MapReduce 计算框架
计算向数据偏移
1、获取文件的location、offset
2、根据设定的split大小 ,构造新的offset
3、拿着新的offset去定位location 一个map对应一个split
4、然后将切片清单 发送到ResourceManager
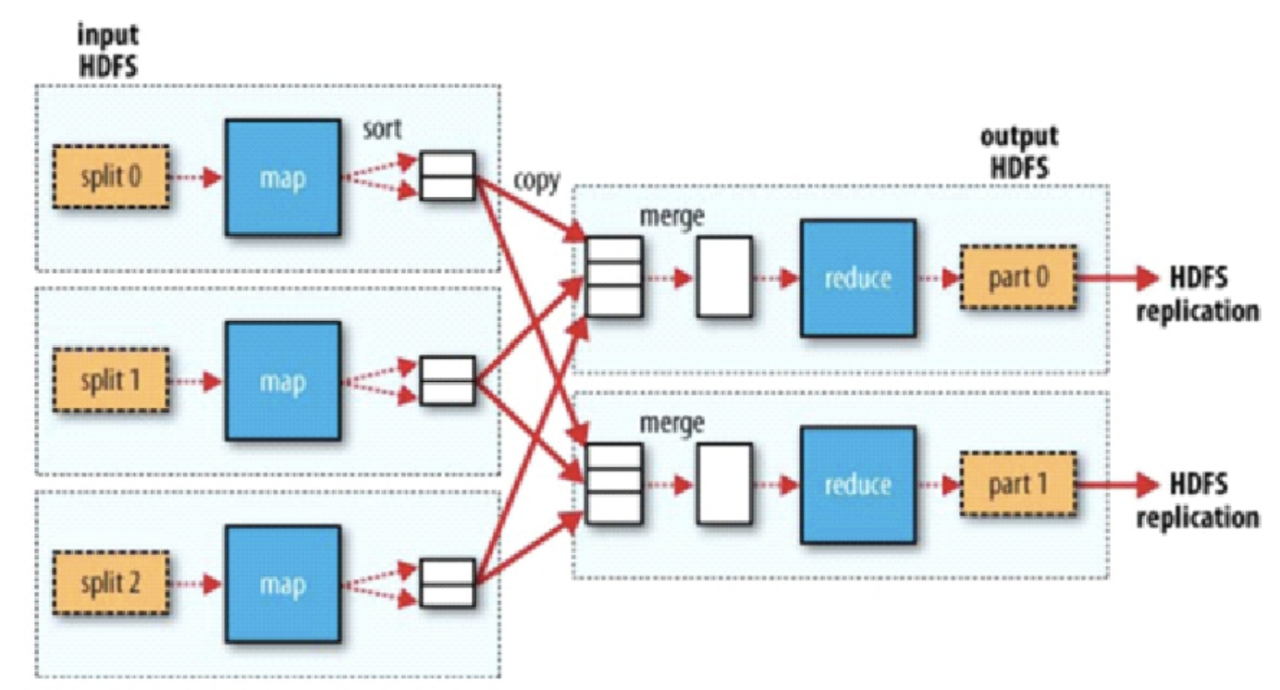
------map---------
1、split不同于block, block是按照字节进行的区分;而split是按照行或者<>;或者。。。 实现物理到逻辑的转换
2、map的操作单元是一个个记录,将相同的key存储为一组
------reduce--------------
3、对每一个key进行一次reduce
mapreduce:批量计算;线性的关系
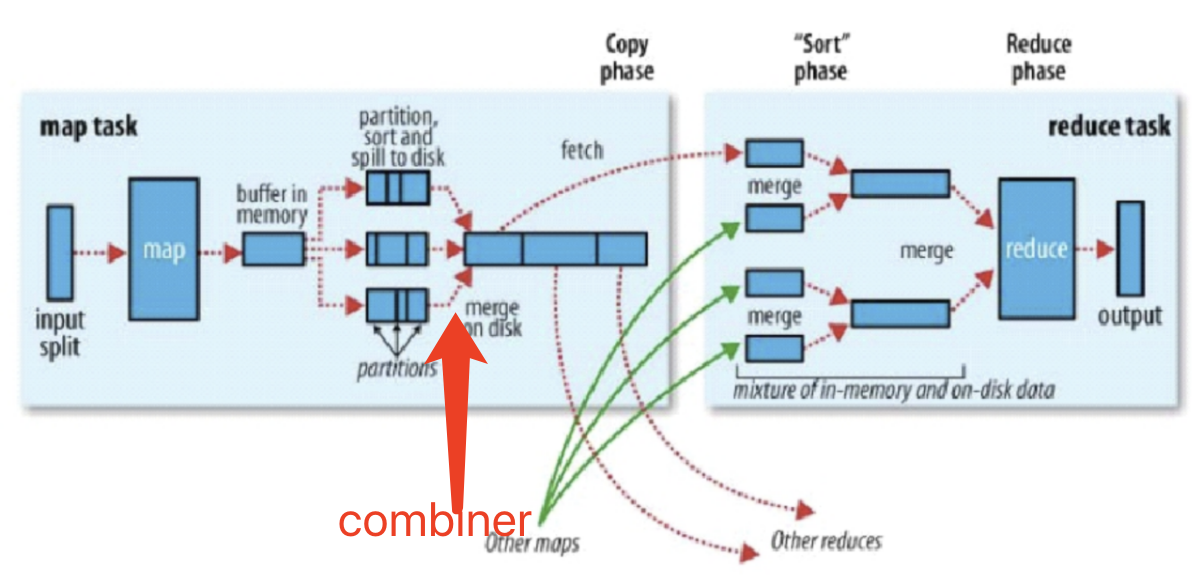
- 再将数据存储到缓存中前;会对数据KEY 哈希 生成分区键
- 然后将每组 具有相同分区键的key进行排序
- 再将所有的数据写入瓷盘中的一个文件中(此时,相同的key(分区键)是挨着的;方便reduce获取
buffer默认100MB,超过80%时会进行后面
hadoop 1.x:
buffer:[(k,v),(k,v)...]
index :[(p,kindex,vindex,vend,各占4B)] ===> 这两个数组空间不好控制
hadoop 2.x:
buffer: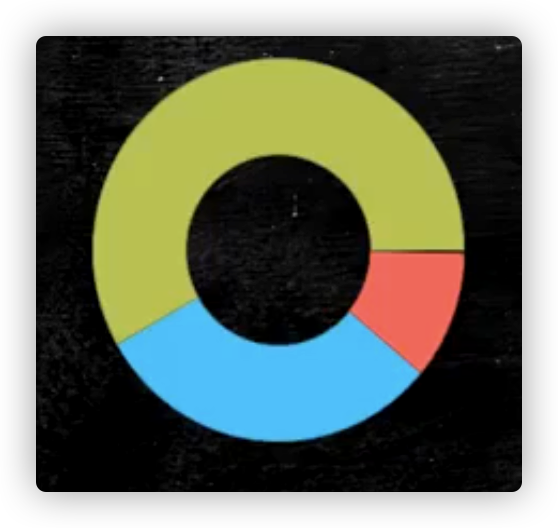 环形空间,从赤道向左存储index,向右存储data, 当超过80%;
环形空间,从赤道向左存储index,向右存储data, 当超过80%;
锁定当前区域,在空余区域选取新的赤道。 使用新的线程在锁定区域排序
排序默认快排(排序的是index,data的顺序并不会改变, 最后根据index读取数据 ) 再 归并,后边默认归并
combiner:小的reduce,为了数据压缩, 假若说map输出10万条hello 1 ;传给reduce很费事,但是数据压缩后,只传输一条,多好
- 其实就是一个map的reduce按组统计
- 发生在哪个时间点
- 内存溢写数据之前排序之后,溢写的io变少
- 最终map输出结束,过程中buffer溢写出多个小文件
mapSpillForCombiner = 3
避免小文件的碎片化对未来reduce拉取数据造成的随机读写
一个reduce会去所有的node获取相同key的数据
ReduceTask
1、shuffle 将相同的key从不同的节点上以HTTP拉取到一个分区
2、sort 整个MR框架中只有map端是无序的,用的是快排
reduce这里的所谓的sort
grouping comparator 分组比较器(主要任务是分组) true/false
例如 : 按照年月 进行分组,按照温度进行倒序
sort comparator 排序比较器 返回 0,1,-1 ==>排序比较器 可以替代分组比较器
计算向数据移动
1、Cli
- 会根据每次的计算数据,咨询NN元数据(block) 算切片(根据计算类型;调整切片清单 ) ==> map的数量
block:(offset,location)
split:(逻辑;任务,以及哪些节点)
- 生成计算程序未来运行时的相关【运行时的配置文件】。。。。xml
- 未来的移动应该相对可靠(hdfs)
cli会将程序,split清单,配置xml,上传到hdfs的目录中 (副本数 最好多几份)
TaskTracker再将响应的文件下载回来执行
- Cli调用JobTracker,通知要启动一个计算程序了,并且告知文件都放在了hdfs的哪些地方
2、JobTracker
- 资源调度
- 任务调度
- 从hdfs取回【split清单】
- 根据自己收到的TT汇报的资源,最终确定每一个split对应的map应该去到哪一个节点【确定清单】
- 未来,TT再心跳的时候会取回分配给自己的资源
* 单点故障
* 压力过大
* 集成了【资源管理、任务调度】两者耦合
弊端:
重复
因为各自实现资源管理,部署在同一批硬件时;因为隔离不能感知--->资源争抢
====> hadoop2.x为了解决这个问题,出现了yarn
2、TaskTracker : 位于DN
- 任务管理
- 资源汇报
- 在心跳取回任务后
- 从hdfs中下载jar,xml。。。
- 最终启动任务描述中的MapTask、ReduceTask

 浙公网安备 33010602011771号
浙公网安备 33010602011771号