4、Hadoop.yarn
yarn是hadoop2.x中出现的,为了解决多个集群中 资源争抢的问题 不同的计算框架会运行在一个环境中,各自之间不能争抢资源,所以所有倾向于将对资源的管理切出交给
一个人去管,一个人对环境资源的任志是一致的 ---> 资源管理独立出来
yarn(RM、NM) 主从,支持HA
1.x---->2.x:
JT,TT是MR的常服务;
2.x之后
MR的cli,调度,任务,都是临时服务
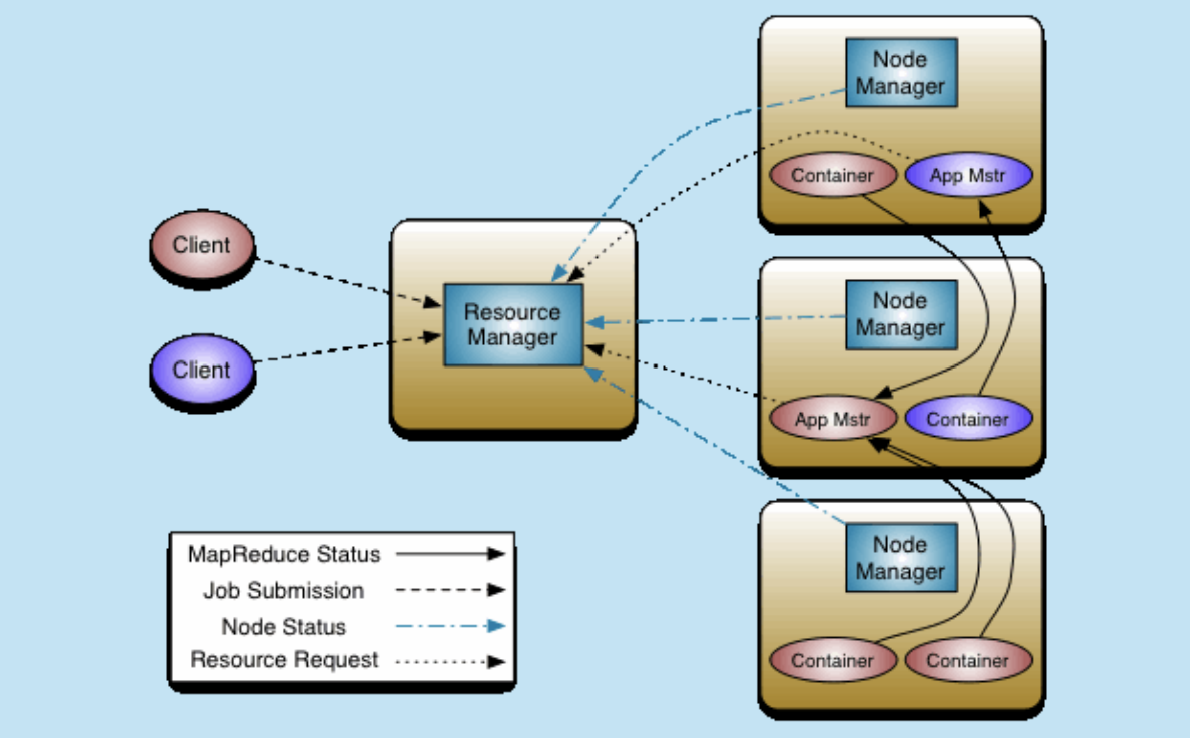
client做该做的事情
1、client向RM提交任务
2、RM选取一个NM启动APP Master (也是一种container,不是docker),有失败重试机制
3、AM根据清单从RM申请Continer
4、RM根据NM启动一批Container
4、Container向app Master注册容器,以供App Master使用 (Container有失败重试)
5、APP Master将(map、reduce)角色分配给对应Container;再由Container从hdfs中获取配置 并启动。
* 单点故障 ---> jontracker变成了一个任务一个 * 压力过大 ---> jobtracker变成了一个任务一个。 * 集成了【资源管理、任务调度】两者耦合 ----------> 抽离出来
MR 运行 MapReduce on yarn 1、MR-CLI(切片清单、配置、jar、上传到hdfs) 访问RM申请AppMaster
2、RM选择一个不忙的节点通知NM启动一个Container,在里面反射一个MRAppMaster
3、启动MRAppMaster,从hdfs下载切片清单,向RM申请资源
4、由RM根据自己掌握的资源情况得到一个确定清单,通知NM启动container
5、container启动后会反向注册到已经启动的MRAppMaster进程
6、MRAppMaster(曾经的JobTracker阉割版,不再带资源管理器) 最终将任务Task发送给container
7、container会反射相应的Task类为对象,调用方法执行,其结果就是我们的业务逻辑代码的执行
8、计算框架都有task失败重试机制

单节点安装
# 目录会自动创建 cp $HADOOP_HOME/etc/hadoop/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml.bak echo -e '<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <!-- <value>yarn</value> --> <value>local</value> </property> </configuration> ' > $HADOOP_HOME/etc/hadoop/mapred-site.xml
cp $HADOOP_HOME/etc/hadoop/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml.bak echo -e '<?xml version="1.0"?> <configuration> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> ' > $HADOOP_HOME/etc/hadoop/yarn-site.xml # Map -shuffle -> Reduce ,协调拉取文件的过程
start-yarn.sh # node01:8088 # stop-yarn.sh
yarn-daemon.sh start resourcemanager
集群
在单点的基础上
cp $HADOOP_HOME/etc/hadoop/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml.bak echo -e '<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <!-- <value>yarn</value> --> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/var/bigdata/hadoop-3.1.3</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/var/bigdata/hadoop-3.1.3</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/var/bigdata/hadoop-3.1.3</value> </property> <!-- 内存相关--> <property> <name>mapreduce.map.memory.mb</name> <value>4096</value> </property> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx4096M</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>4096</value> </property> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx4096M</value> </property> <!-- mr 的任务历史记录 --> <property> <name>mapred.job.history.server.embedded</name> <value>true</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>node03:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node03:50060</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/work/mr_history_tmp</value> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/work/mr-history_done</value> </property> </configuration> ' > $HADOOP_HOME/etc/hadoop/yarn-site.xml
mapred-site.xml
:node03# mr-jobhistory-daemon.sh start historyserver
日志服务
# vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<!-- 启用HA -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>hadoop.zk.address</name> <value>node01:2181,node02:2181,node03:2181</value> </property>
<property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn_cluser_id</value>
<!-- 集群前缀, --> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>master2</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>node03:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>node04:8088</value> </property>
node manager和DataNode一样都是依赖workers文件的。
在node01 start-dfs.sh
jps查看
如果node03,node04没有resourcemanager
在相应机器上
yarn-daemon.sh start resourcemanager
A启动, B启动 都是一样 的。都是依赖配置文件的
访问从RM:8088/时,会跳转到主RM
运行
-----集群 client --> RM --> App Master
1、hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /user/ace/input /user/ace/output
2、嵌入xxx
-----单机
3、local
和mapreduce.framework.name有关
当client为windows时,开启service.app-submisscross-platform true
job.setJar('xxx.jar')
dfs dfs -cat /user/ace/output/part-r-00000 >123.txt
tail -n10 123.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号