11【泛型、双列集合、异常、Debug】
11【泛型、双列集合、异常、Debug】
一、泛型
1.1 泛型概述
泛型定义:把类型明确的工作延迟到创建对象或调用方法的时候才去明确的特殊的类型;
例如,我们知道集合是可以存储任意元素的,那么这样一想,add方法上的参数应该是Object(所有类的父类),但是这样会引入一个新的问题,我们知道,子类都是比父类强大的,我们在使用的时候肯定是希望获取的是当初存进去的具体子类对象;因此我们每次都需要进行强制转换;
但add方法真的是Object吗?
查看ArrayList的add方法:
class ArrayList<E>{
public boolean add(E e){ }
public E get(int index){ }
....
}
Collection类:
public interface Collection<E> extends Iterable<E> {
}
上面的E就是泛型,集合的定义者也不知道我们需要存储什么元素到集合中,具体的类型只能延迟到创建对象时来决定了;
1.2 集合泛型的使用
1.2.1 未使用泛型
定义一个Province对象:
package com.dfbz.demo01_泛型的使用;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Province{
private String name; // 名称
private String shortName; // 简称
private String location; // 所属区域
public void intro(){
System.out.println("名称: " + name + ",简称: " + shortName + ",所属地区: " + location);
}
public Province(String name, String shortName, String location) {
this.name = name;
this.shortName = shortName;
this.location = location;
}
public Province() {
}
@Override
public String toString() {
return "Province{" +
"name='" + name + '\'' +
", shortName='" + shortName + '\'' +
", location='" + location + '\'' +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getShortName() {
return shortName;
}
public void setShortName(String shortName) {
this.shortName = shortName;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
}
测试类:
package com.dfbz.demo01_泛型的使用;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_泛型问题引出 {
public static void main(String[] args) {
Collection list = new ArrayList();
// 往集合存储对象
list.add(new Province("台湾", "台","华东"));
list.add(new Province("澳门", "澳","华南"));
list.add(new Province("香港", "港","华南"));
list.add(new Province("河北", "冀","华北"));
// 获取迭代器
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
// 集合中的元素都被提升为Object对象了
Object obj = iterator.next();
// 强制转换为子类
Province province = (Province) obj;
// 调用子类特有的功能
province.intro();
}
}
}
我们没有给泛型进行明确的定义,对象存储到集合中都被提升为Object类型了,取出来时需要强制转换为具体子类,非常麻烦;
不仅如此,这样的代码还存在这隐藏的风险,集合中可以存储任意的对象,如果往集合中存储其他对象呢?
定义个Book对象:
package com.dfbz.demo01_泛型的使用;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Book {
private String name;
private String author;
public void detail() {
System.out.println("书名: " + name + ",作者: " + author);
}
public Book() {
}
public Book(String name, String author) {
this.name = name;
this.author = author;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
'}';
}
}
测试类:
package com.dfbz.demo01_泛型的使用;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_泛型出现的问题 {
public static void main(String[] args) {
Collection list = new ArrayList();
// 添加几个省份
list.add(new Province("山西", "晋","华北"));
list.add(new Province("河南", "豫","华中"));
list.add(new Province("江西", "赣","华东"));
// 添加几本书
list.add(new Book("《史记》","司马迁"));
list.add(new Book("《三国志》","陈寿"));
// 获取迭代器
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
// 集合中的元素都被提升为Object对象了
Object obj = iterator.next();
// 强制转换为子类
Province province = (Province) obj; // 不可以将Book转换为Province(存在隐藏问题)
// 调用子类特有的功能
province.intro();
}
}
}
运行结果:

上述代码编译时是没有什么问题,但运行时出现了类型转换异常:ClassCastException,代码存在一定的安全隐患;
1.2.2 使用泛型
- 查看List源码:
public interface List<E> extends Collection<E> {
boolean add(E e);
E get(int index);
E set(int index, E element);
....
}
集合的定义者发现,无法在定义集合类时就确定该集合存储的具体类型,因此使用泛型进行占位,使用者创建集合时明确该泛型的类型;
- 指定泛型后:
public interface List<Province> extends Collection<Province>{
boolean add(Province province);
Province get(int index);
Province set(int index, Province element);
....
}
Tips:在创建对象时指定泛型的类型,泛型一旦指定了具体的类型,原来泛型的占位符(E),都将变为此类型;
如何指定泛型类类型?
格式如下:
List<泛型的具体类型> list=new ArrayList();
测试类:
package com.dfbz.demo01_泛型的使用;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_使用泛型来存储元素 {
public static void main(String[] args) {
// 创建集合,并确定好泛型(存储的类型)
List<Province> list = new ArrayList();
// 往集合存储对象
list.add(new Province("甘肃", "甘|陇","西北"));
list.add(new Province("陕西", "陕|秦","西北"));
list.add(new Province("贵州", "贵|黔","西南"));
list.add(new Province("云南", "云|滇","西南"));
list.add(new Province("四川", "川|蜀","西南"));
// 获取City类型的迭代器
Iterator<Province> iterator = list.iterator();
while (iterator.hasNext()){
// 直接获取province类型
Province province = iterator.next();
province.intro();
}
}
}
1.3 泛型类
1.3.1 泛型类的使用
很明显,Collection、List、Set以及其下的子类都是泛型类,我们根据使用情况也可以定义泛型类;让泛型类的类型延迟到创建对象的时候指定;
- 使用格式:
修饰符 class 类名<代表泛型的变量> {}
例如,API中的List接口:
public interface List<E> extends Collection<E>
boolean add(E e);
....
}
在创建对象的时候确定泛型
例如,List<String> list = new ArrayList<String>();
此时,变量E的值就是String类型,那么我们的类型就可以理解为:
public interface List<String> extends Collection<String> {
boolean add(String e);
...
}
再例如,ArrayList<Integer> list = new ArrayList<Integer>();
此时,变量E的值就是Integer类型,那么我们的类型就可以理解为:
public interface List<Integer> extends Collection<Integer> {
boolean add(Integer e);
...
}
举例自定义泛型类:
package com.dfbz.demo02_泛型类的使用;
/**
* @author lscl
* @version 1.0
* @intro:
*/
class GetClass<E> {
private E e;
public E getE() {
return e;
}
public void setE(E e) {
this.e = e;
}
}
Tips:E为泛型的占位符,可以为任意名称
使用:
package com.dfbz.demo02_泛型类的使用;
import com.dfbz.demo01_泛型的使用.Book;
import com.dfbz.demo01_泛型的使用.Province;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01 {
public static void main(String[] args) {
// 在创建GetClass对象的时候就明确泛型类型
GetClass<Province> getClass=new GetClass<>();
getClass.setE(new Province("河北","冀","华北"));
Province p = getClass.getE();
p.intro();
System.out.println("-----------");
GetClass<Book> bookGetClass=new GetClass<>();
bookGetClass.setE(new Book("《红楼梦》","曹雪芹"));
Book book = bookGetClass.getE();
book.detail();
}
}
1.2.2 泛型类的继承
定义一个父类,带有泛型:
public class 类名<泛型类型> { }
例如,
package com.dfbz.demo03_泛型类的继承;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Fu<E> {
public void show(E e) {
System.out.println(e.toString());
}
}
使用格式:
- 1)定义类时确定泛型的类型
例如
package com.dfbz.demo03_泛型类的继承;
import com.dfbz.demo01_泛型的使用.Province;
/**
* @author lscl
* @version 1.0
* @intro: 在定义子类时就确定好泛型的类型,此时子类并不是泛型类
*/
public class Zi1 extends Fu<Province> {
@Override
public void show(Province province) {
System.out.println("zi1: " + province);
}
}
此时,泛型E的值就是Province类型。
- 2)始终不确定泛型的类型,直到创建对象时,确定泛型的类型
例如
package com.dfbz.demo03_泛型类的继承;
/**
* @author lscl
* @version 1.0
* @intro: 子类也变为泛型类,泛型类型具体到创建对象的时候再确定
*/
public class Zi2<P> extends Fu<P> {
@Override
public void show(P p) {
System.out.println("zi2: " + p);
}
}
确定泛型:
package com.dfbz.demo03_泛型类的继承;
import com.dfbz.demo01_泛型的使用.Book;
import com.dfbz.demo01_泛型的使用.Province;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01 {
public static void main(String[] args) {
// 注意: Zi1类以及不是一个泛型类了,不能够指定泛型
// Zi1<Book> zi1=new Zi1(); // 报错
// 创建子类时确定泛型类型
Zi2<Province> zi_a = new Zi2<>();
zi_a.show(new Province("青海", "青", "西北"));
Zi2<Book> zi_b = new Zi2<>();
zi_b.show(new Book("《说岳全传》", "钱彩"));
}
}
1.4 泛型方法
泛型类是在创建类时定义泛型类型,在创建对象时确定泛型类型;泛型方法则是在创建方法是定义泛型类型,在调用方法时确定泛型类型;
- 定义格式:
修饰符 <代表泛型的变量> 返回值类型 方法名(参数){}
例如:
package com.dfbz.demo04_泛型方法;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class GetClassMethod {
// 定义泛型方法
public <E> E getClassMethod(E e) {
return e;
}
}
使用格式:调用方法时,确定泛型的类型
package com.dfbz.demo04_泛型方法;
import com.dfbz.demo01_泛型的使用.Book;
import com.dfbz.demo01_泛型的使用.Province;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01 {
public static void main(String[] args) {
GetClassMethod getClassMethod = new GetClassMethod();
// 调用方式时明确泛型的类型
// Province getClassMethod(Province province)
Province province = getClassMethod.getClassMethod(new Province("西藏", "藏", "西北"));
province.intro();
// Book getClassMethod(Book book)
Book book = getClassMethod.getClassMethod(new Book("《天龙八部》", "金庸"));
book.detail();
}
}
1.5 泛型通配符
1.5.1 通配符的使用
1) 参数列表带有泛型
泛型在程序运行中全部会被擦除,我们把这种现象称为泛型擦除;但编译时期在使用泛型类进行方法传参时,不仅要匹配参数本身的类型,还要匹配泛型的类型;
Number是所有数值类的父类:
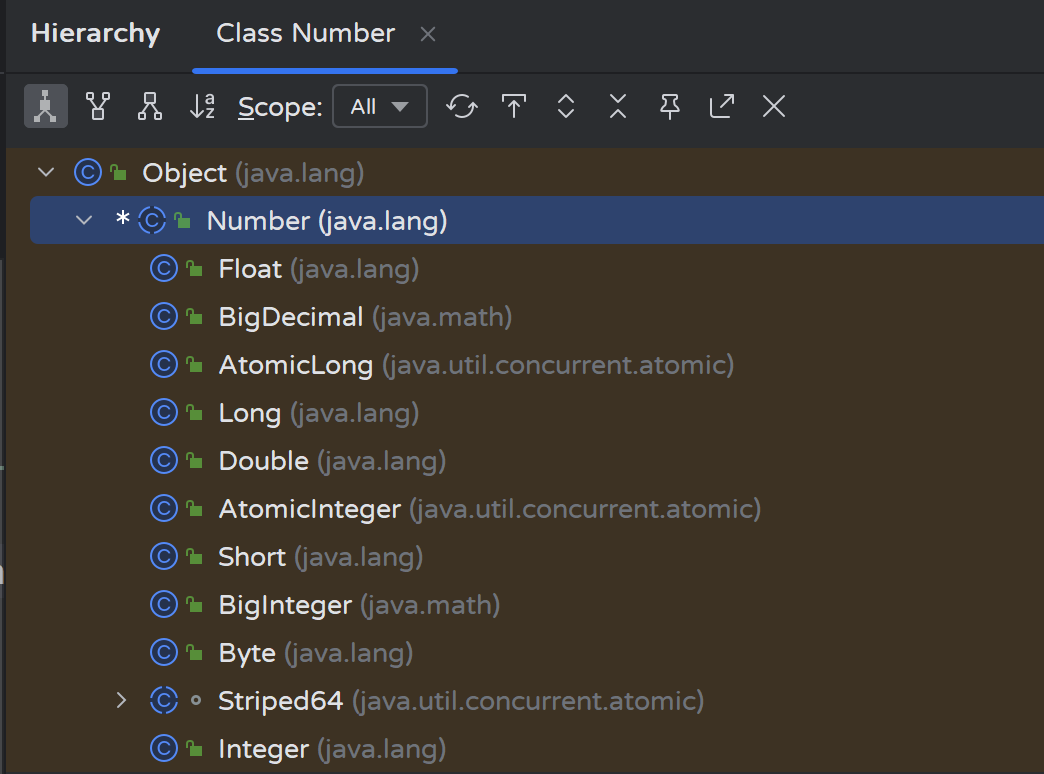
- 定义一个泛型类:
package com.dfbz.demo05_泛型通配符;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class TestClass<E> {
private E e;
public E getE() {
return e;
}
public void setE(E e) {
this.e = e;
}
}
- 测试带有泛型的方法参数列表:
package com.dfbz.demo05_泛型通配符;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_方法传参带有泛型时的问题 {
public static void main(String[] args) {
// 调用方法时不仅要匹配方法参数的本身,还要匹配参数上的泛型类型
TestClass<Number> t1 = new TestClass<>();
test1(t1);
TestClass<Integer> t2 = new TestClass<>();
// 符合方法的参数类型(TestClass),但不符合泛型类型(Number),编译报错
// test1(t2);
}
public static void test1(TestClass<Number> testClass) {
// 可以获取具体的泛型对象
Number number = testClass.getE();
System.out.println("test1...");
}
/*
和上面的方法冲突了,因为泛型在运行期间会被擦除
相当于: public static void test1(TestClass testClass)
*/
/*
public static void test1(TestClass<Integer> testClass) {
System.out.println("test1...");
}
*/
}
2) 泛型通配符
泛型的通配符:不知道使用什么类型来接收的时候,此时可以使用?,?表示未知通配符。
- 示例:
package com.dfbz.demo05_泛型通配符;
import com.dfbz.demo01_泛型的使用.Book;
import com.dfbz.demo01_泛型的使用.Province;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_泛型通配符的使用 {
public static void main(String[] args) {
// 不管泛型是什么类型,都可以调用test1方法
TestClass<String> t1 = new TestClass<>();
test1(t1);
TestClass<Integer> t2 = new TestClass<>();
test1(t2);
TestClass<Number> t3 = new TestClass<>();
test1(t3);
TestClass<Province> t4 = new TestClass<>();
test1(t4);
TestClass<Book> t5 = new TestClass<>();
test1(t5);
}
// ?: 代表可以接收任意泛型
public static void test1(TestClass<?> testClass) {
// 被?接收的泛型都将提升为Object
Object obj = testClass.getE();
System.out.println("test1...");
}
}
Tips:需要注意的是,被<?>接收过的类型都将提升为Object类型;
1.5.2 泛型上下边界
利用泛型通配符?可以接收任意泛型,但是随之而然带来一个问题,就是所有类型都提升为Object;范围太广了,使用起来非常不方便,因此为了让泛型也可以利用多态的特点,泛型的上下边界的概念由此引出;
利用泛型的通配符可以指定泛型的边界;
泛型的上限:
- 格式: 类型名称
<? extends 类>对象名称 - 含义: 只能接收该类型及其子类
- 功能:在使用时,可以使用上边界类来接收泛型类型。因为能够传递进来的都是上边界的子类;因此可以使用上边界类来接收泛型类型;
泛型的下限:
- 格式: 类型名称
<? super 类>对象名称 - 含义: 只能接收该类型及其父类型
- 功能:在使用时,只能使用Object类型来接收泛型类型。因为传递进来的必定是下边界的父类,而下边界的父类可以有N多个,因此只能使用Object来接收泛型类型;
可以看到基本数据类型的包装类都是继承与Number类;
- 测试泛型上下边界:
package com.dfbz.demo06_泛型的上下边界;
import java.util.ArrayList;
import java.util.List;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_泛型的上下边界 {
public static void main(String[] args) {
List<A> list1 = new ArrayList();
List<B> list2 = new ArrayList();
List<C> list3 = new ArrayList();
List<Object> list4 = new ArrayList();
// method1(list1); // 不能
// method1(list2); // 能
// method1(list3); // 能
// method1(list4); // 不能
// method2(list1); // 能
// method2(list2); // 能
// method2(list3); // 不能
// method2(list4); // 能
}
public static void method1(List<? extends B> list) {
// 上边界的好处: 可以使用上边界的对象
for (B b : list) {
System.out.println(b);
}
}
public static void method2(List<? super B> list) {
// 下边界则必须使用Object来接收
for (Object obj : list) {
System.out.println(obj);
}
}
}
class A {
}
class B extends A {
}
class C extends B {
}
1.6 泛型的擦除
Java的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的,使用泛型的时候加上类型参数,在编译器编译的时候会去掉,这个过程称为类型擦除。
1.6.1 限制擦除
泛型在擦除过程中有限制擦除和无限制擦除;
- 有限制擦除:

- 无限制擦除:将泛型类型提升为Object类型

1.6.2 泛型的桥接方法
在接口使用泛型时,在运行期间接口中的泛型也一样会被擦除;

那如果编写了实现类来实现这个泛型接口,实现类中的泛型在运行期间也会被擦除,这样一来就会出现接口的方法并没有在实现类中得到实现:
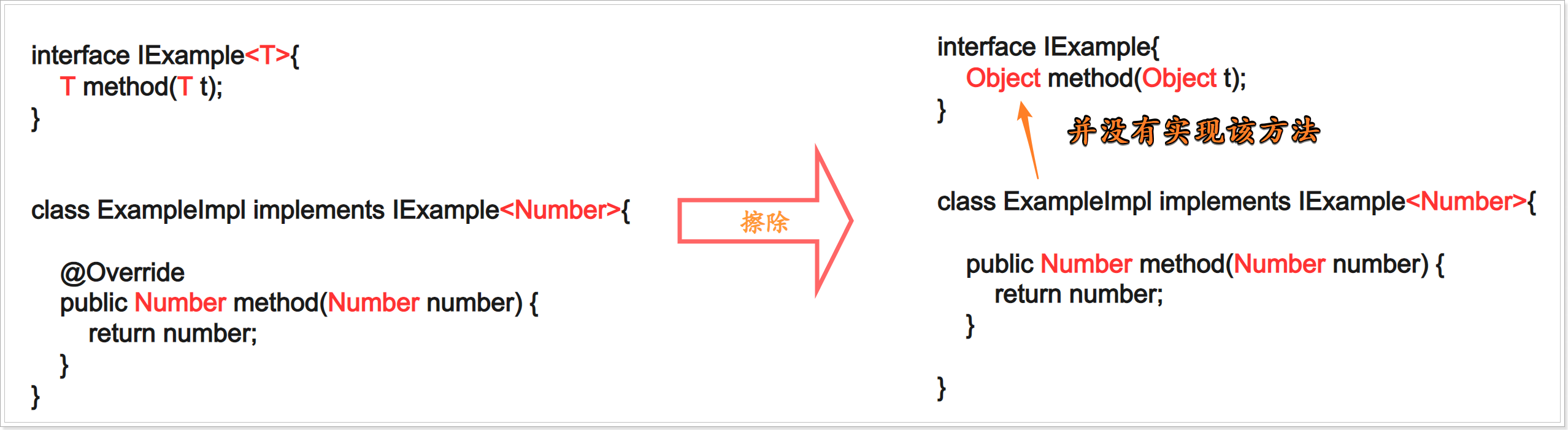
好在JVM进行了特殊处理,如果我们编写的类实现了一个带有泛型的接口时,在运行期期间JVM会在实现类中帮我们自动的生产一个方法来帮助我们实现泛型接口中被擦除过后的那个方法,这个方法被称为桥接方法;
- 如图所示:
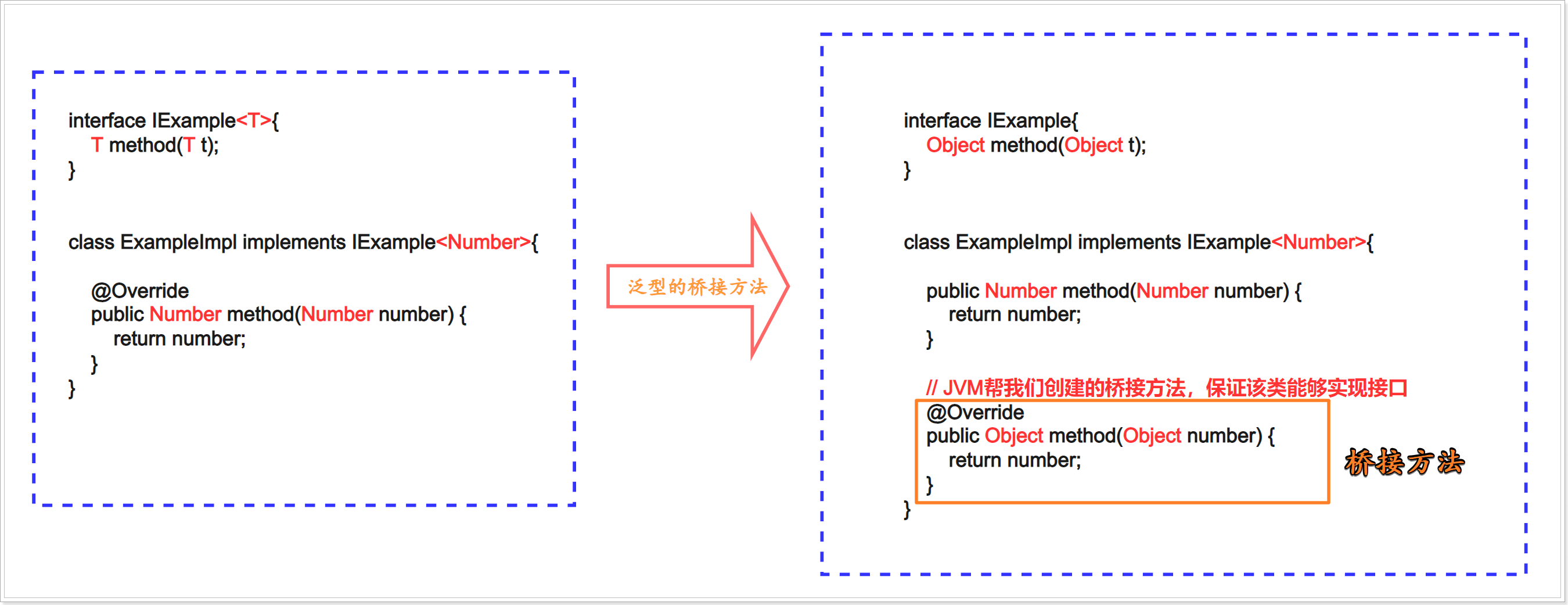
- 示例代码:
package com.dfbz.demo07_泛型的擦除;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_测试泛型的桥接方法 {
public static void main(String[] args) {
ExampleImpl example = new ExampleImpl();
Number res = example.method(10);
System.out.println(res);
}
}
interface IExample<T> {
T method(T t);
}
class ExampleImpl implements IExample<Number> {
@Override
public Number method(Number number) {
return number;
}
// JVM已经帮我们提供了这个桥接方法
/* public Object method(Object number) {
return number;
}*/
}
二、Map双列集合
2.1 Map集合概述
Map 用于保存具有映射关系的数据,如一个学生的ID对应一个学生,一个商品的ID对应一个商品,一个部门ID对应多个员工;这种具有对应关系的数据成为映射;
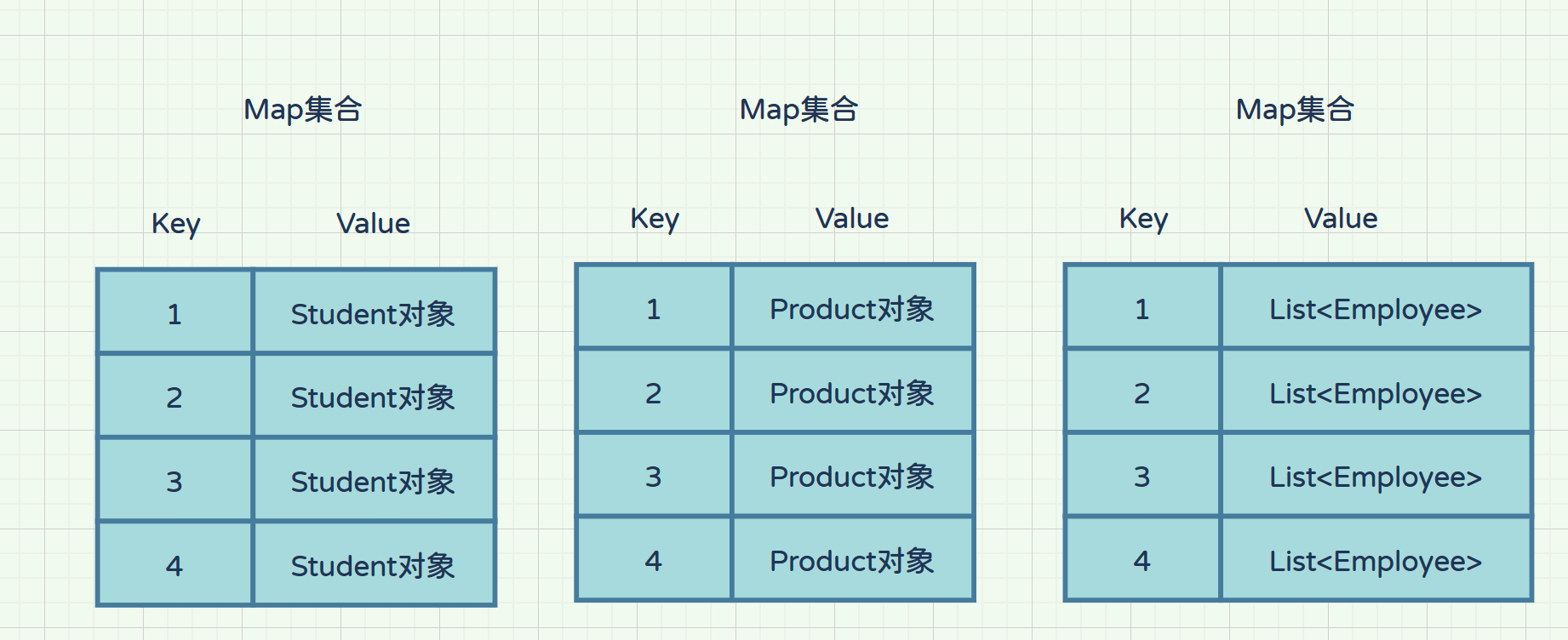
因此 Map 集合里保存着两组值,一组值用于保存 Map 里的 Key,另外一组用于保存 Map 里的 Value,Map 中的 key 和 value 都可以是任何引用类型的数据;
- Map接口的继承体系:
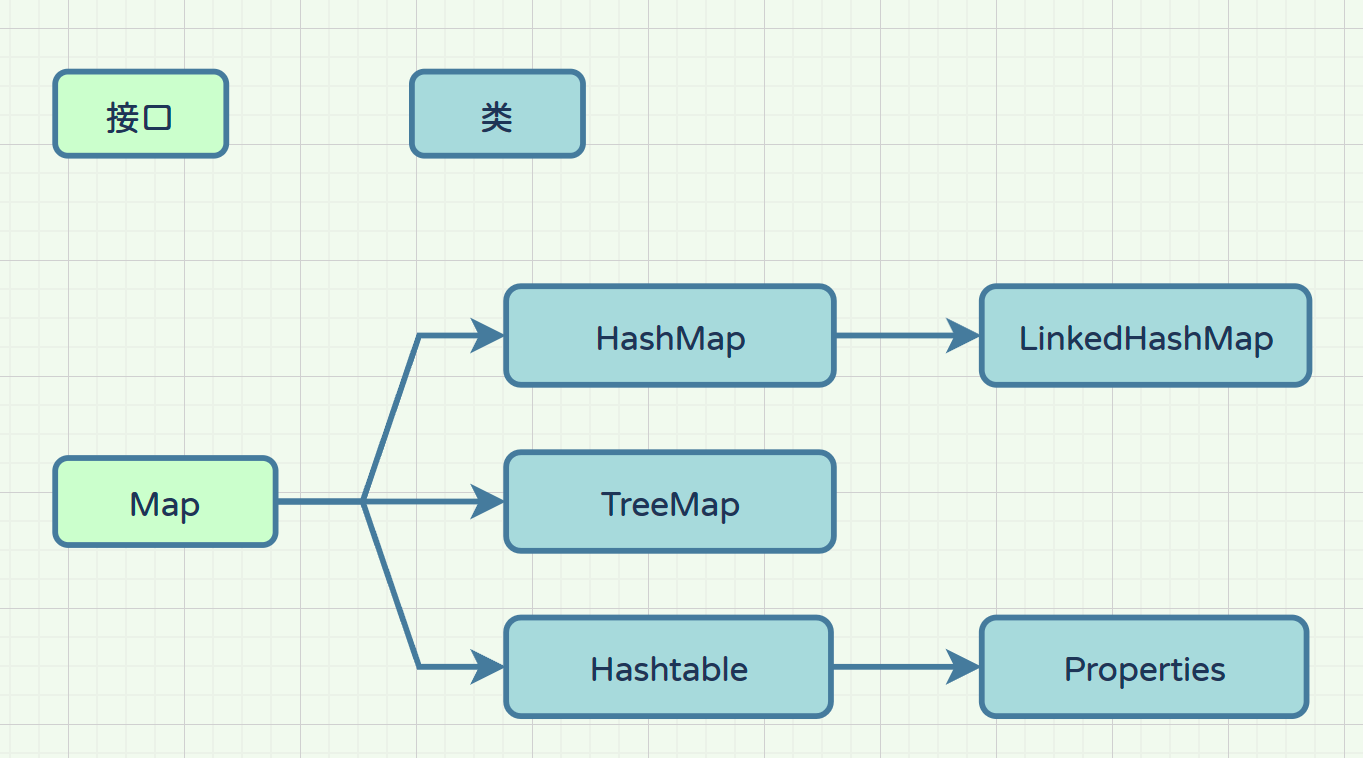
Tips:Collection接口是单列集合的顶层接口,Map则是双列集合的顶层接口;
2.2 Map接口的共有方法
Map是所有双列集合的顶层父类,因此Map中具备的是所有双列集合的共性方法;常用的方法如下:
public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。public V get(Object key)根据指定的键,在Map集合中获取对应的值。boolean containsKey(Object key)判断集合中是否包含指定的键。public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中。public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。public Collection<V> values():获取该map集合的所有value
2.2.1 数据的存取
示例代码:
package com.dfbz.demo01;
import java.util.Collection;
import java.util.HashMap;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_Map集合的常用方法 {
public static void main(String[] args){
//创建 map对象
HashMap<String, String> map = new HashMap();
//添加元素到集合
map.put("江西", "南昌");
map.put("湖南", "长沙");
map.put("湖北", "武汉");
// 存取是无序的
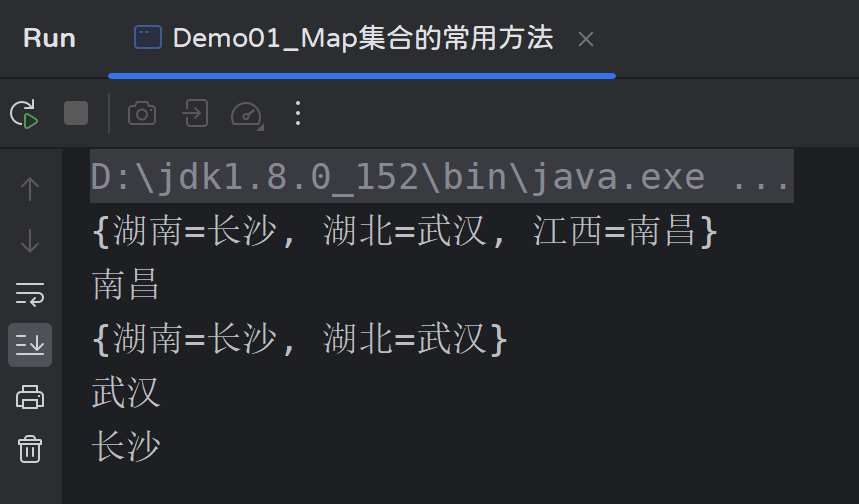
System.out.println(map); // {湖南=长沙, 湖北=武汉, 江西=南昌}
// String remove(String key): 根据key来删除记录,并将key对应的value返回
System.out.println(map.remove("江西")); // 南昌
System.out.println(map); // {湖南=长沙, 湖北=武汉}
// 查看 湖北的省会 是哪座城市
System.out.println(map.get("湖北")); // 武汉
System.out.println(map.get("湖南")); // 长沙
}
public static void test(String[] args) {
// 创建Map对象,指定key和value的类型
HashMap<String, String> map = new HashMap();
//添加元素到集合
map.put("江西", "南昌");
map.put("湖南", "长沙");
map.put("湖北", "武汉");
// 获取该map集合的所有value
Collection<String> values = map.values();
System.out.println(values); // [长沙, 武汉, 南昌]
}
}
运行结果:
2.2.2 数据的遍历
方法:
public V get(Object key)根据指定的键,在Map集合中获取对应的值。public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中。
步骤:
- 1)根据
keySet()方法获取所有key的集合 - 2)通过foreach方法遍历key集合,拿到每一个key
- 3)通过
get()方法,传递key获取key对应的value;
示例代码:
package com.dfbz.demo01;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02_Map集合的遍历_key {
public static void main(String[] args) {
Map<String, String> cities = new HashMap<>();
//添加元素到集合
cities.put("广西", "南宁");
cities.put("云南", "昆明");
cities.put("贵州", "贵阳");
// 1.获取key的集合
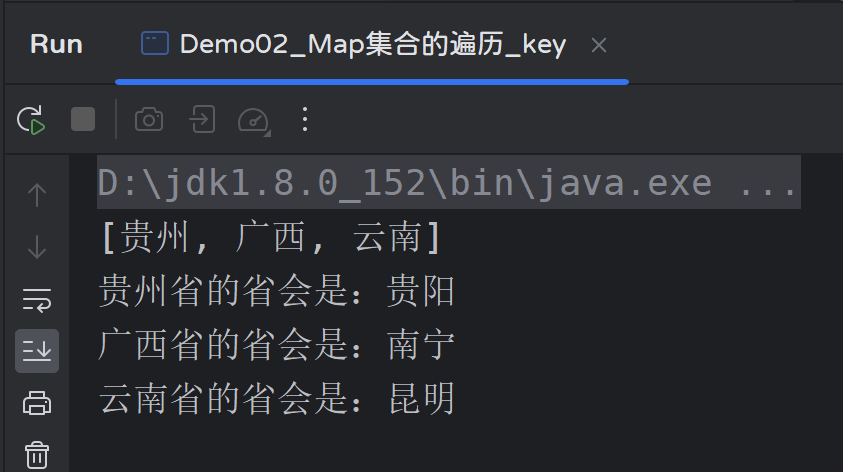
Set<String> provinces = cities.keySet(); // [贵州, 广西, 云南]
System.out.println(provinces);
// 2.遍历key的集合
for (String province : provinces) {
// 3.根据key(省份)拿到value(省会城市)
String city = cities.get(province);
System.out.println(province + "省的省会是:" + city);
}
}
}
运行结果:
2.2.3 Entry对象
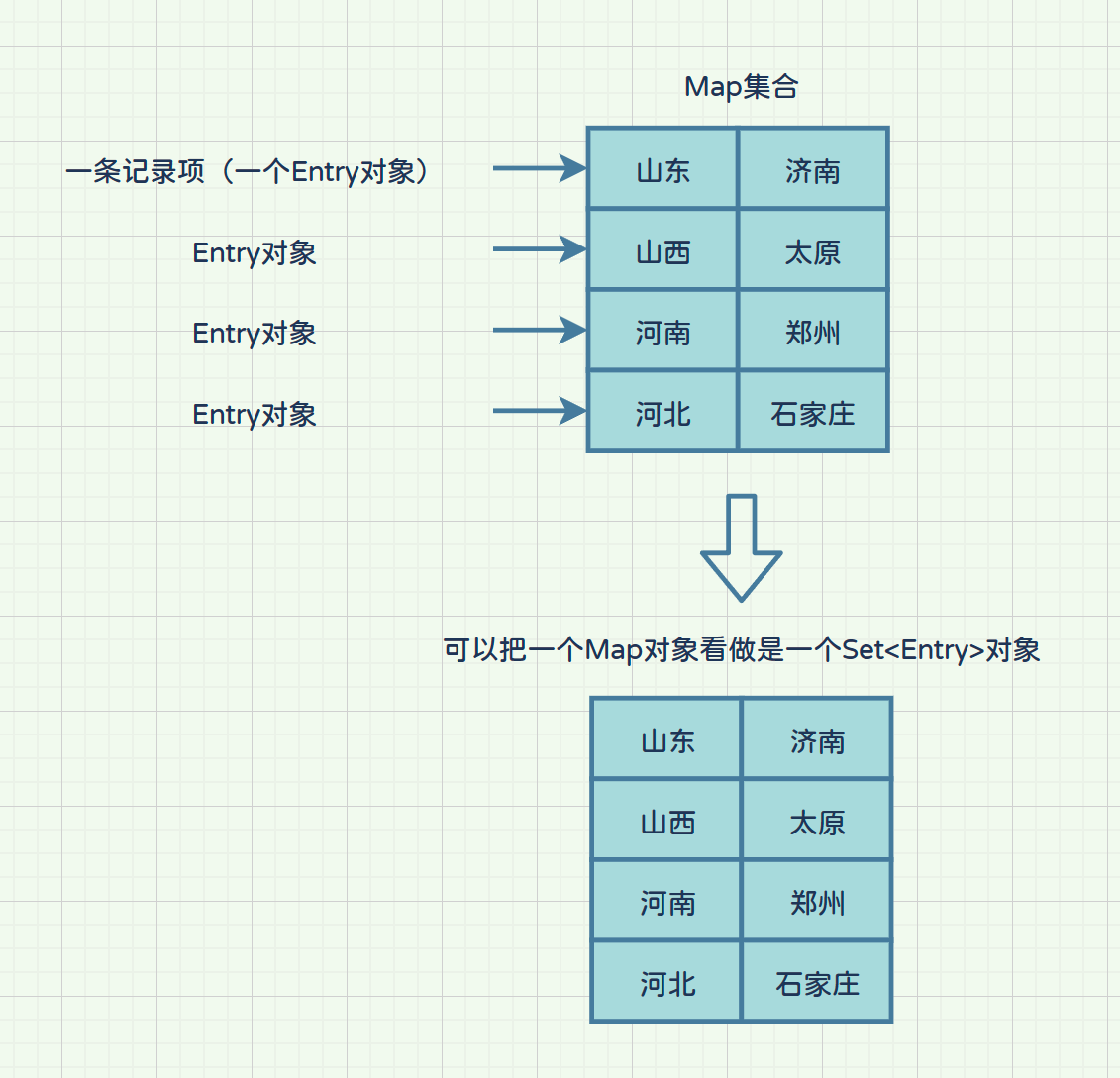
Map集合中几条记录存储的是两个对象,一个是key,一个是value,这两个对象加起来是map集合中的一条记录,也叫一个记录项;这个记录项在Java中被Entry对象所描述;一个Entry对象中包含有两个值,一个是key,另一个则是key对应的value,因此一个Map对象我们可以看做是多个Entry对象的集合,即一个Set<Entry>对象;
Entry是一个接口,是Map接口中的一个内部接口,源码如下:
interface Entry<K,V> {
K getKey();
V getValue();
V setValue(V value);
....
}
HashMap中则提供了Node类对Entry提供了实现,可以看到一个Entry对象(Node对象)中包含有key、value等值:
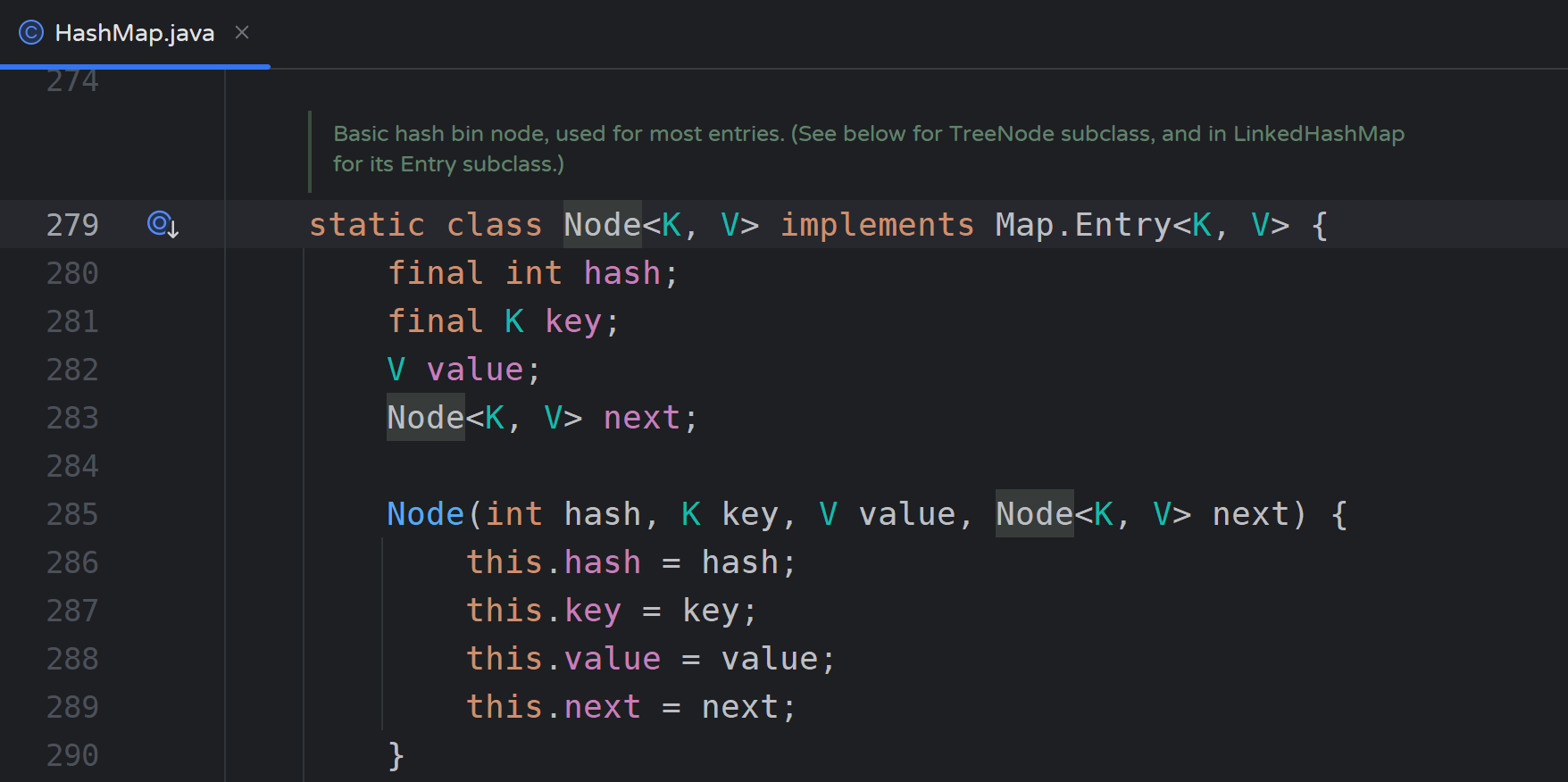
Map接口中提供有方法获取该Map集合的Entry集合对象:
public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。
使用Entry对象来遍历Map集合:
package com.dfbz.demo01;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
/**
* @author lscl
* @version 1.0
* @intro:
*/
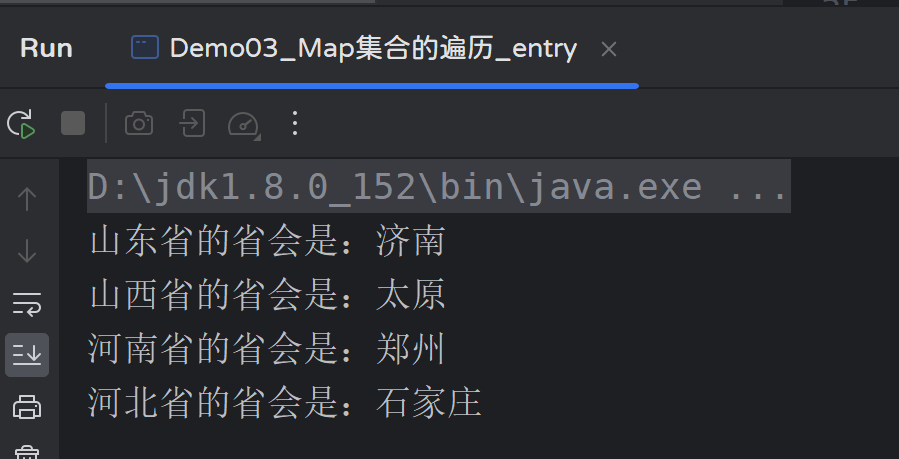
public class Demo03_Map集合的遍历_entry {
public static void main(String[] args) {
Map<String, String> cities = new HashMap<>();
//添加元素到集合
cities.put("山东", "济南");
cities.put("山西", "太原");
cities.put("河南", "郑州");
cities.put("河北", "石家庄");
// 1.获取该Map的Entry集合
Set<Map.Entry<String, String>> entrySet = cities.entrySet();
// 2.遍历该Entry集合,获取每一个entry,也就是Map中的每一条记录
for (Map.Entry<String, String> entry : entrySet) {
// 获取当前entry对象的key(省份)
String province = entry.getKey();
// 获取当前entry对象的value(城市)
String city = entry.getValue();
System.out.println(province + "省的省会是:" + city);
}
}
}
运行结果:
2.3 HashMap
2.3.1 HashMap简介
HashMap是Map集合中比较常用的实现类,其特点依旧是我们之前学习的HashSet特点;即存储数据采用的哈希表结构(JDK8改为hash表+红黑树),元素的存取顺序不一致。由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
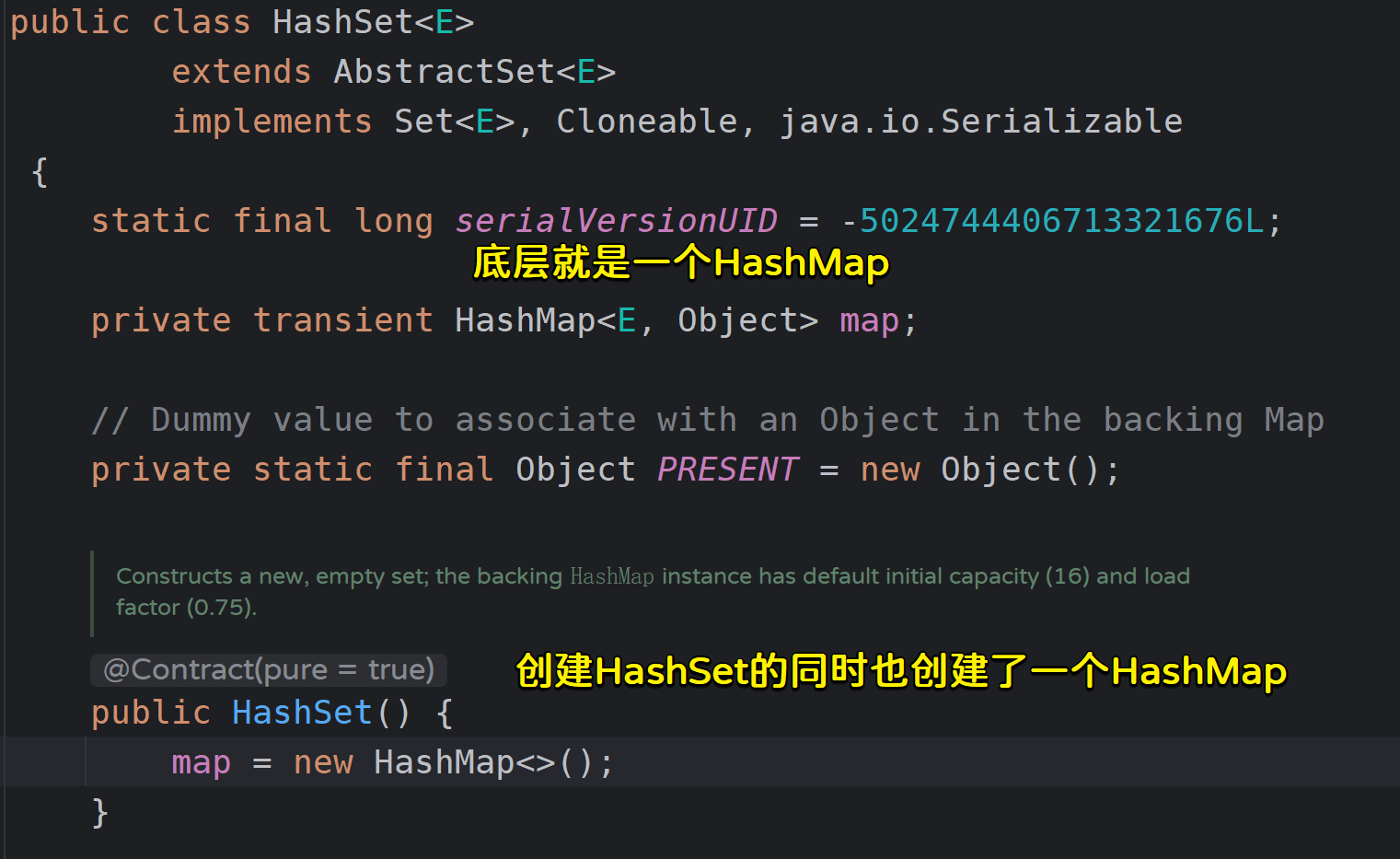
我们之前学习的HashSet底层就是一个HashMap,当我们在讨论HashSet的底层原理时,其实讨论的是HashMap的key的底层原理;
- HashSet底层就是一个HashMap:
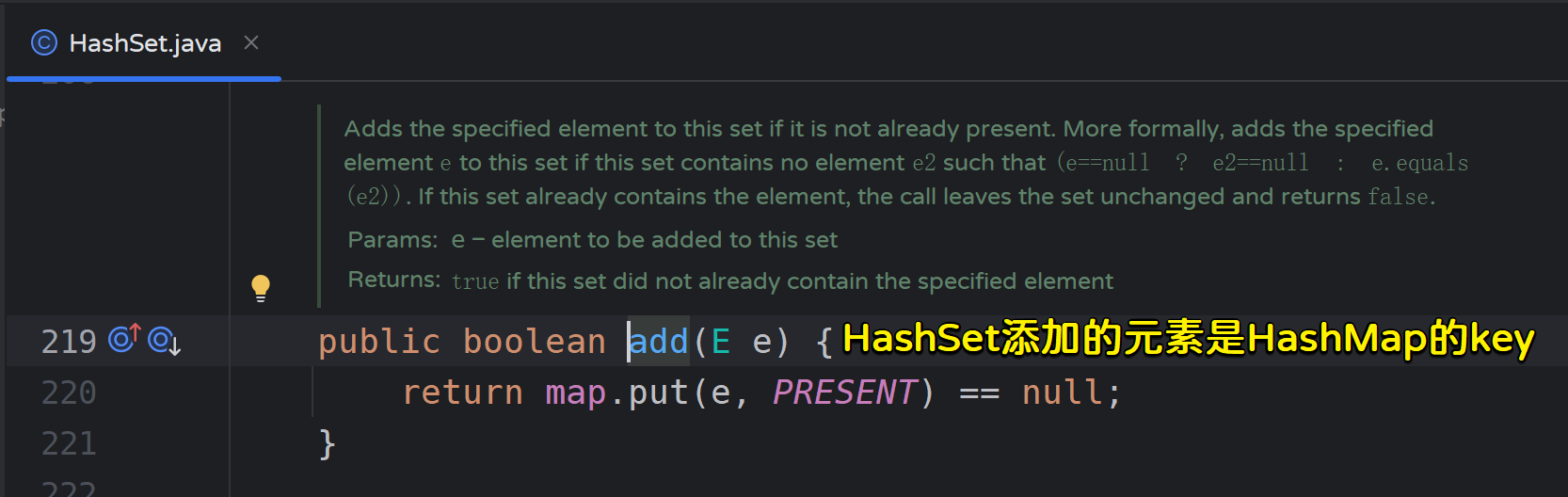
查看HashSet的add方法源码:
HashSet的存储的元素都是HashMap的Key,此HashMap的value总是一个固定的Object;
所以,HashSet的去重原理实质上指的就是HashMap的Key的去重原理;
2.3.2 HashMap的去重
我们知道HashSet底层就是依靠HashMap的key去重原理来是实现的,因此Map接口的HashMap、LinkedHashMap等接口的去重都是和HashSet、LinkedHashSet一致;
定义一个City对象:
class City {
private String name; // 城市名称
private String province; // 所属省份
@Override
public String toString() {
return "City{" + "name='" + name + '\'' + ", province='" + province + '\'' + '}';
}
public City(String name, String province) {
this.name = name;
this.province = province;
}
}
注意:上面没有重写equals和hashCode方法;
存储两个属性一样的City对象:
package com.dfbz.demo01;
import java.util.HashMap;
import java.util.Objects;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo04_HashMap {
public static void main(String[] args) {
HashMap<City,String> map = new HashMap<>();
map.put(new City("呼和浩特","内蒙古"),"1");
map.put(new City("呼和浩特","内蒙古"),"2");
System.out.println(map.size()); // 2
}
}
回顾学习HashSet时的去重原理:
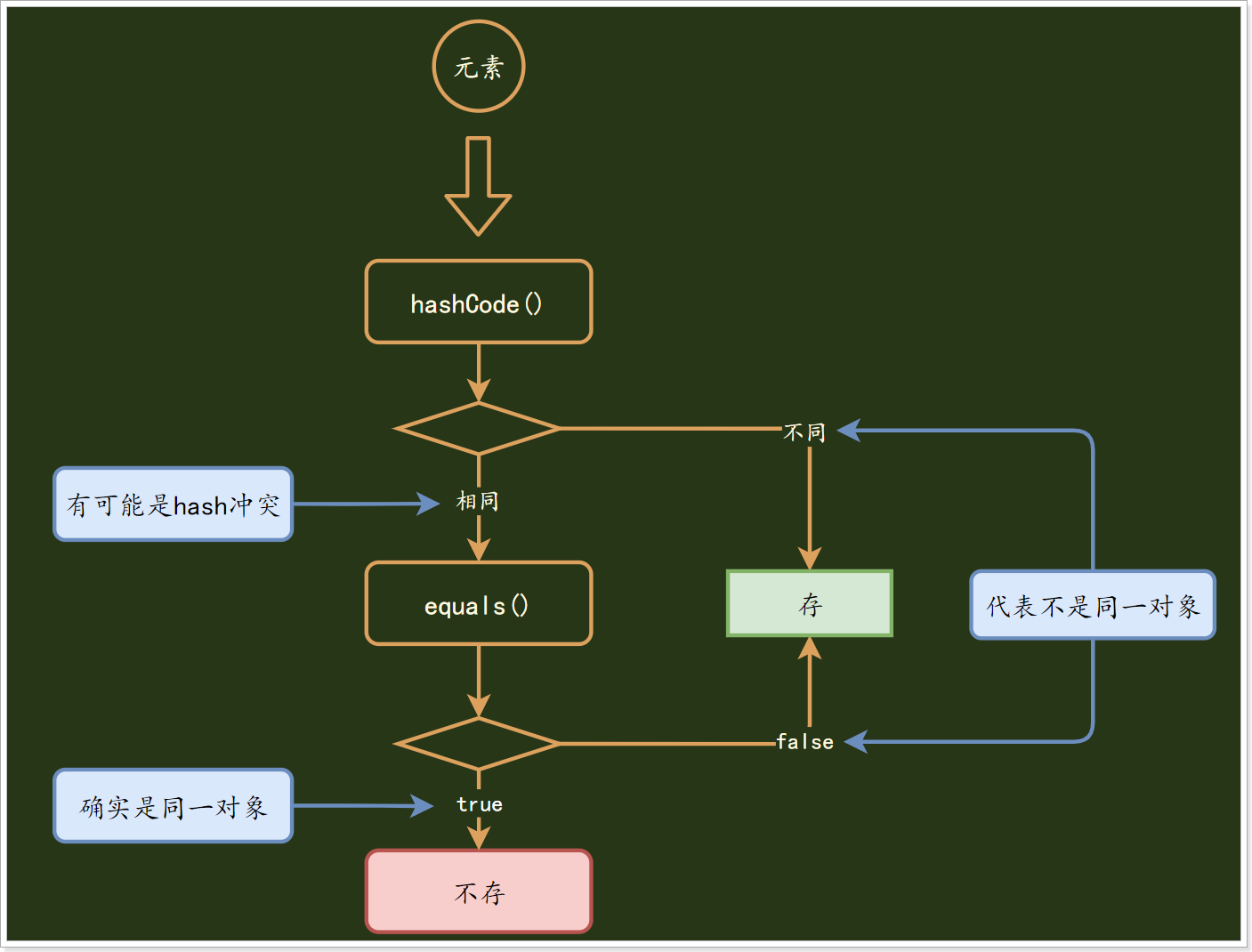
存储的两个条件:
- 1)hashCode不同时存储
- 2)当hashCode冲突时,equals为false时存储
没有重写hashCode时两个对象的hashCode一般情况下是不一致的,如果hashCode一致了(hash冲突),equals方法也不可能为true;
重写City的hashCode和equals方法:
按住alt+insert
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
City city = (City) o;
return Objects.equals(name, city.name) &&
Objects.equals(shortName, city.shortName) &&
Objects.equals(location, city.location);
}
@Override
public int hashCode() {
return Objects.hash(name, shortName, location);
}
HashMap基本上没有对Map集合中的方法进行扩展;并且大部分方法在之前学习List接口的时候我们都使用过了,这里就不再演示了;
2.4 LinkedHashMap
2.4.1 LinkedHashMap 特点
我们之前在学习LinkedHashSet时说过,LinkedHashSet是继承与HashSet的,在HashSet底层的基础上增加了一个循环链表,因此LinkedHashSet除了具备HashSet的特点外(唯一),存储的元素还是有序的;
LinkedHashMap继承与HashMap,并且LinkedHashSet底层就是借助于LinkedHashMap来实现的;
LinkedHashSet源码如下:
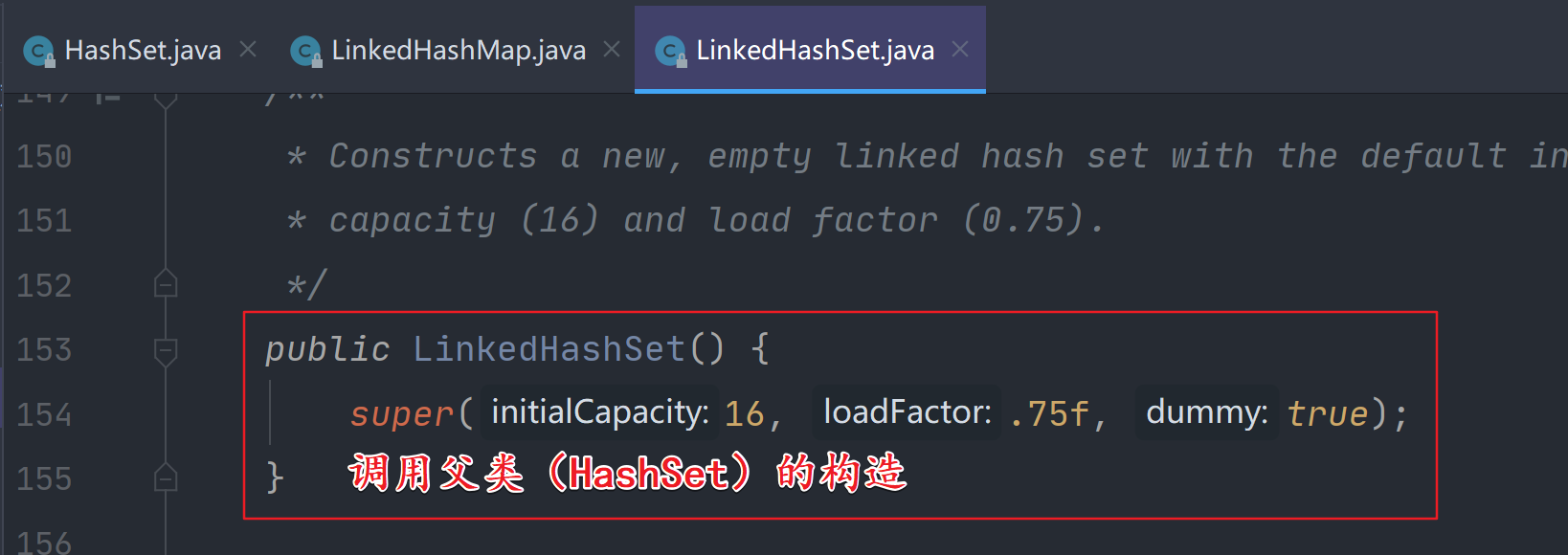
查看HashSet对应的构造:
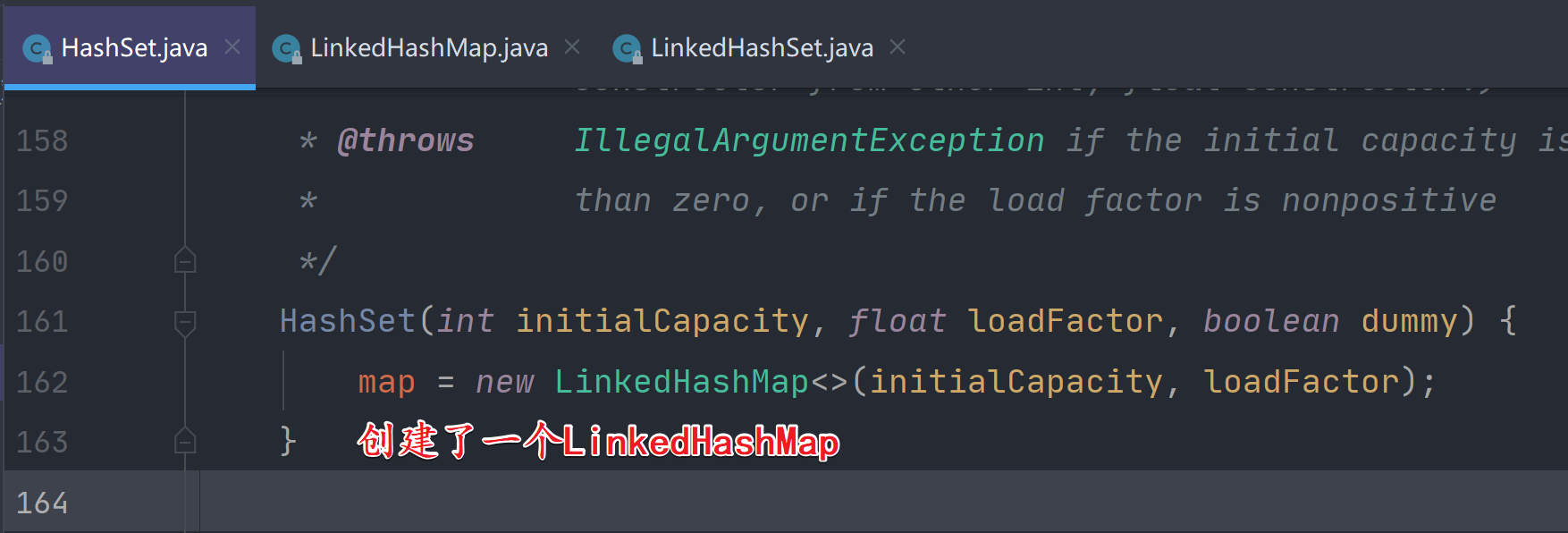
查看LinkedHashSet的add方法源码:
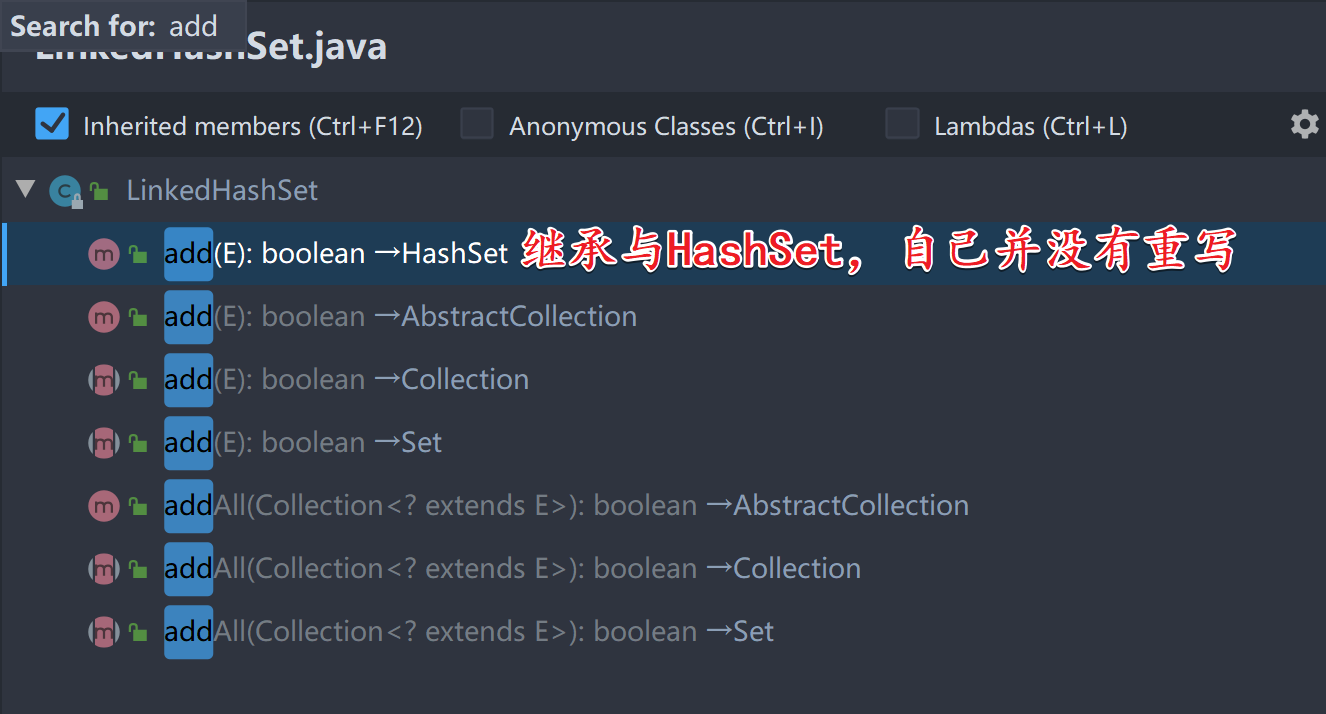
HashSet的add方法源码我们之前看过了,实质上是添加到内置的HashMap中去了;
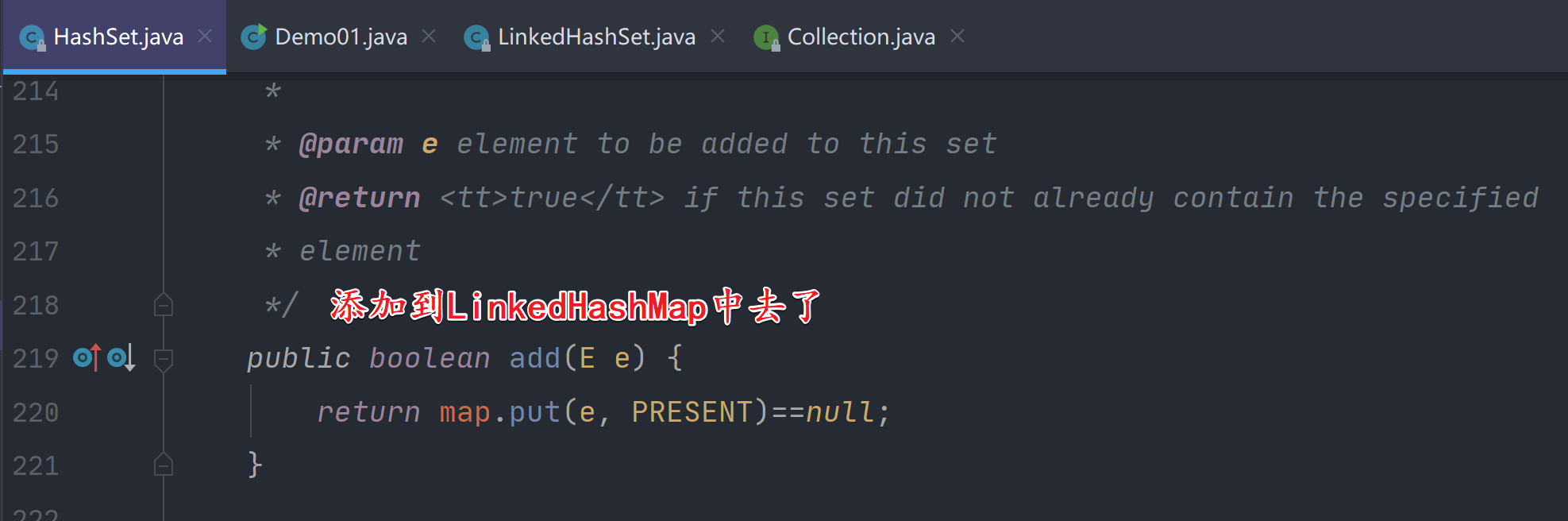
注意:此时的map是LinkedHashMap;
2.4.2 LinkedHashMap 使用
示例代码:
package com.dfbz.demo01;
import java.util.LinkedHashMap;
import java.util.LinkedHashSet;
/**
* @author lscl
* @version 1.0
* @intro:
*/
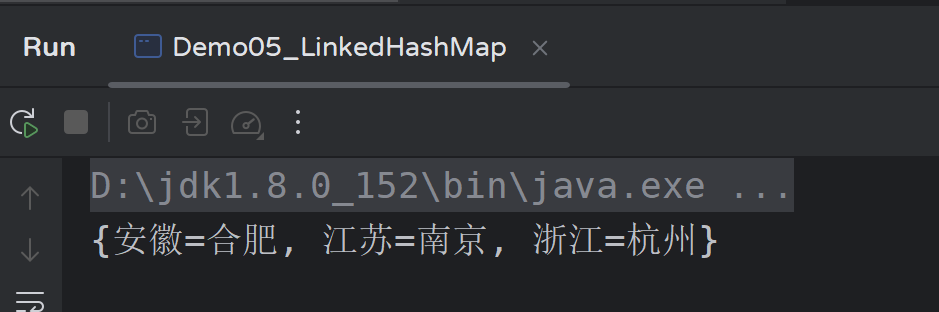
public class Demo05_LinkedHashMap {
public static void main(String[] args) {
LinkedHashMap<String,String> map=new LinkedHashMap<>();
map.put("安徽","合肥");
map.put("江苏","南京");
map.put("浙江","杭州");
System.out.println(map); // {安徽=合肥, 江苏=南京, 浙江=杭州}
}
}
运行结果:
2.5 TreeMap
2.5.1 TreeMap 特点
TreeMap也是TreeSet的底层实现,创建TreeSet的同时也创建了一个TreeMap,在往TreeSet集合中做添加操作是,实质也是往TreeMap中添加操作,TreeSet要添加元素成为了TreeMap的key;
我们来回顾一下TreeSet的特点(也是TreeMap的key的特点):
- 必须实现Compareable接口;
- 存储的数据是无序的,但提供排序功能(Comparable接口);
- 存储的元素不再是唯一,具体结果根据compareTo方法来决定;
2.5.2 TreeMap 使用
定义一个Book类,并重写Compareable方法,按住价格升序排序:
// 必须实现Comparable接口
class Goods implements Comparable<Goods> {
private String name;
private Double price;
/**
* 升序: this - 传递进来的
* 降序: 传递进来的 - this
* @return
*/
@Override
public int compareTo(Goods goods) {
// return (int) (this.getPrice() - goods.getPrice());
return (int) (goods.getPrice()- this.getPrice() );
}
@Override
public String toString() {
return "Goods{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
// 省略get/set...
}
测试代码:
package com.dfbz.demo01;
import java.util.TreeMap;
/**
* @author lscl
* @version 1.0
* @intro:
*/
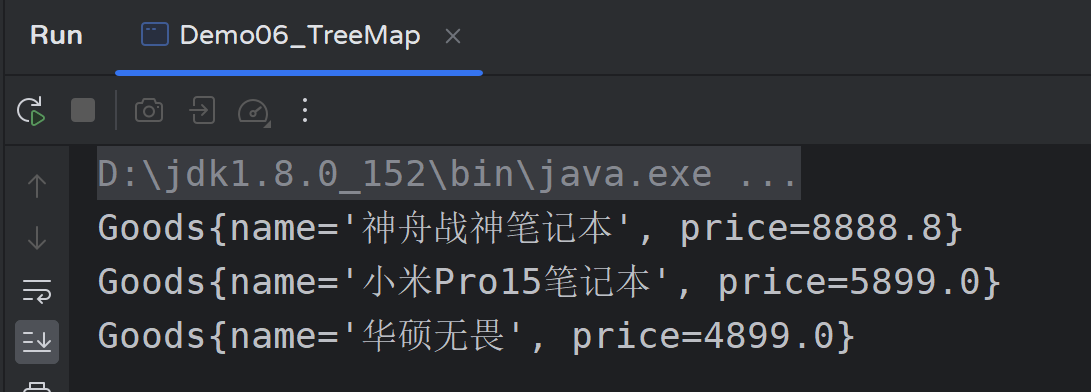
public class Demo06_TreeMap {
public static void main(String[] args) {
TreeMap<Goods, String> treeMap = new TreeMap<>();
treeMap.put(new Goods("神舟战神笔记本", 8888.8D), "神舟");
treeMap.put(new Goods("小米Pro15笔记本", 5899.0D), "小米");
treeMap.put(new Goods("华硕无畏", 4899.0D), "华硕");
// 遍历map集合
for (Goods goods : treeMap.keySet()) {
System.out.println(goods);
}
}
}
输出结果:
2.5 Hashtable
Hashtable是原始的java.util的一部分,属于一代集合类,是一个Dictionary具体的实现 。Java1.2重构的Hashtable实现了Map接口,因此,Hashtable现在集成到了集合框架中。它和HashMap类很相似。
2.5.1 Dictionary类
Dictionary类是一代集合中的双列集合顶层类,Dictionary类中的方法都是双列集合中最基本的方法;严格意义来说Java中所有的双列集合都应该继承与Dictionary类,但Java2推出了一系列二代集合,其中二代集合中的Map接口也已经替代了Dictionary接口,成为双列集合的顶层接口,因此Dictionary接口下面没有太多的实现类;
Tips:目前JDK已经不推荐使用Dictionary类了;
- Dictionary接口方法如下:
| 方法 | 说明 |
|---|---|
Enumeration<V> elements() |
返回此字典中值的枚举。 |
V get(Object key) |
返回该字典中键映射到的值。 |
boolean isEmpty() |
检测该字典是否为空。 |
Enumeration<K> keys() |
返回此字典中键的枚举。 |
V put(K key, V value) |
添加一对key,value到字典中 |
V remove(Object key) |
根据对应的key从字典中删除value。 |
int size() |
返回此字典中的条目数。 |
- 方法测试:
package com.dfbz.hashtable;
import java.util.Dictionary;
import java.util.Enumeration;
import java.util.Hashtable;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01_Hashtable基本使用 {
public static void main(String[] args) {
Dictionary<Integer, String> hashtable = new Hashtable<>();
hashtable.put(1, "南昌拌粉");
hashtable.put(2, "粉蒸肉");
hashtable.put(3, "福羹");
hashtable.put(4, "藜蒿炒腊肉");
hashtable.put(5, "瓦罐汤");
String s1 = hashtable.get(3);
System.out.println(s1); // 福羹
String s2 = hashtable.remove(2);
System.out.println(s2); // 粉蒸肉
System.out.println(hashtable); // {5=瓦罐汤, 4=藜蒿炒腊肉, 3=福羹, 1=南昌拌粉}
System.out.println("-------------");
// 获取到Hashtable的所有key
Enumeration<Integer> keys = hashtable.keys();
while (keys.hasMoreElements()){
Integer key = keys.nextElement();
System.out.println(key);
}
System.out.println("-------------");
// 获取到Hashtable的所有value
Enumeration<String> vals = hashtable.elements();
while (vals.hasMoreElements()){
String val = vals.nextElement();
System.out.println(val);
}
System.out.println("-----------------");
System.out.println(hashtable.size()); // 4
}
}
2.5.2 Hashtable与HashMap的区别
- 1)Hashtable属于一代集合,继承了Dictionary类,也实现了Map接口,HashMap属于二代集合,实现与Map接口,没有与Dictionary类产生关系;
- 2)Hashtable支持iterator遍历(Map接口中的),也支持Enumeration遍历(Dictionary),HashMap只支持iterator遍历
- 3)Hashtable与HashMap底层都是采用hash表这种数据结构,JDK8对HashMap进行了优化(引入红黑树),但并没有对Hashtable进行优化;
- 4)HashMap默认的数组大小是16,Hashtable则是11,两者的负载因子都是0.75,并且都允许传递初始化的数组大小和负载因子
- 5)HashMap对null key和null value进行了特殊处理,可以存储null key和null value,Hashtable则不能存储null key和null value;
- **6)当HashMap存储的元素数量>数组容量_负载因子,数组扩容至原来的2倍,Hashtable则是2倍+1;_
- 7)HashMap在添加元素时使用的是:
**元素本身的hash算法 ^ (元素本身的hash算法 >>> 16)**,而Hashtable则是直接采用元素本身的hash算法;
Tips:
>>代表有符号位移,>>>代表无符号位移;
- 8)HashMap在使用foreach迭代时不能对元素内容进行增删,否则触发并发修改异常。Hashtable中支持Enumeration迭代,使用Enumeration迭代元素时,可以对集合进行增删操作;
- 9)Hashtable是线程安全的,效率低,安全性高;HashMap是线程不安全的,效率高,安全性低;
1)测试存储Null key和Null value:
package com.dfbz.demo01;
import java.util.*;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo08_HashMap与Hashtable的区别_null问题 {
public static void main(String[] args) {
HashMap<Integer, String> hashMap = new HashMap<>();
/*
HashMap对null key和null value
并且,HashMap对null key做了特殊处理,HashMap永远将Null key存储在第0位数组上
*/
hashMap.put(1, null);
hashMap.put(null, "冻米糖");
System.out.println(hashMap); // {null=大闸蟹, 1=null}
}
public static void test1() {
Hashtable<Integer, String> hashtable = new Hashtable<>();
// Hashtable存储null key和null value的时候会出现空指针异常: Exception in thread "main" java.lang.NullPointerException
hashtable.put(1, null);
hashtable.put(null, "冻米糖");
}
}
2)测试并发修改异常问题:
package com.dfbz.demo01;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Set;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo09_HashMap与Hashtable的区别_并发修改问题 {
public static void main(String[] args) {
Hashtable<Integer, String> hashtable = new Hashtable<>();
hashtable.put(1, "拌粉");
hashtable.put(2, "汤粉");
hashtable.put(3, "炒粉");
hashtable.put(4, "泡粉");
hashtable.put(5, "冷粉");
Enumeration<Integer> keys = hashtable.keys();
while (keys.hasMoreElements()) {
Integer key = keys.nextElement();
if (key == 2) {
/*
Hashtable在使用Enumeration遍历时,允许对集合进行增删操作
注意: Hashtable使用foreach迭代也不能对元素进行增删操作
*/
// hashtable.put(6, "扎粉");
hashtable.remove(2);
}
}
System.out.println(hashtable);
}
/**
* hashMap在使用foreach迭代时不允许对集合进行增删等操作
*/
public static void test1() {
HashMap<Integer, String> hashMap = new HashMap<>();
hashMap.put(1, "拌粉");
hashMap.put(2, "汤粉");
hashMap.put(3, "炒粉");
hashMap.put(4, "泡粉");
hashMap.put(5, "冷粉");
Set<Integer> keys = hashMap.keySet();
for (Integer key : keys) {
if (key == 2) {
// hashMap在迭代时不允许对集合进行增删等操作
hashMap.remove(2);
// hashMap.put(6, "扎粉");
}
}
}
}
三、异常
3.1 异常概述
3.1.1 什么是异常
程序运行过程中出现的问题在Java中被称为异常,异常本身也是一个Java类,封装着异常信息;我们可以通过异常信息来快速定位问题所在;我们也可以针对性的定制异常,如用户找不到异常、密码错误异常、页面找不到异常、支付失败异常、文件找不到异常等等...
当程序出现异常时,我们可以提取异常信息,然后进行封装优化等操作,提示用户;
注意:语法错误并不是异常,语法错了编译都不能通过(但Java有提供编译时异常),不会生成字节码文件,根本不能运行;
默认情况下,出现异常时JVM默认的处理方式是中断程序执行,因此我们需要控制异常,当出现异常后进行相应修改,提供其他方案等操作,不要让程序中断执行;
我们之前有见到过很多的异常:
- 空指针异常:
java.lang.NullPointerException
String str=null;
str.toString();
- 数字下标越界异常:
java.lang.ArrayIndexOutOfBoundsException
int[] arr = {1, 3, 4};
System.out.println(arr[3]);
- 类型转换异常:
java.lang.ClassCastException
class A {
}
class B extends A {
}
class C extends A {
}
public static void main(String[] args) {
A a = new B();
C c = (C) a;
}
- 算数异常:
java.lang.ArithmeticException
int i=1/0;
- 日期格式化异常:
java.text.ParseException
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date parse = sdf.parse("2000a10-24");
3.1.2 异常体系
Java程序运行过程中所发生的异常事件可分为两类:
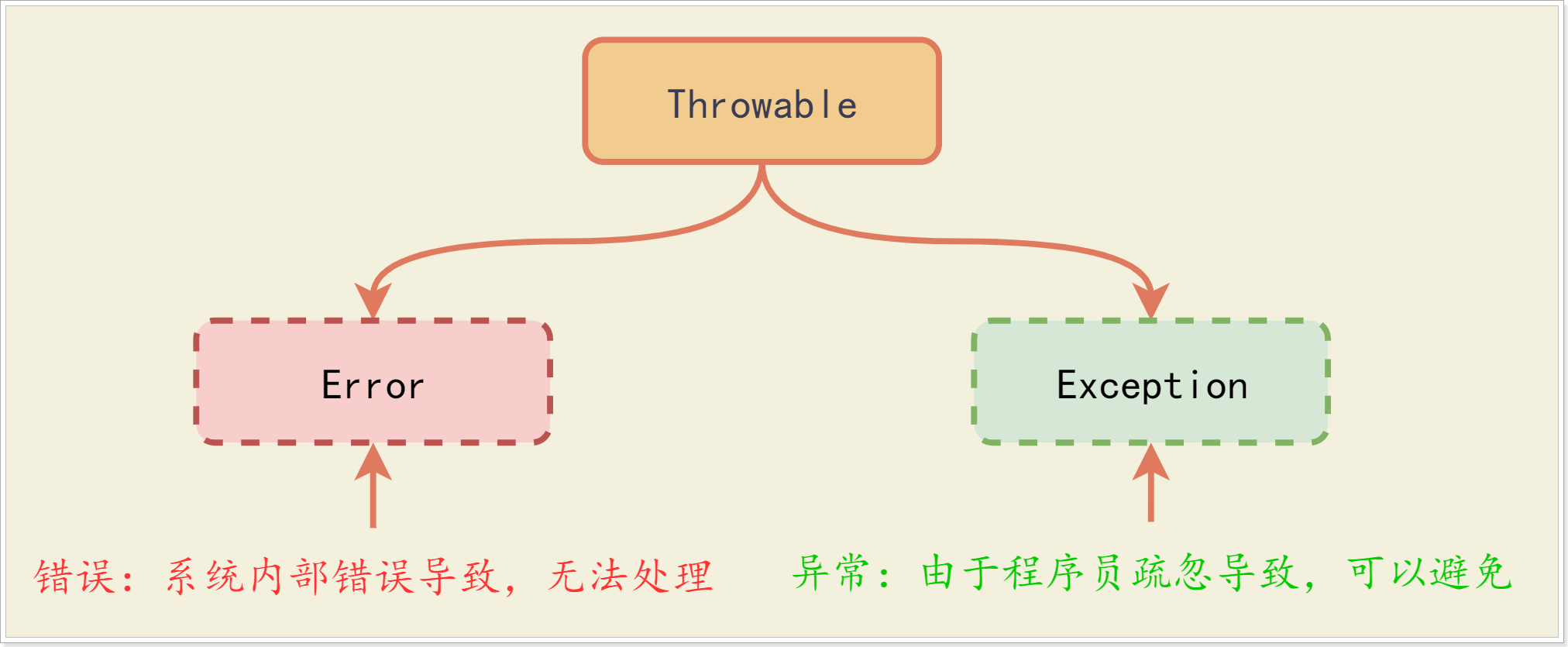
- Error:表示严重错误,一般是JVM系统内部错误、资源耗尽等严重情况,无法通过代码来处理;
- Exception:表示异常,一般是由于编程不当导致的问题,可以通过Java代码来处理,使得程序依旧正常运行;
Tips:我们平常说的异常指的就是Exception;因为Exception可以通过代码来控制,而Error一般是系统内部问题,代码处理不了;
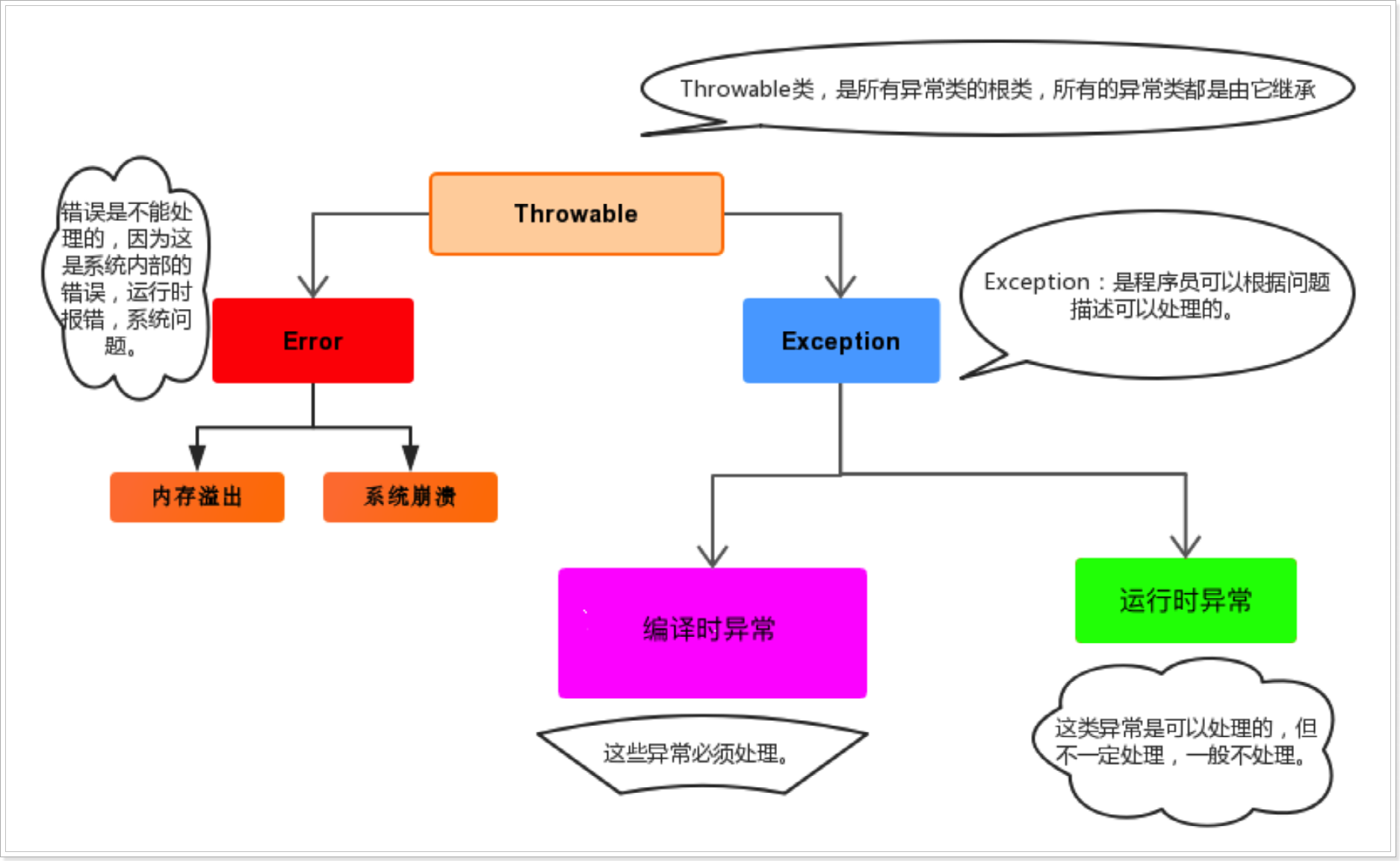
3.1.3 异常分类
异常的分类是根据在编译器检查异常还是在运行时检查异常;
- 编译时期异常:在编译时期就会检查该异常,如果没有处理异常,则编译失败;
- 运行时期异常:在运行时才出发异常,编译时不检测异常;
Tips:在Java中如果一个类直接继承与Exception,那么这个异常将是编译时异常;如果继承与RuntimeException,那么这个类是运行时异常。即使RuntimeException也继承与Exception;
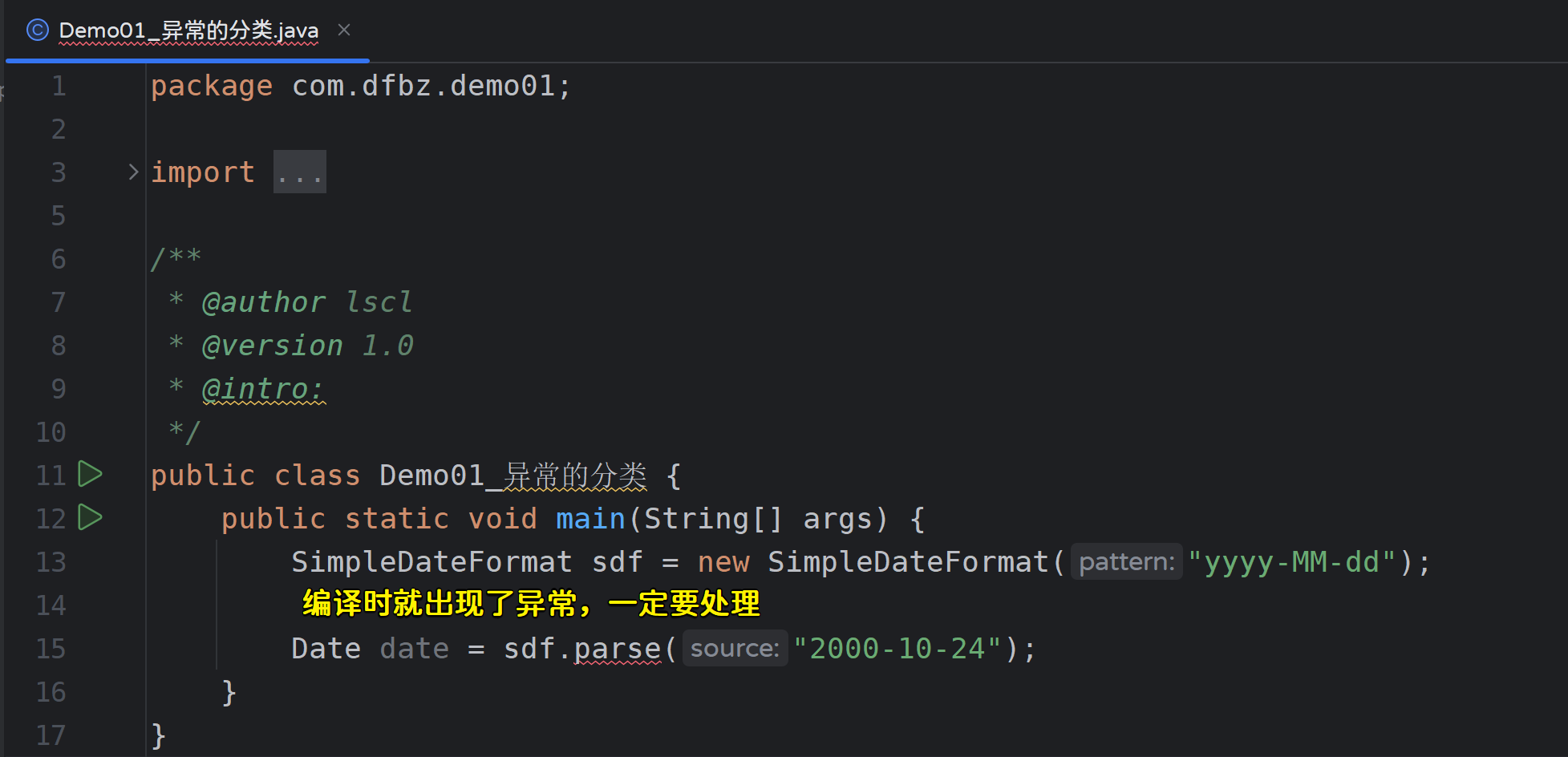
- 编译时异常举例:
public class Demo {
public static void main(String[] args) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date date = sdf.parse("2000-10-24");
}
}
- 运行时异常:
public class Demo {
public static void main(String[] args) {
int i = 1 / 0;
}
}
3.2 异常的处理
Java程序的执行过程中如出现异常,会自动生成一个异常类对象,该异常对象将被提交给Java运行时系统(JVM),这个过程称为抛出(throw)异常。
如果一个方法内抛出异常,该异常会被抛到调用方法中。如果异常没有在调用方法中处理,它继续被抛给这个调用方法的调用者。这个过程将一直继续下去,直到异常被处理。这一过程称为捕获(catch)异常。如果一个异常回到main()方法,并且main()也不处理,则程序运行终止。
流程如下:
3.2.1 异常的捕获
异常的捕获和处理需要采用 try 和 catch 来处理,具体格式如下:
- 1)
try...catch(){}:
try {
// 可能会出现异常的代码
} catch (Exception1 e) {
// 处理异常1
} catch (Exception2 e) {
// 处理异常2
} catch (ExceptionN e) {
// 处理异常N
}
Tips:后处理的异常必须是前面处理异常的父类异常;
- 2)
try...catch(){}...finally{}:
try {
// 可能会出现异常的代码
} catch (Exception1 e) {
// 处理异常1
} catch (Exception2 e) {
// 处理异常2
} catch (ExceptionN e) {
// 处理异常N
} finally {
// 不管是否出现异常都会执行的代码
}
- 3)
try...finally{}:
try {
// 可能会出现异常的代码
} finally {
// 不管是否出现异常都会执行的代码
}
1) 捕获异常
示例代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
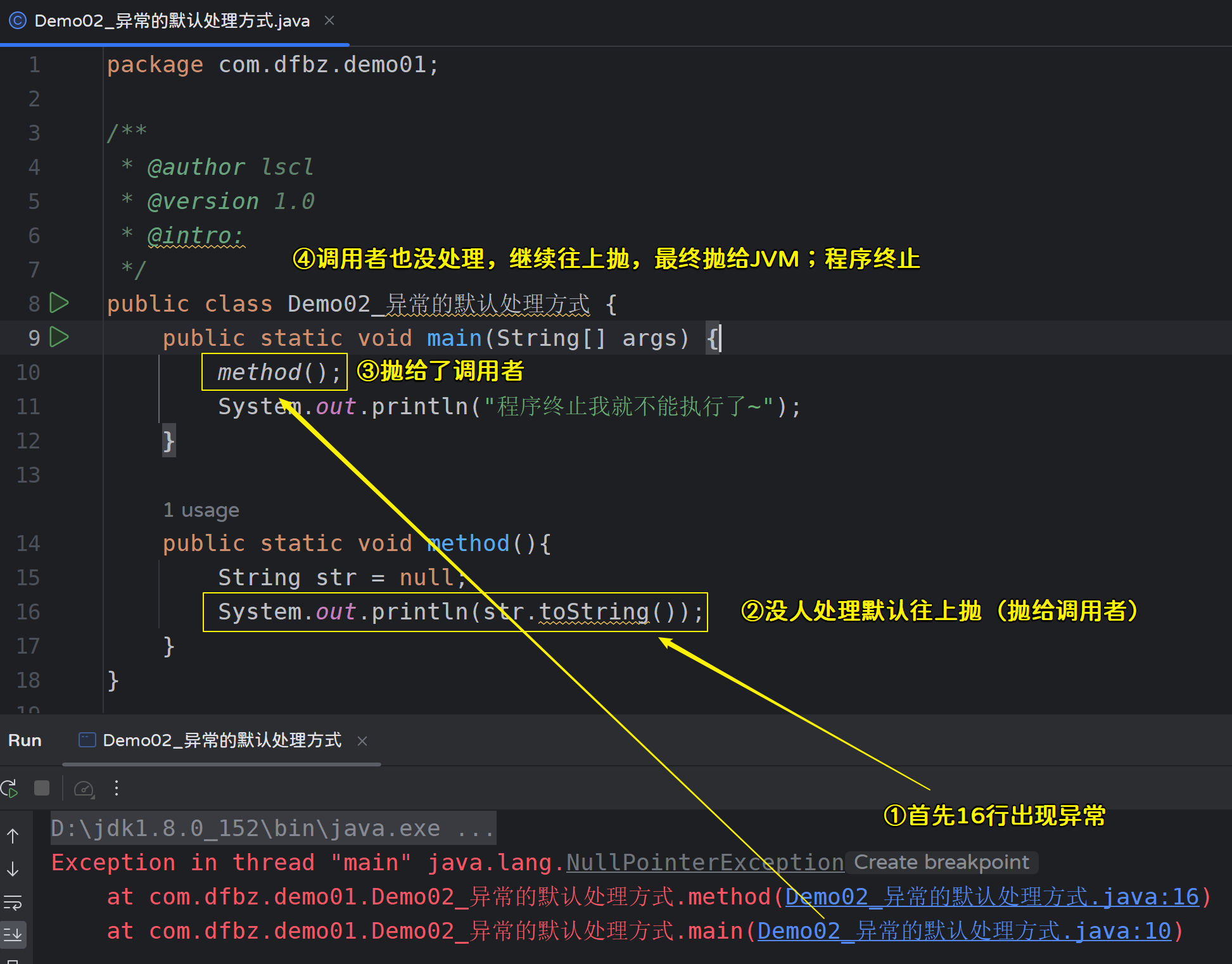
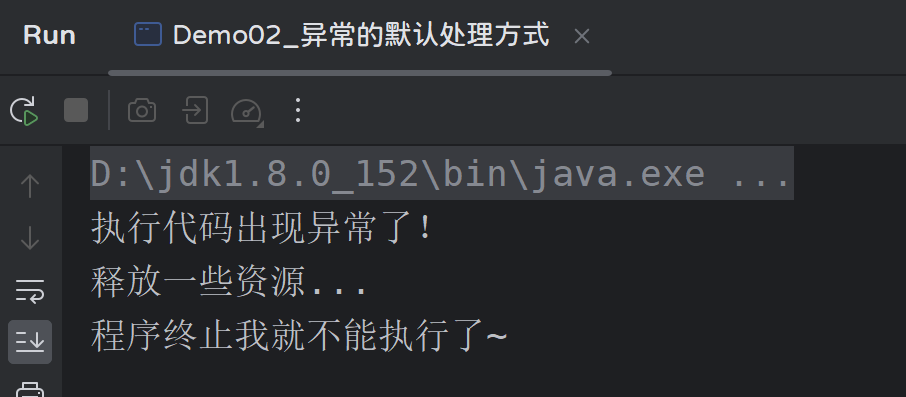
public class Demo02_异常的默认处理方式 {
public static void main(String[] args) {
method();
System.out.println("程序终止我就不能执行了~");
}
public static void method(){
try {
String str = null;
System.out.println(str.toString());
} catch (Exception e) {
System.out.println("执行代码出现异常了!");
} finally {
System.out.println("释放一些资源...");
}
}
}
运行结果:
tips:try...catch语句是可以单独使用的;即:不要finally代码块;
2) 捕获多级异常
示例代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03_异常的捕获_多级异常 {
public static void main(String[] args) {
try {
// System.out.println(1 / 0);
String str = null;
System.out.println(str.toString());
// Object obj = new Object();
// String s = (String) obj;
} catch (NullPointerException e) { // 捕获空指针异常
e.printStackTrace();
} catch (ArithmeticException e) { // 捕获算术异常
e.printStackTrace();
} catch (Exception e) { // 捕获所有异常
e.printStackTrace();
}
System.out.println("程序执行....");
}
}
需要注意的是:如果finally有return语句,则永远返回finally中的结果。我们在开发过程中应该避免该情况;
- 示例代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo04_finally {
public static void main(String[] args) {
int result = method();
System.out.println("method方法的返回值: " + result);
}
public static int method() {
try {
int i = 10;
return 1;
} catch (Exception e) {
e.printStackTrace();
return 2;
} finally {
return 3; // 不管是否出现异常都是返回3
}
}
}
3.2.2 异常的常用方法
在Throwable类中具备如下几个常用异常信息提示方法:
public void printStackTrace():获取异常的追踪信息;
包含了异常的类型,异常的原因,还包括异常出现的位置,在开发和调试阶段,都得使用printStackTrace。public String getMessage():异常的错误信息;
异常触发被抓捕时,异常的错误信息都被封装到了catch代码块中的Exception类中了,我可以通过该对象获取异常错误信息;
示例代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_异常类的方法 {
public static void main(String[] args) {
method();
System.out.println("我继续执行~");
}
public static void method() {
try {
// int i = 1 / 0; // 算术异常
// String str = null;
// System.out.println(str.toString()); // 空指针异常
String str = (String) new Object(); // 类型转换异常
} catch (Exception e) {
System.out.println("异常的错误信息: " + e.getMessage());
// 打印异常的追踪信息
e.printStackTrace();
}
}
}
运行结果如下:
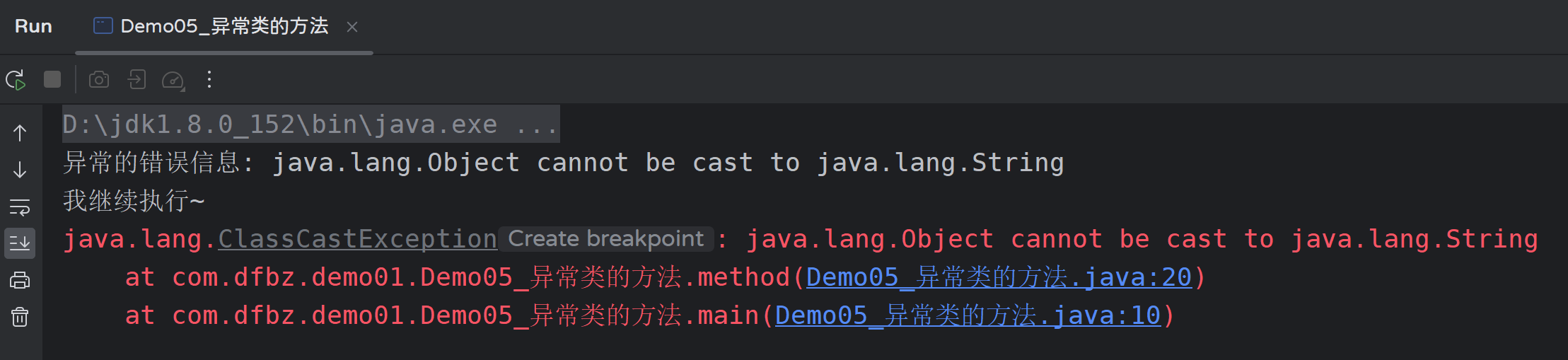
异常的追踪信息可以帮助我们追踪异常的调用链路,一步一步找出异常所涉及到的方法,在实际开发非常常用;
3.2.3 异常的抛出
我们已经学习过出现异常该怎么抓捕了,有时候异常就当做提示信息一样,在调用者调用某个方法出现异常后及时针对性的进行处理,目前为止异常都是由JVM自行抛出,当然我们可以选择性的自己手动抛出某个异常;
Java提供了一个throw关键字,它用来抛出一个指定的异常对象;抛给上一级;
Tips:自己抛出的异常和JVM抛出的异常是一样的效果,都要进行处理,如果是自身抛出的异常一直未处理,最终抛给JVM时程序一样会终止执行;
语法格式:
throw new 异常类名(参数);
示例:
throw new NullPointerException("调用方法的对象是空的!");
throw new ArrayIndexOutOfBoundsException("该索引在数组中不存在,已超出范围");
示例代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo06_异常的抛出 {
public static void main(String[] args) {
method(null);
System.out.println("main running...");
}
public static void method(String str) {
if (str == null) {
// 手动抛出异常(抛出异常后,后面的代码将不会被执行)
throw new ClassCastException("出现空指针异常啦!");
}
System.out.println("method running...");
}
}
运行结果:
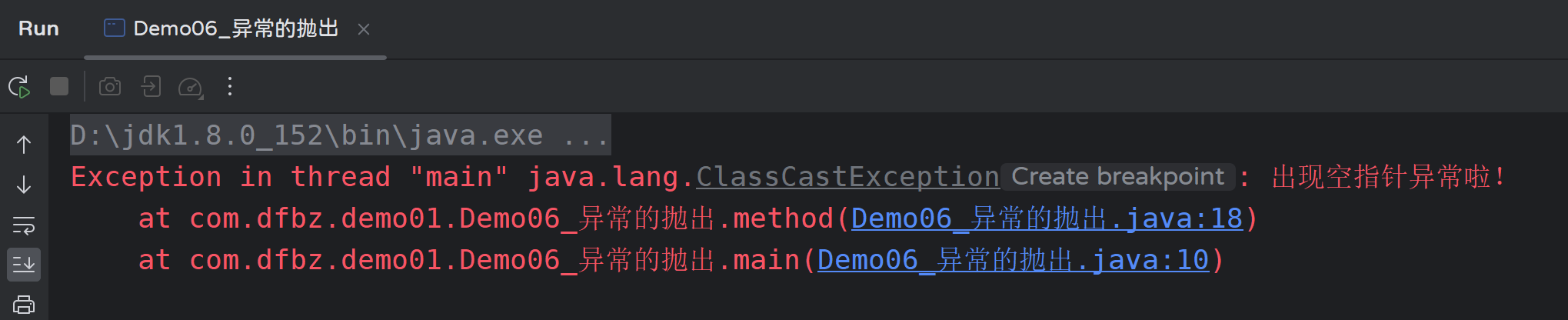
手动抛出的异常和JVM抛出的异常是一个效果,也需要我们来处理抛出的异常;
修改代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo06_异常的抛出 {
public static void main(String[] args) {
try {
method(null);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("main running...");
}
public static void method(String str) {
if (str == null) {
// 手动抛出异常(抛出异常后,后面的代码将不会被执行)
throw new ClassCastException("出现空指针异常啦!");
}
System.out.println("如果出现了异常我是不会执行了,你能执行到这里说明没有异常");
System.out.println("method running...");
}
}
运行结果:
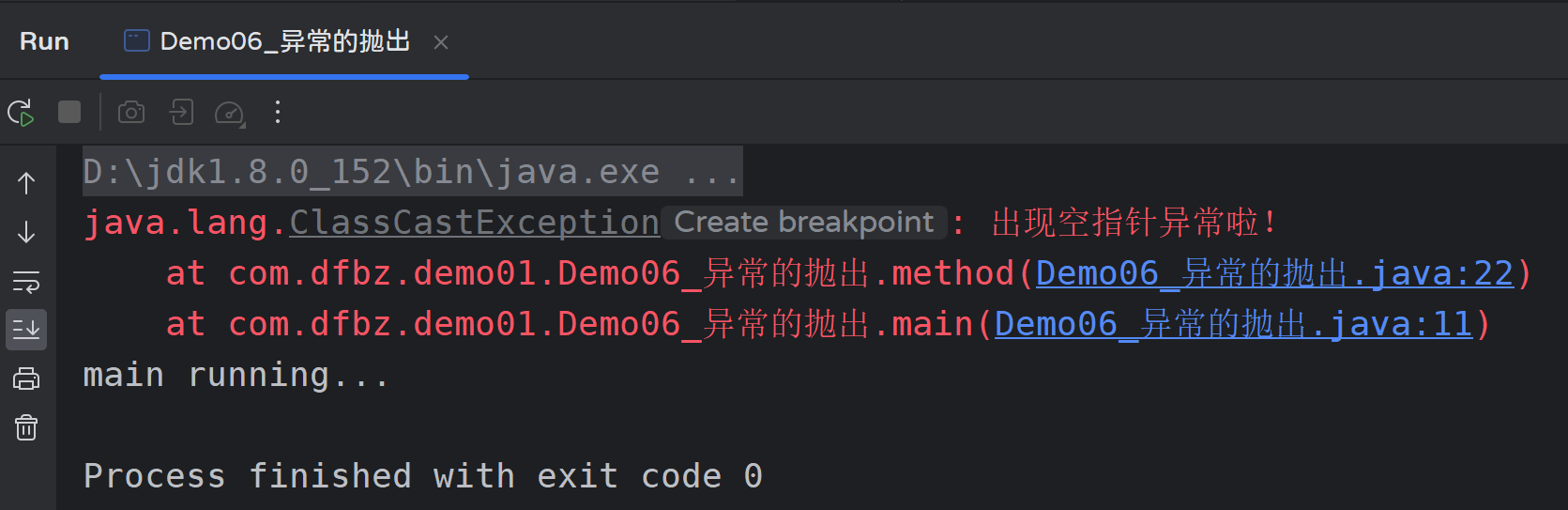
需要注意的时,如果是代码中抛出编译时异常,那么必须要处理,可以选择在方法上声明,或者try...catch处理
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo07_异常的抛出_注意事项 {
public static void main(String[] args) {
method();
}
public static void method() {
Boolean flag = true;
if (flag) {
try {
// 如果抛出的是编译时异常,那么一定要处理
throw new Exception("出现了编译时异常!");
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("111");
}
public static void method2() {
Boolean flag = true;
if (flag) {
// 如果抛出的是运行时异常,可以处理也可以不处理
throw new RuntimeException("出现了运行时异常!");
}
System.out.println("222");
}
}
3.2.4 声明异常
在定义方法时,可以在方法上声明异常,用于提示调用者;
Java提供throws关键字来声明异常;关键字throws运用于方法声明之上,用于表示当前方法不处理异常,而是提醒该方法的调用者来处理异常(抛出异常);
方法上如果声明了编译时异常,那么调用者在调用方法时,必须处理异常,可以使用try...catch捕获,继续往上抛;
方法上如果声明了运行时异常,那么调用者在调用方法时可以选择处理异常,也可以不处理;
- 语法格式:
... 方法名(参数) throws 异常类名1,异常类名2…{ }
运行时异常:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo08_异常的声明_运行时异常 {
public static void main(String[] args) {
// 在调用方法的时候,可以处理,也可以不处理
method();
}
public static void method() throws NullPointerException {
String str = null;
str.toLowerCase();
System.out.println("执行方法成功...");
}
}
编译时异常:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo09_异常的声明_编译时异常 {
public static void main(String[] args) {
try {
// 调用的方法如果声明了编译时异常,那么在调用该方法的时候就一定要处理,可以catch,也可以往上抛
method();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("-----");
}
public static void method() throws Exception {
System.out.println("method...");
}
}
3.3 自定义异常
我们说了Java中不同的异常类,分别表示着某一种具体的异常情况,那么在开发中总是有些异常情况是Java中没有定义好的,此时我们根据自己业务的异常情况来定义异常类。
我们前面提到过异常分类编译时异常和运行时异常:
- 1)继承于
java.lang.Exception的类为编译时异常,编译时必须处理; - 2)继承于
java.lang.RuntimeException的类为运行时异常,编译时可不处理;
定义一个编译时异常:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro: 直接继承与Exception的是编译时异常
*/
public class MyException extends Exception{
public MyException() {
}
public MyException(String message) {
super(message);
}
}
定义一个运行时异常:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro: 继承与RuntimeException的是运行时异常
*/
public class MyRuntimeException extends RuntimeException {
public MyRuntimeException() {
}
public MyRuntimeException(String message) {
super(message);
}
}
测试代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo10_自定义异常测试 {
public static void main(String[] args) {
show();
method();
}
public static void show() {
Boolean flag = true;
if (flag) {
try {
// 抛出的是编译时异常,一定要处理
throw new MyException("出现了我们自己的编译时异常...");
} catch (MyException e) {
e.printStackTrace();
}
}
System.out.println("show...");
}
public static void method() {
Boolean flag = true;
if (flag) {
throw new MyRuntimeException("出现了我们自己的运行时异常...");
}
System.out.println("method..."); // 这句代码是不会执行的,因为前面出现了异常并且往上抛了
}
}
运行结果:
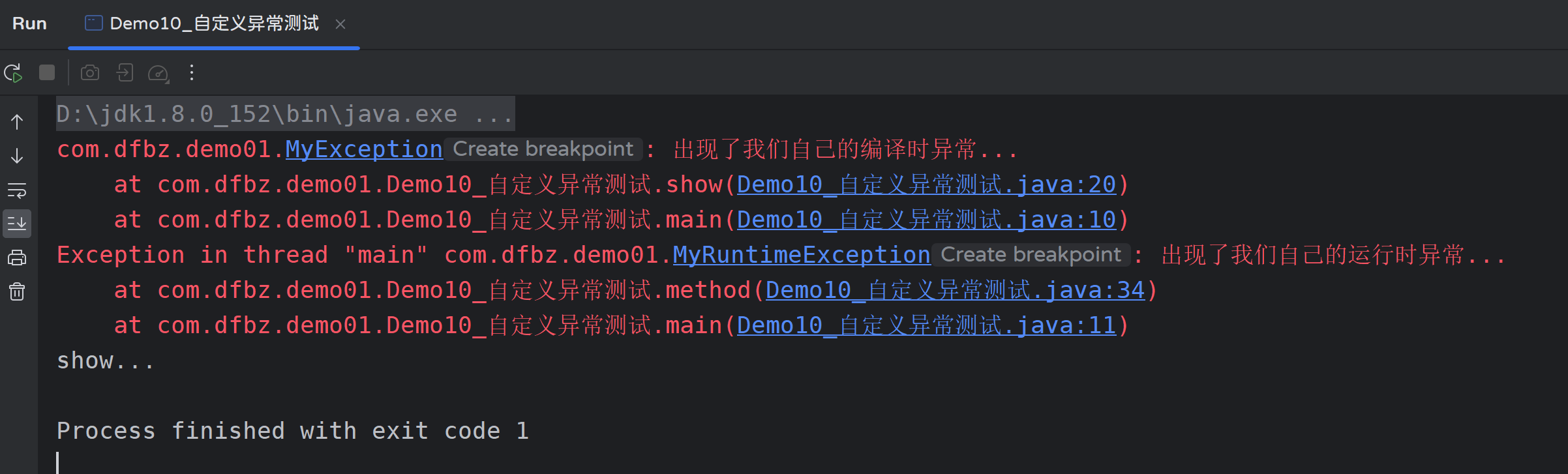
3.4 方法的重写与异常
- 1)子类在重写方法时,父类方法没有声明编译时异常,则子类方法也不能声明编译时异常;
需要注意的是:运行时异常没有这个规定;也就是子类在重写父类方法时,不管父类方法是否有声明异常,子类方法都可以声明异常;
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro: 子类在重写方法时,父类方法没有声明编译时异常,则子类方法也不能声明编译时异常;
*/
public class Demo11_方法的重写与异常的关系_01 {
public static void main(String[] args) {
}
}
// 定义一个编译时异常
class MyTestException extends Exception {
}
class Fu {
public void method() {
}
public void method2() {
}
}
class Zi extends Fu {
// 语法通过,运行时异常随意
public void method() throws NullPointerException {
}
// 语法报错,父类方法没有声明编译时异常,那么子类重写方法时也不能声明编译时异常
/* public void method2() throws MyTestException {
}*/
}
- 2)同样是在编译时异常中,在子类重写父类方法时,子类不可以声明比父类方法大的编译时异常;
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro: 在子类重写父类方法时,子类不可以声明比父类方法大的编译时异常;
*/
public class Demo12_方法的重写与异常的关系_02 {
}
// 定义一个编译时异常
class MyTest02Exception extends Exception {
}
class A {
public void method() throws NullPointerException{
}
public void method2()throws Exception{
}
}
class B extends A {
// 运行时异常没有问题
public void method() throws RuntimeException {
}
// 语法报错,如果是编译时异常,子类在重写父类方法时,不可以抛出比父类大的编译时异常
// public void method2() throws MyTest02Exception {
// }
}
四、Debug
Debug:程序调试,我们在编写代码的过程中,可能会出现一些问题,这个时候就需要进行程序的调试,通过一步一步代码的执行来观察数据发生的变化,以此来排查程序中的错误,接下来我们就来来了解IDEA调试功能。
1)设置断点
设断点是什么意思,其实就是暂定,等待的意思。当程序执行到用户设置的断点时,程序暂定执行,等待下一步命令的执行。在IDEA中只需在代码注释行旁边单击鼠标左键即可。
- 示例代码:
package com.dfbz.demo;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01 {
public static void main(String[] args) {
int num = 0;
for (int i = 0; i <=10; i++) {
num+=i;
}
System.out.println(num);
}
}
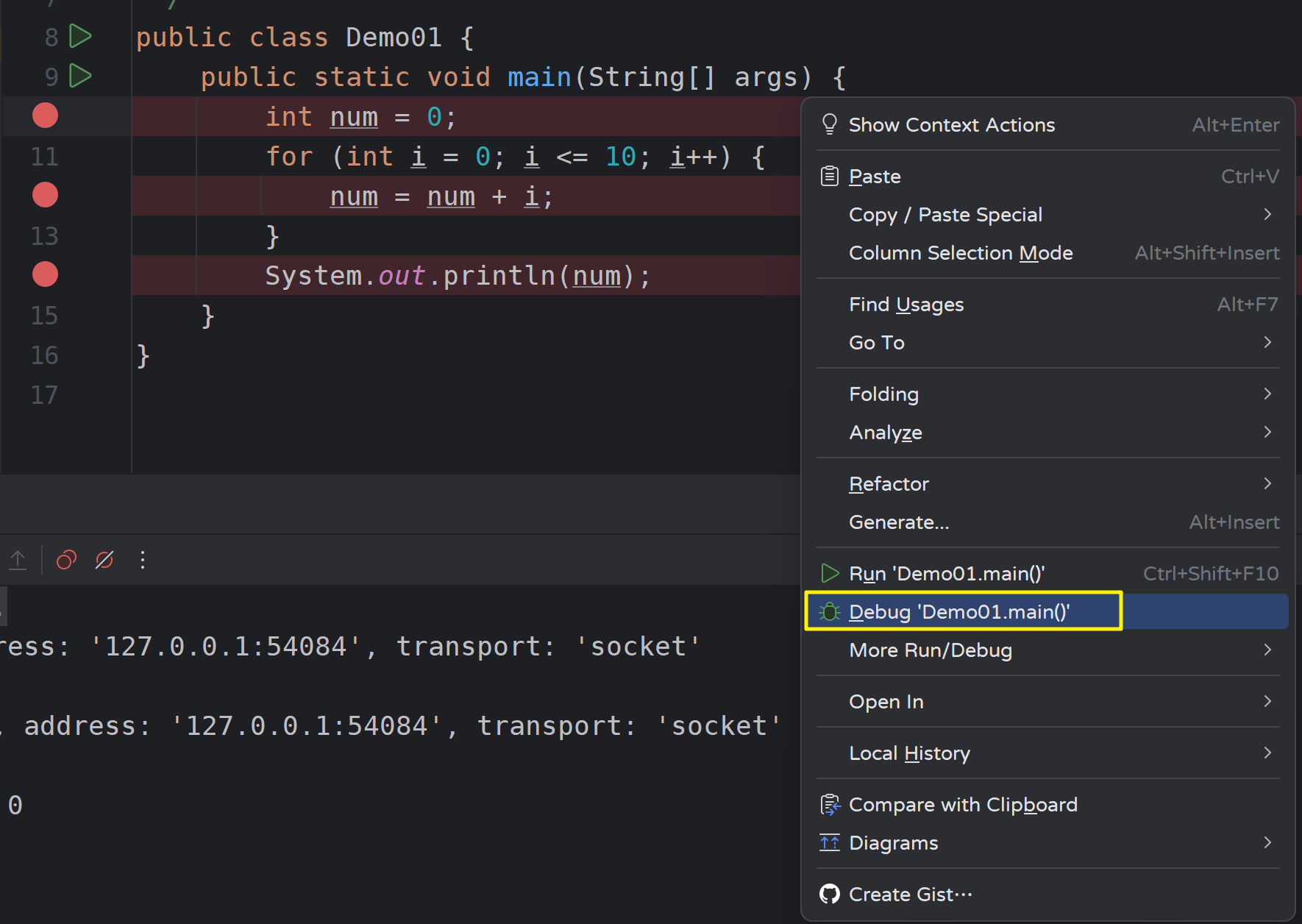
2)基础操作
当程序以Debug方式运行后(快捷键:shift+F9),会卡在我们设置的第一个断点的位置,等待我们执行后续的Debug命令;
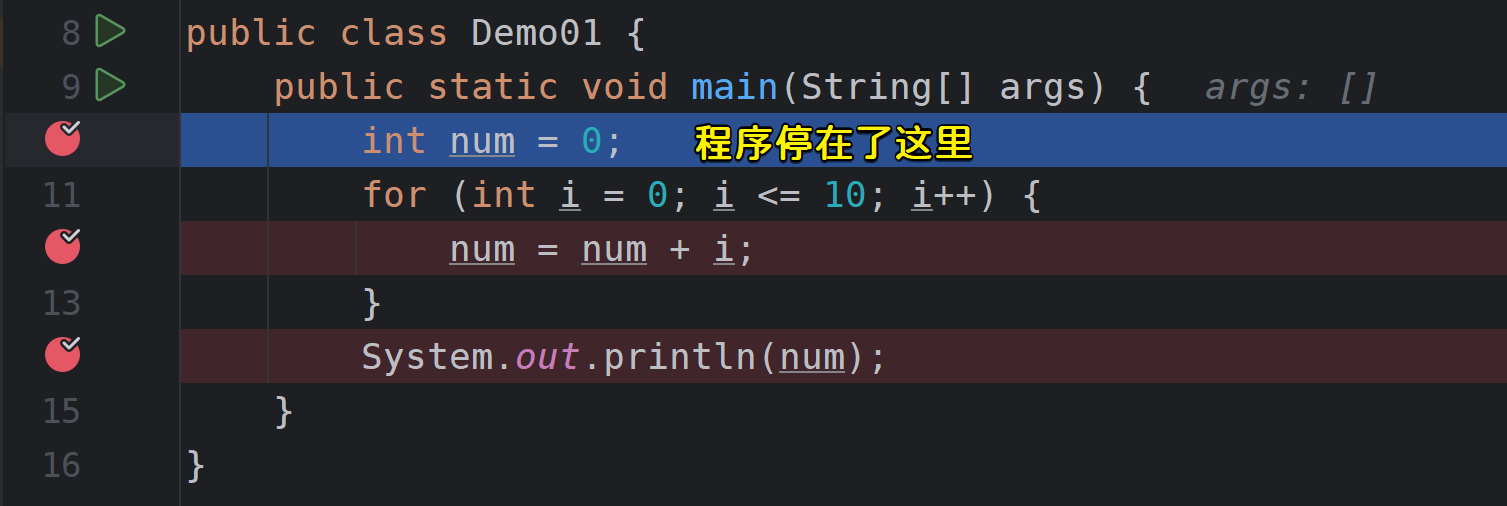
接下来我们可以执行后续的操作;
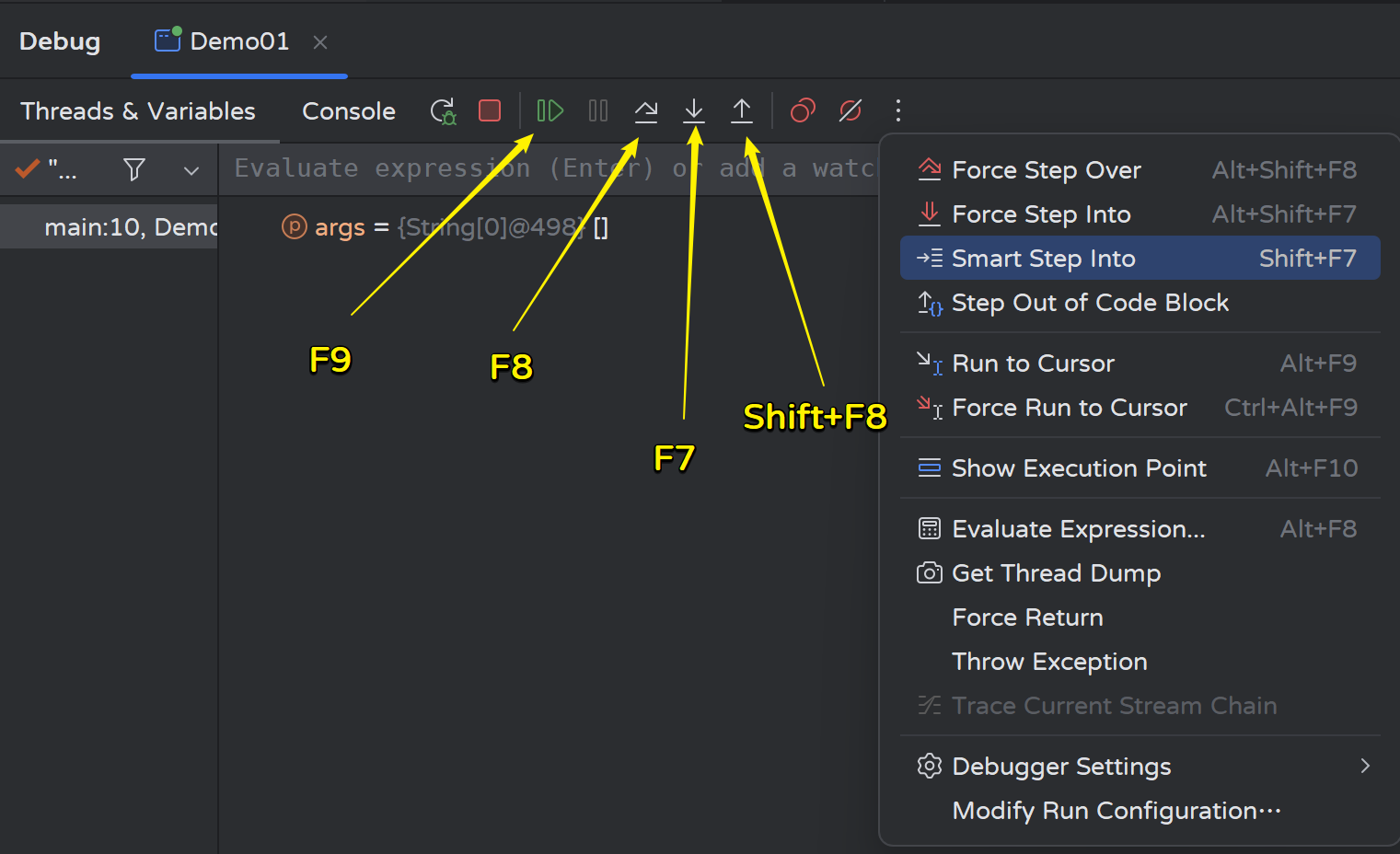
- 1)Step over(F8):程序往下执行一行
- 2)Step into(F7):进入方法内,可以进入自定义方法或三方库方法,JDK方法无法进入
- 3)Smart Step Into:灵活进入方法体
- 4)Force step into(Alt+Shift+F7):强制进入方法内,一般 Step into 进不去时可以使用
Tips:Alt+Shift+F7:一般用于一些隐藏的操作,例如JDK自动拆装箱;
- 5)Step out(Shift+F8):退出方法,跟force step into 配合使用
- 6)Resume Program(F9):恢复运行程序,运行到下一个断点的地方
【演示F7进入方法】
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02 {
public static void main(String[] args) {
show();
System.out.println("main..");
show();
}
public static void show() {
System.out.println("show...");
print();
}
public static void print() {
System.out.println("print...");
}
}
【演示shift+F7与Alt+Shift+F7】
public class Demo03 {
public static void main(String[] args) {
List<Integer> list=new ArrayList<>();
list.add(1);
System.out.println("end..");
}
}

3)断点失效
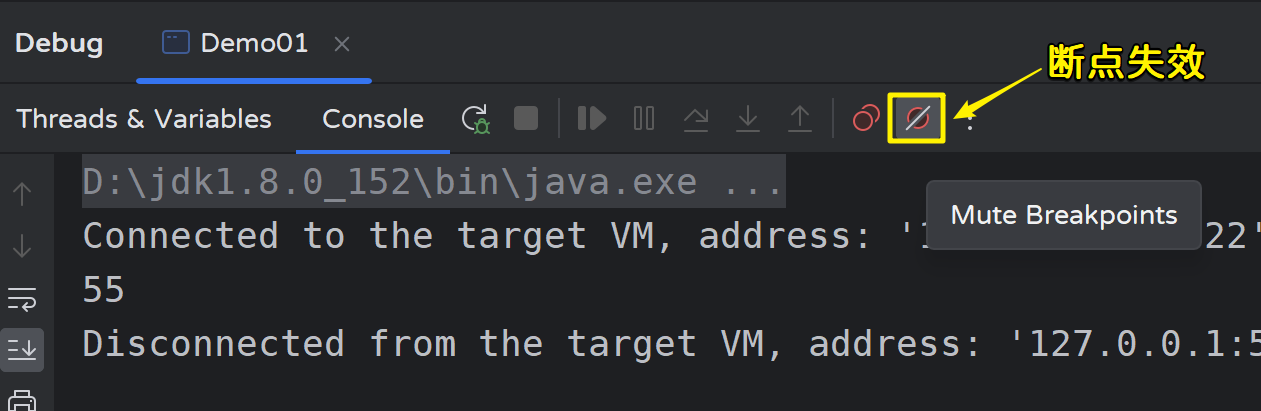
点击后所有断点处于失效状态:当再次点击该按钮时,断点又再次生效
4)设置断点条件
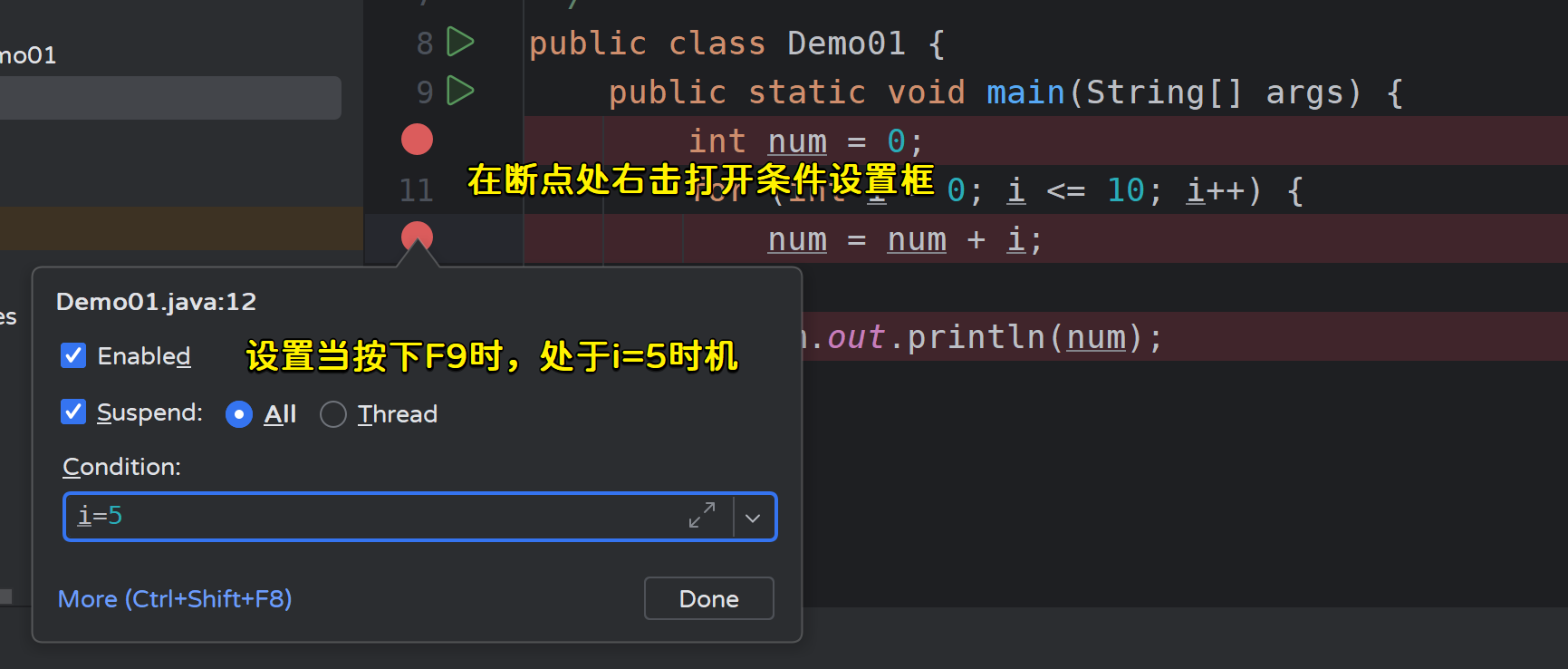
5)方法断点
图标:红色菱形
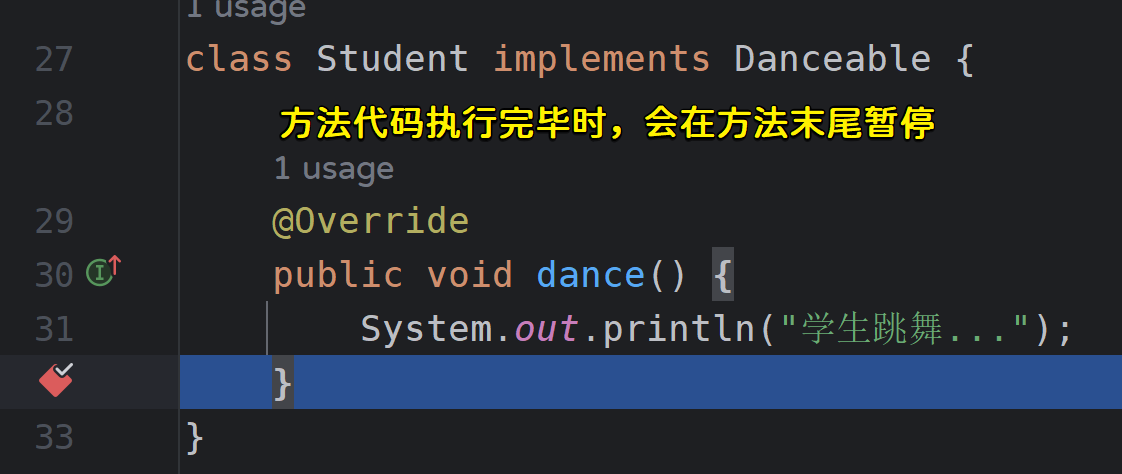
功能:在方法入口(entry)和出口(exit)都会自动暂停。在方法入口暂停可以让我们从头调试整个方法,而在方法出口处暂停可以让我们看到方法执行完毕时,方法内各个变量的数据情况。
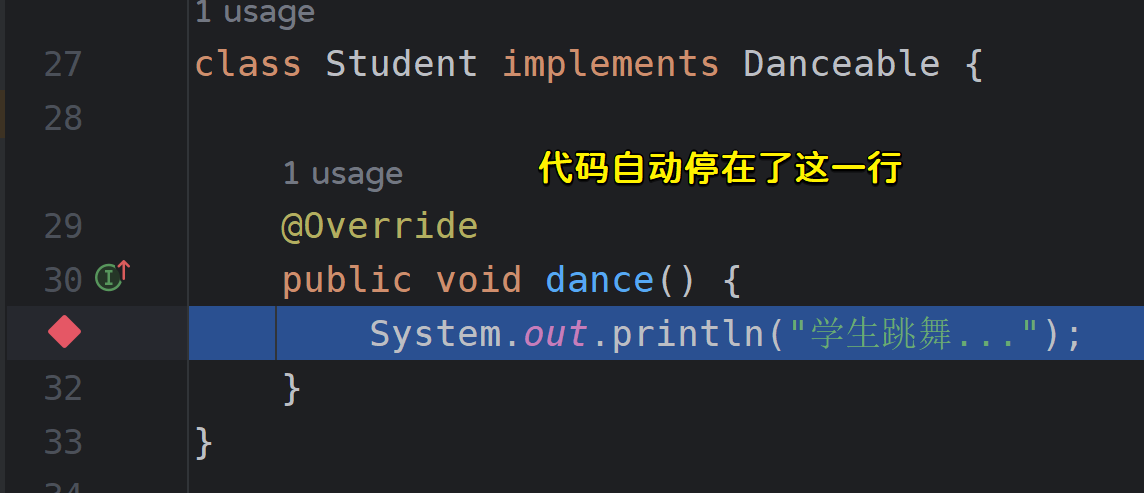
有时候我们的一个接口会存在很多实现类,我们短时间内难以分析究竟是运行到了哪个实现类中,这个时候就可以使用方法断点,我们将断点打在接口方法上,运行到该方法时,会自动跳到实际执行的实现类,无需通过上下文环境去分析是哪个实现类。
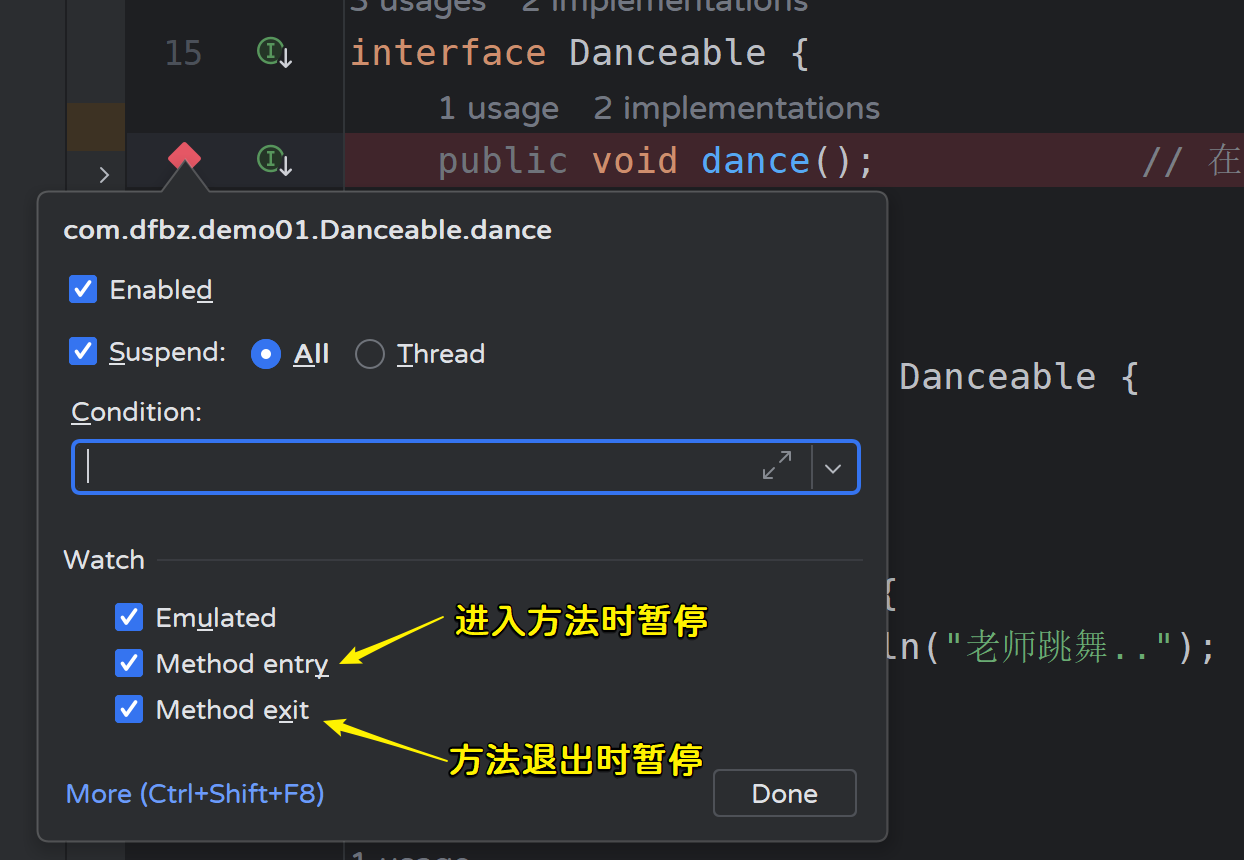
- 示例代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo04_方法断点 {
public static void main(String[] args) {
Danceable danceable = new Student();
danceable.dance();
}
}
interface Danceable {
public void dance(); // 在这一行打上断点,代码会自动在实现类的方法中暂停
}
class Teacher implements Danceable {
@Override
public void dance() {
System.out.println("老师跳舞..");
}
}
class Student implements Danceable {
@Override
public void dance() {
System.out.println("学生跳舞...");
}
}
6)字段断点
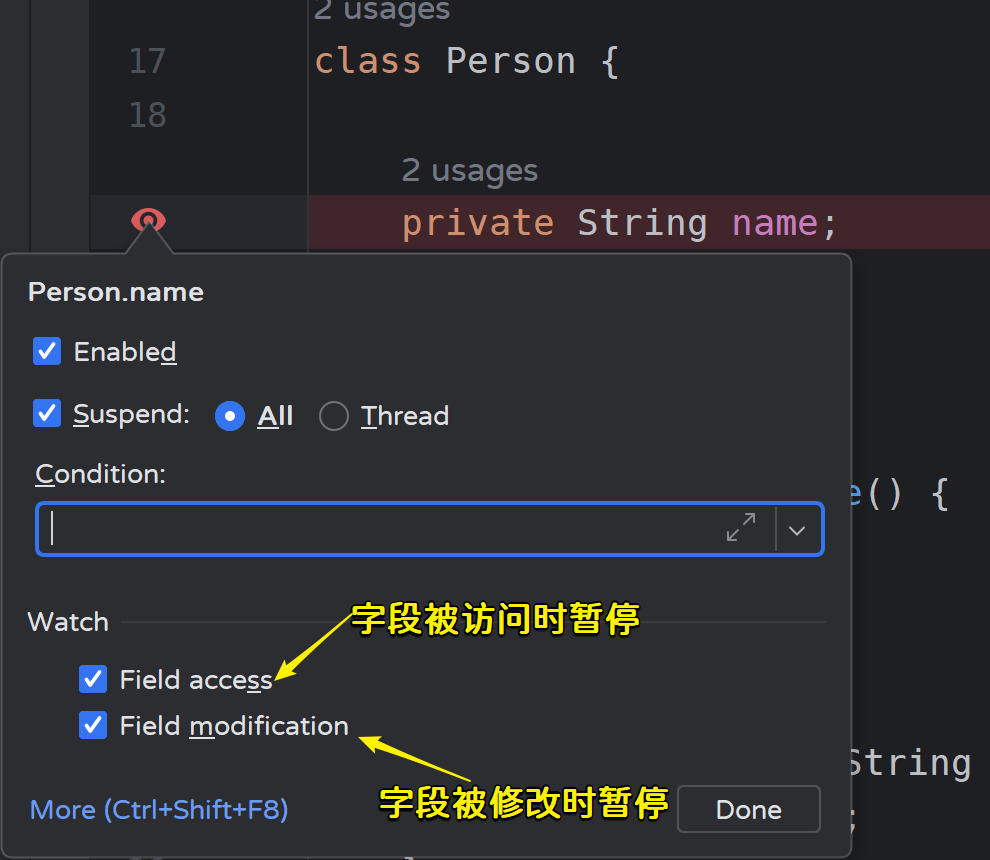
图标:红色眼睛
功能:在字段发生变更(默认)或者被访问(需要额外设置)时暂停。
如果我们想知道某个属性在什么时候被修改,从入口处开始调试太麻烦,我们可以直接在字段上打上字段断点,这样字段被修改的时候就会自动暂停。
而如果我们想在字段被访问时也暂停,则可以右键字段断点,将【Field access】勾选上即可。
测试代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo05_字段断点{
public static void main(String[] args) {
Person p = new Person();
p.setName("小灰");
System.out.println(p.getName());
}
}
class Person {
private String name;
private Integer age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
- 修改name时:

- 访问name时:
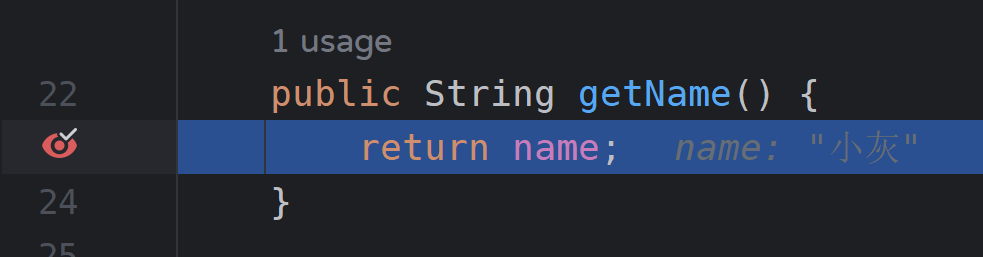
7)异常断点
图标:红色闪电
功能:可以在抛出异常的地方进行暂停
异常断点是无需在具体的代码上打断点的,而是在断点详情页中直接添加,后续在执行时,如果抛出我们监听的异常,则会自动暂停在抛出异常的地方。
- 测试代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01 {
public static void main(String[] args) {
method(100);
}
public static void method(Integer num) {
if(num == 100){
throw new ArithmeticException();
}
if(num == 200){
throw new ClassCastException();
}
if(num == 300){
throw new NullPointerException();
}
}
}
- 添加异常断点:
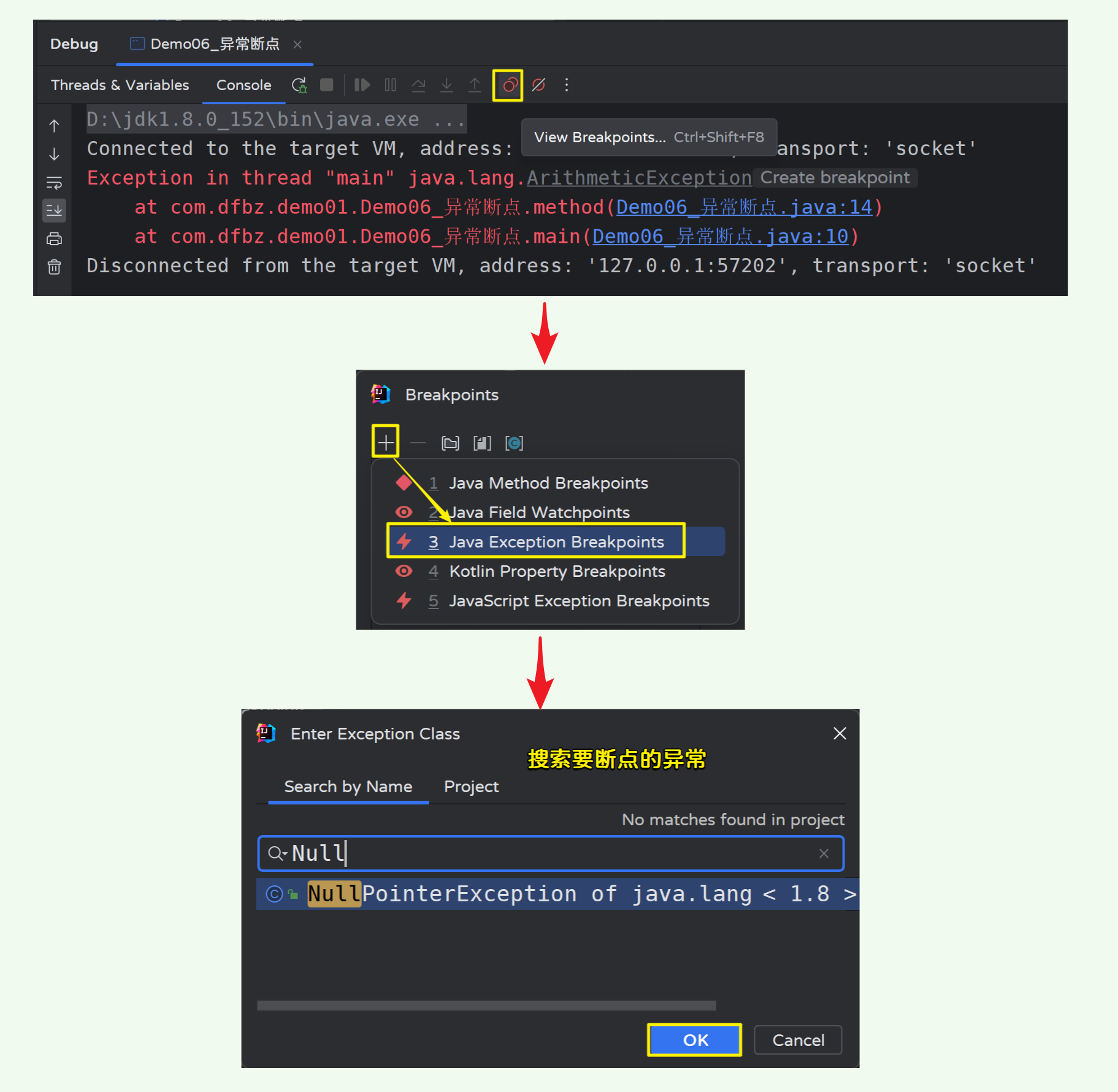
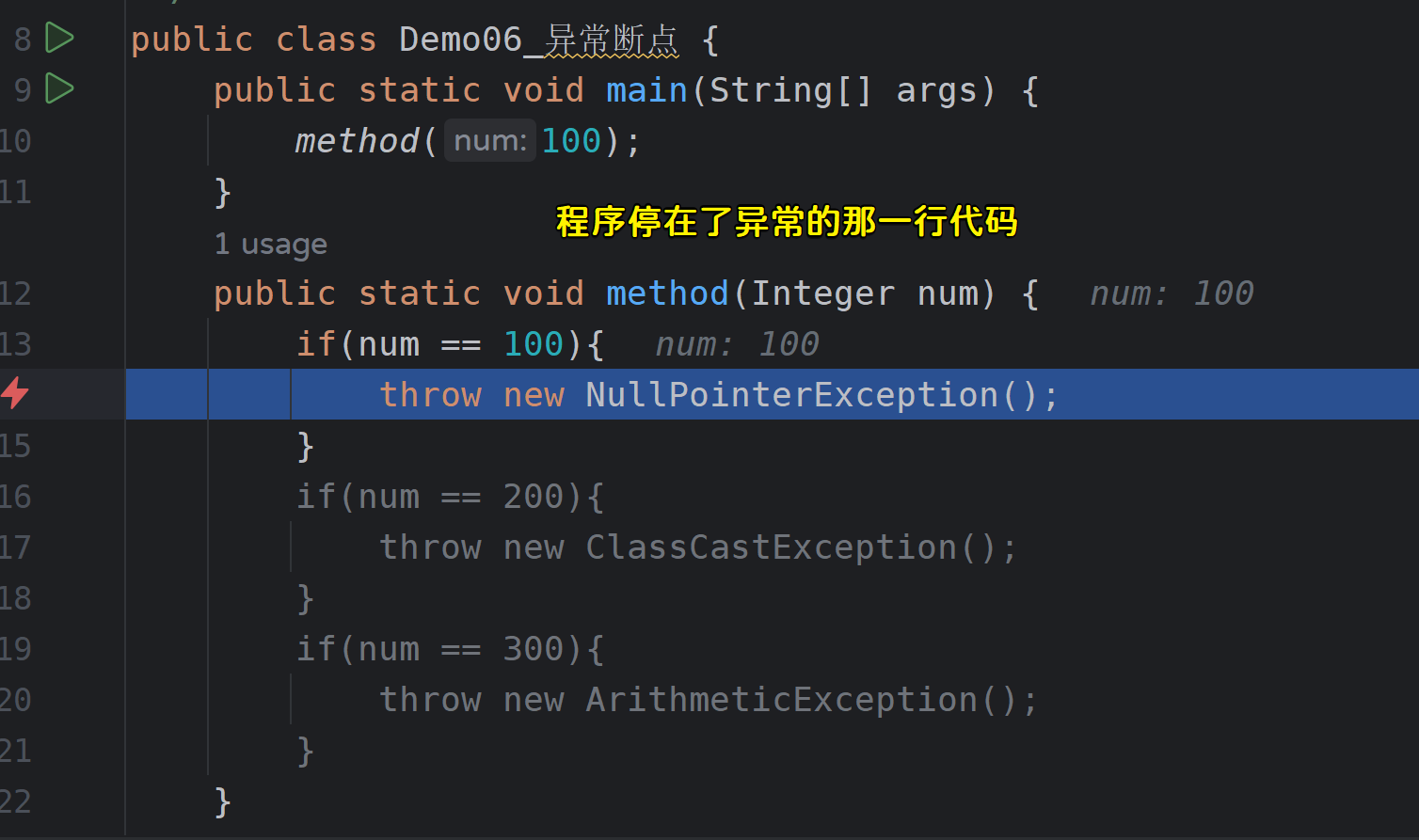
当程序开启Debug运行时,会自动暂停在出现异常的那一行代码;
8)主动抛异常
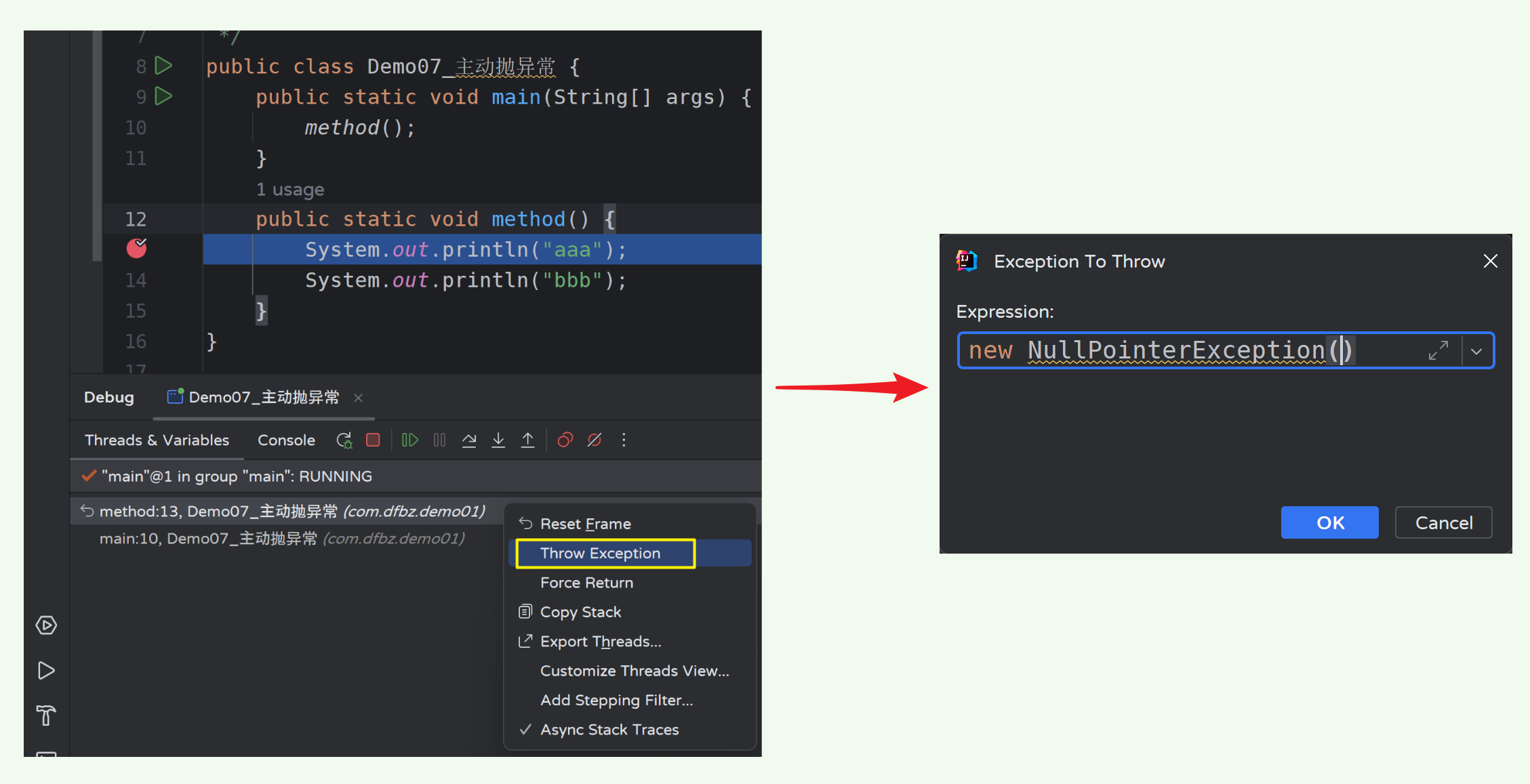
图标:无,Frames 堆栈中右键显示
功能:主动抛出指定异常
在上面的例子中,我们通过代码构造了一个异常,但是这种方式其实是不太方便的,主动抛异常可以让我们在代码正常执行的情况下在任意地点抛出任意异常。
- 示例代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo07_主动抛异常 {
public static void main(String[] args) {
method();
}
public static void method() {
System.out.println("aaa");
System.out.println("bbb");
}
}
9)降帧
功能:当我们 Debug 从 A 方法进入 B 方法时,通过降帧(退帧)可以返回到调用 B 方法前,这样我们就可以再一次调用 B 方法。
通常用于当我们快执行完 B 方法后,发现某个重要流程被我们跳过了,想再看一下,则此时可以先回退到 A 方法,然后再次进入 B 方法。
我们知道方法的执行和结束在 JVM 中对应的是栈帧的入栈和出栈,因此栈帧描述的就是方法对应的模型,而降帧(退帧)则对应的就是回退到上一个方法。
- 示例代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo08_降帧 {
public static void main(String[] args) {
method();
}
public static void method() {
System.out.println("hello method...");
print();
}
public static void print() {
System.out.println("hello print...");
}
}
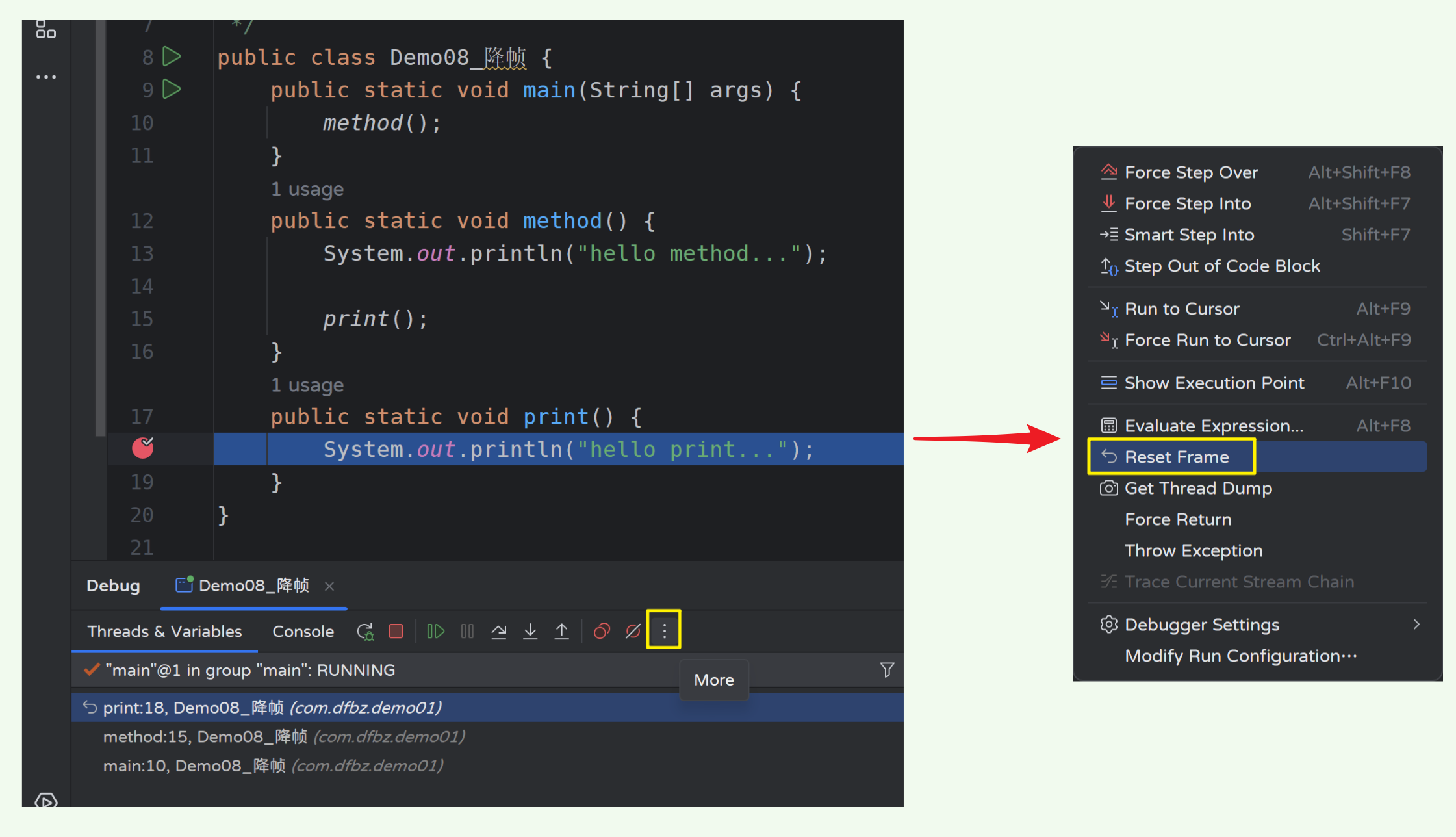

10)强制返回
功能:强制结束当前程序运行流程,直接返回。
当我们调试时,发现继续往下执行就要将错误的数据写入数据库时,我们可以通过 Force Return 来强行结束当前流程。
- 示例代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01 {
public static void main(String[] args) {
method();
}
public static void method() {
System.out.println("hello method...");
print();
System.out.println("hello method2...");
}
public static void print() {
System.out.println("hello print...");
System.out.println("hello print...");
}
}
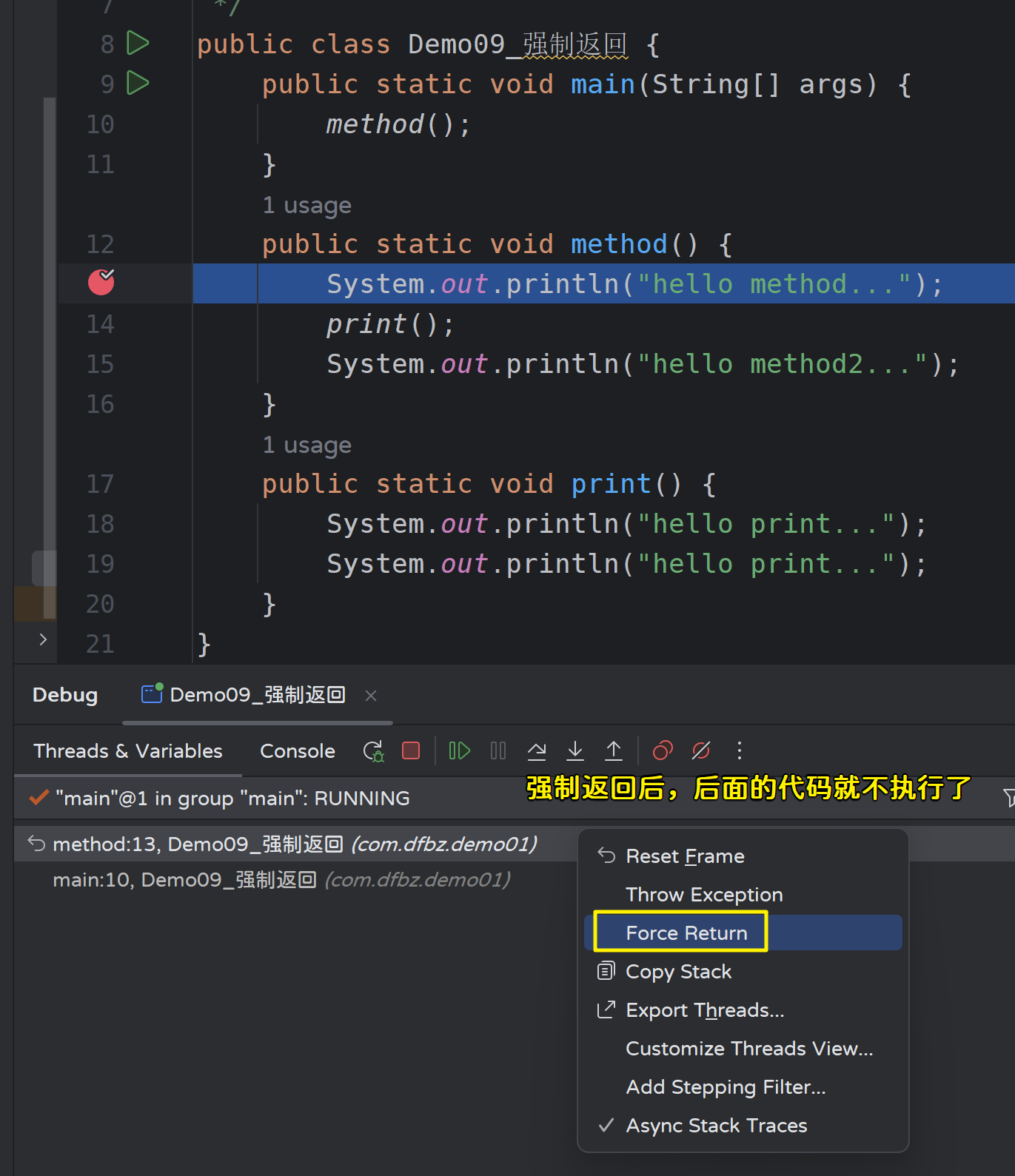
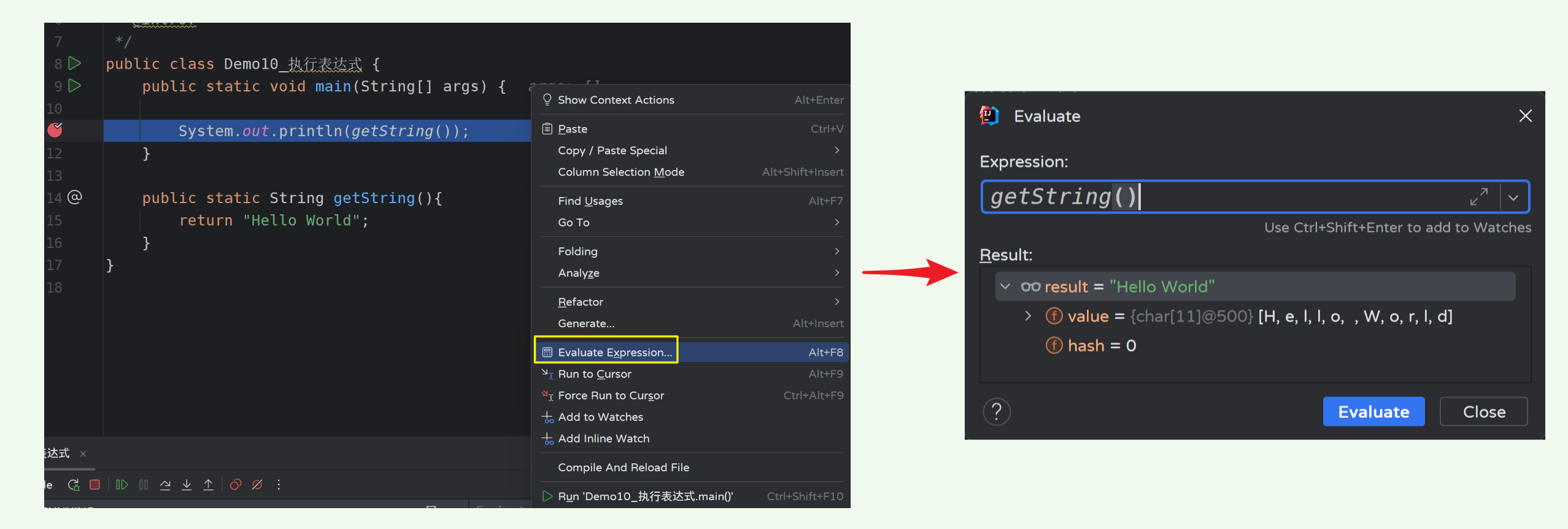
11)执行表达式
功能:用于执行一段我们实时写的代码,例如查看数据、修改数据。
- 示例代码:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo10_执行表达式 {
public static void main(String[] args) {
System.out.println(getString());
}
public static String getString(){
return "Hello World";
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号