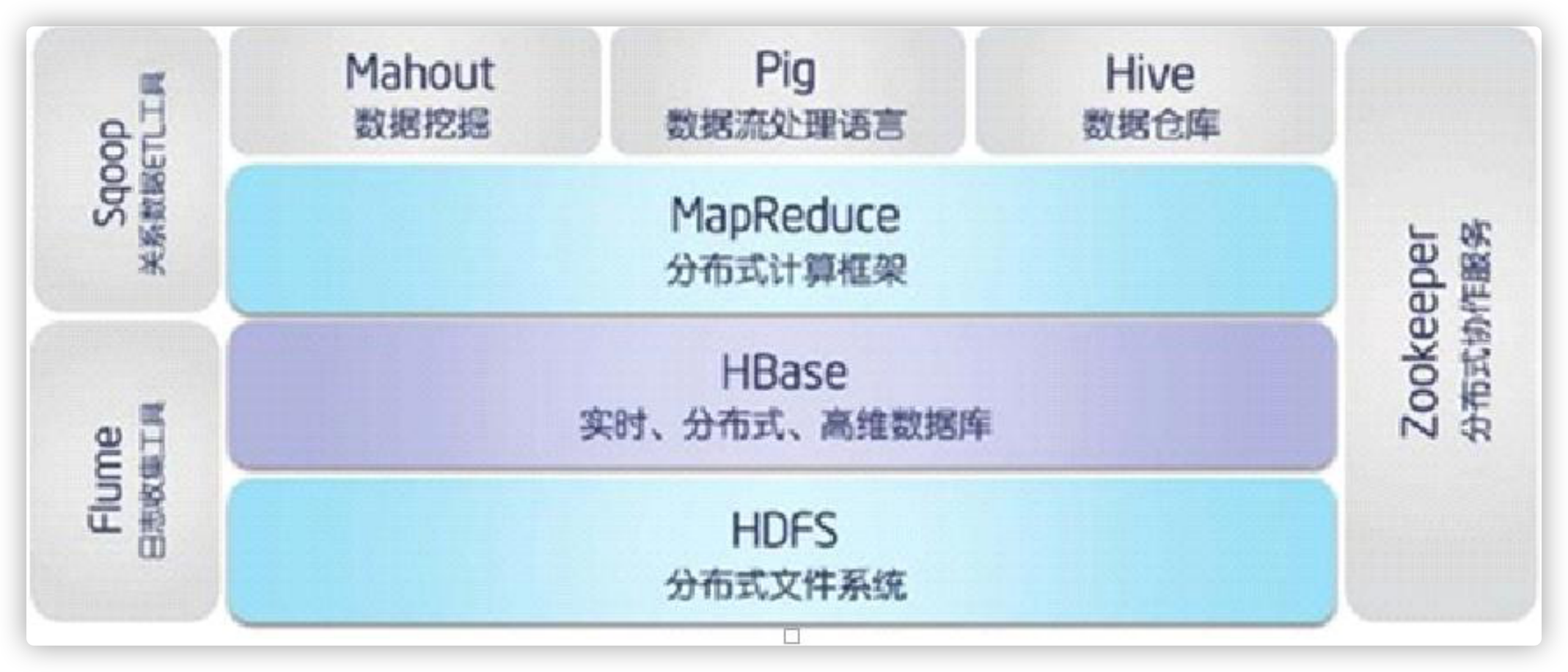
8、Hbase
hive 数据仓库,不能做到实时读写
gfs->hdfs
mapreduce->mapreduce
bigtable->hbase
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables
随机、实时读写(内存)
-- billions of rows X millions of columns
百万行
-- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's
非关系型
Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System,
Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
特点:
高可靠、高性能、面向列、可伸缩(当某列没值时,不占空间)、实时存储的分布式数据库
存储非结构化和半结构化的松散数据(列存NoSQL数据库)
利用hdf、mapreduce、zookeeper(作为其分布式协同服务)
mongodb 文档数据库{:{:,:,:{}}}
逻辑存储结构
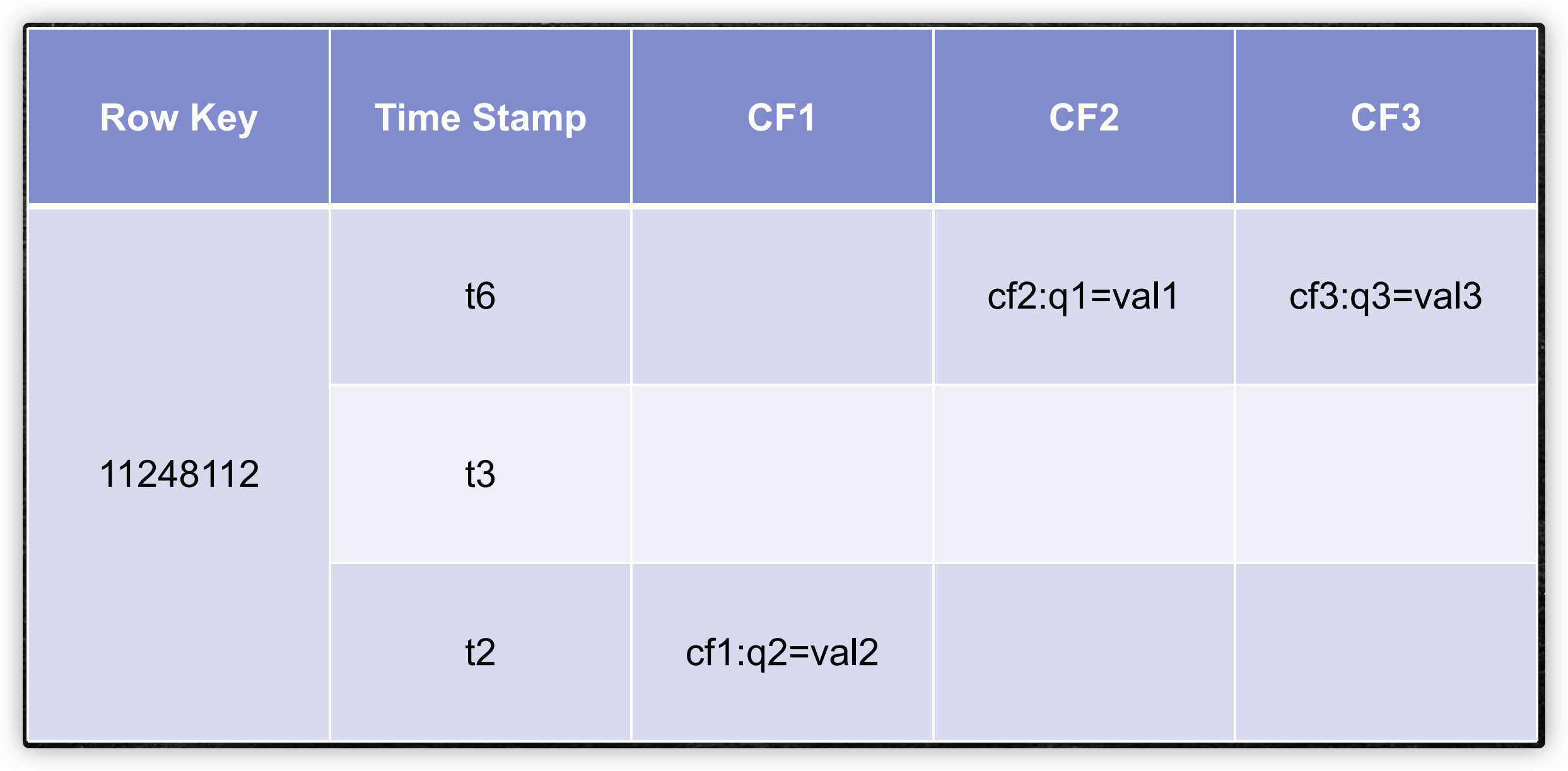
由row key、 cloumn(=<family>+<qualifer>)、version唯一确定数据
一个列族,是1-n个文件
架构
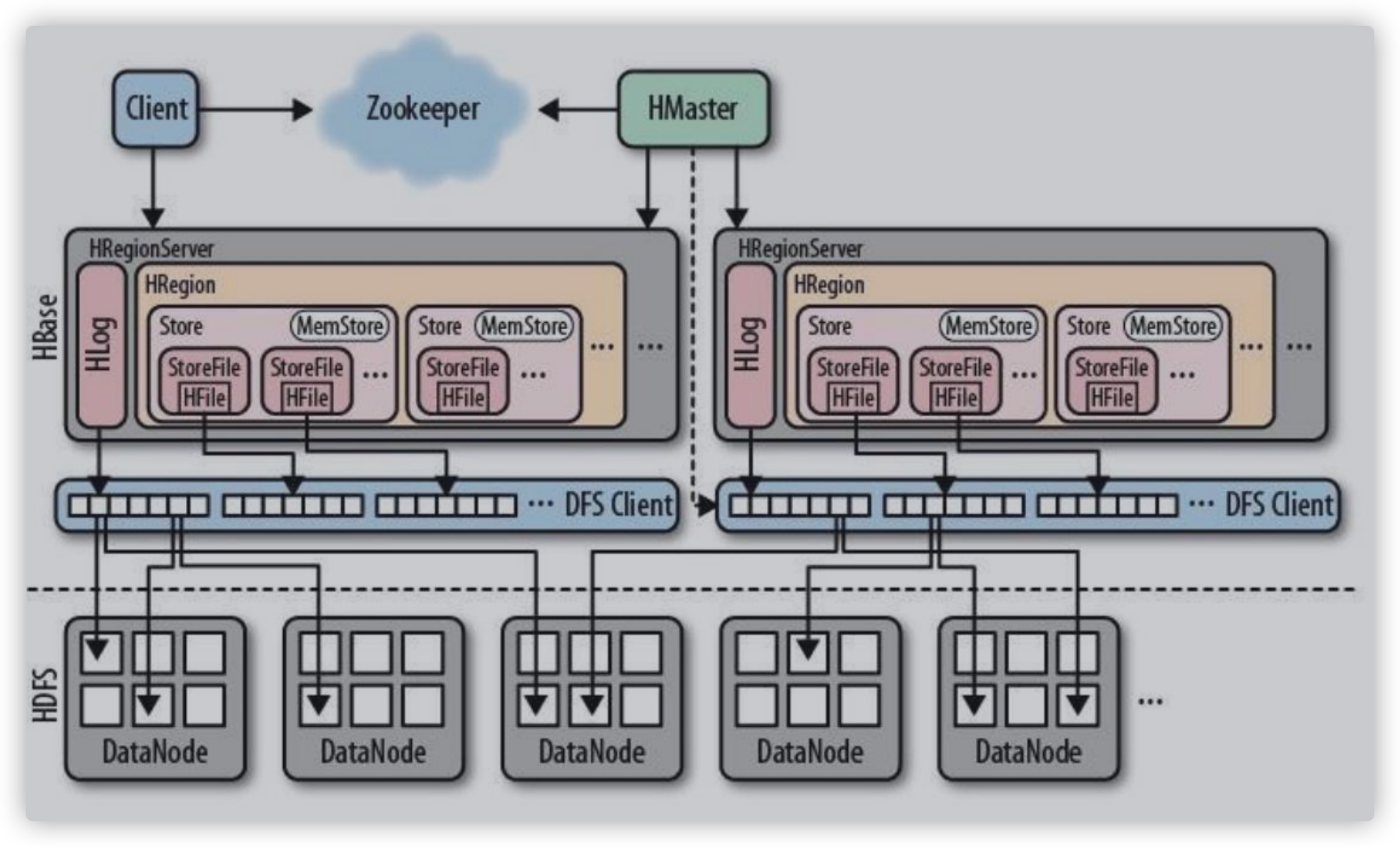
HRegion 表
Store 列族
MemStore 内存
StoreFile 磁盘文件:hbase里的名称
HFile 磁盘文件:hdfs里的名称 ,两者等候室一个文件,不同的封装
当有数据更新时,会有一个程序帮助我们检索;以保证缓存中的数据是新的
client
包含访问HBase的接口并维护cache来加快对HBase的访问
Zookeeper
保证任何时候,集群中只有一个活跃的master
存储所有的Region的所在Server
实时监控Region Server的上线和下线信息,并实时通知Master
存储HBase的schema和table元数据
Master
为Region Server分配Region
负责Region Server的负载均衡器
发现失效的Region Server并重新分配其上的region (真正的数据,保存在hdfs上)
管理用户对table的增删改查
Region Server
Region Server 维护Region,处理对这些region的IO请求
Region server 负责切分在运行过程中变得过大的region
Region
HBase自动把表水平划分为多个region,每个region会保存一个表里面某段连续的数据
每各表一开始只有一个Region,随着数据不断插入表,region不断增大,当增大到一个阈值的时候,region就会等分为两个新的region
当table中的行不断增多,就会有越来越多的region。这样完整的表被保存在多个regionserver上。
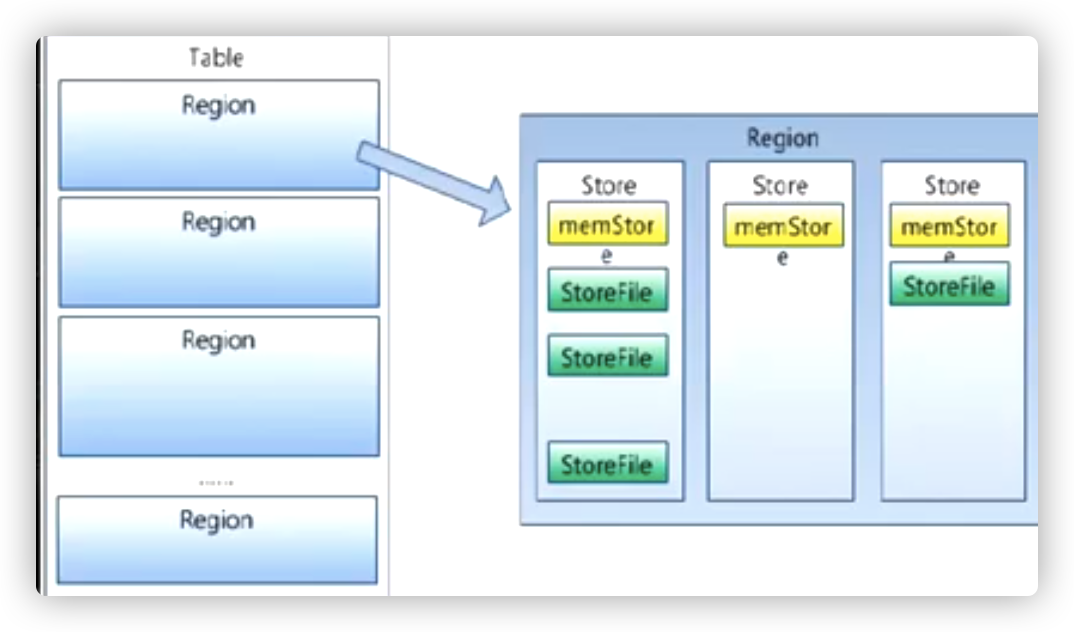
Memstore 与Storefile
一个region由多个store组成,一个store对应一个CF(列族)
store包括位于内存中的memstore和位于磁盘的storefile写操作先写入metastore。当memstore中的数据达到某个阈值,hregionserver会启动
flashcache进程写入storefile,每次写入形成单独的一个storefile
当storefile文件的数量增长到一定阈值时,系统会进行合并(minor、majar compaction),在合并过程中会进行版本合并和删除工作(majar),
形成更大的storefile
当一个region所有storefile的大小和数量超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver
服务器,实现负载均衡,
客户端检索数据,现在memstore找,找不到去blockcache,找不到再去storefile,当找到后往blockcacke中缓存(LRU算法)
缓存更新确认: 当磁盘中存在新的数据比blockcache 新,在内存中会有一个索引提醒 有新的文件生成。
memstore -> index( blockcache + storefile ) index会时刻发生变化
HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRgion可以分布在不同的HRegion上
HRegion由一个或多个Store组成,每个store保存一个columns family
每个Store又由一个memstore和 0至多个storefile组成。 storefile以hfile格式保存在hdfs上
搭建
echo -e '#
export HBASE_HOME=/opt/bigdata/hbase-2.2.5
export PATH=$PATH:$HBASE_HOME/bin
'> /etc/profile
单点
单机部署 :zookeeper、hmaster、hregion server都在一个JVM进程中
echo -e '#!/usr/bin/env bash
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64/jre
export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC"
'> /opt/bigdata/hbase-2.2.5/conf/hbase-env.sh
echo -e '<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hbase.rootdir</name> <value>file:///home/ace/hbase</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/ace/zookeeper</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property>
<!--合并storefile文件配置-->
<property>
<name>hbase.server.thread.wakefrequency</name>
<value>1</value>
</property>
<property>
<name>hbase.hregion.compactchecker.interval.multiplier</name>
<value>1</value>
</property>
</configuration>
'> /opt/bigdata/hbase-2.2.5/conf/hbase-site.xml
分布式
``` yum install ntpdate ntpdate ntp1.aliyun.com ``` ``` ssh-keygen ssh-copy-id -i /root/.ssh/id_rsa.pub node01(节点名称) ```
echo -e '#!/usr/bin/env bash export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el7_8.x86_64/jre export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC" HBASE_MANAGES_ZK=false # 禁用HBASE自带的Zookeeper '> /opt/bigdata/hbase-2.2.5/conf/hbase-env.sh echo -e '<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://mycluster/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node02,node03,node04</value> </property> </configuration>'> /opt/bigdata/hbase-2.2.5/conf/hbase-site.xml
echo -e '
node02
node03
node04'> /opt/bigdata/hbase-2.2.5/conf/regionservers
echo -e '
node04
'> /opt/bigdata/hbase-2.2.5/conf/backup-masters
cp /opt/bigdata/hadoop-3.1.3/etc/hadoop/hdfs-site.xml /opt/bigdata/hbase-2.2.5/conf
[root@node01 ~]# start-hbase.sh master在该节点启动
node01:16010/ HMaster 提供的UI
hbase-daemon.sh start master
操作
hbase(main):011:0> create 'table_psn' , 'cf1' 'cf2'
hbase(main):011:0> descibe 'table_psn'
hbase(main):011:0> scan 'hbase:meta'
hbase(main):011:0> put 'table_psn','row_key','cf1:key','value'
row_key 是字符串类型,字典序排列
hbase(main):011:0> flush 'table_psn'
[ace@node01 cf]$ hbase hfile -p -f file:///home/ace/hbase/data/default/test/89ee2c531921279dd81754ffcaec7e77/cf/a59334e4cc5747ff94fc350e36a7a018 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/bigdata/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/bigdata/hbase-2.2.5/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 2020-07-09 00:20:44,437 INFO [main] metrics.MetricRegistries: Loaded MetricRegistries class org.apache.hadoop.hbase.metrics.impl.MetricRegistriesImpl K: row2/cf:b/1594223767377/Put/vlen=6/seqid=4 V: value2 K: row_key/cf:key/1594224911692/Put/vlen=5/seqid=5 V: value Scanned kv count -> 2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号