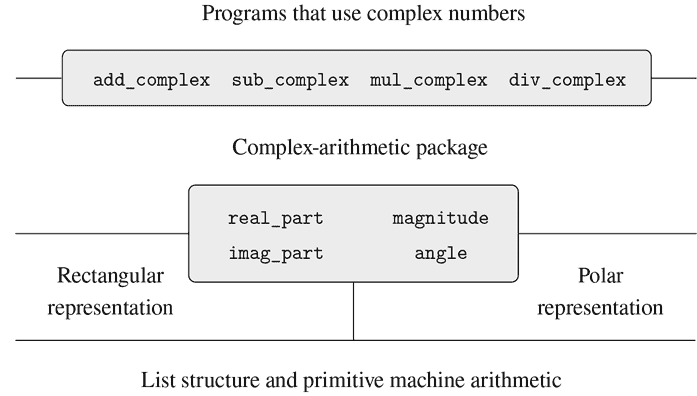
图 2.21 通用复数算术系统的结构。
由于每个数据对象都带有其类型标记,因此选择器以通用方式对数据进行操作。也就是说,每个选择器被定义为具有取决于其应用的特定数据类型的行为。注意将各个表示接口化的一般机制:在给定的表示实现中(比如,艾莉莎的极坐标包),复数是一个无类型的对(幅度,角度)。当通用选择器对polar类型的数字进行操作时,它会去掉标记并将内容传递给艾莉莎的代码。相反,当艾莉莎构造一个用于一般用途的数字时,她会给它打上一个类型标记,以便它可以被高级函数适当地识别。随着数据对象从一个级别传递到另一个级别时,去掉和附加标记的这种纪律可以成为一种重要的组织策略,我们将在第 2.5 节中看到。
2.4.3 数据导向编程和可加性
检查数据类型并调用适当的函数的一般策略称为类型分派。这是在系统设计中获得模块化的强大策略。另一方面,像在第 2.4.2 节中实现分派的方法有两个显著的弱点。一个弱点是通用接口函数(real_part、imag_part、magnitude和angle)必须了解所有不同的表示。例如,假设我们想将新的复数表示合并到我们的复数系统中。我们需要用类型标识这个新表示,然后在每个通用接口函数中添加一个子句,以检查新类型并应用该表示的适当选择器。
该技术的另一个弱点是,即使可以单独设计各个表示,我们必须保证整个系统中没有两个函数具有相同的名称。这就是为什么本和艾莉莎不得不更改他们在第 2.4.1 节中的原始函数的名称。
这两个弱点的根本问题是实现通用接口的技术不是可加的。实现通用选择器函数的人必须每次安装新表示时修改这些函数,而接口各个表示的人必须修改他们的代码以避免名称冲突。在这些情况下,必须对代码进行的更改是直截了当的,但仍然必须进行这些更改,这是一种不便和错误的来源。对于复数系统来说,这并不是什么大问题,但是假设复数有数百种不同的表示,而不是两种。假设抽象数据接口中有许多通用选择器需要维护。事实上,假设没有一个程序员知道所有接口函数或所有表示。这个问题是真实存在的,必须在大规模数据库管理系统等程序中加以解决。
我们需要的是进一步模块化系统设计的手段。这是由编程技术数据导向编程提供的。要理解数据导向编程的工作原理,首先观察一下,每当我们处理一组通用操作,这些操作对一组不同类型都是通用的时候,实际上,我们正在处理一个二维表,该表包含一个轴上可能的操作和另一个轴上可能的类型。表中的条目是为每种类型的参数实现每个操作的函数。在前一节中开发的复数系统中,操作名称、数据类型和实际函数之间的对应关系分散在通用接口函数的各种条件子句中。但是相同的信息可以组织在一个表中,如图 2.22 所示。

图 2.22 复数系统的操作表。
数据导向编程是一种直接设计程序与这样一个表一起工作的技术。以前,我们实现了将复数算术代码与两个表示包接口化的机制,作为一组函数,每个函数都对类型进行显式分派。在这里,我们将实现接口作为一个单一函数,该函数查找表中的操作名称和参数类型的组合,以找到正确的应用函数,然后将其应用于参数的内容。如果我们这样做,那么要向系统添加新的表示包,我们不需要更改任何现有的函数;我们只需要向表中添加新条目。
为了实现这个计划,假设我们有两个函数put和get,用于操作操作和类型表:
-
put(op, type, item)将
item安装在表中,由op和type索引。 -
get(op, type)查找表中的
op、type条目,并返回找到的项目。如果找不到项目,get返回一个唯一的原始值,该值由名称undefined引用,并由原始谓词is_undefined识别。
现在,我们可以假设put和get包含在我们的语言中。在第 3 章(第 3.3.3 节)中,我们将看到如何实现这些和其他操作来操作表。
以下是数据导向编程如何在复数系统中使用。开发了矩形表示的 Ben,实现他的代码就像他最初做的那样。他定义了一组函数或包,并通过向表中添加条目来将其接口化,告诉系统如何在矩形数上操作。这是通过调用以下函数完成的:
function install_rectangular_package() {
// internal functions
function real_part(z) { return head(z); }
function imag_part(z) { return tail(z); }
function make_from_real_imag(x, y) { return pair(x, y); }
function magnitude(z) {
return math_sqrt(square(real_part(z)) + square(imag_part(z)));
}
function angle(z) {
return math_atan(imag_part(z), real_part(z));
}
function make_from_mag_ang(r, a) {
return pair(r * math_cos(a), r * math_sin(a));
}
// interface to the rest of the system
function tag(x) { return attach_tag("rectangular", x); }
put("real_part", list("rectangular"), real_part);
put("imag_part", list("rectangular"), imag_part);
put("magnitude", list("rectangular"), magnitude);
put("angle", list("rectangular"), angle);
put("make_from_real_imag", "rectangular",
(x, y) => tag(make_from_real_imag(x, y)));
put("make_from_mag_ang", "rectangular",
(r, a) => tag(make_from_mag_ang(r, a)));
return "done";
}请注意,这里的内部函数与第 2.4.1 节中 Ben 在孤立工作时编写的相同函数。为了将它们接口化到系统的其余部分,不需要进行任何更改。此外,由于这些函数声明是内部的安装函数,Ben 不必担心与矩形包外的其他函数名称冲突。为了将这些接口化到系统的其余部分,Ben 将他的real_part函数安装在操作名称real_part和类型list("rectangular")下,其他选择器也是如此。接口还定义了外部系统要使用的构造函数。这些与 Ben 内部定义的构造函数相同,只是它们附加了标签。
Alyssa 的极坐标包类似:
function install_polar_package() {
// internal functions
function magnitude(z) { return head(z); }
function angle(z) { return tail(z); }
function make_from_mag_ang(r, a) { return pair(r, a); }
function real_part(z) {
return magnitude(z) * math_cos(angle(z));
}
function imag_part(z) {
return magnitude(z) * math_sin(angle(z));
}
function make_from_real_imag(x, y) {
return pair(math_sqrt(square(x) + square(y)),
math_atan(y, x));
}
// interface to the rest of the system
function tag(x) { return attach_tag("polar", x); }
put("real_part", list("polar"), real_part);
put("imag_part", list("polar"), imag_part);
put("magnitude", list("polar"), magnitude);
put("angle", list("polar"), angle);
put("make_from_real_imag", "polar",
(x, y) => tag(make_from_real_imag(x, y)));
put("make_from_mag_ang", "polar",
(r, a) => tag(make_from_mag_ang(r, a)));
return "done";
}尽管 Ben 和 Alyssa 仍然使用彼此相同名称的原始函数(例如real_part),但这些声明现在是内部不同函数的(参见第 1.1.8 节),因此没有名称冲突。
复数算术选择器通过一个名为apply_generic的通用“操作”函数访问表,该函数将通用操作应用于一些参数。函数apply_generic在表中查找操作的名称和参数的类型,并在存在的情况下应用结果函数。
function apply_generic(op, args) {
const type_tags = map(type_tag, args);
const fun = get(op, type_tags);
return ! is_undefined(fun)
? apply_in_underlying_javascript(fun, map(contents, args))
: error(list(op, type_tags),
"no method for these types – apply_generic");
}使用apply_generic,我们可以定义我们的通用选择器如下:
function real_part(z) { return apply_generic("real_part", list(z)); }
function imag_part(z) { return apply_generic("imag_part", list(z)); }
function magnitude(z) { return apply_generic("magnitude", list(z)); }
function angle(z) { return apply_generic("angle", list(z)); }注意,如果系统中添加了新的表示,这些都不会改变。
我们还可以从表中提取构造函数,供程序包外的程序使用,从实部和虚部以及从幅度和角度构造复数。与第 2.4.2 节一样,我们在有实部和虚部时构造矩形数,在有幅度和角度时构造极坐标数:
function make_from_real_imag(x, y) {
return get("make_from_real_imag", "rectangular")(x, y);
}
function make_from_mag_ang(r, a) {
return get("make_from_mag_ang", "polar")(r, a);
}练习 2.73
第 2.3.2 节描述了一个执行符号微分的程序:
function deriv(exp, variable) {
return is_number(exp)
? 0
: is_variable(exp)
? is_same_variable(exp, variable) ? 1 : 0
: is_sum(exp)
? make_sum(deriv(addend(exp), variable),
deriv(augend(exp), variable))
: is_product(exp)
? make_sum(make_product(multiplier(exp),
deriv(multiplicand(exp), variable)),
make_product(deriv(multiplier(exp), variable),
multiplicand(exp)))
// more rules can be added here
: error(exp, "unknown expression type – deriv");
}
deriv(list("*", list("*", "x", "y"), list("+", "x", 4)), "x");
list("+", list("*", list("*", x, y), list("+", 1, 0)),
list("*", list("+", list("*", x, 0), list("*", 1, y)),
list("+", x, 4)))我们可以将这个程序视为对要进行区分的表达式类型进行调度。在这种情况下,数据的“类型标签”是代数运算符号(如+),正在执行的操作是deriv。我们可以通过将基本导数函数重写为数据导向风格来将这个程序转换为数据导向风格
function deriv(exp, variable) {
return is_number(exp)
? 0
: is_variable(exp)
? is_same_variable(exp, variable) ? 1 : 0
: get("deriv", operator(exp))(operands(exp), variable);
}
function operator(exp) { return head(exp); }
function operands(exp) { return tail(exp); }-
a. 解释上面做了什么。为什么我们不能将谓词
is_number和is_variable合并到数据导向调度中? -
b. 编写求和和乘积的导数函数,以及安装它们在上面程序使用的表中所需的辅助代码。
-
c. 选择任何你喜欢的额外区分规则,比如指数的规则(练习 2.56),并将其安装在这个数据导向系统中。
-
d. 在这个简单的代数操作程序中,表达式的类型是将其绑定在一起的代数运算符。然而,假设我们以相反的方式索引函数,使得
deriv中的调度行看起来像get(operator(exp), "deriv")(operands(exp), variable);对导数系统的相应更改是什么?
练习 2.74
Insatiable Enterprises, Inc.是一个高度分散的企业集团公司,由遍布全球的大量独立部门组成。该公司的计算机设施刚刚通过一种巧妙的网络接口方案相互连接,使得整个网络对任何用户来说都像是一台单一的计算机。Insatiable 的总裁在首次尝试利用网络从部门档案中提取行政信息时,惊讶地发现,尽管所有部门的档案都以 JavaScript 中的数据结构实现,但使用的特定数据结构因部门而异。部门经理们匆忙召开会议,寻求一种整合档案的策略,既能满足总部的需求,又能保留部门的现有自治权。
展示如何使用数据导向编程实现这样的策略。例如,假设每个部门的人事档案都包含一个单一文件,其中包含以员工姓名为键的一组记录。集合的结构因部门而异。此外,每个员工的记录本身是一个集合(在不同部门结构不同),其中包含以address和salary为标识的信息。特别是:
-
a. 为总部实现一个
get_record函数,该函数从指定的人事档案中检索指定员工的记录。该函数应适用于任何部门的档案。解释个别部门的档案应该如何结构化。特别是,必须提供什么类型的信息? -
b. 为总部实现一个
get_salary函数,该函数从任何部门的人事档案中返回给定员工的薪水信息。为了使此操作起作用,记录应该如何结构化? -
c. 为总部实现一个
find_employee_record函数。这个函数应该搜索所有部门的档案,找到给定员工的记录并返回记录。假设这个函数的参数是员工的姓名和所有部门档案的列表。 -
d. 当贪婪公司接管新公司时,必须进行哪些更改才能将新员工信息整合到中央系统中?
消息传递
数据导向编程的关键思想是通过显式处理操作和类型表来处理程序中的通用操作,比如图 2.22 中的表。我们在 2.4.2 节中使用的编程风格通过让每个操作负责自己的调度来组织所需的类型调度。实际上,这将操作和类型表分解为行,每个通用操作函数代表表的一行。
另一种实现策略是将表分解为列,而不是使用在数据类型上分派的“智能操作”,而是使用在操作名称上分派的“智能数据对象”。我们可以通过安排事物,使得数据对象,如矩形数,表示为一个函数,该函数以所需的操作名称作为输入,并执行指示的操作。在这样的学科中,make_from_real_imag可以被写成
function make_from_real_imag(x, y) {
function dispatch(op) {
return op === "real_part"
? x
: op === "imag_part"
? y
: op === "magnitude"
? math_sqrt(square(x) + square(y))
: op === "angle"
? math_atan(y, x)
: error(op, "unknown op – make_from_real_imag");
}
return dispatch;
}相应的apply_generic函数,将通用操作应用于参数,现在只需将操作名称传递给数据对象,让对象完成工作:⁴⁵
function apply_generic(op, arg) { return head(arg)(op); }请注意,make_from_real_imag返回的值是一个函数——内部的dispatch函数。这是在apply_generic请求执行操作时调用的函数。
这种编程风格称为消息传递。这个名字来自这样一个形象,即数据对象是一个接收所请求的操作名称作为“消息”的实体。我们已经在第 2.1.3 节中看到了消息传递的一个例子,在那里我们看到了如何定义pair,head和tail,而不是数据对象,而只是函数。在这里,我们看到消息传递不是一个数学技巧,而是一种组织具有通用操作的系统的有用技术。在本章的其余部分,我们将继续使用数据导向编程,而不是消息传递,来讨论通用算术操作。在第 3 章中,我们将回到消息传递,并且我们将看到它可以是一种构建仿真程序的强大工具。
练习 2.75
以消息传递方式实现构造函数make_from_mag_ang。这个函数应该类似于上面给出的make_from_real_imag函数。
练习 2.76
随着具有通用操作的大型系统的发展,可能需要新类型的数据对象或新操作。对于三种策略——具有显式分派的通用操作、数据导向风格和消息传递风格——描述必须对系统进行的更改,以添加新类型或新操作。对于经常需要添加新类型的系统,哪种组织方式最合适?对于经常需要添加新操作的系统,哪种组织方式最合适?
2.5 具有通用操作的系统
在前一节中,我们看到了如何设计系统,其中数据对象可以以多种方式表示。关键思想是通过通用接口函数将指定数据操作的代码与多种表示链接起来。现在我们将看到如何使用相同的思想,不仅定义可以适用于不同表示的操作,还可以定义可以适用于不同类型参数的操作。我们已经看到了几种不同的算术操作包:语言内置的原始算术(+,-,*,/),第 2.1.1 节中的有理数算术(add_rat,sub_rat,mul_rat,div_rat),以及我们在第 2.4.3 节中实现的复数算术。现在我们将使用数据导向技术来构建一个包含我们已经构建的所有算术包的算术操作包。
图 2.23 显示了我们将构建的系统的结构。注意抽象屏障。从使用“数字”的人的角度来看,有一个单一的函数add,它对提供的任何数字进行操作。函数add是通用接口的一部分,它允许使用数字的程序以统一的方式访问单独的普通算术、有理算术和复数算术包。任何单独的算术包(如复数包)本身可以通过通用函数(如add_complex)访问,这些函数结合了为不同表示设计的包(如矩形和极坐标)。此外,系统的结构是可加性的,因此可以单独设计各个算术包,并将它们组合以产生通用算术系统。
图 2.23 通用算术系统。
2.5.1 通用算术操作
设计通用算术操作的任务类似于设计通用复数操作。例如,我们希望有一个通用加法函数add,它在普通数字上的行为类似于普通原始加法+,在有理数上类似于add_rat,在复数上类似于add_complex。我们可以通过遵循与我们在 2.4.3 节中用于实现复数的通用选择器相同的策略来实现add和其他通用算术操作。我们将为每种数字类型附加一个类型标签,并使通用函数根据其参数的数据类型分派到适当的包。
通用算术函数定义如下:
function add(x, y) { return apply_generic("add", list(x, y)); }
function sub(x, y) { return apply_generic("sub", list(x, y)); }
function mul(x, y) { return apply_generic("mul", list(x, y)); }
function div(x, y) { return apply_generic("div", list(x, y)); }我们首先安装一个用于处理普通数字的包,即我们语言的原始数字。我们用字符串javascript_number标记这些数字。此包中的算术操作是原始算术函数(因此无需定义额外的函数来处理未标记的数字)。由于这些操作每个都需要两个参数,它们被安装在由列表list("javascript_number", "javascript_number")键入的表中。
function install_javascript_number_package() {
function tag(x) {
return attach_tag("javascript_number", x);
}
put("add", list("javascript_number", "javascript_number"),
(x, y) => tag(x + y));
put("sub", list("javascript_number", "javascript_number"),
(x, y) => tag(x - y));
put("mul", list("javascript_number", "javascript_number"),
(x, y) => tag(x * y));
put("div", list("javascript_number", "javascript_number"),
(x, y) => tag(x / y));
put("make", "javascript_number",
x => tag(x));
return "done";
}JavaScript-number 包的用户将通过函数创建(标记)普通数字:
function make_javascript_number(n) {
return get("make", "javascript_number")(n);
}现在通用算术系统的框架已经建立,我们可以轻松地包含新类型的数字。这是一个执行有理数算术的包。注意,由于可加性的好处,我们可以在包中使用 2.1.1 节中的有理数代码作为内部函数,而无需修改:
function install_rational_package() {
// internal functions
function numer(x) { return head(x); }
function denom(x) { return tail(x); }
function make_rat(n, d) {
const g = gcd(n, d);
return pair(n / g, d / g);
}
function add_rat(x, y) {
return make_rat(numer(x) * denom(y) + numer(y) * denom(x),
denom(x) * denom(y));
}
function sub_rat(x, y) {
return make_rat(numer(x) * denom(y) - numer(y) * denom(x),
denom(x) * denom(y));
}
function mul_rat(x, y) {
return make_rat(numer(x) * numer(y),
denom(x) * denom(y));
}
function div_rat(x, y) {
return make_rat(numer(x) * denom(y),
denom(x) * numer(y));
}
// interface to rest of the system
function tag(x) {
return attach_tag("rational", x);
}
put("add", list("rational", "rational"),
(x, y) => tag(add_rat(x, y)));
put("sub", list("rational", "rational"),
(x, y) => tag(sub_rat(x, y)