
模糊测试工具设计思路浅谈
一、说明
去年写了一篇“模糊测试(fuzzing)是什么”,在最后提到可以自己手动编写实现模糊测试工具,但一直没把可行的代码放上来。
其实这不是光说不练没实现,而是在去年就着手编写了,并在前段时间发现参数未做防呆处理导致设备重启上收到了很好的效果,只是一是说代码涉及产品具体业务需要进行处理二是说对之前做到一半没做完的事时常缺乏兴趣回头继续做。
二、模糊测试中的几个关键问题讨论
2.1 如何标识模糊测试项
标识模糊测试项有两大思路:一类是sqlmap的无标识思路,另一类是burpsuite的有标识思路。
sqlmap无标识思路:自动分析数据中的参数,然后逐个参数进行测试;优点是使用方便,缺点是如果协议的结构性越差则其参数分析逻辑就要越复杂且不能只测试指定的参数。如sqlmap -d "username=admin&password=abcd1234" -u "http://192.168.1.1/login",此时sqlmap就会分析出username和password两个参数然后进行测试。
burpsuite的有标识思路:直接使用额外标志标识出要测试的位置;优点是不需要复杂的参数解析代码能测试指定的位置(不过注意其实burpsuite是有参数分析代码的),缺点是需要用户手动标识出要测试的位置当api很多时是一项不小的工作量。在burpsuite的Intruder功能中可以看到各要进行测试的位置使用§符号围起来。
为了简单起见我这里使用burpsuite的有标识思路,标识标志是fuzzer_var()。
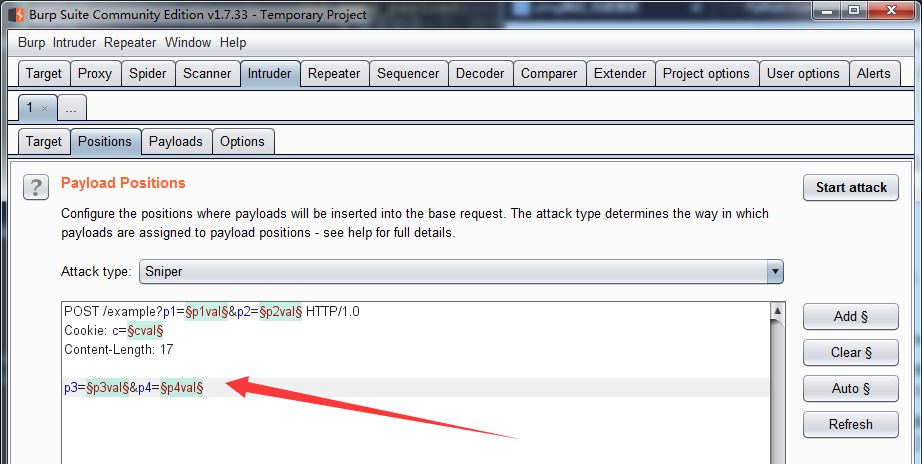
2.2 多个模糊测试项相同有如何处理
如下图所示中,两个要测试的位置我们使用了协定好的fuzzer_var()括了起来,但由于其原来的值都是admin,所以括起来后他们是一样的fuzzer_var(admin)。
这有两个问题,一是如果在代码上我们简单地将fuzzer_var(admin)替换成测试载荷如“AAA”,那么将是用户名密码同时被改为"AAA",与我们想要的先用户名“AAA”,再密码“AAA”不一致。二是在遍历时会重复出现用户名密码同为“AAA”(因为遍历到用户名时用户名密码都被改为“AAA”,而遍历到密码时又会再次出现用户名密码都被改为“AAA”)。
针对这两个问题我们做改下处理:首先是去重只保留一个如fuzzer_var(admin);其次是遍历api中的所有fuzzer_var(admin)。去重好理解,但遍历是如何遍历法呢?分三步,第一步是将已遍历过的还原为原始值,二是将遍历到的替换成测试载荷,三是将剩下的与去其fuzzer_var()一起去除。具体可见fuzzer.py中的send_payload()。

2.3 时序性协议处理
时序性协议有两重含义,一是指后边的请求需要使用前边请求的响应值,如B请求需要A响应的内容而C请求又需要B响应的内容;二是指请求是有强制的先后顺序的,比如一定要先完成A请求然后再完成B请求最后才能进行C请求,直接发送C请求服务器是不处理的。
针对这种情况,较之普通的模糊测试我们需要多两道处理程序:一是每个api需要使用一个函数去动态生成而不能直接写在api文件里边了;二是在测试后边请求时一定要确保前边请求都已正确通过不然请求不能有效测试。
时序性协议我这里使用rtsp协议进行演示,可以看到每个api都是使用一个gen_xxx_header()函数来生成。
2.4 二进制协议处理
前面说的http和rtsp协议可以称为是字符串的,但有些协议是二进制的;二进制的就意味着在接收到数据包时,一是服务端只会接收协议结构限制的长度(如果真做得很粗糙也不一定但至少说很容易限制长度),二是服务端对于接收到的数据只会按协议的结构去解析(比如一个字段是一个字节就是一个字节你构造一个超长字符串没用只是挤占掉后边的字段)。
所以对于二进制协议一般的模糊测试载荷是没有很大意义的,可行的思路是根据协议针对各个字段,在字段长度范围内构造攻击载荷。比如一个字段只有半个字节(4 bit)那么就遍历0到f,一个字段只有一个字节那你可以遍历00到ff,如果一个字段两字节那么就先外边for一个字节里边for一个字节。
这比较麻烦,我这里以snmp为例,但只是偷懒地认为一个字节一个字段的进行测试(即逐个字节遍历00到ff),以后如果再研究再写个规范的。
2.5 返回值监测问题
应当来讲在C语言时代,不管是文件模糊测试还是浏览器模糊测试还是网络协议模糊测试,认为有bug的标志都是处理程序崩溃,这种崩溃使用代码判断是比较麻烦的,比如一个请求发出去服务器没响应那怎么判断是网络不通还是服务器崩溃了?如果是服务器崩溃了那怎么恢复环境进行后续项测试?
总而言之最开始的模糊测试,以人观察到程序崩溃为标志是不需要模糊测试工具监测和分析返回值的,是半自动化而非会自动化的。我这里也不监测分析服务端响应。
而人们中了自动化的毒,希望整个流程都是自动化的,一定要全自动化那唯一的思路就是监测分析服务端响应并约定一些判定标准和制定一些恢复机制;而且监测分析返回值我偏向于认为那是扫描器的事。
当前Java等语言实现的服务端,出错也只是页面出错,中间件进程一般是不会崩溃的,又不监测分析服务端响应,那对于Java等使用中间件服务器的场景模糊测试岂不是没什么用?实话而言,这种情况下,是没什么用。
三、模糊测试工具具体实现
项目语言:Python3
依赖安装:pip install requests selenium scapy
github地址:https://github.com/PrettyUp/Fuzzer
项目目录结构及文件说明如下:
|
|--apis----模糊测试配置及api文件存放目录
| |--api.ini----fuzzer.py默认使用的配置及api文件,一般修改该文件即可测试自己的IP和协议
|
|--common----公共文件存放文件夹
| |--logger.py----自定义日志配置程序
| |--login.py----fuzzer.py使用的登录程序,需要根据自己系统登录逻辑修改该文件
|
|--fuzzers----模糊测试工具存放目录
| |--chromedriver.exe----chrome驱动程序
| |--geckodriver.exe----firefox驱动程序
| |--geckodriver.log----geckodriver.exe自己生成的日志文件
| |--fuzzer.py----一般性的模糊测试工具模板,一般稍加修改即可用来测试自己的api(如token插入位置等);修改api.ini直接python fuzzer.py运行即可
| |--rtsp_fuzzer.py----rtsp协议模糊测试工具,时序性协议示例;修改其中的config_dict,直接python rtsp_fuzzer.py运行即可
| |--snmp_fuzzer.py----snmp协议模糊测试工具,二进制协议示例,半成品;修改其中的config,直接python snmp_fuzzer.py运行即可
|
|--logs----模糊测试日志存放目录
| |--nvr_2019-06-03.log----nvr是自定义的日志前辍,2019-06-03是当前日期,.log是日志固定后辍
|
|--payloads----各类型模糊测试载荷文件存放目录
|--format_string.txt----格式化字符串测试载荷
|--overflow.txt----缓冲区溢出测试载荷,使用了python的"A"*count语法
|--random_num.txt----整数溢出测试载荷
|--special_char.txt----特殊字符测试载荷
|--unicode.txt----unicode编码测试载荷

 浙公网安备 33010602011771号
浙公网安备 33010602011771号