Spark(scala)是一个用来实现快速而通用的集群计算的平台。
RDD (resilient distributed dataset) 弹性分布式数据集
速度快
提供的接口非常丰富
spark:
spark core 包含任务调度、内存管理、错误恢复、与存储系统交互等模块
spark sql 操作结构化数据的程序包
spark streaming 对实时数据进行流式计算的组件
mllib 机器学习功能的程序库
Graphx 操作图的数据库
4040端口有UI
spark可以高效的在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,spark支持在各种集群管理器
(cluster manager)上运行,包括 Hadoop yarn,mesos ,以及spark自带的一个简易调度器,叫做独立调度器。
如果要在没有预装任何集群管理器的机器上安装spark,那么spark自带的独立调度器可以让你轻松入门;
如果已经有了一个装有Hadoop yarn或Mesos的集群,通过spark对这些集群管理器的支持,也能运行在这些集群上。
术语:
Application:
client -> map-stage(mapTask *n) ,reduce-stage(reduceTask * n )
job
stage: 不用出主机,可以完成的一系列操作
mr:
1:app
1:job
1~2:stage
m:map
n:reduce
spark:
1:app
N:job
1:job->N:stage
1:stage->N:task
mapTask:
input: InputFormat -> TextInputFormat
1、client、splits 计算map数量
2、mt、lineRecordreader
input ->map(filter,sort,flatmap) -> output local file ...> shuffle
ReduceTask
shuffle ...> input -> reduce by key -> output
图谱:
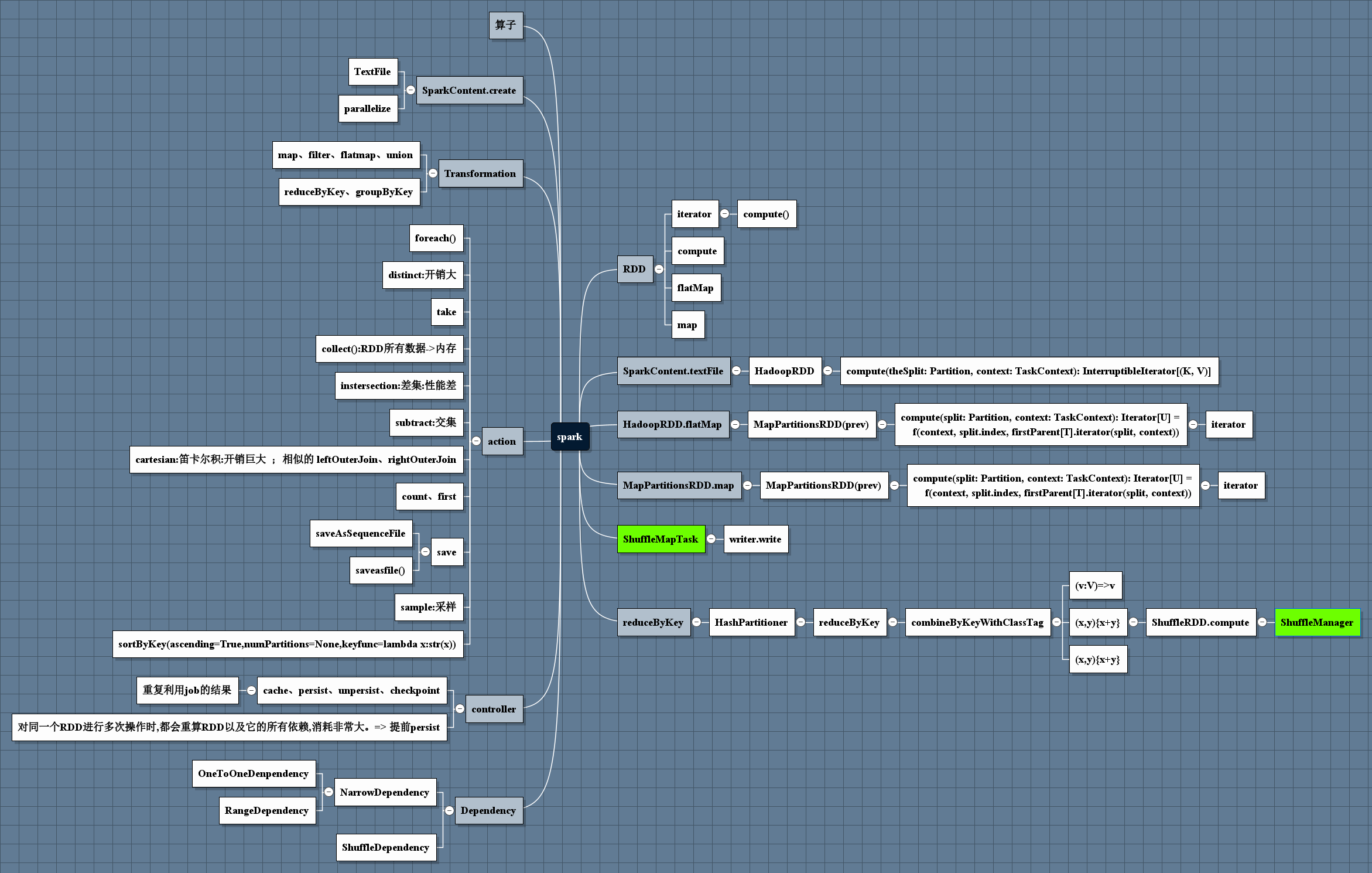
数据分区: 计算前置
并行度由 分区数决定, 但不是分区数越多越好
数据集在节点间的分区进行控制。
在分布式程序中,通信的代价是很大的,因此控制数据分布以获得最少的网络传输可以极大地提升整体性能。
和单节点的程序需要为记录集合选择合适的数据结构一样,Spark程序可以通过控制RDD分区方式来减少通信开销。
分区并不是对所有应用都有好处的------比如:如果给定RDD只需要被扫描一次,我们完全没有必要对其预先进行分区处理。只有当数据集多次在诸如连接这种基于键的
操作中使用时,分区才会有帮助。
分区数调整的必要
在处理过程中 ,一个分区内的数据 ,可能增多,可能减少,可能过少; 如何在进程开辟消耗与cpu处理的时间 中寻找 平衡点很重要
data.repartition(xxx)
data.coalesce(xxx,shuffle=True)
分区数
少->多 ,肯定会发生散的过程: shuffle移动 ,如果 shuffle 为False ,也就是没有分区器,也就是不会发生散列
多->少 ;可以没有shuffle;IO移动
数据移动:
IO移动,shuffle移动(每条数据去的地方不一样)
分区移动
当以ABD进行排序后 ,再以ABC进行排序,那么在获取D的时候,顺序会乱
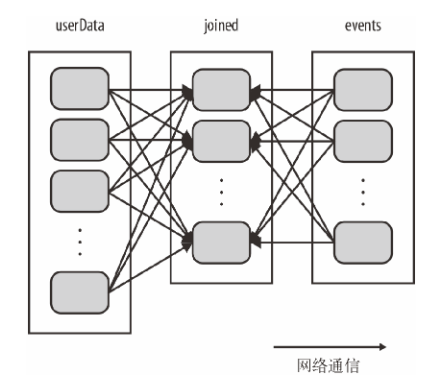
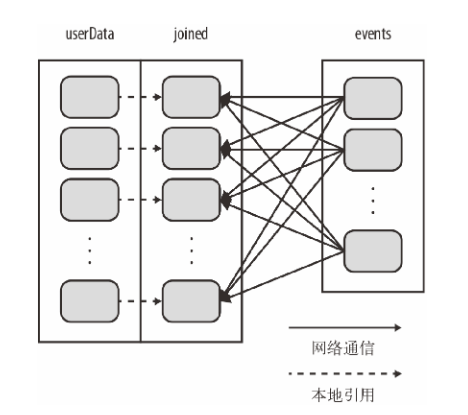
val userData = sc.sequenceFile[UserID, UserInfo]("hdfs://...").persist()
------------------------------------------
val sc = new SparkContext(...)
val userData = sc.sequenceFile[UserID, UserInfo]("hdfs://...").partitionBy(new HashPartitioner(100)).persist() // 构造100个分区
保证相同的key在同一台节点
1、每次调用时都会对userData进行哈希值计算和跨节点数据混洗;浪费时间做很多额外工作
2、只对events进行数据混洗操作,将events中特定的USerId的ID发送到userData的对应分区在的那台机器上,这样需要通过网络传输的数据就大大减少了,程序运行速度也就可以显著提升了
partitionBy是一个转化操作,因此它的返回值总是一个新的RDD,但是他不会改变原来的RDD。RDD一旦创建就无法修改,因此应该对partitionBy的结果进行持久化,并保存为userData,而不是原来的sequenceFile的输出。此外传给partitionBy的100表示分区数目,它会控制之后对这个RDD进行一步操作(比如连接操作)时有多少任务会并行执行。总的来说,这个值至少应该和集群中的总核心数一样。
另外:
sortbykey
groupbykey 会分别生成范围分区的RDD和哈希分区的RDD
map会导致新的RDD失去父RDD的分区信息
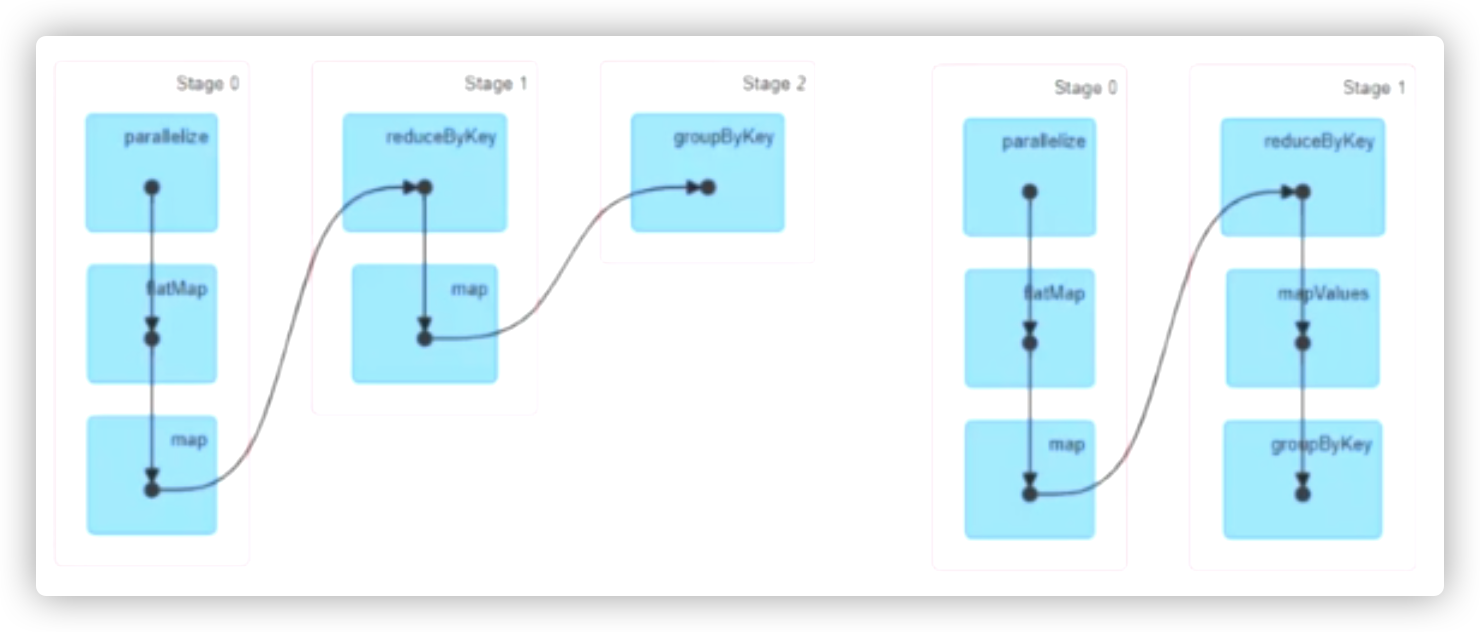
优化
1、key相同、分区器、分区数 都一样的话
使用flatmapvalues mapvalues 替换map、flatmap 以减少 shuffle次数
spark cluster
mesos\k8s
standalone
yarn
standalone
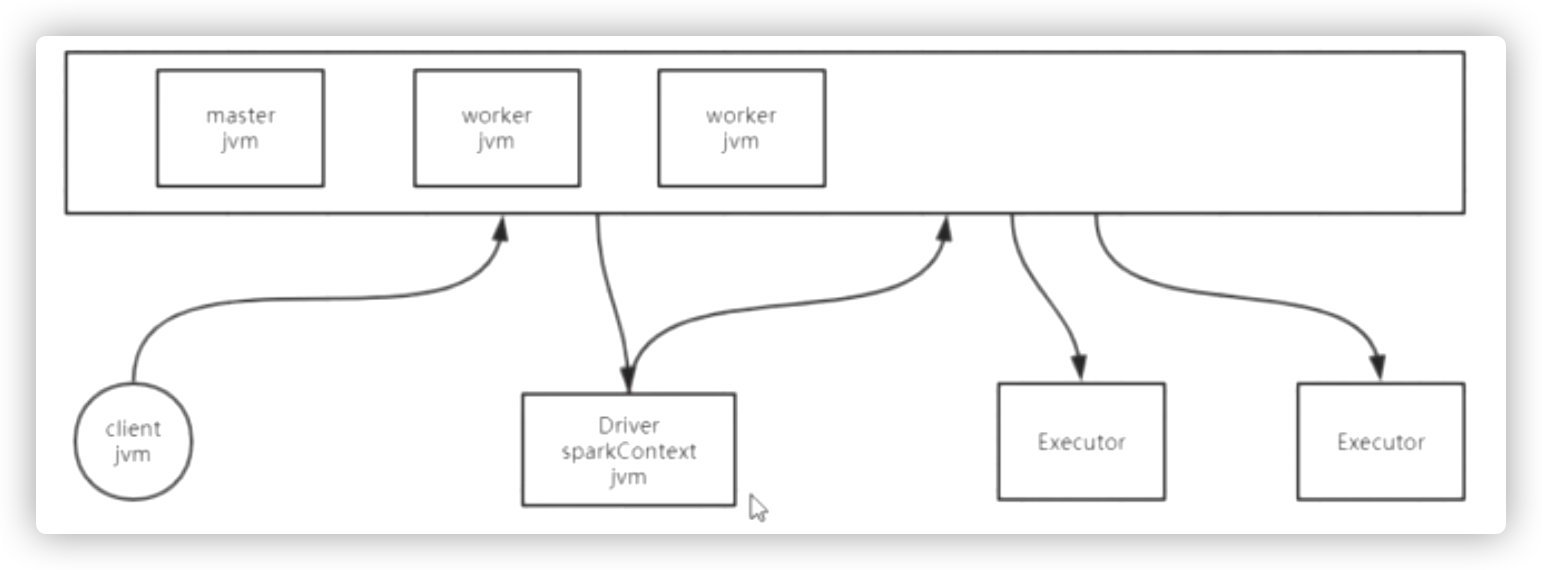
# 启动
master:
./sbin/start-master.sh
slave:
./sbin/start-slave.sh <master-spark-url>
```slaves
node02
node03
node04
```
``` spark-env.sh
export HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.6.5/etc/hadoop
export SPARK_MASTER_HOST=node01
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_WORKER_CORES=4
export SPARK_WORKER_MEMORY=4g
```
``` spark-defaults.conf
# master高可用配置
spark.deploy.recoveryMode ZOOKEEPER
spark.deploy.zookeeper.url node02:2181,node03:2181,node04:2181
spark.deploy.zookeeper.dir /spark
### logging
spark.eventLog.enabled true
spark.eventLog.dir hdfs://cluster/spark_log
spark.history.fs.logDirectory hdfs://cluster/spark_log
spark.history.ui.port 18080
自己创建目录;启动 start-history-server.sh
```
start-all.sh
conf/spark-env.conf
./bin/spark-shell --master spark://IP:PORT,IP:PORT,IP:PORT
submit
```
./bin/spark-submit \
--class <> \
--master <>\
--deploy-mode <>\
--conf <>=<>\
...
<application-jar> \
[application-arguments]
```
spark on yarn
``` spark-env.sh
export HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.6.5/etc/hadoop
```
``` spark-defaults.conf
### logging
spark.eventLog.enabled true
spark.eventLog.dir hdfs://cluster/spark_log
spark.history.fs.logDirectory hdfs://cluster/spark_log
spark.history.ui.port 18080
spark.yarn.jars hdfs://cluster/work/spark_lib/jars/*
# 解决集群运行时,有可能上传所有jar包的事情
自己创建目录;启动 start-history-server.sh
```

分发的是spark目录下jars/*所有jar
spark-shell --master yarn
会追到 spark-env.sh # HADOOP_CONF_DIR 去找yarn的配置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号