2、Hadoop.hdfs集群
在第一篇的基础上,要解决的问题 1、NN单点故障 2、内存压力过大 解决方案: 1、多个NN将数据分片,NN管理不同路径分支的数据
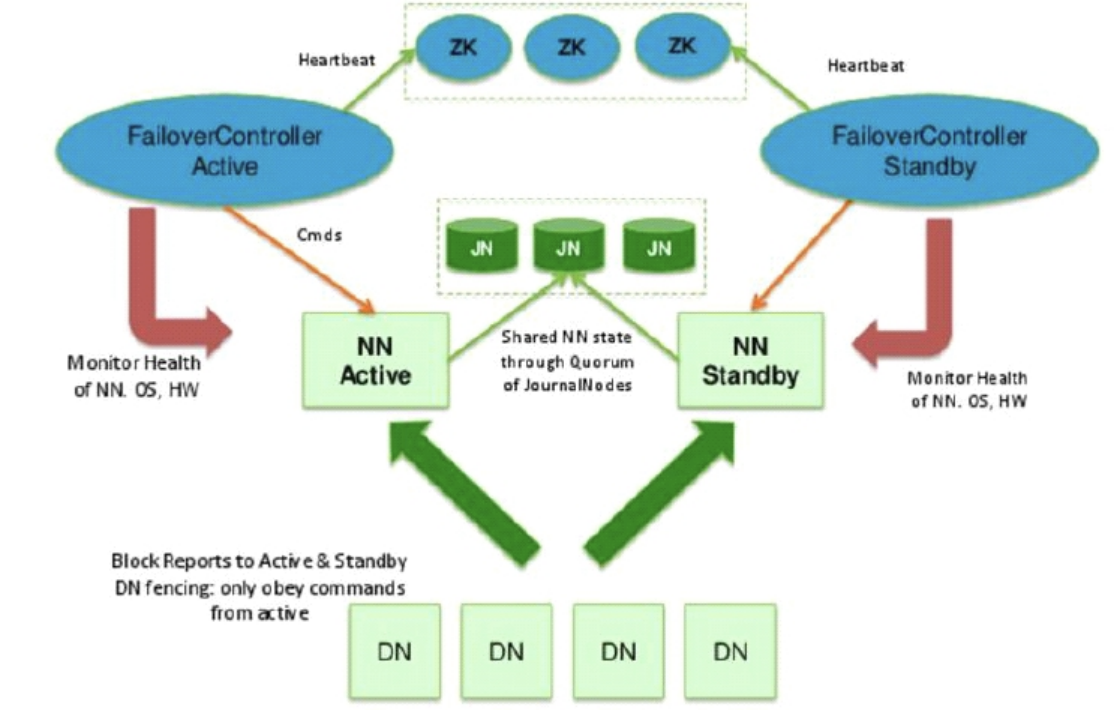
1 先启动JN 2 hadoop-daemon.sh start journalnode 3 选择一个NN做格式化, 这样JN中的数据也可以格式化 <只有第一次搭建做,在任意一台namenode> 4 hdfs namenode -format 5 启动这个格式化的NN,以备另外一台同步 6 hadoop-daemon.sh start namenode 7 在另外一台机器中 hdfs namenode -bootstrapStandby 同步数据 8 格式化ZK hdfs zkfc -format (为每个集群启动一个单独的znode) 9 start-dfs.sh
1 ZKFC 自己登陆自己,登陆其他机器 2 3 1)启动start-dfs.sh脚本的机器需要将公钥分发给其他机器,以便远程登录,启动程序 4 2)在HA模式下,每一个NN身边都有一个ZKFC,会用免密方式控制自己和其他NN
Zookeeper
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.6.1/apache-zookeeper-3.6.1.tar.gz
# 修改 conf/zoo_sample.cfg
dataDir=/var/bigdata/hadoop/zk
....
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
# 配置在每一台都需要配置 权重
mkdir /var/bigdata/hadoop/zk
echo 1 > /var/bigdata/hadoop/zk/myid
export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.6.1
export PATH=$PATH:$ZOOKEEPER_HOME/bin
# 所有ZK节点启动
zkServer.sh start
1、cp zoo_example.cfg zoo.cfg 2、Error: Could not find or load main class org.apache.zookeeper.server.quorum.QuorumPeerMainv 更改版本
http://apache.fayea.com/zookeeper/zookeeper-3.5.5/apache-zookeeper-3.5.5.tar.gz
HDFS集成ZK
1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <configuration> 4 <property> 5 <name>fs.defaultFS</name> 6 <value>hdfs://mycluster</value> 7 </property> 8 <property> 9 <name>ha.zookeeper.quorum</name> 10 <value>node02:2181,node03:2181,node04:2181</value> 11 </property> 12 </configuration>
1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <configuration> 4 <property> 5 <name>dfs.replication</name> 6 <value>2</value> 7 </property> 8 <property> 9 <name>dfs.namenode.name.dir</name> 10 <value>/var/bigdata/hadoop/ha/dfs/name</value> 11 </property> 12 <property> 13 <name>dfs.datanode.data.dir</name> 14 <value>/var/bigdata/hadoop/ha/dfs/data</value> 15 </property> 16 17 <property> 18 <name>dfs.nameservices</name> 19 <value>mycluster</value> 20 </property> 21 <property> 22 <name>dfs.ha.namenodes.mycluster</name> 23 <value>nn1,nn2</value> 24 </property> 25 <!-- 逻辑到物理 --> 26 <property> 27 <name>dfs.namenode.rpc-address.mycluster.nn1</name> 28 <value>node01:8020</value> 29 </property> 30 <property> 31 <name>dfs.namenode.rpc-address.mycluster.nn2</name> 32 <value>node02:8020</value> 33 </property> 34 <property> 35 <name>dfs.namenode.http-address.mycluster.nn1</name> 36 <value>node01:50070</value> 37 </property> 38 <property> 39 <name>dfs.namenode.http-address.mycluster.nn2</name> 40 <value>node02:50070</value> 41 </property> 42 43 <!-- journalnode 配置--> 44 <property> 45 <name>dfs.namenode.shared.edits.dir</name> 46 <value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value> 47 </property> 48 <property> 49 <name>dfs.journalnode.edits.dir</name> 50 <value>/var/bigdata/hadoop/ha/dfs/jn</value> 51 </property> 52 53 <!--免密的配置 --> 54 <property> 55 <name>dfs.client.failover.proxy.provider.mycluster</name> 56 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 57 </property> 58 <property> 59 <name>dfs.ha.fencing.methods</name> 60 <value>sshfence</value> 61 </property> 62 <property> 63 <name>dfs.ha.fencing.ssh.private-key-files</name> 64 <value>/home/god/.ssh/id_dsa</value> 65 </property> 66 67 <!-- 开启HA --> 68 <property> 69 <name>dfs.ha.automatic-failover.enabled</name> 70 <value>true</value> 71 </property> 72 73 </configuration>
1、先启动所有的journalnode hadoop-daemon.sh start journalnode
--------hdfs-------------
2、随便选一台NN
hdfs namenode -format
3、启动第一个NN
hadoop-daemon.sh start namenode
4、其他NN同步
hdfs namenode -bootstrapStandby
-------zkfc--------------
5、在所有ZK节点,格式化;(创建集群对应目录树)
hdfs zkfc -format
--------start-------------
6、在其中一个NN
start-dfs.sh 启动nn,dn,zkfc(无法控制)
权限
useradd god passwd god chown -R god:god /var/bigdata/hadoop-3.6.1/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号