
人工智能、机器学习及深度学习的区别与联系
一、 说明
1.1 背景说明
记得在学校的时候火的是大数据、云计算和物联网,毕业后网上就开始很多讨论人工智能(还有区块链)。当只是网上听说的时候总觉得比较遥远,心里并没有很大的重视,直到有一天忘了是下午回去上班还是下午下班,和他走在路上的时候他也得到了人工智能。
他说,你说我们算1+1就是按规定1+1就是等于2,那你知道人工智能是怎么算1+1的吗,他不是像我们这么算的他是通过学习0.5+0.5=1、2+2=4这样慢慢去推测1+1等于多少的,所以他算出的1+1不一定等于2,当然学习的数据越多结果就越准确。
说到这位小哥另外还不得不提,虽然我看书的习惯不是受这位小哥的影响而形成的,但买书的习惯是受这位小哥的影响形成的,可能还有点青出于蓝的意思,之前我都想着去学校或者区图书馆的,他让我知道可以在亚马逊上买书。当然最近一位大学同学的言传身教又让我感觉去图书馆也挺合适的,为啥就不展开了你要懂其实自己应该可以懂,主要是想说有时经历越多越感觉孔子等人说的话实在很是经典,比如这句三人行必有我师焉,每个人都有其独特的经历(至少相较于你是独特的)每个人都有其独特的经验与感悟每个人都有其值得你学习、借鉴乃至敬重的地方。所以现在而言我总愿意接触更多的人,去听他们的故事和想法。另外同时也想说,我个人一直不太喜欢(或者叫敢)对一件事物并不了解就人云亦云地对其评头品足,比如你连四书五经是什么都不知道你就反对(我觉得《大学》和《中庸》讲得都还挺好的)或者再比如你连马克思主义是什么都不知道你就反对;我挺佩服这位小哥的一点感觉他知道一点就能侃侃而谈,当然最主要的是其判断时常没有很大的偏差。
受此番讨论影响,又回家志趣甚高地拿起了刚买不久的周志华的那本《机器学习》,然后看着那些复杂的数学符号和公式灰心丧气地确认自己看不懂,自己的机器学习之路就此告一段落了。说实话到现在关于高等数学,我大概只模糊记得微分是求导、积分是求面积。
到S市后专门做了安全方面的工作,另外说形成了通过买书来学习的习惯,在找书时看到刘焱的AI安全三部曲,又是AI又是安全的就买了回来。但感觉其内容和周志华的《机器学习》很不一样就有点迷糊了,然后又买了《深度学习框架PyTorch入门与实践》和《TensorFlow实战Google深度学习框架》,这两本的内容又和前边两本又不太一样,加之当时代码能力又有限,只能再次认为人工智能太过博大精深,自己一时间是搞不定了。
去年和一位朋友学习时也有时会提起人工智能,我只能根据自己的感觉判断说机器学习根本不是单纯的一种算法而是一系列算法的集合,这些算法也不是最近才出现的而是很久以前就有了只是现在能收集的数据比较多电脑的计算能力也上来了所以机器学习火了起来,虽然尽量假装得理直气壮但确实没有很多底气。
其实每每谈到人工智能都是这样,如同骨梗在喉。肺炎打乱了年前的一些计划,但困在家也让自己有时间拿下人工智能这一知识框架里边最后一张拼图。
当然也有一些曲折,一是在家时间长了工作学习的效率就比较低,二是本来想好的腾出一周时间中间又抽了几天加班,三是连接GitHub等国外的网站速度比较慢**在这时期又被封了下了文件下半天甚至失败很坏心情,四是一方面周志华的那本《机器学习》给的阴影比较大另一方面有一些其他的事可以去做如同面临围城必缺态度有点消极。不过好在一是这一年多来编程有很大的进步,二是上边说到的几本书也算是翻过了几轮不须要重头理解,三是最重要的昨天看了《Web安全机器学习入门》这本书在GitHub上的源代码每个例子也就一百来行容易看懂。
1.2 内容说明
本文大数多内容总结自刘焱的AI安全三部曲:《Web安全机器学习入门》、《Web安全深度学习实践》、《Web安全强化学习与GAN》。
刘焱GitHub地址:https://github.com/duoergun0729(三本书对应的项目依次是1book、2book、3book)
另外对项目目录结构做一些说明:《Web安全机器学习入门》各章节与1book各python文件对应关系书中有明确说明;《Web安全深度学习实践》基本是一章一个python代码文件,在每章的开头都有说明本章对应的代码文件是哪个,另外也可直接自行按单节名与文件名对应。
二、人工智能、机器学习和深度学习
2.1 三者定义与关系
人工智能:凡是有if-else等分支语句的程序都可以算是人工智能。比如没检测到人进门时不开灯检测到人进门就开灯这种就可以算人工智能。
机器学习:假设特征x和输出结果y的关系为y = w(x),我们得出l = (y1 - y1') ^2 + (y2 - y2') ^2 + ... = (y1 - w(x1)) ^2 + (y2 - w(x2)) ^2 + ...,这么一个关于w的结果损失函数; 其中y为事实的结果,y‘为计算得出的结果,显然损失结果l值越小则y和y’就越接近,我们可以求出关于w的导数,当导函数值有负数时由负转正时原函数值最小,在实际中使用随机梯度下降 + 学习率不断调整w(即反向传播)。通过类似这种形式求(学习)出w的过程就是机器学习,原关系函数 + 损失函数 + w值就是所谓的模型。
深度学习:深度学习和机器学习一样,都是学习y = w(x)中的w; 但机器学习的w一般只有一个隐蔵层,而深度学习的w一般是多个隐蔵层,这即所谓“深度”的原因。深度学习w较机器学习复杂,所以适配性更强,所以在图片、音频、视频等有大量输入但特征又不那么明显的地方较机器学习效果更好。
总之他们的关系是:人工智能 > 机器学习 > 深度学习,是包含关系; 但在现实讨论中一般在前者中剔除后者,用其并列关系。
2.2 机器学习
2.2.1 机器学习算法集合
机器学习算法集合包括:K近邻算法(这个基本不学习)、决策树与随机森林算法、朴素贝叶斯算法、逻辑回归算法、支持向量机算法、K-Means与DBSCAN算法、Apriori与FP-growth算法、隐式马尔可夫算法。
所以机器学习并不是单一的一个算法,而是诸多算法的集合。
那机器学习有这么多算法,他们用途的区别是什么呢,每个算法用于不同的场景吗,比如处理文本用这个算法处理图形用另外一个算法。
其实不是,这些算法并不是某个人某个组织系统地提出的机器学习方案,而是不同的人针对机器学习这一概念提出的自己的算法,所以这些算法可能某个特定的场景这个算法准确度高一些那个算法准确度低一些,但总体而言这些算法具有通用性。粗爆地说就是能用某种算法的地方肯定也可以换成其他算法,比如大家都一样可以检测暴力破解,大家也都可以检测WebShell。或者再打个比方说我们有很多排序算法,比如冒泡排序、快速排序、堆排序等等,各种排序算法在数据量不一样的情况下快慢有些区别,但大家都可以用来排序。
2.2.2 机器学习的通用步骤
基本所有机器学习都是以下5个步骤:源数据、确定特征集、特征集数值化、学习、使用。
源数据:就是格式统一的一堆记录;比如Apache的日志、数据库表中的记录等等。
确定特征集:就是你得选择一些字段集,通过这些字段集能够区分正常记录和你的目标记录。比高的、富的、帅的是你理想的男朋友,[高、富、帅]就组成了一个特征集(我们还可以选择更多的特征以做出更精细化的判断)。
特征集数值化:计算机不擅长处理“高”、“富”、“帅”这种文字的运算的只擅长数值的运算,所以本质上我们要以数值代之实现运算数值得出数值。比如0代表不高1代表高,0代表不富1代表富,0代表不帅1代表帅,0代表不值得交往1代表值得交 往。“高的、富的、帅的”-> 值得交往,就转成了[1,1,1] -> 1。
学习:我们给机器学习算法提供[1,1,0] -> 1,[1,1,1] -> 0等很多的因果数据,机器学习算法根据这些数据+自己算法本身代码整理出因果判断模式,这个过程就是学习。(所谓的因果判断模式本质上是一种概率,这也是很多人批评说所谓机器学习不过就是统计学、概率论的原因)
使用:在上一步学习中机器学习算法已经整理出了因果判断模式,当我们提供一个[0,1,1]的输入时,他就能根据模式给出他的判断结果(即0或1)。
简单而言机器学习就是通过“给定数据+既定算法代码”生成一个各特征的比重关系及与结果的对应关系。比如在上边交往的例子中,假定根据你的喜好得出各特征比重关系最终是高占30%比重富点30%比重帅占40%比重,假定根据你的喜好得出结果关系是具体的某个人如果计算出小于0.6就给出0不推荐交往大于0.6则给出1推荐交往。
2.2.3 机器学习示例及为什么说初级的机器学习就是调包侠
在上一小节中我们提到机器学习分五个步骤,我们去编程时也就是这五个步骤的代码化。
其中前三个步骤和机器学习没什么强关系后两步才和机器学习有关系,而且后两步中机器学习算法本身的代码是固定的封装在写好的类及类的方法中并不需要我们去实现,我们使用机器学习算法顶多就是实例化类、给其传参数、调用其方法。
还是和排序一个意思,我们要排序要做的就是准备好要排序的数组,传给排序方法,最后得到排序结果。像快速排序等这些排序算法原理可能够写一本书,但是不好意思我完全可以不用知道,我就只要调用就好了。
所以看一些初级的机器学习代码,假设其有100行,那么90行是在准备数据10行是在调用机器学习的类及其方法。在这个层次上机器学习编程与普通编程维一的区别就只是:机器学习调用的是机器学习的类和方法、仅此而已。
另外“10行是在调用机器学习的类及其方法”同时意味着我们从一种机器学习方法更换成另一种机器学习方法,就只是把这“10行”从“调用这个机器学习算法对应的类及其方法”改成“调用那个机器学习算法对应的类及其方法”,又仅此而已。
当然我们要有理有据,《Web安全机器学习入门》很多例子都如出一辙,比如都类似如下,换种算法基本就只是把KNeighborsClassifier(n_neighbors=3)换成其他算法对应的类:
if __name__ == '__main__': user_cmd_list,dist=load_user_cmd_new("../data/MasqueradeDat/User3") print "Dist:(%s)" % dist user_cmd_feature=get_user_cmd_feature_new(user_cmd_list,dist) #print user_cmd_feature labels=get_label("../data/MasqueradeDat/label.txt",2) y=[0]*50+labels x_train=user_cmd_feature[0:N] y_train=y[0:N] x_test=user_cmd_feature[N:150] y_test=y[N:150] neigh = KNeighborsClassifier(n_neighbors=3) neigh.fit(x_train, y_train) y_predict=neigh.predict(x_test) score=np.mean(y_test==y_predict)*100
(可直接自己去看一例完整的代码:https://github.com/duoergun0729/1book/blob/master/code/5-3.py)
2.3 深度学习
2.3.1 深度学习算法集合
深度学习算法集合包括:卷积神经网络算法(Convolution Neural Network,CNN)、循环神经网络算法(Recurrent Nerual Network,RNN)。
2.3.2 我们使用深度学习时代码是比机器学习复杂一点点但也就一点点
在2.2.3中我们说各机器学习算法的使用是比较简单的,那么深度学习使用起来是不是会复杂一点呢。我们直接来看《Web安全深度学习实战》给出的CNN例子。对比2.2.4中的普通机器学习算法,其唯一的区别只是单纯的实例化一个算法类变成了需要配置更多参数进行实例化的network网络(或叫model,其定义符合“输入层 -> ( 卷积层+ -> 池化层? )+ -> 全连接层”模式,其中+号表示一次或多次、?表示0或1次)。
从《Web安全深度学习实战》到《深度学习框架PyTorch入门与实践》、《TensorFlow实战Google深度学习框架》两本书可能会让人感觉有比较大的鸿沟。这种感觉的由来,一是从内容结构上第一本直接讲用法后两本还要多介绍框架提供的数据加载、处理、可视化等功能,二是第一本书更多使用“原始”的代码去处理数据而后两本书的代码使用了框架提供的额外能力使得代码相似度降低,三是最主要的第一本书只实现了最基础的深度学习使用方法而后两本书实现了更严谨的深度学习使用方法使得代码得杂度又进一步提高(比如更灵活的激活函数、损失函数、优化器等等)。但不需要怀疑的是深度学习本质上还是和机器学习一样是那几大步骤,这不是空口无凭的臆测而是我初步阅读《深度学习框架PyTorch入门与实践》猫狗分类代码后的结论,虽然有很多代码片段没了解其原理但整个流程就是在实现那几大步骤。
def do_cnn_2d(X, Y, testX, testY ): # Building convolutional network network = input_data(shape=[None, 28, 28, 1], name='input') network = conv_2d(network, 32, 3, activation='relu', regularizer="L2") network = max_pool_2d(network, 2) network = local_response_normalization(network) network = conv_2d(network, 64, 3, activation='relu', regularizer="L2") network = max_pool_2d(network, 2) network = local_response_normalization(network) network = fully_connected(network, 128, activation='tanh') network = dropout(network, 0.8) network = fully_connected(network, 256, activation='tanh') network = dropout(network, 0.8) network = fully_connected(network, 10, activation='softmax') network = regression(network, optimizer='adam', learning_rate=0.01, loss='categorical_crossentropy', name='target') # Training model = tflearn.DNN(network, tensorboard_verbose=0) model.fit({'input': X}, {'target': Y}, n_epoch=5, validation_set=({'input': testX}, {'target': testY}), snapshot_step=100, show_metric=True, run_id='mnist')
三、深度学习框架
常见的机器学习框架有如Scikit-Learn,其但一是因为机器学习是由一个个相互独立的算法组成相互间关系不大,二是机器学习代码还是比较简短,所以机器学习框架一般没那么出名。
说框架都是一般深度学习框架,比如AlphaGo所基于的TensorFlow(2015.11,Google)及风头越来越盛的PyTorch(2017.01,Facebook)都是深度学习框架。深度学习框架做的事情,一是是提供一些将对性的数据加载、处理等函数,二是提供神经网络定义模块nn。
3.1 TensorFlow和PyTorch的区别
深度学习框架一般都是基于计算图的,计算图又分为静态计算图和动态计算图,所谓“图”可以理解为深度学习框架中的变量、代码执行顺序。
TensorFlow使用的是静态计算图,在静态计算图模式中所有可能需要用到的计算图都需要在一开始就定义好,这使得TensorFlow一方面不能很好地利用编程语言中的if-else等现成语句,另一方面又需要引入其他设计以实现分支等逻辑,增大了学习成本。
PyTorch使用的是动态计算图,在动态计算图模式中所有计算图都可以在运行之中进行再进行定义,动态图的这种特性使得其可以充分利用语言现成的语法,尽可能降低了用户的学习成本。这也是PyTorch能后来居上的根本原因。
3.2 PyTorch简介
3.2.1 PyTorch安装
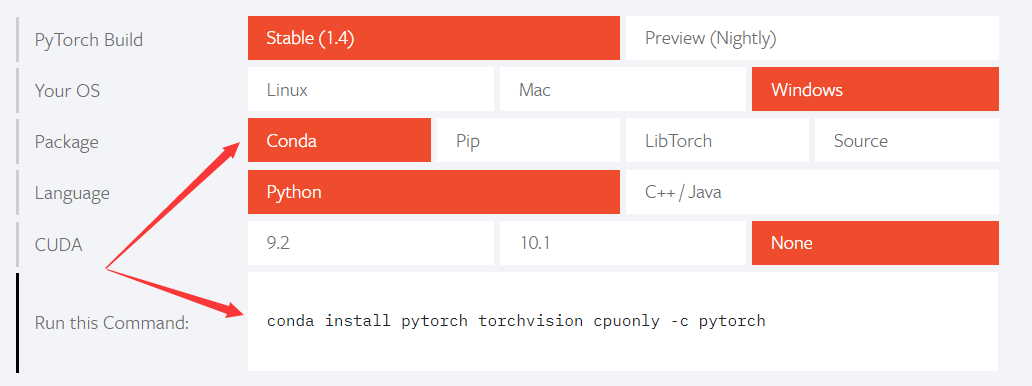
打开官网(https://pytorch.org/),按自己环境进行选择即可得到相应版本的安装命令。其中CUDA表示显卡支持,如果是一般的显卡建议就不要选了。
3.2.2 PyTorch的基本使用框架示例
在2.3.3中提到自己阅读了PyTorch的一个示例代码,但自己并没有真正实现心是还是不是很有底气。
(本节待实现...)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号