5、Hive
数据库:支撑业务数据的访问
数据仓库:本质也是MapReduce,只是将MapReduce封装为了SQL语句
Hive的元数据 存储在关系型数据库中
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.
Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
### 4、数据库与数据仓库的区别
1、数据库是对业务系统的支撑,性能要求高,相应的时间短,而数据仓库则对响应时间没有太多的要求,当然也是越快越好
2、数据库存储的是某一个产品线或者某个业务线的数据,数据仓库可以将多个数据源的数据经过统一的规则清洗之后进行集中统一管理
3、数据库中存储的数据可以修改,无法保存各个历史时刻的数据,数据仓库可以保存各个时间点的数据,形成时间拉链表,可以对各个历史时刻的数据做分析
4、数据库一次操作的数据量小,数据仓库操作的数据量大
5、数据库使用的是实体-关系(E-R)模型,数据仓库使用的是星型模型或者雪花模型
6、数据库是面向事务级别的操作,数据仓库是面向分析的操作
OLTP
1 OLTP,也叫联机事务处理(Online Transaction Processing),表示事务性非常高的系统,一般都是高可用的在线系统,以小的事务以及小的查询为主, 2 评估其系统的时候,一般看其每秒执行的Transaction以及Execute SQL的数量。在这样的系统中,单个数据库每秒处理的Transaction往往超过几百个,或 3 者是几千个,Select 语句的执行量每秒几千甚至几万个。典型的OLTP系统有电子商务系统、银行、证券等,如美国eBay的业务数据库,就是很典型的OLTP数据库。
OLAP
OLAP(On-Line Analysis Processing)在线分析处理是一种共享多维信息的快速分析技术;OLAP利用多维数据库技术使用户从不同角度观察数据;
OLAP用于支持复杂的分析操作,侧重于对管理人员的决策支持,可以满足分析人员快速、灵活地进行大数据复量的复杂查询的要求,并且以一种直观、
易懂的形式呈现查询结果,辅助决策。
架构
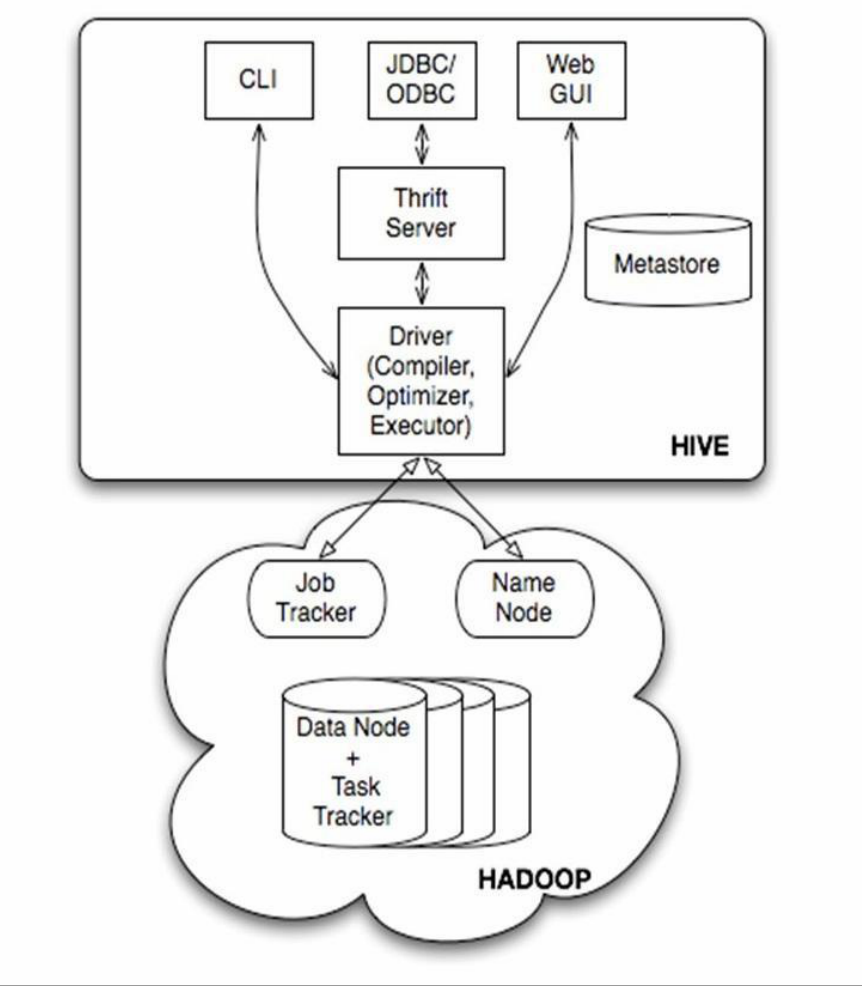
1、用户接口主要有3个:CLI、CLIENT、WUI(2.2之后淘汰).
其中最常用的是CLI,CLI启动的时候,会同时启动一个HIve副本。
Client是Hive的客户端,用户连接至Hive Server。在启动Client模式的时候,需要指出Hive Server所在节点,并且在该节点
启动HIve Server。WUI 是通过浏览器访问Hive
2、Hive将元数据存储在数据库中,如MySQL,Derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性,表的数据所在目录
4、Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询。比如select * from tbl 不会生成MapReduce任务)
Thrift Server : Thrift服务运行客户端使用Java、C++、Ruby等多种语言,通过编程的方式远程访问Hive
Driver : 核心,包括解释器、编译器、优化器等多个组件,完成从SQL到MapReduce的解析优化执行过程
MetaStore : 元数据存储服务,一般将数据存储在关系型数据库中,为了实现HIve元数据的持久化操作,Hive的安装包自带了Derby内存数据库,但是在实际的生产环境中一般使用MySQL来存储元数据
安装要求
http://mirror.cc.columbia.edu/pub/software/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
http://hive.apache.org/
java
hadoop
MetaBase安装
3种安装模式
1、Local/Embedded Metastore Database (Derby) 默认使用 2、Remote Metastore Database
javax.jdo.option.ConnectionURL jdbc:mysql://<host name>/<database name>?createDatabaseIfNotExist=true javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver javax.jdo.option.ConnectionUserName <user name> javax.jdo.option.ConnectionPassword <password>
3、Local/Embedded Metastore Database
4、Remote Metastore Server
用于非Java客户端访问的元数据库,在服务端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库
wget http://mirror.cc.columbia.edu/pub/software/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/bigdata/
cd /opt/bigdata/
mv apache-hive-3.1.2-bin/ apache-hive-3.1.2
mv conf/hive-default.xml.template conf/hive-site.xml
# :.,$-1d 将光标所在行到文件结束行之间删除
1、直连mysql
echo -e '<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true&allowPublicKeyRetrieval=true&characterEncoding=utf8&useSSL=false&localHostTrusted=false&remoteHostTrusted=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>@aA</value> </property> </configuration>'> /opt/bigdata/apache-hive-3.1.2/conf/hive-site.xml
echo -e 'export HIVE_HOME=/opt/bigdata/apache-hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin' >> /etc/profile
https://www.cnblogs.com/it-mh/p/11205866.html
下载java的mysql驱动包
cp mysql-connector-java-8.0.20.jar /opt/bigdata/apache-hive-3.1.2/lib/
2.x之后
服务端: schematool -dbType mysql -initSchema
hive
checkArgument 错误 https://www.cnblogs.com/syq816/p/12632028.html
2、thrift server
比直连多一个配置项
echo -e '<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true&allowPublicKeyRetrieval=true&characterEncoding=utf8&useSSL=false&localHostTrusted=false&remoteHostTrusted=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>@aA</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>@aA</value> </property> </configuration>'> /opt/bigdata/apache-hive-3.1.2/conf/hive-site.xml
hive --service metastore -p <port_num> 默认9083 可以通过hive连接
hiveserver2 & 可以通过jdbc连接
client
echo -e '<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true&characterEncoding=utf8&useSSL=false&localHostTrusted=false&remoteHostTrusted=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>@aA</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>@aA</value> </property> </configuration>'> /opt/bigdata/apache-hive-3.1.2/conf/hive-site.xml
hive
hive> show databases; OK default Time taken: 0.329 seconds, Fetched: 1 row(s) hive> create table tbl(id int,age int); OK Time taken: 0.709 seconds hive> show tables; OK tbl Time taken: 0.062 seconds, Fetched: 1 row(s) hive>
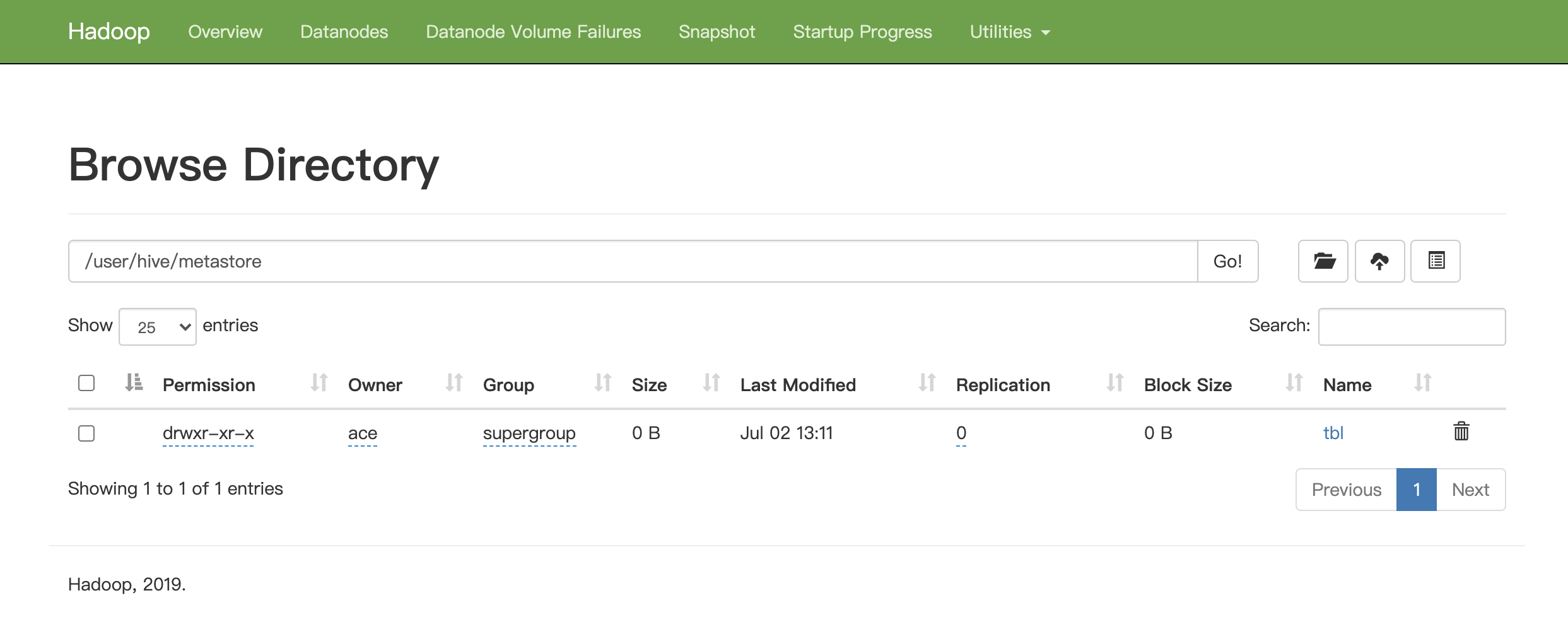


hive> desc tbl; OK id int age int Time taken: 0.049 seconds, Fetched: 2 row(s) hive> desc formatted tbl; OK # col_name data_type comment id int age int # Detailed Table Information Database: default OwnerType: USER Owner: ace CreateTime: Thu Jul 02 13:11:39 CST 2020 LastAccessTime: UNKNOWN Retention: 0 Location: hdfs://node01:9000/user/hive/metastore/tbl Table Type: MANAGED_TABLE Table Parameters: COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"age\":\"true\",\"id\":\"true\"}} bucketing_version 2 numFiles 1 numRows 1 rawDataSize 3 totalSize 4 transient_lastDdlTime 1593666982 # Storage Information SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe InputFormat: org.apache.hadoop.mapred.TextInputFormat OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat Compressed: No Num Buckets: -1 Bucket Columns: [] Sort Columns: [] Storage Desc Params: serialization.format 1 Time taken: 0.074 seconds, Fetched: 32 row(s) hive>
dfs -ls /;
!ls /;
hive的配置有三种
hiveconfig
system
1、可以再启动hive时指定
set hive.cli.print.header=true
2、可以再session设置
set ***
3、.hiveerc文件,并运行配置 需要自己建
每次hive启动时,会去用户家目录下
.hivehistory 保存历史命令


 执行外部命令
执行外部命令
hive -d abc=1
select *from psn where id=${abc};
hive -S -e "select *from psn;select *from psn";
-S静默模式 不显示OK,TOKEN
运行方式
hive --service cli --help
1、cli
2、脚本
3、JDBC hiveserver2
4、GUI接口(hwi,hue)
hive -f sql.txt;
读取文件的命令并执行,
hive -i sql;
读取文件的命令并执行,但不退出会话;
用于初始化会话
Hive SQL
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
CREATE EXTERNAL TABLE psn
(
id int,
name string,
likes ARRAY<string>,
address ARRAY<string>
)
PARTITIONED BY (gender string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
stored as orc
LOCATION '/data'
tblproperties ("orc.compress"="NONE");
看优化
必须是已存在目录
内部表:在默认的存储目录中;再删除时,将元数据库和数据目录删除
外部表:可以指定存储目录,需指定EXTERNAL;只删除元数据
load data local inpath '/root/123.txt' into table span; //导入大量已存在的数据


load data local inpath '/root/123.txt' into table span;
\001代表 ^A \002代表 ^B \003代表 ^C \004代表 ^D \005代表 ^E \006代表 ^F \007代表 ^G \008代表 ^H
Serde
Hive Serde用来做序列化和反序列化,构建在数据存储和执行引擎之间,对两者实现解耦。
1、hive主要用来存储结构化数据,如果结构化数据存储的格式嵌套比较复杂的时候,可以使用serde的方式,利用正则表达式匹配的方法来读取数据
2、当读取数据的时候,数据的某些特殊格式不希望显示在数据中
```
192.168.57.4 - - [29/Feb/2019:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:35 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
```
1 --创建表
2 CREATE TABLE logtbl (
3 host STRING,
4 identity STRING,
5 t_user STRING,
6 `time` STRING,
7 request STRING,
8 referer STRING,
9 agent STRING
10 )
11 ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
12 WITH SERDEPROPERTIES (
13 'input.regex'='([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0- 9]*)'
14 )
15 STORED AS TEXTFILE;
16 --加载数据
17 load data local inpath '/home/ace/nginx.txt' into table logtbl;
18 --查询操作
19 select * from logtbl;
20 --数据显示如下(不包含[]和")
21 192.168.57.4 - - 29/Feb/2019:18:14:35 +0800 GET /bg-upper.png HTTP/1.1 304 -
22 192.168.57.4 - - 29/Feb/2019:18:14:35 +0800 GET /bg-nav.png HTTP/1.1 304 -
23 192.168.57.4 - - 29/Feb/2019:18:14:35 +0800 GET /asf-logo.png HTTP/1.1 304 -
24 192.168.57.4 - - 29/Feb/2019:18:14:35 +0800 GET /bg-button.png HTTP/1.1 304 -
25 192.168.57.4 - - 29/Feb/2019:18:14:35 +0800 GET /bg-middle.png HTTP/1.1 304 -
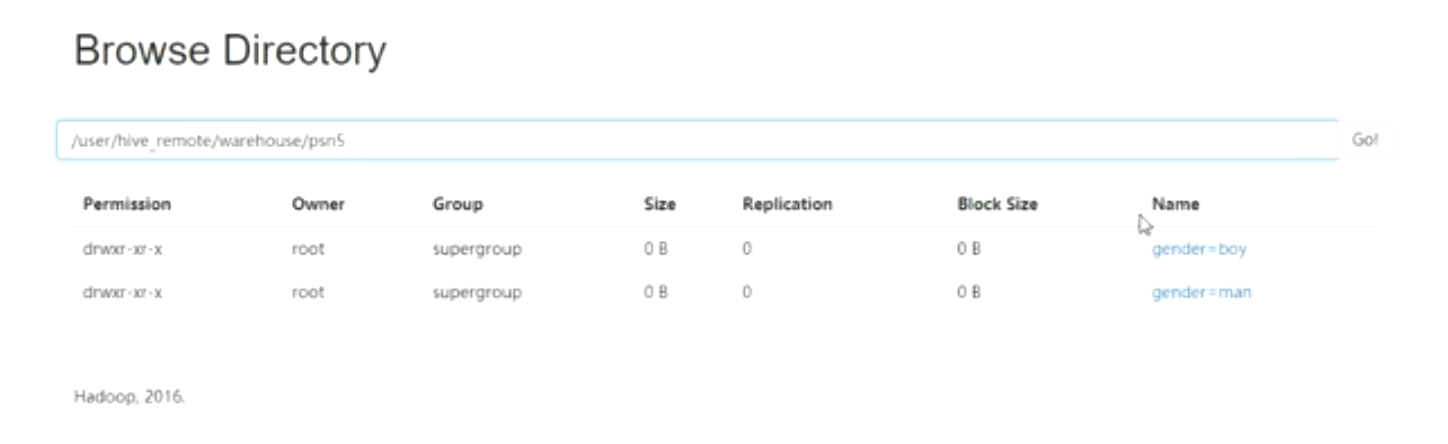
分区
类似于多级缓存
体现在多及目录
CREATE TABLE psn ( id int, name string, likes ARRAY<string>, address ARRAY<string> )
PARTITIONED BY (gender string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':';
分区键也是一列,不用在上边写
可以写多个分区键,顺序不用固定,前后随意,
指定分区键,但是分区值没有,分区值体现在路径上
load data local 'xxx.txt' [overwrite] into table psn partition(gender='man');
ALTER TABLE page_view ADD PARTITION (dt='2008-08-08', country='us') location '/path/to/us/part080808' PARTITION (dt='2008-08-09', country='us') location '/path/to/us/part080809';
ALTER TABLE page_view DROP PARTITION (dt='2008-08-08');
问题:
当数据进入hive时,小根据数据的某一个字段向HIve插入数据,无法满足动态需求
当hdfs存在数据,并且符合分区的格式,此时创建外部表,一定要修复分区
才能查询到对应的数据,否则没有数据
msck repair table psn7;
动态分区
CREATE TABLE psn ( id int, name string, likes ARRAY<string>, address ARRAY<string> ) PARTITIONED BY (gender string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':';
insert into table psn partition(age,render) select id,name,age,render from psn21;
要和psn顺序一样
注意:
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nostrict; 非严格模式,会自动创建目录 ----相关参数---- set hive.exec.max.dynamic.partitions.pernode; set hive.exec.max.dynamic.partitions; set hive.exec.max.created.files.
set hive.exec.dynamic.partition.mode=nostrict;
insert into table psn partition(age=10,render) select id,name,/*age,*/render from psn21;
要和psn顺序一样
insert into table values(1,'asd');
------------------------------------
insert into table psn7 select id,name from psn;
from psn insert overwrite table psn9 select id,name insert into table psn10 select id
# 将psn的id,name插入psn9; id插入psn10
将查询结果保存到本地
insert overwrite local directory '/123.txt' select * from psn;
HIVE基于HDFS, 可以修改,但需要做很多配置, 但是有很多限制。
不支持事务,文件必须被分桶
分桶
解决单个文件太大的问题
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL+BucketedTables
CREATE TABLE user_info_bucketed(user_id BIGINT, firstname STRING, lastname STRING) COMMENT 'A bucketed copy of user_info' PARTITIONED BY(ds STRING) CLUSTERED BY(user_id) INTO 256 BUCKETS;
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':';
最终将数据分到256个文件中
抽样查询
select * from psn tablesample(bucket 2 out of 4 )
x y
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。
x表示从哪个bucket开始抽取,如果需要取多个分区,以后的分区号为当前分区号加上y。
例如,table总共分了4份,当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据。
例如,table总bucket数为4,tablesample(bucket 1 out of 2),表示总共抽取(4/2=)2个bucket的数据,抽取第1(x)个和第3(x+y)个bucket的数据。
x一定要小于y
视图、索引
### 1、Hive Lateral View ##### 1、基本介绍 Lateral View用于和UDTF函数(explode、split)结合来使用。 首先通过UDTF函数拆分成多行,再将多行结果组合成一个支持别名的虚拟表。主要解决在select使用UDTF做查询过程中,查询只能包含单个UDTF,不能包含其他字段、以及多个UDTF的问题。 语法: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias) ##### 2、案例 ```sql select count(distinct(myCol1)), count(distinct(myCol2)) from psn2 LATERAL VIEW explode(likes) myTable1 AS myCol1 LATERAL VIEW explode(address) myTable2 AS myCol2, myCol3; ``` ### 2、Hive视图 ##### 1、Hive视图基本介绍 Hive 中的视图和关系型数据库中视图的概念一致,都是一组数据的逻辑表示,本质上就是一条SELECT语句的结果集。视图是纯粹的逻辑对象,没有关联的存储(Hive 3.0.0引入的物化视图除外),当查询引用视图时,Hive可以将视图的定义与查询结合起来,例如将查询中的过滤器推送到视图中。 ##### 2、Hive视图特点 1、不支持物化视图 2、只能查询,不能做加载数据操作 3、视图的创建,只是保存一份元数据,查询视图时才执行对应的子查询 4、view定义中若包含了ORDER BY/LIMIT语句,当查询视图时也进行ORDER BY/LIMIT语句操作,view当中 定义的优先级更高 5、view支持迭代视图 ##### 3、Hive视图语法 ```sql --创建视图: CREATE VIEW [IF NOT EXISTS] [db_name.]view_name [(column_name [COMMENT column_comment], ...) ] [COMMENT view_comment] [TBLPROPERTIES (property_name = property_value, ...)] AS SELECT ... ; --查询视图: select colums from view; --删除视图: DROP VIEW [IF EXISTS] [db_name.]view_name; ``` ### 3、Hive索引 ##### 1、hive索引 为了提高数据的检索效率,可以使用hive的索引 ##### 2、hive基本操作 ```sql --创建索引: create index t1_index on table psn2(name) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild in table t1_index_table; --as:指定索引器; --in table:指定索引表,若不指定默认生成在default__psn2_t1_index__表中 create index t1_index on table psn2(name) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild; --查询索引 show index on psn2; --重建索引(建立索引之后必须重建索引才能生效) ALTER INDEX t1_index ON psn2 REBUILD; --删除索引 DROP INDEX IF EXISTS t1_index ON psn2; ```
JOIN
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Joins
分页
限制输出
select * from psn order by id limit 10;
授权
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Authorization
# Hive权限管理 ##### 1、hive授权模型介绍  (1)Storage Based Authorization in the Metastore Server 基于存储的授权 - 可以对Metastore中的元数据进行保护,但是没有提供更加细粒度的访问控制(例如:列级别、行级别)。 (2)SQL Standards Based Authorization in HiveServer2 (推荐) 基于SQL标准的Hive授权 - 完全兼容SQL的授权模型,推荐使用该模式。 (3) 集成第三方的 (4)Default Hive Authorization (Legacy Mode) hive默认授权 - 设计目的仅仅只是为了防止用户产生误操作,而不是防止恶意用户访问未经授权的数据。 ##### 2、基于SQL标准的hiveserver2授权模式 (1)完全兼容SQL的授权模型 (2)除支持对于用户的授权认证,还支持角色role的授权认证 1、role可理解为是一组权限的集合,通过role为用户授权 2、一个用户可以具有一个或多个角色,默认包含另种角色:public、admin ##### 3、基于SQL标准的hiveserver2授权模式的限制 1、启用当前认证方式之后,dfs, add, delete, compile, and reset等命令被禁用。 2、通过set命令设置hive configuration的方式被限制某些用户使用。 (可通过修改配置文件hive-site.xml中hive.security.authorization.sqlstd.confwhitelist进行配置) 3、添加、删除函数以及宏的操作,仅为具有admin的用户开放。 4、用户自定义函数(开放支持永久的自定义函数),可通过具有admin角色的用户创建,其他用户都可以使用。 5、Transform功能被禁用。 - 完全兼容SQL的授权模型 - 处指出对于用户的授权认证,还支持角色role的授权认证 role可以理解为是一组权限的集合,通过role为用户授权 一个用户可以具有一个或多个角色 默认包含另种角色:public admin ##### 4、详细配置 ``` <property> <name>hive.security.authorization.enabled</name> <value>true</value> </property> <property> <name>hive.server2.enable.doAs</name> <value>false</value> </property> <property> <name>hive.users.in.admin.role</name> <value>root</value> </property> <property> <name>hive.security.authorization.manager</name> <value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory</value> </property> <property> <name>hive.security.authenticator.manager</name> <value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator</value> </property> ``` ##### 5、Hive权限管理命令 ```sql --角色的添加、删除、查看、设置: -- 创建角色 CREATE ROLE role_name; -- 删除角色 DROP ROLE role_name; -- 设置角色 SET ROLE (role_name|ALL|NONE); -- 查看当前具有的角色 SHOW CURRENT ROLES; -- 查看所有存在的角色 SHOW ROLES; -- 查看权限 SHOW ROLE GRANT (USER|ROLE) perinciple_name; show grant user abcd on psn; -- 授予权限 GRANT ADMIN TO ROLE test with admin option; GRANT SELECT ON psn TO USER abcd with grant option ; -- 删除权限 REVOKE ADMIN FROM ROLE test; ``` ##### 6、Hive权限分配图 Y :privilege required Y+G: privilege "with grant option" required | Action | Select | Insert | Update | Delete | Owership | Admin | URL Privilege(RWX Permission + Ownership) | | ----------------------------------------------- | ------------ | ---------- | ------ | ----------------- | --------------- | ----- | --------------------------------------------- | | ALTER DATABASE | | | | | | Y | | | ALTER INDEX PROPERTIES | | | | | Y | | | | ALTER INDEX REBUILD | | | | | Y | | | | ALTER PARTITION LOCATION | | | | | Y | | Y (for new partition location) | | ALTER TABLE (all of them except the ones above) | | | | | Y | | | | ALTER TABLE ADD PARTITION | | Y | | | | | Y (for partition location) | | ALTER TABLE DROP PARTITION | | | | Y | | | | | ALTER TABLE LOCATION | | | | | Y | | Y (for new location) | | ALTER VIEW PROPERTIES | | | | | Y | | | | ALTER VIEW RENAME | | | | | Y | | | | ANALYZE TABLE | Y | Y | | | | | | | CREATE DATABASE | | | | | | | Y (if custom location specified) | | CREATE FUNCTION | | | | | | Y | | | CREATE INDEX | | | | | Y (of table) | | | | CREATE MACRO | | | | | | Y | | | CREATE TABLE | | | | | Y (of database) | | Y (for create external table – the location) | | CREATE TABLE AS SELECT | Y (of input) | | | | Y (of database) | | | | CREATE VIEW | Y + G | | | | | | | | DELETE | | | | Y | | | | | DESCRIBE TABLE | Y | | | | | | | | DROP DATABASE | | | | | Y | | | | DROP FUNCTION | | | | | | Y | | | DROP INDEX | | | | | Y | | | | DROP MACRO | | | | | | Y | | | DROP TABLE | | | | | Y | | | | DROP VIEW | | | | | Y | | | | DROP VIEW PROPERTIES | | | | | Y | | | | EXPLAIN | Y | | | | | | | | INSERT | | Y | | Y (for OVERWRITE) | | | | | LOAD | | Y (output) | | Y (output) | | | Y (input location) | | MSCK (metastore check) | | | | | | Y | | | SELECT | Y | | | | | | | | SHOW COLUMNS | Y | | | | | | | | SHOW CREATE TABLE | Y+G | | | | | | | | SHOW PARTITIONS | Y | | | | | | | | SHOW TABLE PROPERTIES | Y | | | | | | | | SHOW TABLE STATUS | Y | | | | | | | | TRUNCATE TABLE | | | | | Y | | | | UPDATE | | | Y | | | | |
和HBASE集成
https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration#HBaseIntegration-Introduction
连接单机 HBASE
hive --auxpath
$HIVE_SRC/build/dist/lib/hive-hbase-handler-0.9.0.jar,
$HIVE_SRC/build/dist/lib/hbase-0.92.0.jar,
$HIVE_SRC/build/dist/lib/zookeeper-3.3.4.jar,
$HIVE_SRC/build/dist/lib/guava-r09.jar
--hiveconf hbase.master=node01:60000
链接集群 hbase
hive --auxpath
$HIVE_SRC/build/dist/lib/hive-hbase-handler-0.9.0.jar,
$HIVE_SRC/build/dist/lib/hbase-0.92.0.jar,
$HIVE_SRC/build/dist/lib/zookeeper-3.3.4.jar,
$HIVE_SRC/build/dist/lib/guava-r09.jar
--hiveconf
hbase.zookeeper.quorum=zk1.yoyodyne.com,zk2.yoyodyne.com,zk3.yoyodyne.com
1、hive 创建内部表 ,Hbase也会一起创建 2、hive创建外部表, hbase 的表必须存在

 浙公网安备 33010602011771号
浙公网安备 33010602011771号